PageRank模型的改進及微博用戶影響力挖掘算法
2017-06-29 12:00:34毛國君謝松燕胡殿軍
計算機應用與軟件 2017年5期
毛國君 謝松燕 胡殿軍
(中央財經大學信息學院 北京 100081)
PageRank模型的改進及微博用戶影響力挖掘算法
毛國君 謝松燕 胡殿軍
(中央財經大學信息學院 北京 100081)
隨著Web技術的發展,微博逐漸成為當下最流行的社交平臺之一。微博中用戶影響力計算是相關研究中的焦點問題。通過對PageRank模型的改進,提出一種新的用戶影響力挖掘算法PR4WB(PageRank for MicroBlogs),解決了傳統的PageRank算法由于頁面權威值的等分傳遞帶來的潛在誤差過大的問題。PR4WB算法在考慮微博中用戶關系的同時,利用社會網絡概念將自身的活躍度、博文質量及可信性加以關聯,形成動態的評價模型。基于Twitter數據的實驗表明,PR4WB算法能更加準確、客觀地反映出用戶的實際影響力。
用戶影響力 社會網絡 微博 推特 PageRank算法
0 引 言
隨著大數據時代的到來以及Web2.0技術的應用,在線社會網絡得到了快速的發展。微博作為一種重要的社交平臺,已經在社會、政治、生活等方面成為不可忽略的輿情傳播載體。國內使用最多的微博平臺是新浪微博,而國際上使用較為廣泛的微博服務則是Twitter。據統計,截至2014年7月,Twitter的活躍注冊用戶數已超過6億,而且每日平均新增用戶數為135 000,平均每日發表微博數為5 800萬。因此,微博是一個用戶數目多、博文帖子多的一個現代社交媒介。然而,微博中的用戶是不對等的,博文也有輕重之分,所以微博中用戶影響力的計算除了簡單地考慮用戶的鏈接關系外,也應該綜合地利用用戶的活躍程度、博文數量及質量和用戶的可信度等因素。
已經出現的基于PageRank模型的微博用戶影響力計算和排名方法更多地是考慮用戶的鏈接數目,對于用戶的博文質量及可信程度關注較少,因此很難客觀地評價用戶的影響力。特別是,由于缺乏對用戶動態表現(如活躍度)、可信度(如是否認證)等的評估,使得計算結果距離實際用戶的影響力相差較大。本文將分析傳統的PageRank算法在解決微博用戶影響力挖掘中可能出現的問題,在此基礎上通過嵌入用戶活躍度、博文質量及可信度等因素的評估結果,改進傳統的PageRank模型,形成適合于微博中用戶影響力挖掘的動態評價算法。
1 相關研究及PageRank模型的發展
PageRank模型[1]是由Google公司的兩位創始人拉里·佩琪和謝爾蓋·布林共同提出的。該模型的最初動因是實現網絡上的網頁排名,因此該技術被廣泛應用到網絡的搜索引擎設計中。由于PageRank模型本質上是對有向圖的節點等級的計算技術,所以它也能應用到其他的領域。特別地,PageRank算法近年已經被應用到微博的用戶影響力排名中。
Tunkelang[2]等利用Twitter用戶節點之間的關注(Follow)關系,構造了一張基于鏈接關系的有向圖,并且利用PageRank模型實現了Twitter用戶的影響力排序。Weng[3]等也成功地從Twitter中構建了一個好友關系圖,并且利用PageRank算法思想提出了一個被稱為TwitterRank的算法。之后,Weng[4]等也將用戶興趣加入到評價體系中,改進了TwitterRank算法,可以更好地實現在某一特定話題討論中的用戶影響力分析。
事實上,微博影響力研究已經成為一個重要的交叉研究課題。有3個重要的研究視點被關注:(1) 將微博用戶及其交互行為在社會網絡的分析框架下進行分析[5-6];(2) 利用信息傳播理論研究微博中的網絡傳播動力學行為規律,發現傳播中的關鍵用戶及其行為[7];(3) 從數據挖掘觀點,進行數據的關聯性分析,發現微博中數據隱含的規律性知識[8-9]。這些研究都有一個核心技術支撐,即有向圖分析。微博中的用戶通過用戶間的交互行為可以構成特定的有向圖結構;微博中的用戶就是有向圖的節點、并且微博中的社會關系或者博文傳播可以形成有向圖的弧;微博中的數據可以在有向圖的邏輯結構下實施數據挖掘技術。從這個意義上說,PageRank模型能夠將以上3種視點從技術層面上加以統一。
原始的PageRank模型是針對網站中的網頁的重要性評估提出來的,通過計算每個頁面的權威值來實現頁面的等級劃分。簡單地說,一個頁面的權威值就是所有指向該頁面的各個頁面平均分配給該頁面的權威值之和[1]。很顯然,基于這樣模型的PageRank算法是一個逐層進行節點權威值計算的過程。谷歌公司在實際應用中發現了原始PageRank算法的致命缺點:假如一個頁面節點沒有出度,特別是入度又很大,就可能造成節點的權威值“滯留”,進而使傳遞受阻。解決這個問題的基本方法就是引入隨機沖浪模型,這也成為目前使用的最廣泛的PageRank模型[10]。基于隨機沖浪的PageRank模型的頁面權威值計算如下:
(1)
其中:PR(x)代表頁面x的權威值;d(∈[0,1])為阻尼系數,暗示頁面的隨機跳轉概率為1-d;B(x)表示指向頁面x的網頁的集合;N(x)表示頁面x鏈出的網頁集合。
式(1)給出的模型需要轉變成可計算的算法來完成。各種版本的PageRank算法都是通過多次迭代計算實現的,其中最流行的迭代方式是通過所謂的轉移概率矩陣技術來實施的[8]。簡單地說,一個轉移概率矩陣表示為M=(mi,j),其中mi,j是頁面j跳轉到頁面i的概率。目前使用的PageRank算法大多都是采用等分概率的方法來進行傳遞的。例如:圖1給出了一個4個節點的有向圖,對應著4個不同的頁面及其鏈接關系。通過傳統的PageRank算法可以獲得對應的轉移概率矩陣M:

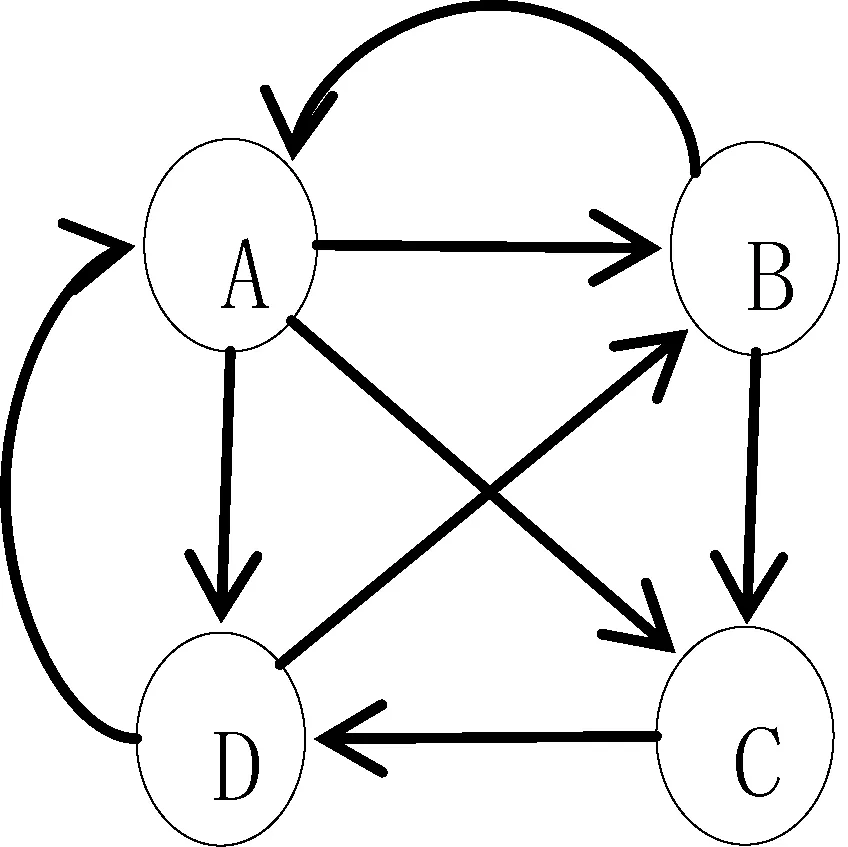
圖1 一個頁面鏈接對應有向圖
這樣,設n是頁面節點的數目,R=(r1,r2, …,rn)T表示頁面節點的權威值向量,則可以通過多次迭代執行下面的式(2)來逐步逼近式(1)的效果:
Ri+1=(1-d)·I+d·M·Ri
(2)
其中:I為全1向量,即(1,1,…,1)T;Ri(i=1,2,…)是第i次迭代得到的權威值向量;迭代的終止條件可以通過迭代次數或者最近兩次的迭代結果的比較來實現。
基于傳統的PageRank模型,本文的技術解決方案簡單歸納為:首先,利用社會網絡概念和分析工具構建微博數據的邏輯分析結構(有向圖);然后,考慮博文傳播導致的用戶行為的影響力要素,形成節點級的綜合的行為評測模型;最后,改進傳統的PageRank算法的模式演化過程,形成微博用戶影響力的動態挖掘算法。
2 PageRank模型的改進及微博用戶影響力挖掘
傳統的PageRank模型和算法的思想可以用在微博用戶影響力評估中,但是要想獲得更準確的評估結果,一個關鍵的問題需要解決:假如采用傳統的PageRank模型來完成平均權威值傳遞的話,那么實際上是在承認所有的用戶是絕對對等的,這和微博中實際用戶的情況相差甚遠。
雖然微博中的用戶關系并不復雜,但是作為一種特殊的社交媒體有其特殊性。例如,最常用社會網絡工具是通過用戶的“關注(follow)”行為來構建有向圖的[8]。然而,微博作為一個公共的開放平臺,其用戶的權威性或者說重要性差別是很大的。一個大V用戶的關注數目遠遠多于一個普通用戶;一個認證用戶其傳播信息的可信度要明顯高于非認證用戶;一個致力于推銷自己產品的維店用戶,即使是博文再多,可能對于大多數用戶而言都是當作噪音數據來看待的。因此,如何更準確地確定和實施微博中用戶的權威值的傳遞策略是必須要面對的問題。我們的策略是通過對用戶活躍度、博文質量及可信度的評估,按著重要程度形成節點權威值的不對等傳遞,以真實地反映微博用戶的影響力。
用戶的活躍度被認為是衡量用戶影響力的重要因素之一[10]。典型的微博用戶活躍度通過用戶在微博平臺發表博文的多少來評價,通常使用式(3)[11-12]來計算:
Activity(i)=ni/N
(3)
其中:Activity(i)代表用戶i的活躍度;ni是用戶i發表的博文數目;N為全部用戶發表的微博總數。
依據式(3),用戶活躍度可以很好地反映用戶發表博文的數量。然而,除了尊重博文發表越多的用戶可能影響力越大這一事實外,至少兩個因素需要在評價一個用戶的影響力時也要加以考慮:(i)用戶發文的質量;(ii)用戶的可信度。
用戶的質量表示用戶發表博文質量的高低,博文質量值越高,就越多人轉發。當高質量的博文數發表的多時,說明該用戶在這個話題圈內擁有的話語權越高,即權威值越高。有研究把高質量博文定義為轉發量超過一定量的博文,用戶的質量值即該用戶所發的高質量博文的占比。遵循這樣的原則,我們把轉發量超過300的博文定義為高質量博文,且最簡單的評估用戶質量值的方式可以用式(4)給出:
Quality(i)=mi/ni
(4)
其中:Quality(i)代表用戶i的質量值;mi是用戶i發表的高質量博文數目;ni為該用戶發表的微博總數。
用戶的可信度可以通過是否被微博平臺認證來衡量,同時認證用戶的好友粉絲數也是影響其可信度的重要因素。根據用戶好友粉絲數的多少可以衡量該用戶在發微博時能夠影響到多少人,好友粉絲數越多就能讓越多的人看到微博消息,也就表示該用戶的影響力越大。最簡單地方法可以通過式(5)完成:

(5)
其中:B(i)和C(i)分別代表用戶i的鏈入和鏈出節點數目,即用戶i的好友粉絲數。
接下來的問題就是如何將用戶活躍度、博文質量及用戶可信度整合成一個綜合評價模型,并把它用于PageRank模型的權威值傳遞過程中。依據式(3)-式(5),可以使用式(6)形成一個綜合評價參數w(i):
w(i)=Activity(i)+Quality(i)+Confidence(i)
(6)
于是,w(i)可以用來修正PageRank模型,形成加權轉移概率矩陣M=(mi,j),mi,j表示節點j傳遞給節點i的權威值,可以通過式(7)來計算:
(7)
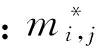
對于圖1所示的社會網絡,假如我們已經獲得各個節點的評價參數:w(A)=0.10、w(B)=0.15、w(C)=0.20、w(D)=0.15,則對應的加權轉移概率矩陣M為:

使用加權概率轉移矩陣,利用PageRank算法思想,我們可以設計一個綜合考慮用戶活躍度、用戶質量及可信度的微博社會網絡挖掘算法,稱為PR4WB算法。該算法以傳統的PageRank算法為技術構架,將影響微博用戶影響力的關鍵因素整合進來。算法1給出了PR4WB的偽代碼描述:
算法1 微博用戶影響力向量生成算法PR4WB
輸入:微博用戶社會網絡圖G;阻尼系數d;迭代終止條件ε;
輸出:用戶節點的影響力向量R。
過程描述:
2) Fori∈GDo
3) 計算Activity(i),Quality(i),Confidence(i);
4)w(i) =Activity(i)+Quality(i) +Confidence(i);
5)Enddo
6)Fori∈GDo
7)Forj∈GDo
9)M=(mi,j);
10)R0= (1, 1, …, 1)T;I=R0;
11)Repeat
12)R=(1-d) *I+d*M*R0;
13)R0=R;
14)Until‖R-R0‖≤ε;
15) 輸出R作為最終的影響力向量。
算法1中的步驟1根據傳統的PageRank算法來計算概率轉移矩陣;步驟2-步驟5計算用戶的活躍度、博文質量和可信度(見式(3)-式(5));步驟6-步驟9生成加權概率轉移矩陣;步驟10-步驟15完成所有節點的影響力計算。
3 實驗與分析
實驗數據來自于Twitter平臺。我們采用Twitter提供的API接口獲取了近5年的數據,選取了其中3 049位微博用戶,利用Gephi社會網絡生成工具形成了包含7萬多條(關注)弧的有向圖。當然,3 049個用戶只是全部Twitter用戶中的一小部分,但是這些用戶的關系網絡是相對完整的,可以用來檢驗本文算法的有效性和效率。
表1和表2分別給出了利用傳統的PageRank算法和本文的PR4WB算法找出的前十名微博用戶及其對應的情況。
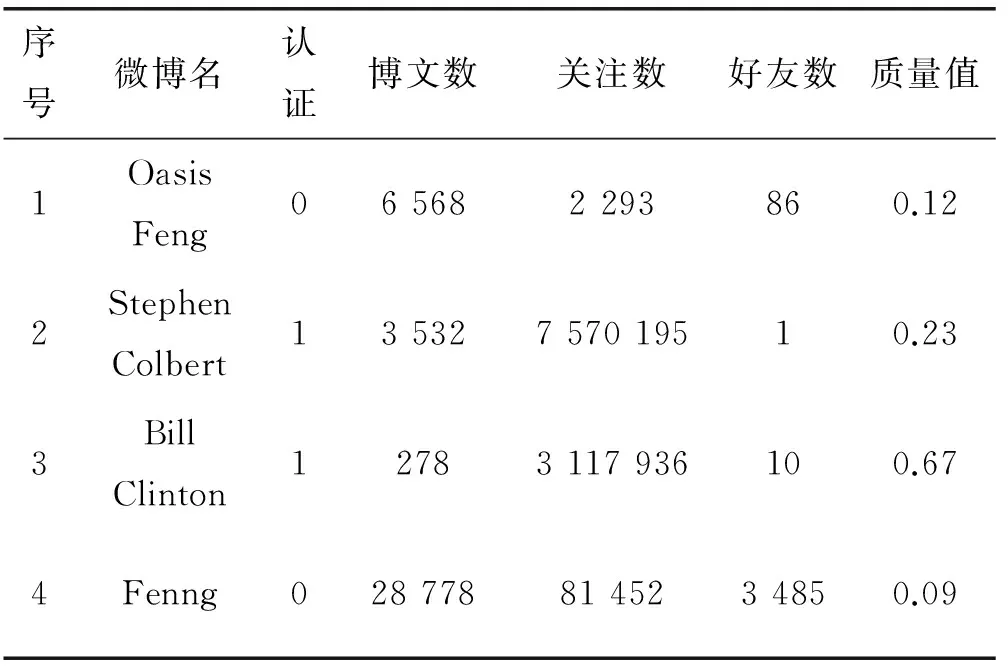
表1 傳統的PageRank算法找出的前十名用戶信息表

續表1

表2 PR4WB算法找出的前十名用戶信息表
對照表1和表2,對相同的數據,傳統的PageRank算法和本文的PR4WB算法找到的影響力最高的前10名用戶存在差異。當然,我們不能主觀地斷定哪個更好,但是表1的一些問題是可以通過分析被發現的。例如:(1) PageRank算法排名第1位用戶為非認證用戶,而且這段時間發表的博文數據也不多,所以算不上是一個很活躍的用戶。通過我們進一步跟蹤傳統PageRank算法的權威值計算過程發現,這主要是由于該用戶的關注者大多具有很高的權威值、進而使他的權威值累計起來很高。(2) 表1中排名第4位的也是一個非認證用戶,它的關注數也不算多,但是他的排名也很高。究其原因,是Fenng一位IT界的知名人物,其關注者的影響力很高、而且他很少關注其他的人。
相比較而言,我們根據PR4WB算法要求進行了用戶的活躍度、博文質量及可信度的評估,并且使用它們改進了PageRank成PR4WB算法,得到了表2的結果。計算出的影響力排名前十位用戶均為認證用戶,而且所發的博文數、關注數及好友數都相對較高。另外,我們利用微博的轉發功能來評估博文質量,我們發現好友粉絲數多的認證用戶的質量值都較高,這是因為認證用戶一般都在發布消息時具有一定的權威性,并且其眾多的好友粉絲會對其所發出的博文進行轉發評論,相較于一般用戶,認證用戶的影響力更大。實驗結果中PR4WB算法得到的前十名用戶大多數為新聞媒體的官方微博,這些從一個側面上可以說明,PR4WB算法所得到的排名與現實生活中的實際用戶的影響力更接近。
此外,通過跟蹤傳統的PageRank算法和本文的PR4WB算法的運行時間,我們測試了兩個算法隨用戶數目增加時對應的執行時間的變化情況。兩個算法是在同樣的數據集和實驗環境下進行的。實驗是在四核 CPU、4 GB內存、Windows 7操作環境下的計算機實施的。同時,為了說明隨數據容量增加執行時間的增長規律,我們從已經獲取的Twitter平臺的3 049位用戶對應的社會網絡圖中分別截取了500,1 000,1 500,2 000和2 500個用戶對應的網絡子圖,分別實施PageRank和 PR4WB算法。圖2給出了對應的實驗結果。
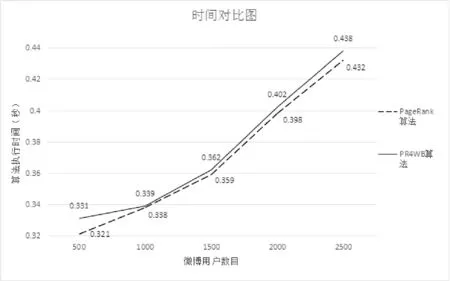
圖2 PR4WB算法與PageRank算法所耗時間對比
圖2表明:在同樣的數據容量下,PR4WB算法的執行時間略高于PageRank算法。這是因為相比傳統的PageRank算法,PR4WB算法需要額外計算用戶活躍度等動態評估指標,所以自然要高些。然而,兩個算法在相同數據容量下,差距并不大;而且,隨著數據容量(用戶數)的增加,兩者的時間攀升趨勢相當,都小于線性增長速率。因此,雖然PR4WB算法是以時間為代價來獲取比PageRank算法更好的挖掘結果的,但是其時間代價并不高,是一個性價比很高的算法。
4 結 語
通過對微博中用戶影響力分析中需要考慮的關鍵因素分析,提出了一種更適合挖掘微博數據的加權PageRank算法,即PR4WB算法。PR4WB算法對于PageRank算法存在的平分權威值這一問題進行了修正,使得排序結果更客觀、準確。通過計算微博用戶的活躍度、博文質量及可行度,獲得節點的權重,利用權重修正傳統的PageRank模型的概率轉移矩陣。這樣,用戶的影響力排序不僅考慮了社會網絡中個體之間的鏈接關系,同時將用戶活躍度等動態因素參與影響力的排序中,使得微博用戶的影響力評估更全面。實驗結果表明,相比于傳統的PageRank算法,PR4WB算法用較小的時間代價換取了更準確的評估效果。
[1] Page L,Brin S,Motwani R,et al.The PageRank citation ranking: bringing order to the web:SIDL-WP-1999-0120[R].Technical Report of Stanford University,1999.
[2] 縣小平.一種改進的PageRank算法[J].太原師范學院學報(自然科學版),2011,10(1):92-94.
[3] Weng J,Lim E P,Jiang J,et al.TwitterRank:finding topic-sensitive influential twitterers[C]//Proceedings of the Third ACM International Conference on Web Search and Data mining.New York,NY,USA:ACM Press,2010:261-270.
[4] Weng J,Yao Y,Leonardi E,et al.Event detection in Twitter:HPL-2011-98[R].Technical Report of HP Laboratories,2011.
[5] 尹紅軍.大規模社交網絡中局部興趣社區發現研究[D].合肥:中國科學技術大學,2014.
[6] Kempe D,Kleinberg J,Tardos é.Maximizing the spread of influence through a social network[C]//Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington,DC,USA,2003:137-146.
[7] 熊小兵.微博網絡傳播行為中的關鍵問題研究[D].鄭州:解放軍信息工程大學,2013.
[8] 丁兆云,賈焰,周斌.微博數據挖掘研究綜述[J].計算機研究與發展,2014,51(4):691-706.
[9] Noordhuis P,Heijkoop M,Lazovik A.Mining Twitter in the cloud:a case study[C]//Proceedings of the 2010 IEEE 3rd International Conference on Cloud Computing (CLOUD),2010:107-114.
[10] 陸研,毛健駿,屠方楠.網絡信息老化規律研究——新浪新聞與新浪微博實證研究[J].高等函授學報(哲學社會科學版),2011,24(12):52-55.
[11]JavaA,KolariP,FininT,etal.Modelingthespreadofinfluenceontheblogosphere[C]//Proceedingsofthe15thInternationalWorldWideWebConference(WWW06),Edinburgh,UK,2006:1-7.
[12]ChaM,HaddaiH,BenevenutoF,etal.MeasuringuserinfluenceinTwitter:themillionfollowerfallacy[C]//ProceedingsoftheFourthInternationalAAAIConferenceonWeblogsandSocialMedia,Washington,DC,USA,2010:10-17.
IMPROVEMENT OF PAGERANK MODEL AND MINING ALGORITHM OF MICROBLOG USER INFLUENCE
Mao Guojun Xie Songyan Hu Dianjun
(SchoolofInformation,CentralUniversityofFinanceandEconomics,Beijing100081,China)
With the development of Web technology, microblog has become one of the most popular social platforms. The calculation of user influence in microblog is the focus of related research. Through the improvement of the PageRank model, a new user influences mining algorithm PR4WB (PageRank for Microblog) is proposed to solve the problem that the traditional PageRank algorithm has too much potential error due to the transfer of page authority value. PR4WB algorithm takes into account the user relationship in microblog while using the concept of social network to link its activity, blog quality and credibility to form a dynamic evaluation model. Experiments based on Twitter data show that, PR4WB algorithm can more accurately and objectively reflect the user’s actual influence.
User influence Social network Microblog Twitter PageRank algorithm
2016-04-02。國家自然科學基金項目(61273293)。毛國君,教授,主研領域:數據挖掘。謝松燕,碩士生。胡殿軍,碩士生。
TP391.1
A
10.3969/j.issn.1000-386x.2017.05.005
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
汽車觀察(2016年3期)2016-02-28 13:16:26
創業家(2015年5期)2015-02-27 07:53:25
