位置正則的支持向量域描述在人臉識別中的應用研究
2017-06-29 12:00:34曾青松
計算機應用與軟件 2017年5期
熊 昕 曾青松
1(廣州番禺職業技術學院教育技術與信息中心 廣東 廣州 511483)2(廣州番禺職業技術學院信息工程學院 廣東 廣州 511483)
位置正則的支持向量域描述在人臉識別中的應用研究
熊 昕1曾青松2*
1(廣州番禺職業技術學院教育技術與信息中心 廣東 廣州 511483)2(廣州番禺職業技術學院信息工程學院 廣東 廣州 511483)
支持向量域描述是一種有效的一分類數據描述方法,能夠有效地對單一類別的數據進行表達,并能有效地降低負樣本的干擾。應用支持向量域描述方法,將人臉圖像集合投影到高維特征空間構建描述特征空間中人臉圖像的超球體,并定義兩個超球體之間的相似性度量,應用最近鄰分類器進行分類。在基于集合的人臉識別應用標準數據庫上測試了該方法,在Honda/UCSD、CMU Mobo和YouTube數據分別取得100%、97.55%和59.78%的識別率。實驗結果表明,該方法是一種有效的基于圖像集匹配的人臉識別方法。
支持向量域描述 人臉識別 模式識別 集合匹配
0 引 言
近年來,在人臉識別領域中,隨著數字監控系統的普及視頻采集技術的提高,人們能夠方便地采集到更多的數據樣本,研究人員轉向關注以圖像集為研究對象的識別方法[1-2]。由于光照、遮擋等因素的影響,視頻監控系統的數據源一般經過壓縮,獲取到的圖像的分辨率和清晰度都比較低。但是在監控環境中,人們可以獲取更多的圖像,這些圖像能夠從不同角度提供有助于鑒別分析的信息,最終提高識別的精度。
與傳統的方法相比,基于集合的識別方法把整個圖像集合當作一個整體,建立相應的數學模型。這一類方法需要解決如何提取人臉的特征,建立相應的數學模型,設計兩個模型之間的相似性的度量方法等一系列的問題。一般可以對圖像集合張成的子空間建模,將圖像集投影到低維線性子空間,計算子空間之間的主夾角,用典型相關作為相似性的度量[3]。或者計算圖像集合的張成的仿射子空間,使用兩個仿射包中最近鄰點之間的幾何距離來度量集合之間的相似性[4],在這個基礎上,Hu等人引入稀疏表達的通過仿射包對圖像集合建模,運用最近鄰點來度量兩個仿射包之間的相似性[5]。
一般可以把一個子空間理解成成格拉斯曼流形上的一個點,通過核函數將流形上的特征映射到歐式空間,然后在新的空間中學習一個分類器。比較流行的方法是使用核函數將歐式空間的特征投影到再生核希爾伯特空間,核Fisher鑒別分析中應用格拉斯曼核進行鑒別分析[6]。或者將每一個圖像集合當成構成格拉斯曼流形的子空間,組合使用投影核和典型相關核進行鑒別分析[7]。
流形學習是一種非線性降維方法。流形能夠有效刻畫樣本數據的本質結構,并提供一種結構緊致的表示[8]。這一類方法,使用流形來刻畫一個圖像集合,比較兩個流形的相似性。作為一種子空間的相似性的度量方法,主夾角方法可以有效地捕捉兩個子空間之間的公共的數據變化模式[9],通過主夾角度量兩個子空間或者流行上兩個局部線性模型之間的距離[3,10],通過多流形學習解決有監督的流形間距離計算問題[11]。

支持向量域描述SVDD(Support Vector Domain Description)是一種基于支持向量機學習的方法[16-17]。它用一個包含大部分正例樣本的超球表示一個集合。本文使用支持向量域描述方法建立數據集合進行的數據域描述模型,并通過對不同位置的樣本賦予不同權來進一步提高了數據域的描述能力,并將該方法應用到基于集合的人臉識別中。
1 支持向量域描述
數據域描述的主要任務是學習數據集的有效描述,使得該描述能夠有效地覆蓋數據空間的正樣本點同時排除數據空間的負樣本點。而作為識別用途的數據域描述,構建的模型還要能夠方便、有效地區分不同類別的樣本[18-19]。
1.1 支持向量域描述
支持向量域描述是一個球狀的數據域描述方法,通過一個非線性映射函數將數據集從原始數據空間投影到高維核空間,構建一個僅僅依賴于少數支持向量的非常精確的數據域描述,尋找一個能夠圍住大部分樣本的最小閉球來表示整個數據集。
給定一個包含N個樣本的數據集,X={xi∈RD|i=1,2,…,N}及一個從原始數據空間投影到高斯核空間的非線性映射φ,我們需要學習一個核空間上圍住大部分的映射樣本點的最小超球體。采用超球中心μ以及球的半徑R表示超球體,?ξi≥0,在滿足約束條件:
‖φ(xi)-μ‖2≤R2+ξi
(1)
的前提下,最小化目標函數:
(2)
其中‖·‖表示歐式距離,μ、R分別表示超球體的球心和半徑,ξi≥0是使得允許邊界存在的松弛變量,平衡參數C控制對噪聲點的懲罰,權衡了超球體的體積與數據域描述的精度。由拉格朗日法則,我們有:

(3)
(4)

核半徑函數定義為:
R(x)=‖φ(x)-μ‖=

(5)
理想的情況下,所有的SV都應該具有相同的半徑。由于數值誤差的存在,可能會有輕微的不同。一般超球體的半徑可以定義所有樣本點的核半徑的最大值:
(6)
數據集的數據域描述定義為原始的空間中,{x|R(x)=R}的這些樣本點的輪廓線。圖1給出一個標準測試集的特征空間中的超球體的示意圖,所有的邊界向量連接在一起構成超球體的球面,少量的位于球面外部的點可以理解成負樣本點。

圖1 特征空間的超球示意圖
1.2 位置正則的支持向量域描述
式(2)描述的模型嚴重依賴于參數C。這個參數決定了超球體的大小,影響到超球體表面樣本的分布。
在核空間,如果樣本點離樣本集合中心的距離越遠,它們成為離群點的可能性就越大,在原始輸入空間該樣本與其它樣本越遠。因此可以賦予一個與樣本位置相關的權重來描述孤立程度。基于上述分析,通過對不同位置的樣本賦予不同權來代替目標函數中的參數C,進一步提高了數據域的描述能力[20]。為計算公式基于位置的權重參數,首先通過式(7)計算一個核距離矩陣:D=[Dl|l=1,2,…,N]。


(7)
接著,權重wi可以定義為:
(8)
(9)
?i=1,2,…,N在滿足約束條件式(1)的前提下,最小化超球的半徑:
(10)
與式(2)描述的目標函數不同的是,式(10)中,每個權重Wi分別正則化對應的樣本點xi成為奇異點的可能性。權重Wi越小,則松弛變量ξi越大。而松弛變量ξi則直接對應于產生超球體軟邊界和邊界支持向量。
2 圖像集建模
2.1 圖像集的數據域描述
本文直接使用圖像的灰度值作為特征,每一張圖通過列拼接得到一個向量表示一個圖像的特征,多張圖像組合在一起構成一個矩陣,作為圖像集合的輸入空間。
設SV和BSV分別表示支持向量和邊界向量的集合,圖像集合可以表達為D(μ,R,R(x))={SV,BSV,μ,R(x)}。其中核半徑函數R(x)在式(5)中定義,半徑R在式(6)中定義。
2.2 相似性度量

(11)
式(11)中球心的距離通過式(12)計算:
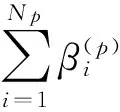


(12)
3 實驗設置與結果分析
本節我們討論在HondaUCSD視頻數據庫、CMUMoBo數據庫[22]和YouTube視頻數據庫[23]上進行基于集合的人臉識別實驗。實驗計算機配置為:Intel(R)Xeon(R)E7-4807雙1.87GHzCPU(2×6核),64GB內存,安裝WindowsServer2008R2,程序使用MATLAB2013編寫。
3.1 數據集
Honda/UCSD數據集是人臉識別領域的基準數據集,它一共包含19個人的59段視頻。這個數據庫的所有視頻是在室內光照條件受到控制的條件下錄制的,視頻相對比較清晰。每個視頻片段內只有一個人,包含該人的不同姿態和表情的變化。每段視頻長度大約300~500幀,被分割成多個視頻小片段,用于構建訓練和驗證集合。實驗使用Viola[24]算法逐幀檢測出人臉區域。如圖2所示,檢測到的人臉圖像都接近正面人像。

圖2 Honda/UCSD數據庫人臉示意圖
CMUMoBo數據庫最初是為了研究遠距離人的身份識別問題而收集的[22]。每一個人包含4種不同的走路的方式,這些視頻是室內固定位置攝像機拍攝的。本文使用它的一個子集,包含96個視頻序列,24種不同的主題,每一個序列包含大約300幀。
YouTube數據庫是收集來自于YouTube網站的一些公開視頻片段,共計47個人的1 910段視頻,每個人的視頻片段分為3個小節,每一個小節對應不同的采集時間與場景。這個數據庫包含大范圍的姿態、光照和表情變化,本文使用對象跟蹤算法,提取相應的人臉圖像[25]。由于視頻的清晰度不高,部分視頻中包含超過1個人的頭像,盡管我們采用了對象跟蹤方法獲取人臉圖像,但是實驗中發現有人像跟丟和錯誤跟蹤的問題,導致視頻中有部分的人像不完整甚至是錯誤的。

圖3 YouTube數據庫人臉跟蹤的結果
3.2 比較的方法和設置
實驗以原始論文公開的代碼為基礎,檢測到的人臉圖像經過簡單的直方圖均衡化處理之外,按照列堆疊成行向量。Honda/UCSD和YouTube數據庫使用灰度特征,CMUMoBo數據庫使用LBP特征[26]。實驗中,算法的具體參數設置如下:互子空間方法MSM[3]、流形-流形距離MMD[10]和圖像集稀疏最近鄰逼近SANP[5]算法使用PCA降維,保留95%的能量。MMD算法采用原文相同的參數設置:歐式距離與幾何距離比值設置為2.0,使用最大典型相關計算距離,鄰域大小設置為12。格拉斯曼流形鑒別分析GDA[6]算法采用投影核,格拉斯曼流形上圖嵌入鑒別分析GGDA[7]算法實現了最簡單的二分圖結構,使用最大典型相關計算核函數,鄰域參數k設置為2。
本文的方法,首先建立數據庫中每個集合的數據域描述模型Di(i=1,2,…)。測試階段,先計算查詢圖像集合的數據域描述模型Q,然后應用式(11)計算其與數據庫中的每一個模型之間的距離,應用最近鄰分類器進行分類。
3.3 實驗結果與分析
表1 報告了Honda/UCSD、CMUMoBo和YouTube數據庫上5次隨機實驗的平均識別率(RR)、方差(STD)和平均計算時間(秒)。在Honda/UCSD和CMUMoBo數據庫上,本文提出的方法取得了最好的識別結果。YouTube數據庫的視頻質量比較差,帶有一定程度的噪聲污染,根據實驗設定,對象跟蹤的結果中含有部分噪聲點,這些噪聲點被描述成超球體的外點,有效地降低其對識別結果的影響。
從表1的實驗結果分析,所有算法在YouTube這個數據庫上取得的結果都比較差,但是本文提出的方法取得的結果相對好于其它的算法。雖然本文的方法比SANP方法識別率要低,但是計算速度比SANP方法快了近100倍。
4 結 語
圖像集匹配是模式識別領域研究的熱點問題之一。雖然現在有若干較有效的圖像集匹配方法,但是由于多視角、多光照變化等復雜環境所導致的多局部模型分布下的無監督圖像集匹配問題仍然是一個具有挑戰性的問題。支持向量域描述不僅對一類數據具有很好的描述能力,而且在例外點檢測和降噪方面表現非常優秀。本文擴展了SVDD,借助位置正則的方法,對特征空間中樣本動態加權,提高SVDD對數據集合的表達能力,有效地解決了全局單一平衡參數所帶來的問題。
[1] Barr J R, Bowyer K W, Flynn P J, et al. Face recognition from video: A review[J]. International Journal of Pattern Recognition and Artificial Intelligence, World Scientific, 2012,26(05).
[2] 嚴嚴, 章毓晉. 基于視頻的人臉識別研究進展[J].計算機學報,2009,32(5):878-886.
[3] Yamaguchi O, Fukui K, Maeda K. Face Recognition Using Temporal Image Sequence[C]//3rd International Conference on Face & Gesture Recognition. Nara, Japan: IEEE Computer Society, 1998:318-323.
[4] Yang M, Zhu P, Gool L J Van, et al. Face recognition based on regularized nearest points between image sets[C]//10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, FG 2013. Shanghai, China: IEEE, 2013:1-7.
[5] Hu Y, Mian A S, Owens R. Face recognition using sparse approximated nearest points between image sets[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2012,34(10):1992-2004.
[6] Hamm J, Lee D D. Grassmann discriminant analysis: a unifying view on subspace-based learning[C]//Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008:376-383.
[7] Harandi M T, Sanderson C, Shirazi S, et al. Graph embedding discriminant analysis on Grassmannian manifolds for improved image set matching[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2011:2705-2712.
[8] 王瑞平. 流形學習方法及其在人臉識別中的應用研究[D]. 北京: 中國科學院研究生院,2010.
[9] Kim T K, Arandjelovi? O, Cipolla R. Boosted manifold principal angles for image set-based recognition[J]. Pattern Recognition,2007,40(9):2475-2484.
[10] Wang R, Shan S, Chen X, et al. Manifold-Manifold Distance with application to face recognition based on image set[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition,2008:1-8.
[11] Wang R, Shan S, Chen X, et al. Manifold-Manifold Distance and its Application to Face Recognition With Image Sets[J]. IEEE Transactions on Image Processing, 2012,21(10):4466-4479.
[12] Jayasumana S, Hartley R, Salzmann M, et al. Kernel Methods on the Riemannian Manifold of Symmetric Positive Definite Matrices[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2013:73-80.
[13] 曾青松. 黎曼流形上的保局投影在圖像集匹配中的應用[J]. 中國圖象圖形學報,2014,19(3):414-420.
[14] Wang R, Guo H, Davis L S, et al. Covariance discriminative learning: A natural and efficient approach to image set classification[C]//Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on,2012:2496-2503.
[15] 詹增榮, 曾青松. 基于協方差矩陣表示的圖像集匹配[J]. 湖南師范大學自然科學學報,2015,38(4):74-79.
[16] Tax D M J, Duin R P W. Data domain description using support vectors[C]//Esann 1999, European Symposium on Artificial Neural Networks, Bruges, Belgium, April 21-23, 1999, Proceedings,1999:251-256.
[17] Ben-Hur A, Horn D, Siegelmann H T, et al. Support Vector Clustering[J]. Journal of Machine Learning Research, 2002,2(2):125-137.
[18] 曾青松. 基于支持向量域描述的圖像集匹配[J]. 模式識別與人工智能,2014,8(8):735-740.
[19] Zeng Q S, Lai J H, Wang C D. Multi-local model image set matching based on domain description[J].Pattern Recognition,2014,47(2):694-704.
[20] Wang C D, Lai J H. Position regularized Support Vector Domain Description[J]. Pattern Recognition,2013,46(3):875-884.
[21] Wang C D, Lai J H, Huang D, et al. SVStream: A Support Vector-Based Algorithm for Clustering Data Streams[J].IEEE Transactions on Knowledge & Data Engineering,2013,25(6):1410-1424.
[22] Gross R, Shi J. The CMU Motion of Body (MoBo) Database[R].Pittsburgh, PA, 2001(CMU-RI-TR-01-18).
[23] Kim M, Kumar S, Pavlovic V, et al. Face tracking and recognition with visual constraints in real-world videos[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008). Anchorage, Alaska, USA: IEEE Computer Society, 2008.
[24] Viola P, Jones M J. Robust real-time face detection[J]. International Journal of Computer Vision, Springer, 2004,57(2):137-154.
[25] Ross D A, Lim J, Yang M-H. Adaptive Probabilistic Visual Tracking with Incremental Subspace Update[C]//Computer Vision-ECCV 2004, 8th European Conference on Computer Vision. Prague, Czech Republic: Springer, 2004:470-482.
[26] Chan C H, Tahir M A, Kittler J, et al. Multiscale local phase quantization for robust component-based face recognition using kernel fusion of multiple descriptors[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(5):1164-1177.
APPLICATION OF POSITIONAL REGULAR SUPPORT VECTOR DOMAINS IN FACE RECOGNITION
Xiong Xin1Zeng Qingsong2*
1(EducationalTechnologyandInformationCenter,GuangzhouPanyuPolytechnic,Guangzhou511483,Guangdong,China)2(SchoolofInformationandTechnology,GuangzhouPanyuPolytechnic,Guangzhou511483,Guangdong,China)
Support vector domain description is an effective method to describe a single class of data, and can effectively reduce the interference of negative samples. In this paper, the support vector domain description method is used to construct a hypersphere that describes the face image in the feature space by projecting the face image set into the high-dimensional feature space. And the similarity measure between two hyperspheres is defined and classified by nearest neighbor classifier. This method was tested on the standard database of face recognition based on collection. The recognition rate of Honda/UCSD, CMU Mobo and YouTube data were 100%, 97.55% and 59.78% respectively. Experimental results show that the proposed method is an effective method for face recognition based on image set matching.
Support vector domain description Face recognition Pattern recognition Set matching
2016-04-25。廣東省自然科學基金項目(2015A030313807)。熊昕,實驗師,主研領域:模式識別。曾青松,副教授。
TP391.4
A
10.3969/j.issn.1000-386x.2017.05.029
猜你喜歡
新高考·高一數學(2022年3期)2022-04-28 07:02:46
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:36
數學物理學報(2020年2期)2020-06-02 11:28:48
學生天地(2020年31期)2020-06-01 02:32:06
數學年刊A輯(中文版)(2019年3期)2019-10-08 07:34:38
數學物理學報(2019年1期)2019-03-21 05:26:18
高中生學習·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二數學(2015年11期)2015-12-23 18:17:44
計算機工程(2015年8期)2015-07-03 12:19:07
