一種基于Spark的改進(jìn)協(xié)同過濾算法研究
2017-06-29 12:00:34許智宏蔣新宇董永峰趙嘉偉
計(jì)算機(jī)應(yīng)用與軟件 2017年5期
關(guān)鍵詞:用戶
許智宏 蔣新宇 董永峰 趙嘉偉
1(河北工業(yè)大學(xué)計(jì)算機(jī)科學(xué)與軟件學(xué)院 天津 300401)2(河北省大數(shù)據(jù)計(jì)算重點(diǎn)實(shí)驗(yàn)室 天津 300401)
一種基于Spark的改進(jìn)協(xié)同過濾算法研究
許智宏1,2蔣新宇1董永峰1,2趙嘉偉1
1(河北工業(yè)大學(xué)計(jì)算機(jī)科學(xué)與軟件學(xué)院 天津 300401)2(河北省大數(shù)據(jù)計(jì)算重點(diǎn)實(shí)驗(yàn)室 天津 300401)
為提高協(xié)同過濾算法在大數(shù)據(jù)環(huán)境下的可擴(kuò)展性以及在高維稀疏數(shù)據(jù)下的推薦精度,基于Spark平臺(tái)實(shí)現(xiàn)了一種分層聯(lián)合聚類協(xié)同過濾算法。利用聯(lián)合聚類對(duì)數(shù)據(jù)集進(jìn)行稀疏性處理并構(gòu)建聚類模型,運(yùn)用層次分析模型并結(jié)合評(píng)分密集度分析聯(lián)合聚類模型中用戶和項(xiàng)目潛在類別權(quán)重,由此進(jìn)行項(xiàng)目相似度計(jì)算并構(gòu)建項(xiàng)目最近鄰居集合,完成在線推薦。通過在GroupLens提供的不同規(guī)模MovieLens數(shù)據(jù)集上實(shí)驗(yàn)表明,改進(jìn)后的算法能夠明顯提高推薦的準(zhǔn)確度,并且在分布式環(huán)境下具有良好的推薦效率和可擴(kuò)展性。
協(xié)同過濾 聯(lián)合聚類 層次分析模型 Spark
0 引 言
互聯(lián)網(wǎng)的普及和快速發(fā)展為用戶提供了大量的信息,滿足了用戶的信息需求,但用戶在海量信息中如何獲取對(duì)自己有用的信息成為了一個(gè)急需解決的問題,個(gè)性化推薦系統(tǒng)的出現(xiàn)使得這一問題得到改善。
常見的個(gè)性化推薦系統(tǒng),如協(xié)同過濾、內(nèi)容過濾和社會(huì)化推薦系統(tǒng)[1]等。其中,基于協(xié)同過濾的推薦系統(tǒng)最為成熟、有效并且應(yīng)用廣泛。它根據(jù)目標(biāo)用戶對(duì)推薦對(duì)象最近鄰居的評(píng)價(jià)來預(yù)測對(duì)推薦對(duì)象的評(píng)價(jià)。通常包括:基于用戶的協(xié)同過濾[2]、基于項(xiàng)目的協(xié)同過濾[3]。
基于項(xiàng)目的協(xié)同過濾推薦算法需要計(jì)算項(xiàng)目間相似性搜索被推薦項(xiàng)目的最近鄰居,從而為目標(biāo)用戶進(jìn)行評(píng)分預(yù)測和推薦。由于用戶和項(xiàng)目數(shù)量的不斷增長,協(xié)同過濾算法面臨著嚴(yán)重的數(shù)據(jù)稀疏性和數(shù)據(jù)規(guī)模可擴(kuò)展性問題。
針對(duì)數(shù)據(jù)稀疏性問題,許多研究者從不同的角度對(duì)協(xié)同過濾提出了改進(jìn)方法,如文獻(xiàn)[4]從相似度傳播的角度對(duì)數(shù)據(jù)稀疏性問題進(jìn)行了相關(guān)研究,但該算法的復(fù)雜度較高,時(shí)空開銷較大。文獻(xiàn)[5]通過融入社交網(wǎng)絡(luò)好友信任關(guān)系,有效緩解了數(shù)據(jù)的稀疏性問題,文獻(xiàn)[6]使用奇異值分解來降低評(píng)分矩陣的維數(shù)從而達(dá)到降低矩陣稀疏性的目的,但該方法計(jì)算量較大,而且降維也會(huì)導(dǎo)致信息缺失。通過聚類技術(shù)降低稀疏度的方法,如文獻(xiàn)[7]首先通過k-means算法進(jìn)行基于項(xiàng)目的聚類,然后在項(xiàng)目聚類的基礎(chǔ)上計(jì)算最近鄰用戶全局相似度。文獻(xiàn)[8]提出了基于雙向聚類的協(xié)同過濾推薦算法,利用雙向聚類平滑填充的方法去解決數(shù)據(jù)稀疏性問題。
針對(duì)傳統(tǒng)協(xié)同過濾算法在處理大規(guī)模數(shù)據(jù)所遇到的可擴(kuò)展性問題,許多研究者采用分布式計(jì)算實(shí)現(xiàn)協(xié)同過濾算法來改善算法的可擴(kuò)展性。文獻(xiàn)[9]將基于用戶的協(xié)同過濾算法部署在Hadoop分布式處理平臺(tái)上。文獻(xiàn)[10]將改進(jìn)的基于項(xiàng)目的協(xié)同過濾推薦算法,在Hadoop平臺(tái)下實(shí)現(xiàn)了并行化。文獻(xiàn)[11]提出了一種基于Hadoop平臺(tái)的k-means和slope one的混合協(xié)同過濾推薦算法。文獻(xiàn)[12]分別在Hadoop和Spark平臺(tái)上實(shí)現(xiàn)了基于項(xiàng)目的協(xié)同過濾算法,并在Spark平臺(tái)上獲得了更高的執(zhí)行效率。
本文針對(duì)傳統(tǒng)協(xié)同過濾算法的稀疏性和可擴(kuò)展性問題展開研究,在基于項(xiàng)目的協(xié)同過濾算法基礎(chǔ)上,引入聯(lián)合聚類、評(píng)分密集度、層次分析模型,提出了一種分層的聯(lián)合聚類協(xié)同過濾算法(AHCCF),并基于Spark平臺(tái)實(shí)現(xiàn)AHCCF算法并行化。通過基于用戶維度的聚類將數(shù)據(jù)劃分為不同用戶族,緩解數(shù)據(jù)稀疏性對(duì)相似度計(jì)算的影響。在每個(gè)不同用戶簇中計(jì)算項(xiàng)目的相似性,再根據(jù)聯(lián)合聚類和層次分析模型計(jì)算用戶簇的權(quán)重,進(jìn)而得到項(xiàng)目的最終相似性,提高了推薦的準(zhǔn)確性。通過Spark平臺(tái)構(gòu)建推薦算法,可以充分利用Spark基于RDD的內(nèi)存計(jì)算優(yōu)勢(shì),在并行計(jì)算階段進(jìn)行高效的數(shù)據(jù)共享,使算法能夠具有良好的可擴(kuò)展性和執(zhí)行效率。
1 一種分層的聯(lián)合聚類協(xié)同過濾算法
1.1 構(gòu)建用戶模型
協(xié)同過濾算法的用戶模型通常是一個(gè)m×n的評(píng)分矩陣Rmn,用來表示m個(gè)用戶數(shù)對(duì)n個(gè)項(xiàng)目的興趣偏好。其中,用戶的興趣偏好可通過評(píng)分值來表示,如rij可用來表示用戶i對(duì)項(xiàng)目j的評(píng)分,評(píng)分高低決定了用戶對(duì)項(xiàng)目感興趣程度。
1.2 項(xiàng)目相似性度量
項(xiàng)目的相似性計(jì)算,AHCCF算法主要采用皮爾森相關(guān)相似性[13],其中皮爾森相關(guān)相似性是目前采用比較廣泛的度量方法。皮爾森相關(guān)系數(shù)公式如下:
(1)
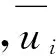
傳統(tǒng)基于項(xiàng)目的協(xié)同過濾算法僅僅采用了單一的相似度來描述項(xiàng)目之間對(duì)于所有用戶的相似程度,而沒有考慮到用戶所屬類別的不同對(duì)相似度產(chǎn)生的影響。日常經(jīng)驗(yàn)告訴我們,在一個(gè)喜好程度相近的用戶群中,由于其共同喜好,用戶群中的用戶對(duì)感興趣的項(xiàng)目評(píng)分比較密集。因此用戶群感興趣的兩個(gè)項(xiàng)目之間的相似性能夠比較真實(shí)地反映這兩個(gè)項(xiàng)目的實(shí)際的相似性,因此可以在不同的用戶群中考慮項(xiàng)目的相似性,最后通過用戶群的權(quán)重獲得項(xiàng)目最終的相似性。
為了改善數(shù)據(jù)稀疏性在相似度計(jì)算過程中所帶來的影響,AHCCF算法在皮爾森相關(guān)系數(shù)的基礎(chǔ)上提出了一種新的項(xiàng)目相似性計(jì)算方法。通過對(duì)評(píng)分矩陣R進(jìn)行用戶聚類得到k個(gè)用戶潛在類別,在每個(gè)用戶潛在類別的評(píng)分矩陣當(dāng)中運(yùn)用式(1)進(jìn)行項(xiàng)目相似性計(jì)算,進(jìn)而得到每個(gè)用戶聚類的相似度矩陣集合simUC={simUC1,simUC2,…,simUCk},使用層次分析模型計(jì)算得到用戶潛在類別權(quán)重向量WUC,根據(jù)式(2)得到最終項(xiàng)目之間的相似度。權(quán)重向量WUC需要通過聯(lián)合聚類對(duì)原始評(píng)分矩陣分塊,評(píng)估分塊矩陣的評(píng)分密集度,構(gòu)造分層模型計(jì)算得到。
(2)
1.2.1 聯(lián)合聚類
聚類是將具有相同類別屬性的內(nèi)容聚集在一起的機(jī)器學(xué)習(xí)方法,是一種處理海量、稀疏數(shù)據(jù)的有效方法。聯(lián)合聚類(Co-Clustering)是對(duì)于行列相關(guān)的二維矩陣數(shù)據(jù)模型[14],從行、列兩個(gè)角度進(jìn)行聚類。相對(duì)于傳統(tǒng)僅考慮一維相關(guān)信息的單聚類算法,該算法能夠更加有效地挖掘出數(shù)據(jù)模型當(dāng)中的潛在類別。
如圖1所示,AHCCF算法采用聯(lián)合聚類分別對(duì)用戶維和項(xiàng)目維聚類得到用戶潛在類別、項(xiàng)目潛在類別,其中用戶聚類UC={UC1,UC2,…,UCk}、項(xiàng)目聚類IC={IC1,IC2,…,ICk}。經(jīng)過聯(lián)合聚類,可從用戶和項(xiàng)目兩個(gè)維度上將評(píng)分矩陣劃分成分塊矩陣BC=[BC11,BC12,…,BC1k;…;BCk1,BCk2,BCkk]。通過聯(lián)合聚類,可獲取用戶類別在項(xiàng)目維度上的評(píng)分分布情況以及項(xiàng)目類別在用戶維度上的評(píng)分分布情況。一般來說,一個(gè)用戶群在一個(gè)項(xiàng)目類別中的評(píng)分越密集,表示該類項(xiàng)目更能體現(xiàn)用戶的興趣偏好,計(jì)算的項(xiàng)目相似度越真實(shí)。因此,可通過分析分塊矩陣以及項(xiàng)目類別矩陣的評(píng)分分布情況,來計(jì)算每個(gè)用戶群在相似度計(jì)算過程中所占權(quán)重。
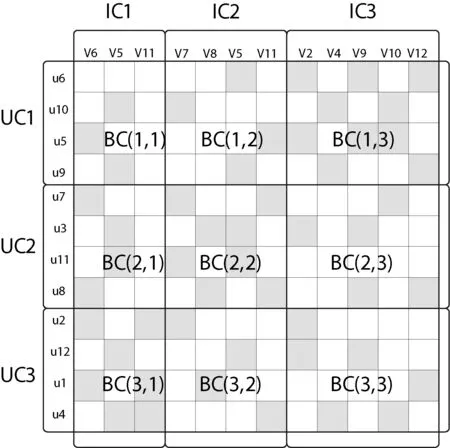
圖1 聯(lián)合聚類
AHCCF算法采用k-means算法,從用戶和項(xiàng)目兩個(gè)維度上進(jìn)行聯(lián)合聚類(CoCluster),算法具體步驟如下所示:
聯(lián)合聚類CoCluster流程:
function [UCIndex, UC, ICIndex,IC] = CoCluster(data, kUCluster, kICluster)
1. UCIndex =kmeans(data, kUCluster);
//用戶維聚類劃分
2. for i = 1: kUCluster
//循環(huán)遍歷用戶維聚類
3. UCUserIds = find(UCIndex == i);
//生成用戶類簇所包含的userId集
4. for j=1:length(UCUserIds)
5. uc(j,:)=data(UCUserIds(j),:);
//獲取用戶類簇包含的評(píng)分向量集
6. end
7. UC{i}=uc;
//保存所有用戶類簇的評(píng)分向量集UC
8. end
9. data = data’;
//轉(zhuǎn)置生成項(xiàng)目-用戶矩陣
10. ICIndex =kmeans(data,kICluster);
//項(xiàng)目維聚類劃分
11. for i = 1: kICluster
//循環(huán)遍歷項(xiàng)目維聚類
12. ICItemIds = find(ICIndex == i);
//生成項(xiàng)目類簇所包含的itemId集
13. for j=1:length(ICItemIds)
14. ic(j,:)=data(ICItemIds(j),:);
//獲取項(xiàng)目類簇包含的評(píng)分向量集
15. end
16. IC{i}=ic;
//保存所有項(xiàng)目類簇的評(píng)分向量集IC
17. end
1.2.2 評(píng)分密集度
分塊矩陣的評(píng)分密集度(Rating Intensity)能夠反映分塊矩陣在項(xiàng)目相似度計(jì)算上的真實(shí)性,一般評(píng)分密集度越高的矩陣計(jì)算的項(xiàng)目相似度越真實(shí)。因此,可通過評(píng)分密集度來評(píng)價(jià)分塊矩陣中的評(píng)分分布情況。評(píng)分密集度的計(jì)算方法:
ri=n/N
(3)
其中n為分塊矩陣中非零評(píng)分的個(gè)數(shù),N為分塊矩陣中所有評(píng)分的個(gè)數(shù)。
根據(jù)式(3)計(jì)算基于項(xiàng)目維度的每個(gè)聚類IC1,IC2,…,ICk的評(píng)分密集度,并構(gòu)造向量RIIC=(riIC1,riIC2,…,riICk)T,計(jì)算每個(gè)分塊矩陣BC(i,j)的評(píng)分密集度,進(jìn)而得到評(píng)分密集度矩陣RIBC=(αIC1,αIC2,…,αICk),其中的每個(gè)列向量為αICk=(riUC1,riUC2,…,riUCk)T,即αICk是圖1中ICk列各分塊矩陣的評(píng)分密集度構(gòu)成的向量。
AHCCF算法,根據(jù)CoCluster的計(jì)算結(jié)果:用戶聚類評(píng)分矩陣(UC)、項(xiàng)目聚類評(píng)分矩陣(IC)以及項(xiàng)目聚類所包含的項(xiàng)目索引矩陣(ICIndex),可計(jì)算出分塊矩陣(block)和評(píng)分密集度(RatingIntensity)。之后,在AHP中便可通過評(píng)分密集度,生成相應(yīng)的判斷矩陣,計(jì)算用戶類簇的相似度計(jì)算權(quán)重。評(píng)分密集度計(jì)算的具體步驟如下所示:
評(píng)分密集度計(jì)算流程:
function [blockIntensityMat, ICIVector]=RatingIndensity(UC, IC, ICIndex)
1. for i=1: kICluster
//項(xiàng)目維聚類遍歷
2. ICItemIds=find(ICIndex ==i);
//查找項(xiàng)目簇包含的ItemIds集
3. for j=1: kUCluster
//用戶維聚類遍歷
4. for k=1:length(ICItemIds)
5. block(:,k)=UC{j}(:,ICItemIds(k));
//構(gòu)建分塊矩陣
6. end
//計(jì)算分塊矩陣評(píng)分密集度矩陣
7. blockIntensityMat (j,i)=nnz(block)/numel(block);
8. end
//計(jì)算項(xiàng)目聚類評(píng)分密集度向量
9. ICIVector(i)=nnz(IC{i})/numel(IC{i});
10. end
1.2.3 層次分析模型
層次分析法是20世紀(jì)70年代由美國運(yùn)籌學(xué)家Saaty提出的一種層次權(quán)重決策分析方法。通過建立層次分析模型,進(jìn)行定量計(jì)算權(quán)重的方法。AHCCF算法通過層次分析模型,并根據(jù)1.2.2節(jié)中的項(xiàng)目類別評(píng)分密集度以及分塊矩陣評(píng)分密集度來分析用戶類別在項(xiàng)目相似度計(jì)算過程中所占權(quán)重。
AHCCF算法以項(xiàng)目聚類的各個(gè)潛在類別作為準(zhǔn)則層,各個(gè)用戶潛在類別作為方案層,通過每個(gè)項(xiàng)目潛在類別中的各個(gè)分塊矩陣的評(píng)分密集度作比較,可以得到每個(gè)用戶潛在類別在當(dāng)前項(xiàng)目潛在類別中的權(quán)重,最后綜合各項(xiàng)目潛在類別的權(quán)重得到用戶潛在類別的權(quán)重。計(jì)算用戶潛在類別權(quán)重WUC按照下面3個(gè)步驟進(jìn)行:
(1) 構(gòu)建層次結(jié)構(gòu)模型
分層過程中將用戶潛在類別權(quán)重作為目標(biāo)層,項(xiàng)目潛在類別作為準(zhǔn)則層,用戶潛在類別作為方案層,如圖2所示。

圖2 層次分析結(jié)構(gòu)圖
(2) 構(gòu)造各層次的判斷矩陣
通過聯(lián)合聚類過程將用戶和項(xiàng)目劃分成k個(gè)潛在類別,每個(gè)潛在類別的評(píng)分密集度分別為ri1,ri2,…,rik,把這些評(píng)分密集度兩兩比較,得到表示相對(duì)關(guān)系的判斷矩陣:
將權(quán)重向量w右乘矩陣A,則有:
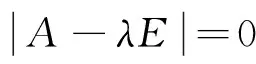
(3) 層次單排序和總排序
根據(jù)步驟(2)得到的項(xiàng)目潛在類別權(quán)重向量WIC和每個(gè)項(xiàng)目潛在類別中用戶潛在類別權(quán)重矩陣WBC,依據(jù)式(4)計(jì)算得到用戶潛在類別權(quán)重WUC。
WUC=WBC·WIC
(4)
在用戶和項(xiàng)目聚類數(shù)均為3時(shí),AHP的層次排序過程,如表1所示。
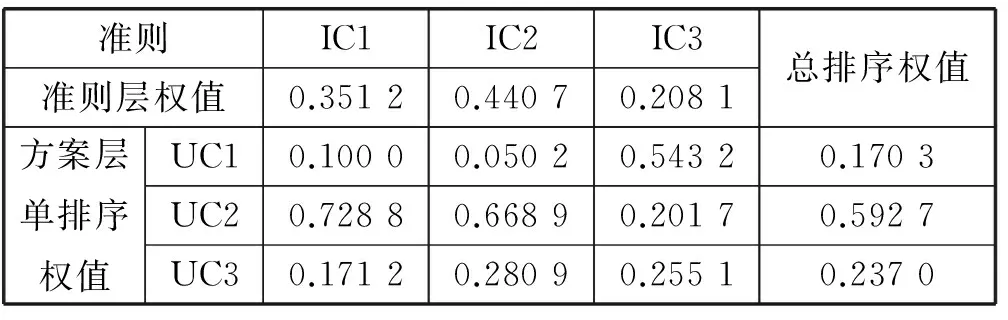
表1 AHP層次排序
AHCCF算法,采用AHP計(jì)算用戶潛在類別在項(xiàng)目相似度計(jì)算時(shí)所占權(quán)重,權(quán)重計(jì)算的具體步驟如下所示:
用戶潛在類別權(quán)重計(jì)算:
function [Wuc]=UCWeight (blockIntensityMat, ICIVector, kICluster)
1. for i=1:kICluster;
//計(jì)算每個(gè)項(xiàng)目類別中的每個(gè)分塊矩陣權(quán)重向量
2. w=AHP(blockIntensityMat(:,i));
3. Wbc(:,i)=w;
//將每個(gè)項(xiàng)目類別分塊矩陣權(quán)重向量放入權(quán)重矩陣
4. end
5. Wic=AHP(ICIVector)
//計(jì)算項(xiàng)目類別權(quán)重向量
6. Wuc= Wbc* Wic
//層次總排序,計(jì)算用戶類別權(quán)重向量
1.2.4 項(xiàng)目相似度
AHCCF算法,經(jīng)過CoCluster處理后將喜好程度相近的用戶劃分到同一個(gè)簇中。在該用戶族中計(jì)算項(xiàng)目相似性,能夠更加反應(yīng)項(xiàng)目真實(shí)相似性。AHCCF算法,在CoCluster生成的每個(gè)用戶類簇中,運(yùn)用式(1)進(jìn)行項(xiàng)目間相似度計(jì)算。然后,根據(jù)1.2.3節(jié)計(jì)算出的用戶潛在類別權(quán)重,計(jì)算出項(xiàng)目的最終相似度。算法的具體步驟如下所示:
項(xiàng)目相似度計(jì)算:
function [sim]=computeSim (UC, kUCluster)
1. for i = 1: kUCluster
//循環(huán)遍歷用戶維聚類
2. uc = UC{i};
//獲取某個(gè)用戶類簇評(píng)分矩陣
//皮爾森相似度計(jì)算
3. for i=1:size(uc,2)
4. for j=1:size(uc,2)
5. temp=find(uc(:,i)~=0 & uc (:,j)~=0);
//查找item共同評(píng)分記錄
6. Rui=data(temp,i);
//獲取item i的共同評(píng)分信息
7. Ruj=data(temp,j);
//獲取item j的共同評(píng)分信息
8. Ri=mean(data(:,i));
//獲取item i的共同評(píng)分均值
9. Rj=mean(data(:,j));
//獲取item j的共同評(píng)分均值
10. D(i,j)=(Rui-Ri)'*(Ruj-Rj)/(norm(Rui-Ri)*norm(Ruj-Rj));
11. if isnan(D(i,j))
12. D(i,j)=0;
13. end
14. D(i,j)=abs(D(i,j));
15. D(i,i)=0;
16. end
17. end
18. ucSims(i)=D
//保存每個(gè)用戶類簇的相似度計(jì)算結(jié)果
19. end
20. sim=itemSim(ucSims,Wuc)
//根據(jù)用戶聚類權(quán)重,計(jì)算項(xiàng)目最終相似度
1.3 評(píng)分預(yù)測
根據(jù)1.2節(jié)計(jì)算出的項(xiàng)目間相似度,找出與目標(biāo)項(xiàng)目最相似的最近鄰居集合,即為其生成一個(gè)相似度遞減排列的最近鄰居列表Ni。該過程分兩步完成:首先,采用1.2.4節(jié)中的方式計(jì)算項(xiàng)目之間的相似度;其次,將最相似的前k個(gè)項(xiàng)目作為最近鄰居集合。
經(jīng)過項(xiàng)目相似度計(jì)算,并生成最近鄰居集Ni后,可對(duì)目標(biāo)用戶u的未評(píng)分項(xiàng)目進(jìn)行評(píng)分預(yù)測,計(jì)算方法如下:
(5)

1.4 算法流程
整個(gè)AHCCF算法的流程如圖3所示。

圖3 AHCCF算法流程圖
輸入:目標(biāo)用戶u,用戶-項(xiàng)目評(píng)分矩陣Rm×n,聚類數(shù)k
輸出:目標(biāo)用戶對(duì)每個(gè)項(xiàng)目的預(yù)測評(píng)分Pu,j,Top-N推薦
Step1 對(duì)用戶-項(xiàng)目評(píng)分矩陣Rm×n進(jìn)行用戶聚類劃分得到k個(gè)用戶聚類UC1,UC2,…,UCk,利用式(1)計(jì)算每個(gè)聚類中項(xiàng)目與項(xiàng)目之間的相似度得到項(xiàng)目相似度矩陣集合simUC={simUC1,simUC2,…,simUCk}。
Step2 對(duì)用戶-項(xiàng)目評(píng)分矩陣Rm×n進(jìn)行項(xiàng)目聚類劃分得到k個(gè)項(xiàng)目聚類IC1,IC2,…,ICk,根據(jù)式(3)計(jì)算每個(gè)聚類的評(píng)分密集度得到RIIC=(riIC1,riIC2,…,riICk)T。
Step3 根據(jù)步驟1和步驟2將評(píng)分矩陣Rm×n分塊得到分塊矩陣BC=[BC11,BC12,…,BC1k;…;BCk1,BCk2,BCkk],計(jì)算每個(gè)分塊矩陣BCij的評(píng)分密集度得到評(píng)分密集度矩陣RIBC=(αIC1,αIC2,…,αICk),αICk=(riUC1,riUC2,…,riUCk)T。
Step4 利用層次分析模型(AHP)對(duì)Step2、Step3得到的RIIC和RIBC的列向量αICk構(gòu)造判斷矩陣并計(jì)算特征向量,得到項(xiàng)目潛在類別權(quán)重向量WIC=(wIC1,wIC2,…,wICk)T和每個(gè)項(xiàng)目潛在類別中用戶潛在類別的權(quán)重向量所構(gòu)成的矩陣WBC=(βIC1,βIC2,…,βICk)。
Step5 利用式(4)計(jì)算得到用戶潛在類別的權(quán)重,再根據(jù)Step1計(jì)算得到的每個(gè)用戶潛在類別中項(xiàng)目之間的相似度,利用式(2)計(jì)算得到項(xiàng)目間的最終相似度矩陣Sim。
Step6 在Sim中求得目標(biāo)項(xiàng)目i的最近鄰集合Ni={n1,n2,…,nk}。
Step7 根據(jù)用戶u對(duì)i的最近鄰集合Ni的評(píng)分值,利用式(5)預(yù)測用戶u對(duì)目標(biāo)項(xiàng)目i的評(píng)分,產(chǎn)生Top-N推薦列表。
2 基于Spark平臺(tái)AHCCF算法并行化
AHCCF算法,在Spark分布式計(jì)算平臺(tái)下實(shí)現(xiàn)算法的并行化。通過基于RDD的內(nèi)存計(jì)算以及數(shù)據(jù)共享等技術(shù)優(yōu)勢(shì),能夠有效提高AHCCF算法的可擴(kuò)展性和執(zhí)行效率。
并行化AHCCF算法,可分為如圖4所示的三個(gè)階段。階段一,利用基于Spark平臺(tái)的k-means聚類算法[12]分別從用戶維度和項(xiàng)目維度對(duì)數(shù)據(jù)集進(jìn)行聚類劃分,并生成相應(yīng)的聚類模型。階段二,對(duì)用戶-項(xiàng)目評(píng)分記錄進(jìn)行聚類劃分,并進(jìn)行用戶聚類相似度計(jì)算以及利用AHP計(jì)算用戶潛在類別權(quán)重。其中AHP的特征值求解,在Spark平臺(tái)下基于冪法并行求解實(shí)現(xiàn)。階段三,根據(jù)用戶潛在類別項(xiàng)目相似度以及用戶潛在類別權(quán)重,計(jì)算項(xiàng)目最終相似度。然后,生成項(xiàng)目最近鄰居集合,進(jìn)行評(píng)分預(yù)測及推薦。

圖4 基于Spark的AHCCF算法流程
AHCCF算法并行化,采用如上圖所示的三個(gè)階段來完成。在階段一,需要將訓(xùn)練集中的每個(gè)用戶或項(xiàng)目的評(píng)分記錄(userId,ItemID,rate),轉(zhuǎn)化為相應(yīng)的評(píng)分向量(userID,Vector)/ (itemID,Vector)。進(jìn)而進(jìn)行用戶和項(xiàng)目維度的聚類。由于推薦系統(tǒng)中的評(píng)分矩陣是稀疏矩陣,平均每個(gè)用戶所包含的評(píng)分記錄很少。若在計(jì)算過程中,直接存儲(chǔ)或傳輸這樣的矩陣將會(huì)占用過多的內(nèi)存和網(wǎng)絡(luò)資源。因此,在加載用戶-項(xiàng)目評(píng)分矩陣時(shí),為減少內(nèi)存消耗以及網(wǎng)絡(luò)通信量,采用稀疏向量存儲(chǔ)用戶-項(xiàng)目評(píng)分矩陣中的每行記錄。Spark中SparseVector結(jié)構(gòu)如圖5所示。
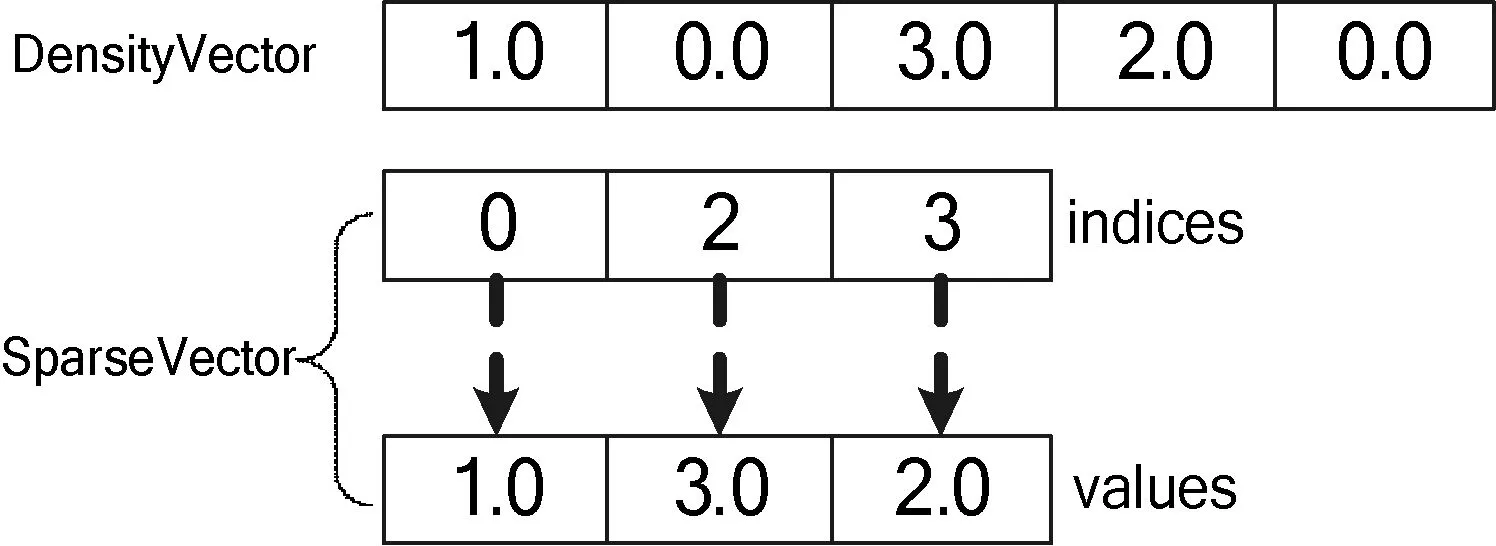
圖5 稠密向量和稀疏向量
SparkVector對(duì)應(yīng)的實(shí)例化簽名為newSparseVector(valsize:Int,valindices:Array[Int],valvalues:Array[Double])。其中,size表示向量長度,indices表示非零元素索引,values表示非零元素值。因此,采用稀疏向量存儲(chǔ)n×n的稀疏矩陣時(shí),空間復(fù)雜度由O(n2)降為O(nk),遍歷矩陣的時(shí)間復(fù)雜度由O(n2)降為O(nk)。其中,k為每行的非零元素個(gè)數(shù)。
階段二中,項(xiàng)目聚類劃分結(jié)果(UClusterRDD)和用戶聚類劃分結(jié)果(IClusterRDD),需要被重用。因此通過Spark的cache算子將其緩存。當(dāng)下次使用該RDD時(shí),不會(huì)進(jìn)行重算,直接從緩存中獲取該RDD,提高算法執(zhí)行效率。
在進(jìn)行分塊矩陣評(píng)分密集度計(jì)算時(shí),需要根據(jù)用戶類簇評(píng)分矩陣信息UClusterRDD(UCId,Vector)以及每個(gè)項(xiàng)目類簇所包含的項(xiàng)目索引信息ICIndexRDD(ICId,ICItemIndex),進(jìn)行分塊矩陣劃分以及評(píng)分密集度計(jì)算。在Spark平臺(tái)下,需要將UClusterRDD和ICIndexRDD進(jìn)行笛卡兒積(Cartesian),獲取每個(gè)用戶類簇中的項(xiàng)目類簇信息,然后進(jìn)行分塊矩陣劃分以及評(píng)分密集度計(jì)算。少量數(shù)據(jù)時(shí),Cartesian性能良好。當(dāng)數(shù)據(jù)量相對(duì)較大時(shí),Cartesian操作,一方面會(huì)占用大量網(wǎng)絡(luò)資源;另一方面,在Cartesian后會(huì)增加RDD分片數(shù)量,可能會(huì)增加額外的調(diào)度開銷。因此Cartesian操作之后一般需要調(diào)整分區(qū)(repartition),然后再通過map、reduceByKey等算子統(tǒng)計(jì)評(píng)分密集度。然而repartition同樣會(huì)造成額外的shuffle開銷。 因此,需要對(duì)Cartesian進(jìn)一步優(yōu)化。
經(jīng)分析發(fā)現(xiàn),參與笛卡兒積的ICIndexRDD其維度要遠(yuǎn)小于UClusterRDD,ICIndexRDD中僅包含每個(gè)項(xiàng)目類簇的編號(hào)(ICId)以及該項(xiàng)目類簇對(duì)應(yīng)的項(xiàng)目索引(ICItemIndex),占用空間較少可視為小表。因此可將ICIndexRDD內(nèi)容轉(zhuǎn)換為一個(gè)HashMap結(jié)構(gòu):ICMap(ICId,ICItemIndex)。通過Spark廣播機(jī)制,將ICMap廣播發(fā)送到每個(gè)節(jié)點(diǎn)上來共享該信息。進(jìn)而RDD中的每個(gè)分片均可訪問到ICMap,在map-side本地即可完成Cartesian操作,具體流程如圖6所示。
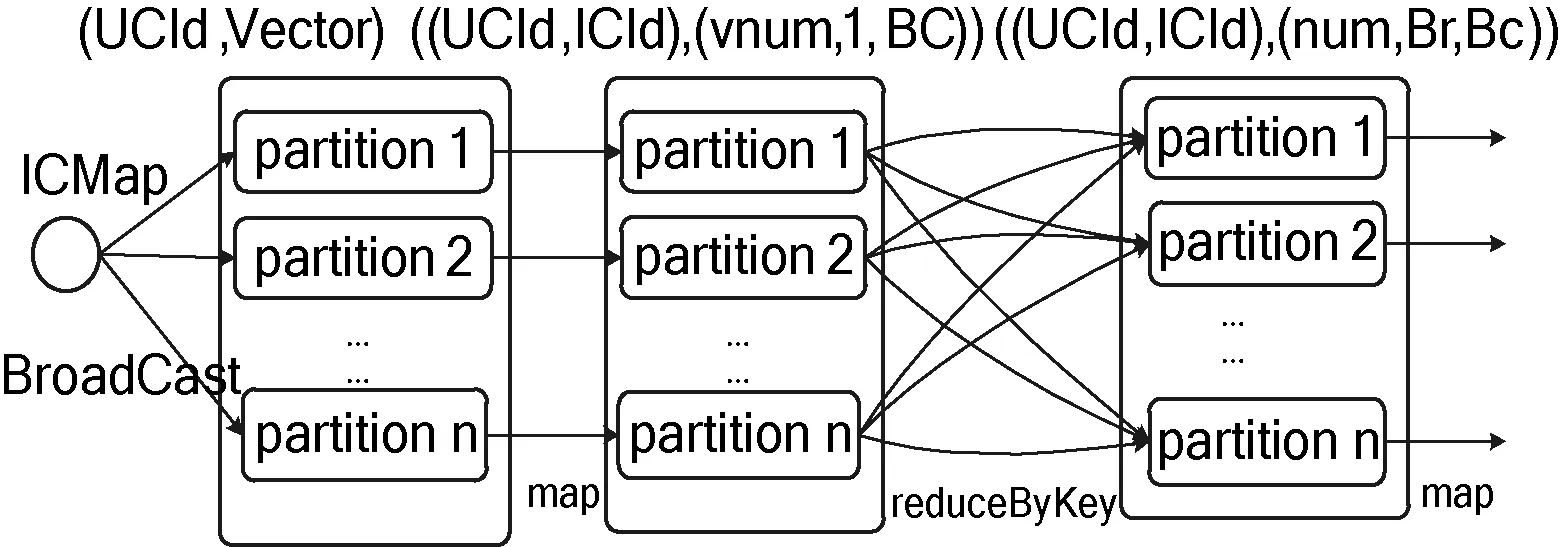
圖6 評(píng)分密集度計(jì)算
如圖6所示,經(jīng)broadcast機(jī)制優(yōu)化后,與ICIndexRDD的關(guān)聯(lián)操作在本地即可完成,降低了網(wǎng)絡(luò)IO,而且不影響原始分區(qū)數(shù)量,一般不需要repartition,使得運(yùn)行效率大幅度提高。其中,每個(gè)節(jié)點(diǎn)的平均網(wǎng)絡(luò)IO由O(nc′)變?yōu)镺(c′),n為節(jié)點(diǎn)中的分片數(shù)量,c′為小表容量,c′≤nc′。
在階段三中,不管是近鄰集合選取還是推薦列表計(jì)算,均需要生成一個(gè)遞減排序的列表項(xiàng)。然后從中選取前k個(gè)列表項(xiàng),即TopK。在少量數(shù)據(jù)情況下,可通過groupBy算子進(jìn)行分組后,再通過flatMap算子選取每個(gè)分組的前k個(gè)列表項(xiàng)。在數(shù)據(jù)量較大的情況下,由于groupBy沒有本地combine特性直接進(jìn)行分組,shuffle過程中的網(wǎng)絡(luò)通信量較高,影響算法性能。
因此當(dāng)數(shù)據(jù)量較大時(shí),可通過mapPartition算子實(shí)現(xiàn)以數(shù)據(jù)分片為粒度,進(jìn)行TopK計(jì)算。可以在每個(gè)分片中維護(hù)一個(gè)大小為k的大根堆,然后對(duì)大根堆進(jìn)行不斷調(diào)整。經(jīng)過mapPartition處理后,便可求出每個(gè)分區(qū)的TopK。最后,通過reduceBykey算子,將每個(gè)Key所對(duì)應(yīng)的多個(gè)分區(qū)的TopK進(jìn)行合并,即可生成每個(gè)Key的最終列表項(xiàng),具體流程如圖7所示。

圖7 計(jì)算每個(gè)Key對(duì)應(yīng)的TopK Value
經(jīng)過mapPartition計(jì)算,可過濾大量信息。因此可降低shuffle過程中網(wǎng)絡(luò)IO,由O(nc)降到O(nk)。其中,n表示分片數(shù)量,c表示每個(gè)分片中原始數(shù)據(jù)量,k表示每個(gè)分片經(jīng)過TopK處理后的數(shù)據(jù)量,k?c。
3 實(shí)驗(yàn)分析
3.1 數(shù)據(jù)集與實(shí)驗(yàn)環(huán)境
為了驗(yàn)證AHCCF算法的基本表現(xiàn)和分布式環(huán)境下的并行效率,本文選取明尼蘇達(dá)大學(xué)的GroupLens項(xiàng)目組提供的一組中等規(guī)模和兩組較大規(guī)模的數(shù)據(jù)集,具體描述如表2所示。
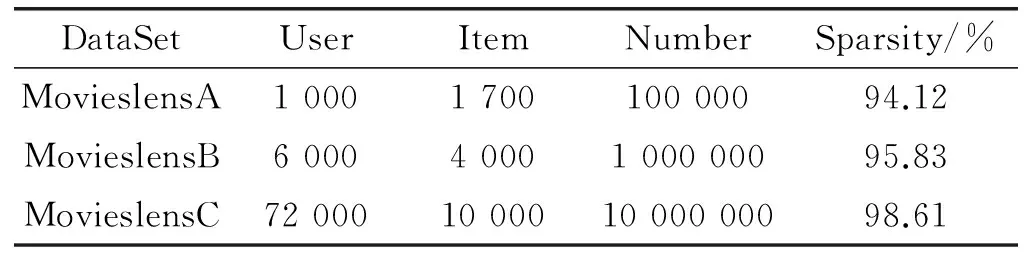
表2 數(shù)據(jù)集信息
AHCCF算法,在一個(gè)配備有5個(gè)節(jié)點(diǎn)的Spark集群進(jìn)行實(shí)驗(yàn)。1個(gè)主節(jié)點(diǎn),4個(gè)從節(jié)點(diǎn)。在集群的每個(gè)節(jié)點(diǎn)中,操作系統(tǒng)為Ubuntu14.04,Spark版本為1.3.0,Hadoop版本為2.6.0。
3.2 算法精準(zhǔn)度實(shí)驗(yàn)
AHCCF算法采用平均絕對(duì)偏差MAE,作為算法精準(zhǔn)的評(píng)價(jià)指標(biāo)。其計(jì)算公式定義如下:
(6)
其中,N表示項(xiàng)目數(shù)量,pi表示項(xiàng)目的實(shí)際分?jǐn)?shù),qi表示項(xiàng)目的預(yù)測分?jǐn)?shù)。MAE越小,推薦質(zhì)量越高。
AHCCF算法選取MovieLensA數(shù)據(jù)集,來對(duì)算法的精準(zhǔn)度進(jìn)行驗(yàn)證。設(shè)計(jì)兩組實(shí)驗(yàn):AHCCF算法在不同聯(lián)合聚類數(shù)k下的準(zhǔn)確度、在數(shù)據(jù)不同稀疏度下AHCCF算法與IBCF算法[3]、GBCF算法[7]、BSCF算法[8]的對(duì)比。
實(shí)驗(yàn)1 測試不同聯(lián)合聚類數(shù)k對(duì)推薦結(jié)果的影響,k分別取5、10、20、30、40、50,最近鄰居數(shù)取5、10、20、30、40、50、60、70、80、90、100,結(jié)果如圖8所示。
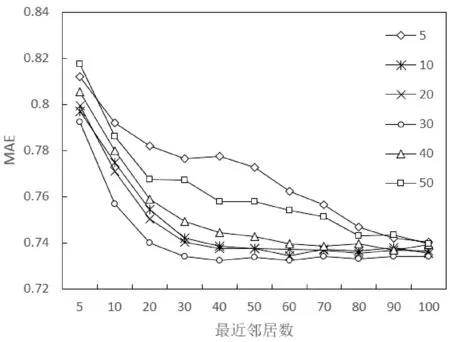
圖8 不同聯(lián)合聚類參數(shù)K下算法精度
實(shí)驗(yàn)結(jié)果表明:算法精度受參數(shù)k所影響,聯(lián)合聚類數(shù)k過大、過小都會(huì)使推薦精度不理想。一般聚類數(shù)越接近項(xiàng)目真實(shí)類別數(shù),結(jié)果越精確,本實(shí)驗(yàn)中當(dāng)k=30時(shí)算法性能最好,在較少項(xiàng)目最近鄰的情況下,算法很快收斂到誤差最小的推薦結(jié)果。
實(shí)驗(yàn)2 測試AHCCF算法在不同稀疏度下的準(zhǔn)確度,并通過與IBCF算法、BSCF算法、GBCF算法對(duì)比來驗(yàn)證算法的有效性。實(shí)驗(yàn)過程中,通過調(diào)整訓(xùn)練集和測試集所占評(píng)分比重,觀測數(shù)據(jù)稀疏度對(duì)算法精度的影響,實(shí)驗(yàn)結(jié)果如表3所示。
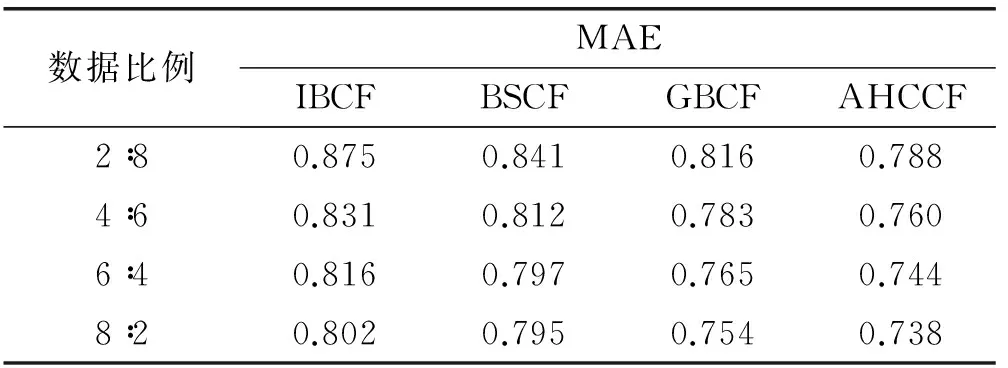
表3 算法運(yùn)行結(jié)果
實(shí)驗(yàn)結(jié)果表明:隨著訓(xùn)練集在整個(gè)數(shù)據(jù)集中所占比重的提高,數(shù)據(jù)的稀疏度逐漸減小,幾個(gè)算法的MAE值都在減小,即幾個(gè)算法的準(zhǔn)確度不斷提升。其中,BSCF算法、GBCF算法的準(zhǔn)確度均高于傳統(tǒng)IBCF算法,表明兩者在一定程度上緩解了數(shù)據(jù)稀疏性問題,提高了算法的準(zhǔn)確度。本文提出的AHCCF算法在每種稀疏度情況下,其MAE值均低于BSCF和GBCF算法,表明AHCCF算法能夠更加有效地處理數(shù)據(jù)的稀疏性問題,提供更高的推薦效率。
3.3 算法并行實(shí)驗(yàn)
AHCCF算法通過采用加速比,來驗(yàn)證通過對(duì)Spark集群的擴(kuò)展能有效提高不同數(shù)據(jù)規(guī)模下AHCCF算法的執(zhí)行效率。其計(jì)算定義公式如下:
(7)
其中,T1表示在單節(jié)點(diǎn)情況下算法運(yùn)行時(shí)間,Tn表示n個(gè)節(jié)點(diǎn)算法的運(yùn)行時(shí)間。理想情況下,依次增加節(jié)點(diǎn)時(shí)S將與y=x重合。
AHCCF算法選取表1中不同規(guī)模的MovieLens數(shù)據(jù)集來對(duì)算法的并行效率進(jìn)行驗(yàn)證。設(shè)計(jì)兩組實(shí)驗(yàn):相同數(shù)據(jù)集下AHCCF算法在Hadoop平臺(tái)與Spark平臺(tái)執(zhí)行時(shí)間對(duì)比、不同規(guī)模數(shù)據(jù)集下AHCCF算法的加速比對(duì)比。
實(shí)驗(yàn)3 測試在相同數(shù)據(jù)集下AHCCF算法在Hadoop平臺(tái)與Spark平臺(tái)上的執(zhí)行效率。本實(shí)驗(yàn)選取MovieLensB數(shù)據(jù)集,在Hadoop和Spark兩種計(jì)算平臺(tái)上實(shí)驗(yàn),結(jié)果如圖9所示。
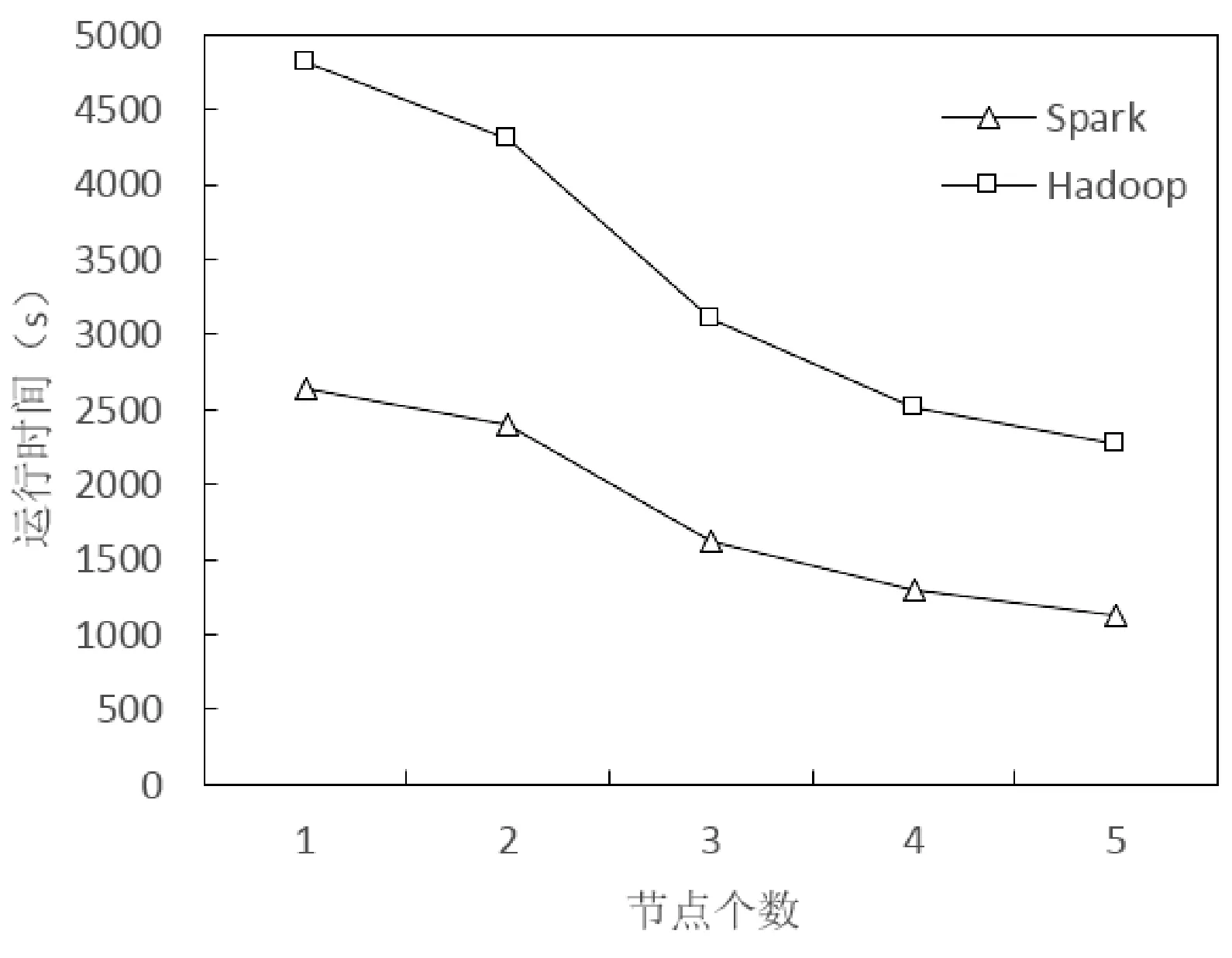
圖14 Hadoop與Spark平臺(tái)運(yùn)行效率對(duì)比
從圖9實(shí)驗(yàn)結(jié)果可以看出,隨著節(jié)點(diǎn)數(shù)量的增加,AHCCF算法在兩種計(jì)算平臺(tái)上的執(zhí)行時(shí)間逐漸減少。其中,在Spark計(jì)算平臺(tái)上算法獲得更好的執(zhí)行效率,表明了AHCCF算法在Spark平臺(tái)上更具有優(yōu)勢(shì),基于Spark的并行方案是有效的。
實(shí)驗(yàn)4 測試不同規(guī)模數(shù)據(jù)集下AHCCF算法加速比隨集群大小的變化情況,集群大小取1~5。偽分布模式下,集群只有一個(gè)節(jié)點(diǎn),master和slave為同一節(jié)點(diǎn),集群大小大于等于2時(shí),為完全分布模式,結(jié)果如圖10所示。
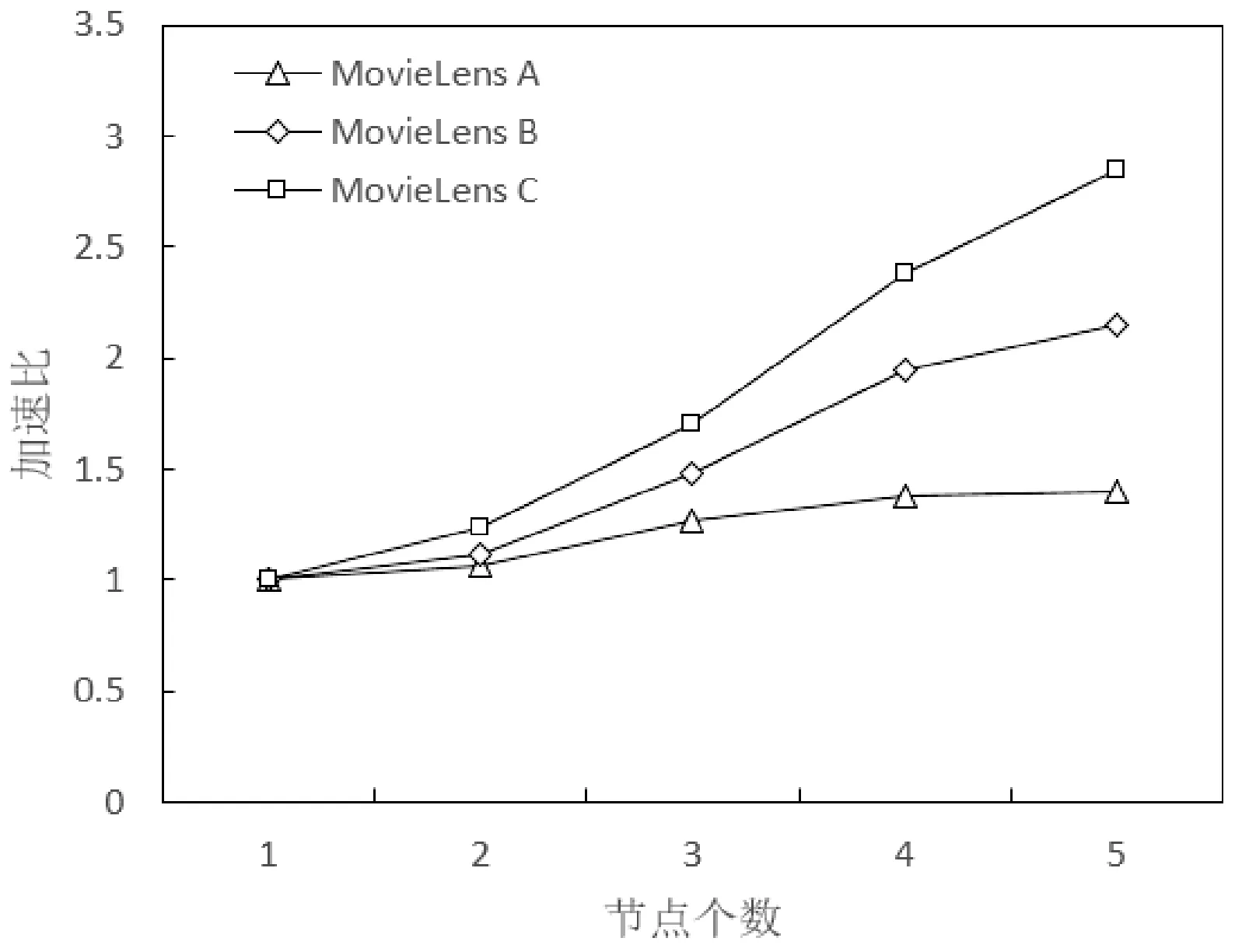
圖10 不同規(guī)模數(shù)據(jù)集的加速比對(duì)比
實(shí)驗(yàn)結(jié)果表明,隨著集群節(jié)點(diǎn)數(shù)量的增加,三個(gè)數(shù)據(jù)集的加速比曲線在不斷增大。相同數(shù)據(jù)集在節(jié)點(diǎn)數(shù)量較少時(shí),算法效率提升不是很明顯。這是因?yàn)樵谏倭抗?jié)點(diǎn)時(shí),節(jié)點(diǎn)要分擔(dān)一定計(jì)算任務(wù)的同時(shí),也要分擔(dān)一定的資源調(diào)度等任務(wù),影響節(jié)點(diǎn)的計(jì)算性能。在節(jié)點(diǎn)個(gè)數(shù)大于3時(shí),算法效率提升的更為明顯。與此同時(shí),可以看出在相同節(jié)點(diǎn)情況下,算法效率在規(guī)模較大的數(shù)據(jù)集上提升更為明顯,加速比曲線逐漸向線性靠攏,這也說明了并行化的AHCCF算法在處理大數(shù)據(jù)集時(shí)更有優(yōu)勢(shì)。
4 結(jié) 語
AHCCF算法針對(duì)傳統(tǒng)協(xié)同過濾算法存在的稀疏性以及可擴(kuò)展性問題展開研究,在基于項(xiàng)目的協(xié)同過濾算法基礎(chǔ)上,提出了一種分層的聯(lián)合聚類協(xié)同過濾算法(AHCCF),并在Spark平臺(tái)下實(shí)現(xiàn)了AHCCF算法的并行化。實(shí)驗(yàn)表明,AHCCF算法改善了傳統(tǒng)協(xié)同過濾算法的性能,提高了算的推薦精度,并在Spark分布式平臺(tái)具有良好的執(zhí)行效率和可擴(kuò)展性。下一步研究需要對(duì)算法進(jìn)行嚴(yán)格的理論推導(dǎo),同時(shí)研究不同維聚類個(gè)數(shù)的選取以及在更大規(guī)模數(shù)據(jù)上算法的并行效率。
[1] 郭磊,馬軍,陳竹敏,等.一種結(jié)合推薦對(duì)象間關(guān)聯(lián)關(guān)系的社會(huì)化推薦算法[J].計(jì)算機(jī)學(xué)報(bào),2014,37(1):219-228.
[2]WangJ,VriesAPD,ReindersMJT.Unifyinguser-basedanditem-basedcollaborativefilteringapproachesbysimilarityfusion[C]//Proceedingsofthe29thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM,2006:501-508.
[3] Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th Internationnal World Wide Web Conference.New York,NY,USA:ACM Press,2001:285-295.
[4] 趙琴琴,魯凱,王斌.SPCF:一種基于內(nèi)存的傳播式協(xié)同過濾推薦算法[J].計(jì)算機(jī)學(xué)報(bào),2013,36(3):671-676.
[5] 何潔月,馬貝.利用社交關(guān)系的實(shí)值條件受限玻爾茲曼機(jī)協(xié)同過濾推薦算法[J].計(jì)算機(jī)學(xué)報(bào),2016,39(1):183-195.
[6] Kumar R,Verma B K,Rastogi S S.Social popularity based SVD++ recommender system[J].International Journal of Computer Applications,2014,87(14):33-37.
[7] Wei S,Ye N,Zhang S,et al.Collaborative filtering recommendation algorithm based on item clustering and global similarity[C]//Proceedings of the 5th International Conference on Business Intelligence and Financial Engineering.IEEE,2012:69-72.
[8] Wang J,Song H,Zhou X.A collaborative filtering recommendation algorithm based on biclustering[C]//Cyber Technology in Automation,Control and Intelligent Systems (CYBER),2015 IEEE Internationa Conference on.IEEE,2015:803-807.
[9] Zhao Z D,Shang M S.User-based collaborative filtering recommendation algorithms on Hadoop[C]//Proceedings of the 2010 Third International Conference on Knowledge Discovery and Data Mining,2010:478-481.
[10] Fan L,Li H,Li C.The improvement and implementation of distributed item-based collaborative filtering algorithm on Hadoop[C]//2015 34th Chinese Control Conference (CCC).IEEE,2015:9078-9083.
[11] Lin K,Wang J,Wang M,et al.A hybrid recommendation algorithm based on Hadoop[C]//2014 9thInternational Conference on Computer Sicence and Education,2014:540-543.
[12] Kupisz B,Unold O.Collaborative filtering recommendation algorithm based on Hadoop and Spark[C]//Industrial Technology (ICIT),2015 IEEE International Conference on.IEEE,2015:1510-1514.
[13] 朱銳,王懷民,馮大為.基于偏好推薦的可信服務(wù)選擇[J].軟件學(xué)報(bào),2011,22(5):852-864.
[14] 吳湖,王永吉,王哲,等.兩階段聯(lián)合聚類協(xié)同過濾算法[J].軟件學(xué)報(bào),2010,21(5):1042-1054.
[15] Ketu S,Agarwal S.Performance enhancement of distributed K-Means clustering for big data analytics through in-memory computation[C]//Contemporary Computing (IC3),2015 Eighth International Conference on.IEEE,2015:318-324.
AN IMPROVED COLLABORATIVE FILTERING ALGORITHM BASED ON SPARK
Xu Zhihong1,2Jiang Xinyu1Dong Yongfeng1,2Zhao Jiawei1
1(SchoolofComputerScienceandEngineering,HebeiUniversityofTechnology,Tianjin300401,China)2(HebeiProvinceKeyLaboratoryofBigDataCalculation,Tianjin300401,China)
In order to improve the scalability of collaborative filtering algorithm in big data environment and the recommendation accuracy in high dimensional sparse data, a hierarchical co-clustering collaborative filtering algorithm based on spark is implemented. The data sets are sparsely processed by using co-clustering and the clustering model is constructed. The potential categories weight of users and projects in the co-clustering model are analyzed by using the analytic hierarchy model combined with the score-density analysis. The project similarity is calculated and the project nearest neighbor set is constructed to complete the online recommendation. The experiments different scale MovieLens datasets provided by GroupLens show that the improved algorithm can significantly improve the accuracy of recommendation, and it has good recommendation efficiency and expansibility in distributed environment.
Collaborative filtering Co-clustering Analytic hierarchy model Spark
2016-04-07。天津市科技計(jì)劃項(xiàng)目(14ZCDGSF00124);河北省青年科學(xué)基金項(xiàng)目(F2015202311)。許智宏,副教授,主研領(lǐng)域:分布式技術(shù),智能信息處理。蔣新宇,碩士。董永峰,副教授。趙嘉偉,碩士。
TP3
A
10.3969/j.issn.1000-386x.2017.05.043
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業(yè)黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛(wèi)星與網(wǎng)絡(luò)(2016年12期)2016-02-05 09:23:23
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
