一種基于樸素貝葉斯的內容選擇方法
2017-07-05 12:59:28龔雋鵬曹娟
中國傳媒大學學報(自然科學版) 2017年4期
龔雋鵬,曹娟
(1.中國傳媒大學理工學部,北京 100024;2.中國傳媒大學新媒體研究院,北京 100024)
一種基于樸素貝葉斯的內容選擇方法
龔雋鵬1,曹娟2
(1.中國傳媒大學理工學部,北京 100024;2.中國傳媒大學新媒體研究院,北京 100024)
主要研究通過語料庫自動學習特定領域的內容選擇方法。我們基于語料庫提出了選擇的內容特征,通過樸素貝葉斯方法訓練出一個內容選擇模型。實驗標明,該方法在特定領域的內容選擇任務中可以取得較好的效果。
內容選擇模型;樸素貝葉斯;內容特征
1 引言
內容選擇是自然語言生成中的一個重要任務。在自然語言生成系統中,我們通常將特定某一次內容生成的上下文稱為場景Scenarios。不同的場景,生成的文本也相應不同。在某場景下,提供的信息通常和領域、用戶等不同的內容相關,我們將選擇恰當的信息提供給用戶的過程叫做內容選擇。
表1是一個內容選擇的實例,對于出現的概念實體包括天空遮蔽情況、降雨概率、降雪概率和風向,每個概念對應了1到多個實例;表格第一列標明概念是否選中;表格第二列標明所屬概念;表格第三列標明實例的屬性及其取值。其輸入可看作是一個概念的名-值對的集合Set〈topic,propertySet〉,輸出是一個被選中的概念名-值對的子集Setselected〈topic,propertySet〉,從集合Set〈topic,propertySet〉到集合Setselected〈topic,propertySet〉的過程就是一個內容選擇過程。其中子集Setselected〈topic,propertySet〉就是包含了最終向用戶需要交付的信息,決定了最終生成的文本。
因此,我們可以將內容選擇的過程看作是一個分類的問題或者是一個序列標注的過程。
如果將內容選擇的過程單純考慮成一個分類的過程,我們的任務就是對輸入的名-值對集合Set〈topic,propertySet〉中的每一條記錄進行簡單的{selected,unselected}二分類的標注。內容選擇的問題也由此轉換為分類問題,對于每個概念實體實例的二分類標注。但事實上,對于某些受限領域的內容選擇,也可以考慮成對一般文檔的多標簽標注[1],在本節中,我們主要考慮二分類的標注問題。
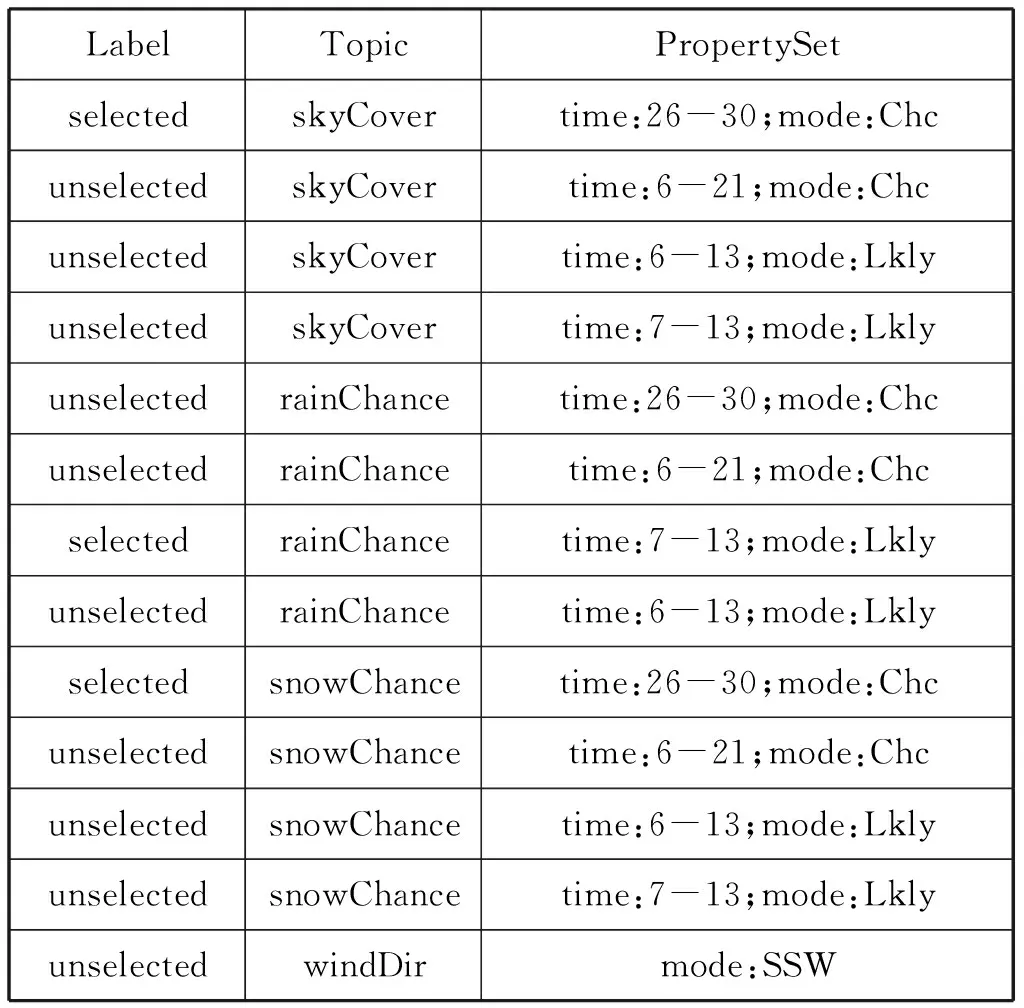
表1 內容選擇實例
2 相關工作
與人類在用自然語言交流時總是先想好說什么類似,內容選擇在自然語言生成的系統中總是作為第一個模塊出現。Sripada[2]的工作指出,相較于文字拼寫等其他錯誤,文本中信息的不恰當是用戶更不能接受的。
在早期經典的內容選擇方法中,內容選擇的問題通常被考慮成真正內容索要陳述的內容和描述內容的結構兩個方面。Moore[3]的工作將內容選擇的算法和文檔結構的算法集成在一起進行考慮。文獻[2,4,5]將內容選擇和文檔結構的工作看作一個流水線工作的兩個階段。
近些年來,出現了很多使用機器學習的方法,直接研究端到端的工作。Konstas[6]的工作研究了一個直接從語料庫訓練文本生成模型,直接完成內容選擇和文本生成的工作。Shang[7]研究定義了一個深度學習網絡,通過語料訓練了一個語義編碼器,自動生成自然語言。
是否將內容選擇的問題作為一個獨立問題解決,需要根據不同的場景單獨思考。在ILEX的工作中,內容選擇的查詢一次性的給出了用戶、物品和文章結構的相關信息。但是,如果要將機器學習的技術應用到相應的場景下,這也要求算法中要預置例如RST等更多的信息,這意味著大量的標注工作,也為算法在不同領域的遷移使用帶來了問題。因此,我們將內容選擇和用戶模型等內容進行分解,單獨考慮內容選擇。
3 內容選擇算法
本文提出的內容選擇算法框架如圖 1 所示。主要思想如下:在首先根據數據集進行結構特征的計算,并訓練相應的分類器。最后,對于特定場景,可通過分類器得到最終結果。
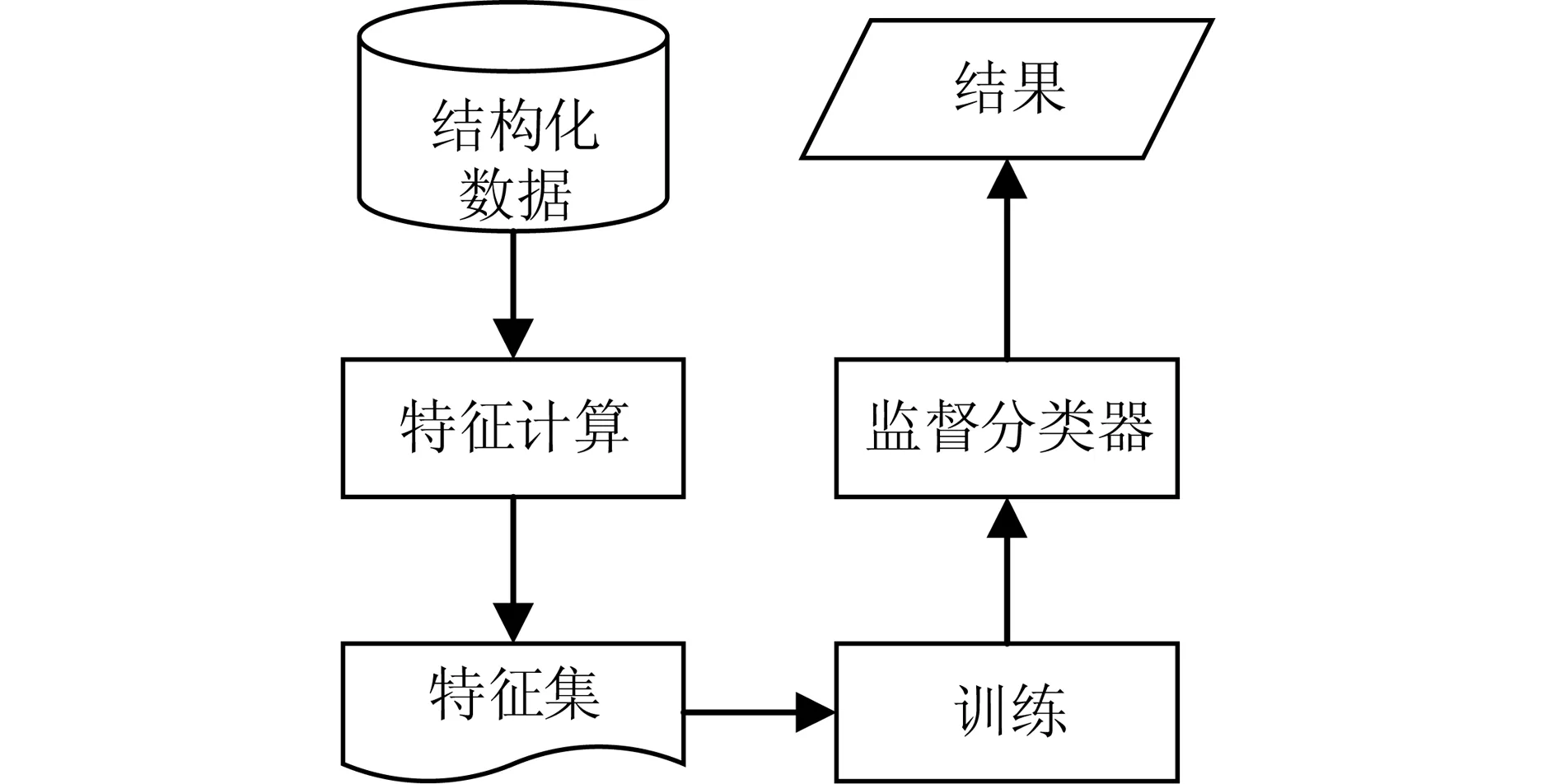
圖1 算法框架示意圖
3.1 樸素貝葉斯模型
樸素貝葉斯算法基于貝葉斯定理[8],是利用統計學的分類方法,我們假設topic的特征項之間是相互獨立的,利用概率求topic的類別。topic的最終類別是由概率的最大值所在的類別指定。
我們假設話題d={w1,w2,...,wm},使用該算法實現對文本d的分類,轉化成對P(Ck|d),其中1≤j≤n的求解,如果
P(ck|d)=max{P(c1|d)P(c2|d),…,
P(cn|d)}
(1)
則d屬于ck。
計算公式如下:
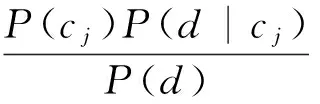
(2)

3.2 特征選擇
在傳統的內容選擇的工作中,內容選擇的方法是通過定義一個內容選擇的規則集合RuleSet。如果從監督學習系統的角度考慮,系統通過語料庫學習到相應的內容選擇規則RuleSet,特別的,在監督學習系統中,我們可以將這些RuleSet看作樣本的某種特征。
對于所有的內容選擇規則Rule,我們可以認為是一個關于結構數據的函數f,函數f將話題映射到至取值為{True,False}的二值空間。是否包含某一知識節點的決策過程,不考慮外部的領域知識庫DomainKnowledge和用戶知識庫Userknowledge,僅由輸入的語料數據決定。規則通常是對實例節點本身的取值進行判定,例如:一個異常的溫度通常是值得報道的。但有的時候規則也受其相關的節點的內容影響,例如:如果報道了降雨,通常也會報道降雨的數量。
通過對語料庫進行分析和驗證后,使用如表2的限定規則。

表2 內容選擇特征
與話題節點間關系相關的規則。
Topic規則主要獲取宏觀層面的內容選擇特征。對于每一個話題選擇,
f2主要獲取話題結構方面的內容選擇信息。例如,我們可以學習到在描述風向后,通常會緊接著秒速風速。
f1主要捕獲話題的共現情況,例如,降水概率可能和雨夾雪共同出現的概率可能很低。
與話題節點相關的規則。
f3主要體現當前話題類型出現的概率情況,例如,降水出現的概率很大,通常是會被提到的。
與話題節點屬性相關的規則
f4主要體現不同取值情況下,話題被選擇的情況。
4 試驗及分析
4.1 實驗數據
WeatherGov數據集包含了地區天氣預報的詳細氣象信息,其文本是天氣預報的短文本。數據集收集了2009年2月7日-2009年2月9日期間,人口超過1000人的美國城市天氣預報,共計3753個城市,文字和相應的數據來源均為www.weather.gov。數據集每天為每個城市創建2個記錄,共計22000條,一個場景是日間天氣預報,一個場景是夜間天氣預報,其內容主要由氣溫,風速,降雨概率等構成。
4.2 實驗設置
我們分別使用特征f1,f1+f2,f1+f2+f3,f1+f2+f3+f4的特征集進行測試,考查不同特征對結果的影響。
構建的數據集被分為兩部分。第一部分20000條被作為訓練集(development set),第二部分2000條作為測試集(test set)。
4.3 評價
評價標準使用精確率(precision)、召回率(recall)和F1值(F1-measure)。
4.4 實驗結果
實驗結果如表3所示。
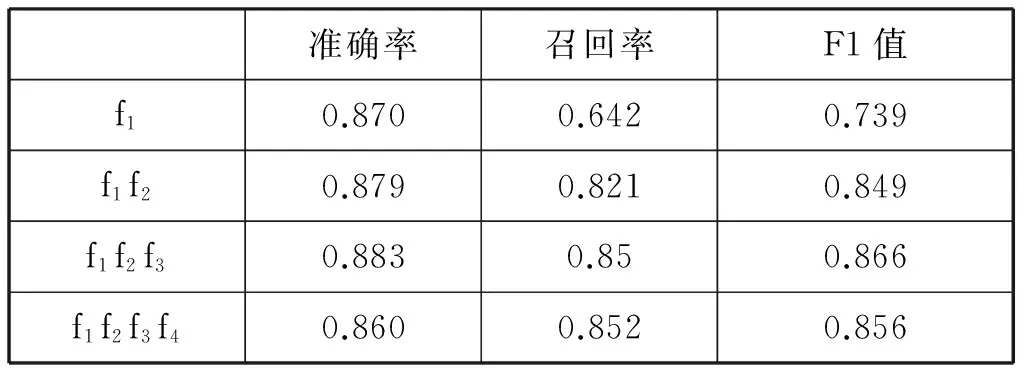
表3 實驗結果
可以看出,樸素貝葉斯模型在受限領域的內容選擇任務上可以達到較好的效果,從圖3中可以看出,在使用f1+f2+f3時的效果最好,f1值可以達到0.86。受到樸素貝葉斯其獨立性假設影響,使用所有的特征f1+f2+f3+f4效果相比反而有所下降。
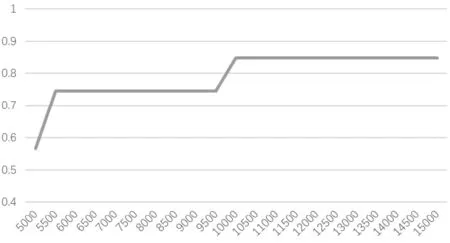
圖2 樣本數與F1值間的關系
此外,圖2描述了訓練樣本數和F1值間的關系,樣本數量在10000左右到達最優。
5 小結
本文提出了一種基于樸素貝葉斯的內容選擇方法。實驗表明,模型可以較好的在天氣數據集上完成內容選擇的任務。在未來的工作中,我們將研究獨立于領域的內容選擇特征,研究通用領域的內容選擇模型。
[1]Gkatzia D.Data-driven approaches to content selection for data-to-text generation[D].Edinburgh,UK:Heriot-Watt University,2015.
[2]Sripada S G,Reiter E,Hunter J,et al.A two-
stage model for content determination[C].Proceedings of the 8th European workshop on Natural Language Generation,Association for Computational Linguistics,2001,8:1-8.
[3]Moore J D,Swartout W R.A reactive approach to explanation:taking the user’s feedback into account[C].Natural language generation in artificial intelligence and computational linguistics,Springer,US,1991:3-48.
[4]Lester J C,Porter B W.Developing and empirically evaluating robust explanation generators:The KNIGHT experiments[J].Computational Linguistics,1997,23(1):65-101.
[5]Bontcheva K,Wilks Y.Dealing with dependencies between content planning and surface realisation in a pipeline generation architecture[C].International Joint Conference on Artificial Intelligence,Lawrence Erlbaum Associates Ltd,2001,17(1):1235-1240.
[6]Konstas I,Lapata M.A Global Model for Concept-to-Text Generation[J].J Artif Intell Res(JAIR),2013,48:305-346.
[7]Shang L,Lu Z,Li H.Neural responding machine for short-text conversation[C].arXiv preprint arXiv:1503.02364,2015.
[8]Lewis D D.Naive(Bayes)at forty:The independence assumption in information retrieval[C].European Conference on Machine Learning,Springer,Berlin Heidelberg,1998:4-15.
(責任編輯:王謙)
A Na?ve Bayes-based Content Selection Model
GONG Jun-peng1,CAO Juan2
(1.Faulty of Science and Technology,Communication University of China,Beijing 100024,China;2. New Media Institute,Communication University of China,Beijing 100024,China)
This article proposes a new method for learning content selection rules.Central to this approach is the content select feature.The algorithm introduced in the article automatically train a na?ve bayes model from a set of concept features.The results indicate model suits the task well in specific domain.
content selection;na?ve bayes;content feature
2017-04-25
北京市科委項目(Z161100000216141);中國傳媒大學工科規劃項目(3132016XNG1605)
龔雋鵬(1982-),男(漢族),重慶市人,中國傳媒大學副教授.E-mail:JPGONG@cuc.edu.cn
TP
A
1673-4793(2017)04-0014-04
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
Coco薇(2017年11期)2018-01-03 20:59:57
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
臺聲(2016年2期)2016-09-16 01:06:53
河南科技(2014年23期)2014-02-27 14:19:15
