區別特征單音節評測中過渡音征的影響
2017-07-05 12:59:25彭夢婭劉亞麗
中國傳媒大學學報(自然科學版) 2017年4期
關鍵詞:特征
彭夢婭,劉亞麗
(中國傳媒大學 傳播聲學研究所,北京 100024)
區別特征單音節評測中過渡音征的影響
彭夢婭,劉亞麗
(中國傳媒大學 傳播聲學研究所,北京 100024)
為將區別特征應用于語音評測,需分析區別特征應用的可行性及過渡音征對區別特征單音節評測的影響。利用區別特征探針參數并在區別特征決策樹中逐層判斷的方法進行單音節中聲母和韻母的唯一確定,對含過渡音征的語音樣本信號與無過渡音征的語音樣本信號分別計算聲母正檢率,兩組正檢率顯著性檢驗結果顯示無顯著性差異,因此建議在區別特征單音節檢測中不考慮過渡音征。該結果可以為進一步將區別特征應用于普通話語音客觀評測提供參考。
區別特征;過渡音征;計算機輔助評測
1 引言
目前的普通話水平測試工作中,雖有部分地區采用人工打分為主,計算機輔助評測的方式,大部分地區采用的仍是人工打分的主觀評測方法。雖然主觀評分能夠真實地反映被試者的語言能力,但存在評分員勞動強度大、測試成本高以及測試信度受主觀影響大等問題。隨著實驗語音學和語音識別等相關技術的進步,計算機輔助發音質量評測技術也在不斷發展。當下主流的客觀評測方法是基于統計模型的方法,該方法可操作性強適用范圍廣泛且可信度高,但統計模型缺少對語音的聲學模型和語音的知覺模型內部細節問題的研究,而且系統性能的提高過于依賴數據驅動。20世紀80年代國內開始進行普通話區別特征的研究,區別特征方法可以很好地解決基于統計模型方法存在的弊端。區別特征是針對語言的本質特征的理論,可以鎖定普通話評測中的發音錯誤和發音缺陷,將區別特征概念引入到計算機輔助發音評測,為漢語普通話語音評測提供了新的思路和方法。
關于區別特征的研究已經達到一定的深度。張家祿[1]首次建立了聲韻調體系的區別特征系統。章斯宇[3]建立了基于言語知覺特性的普通話區別特征聲韻調體系。遺憾的是,他們并未進行區別特征的參數化,因此無法將區別特征實際應用于語音評測。為解決這一問題,徐益華[4]和李戈[5]嘗試利用探針概念基本完成了漢語普通話聲母和韻母的區別特征參數化。他們完成了每個聲母或韻母對應的區別特征組中的單個區別特征的檢測,目的是檢測區別特征探針參數的有效性,但并未利用這些參數進行判別決策樹中的聲韻母檢測。
無論是識別還是評測中,過渡音征問題一直是難點。過渡音征現象主要由聲韻過渡段表現,它使得聲母的一部分特征或全部特征由韻母攜帶,特別是某些聲母,如不送氣塞音,其區別特征幾乎全部由過渡段攜帶。在基于統計模型的方法中,普遍認為過渡音征是必須考慮的,如論文[5-8]為解決過渡音征對聲母識別的影響,根據后接韻母第一音位的不同建立各種聲母模型,再使用基于聲韻母時長和短時能量的算法進行聲韻自動切分,之后進行模式識別。該方法需要建立91種聲母模型,數據量大,并且依賴聲韻自動切分,切分算法改變可能會造成聲母模型失效,降低了應用的普適性。區別特征理論是針對語言的本質特征的理論,在進行區別特征的研究時一般認為過渡音征問題是不需要單獨考慮的,那么在將區別特征應用于普通話語音評測時過渡音征問題的影響是否需要考慮,是我們將要進行討論的。
本文在區別特征相關研究的基礎之上,針對過渡音征問題,通過提取區別特征探針參數并在區別特征決策樹中逐層判斷的方法進行單音節中聲母和韻母的唯一確定,并對含過渡音征的語音樣本信號與無過渡音征的語音樣本信號分別進行聲母正檢率計算,對兩者正檢率結果之間的差異進行顯著性檢驗,分析在區別特征單音節檢測中過渡音征問題的影響。除此之外,對單音節中韻母進行正檢率計算,結合單音節中含過渡音征的聲母正檢率,分析區別特征應用的可行性。
2 實驗方法
2.1 樣本的選取和處理
語音樣本信號選自中國傳媒大學傳播聲學研究所錄制的語音語料數據庫中的單音節數據庫部分[11]。在該數據庫中選取50個人的語音樣本數據(男女比例1:1),年齡分布在19~21歲之間。該單音節數據庫涵蓋所有聲韻組合,選取362種聲韻組合的單音節,聲調全部為一聲,共18100個(50×362)。語音樣本采樣率為16kHz。按過渡音征有無將語音信號分別進行處理,處理方法如下:
含過渡音征樣本:通過人工聽辨去除不可用的單音節信號(誤讀或噪聲過大等),最終選定單音節樣本總數為14736個,包含所有可能的聲韻組合情況。并通過人工觀察語譜圖、時域圖的方法,將單音節前后的靜音區去除,只保留純凈的單音節信號。
無過渡音征樣本:通過人工聽辨去除不可用的單音節信號(誤讀或噪聲過大等),最終選定單音節樣本總數為3247個,從聲母呼讀音樣本中獲取,如表1所示。為了得到純凈的聲母信號,處理上不受后面的元音信號和過渡音征的影響,將呼讀音后部的非聲母部分切除。采取人工切音的方法,保留起始點和排除過渡音、韻母的干擾。切割主要根據輔音的語圖特點、時域信號特點,并通過聽辨進行切分。
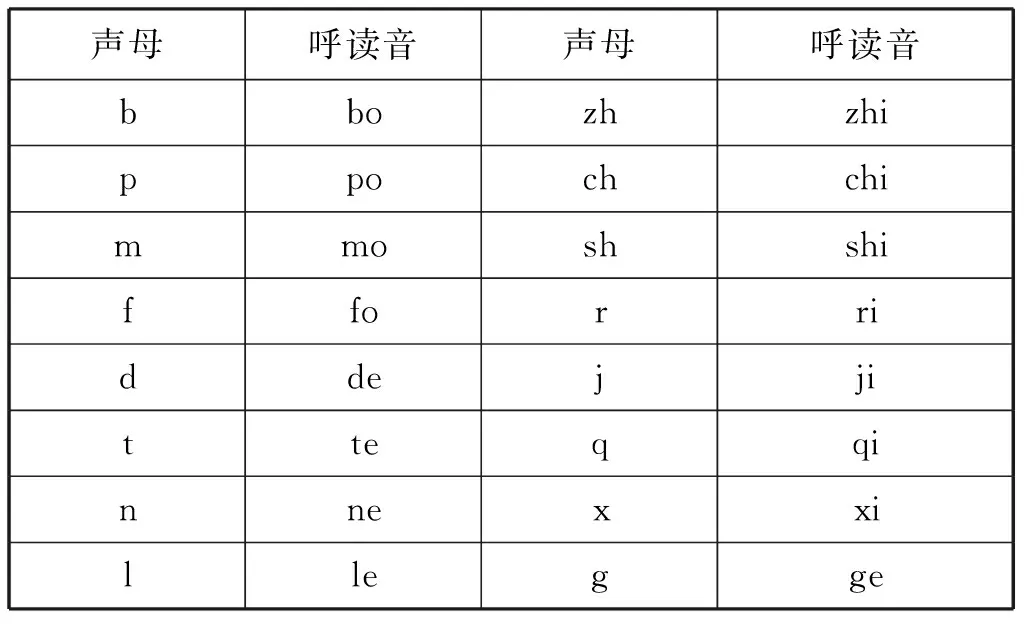
表1 聲母呼讀音對照表
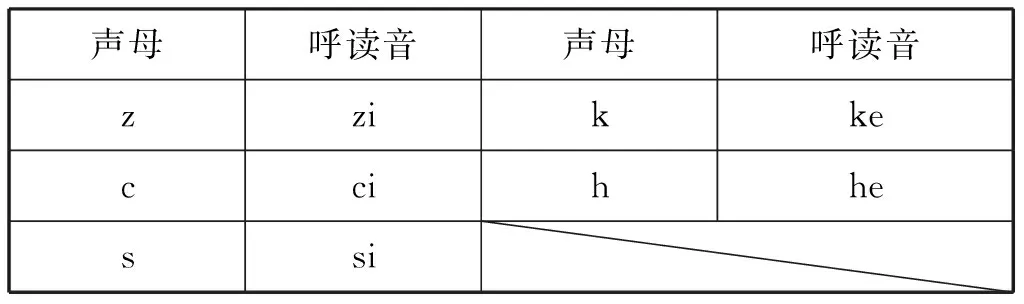
續表
2.2 參數選取
選用文獻[4-5]的聲母和韻母區別特征探針參數,用于聲韻母區別特征決策樹[3]中各區別特征有無的判別。
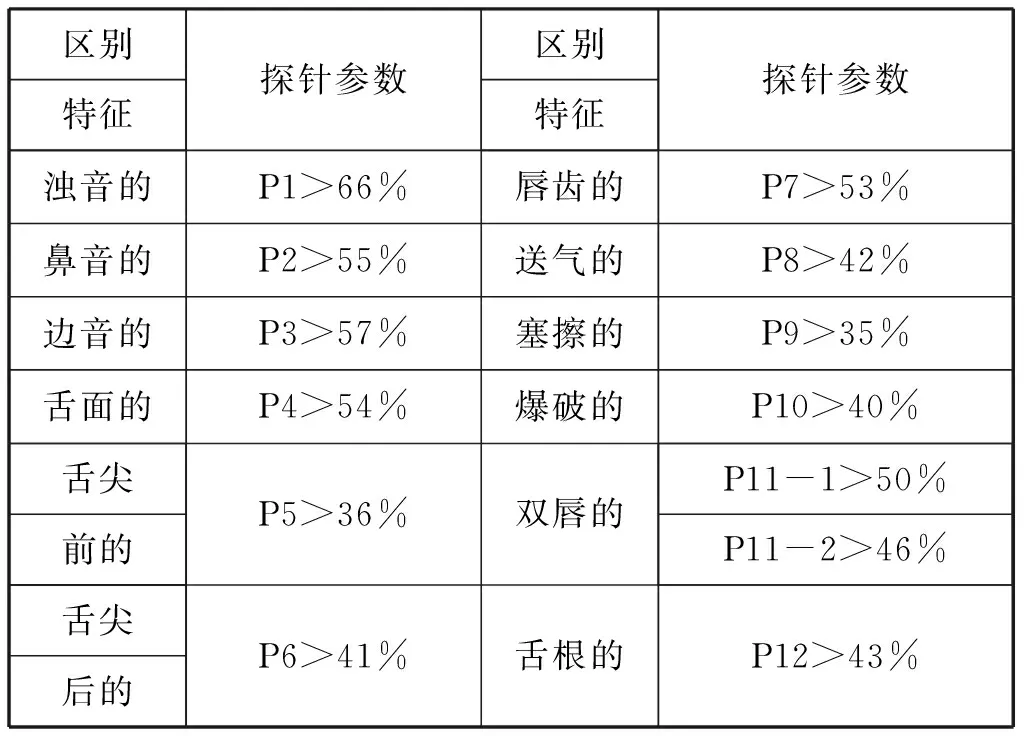
表2 聲母區別特征探針參數
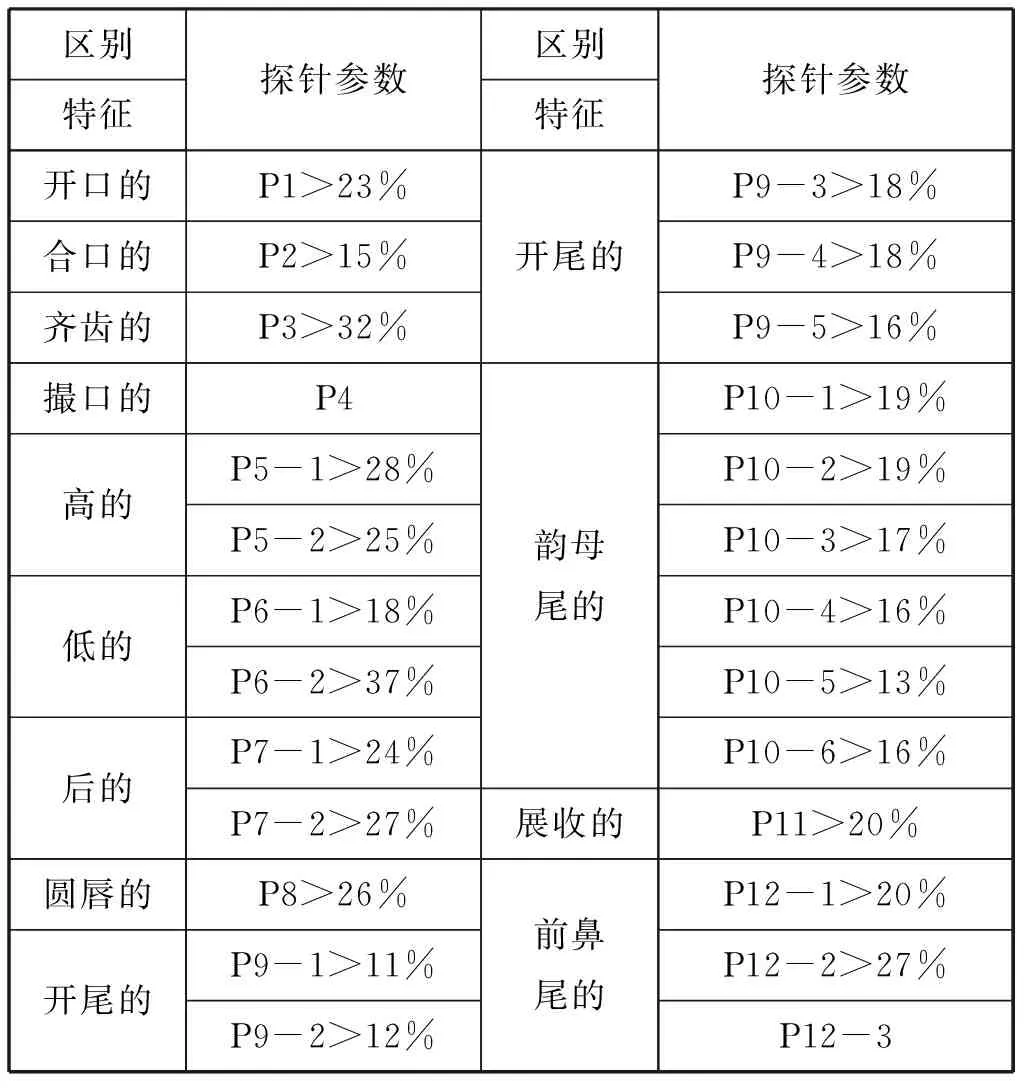
表3 韻母區別特征探針參數
2.3 實驗流程
針對每個單音節,通過計算得出的12個聲母探針參數(見表2)和24個韻母探針參數(見表3)對聲韻母進行判別的流程如圖1所示。
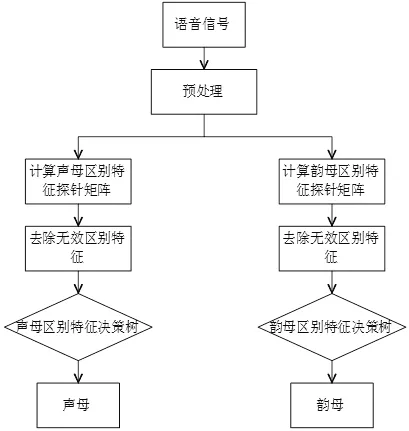
圖1 單音節中聲韻母正檢流程圖
第一步,對單音節語音樣本信號進行預處理,包括預加重、分幀、加窗、聲母邊界初判(聲母邊界初判指的是,聲母部分語音幀的能量值要低于整個音節語音幀的能量平均值,利用此特征實現音節中聲母位置的初判);
第二步,對預處理后的語音信號進行區別特征探針參數的計算,得到1×12的聲母區別特征探針參數矩陣和1×24的韻母區別特征探針參數矩陣;
第三步,將每個聲母和韻母判別時用不到的區別特征探針參數矩陣值設定為0,即把不參與判別的區別特征(后稱無效區別特征)去除,只考慮理論上含有的區別特征;
最后,根據區別特征探針矩陣在聲母/韻母區別特征決策樹[3]進行路徑搜索,通過對節點處區別特征有無的判定實現對單音節中聲母和韻母的唯一確定,以q為例,如圖2所示,依次判別“濁音的”、“舌面的”、“送氣的”和“塞擦的”四個區別特征的有無,最終確定聲母q。

圖2 聲母“q”判決路徑
將樣本中所有單音節進行上述聲韻母判別,判別結果用于正檢率的計算,計算方法如下:
對于某一聲母或某一韻母,測試集中含有該聲母或韻母的單音節樣本為a個,在這些樣本中,通過區別特征檢測出含有該聲母或韻母的單音節樣本為b個,則:正檢率=b/a×100%。
3 實驗結果及分析
使用上述流程及計算方法進行正檢率計算,含過渡音征語音樣本聲母正檢率與無過渡音征語音樣本聲母正檢率如表4所示,韻母的正檢率如表6所示。
表4顯示含過渡音征語音樣本聲母正檢率大多在60%以上,平均正檢率為63%。無過渡音征語音樣本聲母正檢率大多在60%以上,平均正檢率為62%。正檢結果偏低,進一步分析表4,可以得出:
(1)參與判別的區別特征個數增多正檢率會相應降低,如j/q/x,其中j的判別需要3個區別特征,q和x的判別需要4個區別特征,j的正檢率明顯高于q和x。同樣的情況還存在于z/c/s、zh/ch/sh、b/g/d等聲母判別中。說明區別特征逐層判斷存在誤判不斷累積的情況,參與判別的區別特征越多,正檢率就相應越低,但由于各區別特征之間非相互獨立,最終正檢率并不是各參與判別的區別特征正檢率的乘積。
(2)每個區別特征對于判別的貢獻程度是不同的,如m有三個參與判別的區別特征:“濁音的”、“鼻音的”和“雙唇的”,l也有3個參與判別區別特征:“濁音的”、“鼻音的”和“邊音的”,在兩者的判別中雖然只有一個參與的區別特征不同,但是正檢率差距較大,說明區別特征“雙唇的”和“邊音的”在聲母的判別中,貢獻程度是不同的。同樣的情況還存在于b/h等聲母的判別中。
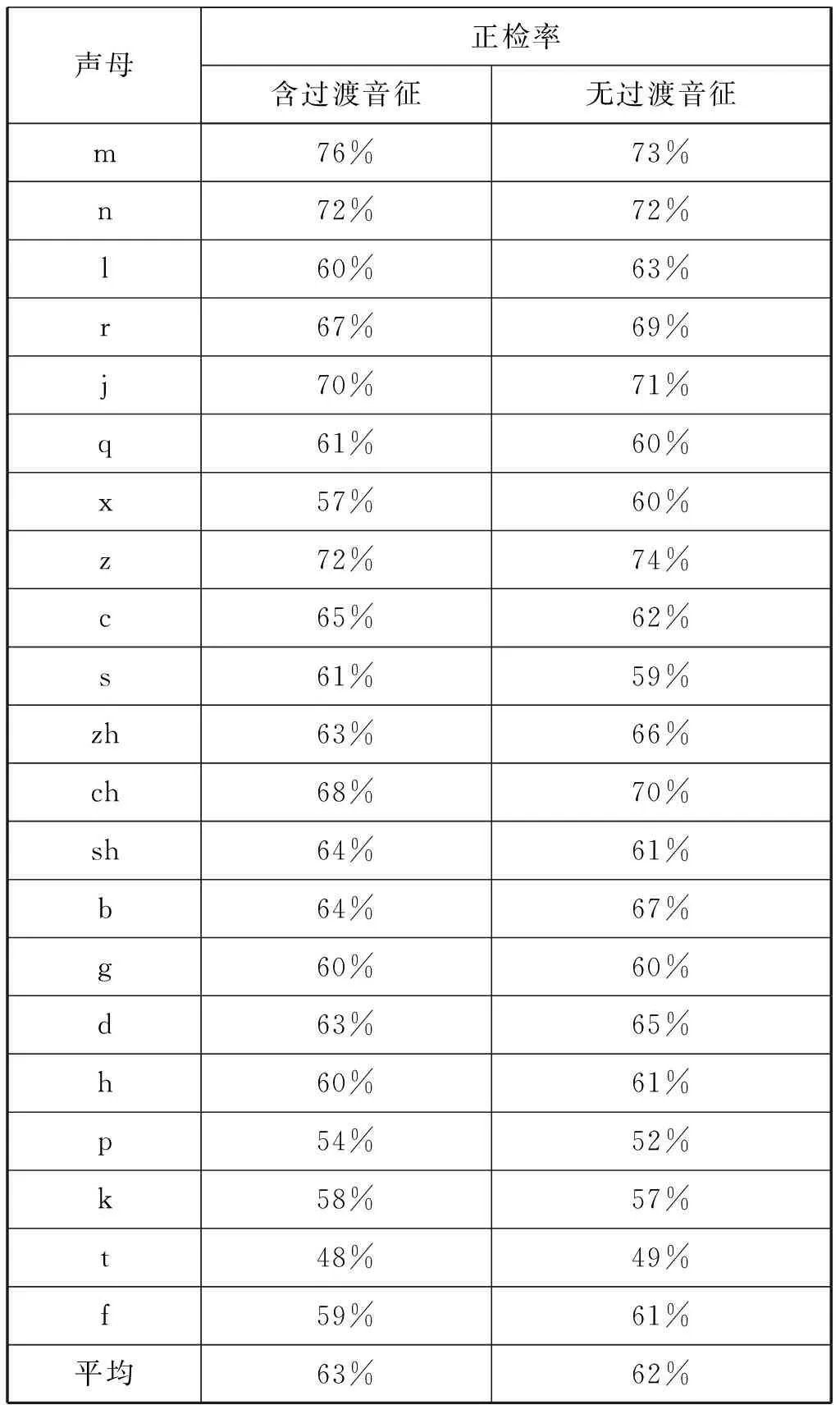
表4 含、無過渡音征語音樣本聲母正檢率
此外,為觀察過渡音征對聲母判別的影響,將表4中的含過渡音征語音樣本聲母正檢率和無過渡音征語音樣本聲母正檢率進行如下對比分析。
含過渡音征語音樣本聲母正檢率和無過渡音征語音樣本聲母正檢率之間的相對變化率如表5所示,此變化率指的是無過渡音征聲母正檢率相對于含過渡音征聲母正檢率的變化率。
由表5可以看出,兩組正檢率之間的平均變化率為3%,變化幅度很小。將兩組正檢率進行顯著性檢驗,結果為p=0.319>0.05,即含過渡音征語音樣本聲母正檢率和無過渡音征語音樣本聲母正檢率之間不具有顯著性差異,說明從區別特征角度進行聲母正檢時過渡音征影響很小。
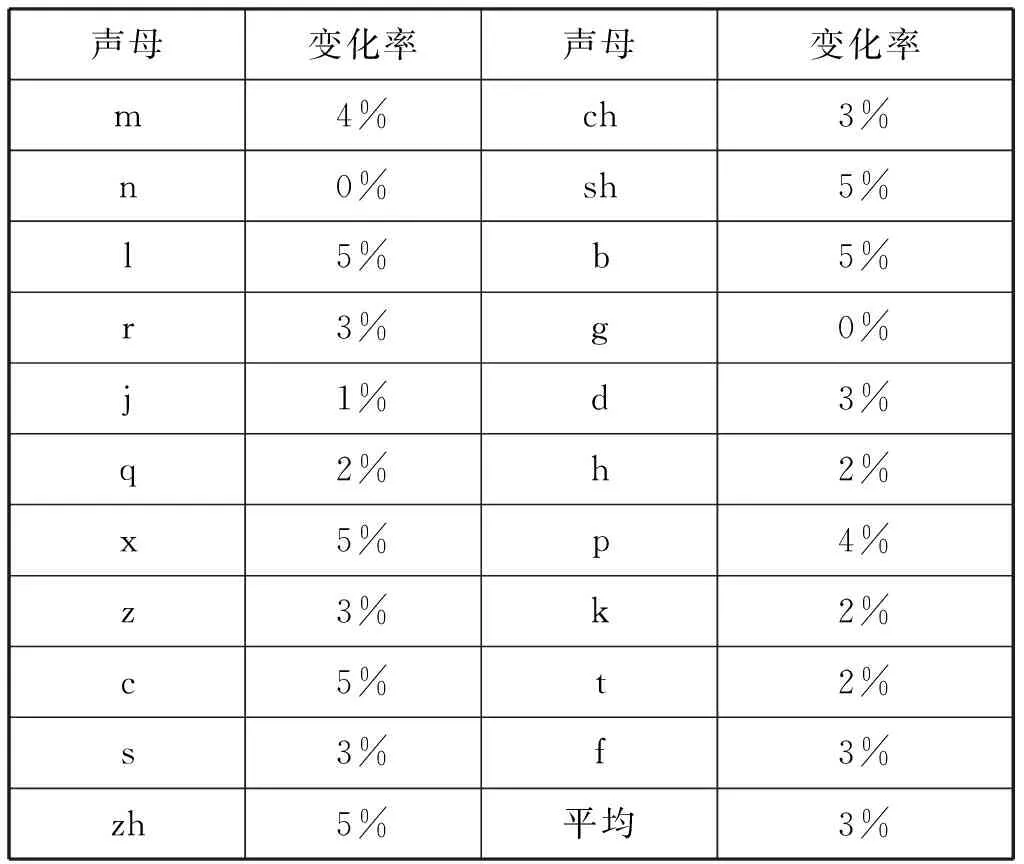
表5 聲母正檢率相對變化率
韻母正檢率結果如表6所示,語音樣本為含過渡音征的語音樣本信號,正檢流程如圖1中韻母部分所示,計算方法與聲母相同。
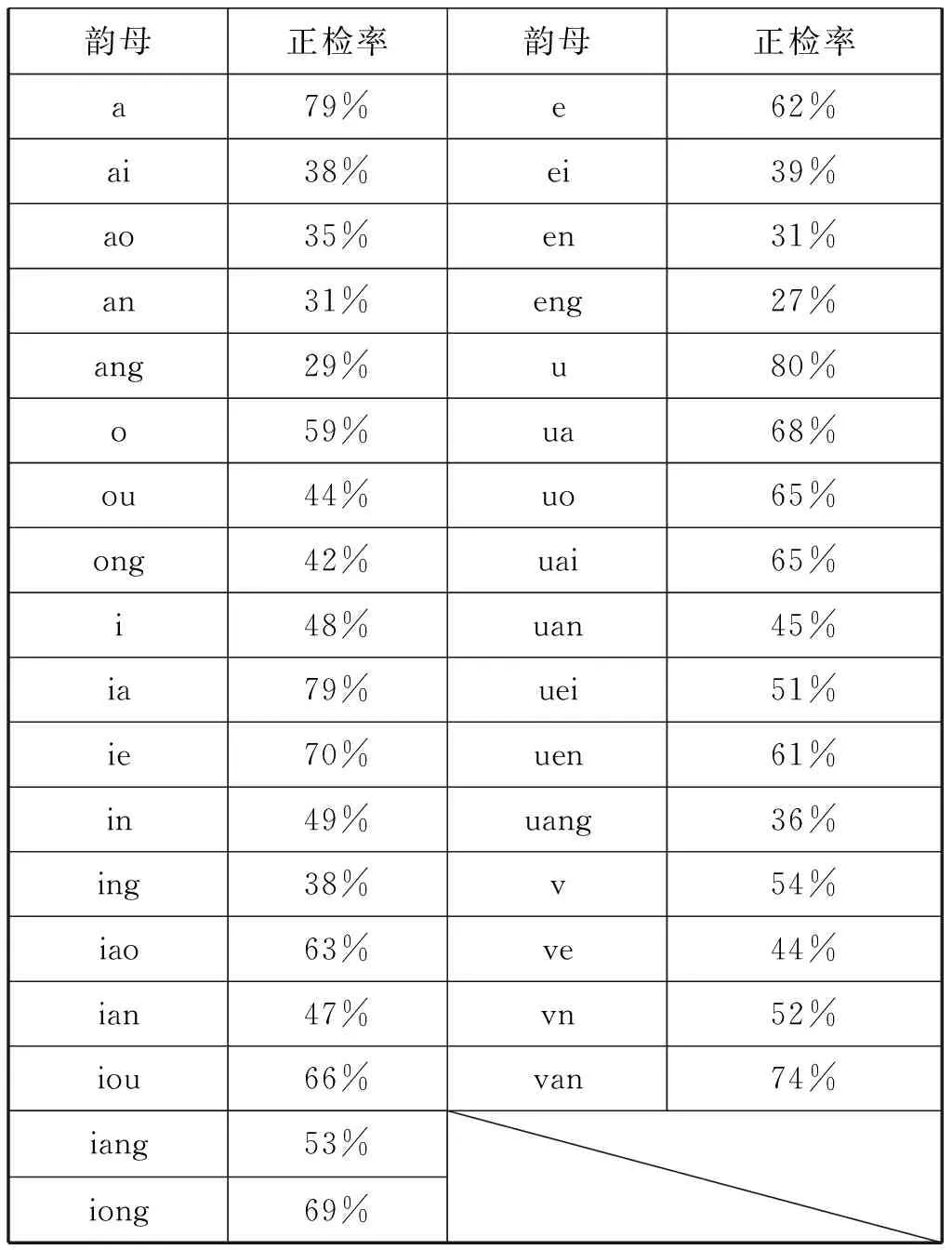
表6 韻母正檢率
表6顯示韻母正檢率大多在50%以上,平均正檢率為54%。相比表4中含過渡音征聲母正檢率,正檢結果偏低,進一步分析表6,可以得出:
(1)韻母正檢率同樣存在參與判別的區別特征個數增多正檢率降低的現象,如無介音韻母o/ou/ong,其中o的判別需要4個區別特征,o和ong的判別需要5個區別特征,o的正檢率明顯高于ou和ong。同樣的情況還存在于a/ai/ao、o/ou/ong等韻母的判別中。韻母正檢率同樣存在不同區別特征對于判別的貢獻程度不同的現象,如ia有4個參與判別的區別特征:“合口的”、“齊齒的”、“低的”和“后的”,iong也有4個參與判別的區別特征:“合口的”、“齊齒的”、“低的”和“開尾的”,在兩者的判別中雖然只有一個區別特征不同,但是正檢率差距較大,說明區別特征“低的”和“開尾的”在韻母的判別中,貢獻程度是不同的。同樣的情況還存在與ai/ao/an/ang等韻母的判別中。
(2)韻母中含有的音位越多,其正檢率越低,如a/ai/ang、o/ou/ong、i/in/ing、u/ua/uai/uang等,音位增多的同時韻母正檢率呈現由大到小的變化趨勢。韻母中含有的音位增多,發音時口型和舌位都會發生不同程度的變化,區分難度隨之增加,造成了正檢率的降低。
(3)韻母按內部結構的不同,可以分為單韻母、復韻母和鼻韻母三類,鼻韻母所占比例最大,有16個。由表6可以看出鼻韻母正檢率普遍較低,平均正檢率為46%,相比于單韻母和復韻母低得多。韻母按韻尾情況分為無尾韻母、元音尾韻母和鼻音尾韻母三類,將這三類韻母正檢率分別求平均值的結果如表7所示。
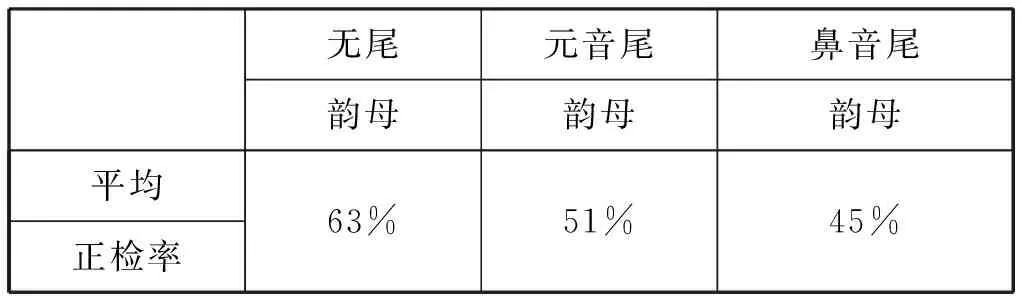
表7 按韻尾情況分類韻母平均正檢率
由表7可以看出,無尾韻母正檢率較好,鼻韻尾韻母正檢率較差。鼻音相關韻母一直是韻母識別與評測中的難點,在論文[5]進行韻母區別特征“鼻韻尾的”的正檢時就存在結果不理想的情況,鼻音相關的區別特征參數應進一步研究,必要時可嘗試其它聲學參數。
(4)含過渡音征聲母正檢率和韻母正檢率,兩者所用語音信號樣本相同,但對比表4和表6可以發現聲母的正檢率明顯好于韻母正檢率。對比聲韻母區別特征理論體系,韻母的區別特征體系相對復雜,許多韻母在判別中涉及的區別特征多,誤判累積也會相應增多,在目前的韻母參數研究中仍有個別特征參數選取不夠理想,需改進。
綜上所述,從區別特征角度進行單音節中聲母的檢測時過渡音征問題影響很小,建議忽略。韻母中音位增多正檢率隨之降低,部分區別特征參數應進一步研究,必要時可嘗試其它聲學參數。參與判別的區別特征個數增加會造成誤判累積,而且各個區別特征對最終的判別貢獻程度是不同的,因此有必要對各區別特征進行權值設定,以降低誤判的累積程度。
4 結論
區別特征單音節檢測中聲母和韻母的平均正檢率可以達到60%左右,表明區別特征應用于單音節測評是可行的。但總體來說正檢率偏低,這說明已有的區別特征參數仍需改進后才能應用到普通話語音評測當中。
對比含過渡音征語音樣本聲母正檢率與無過渡音征語音樣本聲母正檢率,兩者之間的顯著性檢驗結果說明兩者之間不具有顯著差異,因此從區別特征角度進行單音節檢測時建議不考慮過渡音征。
韻母區別特征體系相對復雜,口型和鼻音相關區別特征對最終判別結果影響較大,應進一步研究,或嘗試其它聲學參數。
各區別特征之間的相互影響及誤判率的累計都可能造成評判結果不理想,應當確定每個區別特征對于聲母或韻母判別的貢獻程度,根據每一個區別特征的在評判時的重要性進行權值的設定,權值的設定可以將區別特征之間的相互影響和誤判累積程度降低。不僅如此,區別特征參數是根據已有的數據結果,按照統計判別的最佳標準而設定的,而沒有結合評測人員的主觀經驗,完全依賴標準數據得到的參數是片面的,最終的評分機制應與主觀測評相結合的合理評分機制。這也是下一步需要進行的工作。
[1]張家騄.漢語普通話區別特征系統[J].聲學學報,2005,30(6):506-514.
[2]陸致極.試論普通話音位的區別特征[J].語文研究,1987,(4):10-21.
[3]章斯宇.基于言語知覺特性的普通話區別特征系統研究[D].北京:中國傳媒大學博士學位論文,2011.
[4]徐益華.自然音節狀態下聲母區別特征檢測[D].北京:中國傳媒大學碩士學位論文,2015.
[5]李戈.自然音節狀態下韻母區別特征檢測[D].北京:中國傳媒大學碩士學位論文,2016.
[6]戚建宇.普通話單字發音客觀評價方法研究[D].蘇州:蘇州大學碩士學位論文,2006.
[7]陳麗霞.基于聲韻母基元的漢語語音識別系統[D].南京:南京理工大學碩士學位論文,2005.
[8]湯霖.普通話聲母的客觀評測[J].計算機應用.2010,(6):30-4.
[9]劉振安.基于特征比較的語音評分方法研究.計算機應用[J].2005,(12):25-12.
[10]鄭世杰.基于語音自動評測的普通話學習系統的研究[D].哈爾濱:哈爾濱師范大學碩士學位論文,2015.
[11]呂軍,基于語音識別的漢語發音自動評分系統的設計與實現[J].計算機工程與設計,2007,(3):28-5.
[12]馮曉亮.普通話輔音的參數化區別特征體系構建[D].北京:中國傳媒大學博士學位論文,2009.
(責任編輯:王謙)
Effect of Initial-to-Final Transition in Detecting Syllables by Distinctive Features
PENG Meng-ya,LIU Ya-li
(Communication Acoustics Laboratory,Communication University of China,Beijing 100024,China)
In order to apply distinctive feature theory in Mandarin evaluation technology,it is necessary to analyze the feasibility of application of distinctive features and effect of initial-to-final transition in detecting syllables.By extracting acoustic parameters and distinguishing layer by layer,the initial and the final in a syllable can be determined uniquely.The detective accuracy of initials in speech samples with initial-to-final transition and speech samples without initial-to-final transition shows no significant difference,so initial-to-final transition is suggested to be ignored in in detecting syllables by distinctive features.The results obtained in this paper can provide a reference for further applying the distinctive features to the objective evaluation of Mandarin.
distinctive features;initial-to-final transition;computer-assisted assessment system
2017-04-14
彭夢婭(1992-),女(漢族),安徽阜陽人,中國傳媒大學碩士研究生.E-mail:yl_liu@cuc.edu.cn
O
A
1673-4793(2017)04-0064-06
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
