基于Hadoop平臺的K—means算法優化綜述
2017-07-12 13:46:51孟佳偉孫紅
軟件導刊 2017年6期
孟佳偉+孫紅
摘要:在科技高速發展的今天,海量數據處理問題受到人們廣泛關注。將K-means聚類算法與Hadoop平臺相結合是處理海量數據問題的一條可靠途徑。簡單介紹Hadoop和K-means算法以及K-means聚類算法MapReduce并行化實現,并闡述目前Hadoop平臺下K-means算法的幾種優化方式,最后提出研究展望。
關鍵詞:海量數據處理;Hadoop;K-means;MapReduce
DOIDOI:10.11907/rjdk.171405
中圖分類號:TP301
文獻標識碼:A 文章編號:1672-7800(2017)006-0208-04
0 引言
隨著科學技術的飛速發展,互聯網技術已經深入到社會的各個領域,由此,數據量呈現出一種指數級增長[1]。如何高效地對這些海量數據進行處理和分析已成為當前研究熱點。隨著數據規模越來越大,在面對海量數據時,傳統的數據挖掘工作會出現儲存量不足、用時過長等缺點[2]。而云計算的出現則為解決這些問題提供了新思路,將云計算與傳統數據挖掘方法相結合并對其進行優化是科學工作者們不斷研究的方向。
聚類分析是數據挖掘方法中的常用方法。1975年,Hartigan對聚類算法提出了系統論述[3]。在眾多聚類算法中,K-means算法是被應用與研究最廣泛的算法。如今,云計算已經得到了人們的廣泛關注,而Hadoop平臺是一個可以開發和并行處理大數據的云計算平臺。作為一種由分布式技術、網絡計算機技術及并行技術發展而來的產物,Hadoop可以說是一種為了適應大規模數據存儲以及計算而衍生出的模型構架[4]。本文將對當前基于Hadoop平臺的K-means算法的各種優化方法進行綜述,并提出展望。
1 Hadoop
從最初版本HDFS和MapReduce于2004年開始實施,到2011年1.0.0版本釋出標志Hadoop已初具生產規模,經歷了短短不到十年的時間。作為一種開源云計算模型,Hadoop模仿并實現了Google云計算的主要技術,不但可移植性強,而且使用Java語言進行編寫[5]。其最早是來自于Google的一款名為MapReduce的編程模型包。MapReduce最早是由Google公司在2004年提出的一種可伸縮并且是線性的用于處理海量數據的并行編程模型[6]。Hadoop平臺的出現極大地便利了對于處理海量數據和應用程序的算法研究。Hadoop框架中最核心的部分是MapReduce和HDFS。分布式文件系統Hadoop Distributed File System的縮寫即HDFS,其具有極高的容錯性并且對機器要求不高,適合部署在廉價的機器上,為分布式計算存儲提供底層支持。其能夠提供高吞吐的數據訪問,因而適合于大規模數據集上的應用。
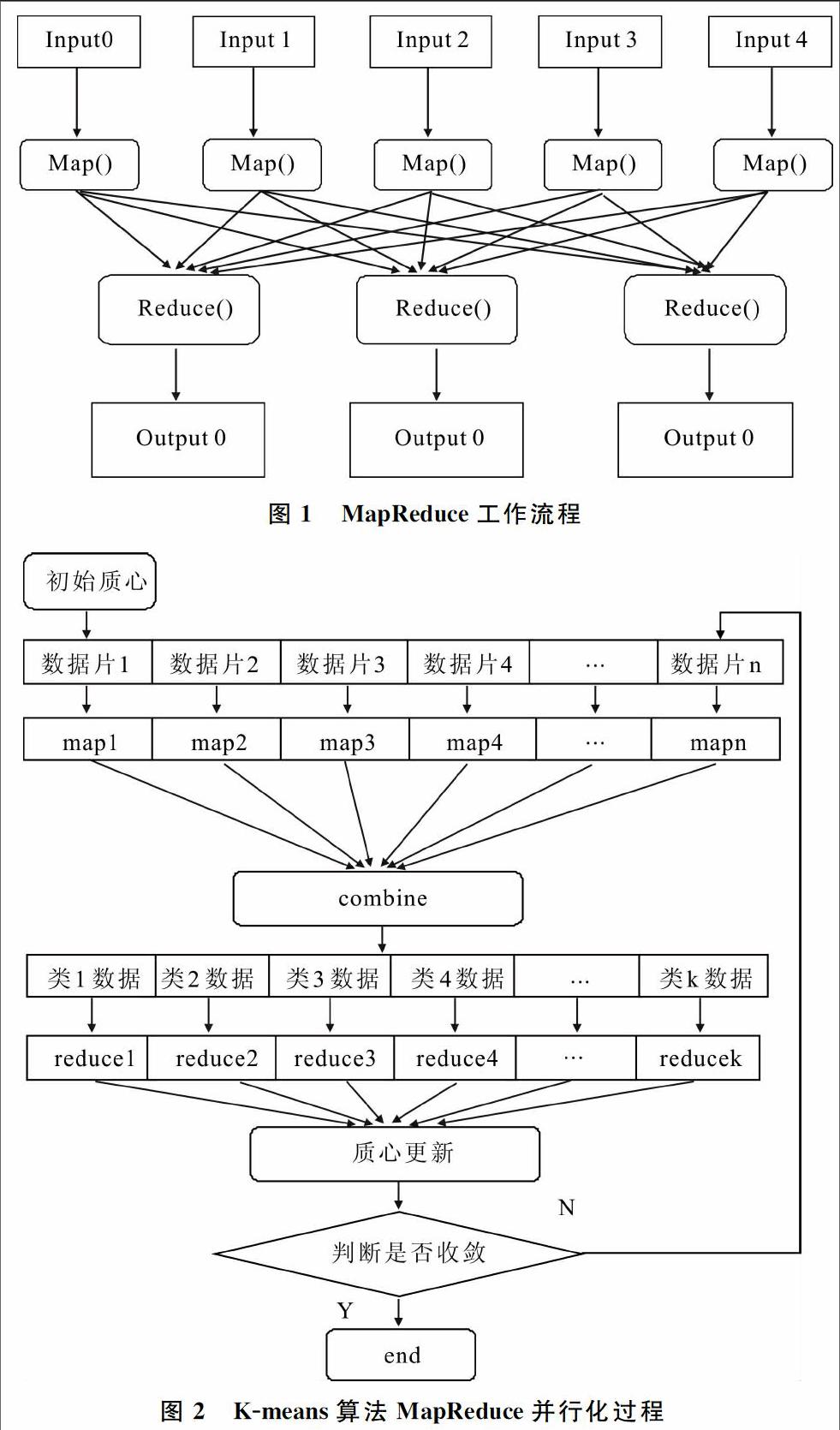
MapReduce可以使程序自動分布到一個超大集群上并發執行,并且這個超大集群可以由普通機器組成[7]。其中,Map將一個任務分解為多個任務。而Reduce則是將分解之后的多任務的處理結果進行匯總并且得出分析結果。由大量機器組成的機器集群可以被視作分布式系統的資源池,通過對并行任務進行拆分并且交給空閑機器資源處理這種方式提高了計算效率。對MapReduce的工作流程進行展示如圖1所示,Map對任務進行分解,Reduce則負責合并。通過Map函數及Reduce函數對一組輸入鍵值對(Key/Value)的計算,得到一組輸出鍵值對。一個Mapper類、Reducer類和一個創建JobConf的驅動函數組成了運行于Hadoop平臺下的MapReduce應用程序。另外若有需要,還可以有一個Combiner類,實際上該類也是Reducer的一種實現。基本計算流程首先將輸入數據劃分為數據塊,之后處理數據塊得到
2 K-means算法
追根溯源,K-means算法是由MacQueen[9]于1967年提出,并且用數學方法對算法進行了證明。K-means算法由于其簡單、高效、易實施等特性受到科學工作者的青睞,被不斷改進優化并應用于實踐,目前被廣泛應用于文本聚類、考古和自然語言處理等諸多領域。K-means算法的第一步工作是初始聚類中心的選取,然后對數據點進行分類后通過對每個聚類平均值的計算來調整聚類中心并且不斷迭代循環,最終達到使得類間對象相似性最小,而類內對象相似性最大的目的。算法步驟:首先是自樣本隨機選取K個對象作為初始聚類中心,然后計算其它數據對象到聚類中心距離并將其分配到相應類,接著計算每一類中所有對象平均值作為新聚類中心,循環上一步與此步驟直至目標函數不再變化[10]。K-means算法本身存在全局搜索能力差、對初始聚類中心依賴性大、聚類效率和精度都不高,而且容易陷入局部最優解等缺點[11]。因此,這些都是科學工作者們不斷優化和改進K-means算法的方向。
3 K-means算法MapReduce并行化實現
通過MapReduce模型實現K-means算法并行化的基本思路實際上就是每一次迭代都啟動一個MapReduce過程。根據計算需求,對數據做按行存儲的安排同時可按行分片且片間數據無相關性[12]。具體流程如圖2所示,通過Map函數從HDFS的文件中讀取數據并通過每條記錄得到其與各質心距離,Map函數的輸入為原始文件和聚類質心,通過比較得到各記錄到質心的距離,對每個記錄進行分類,將其歸到距離最近質心所屬類,最后將記錄以及記錄所屬類寫入中間文件,因此Map函數輸出為中間結果。在執行Map函數之后,MapReduce首先會對輸出結果進行合并,之后再執行Reduce函數,根據Map函數的輸出通過Reduce函數進行聚類中心的更新;同時對標準測度函數值進行計算,為主函數是否結束迭代提供判斷依據。如果未結束則繼續進行循環并且得到的新聚類中心將由下一輪Map函數使用。在主函數中調用MapReduce過程,每次迭代申請一個新Job。迭代結束的判斷標準就是兩次得到平方誤差和差值小于給定閾值,則最后結果就是Map函數最后一次中間結果[13]。
4 Hadoop平臺下的K-means算法優化
4.1 粒子群算法引入
有研究者[14]提出了一種并行基于MapReduce的K-PSO算法。馬漢達,楊麗娜[15]進一步將PSO-KM全部并行運行,提出了一種用粒子群算法對K-means算法的初始聚類中心進行優化的在Hadoop平臺上加以實現的改進方法,這種改進使得K-means算法和PSO算法都可以用MapReduce模型處理。引入PSO算法在一定程度上克服了K-means算法對初始聚類中心敏感的問題。在Map階段,更新和移動并且評估粒子,之后判斷更新單個粒子最優解,如果粒子有更新則進行粒子群最優解的更新;然后進入Reduce階段,接收更新后粒子并對粒子信息進行合并,且更新粒子群最優解。
其中,進行PSO算法處理操作的第一步是初始化和構建初始粒子群,再以每個粒子為每個Map接收新位置、速度、價值以及單個粒子最優適應度,最終的Key為粒子id。Value屬性則是更新后粒子屬性字符串,接收Key和List(Value)的為PSO-Reduce函數。特定粒子的id即為這個Key,最新更新的粒子屬性信息包含于Value列表。通過Reduce函數實現信息合并,全局更新粒子群最優位置以及粒子群最優適應度并輸出粒子群最優粒子。
4.2 Canopy算法與K-means算法相結合
朱薔薔、張桂蕓等[16]提出了一種在Hadoop平臺下將Canopy算法與K-means算法結合使用的優化思想,使用Canopy算法對數據經行預處理,得到K-means算法的K值,并且K值由得到的Canopy個數決定。實驗證明,這種優化方式具有良好的加速比及可擴展性。毛典輝[17]針對Canopy-Kmeans算法中的Canopy選擇具有隨意性和盲目性的問題,提出一種使用“最大最小原則”對算法進行改進,并通過MapReduce并行框架進行并行擴展的優化思想。改進后的算法在抗噪能力和分類準確率上明顯優于隨機挑選Canopy策略。基于以上研究,盧勝宇、王靜宇等[18]提出了一種新的改進方式,針對K-means算法選擇初始聚類中心的盲目性使用余弦相似度度量及Canopy算法進行改善,并通過并行計算框架實現并行擴展。Canopy算法的過程首先是進行閾值tl、t2的設定,并且t1要大于t2;然后在數據集里隨機選取中心點并且將與之距離不大于t1的數據點放入聚類中心是剛才選取的點的聚簇。之后剔除數據集中與中心點距離不大于t2的點,循環至數據集為空。通過優化之后,在Hadoop平臺下通過Map及Reduce階段獲得全局Canopy中心集合,并使用其進行粗糙聚類之后得到數個相互重疊的Canopy聚類集合,將其作為下一步K-means初始聚類中心。所有對象到簇類中心距離是K-means算法每次迭代都必須計算的。優化之后通過實驗證明,其在處理海量數據時具有較好的聚類質量、加速比及擴展性。
4.3 Hash算法引入
通過散列函數將任意長度輸入轉化為固定長度輸出即為Hash算法,也稱為散列算法[19]。對于海量高維數據在Hadoop平臺下使用K-means算法存在聚類效果不好的問題,張波,徐蔚鴻等[20]提出了基于Hash改進的并行化并在算法整體并行化時通過Combine等機制改善執行效率及并行化程度的優化方案。通過Hash改進的并行化方案的原理是將高維數據映射至壓縮標識空間,進而實現聚類關系的挖掘以及初始聚類中心的選取。用Hash算法進行初始聚類中心選取就是將不同相似度數據散列至不同的地址空間。對應地將相似度大的數據散列到同一地址空間。初始聚類中心就是選自最多同義詞的K個地址空間。在實現并行化時,設計了3個獨立運行的Job作業鏈工作且上一Job輸出為下一輸入。其中第1個Job用于構造散列表,第2個則是計算初始聚類中心,第3個用于完成對全部數據的K-means聚類。最后通過實驗證明,這種優化對聚類穩定性及準確率都有很好的改善作用。
4.4 遺傳算法與K-means算法相結合
與K-means算法一樣,遺傳算法也是廣為人知的算法之一[21]。因此將K-means算法與遺傳算法相結合的研究也吸引著許多研究者。戴文華、焦翠珍[22]等將K-means聚類算法與并行遺傳算法相結合,對聚類的結果及K值進行優化。之后,賈瑞玉、管玉勇等[23]提出了基于MapReduce模型的并行遺傳K-means算法,實驗證明其優化效果良好。實質上,遺傳K-means算法就是把每個聚類中心坐標當成染色體基因。聚類中心個數就是染色體長度,對若干相異染色體進行初始化操作并將其當成一個種群進行遺傳操作,最終獲得適應度最大染色體,而最優聚類中心坐標就是解析出的各中心點坐標。該算法第一步是初始化聚類個數K和最大遺傳代數以及種群個數P;第二步是初始化種群也即隨機產生種群個數且每個都表示一個聚類結果的染色體;第三步是對染色體進行K-means操作并評價適應度和記錄;第四步是對結束條件進行判斷看是否達到,若未滿足則進行選擇、交叉和變異操作;第五步轉到步驟三。在Map和Reduce設計過程中,在Map階段進行個體初始化和適應度評價以及K-means操作。在Reduce過程中,針對相同鍵,滿足停機條件則輸出各子種群中最優個體后選出最終的最優個體。依據是染色體末位適應度值,若否,則需要完成一個子種群的遺傳操作。
4.5 人工魚群算法與K-means算法相結合
將人工魚群算法與K-means算法相結合也是一種優化思路[24]。陳書會、周蓮英[25]利用人工魚群算法對K-means算法進行優化,并通過MapReduce并行處理框架進行并行處理。通過afsa全局尋優特點在數據集中靠魚群行為搜索最優解或與之相近解并將其作為K-means初始值。并行人工魚群算法思想就是對魚群進行劃分,劃分之后的各子魚群在所給數據集中獲得此次過程局部最優解。本次運行的全局最優解通過對子魚群最優解進行匯總之后獲得。用人工魚群算法優化K-means算法后在執行速度和加速比以及準確度等方面都有很大改善。
4.6 對數據多次采樣并引入密度法
李歡、劉峰等[26]提出了一種優化思路,即對海量數據通過多次采樣的方式進行聚類個數的確定,再加上用密度法來確定采樣數據聚類中心,原始數據聚類中心通過歸并各樣本中心點的方式得到。在數據集合中,一個數據對象鄰域內其它數據對象越多,距離它的路徑越小,就證明密度越大,則以該數據對象作為聚類中心能很好地反映出數據分布特征[27]。正是由于這一優異特性,因此采用密度法來選擇初始聚類中心。李歡,劉峰等[26]在Hadoop平臺下實施了改進后的算法,通過實驗的方式證明優化后的算法在聚類精度和聚類性能上有了明顯提高。
5 結語
Hadoop和K-means算法都經歷了很長的一段發展時間,它們所具有的獨特優勢使得其被廣大研究者不斷地優化和使用。在互聯網高速發展的今天,將Hadoop與K-means算法相結合,并不斷地對其加以優化是處理當前海量數據的有效途徑。本文介紹的幾種基于Hadoop平臺的K-means算法優化大多是通過引入其它算法對K-means算法的初始聚類中心選取及K值進行改善來實現。將一些能夠彌補K-means算法本身缺點的、高效的算法與K-means算法相結合,并在Hadoop平臺下實現是下一步重點研究方向。
參考文獻:
[1]張石磊,武裝.一種基于Hadoop云計算平臺的聚類算法優化的研究[J].計算機科學,2012,39(s2):115-118.
[2]孫玉強,李媛媛,陸勇.基于MapReduce的K-means聚類算法的優化[J].計算機測量與控制,2016,24(7):272-275.
[3]吳夙慧,成穎,鄭彥寧,等.K-means算法研究綜述[J].現代圖書情報技術,2011(5):28-35.
[4]唐世慶,李云龍,田鳳明,等.基于Hadoop的云計算與存儲平臺研究與實現[J].四川兵工學報,2014(8):97-100.
[5]王宏宇.Hadoop平臺在云計算中的應用[J].軟件,2011,32(4):36-38.
[6]王鑫.基于Hadoop平臺的MapReduce的技術研究[J].信息通信,2015(6):5-6.
[7]向小軍,高陽,商琳,等.基于Hadoop平臺的海量文本分類的并行化[J].計算機科學,2011,38(10):184-188.
[8]謝桂蘭,羅省賢.基于Hadoop MapReduce模型的應用研究[J].微型機與應用,2010,29(8):4-7.
[9]MACQUEEN J.Some methods for classification and analysis of multivariate observations[C].Proc.of Berkeley Symposium on Mathematical Statistics and Probability,1967:281-297.
[10]周愛武,于亞飛.K-Means聚類算法的研究[J].計算機技術與發展,2011,21(2):62-65.
[11]洪月華.蜂群K-means聚類算法改進研究[J].科技通報,2016,32(4):170-173.
[12]李建江,崔健,王聃,等.MapReduce并行編程模型研究綜述[J].電子學報,2011,39(11):2635-2642.
[13]周婷,張君瑛,羅成.基于Hadoop的K-means聚類算法的實現[J].計算機技術與發展,2013,23(7):18-21.
[14]WANG J,YUAN D,JIANG M.Parallel K-PSO based on MapReduce[C].International Conference on Communication Technology,2012:1203-1208.
[15]馬漢達,楊麗娜.基于Hadoop的PSO-KM聚類算法的并行實現[J].信息技術,2015(7):90-94.
[16]朱薔薔,張桂蕓,劉文龍.基于Hadoop平臺上面向電影數據集Kmeans算法的改進[J].哈爾濱師范大學:自然科學學報,2012,28(1):32-36.
[17]毛典輝.基于MapReduce的Canopy-Kmeans改進算法[J].計算機工程與應用,2012,48(27):22-26.
[18]盧勝宇,王靜宇,張曉琳,等.基于Hadoop平臺的K-means聚類算法優化研究[J].內蒙古科技大學學報,2016,35(3):264-268.
[19]KASSELMAN P R.A fast attack on the MD4 hash function[C].COMSIG '97.Proceedings of the 1997 South African Symposium on Communications and Signal Processing,1997:147-150.
[20]張波,徐蔚鴻,陳沅濤,等.基于Hash改進的K-means算法并行化設計[J].計算機工程與科學,2016,38(10):1980-1985.
[21]李紅梅.遺傳算法概述[J].軟件導刊,2009(1):67-68.
[22]戴文華,焦翠珍,何婷婷.基于并行遺傳算法的K-means聚類研究[J].計算機科學,2008,35(6):171-174.
[23]賈瑞玉,管玉勇,李亞龍.基于MapReduce模型的并行遺傳K-means聚類算法[J].計算機工程與設計,2014,35(2):657-660.
[24]鄒康,劉婷,鮑韋韋,等.人工魚群算法研究綜述[J].山西電子技術,2012(2):92-93.
[25]陳書會,周蓮英.基于 MapReduce的afsa-km聚類算法并行實現[J].軟件導刊,2016,15(7):51-54.
[26]李歡,劉鋒,朱二周.基于改進K-means算法的海量數據分析技術研究[J].微電子學與計算機,2016,33(5):52-57.
[27]ERISOGLU M,CALIS N,SAKALLIOGLU S.A new algorithm for initial cluster centers in K-means algorithm[J].Pattern Recognition Letters,2011,32(14):1701-1705.
(責任編輯:孫 娟)
英文摘要Abstract:Today, with the rapid development of science and technology, more and more people pay attention to the problem of massive data processing.The combination of K-means clustering algorithm and Hadoop platform is a reliable way to deal with massive data problems.In this paper, we do a brief introduction about Hadoop and K-means algorithm and parallel implementation of K-means clustering algorithm based on MapReduce.At the same time, we do a introduction and elaboration about several optimization methods of K-means algorithm based on Hadoop platform .Finally, the future research directions are discussed.
英文關鍵詞Key Words: Mass Data Processing;Hadoop;K-means;MapReduce
