基于依存句法分析的復合事實型問句分解方法
2017-07-18 10:53:41張偉男
中文信息學報 2017年3期
劉 雄,張 宇,張偉男,劉 挺
(哈爾濱工業大學 社會計算與信息檢索研究中心,黑龍江 哈爾濱 150001)
基于依存句法分析的復合事實型問句分解方法
劉 雄,張 宇,張偉男,劉 挺
(哈爾濱工業大學 社會計算與信息檢索研究中心,黑龍江 哈爾濱 150001)
問答系統一直以來都是自然語言處理領域的研究熱點之一,然而現有問答系統技術對復合事實型問句的處理效果并不完美。為了增強問答系統理解復合事實型問句的能力,該文提出了一種針對復合事實型問句的分解方法: 使用基于樹核的支持向量機對問句的分解類別進行識別,進而使用基于依存句法分析的方法生成分解結果。實驗結果顯示,在我們所構建的高質量問句分解語料庫中,我們的方法對問句分解類別進行了準確的識別,同時也可以較好地生成嵌套型問句的子問句。
問句分解;復合事實型問句;問句理解;問答系統;自然語言處理
1 引言
問答系統是目前自然語言處理領域中的研究熱點之一,它以精準的答案直接回答用戶以自然語言方式表達的問題。宏觀地來看,問答系統一般由三個主要部分組成: 問題理解、篇章檢索及答案抽取[1]。隨著用戶越來越傾向于輸入自然語言問題作為查詢,問題理解成為了信息檢索和問答系統領域的研究重點之一。
對于用戶輸入的復合型自然語言問題,回答此類復合的問題往往要求問答系統結合多個文檔的內容得出答案,而傳統的問題理解技術(如問題分類[2]、問題主題識別[3]、自動查詢擴展[4]、復述[5]及詞項賦權[6]等)不能夠有效地幫助問答系統處理此類問題。
受TREC(text retrieval conference)評測的影響,問答系統領域通常將問句分為如下幾類: 事實型問句、列表型問句、定義型問句、原因型問句及HOW-TO型問句等。事實型問題關心的是時間、地點、人物及事件等客觀事實,簡單事實型問句的答案通常很短,為包含事實的詞或短語,可以通過其上下文構成的語境從文檔庫中直接抽取得到;復合事實型問句中包含多于一個的簡單事實型問句作為子問句,并且通常具有復雜的修飾限制,最終答案需要分別解答原始問題中包含的各個子問句,并在原始問題的修飾限制條件下綜合各個子問句的答案得到。
在我們的研究過程中,從分解的角度出發,將可分解的復合事實型問句歸為并列類和嵌套類兩類。例如問句“考拉,又叫作樹袋熊,是哪個國家的國寶動物”就是一個并列類的問句,它可以分解成“考拉是哪個國家的國寶動物”和“樹袋熊是哪個國家的國寶動物”兩個并列的子問句,這兩個子問句的答案都是原問句的最終答案;而問句“飛機的發明者是哪國人”則屬于嵌套類,它需要被分解為“飛機的發明者是誰”(其答案為“萊特兄弟”)和“萊特兄弟是哪國人”兩個嵌套的子問句,外層子問句需要得到內層子問句的答案才能進行解答。
復合事實型問句分解技術研究具有如下意義:
(1) 為回答復合事實型問句提供證據支持,增強問答系統的可信度。在問答系統中,通過展示問句分解得到的各個子問句、對應的子問句答案及子問句之間的關系,可以讓用戶了解問答系統解決問題的過程,增加用戶對問答系統的信任度。
(2) 豐富原始問句的語義信息,提高答案準確度。將子問句的答案帶回到原始問句中,可以更加明確原始問句的提問意圖,提高準確回答原始問句的概率。
2 相關工作
總體來說,由于復合問句的分解研究工作在問句理解中是一個新興的研究方向,國內外學者對于復合問句分解技術的研究尚處于初級階段,前人相關的研究工作積累也較少。同時,不同學者所做的研究針對不同的問題類型及數據集,國際上沒有權威機構組織相關工作的評測,這也造成沒有標準問題集可用于不同方法之間的比較,無法直接比較各種方法的優劣。
IBM公司研發的沃森機器人在美國益智問答游戲節目“危險邊緣(Jeopardy!)”中大勝優秀的人類選手而聞名全球,Deep QA項目是沃森背后的主要問答框架。IBM的研究團隊在其論文[7]中介紹了他們在問句分解方面的工作: 與本文分類體系類似地,他們將節目中的線索句分成并行類和嵌套類,對這兩類問題應用不同的方法進行檢測和分解,通過對復合事實型問句的分解,沃森在“Jeopardy!”決賽問題集上的準確率提高了1.5%。
START問答系統是美國麻省理工學院研究開發的世界上第一個面向網絡的問答系統,自1993年12月上線連續運行至今。其領導者Boris Katz教授在其論文[8]中闡述了他們在START系統中所應用的三種問句分解策略: 基于語言學知識的句法分解策略、基于詳盡語言描述內容的語義分解策略,以及將問句和資源內容同時分解成斷言的策略。
社區問答系統(community question answering, CQA)是近年來互聯網上蓬勃發展的問答服務,已經積累了許多高質量問答資源。Liu等人在其論文[9]中針對CQA問答資源提出一套分類體系,并從不同的答案資源中抽取自動摘要,以回答用戶所提出問題中的不同部分。這也可以看作是問句分解在社區問答系統中的一次應用探索。
現有相關研究均證明了: 通過對復合問句的分解,識別子問句之間的關系,可以提高這些問答系統回答復合問題的能力。在用戶查詢從關鍵詞過渡到復雜自然語言的趨勢下,分解復合問句將在問句理解模塊中占據重要的位置。
3 基于樹核及依存句法分析的問句分解方法
由于問句分解是問答系統中一個新興的任務,前人的經驗和積累都很少。因此,作為研究的第一步,我們需要收集相應的復合事實型問句集合,制訂詳盡的標注規則,以構建高質量的問句分解語料庫,作為進一步研究的基礎。
在構建語料庫的過程中,我們總結歸納出了復合事實型問句的三種分解類型,分別是原子類(atomic)、并列類(parallel)及嵌套類(nested)。對問句的分解類別進行識別是問句分解中的一個必要步驟,它可以在兩方面幫助我們完成問句分解的任務: 一方面,不同的分解類別表示了不同子問句之間的關系: 在并列類問句中,各個子問句之間獨立互斥,而在嵌套類問句中,外層子問句的解答需要依賴于內層子問句的答案;另一方面,并列類問句和嵌套類問句在句法結構等語言學特征上存在明顯的差異,準確地識別這兩種類型可以給子問句序列生成以指導信息,讓我們在后續分解時做到有的放矢。
借助于分解類別識別結果的指導信息,我們可以對不同類型的問句訓練不同的機器學習模型。我們的子問句生成方法借鑒了自然語言處理中句法分析的工作,將子問句生成的過程融入到句法分析器生成句法樹的過程中,以完成對復合事實型問句的分解工作。
本章將從語料標注規則、分解類別識別及子問句生成三個方面來闡述我們的復合事實型問句分解方法。
3.1 語料標注規則
為了規范問句分解的標注過程,縮小不同標注者主觀意見所帶來的標注差別,我們設定了詳細的標注規則,一條數據的標注格式定義如圖1所示。

圖 1 問句分解數據標注格式
如圖 1 所示,一條問句分解數據的標注結果由“問句編號”“問句分詞結果”“分解類別”及“子問句序列”四部分組成,并由符號“|”作為這四部分之間的分隔符。
問句分詞結果是由若干詞項組成的序列,詞項與詞項之間以空格符號分隔,在每個詞項中,由“-”連接詞語序號和詞語內容,詞語序號從“0”開始計數。
為了區分不同的問句分解類別,我們設定了三個類: “ATOMIC”“PARALLEL”“NESTED”,分別對應了原子類、并列類及嵌套類。
子問句序列由符號“=”連接詞語序號序列及子問句答案代號組成。詞語序號序列由空格連接若干詞語序號組成,以表示子問句。此外,若該問句為嵌套類,且當前子問句非最“內層”子問句,則可以插入適當的子問句答案代號,使當前子問句更通順。
圖 2 展示了問句分解標注的一個具體實例,它是語料庫中的第25號問句,問句具體內容分詞后的結果為“在/我國/可/兌換/的/國際/通用/外幣/中/,/最/值錢/的/是/哪個/幣種”,它的分解類別被標注為“NESTED”(即嵌套類)。第一個子問句的內容為“我國/可/兌換/的/國際/通用/外幣”,其答案為一個列表,用代號“LIST0”表示;第二個子問句的內容為“在/LIST0/中/,/最/值錢/的/是/哪個/幣種”,其答案為原問句的最終答案,以代號“ANS”表示。

圖 2 問句分解標注示例
3.2 基于樹核的分解類別識別
如前所述,原子類、并列類及嵌套類構成了我們的問句分解類別體系。
不同分解類別的問句主要差異體現在句法結構上,因此我們在進行分解類別識別的過程中使用的方法主要從問句的句法結構特征出發。句法分析器是一種廣泛應用于自然語言處理各個任務的工具,它們能夠提供句子的句法結構信息;樹核通過子結構的重合度來度量兩個句法樹的結構相似度,被成功地應用于問題分類的任務中。我們應用了此類基于樹核的方法[10]來進行問句分解類別識別的工作。
樹核的定義公式如式(1)所示,用兩棵句法樹中以各個節點為根的子樹中相同的子結構數目來度量這兩棵句法樹的相似度。計算時我們定義不同的子結構,則可以得到如下四種不同的樹核空間。
(1) 子樹(subtree,ST)空間: 樹T中的任意節點及該節點所有后代節點可組成樹S,則S為T的一棵子樹,ST空間直接用子樹作為子結構。
(2) 子集樹(subset tree,SST)空間: SST與ST大致相同,唯一的不同在于: 在SST中,原樹中的非終結符可以作為子結構的葉子節點,而在ST中,原樹中的非終結符是不可以作為葉子結構子節點的。
(3) 子集樹—詞袋(SST-BOW)空間: 在SST的基礎上,進一步比較子結構中葉子節點上的標記符,若兩者葉子節點上的標記符相同,則相似度增加。
(4) 部分樹(partial tree,PT)空間: PT在SST的基礎上進一步放松了控制,允許子結構只使用語法生成規則一部分,而之前ST和SST中的子結構均需遵守語法完整的生成規則。
我們采用支持向量機作為分類器,將樹核作為支持向量機中的核方法,對不同的分解類別進行識別。
3.3 基于依存句法分析的子問句生成
在子問句生成的過程中,借鑒依存句法分析的工作,我們保留了依存句法樹的整體結構,而將樹中邊上的依存關系標簽改為表征問句分解信息的分解標簽。這樣做的優點在于: (1)保留了原句法樹的結構,可提供句法結構信息;(2)前人已經積累了許多優秀的依存句法分析方法,這些方法都可以被用到子問句生成的過程中。
表征問句分解信息的分解標簽可以根據標注結果自動地生成,其生成過程簡潔明了,可以看作一個二進制編碼的過程: 對于問句中的每個詞語,如果該詞語出現在某層的子問句中,則對應的二進制編碼置為1;若該詞語在某層子問句中未出現,則對應的二進制編碼置為0;將二進制編碼轉換為十進制數即得到所對應的分解標簽。例如在圖 2的標注結果中,共有兩層的子問句,則每個詞語的二進制編碼有兩位,對于該問句的最后一個詞“幣種”,它在第一層子問句中并未出現,僅出現在第二層子問句中,其二進制標簽為“10”,轉換為十進制標簽為“2”。圖 3 展示了圖 2標注結果轉化后的句法樹。

圖 3 帶有問句分解標簽依存句法樹
我們使用了基于圖的依存分析方法訓練面向問句分解的依存句法分析器。基于圖的依存句法分析方法由McDonald首先提出[11],他將依存分析問題化歸為在一個有向圖中尋找最大生成樹的問題。
式 (2)定義了句子x所對應的依存句法樹y的得分,其中f(i,j)是詞i與詞j之間依存關系的特征向量,而w則為對應的權重向量。在我們面向問句分解的依存句法分析器中,主要從當前詞、父親節點詞、子節點詞及孫子節點詞的詞性、樹結構中抽取特征組成特征向量f,使用感知器算法訓練權重向量w,使用高階的Eisner算法進行解碼[12]。
4 實驗結果及討論
4.1 語料庫構建結果及評價
我們收集了江蘇衛視《一站到底》欄目從2012年3月至2013年1月共91期節目中提問的約 8 500個復合事實型問句,以純文本保存。
在標注過程中,我們先讓三位標注者同時標注了前1 000個問句,以期標注人員可以熟悉并理解所制定的標注規則,并對標注規則的認知達成一致。至于剩余約7 500個問句,則分別派給三位標注者2 500個問句進行標注。
我們對三位標注者前1 000句的標注一致性進行了評價,評價的標準采用了常用的Fleiss’ Kappa值[13]。
對于分解類別(即ATOMIC、PARALLEL和NESTED)的標注,三位標注者的一致性達到了0.779 251,在Fleiss’ Kappa的評價類別里達到了第二檔。
對于子問句序列的標注,我們同樣也做了評價。在評價時,我們將標注問題看成對每個詞的二分類問題,即該詞是否出現于某子問句中。根據這樣的評價方法,三位標注者的子問句序列標注一致性達到了0.697 617,同樣達到了Fleiss’ Kappa評價類別中的第二檔。
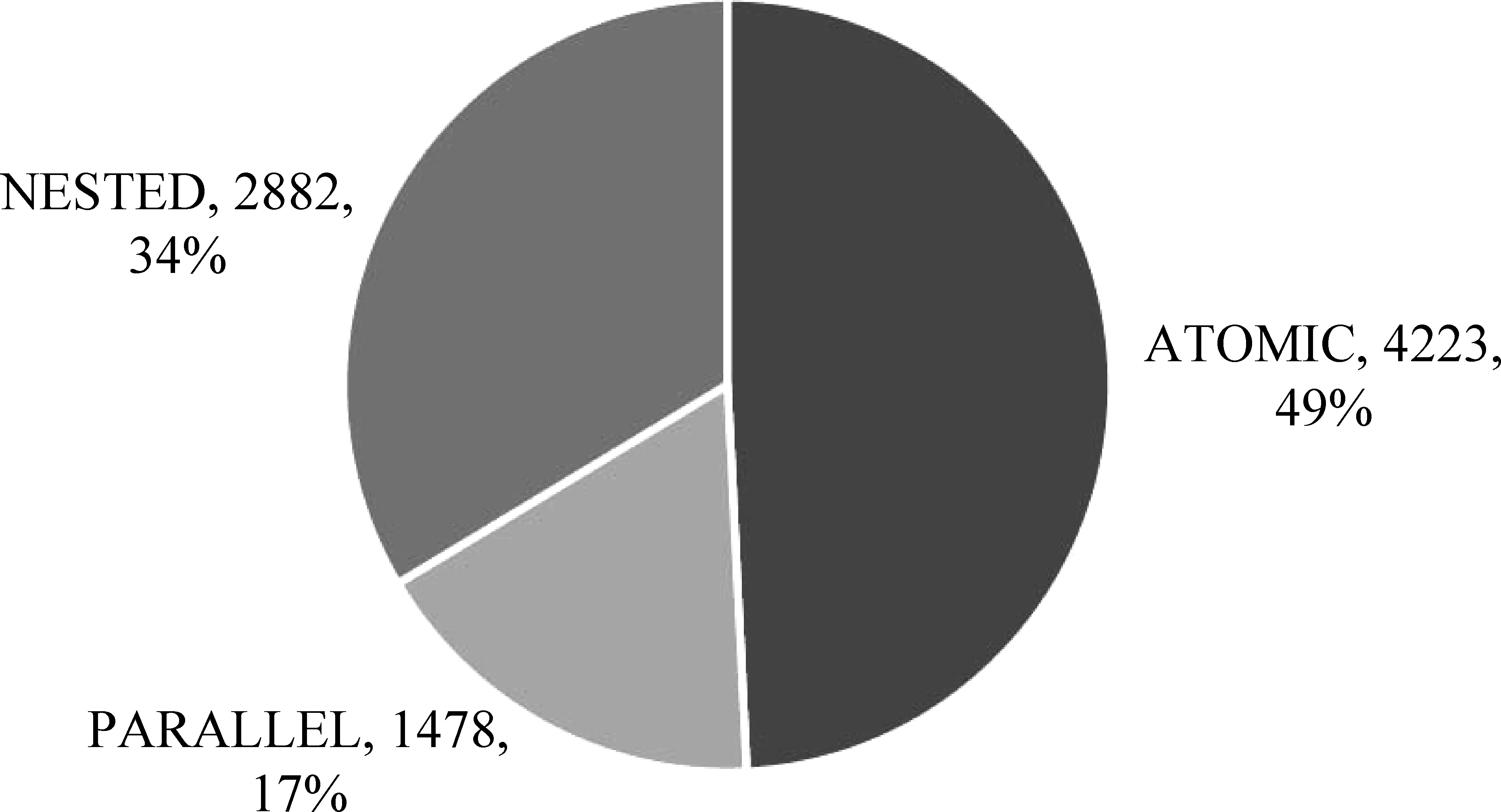
圖 4 分解類別占比分布
為了解分解類別分布,我們也對其進行了統計,統計結果如圖 4 所示。在我們所標注的8 500多句中,不可分解的問句占比49%,略少于一半;而可分解的問句占比51%,略多于一半。進一步地觀察,在可分解的問句中,嵌套類問句占比三分之二,而并列類問句占比三分之一。
4.2 分解類別識別的實驗結果
為了驗證句法結構信息在問句分解類別識別過程中的作用,在實驗中我們使用了如下六種樹結構。
(1) 短語句法樹(constituency tree,CT): 此類句法樹遵循短語結構句法,樹的內部節點均為句法節點,而葉子節點均為詞語節點。
(2) 詞語中心句法樹(lexical centered tree,LCT): 此類句法樹由依存句法樹轉化得到,以詞語作為中心節點,將對應的語法關系和詞性作為添加到詞語中的孩子節點。
(3) 詞性中心句法樹(postag centered tree,PCT): 此類句法樹在保留依存句法結構的基礎上,以詞性節點作為中心,將對應的語法關系節點作為其父親節點,而對應的詞語節點作為孩子節點。
(4) 語法關系中心句法樹(grammatical relation centered tree,GRCT): 此類句法樹同樣保留了依存句法的結構,但它們以語法關系節點作為中心,分別將詞性節點和詞語節點作為語法關系節點的孩子節點和孫子節點。
(5) 詞語詞性序列樹(lexical and postag sequence tree,LPST): 此類樹忽略了問句的句法結構,直接將詞語節點和詞性節點依次添加到樹的根節點。
(6) 詞語序列樹(lexical sequence tree,LST): 此類樹忽略了問句的句法結構,直接將詞語節點依次添加到樹的根節點中。
在實驗中,上述句法樹中的短語結構句法樹均使用Stanford Parser[14]自動分析生成,而依存句法結構樹均使用哈爾濱工業大學語言技術平臺[15](language technology platform,LTP)自動分析生成。
基于樹核的問句分解類別識別實驗結果如表 1~表 4 所示,表中不同行表示不同的樹核空間,而不同列表示不同的樹結構。我們采用了三種問句分解類型(即ATOMIC、PARALLEL和NESTED)的F1值,以及總體的分類準確率(ACC)作為實驗的評價指標,各個指標均是在整個語料庫上做了五次交叉驗證后取平均值計算得到的。
觀察表中結果我們可以看到,整體表現最好的句法樹為短語句法樹(CT),在四個評價指標上,均是使用短語句法樹結構的組合取得了最優效果。而在由依存句法樹轉換得到的三種樹結構中,語法關系中心樹(GRCT)的表現更好,與CT的表現基本相當。這是由于短語句法比依存句法稍簡單,短語句法樹生成的準確率稍高。
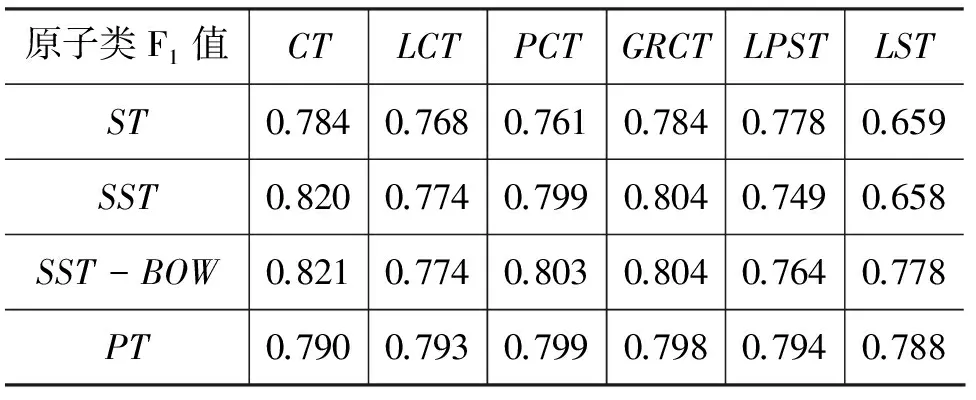
表1 原子類問句識別F1值
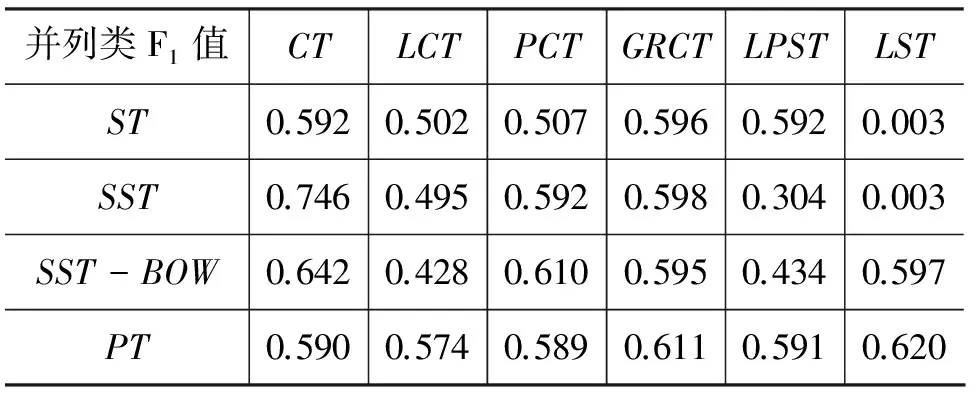
表 2 并列類問句識別F1值

表 3 嵌套類問句識別F1值

表 4 分解類型識別整體分類準確率(ACC)
而從樹核空間上來講,SST及其改進版SST-BOW較ST及PT表現更加優異。這說明對于我們的任務,SST比較子結構時的限制程度剛好,而ST限制過緊,PT限制過松。
LST+SST及LST+ST兩個組合在識別PARALLEL類和ATOMIC類的時候完全失效,其原因在于LST直接將樹扁平化,忽略了問句的句法結構信息,這進一步說明了句法結構信息在問句分解類別識別任務中起到了關鍵的作用。
另一個發現是,除了在CT+SST的組合中,PARALLEL類的F1值略高于NESTED類的F1值以外,在其余的句法樹和樹核空間的組合里,關于三種問句分解類型F1值的排序均是ATOMIC>NESTED>PARALLEL,這反映了三種不同分解類別的識別難度。
4.3 子問句生成的實驗結果
我們對語料庫中嵌套類及并列類的問句分別進行了實驗,實驗結果如表 5 所示,表中的數據均由10次交叉驗證得到。
每類實驗分為兩組: 一組為生成第一層子問句,對于原問句中的每個詞語,只需判斷其是否出現在第一層子問句中,因此分解標簽數目均為2;另一組生成完整的子問句序列,句子中的每個詞語可出現在若干層子問句中,因此分解標簽數目有所增加,其中嵌套類的標簽數目為7,而并列類的標簽數目為13。

表 5 基于依存句法分析的復合子問句生成實驗結果
評價時我們引入了評價依存句法分析器常用的兩個指標: UAS(unlabeled attachment score)和LAS(labeled attachment score)。在實驗結果中,嵌套類UAS都高于85%,并列類UAS均在80%左右,說明我們的方法可以很好地保留句子的句法結構信息;嵌套類LAS處于70%左右,可以為子問句生成提供有效指導,而并列類LAS在50%左右,相對較低。
同時,為了實際檢驗子問句生成的效果,我們將生成的子問句詞序列與標注的子問句詞序列進行了比較以得到準確率,同時使用編輯距離作為容忍度。我們的實驗在嵌套類問句集合上取得了不錯的效果: 在容忍度為2的條件下,兩組實驗的準確率為60%左右;在容忍度為1的條件下,準確率為47%左右;在精確比較的條件下,子問句生成的準確率也有28%。
通過觀察發現,我們的方法在并列類問句上取得的效果在各個比較維度上都弱于嵌套類。通過觀察實際的分解結果我們做出了如下的分析: 嵌套類問句的分解比較“立體”,子問句通常分布在一個較大的子樹中;而并列類問句的分解則比較“扁平”,分解時通常需要將以頓號或連詞等連接的若干并列成分放入不同的子問句中,而這些并列成分在句法分析時會分布在同一棵子樹下。我們的分解方法基于依存句法分析的過程,更加適合嵌套類問句的特點,因此在嵌套類的問句上取得的效果更佳。
進一步地,我們還和前人的工作[16]進行了比較,結果如表 6 所示。前人工作分解的目標是問句中的一個隱含事實(可視為子問句的不同表達),使用了人工定義的句法模板生成候選,然后進一步使用語言模型對候選進行排序。通過比較可以發現,我們的工作使用了規模更大的語料,分解得也更準確。

表 6 與前人的工作進行比較
5 結論及未來工作
從增強問答系統理解復合事實型問句能力的角度出發,本文提出了基于依存句法分析的問句分解方法,并從問句分解語料庫構建、問句分解類別識別及子問句生成三個方面闡述了復合事實型問句分解的研究工作。最終,我們構建了高質量的問句分解語料庫,對問句分解類別進行了準確的識別,并能較好地生成嵌套型問句的子問句。
盡管我們當前的方法可以較好地解決部分問句分解的問題,但是對于并列類的復合問句仍有部分問題亟待解決。同時,在問答系統中如何高效地利用問句分解的結果,以期獲得更高質量的答案,也是未來的研究方向之一。
[1] Ferrucci David, Brown Eric, Chu-Carroll Jennifer, et al. Building Watson: An Overview of the DeepQA Project[J]. AI Magazine, 2010, 31(3): 59-79.
[2] Bu Fan, Zhu Xingwei, Hao Yu, et al. Function-based question classification for general QA[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2010: 1119-1128.
[3] Duan Huizhong, Cao Yunbo, Lin Chin-Yew, et al. Searching Questions by Identifying Question Topic and Question Focus.[C]//Proceedings of Annual Meeting of the Association for Computational Linguistics Human Language Tchnologies. 2008: 156-164.
[4] Carpineto Claudio, Romano Giovanni. A Survey of Automatic Query Expansion in Information Retrieval[J]. ACM Computing Surveys, ACM, 2012, 44(1): 1-50.
[5] Androutsopoulos Ion, Malakasiotis Prodromos. A Survey of Paraphrasing and Textual Entailment Methods[J]. Journal of Artificial Intelligence Research, 2010: 135-187.
[6] Zhang W, Ming Z, Zhang Y, et al. The Use of Dependency Relation Graph to Enhance the Term Weighting in Question Retrieval.[C]//COLING. 2012: 3105-3120.
[7] Kalyanpur Aditya, Patwardhan Siddharth, Boguraev Branimir K, et al. Fact-based question decomposition in DeepQA[J]. IBM Journal of Research and Development, 2012, 56(3,4): 13: 1-13: 11.
[8] Katz Boris, Borchardt Gary, Felshin Sue. Syntactic and Semantic Decomposition Strategies for Question Answering from Multiple Resources[C]//Proceedings of the AAAI 2005 workshop on inference for textual question answering. 2005: 35-41.
[9] Liu Y, Li S, Cao Y, et al. Understanding and summarizing answers in community-based question answering services[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2008: 497-504.
[10] Croce Danilo, Moschitti Alessandro, Basili Roberto. Structured Lexical Similarity via Convolution Kernels on Dependency Trees[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 1034-1046.
[11] McDonald Ryan, Pereira Fernando, Ribarov Kiril, et al. Non-projective Dependency Parsing using Spanning Tree Algorithms[C]//Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing. Morristown, NJ, USA: Association for Computational Linguistics, 2005: 523-530.
[12] Che Wanxiang, Li Zhenghua, Li Yongqiang, et al. Multilingual Dependency-based Syntactic and Semantic Parsing[C]//Proceedings of the Thirteenth Conference on Computational Natural Language Learning: Shared Task. Association for Computational Linguistics, 2009: 49-54.
[13] Fleiss Joseph L. Measuring Nominal Scale Agreement among Many Raters.[J]. Psychological Bulletin, 1971, 76(5): 378-382.
[14] Socher Richard, Bauer John, Manning Christopher D, et al. Parsing With Compositional Vector Grammars[C]//Proceedings of the 51th Annual Meeting of the Association for Computational Linguistics. 2013.
[15] Che Wanxiang, Li Zhenghua, Liu Ting. LTP: a Chinese Language Technology Platform[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Demonstrations. Association for Computational Linguistics, 2010: 13-16.
[16] 張健. 問答系統中問題拆分技術研究[D]. 哈爾濱工業大學碩士學位論文, 2013.
ADecompositionMethodforComplexFactoidQuestionsBasedonDependencyParsing
LIU Xiong, ZHANG Yu, ZHANG Weinan, LIU Ting
(Research Center for Social Computing and Information Retrieval, Harbin Institute of Technology, Harbin, Heilongjiang 150001,China)
Question answering systems have been one of the hot research areas of natural language processing for a long time. To enhance the ability of analyzing complex factoid questions in question answering systems, we presented a novel method to decompose complex factoid questions: using a tree kernel based support vector machine to recognize decomposition categories of questions, and generating decomposition results with a dependency parsing based method. The evaluation shows that based on the high quality question decomposition corpus we had built, our method recognizes question decomposition categories with high performance and generated sub-question series with high quality, especially for the nested-typeones.
question decomposition; complex factoid question; question analysis; question answering system; natural language processing

劉雄(1990—),碩士,主要研究領域為自然語言處理、問答系統。

張宇(1972—),博士,教授,主要研究領域為信息檢索、問答。

張偉男(1985—),博士,講師,主要研究領域為聊天機器人、對話系統。
1003-0077(2017)03-0140-07
2015-12-11定稿日期: 2016-02-19
國家自然科學基金(61472105)
TP391
: A
