基于互信息的加權(quán)樸素貝葉斯文本分類算法①
2017-07-19 12:27:20武建軍李昌兵
計算機系統(tǒng)應(yīng)用 2017年7期
武建軍, 李昌兵
(重慶郵電大學(xué), 重慶 400065)
基于互信息的加權(quán)樸素貝葉斯文本分類算法①
武建軍, 李昌兵
(重慶郵電大學(xué), 重慶 400065)
文本分類是信息檢索和文本挖掘的重要基礎(chǔ), 樸素貝葉斯是一種簡單而高效的分類算法, 可以應(yīng)用于文本分類. 但是其屬性獨立性和屬性重要性相等的假設(shè)并不符合客觀實際, 這也影響了它的分類效果. 如何克服這種假設(shè), 進(jìn)一步提高其分類效果是樸素貝葉斯文本分類算法的一個難題. 根據(jù)文本分類的特點, 基于文本互信息的相關(guān)理論, 提出了基于互信息的特征項加權(quán)樸素貝葉斯文本分類方法, 該方法使用互信息對不同類別中的特征項進(jìn)行分別賦權(quán), 部分消除了假設(shè)對分類效果的影響. 通過在UCIKDD數(shù)據(jù)集上的仿真實驗, 驗證了該方法的有效性.
樸素貝葉斯; 文本分類; 互信息; 加權(quán); 特征項
隨著互聯(lián)網(wǎng)的不斷發(fā)展, 互聯(lián)網(wǎng)已經(jīng)滲透到各行各業(yè)中, 而伴隨著電子商務(wù)、自媒體、社交網(wǎng)絡(luò)等概念和技術(shù)的出現(xiàn)和發(fā)展, 互聯(lián)網(wǎng)每天都會產(chǎn)生巨大的信息, 大數(shù)據(jù)時代已經(jīng)到來. 在這些信息中主要是文本數(shù)據(jù), 如何對這些數(shù)據(jù)進(jìn)行管理, 并進(jìn)行分析和文本挖掘已成為一個重要的研究領(lǐng)域.
文本分類是對文本進(jìn)行分析和挖掘的基礎(chǔ). 分類任務(wù)就是通過學(xué)習(xí)得到一個目標(biāo)函數(shù), 即分類模型y=f(x), 通過此分類模型把每個屬性集x映射到一個預(yù)先定義的分類標(biāo)簽y[1]. 文本分類是在預(yù)定義的分類體系下, 根據(jù)文本的內(nèi)容得到文本的特征項, 并將給定文本與一個或多個類別相關(guān)聯(lián)的過程[2]. 文本自動分類可以很好的地解決大量文本信息自動歸類的問題, 并可以應(yīng)用于郵件過濾、文獻(xiàn)組織、文本識別等領(lǐng)域. 因此, 對文本分類的研究具有重要的理論意義和實用價值.
樸素貝葉斯分類方法基于“屬性獨立性假設(shè)”, 是一種基于概率統(tǒng)計的分類方法, 適合于處理屬性個數(shù)較多的分類任務(wù), 而文本分類正是這種多屬性的分類任務(wù), 因此樸素貝葉斯成為文本分類的一種常用分類方法. 樸素貝葉斯分類方法不僅簡單有效, 而且其性能在某些領(lǐng)域中表現(xiàn)得很好[3,4], 成為文本分類算法的重點研究對象之一.
樸素貝葉斯分類假定屬性之間是相互獨立的且重要性相同. 但是, 現(xiàn)實中這種假設(shè)通常是不成立的. 為了保證其分類效果, 許多學(xué)者對改進(jìn)樸素貝葉斯分類器的屬性加權(quán)方法做了一些嘗試, 繼Ferreira[5]提出屬性加權(quán)的模型架構(gòu)之后, Zhang[6]提出了基于增益比的屬性加權(quán)方法, 鄧維斌[7]提出了一種基于粗糙集的屬性加權(quán)方法, Hall[8]提出了一種基于決策樹的屬性加權(quán)方法, ANGLEY[9]提出了一種基于屬性刪除方法的選擇貝葉斯分類器(Selective Na?ve Bayesian, SNB),ARRY[10]提出了加權(quán)樸素貝葉斯(Weighted Na?ve Bayes, WNB)模型, 即根據(jù)屬性的重要程度給不同屬性賦不同權(quán)重的, 并通過實驗發(fā)現(xiàn)它們能改進(jìn)樸素貝葉斯的分類效果[9,10]. 但是這些都是對樸素貝葉斯算法的改進(jìn), 沒有考慮貝葉斯算法應(yīng)用到文本分類中的情況.
本文通過對文本分類的研究, 利用互信息的理論,研究如何使用屬性加權(quán)來改進(jìn)樸素貝葉斯算法, 在文本分類中, 通過使用特征項相對于類別的互信息作為特征項權(quán)重, 提出了基于互信息的特征項加權(quán)樸素貝葉斯文本分類算法, 以消除屬性重要性相等的假設(shè)對分類效果的影響, 提高樸素貝葉斯文本分類算法的分類效果.
1 互信息的相關(guān)概念
文本分類時首先要對待分類的文本進(jìn)行預(yù)處理,提取特征項. 在預(yù)處理過程中, 因為一篇文章提取出的特征項往往非常多, 而很多詞是對表達(dá)該文章是無意義的, 需要做降維處理, 特征選擇和特征提取[11,12]是兩類主要的特征項降維的方法. 互信息(MI)是一種特征選擇算法, 用來表征兩個變量之間的相關(guān)性. 特征項w和類別Cj之間的互信息MI(w, Cj)定義如下:
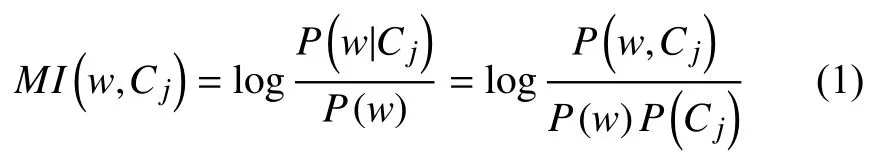
P(w)表示特征項w在整個訓(xùn)練集出現(xiàn)的概率,P(Cj)表示訓(xùn)練集中Cj類文檔出現(xiàn)的概率, P(w, Cj)表示類別Cj中含有特征項w的概率.
當(dāng)w和類別Cj無關(guān)時, 互信息為0;當(dāng)特征項的出現(xiàn)依賴于某個類別時, 該特征項與該類別的MI 值就會很大;當(dāng)特征項在某個類別很少出現(xiàn)時, 它們的MI值會很小, 甚至為負(fù)數(shù). 通過設(shè)定互信息的閾值, 可以實現(xiàn)對特征項的選擇, 從而實現(xiàn)特征項降維處理.
2 樸素貝葉斯分類算法
樸素貝葉斯分類算法基于貝葉斯公式. 它的基本原理是: 在已知類的先驗概率和該類中每個屬性所有取值的條件概念的情況下, 可以計算出待分類樣本屬于某個類別的條件概率, 從中選擇條件概率最大的作為該樣本的分類.
假設(shè)共有m個類, C={C1, C2, …, Cm}, j=1, 2, …, m,以P(Cj)表示Cj類發(fā)生的先驗概率, 且P(Cj)>0. 對于任一文檔di={w1, w2, …, w|V|}, i=1, 2, …, l, 其中, wk為特征項, k=1, 2, …, |V|, |V|為特征項總個數(shù), Cj類中di條件概率是P(di|Cj), 則計算文檔di屬于Cj類的后驗概率為:
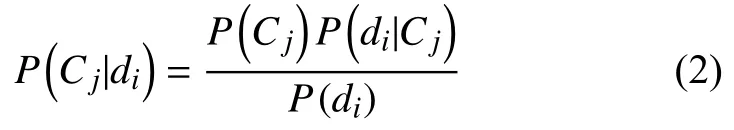
由于P(di)是一個常數(shù), 并且基于屬性獨立性假設(shè)P(d|C)=P(w1|C)P(w2|C)…P(wn|C), 故有:
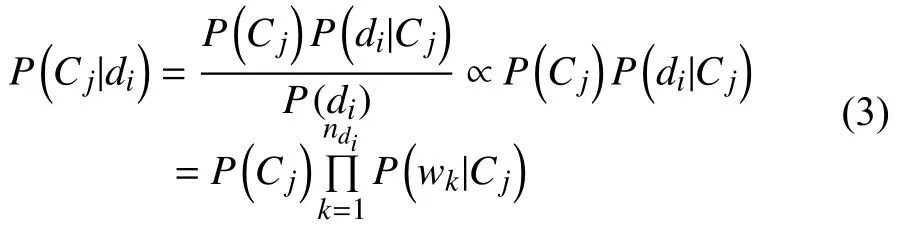
P(wk|Cj)是特征項wk出現(xiàn)在Cj類中的后驗概率,ndi是文檔di中特征項的個數(shù). 樸素貝葉斯分類的目標(biāo)是尋找“最佳”的類別. 最佳類別是指具有最大后驗概率(maximum a posteriori -MAP)的類別cmap:
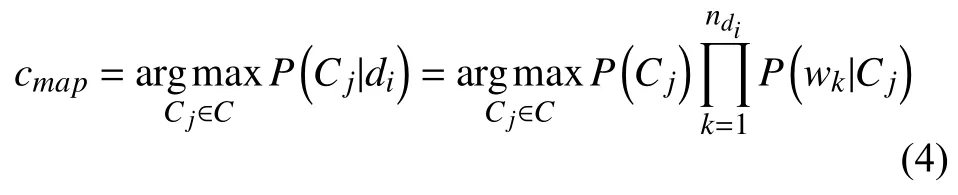
其中, Cj類的先驗概率P(Cj)可以通過公式P(Cj)=Ncj/N取得, Ncj表示訓(xùn)練集中Cj類中的文檔數(shù)目, N表示訓(xùn)練集中所有文檔數(shù)據(jù). P(wk|Cj)可以通過以下公式得出:
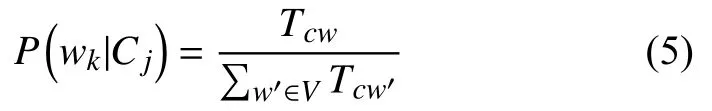
Tcw是訓(xùn)練集中類別Cj中的特征項wk的次數(shù) (多次出現(xiàn)要計算多次),是類別Cj中所有特征項出現(xiàn)的總次數(shù). 為了避免零概率問題, 需要對上述公式進(jìn)行平滑處理:
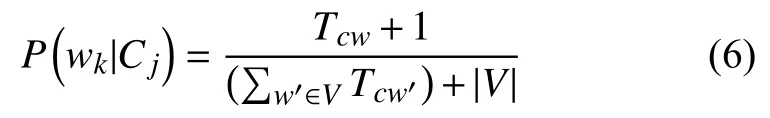
|V|為不同特征項的個數(shù).
由于很多小概率的乘積會導(dǎo)致浮點數(shù)下溢出, 可以通過取對數(shù)將原來的乘積計算變成求和計算, 對應(yīng)的公式為:

3 加權(quán)樸素貝葉斯分類算法
樸素貝葉斯認(rèn)為所有特征項對于文檔的分類重要性都是一致的, 但現(xiàn)實中每個特征項的重要性是不一樣的. 因此, 可以根據(jù)特征項的重要程度給不同的特征項賦不同的權(quán)值, 即加權(quán)樸素貝葉斯分類算法, 其模型為:
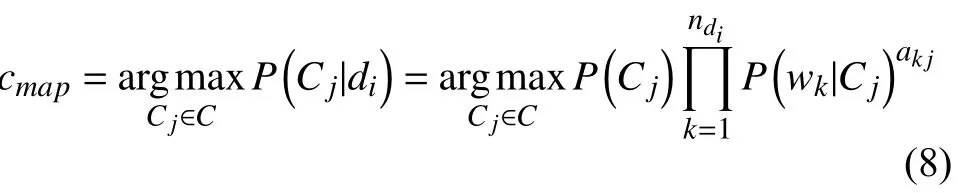
ak,j表示特征項wk在Cj類中的權(quán)重. 屬性的權(quán)值越大, 該屬性對分類的影響就越大. 其對數(shù)形式為:
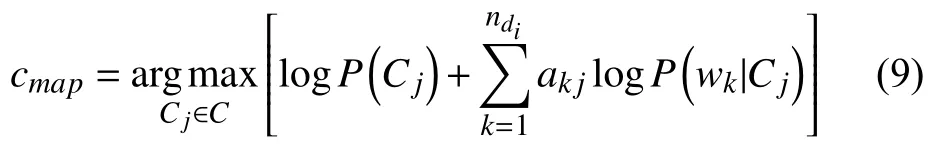
4 特征項加權(quán)的樸素貝葉斯分類算法
在實際情況中, 特征項與類別之間必然存在某種關(guān)聯(lián)關(guān)系, 而樸素貝葉斯算法為了簡化計算過程, 忽略了這種關(guān)聯(lián), 降低了分類的效果. 可以通過某種方式量化特征項與類別之間的關(guān)聯(lián)關(guān)系, 以此值作為該特征項出現(xiàn)在類中條件概率的權(quán)值, 以反映不同特征項的重要程度, 這樣有利于提升樸素貝葉斯的分類效果.
互信息MI作為一種特征選擇的算法, 用來表示特征項w和類別c之間相關(guān)性. 用互信息MI作為后驗概率P(wk|Cj)的權(quán)重非常合適, 因為與類別相關(guān)性大的特征項, 其權(quán)重就應(yīng)該更大一些;當(dāng)特征項與類別不相關(guān)時, MI為0, 表示該特征項的后驗概率P(wk|Cj)對分類不起作用;當(dāng)特征項很少出現(xiàn)在某個類別時, MI是負(fù)數(shù),表示該特征項是噪聲, 對分類產(chǎn)生了負(fù)作用. 使用互信息MI作為權(quán)重, 體現(xiàn)了不同特征項的對分類的作用不同, 在很大程度上消除了屬性獨立性假設(shè)對分析產(chǎn)生的影響, 使分類效果更好. 根據(jù)互信息的計算過程, 特征項wk對類別Cj的權(quán)重可以表示為:
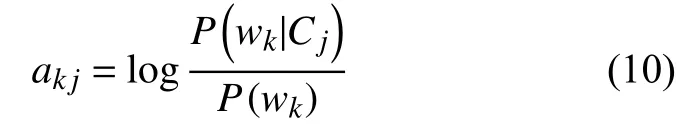
代入公式9得到加權(quán)的樸素貝葉斯算法:
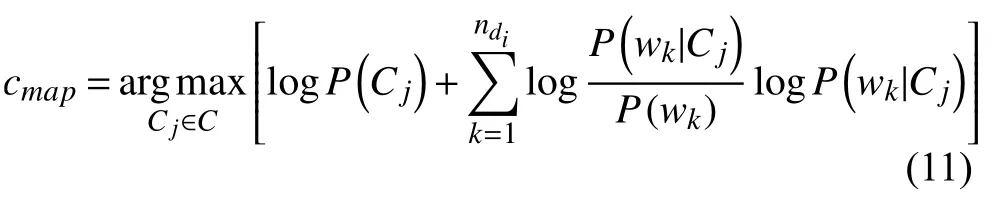
Cj類的先驗概率P(Cj)以及特征項wk出現(xiàn)在Cj類中的后驗概率P(wk|Cj)前面已經(jīng)給出了計算公式, 而P(wk)表示特征項wk的先驗概率, 可以通過以下公式得出:
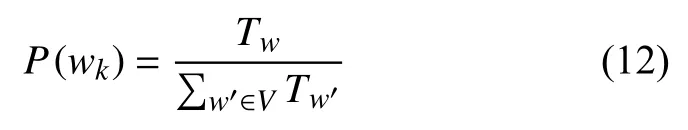
Tw是訓(xùn)練集中特征項wk在所有類別中出現(xiàn)的次數(shù)(多次出現(xiàn)要計算多次),是訓(xùn)練集中所有特征項出現(xiàn)的總次數(shù). 為了避免零概率問題, 需要對上述公式進(jìn)行平滑處理:
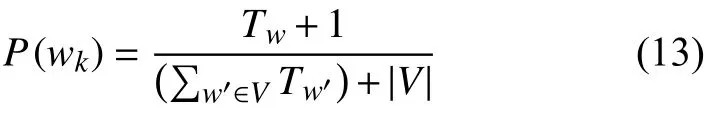
|V|為訓(xùn)練集中不同特征項的個數(shù).
為了建立特征項加權(quán)樸素貝葉斯分類器, 首先需要利用訓(xùn)練樣本進(jìn)行模型訓(xùn)練, 通過計算得到每個特征項的條件概率及其權(quán)重, 然后通過測試樣本對建立的模型進(jìn)行驗證. 分類器的實現(xiàn)步驟如下:
步驟1. 數(shù)據(jù)預(yù)處理: 將訓(xùn)練樣本和待分類樣本進(jìn)行分詞、去停用詞.
步驟2. 文本向量化: 把文本轉(zhuǎn)換為VSM(向量空間模型), 文本di表示為一個空間向量: di={w1, w2, …,w|V|}, i=1, 2, …, l, 其中, wk為特征項, k=1, 2, …, |N|,|N|為特征項總個數(shù).
步驟3. 特征選擇: 計算每個特征項wk與每個類別Cj的互信息MI, 并根據(jù)MI值進(jìn)行特征選擇, 得到一個MI矩陣:
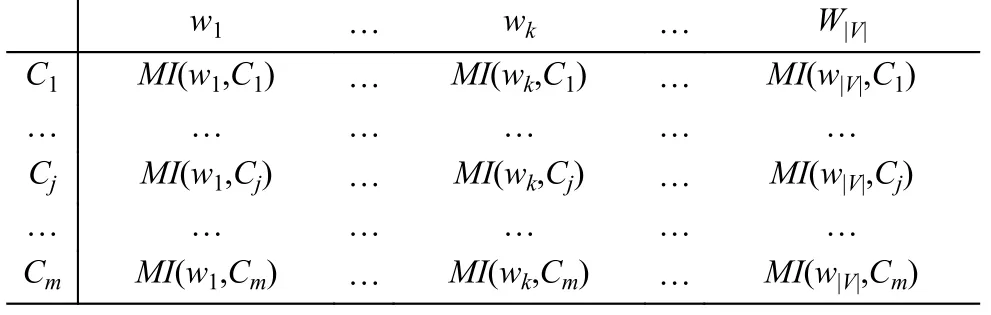
其中MI(wk, Cj)表示特征項wk與類別Cj的互信息.
步驟4. 分類器構(gòu)造:
步驟4.1 掃描所有訓(xùn)練樣本, 統(tǒng)計訓(xùn)練集中文檔總數(shù), 每個類別文檔總數(shù), 每個特征項在每個類別出現(xiàn)的次數(shù), 以及不同特征項的個數(shù), 形成統(tǒng)計表.
步驟4.2 計算每個類別Cj的先驗概率P(Cj), 得到先驗概率向量P(C){P(C1), P(C2), …, P(Cm)}
步驟4.3 計算每個特征項wk出現(xiàn)在Cj類中的后驗概率P(wk|Cj), 得到后驗概率矩陣:

步驟4.4 根據(jù)互信息計算得到后驗概率P(wk|Cj)的權(quán)重, 得到權(quán)重矩陣:
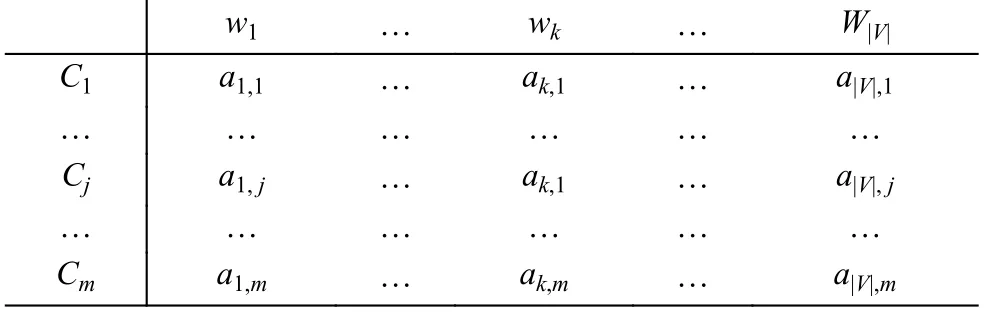
5 特征項加權(quán)的樸素貝葉斯分類算法
實驗采用的數(shù)據(jù)是來源于UCI KDD Archive的20個Newsgroup英文文本數(shù)據(jù)集, 大小約為44.5M. 數(shù)據(jù)集中包括20個不同的新聞組, 共20000篇文檔, 涉及的領(lǐng)域有政治、宗教、體育、科學(xué)、醫(yī)藥、電子、計算機等.
選取其中的10類作為實驗數(shù)據(jù): alt.atheism、comp.graphics、comp.sys.ibm.pc.hardware、misc.forsale、rec.motorcycles、rec.sport.baseball、sci.electronics、sci.space、talk.politics.guns、talk.politics.mideast, 為了方便實驗結(jié)果分析的表述, 依次簡記為L1、L2、L3、L4、L5、……、L10. 其中每類文件包含1000篇文檔,共10000篇文檔. 將數(shù)據(jù)集平均分成5份, 首先用其中4份作為訓(xùn)練樣本, 1份作為測試樣本. 使用訓(xùn)練樣本通過訓(xùn)練過程得到貝葉斯概率矩陣及特征項權(quán)重矩陣,然后調(diào)用加權(quán)樸素貝葉斯文本分類算法對測試樣本進(jìn)行測試, 依次輪回, 采用不同的訓(xùn)練樣本和測試樣本做5次實驗, 取其平均值. 分別用樸素貝葉斯算法(NB)和特征項加權(quán)貝葉斯文本分類算法(TWNB)進(jìn)行測試.
實驗使用了數(shù)據(jù)挖掘平臺Weka, Weka是懷卡托智能分析環(huán)境(waikato envimnment for knowledge analysis), 是由新西蘭懷卡托大學(xué)開發(fā)的基于Java環(huán)境的、開源的機器學(xué)習(xí)及數(shù)據(jù)挖掘軟件[13,14], 本實驗主要是利用Weka的二次開發(fā)功能, 編寫了加權(quán)樸素貝葉斯文本分類算法, 并使用Weka進(jìn)行數(shù)據(jù)的準(zhǔn)備、模型建立和模型驗證過程. 實驗的數(shù)據(jù)雖然是英文文檔, 但是還是需要進(jìn)行數(shù)據(jù)的預(yù)處理包括分詞、粗降維等, 得到Weka需要的數(shù)據(jù)格式, 如{People in the San Francisco Bay area can get Darwin Fish from Lynn Gold}, 即每個文檔包含該文檔所有單詞, 并以空格分隔, 每個不同類別的所有文檔放在以類別名稱命名的文件夾. 在數(shù)據(jù)預(yù)處理過程中采用了分詞軟件包IKAnalyzer, IK Analyzer是一個開源的, 基于java語言開發(fā)的輕量級的中文分詞工具包[15], 支持中文和英文的分詞. 在IKAnalyzer的基礎(chǔ)上編寫了數(shù)據(jù)預(yù)處理程序Splitword, 實現(xiàn)了分詞、粗降維等過程.
測試步驟如下:
步驟1. 對所有樣本文件進(jìn)行分詞, 對分詞后的文本進(jìn)行粗降維, 即將停用詞, 低頻詞從文檔中去除.
步驟2. 在Weka的Simple CLI中運行命令: java weka.core.converters.TextDirectoryLoader -dir e:/data >e:data.arff, 所有訓(xùn)練樣本和測試樣本存在e:/data文件夾下, 執(zhí)行完后生成Weka的數(shù)據(jù)格式為data.arff.
步驟3. 通過weka.filters.unsupervised.attribute.String To Word Vector類, 將文本轉(zhuǎn)化為文本向量形式,并使用weka.filters.supervised.attribute.Attribute Selection類, 進(jìn)行特征選擇.
步驟4. 使用訓(xùn)練樣本通過計算得到加權(quán)貝葉斯文本分類模型, 即貝葉斯概率矩陣和特征項權(quán)重矩陣.
步驟5. 使用測試樣本對模型進(jìn)行測試, 測試采用Cross-validation方式, Folds設(shè)置為5, 得到測試結(jié)果, 與貝葉斯算法進(jìn)行比較.
通過精確率(Precision)、召回率(Recal1)、F1測試值3項主要指標(biāo)進(jìn)行評估測試, 實驗結(jié)果如表1所示.
為了直觀的反映實驗結(jié)果, 將上面的實驗結(jié)果使用圖來表示, 如圖1所示.

表1 實驗結(jié)果
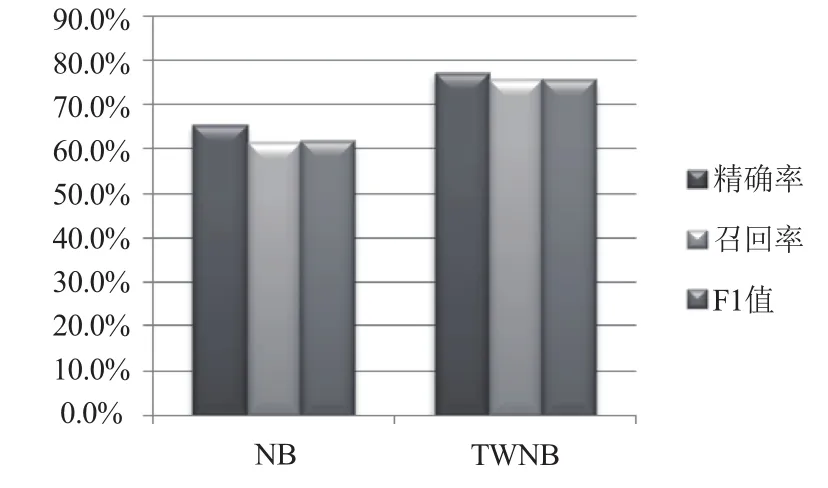
圖1 實驗結(jié)果
從上面的實驗結(jié)果可以得出以下結(jié)論:
1)使用互信息進(jìn)行加權(quán)的貝葉斯分類算法的分類效果明顯高于貝葉斯算法.
2)當(dāng)文檔特征項比較多時, 加權(quán)的貝葉斯分類算法的優(yōu)勢更加明顯.
6 總結(jié)
傳統(tǒng)樸素貝葉斯分類方法有精度較高、分類性能較好、時間復(fù)雜度低等優(yōu)點, 但其特征項獨立性假設(shè)及特征項重要性相等假設(shè)通常與現(xiàn)實不符, 這影響了它的分類效果. 本文根據(jù)文本分類的特點, 采用互信息來計算各個特征項的權(quán)重, 提出了基于互信息的加權(quán)樸素貝葉斯文本分類算法. 以UCI KDD Archive的10個Newsgroup英文文本數(shù)據(jù)集為測試數(shù)據(jù), 通過實驗比較了樸素貝葉斯算法、特征項加權(quán)貝葉斯算法的分類效果. 實驗表明:本文所提出的方法可以部分去除樸素貝葉斯分類算法特征項獨立性假設(shè)及特征項重要性相等假設(shè), 提高樸素貝葉斯的文本分類效果.
1Tan PN, Steinbach M, Kumar V. 數(shù)據(jù)挖掘?qū)д? 第2版. 范明, 范宏建, 譯. 北京: 人民郵電出版社, 2011.
2宗成慶. 統(tǒng)計自然語言處理. 第2版. 北京: 清華大學(xué)出版社, 2013.
3Agrawal R, Imielinski T, Swami A. Database mining: A performance perspective. IEEE Transactions on Knowledge and Data Engineering, 1993, 5(6): 914–925. [doi:10.1109/69.250074]
4Friedman N, Geiger D, Goldszmidt M. Bayesian network classifiers. Machine Learning, 1997, 29(2): 131–163.
5Ferreira JTAS, Denison DGT, Hand DJ. Weighted naive bayes modelling for data mining. London, UK: Deparment of Mathematics, Imperial College, 2001. 454–460.
6Zhang H, Sheng SL. Learning weighted naive Bayes with accurate ranking. Proc. of the 4th IEEE International Conference on Data Mining. Brighton, UK. 2004. 567–570.
7鄧維斌, 王國胤, 王燕. 基于Rough Set的加權(quán)樸素貝葉斯分類算法. 計算機科學(xué), 2007, 34(2): 204–206.
8Hall M. A decision tree-based attribute weighting filter for naive bayes. Knowledge-Based Systems, 2007, 20(2):120–126. [doi: 10.1016/j.knosys.2006.11.008]
9Langley P, Sage S. Induction of selective Bayesian classifiers. Proc. of the 10th International Conference on Uncertainty in Artificial Intelligence. Seattle, USA. 1994.399–406.
10Zhang H, Sheng SL. Learning weighted naive bayes with accurate ranking. Proc. of the 4th IEEE International Conference on Data Mining. Brighton, UK. 2004. 567–570.
11Pinheiro RHW, Cavalcanti GDC, Correa RF, et al. A globalranking local feature selection method for text categorization.Expert Systems with Applications, 2012, 39(17): 12851–12857. [doi: 10.1016/j.eswa.2012.05.008]
12奉國和, 鄭偉. 文本分類特征降維研究綜述. 圖書情報工作, 2011, 55(9): 109–113.
13Witten IH, Frank E. 數(shù)據(jù)挖掘: 實用機器學(xué)習(xí)技術(shù). 第2版.董琳, 邱泉, 于曉峰, 譯. 北京: 機械工業(yè)出版社, 2006.
14WEKA官方網(wǎng)站. http://weka.wikispaces.com/.
15開源中國社區(qū). http://www.oschina.net/p/ikanalyzer/.
Mutual Information-Based Weighted Naive Bayes Text Classification Algorithm
WU Jian-Jun, LI Chang-Bing
(Chongqing University of Posts and Telecommunications, Chongqing 400065, China)
Text classification is the foundation of information retrieval and text mining. Naive Bayes can be applied to text classification as it is simple and efficient classification. But the two assumption about Naive Bayes algorithm that its attribute independence is equal to its attribute importance are not always consistent with the reality, which also affects the classification results. It is a difficult problem to disapprove the assumptions and improve the classification effect.According to the characteristics of text classification, based on text mutual information theory, a Term Weighted Naive Bayes text classification method based on mutual information is proposed, which uses the mutual information method to weight the feature in different class. The effect of two assumptions on classification is partially eliminated. The effectiveness of the proposed method is verified by the simulation experiment on the UCI KDD data set.
Naive Bayes; text classification; mutual information; weighted; term
武建軍,李昌兵.基于互信息的加權(quán)樸素貝葉斯文本分類算法.計算機系統(tǒng)應(yīng)用,2017,26(7):178–182. http://www.c-s-a.org.cn/1003-3254/5840.html
國家自然科學(xué)基金(61472464); 重慶市基礎(chǔ)與前沿研究計劃項目(cstc2013jcyjA40017)
2016-10-14; 收到修改稿時間: 2016-12-01
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
