性能收益模型的流處理算子優(yōu)化技術(shù)綜述*
2017-07-31 20:55:58檀國林陳志鵬
計算機與生活 2017年7期
關(guān)鍵詞:優(yōu)化
檀國林,海 玲,張 鵬,陳志鵬
1.中國科學(xué)院 信息工程研究所,北京 100093
2.信息內(nèi)容安全技術(shù)國家工程實驗室,北京 100093
3.中國科學(xué)院大學(xué),北京 100049
4.新疆工程學(xué)院,烏魯木齊 830091
性能收益模型的流處理算子優(yōu)化技術(shù)綜述*
檀國林1,2,3,海 玲4+,張 鵬1,2,3,陳志鵬1,2,3
1.中國科學(xué)院 信息工程研究所,北京 100093
2.信息內(nèi)容安全技術(shù)國家工程實驗室,北京 100093
3.中國科學(xué)院大學(xué),北京 100049
4.新疆工程學(xué)院,烏魯木齊 830091
+Corresponding autho author:r:E-mail:2468775007@qq.com
TAN Guolin,HAILing,ZHANG Peng,et al.Survey of stream processing operator optim izations for performancegain.Journalof Frontiersof Com puter Scienceand Technology,2017,11(7):1021-1032.
算子優(yōu)化;流處理;性能收益
1 引言
隨著移動互聯(lián)網(wǎng)時代的到來,越來越多的流處理應(yīng)用不斷出現(xiàn)。這些流處理應(yīng)用廣泛地應(yīng)用于各種生產(chǎn)生活環(huán)境,例如網(wǎng)絡(luò)監(jiān)控、通訊數(shù)據(jù)管理、網(wǎng)站點擊數(shù)據(jù)流監(jiān)控、傳感器網(wǎng)絡(luò)、移動設(shè)備掃描監(jiān)控等。在這些應(yīng)用中數(shù)據(jù)是以一種持續(xù)的數(shù)據(jù)流的形式存在,而不是存在于傳統(tǒng)關(guān)系數(shù)據(jù)庫中。
數(shù)據(jù)流的廣泛存在,促使了國內(nèi)外許許多多的研究團(tuán)隊開發(fā)出了各種流處理應(yīng)用,例如Storm、S4、Spark Streaming等。這些流處理應(yīng)用實現(xiàn)方法和原理雖然不盡相同,但是它們的底層實現(xiàn)或多或少都使用到了流處理算子優(yōu)化技術(shù)。流處理應(yīng)用由算子和數(shù)據(jù)流組成,如果把算子表示成有向圖中的節(jié)點,把數(shù)據(jù)流表示成有向圖中的邊,那么它們構(gòu)成的有向圖被稱作流圖,或者數(shù)據(jù)流圖、流拓?fù)鋱D。
本文提到流處理算子優(yōu)化就是針對流圖中的算子進(jìn)行優(yōu)化重組,盡可能大地提升流處理應(yīng)用的處理性能。根據(jù)不同算子優(yōu)化技術(shù)的特點,本文按照表1中所列的8種算子優(yōu)化技術(shù)分別進(jìn)行介紹。
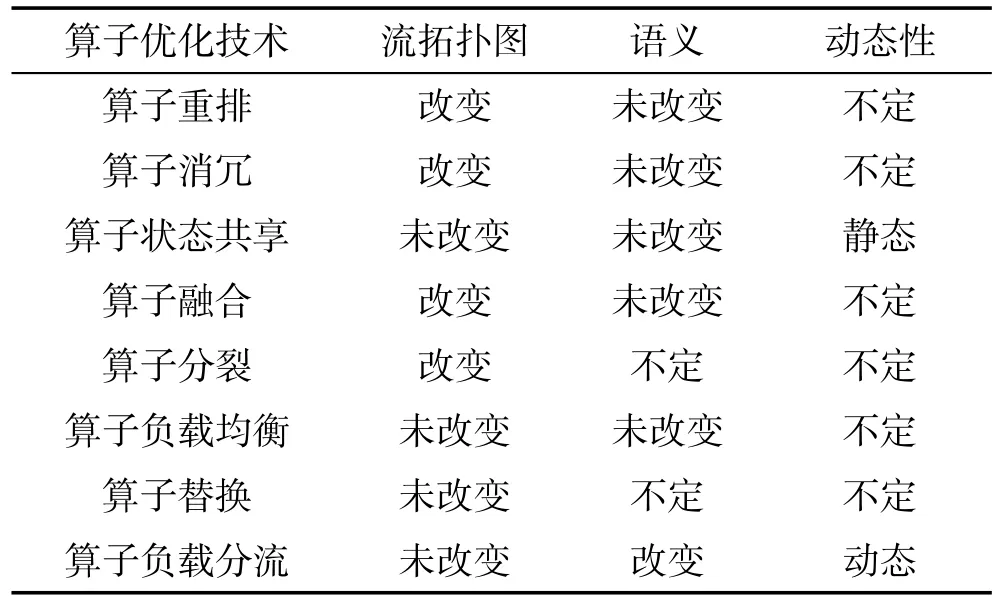
Table1 Operatoroptimization techniques表1 算子優(yōu)化技術(shù)
其中“語義”表示該優(yōu)化技術(shù)的輸入/輸出行為,“未改變”表示采用該算子優(yōu)化技術(shù)后,算子的輸入和輸出都沒有變化;“動態(tài)性”表示算子優(yōu)化技術(shù)是在算子編譯之前靜態(tài)發(fā)生還是運行過程中發(fā)生的,“不定”表示兩種情況都有可能,具體看相應(yīng)的流處理應(yīng)用的實現(xiàn)。
2 算子重排
算子重排是把選擇度低的算子移動到上游算子前面,使流處理應(yīng)用盡可能早地過濾掉無用的數(shù)據(jù),減少下游算子需要處理的數(shù)據(jù)量,從而提升系統(tǒng)性能。算子重排原理如圖1所示,將選擇度低的算子B移動到算子A前面。
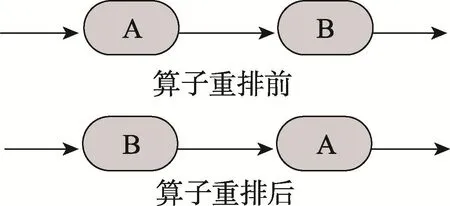
Fig.1 Operator reorder圖1 算子重排示意圖
2.1 應(yīng)用舉例
考慮一個視頻監(jiān)控的流處理應(yīng)用,某城市各個區(qū)都布置一定數(shù)量的視頻監(jiān)控設(shè)備,監(jiān)控把實時拍攝的視頻幀數(shù)據(jù)流回傳到服務(wù)器。在一次犯罪嫌疑人抓捕過程中,現(xiàn)已經(jīng)確定該犯罪嫌疑人的身份,警方希望通過該城市的視頻監(jiān)控設(shè)備來幫助他們實施抓捕,在視頻幀回傳服務(wù)器端實時監(jiān)測犯罪嫌疑人,一旦發(fā)現(xiàn)可疑人物,立即通知警方實施抓捕。
已經(jīng)確定犯罪嫌疑人的性別為男性,以及他的主要活動區(qū)域。視頻幀回傳服務(wù)器端流處理應(yīng)用包含兩個算子,算子A在視頻幀中識別人物的性別,并將包含男性人物的數(shù)據(jù)幀發(fā)送給下游算子B,算子B負(fù)責(zé)將接收到的數(shù)據(jù)幀按照該市不同的區(qū)進(jìn)行過濾。
假設(shè)視頻幀中男女性別分布是1∶1,那么算子A將過濾掉一半的數(shù)據(jù);算子B過濾掉絕大部分無關(guān)區(qū)域的數(shù)據(jù)。如果將算子B移動到算子A前面,那么算子A需要處理的數(shù)據(jù)將會大大減少,系統(tǒng)的性能也會因此而提高。
2.2 收益模型
對于一個算子β,如果輸入的數(shù)據(jù)項個數(shù)是N,輸出的數(shù)據(jù)項個數(shù)是n,那么將n與N的比值稱作算子β的選擇度。
對于上面的例子,算子A的選擇度是0.5。如果將選擇度低的算子移動到前面,那么算子重排是有收益的。
假設(shè)算子A的選擇度固定為0.5,算子B的選擇度是變化的。圖2顯示了在算子B選擇度變化的情況下,算子重排前和算子重排后的系統(tǒng)負(fù)載量。
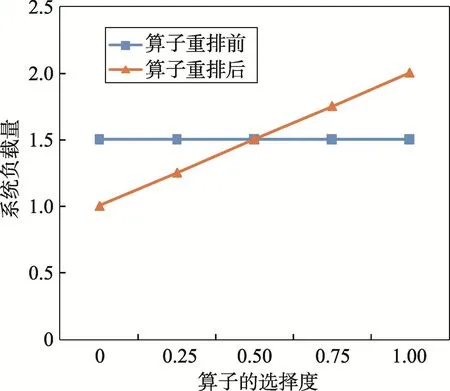
Fig.2 Influenceofoperator reorderon system load under differentoperator selection degrees圖2 不同算子選擇度下算子重排對系統(tǒng)負(fù)載量的影響
算子重排前,所有到來的數(shù)據(jù)算子A都要處理(數(shù)據(jù)量按單位1計算),接著算子A篩選一半的數(shù)據(jù)給下游算子B處理,因此算子重排前算子A和算子B總共處理的數(shù)據(jù)恒為1.5。
算子重排后,所有到來的數(shù)據(jù)先由算子B處理(數(shù)據(jù)量按單位1計算),接著算子B按照自己的選擇度β篩選數(shù)據(jù)給下游算子A處理,因此算子A和算子B處理的數(shù)據(jù)量總共為1+β。
從圖2中可以看出,當(dāng)橫坐標(biāo)算子B選擇度β低于0.5時,算子重排前的系統(tǒng)負(fù)載量要高于算子重排后的,當(dāng)算子B的選擇度 β大于0.5時,算子重排后的系統(tǒng)負(fù)載量要高于算子重排前的。因此得出結(jié)論,只要將低選擇度的算子移動到上游,就可以降低系統(tǒng)負(fù)載量,從而提高系統(tǒng)性能。
2.3 安全條件
并不是所有情況下算子重排都是安全的。當(dāng)滿足以下條件時算子重排是安全可行的。
確保屬性可用性:由于第二個算子B處理的數(shù)據(jù)是經(jīng)過算子A過濾后的數(shù)據(jù)項,如果要算子重排的話,算子B讀取的數(shù)據(jù)屬性集必須和算子A寫入的數(shù)據(jù)屬性集是不相交的。
確保交換性:算子重排后和算子重排前的結(jié)果必須是一樣的,因為必須保證算子A和算子B是可以交換的。如果已經(jīng)確保了屬性的可用性,那么交換的充分條件是算子A和算子B都是無狀態(tài)的。
2.4 動態(tài)性
從前面的介紹中可以知道,算子重排的性能收益是受算子選擇度的影響,因此算子重排的性能收益通常依賴于輸入數(shù)據(jù)的分布。如果輸入數(shù)據(jù)的分布是明確并且不變的,那么算子重排可以在算子靜態(tài)編譯之前確定;反之,需要在算子運行的時候動態(tài)地改變算子順序,從而來提高算子性能。
Eddy算子通過靜態(tài)拓?fù)鋱D轉(zhuǎn)換實現(xiàn)動態(tài)算子重排[1]。它假定一個數(shù)據(jù)項被一個算子丟棄的概率與被另一個算子丟棄的概率是獨立的,優(yōu)點是不必事先知道其選擇度,但是這樣會導(dǎo)致一些額外的開銷來進(jìn)行數(shù)據(jù)路由選擇。
Babu等人提出了另一種利用近似算法的動態(tài)算子重排技術(shù)。該方法能夠處理數(shù)據(jù)項在算子之間被丟棄的概率是相互依賴的情況,并且保證結(jié)果是在最優(yōu)解的一個小的常數(shù)區(qū)間之內(nèi)[2-3]。
3 算子消冗
算子消冗又叫作子圖共享,它通過共享算子的方式將數(shù)據(jù)流圖中冗余算子消除,如圖3所示。
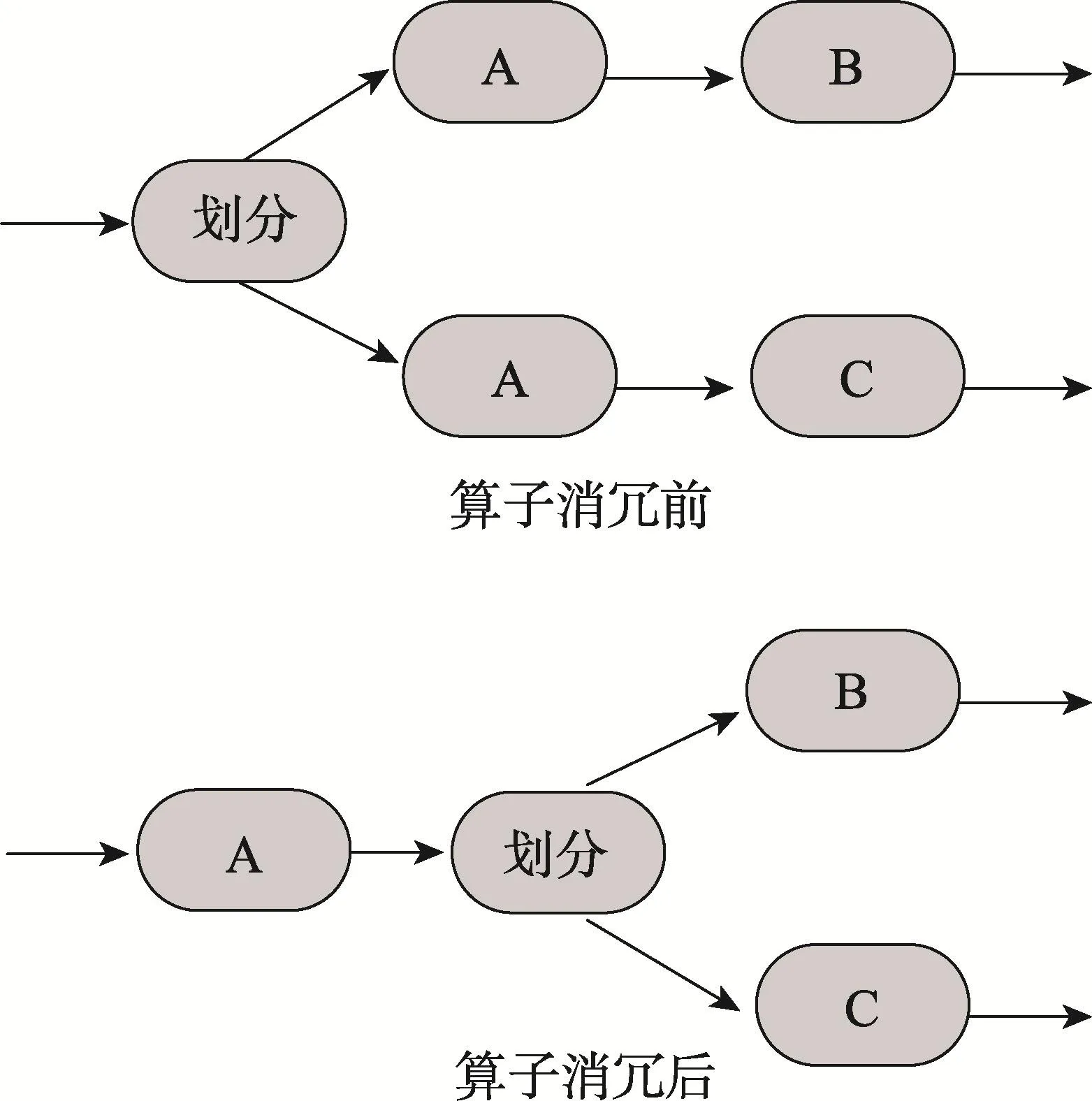
Fig.3 Operator redundancy elimination圖3 算子消冗示意圖
3.1 應(yīng)用舉例
有兩個Web統(tǒng)計應(yīng)用,分別接收來自不同網(wǎng)站發(fā)來的請求,它們都是以算子A開始來解析發(fā)送來的JSON請求數(shù)據(jù),然后將解析后的數(shù)據(jù)分別交給下游算子B和算子C。這兩個應(yīng)用都包含解析JSON(Java-Scriptobjectnotation)數(shù)據(jù)的算子A,因此可以通過算子消冗技術(shù)來消除多余的算子A,使它們共享一個算子A,從而節(jié)省了計算資源。
3.2 收益模型
如果算子消冗的兩個應(yīng)用運行在同一臺機器上,并且是單核執(zhí)行的,那么通過算子消冗是有收益的。
算子消冗前,假設(shè)系統(tǒng)的負(fù)載量是單位1,算子消冗后,因為流處理應(yīng)用共享了同一個算子A,那么系統(tǒng)會少做一次算子A的計算,所以系統(tǒng)的負(fù)載量會由于消除的算子A的負(fù)載量而減少。
從圖4可以看出算子A的負(fù)載量在整個應(yīng)用中的負(fù)載比值越大,那么算子消冗所帶來的性能收益越大。
3.3 安全條件
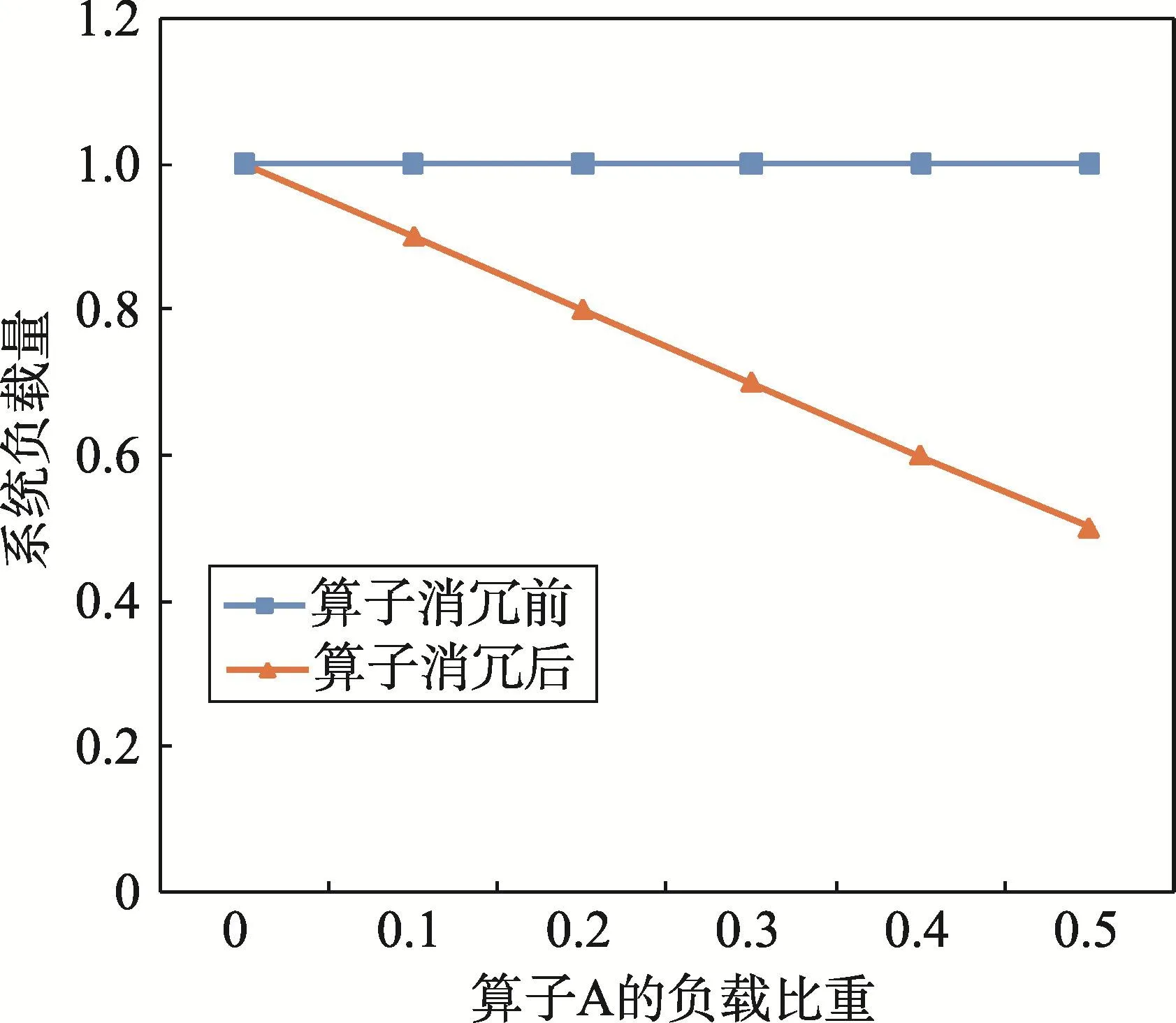
Fig.4 Influenceof system load underoperatorAw ith different load proportion圖4 算子A不同負(fù)載比重消冗后對系統(tǒng)負(fù)載量的影響
確保相同的算法:由于算子消冗會改變流拓?fù)鋱D,在這種情況下要保證算子優(yōu)化技術(shù)的語義不變,那么就要確保消除的冗余算子是等價的。算子等價是經(jīng)典的不可判定問題,在實際應(yīng)用過程中可以采用判斷算子是否具有相同代碼的方法。
確保組合的狀態(tài):當(dāng)消除的冗余算子是無狀態(tài)的,那么消除冗余算子是很容易的事情;但是如果消除的冗余算子是有狀態(tài)的,那么需要考慮的問題就更多了。
3.4 動態(tài)性
基于數(shù)據(jù)流圖的算子靜態(tài)編譯器已經(jīng)可以檢測和消除一個流應(yīng)用中的冗余算子、無意義算子、冪等算子和死子圖等情況。
動態(tài)的算子消冗更多的是應(yīng)用于分布式集群流處理應(yīng)用的情況,流拓?fù)鋱D中的算子被分配到集群中的機器上運行。當(dāng)提交新的拓?fù)涞郊寒?dāng)中時,系統(tǒng)可以先搜索判斷當(dāng)前是否已經(jīng)存在公共子圖,如果存在的話,就可以通過算子消冗技術(shù)來減少系統(tǒng)資源占用。Pietzuch等人提出比較極端的方法[4-5],把流應(yīng)用的添加和移除看成一個類似常規(guī)數(shù)據(jù)項添加和移除的優(yōu)先操作。
4 算子融合
算子融合是把兩個連續(xù)的算子融合成一個更大的算子,如圖5所示。

Fig.5 Operator fusion圖5 算子融合示意圖
4.1 應(yīng)用舉例
考慮這樣一個流量監(jiān)控應(yīng)用,算子A接收前端回傳的流量,并將流量還原成<源IP,源端口,目的IP,目的端口,協(xié)議類型>形式的五元組信息,然后將五元組發(fā)送給后端的算子B。算子B根據(jù)五元組信息過濾掉一些常規(guī)的流量,對異常的流量進(jìn)行提取分析。
由于算子B只是根據(jù)規(guī)則簡單地匹配提取信息,所花費的計算成本非常小,因此可以將算子A和算子B融合到一個算子里面,這樣就可以減少數(shù)據(jù)傳輸?shù)某杀尽M瑫r由于減少了數(shù)據(jù)處理步驟,也減低了系統(tǒng)出錯的幾率。在這種情況下,算子融合技術(shù)是可以考慮的。
4.2 收益模型
算子融合技術(shù)與前面介紹的幾種算子優(yōu)化技術(shù)不一樣,前面介紹的算子優(yōu)化技術(shù)是以減少整個流處理應(yīng)用的負(fù)載量來提升性能收益的,而算子融合技術(shù)并沒有減少整個流處理應(yīng)用的負(fù)載量,它只是把位于不同機器上的算子融合到一個算子里面。這樣做的好處是可以減少數(shù)據(jù)在不同算子之間移動所帶來的成本,但是同時它也減少了管道并行。這就需要對管道并行和數(shù)據(jù)算子間移動的成本進(jìn)行比較,權(quán)衡后選擇是否進(jìn)行算子融合。當(dāng)算子B計算成本很小,同時數(shù)據(jù)算子間移動的成本很大時,可以考慮進(jìn)行算子融合。
另一方面,算子融合技術(shù)減少了數(shù)據(jù)在算子間移動的步驟,因此也減少了數(shù)據(jù)傳輸錯誤和機器故障的可能性。
4.3 安全條件
目前大多數(shù)流處理應(yīng)用都是基于分布式集群的,流處理任務(wù)提交到集群后,會將算子分發(fā)到集群中的機器上去執(zhí)行。因此不同機器上的算子間不會存在本地資源的競爭,例如本地文件、CPU、內(nèi)存等。
避免無限遞歸:如果在流拓?fù)鋱D中存在閉環(huán),例如一個反饋回路,那么數(shù)據(jù)可以在回路中無限循環(huán)。如果算子是通過函數(shù)調(diào)用的方式實現(xiàn)融合的,那么將會導(dǎo)致堆棧調(diào)用溢出。
4.4 動態(tài)性
融合通常是靜態(tài)完成的,也有一些系統(tǒng)是動態(tài)地使用算子融合技術(shù)。flextream系統(tǒng)通過暫停應(yīng)用,重新編譯融合后的代碼,然后恢復(fù)應(yīng)用來實現(xiàn)動態(tài)融合[6]。這種動態(tài)融合技術(shù)可以應(yīng)對流處理應(yīng)用可用資源的改變,但是由于重新編譯和運行也會導(dǎo)致一定的延遲。Tang和Gedik應(yīng)用算子融合技術(shù),把那些算子共享一個線程的決策留給了運行時,這使得他們能夠動態(tài)地控制流水線、線程切換和通信之間的成本開銷[7-8]。
5 算子狀態(tài)共享
算子狀態(tài)共享是指多個算子共享同一塊內(nèi)存空間,從而減少內(nèi)存占用,降低對系統(tǒng)的資源需求,如圖6所示。
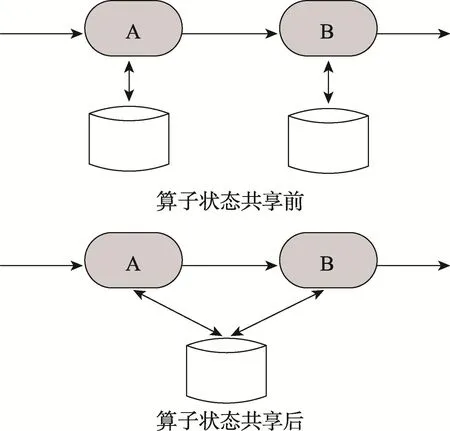
Fig.6 Operatorstate sharing圖6 算子狀態(tài)共享示意圖
5.1 應(yīng)用舉例
假設(shè)有兩個算子A和B,分別實時計算某社交網(wǎng)站一分鐘內(nèi)和一小時內(nèi)最熱門的top N動態(tài),這樣算子A和算子B需要維護(hù)一個很大的內(nèi)存窗口,來記錄當(dāng)前所有用戶發(fā)布的動態(tài)。如果算子A和B只是計算的時間粒度不一樣,那么可以讓算子A共用算子B的內(nèi)存空間[9-10]。
5.2 收益模型
算子狀態(tài)共享能夠帶來兩方面的收益。首先,由于多個算子共享內(nèi)存,減少了內(nèi)存空間的使用,能夠減少流處理應(yīng)用對資源使用的需求。另一方面,減少內(nèi)存空間的使用可以提高計算機緩存的命中率,甚至能夠減少磁盤I/O時間。
5.3 安全條件
確保狀態(tài)是可訪問的:由于多個算子訪問同一個內(nèi)存空間,要求該內(nèi)存空間對多個算子是可訪問的。Storm底層實現(xiàn)了多種并行化技術(shù),Storm的一個worker進(jìn)程包含有多個Executor線程,而每個Executor線程又可以啟動多個task,這里的task相當(dāng)于一個算子。Storm通過這種方式能夠確保同一個Executor線程不同task算子之間狀態(tài)是可訪問的[11-12]。
避免資源競爭:當(dāng)多個算子讀寫同一塊內(nèi)存空間時就需要考慮資源競爭的問題,要么確保操作是只讀的,要么通過同步訪問來控制讀寫正確性。Brito等人使用了軟件事務(wù)內(nèi)存,該機制允許嘗試性地同時對同一狀態(tài)進(jìn)行更新,如果需要的話,可以使用回滾技術(shù)[13]。
5.4 動態(tài)性
狀態(tài)共享通常是靜態(tài)執(zhí)行的。Stream It采用全靜態(tài)方法,其中一個靜態(tài)調(diào)度規(guī)定了什么樣的數(shù)據(jù)在什么時間被什么算子所訪問。Brito等人的工作更多的是動態(tài)方式,共享狀態(tài)的訪問通過軟件事務(wù)內(nèi)存來協(xié)商完成。
6 算子分裂
算子分裂又叫作算子劃分和數(shù)據(jù)并行化,它是把數(shù)據(jù)按照一定的規(guī)則劃分成好幾份,然后將每份數(shù)據(jù)路由給下游相同的算子進(jìn)行處理,是一種典型的數(shù)據(jù)并行化,如圖7所示。
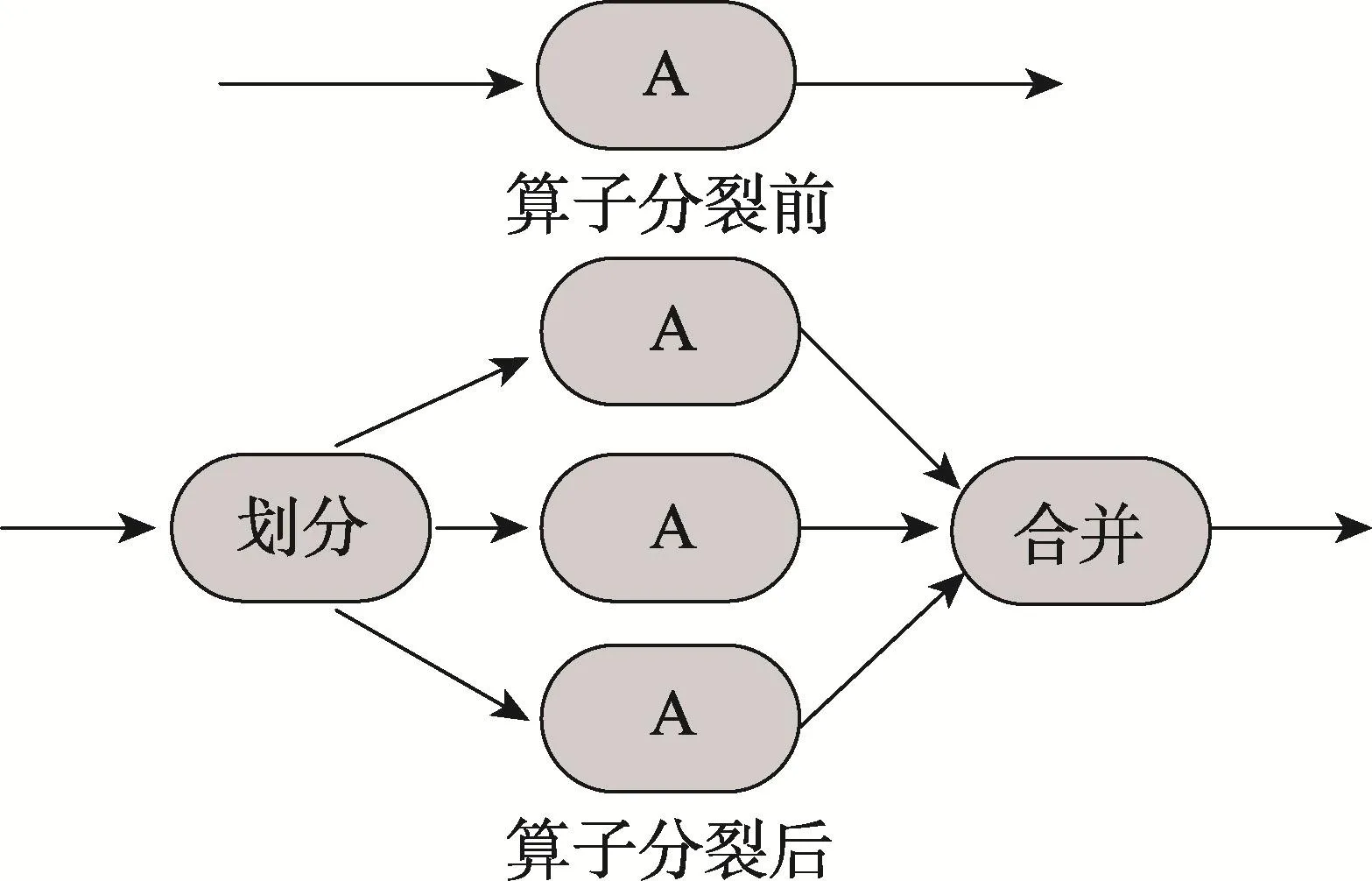
Fig.7 Operator fission圖7 算子分裂示意圖
算子分裂又分為兩種,一種是基于key的算子分裂,另一種是基于批處理的算子分裂。基于key的算子分裂是將數(shù)據(jù)中的某一個或者某一些屬性,按照屬性值的不同劃分到不同機器上的下游算子。最常見的劃分算法是利用哈希函數(shù)進(jìn)行劃分。基于key的算子分裂受限于key的個數(shù),并行度有限。基于批處理的算子分裂是把數(shù)據(jù)按照一定的窗口大小進(jìn)行劃分,最常見的兩種窗口是時間滑動窗口和個數(shù)滑動窗口。
6.1 應(yīng)用舉例
假設(shè)有一個大型的購物網(wǎng)站,時時刻刻都在接收來自全球各地的用戶請求,如果只是由單個算子A來響應(yīng)用戶請求的話,在請求高峰時期必定會導(dǎo)致請求擁堵等待,影響用戶體驗。如果將用戶發(fā)送來的請求按照不同地區(qū),分別劃分到下游多個相同的算子A,那么就可以通過算子分裂來滿足所有用戶的請求。這是一種典型的基于key的算子分裂。
6.2 收益模型
算子分裂會引入兩個額外的算子,劃分算子和合并算子。劃分算子將數(shù)據(jù)劃分成多份,然后決定將劃分的數(shù)據(jù)路由到下游哪個算子當(dāng)中。合并算子負(fù)責(zé)將所有算子A處理后的結(jié)果合并,如果合并的數(shù)據(jù)流有先后順序,那么合并的開銷會很大。
在一般情況下,算子分裂中數(shù)據(jù)劃分和合并的計算成本相對于算子A來說是非常小的,因此通過算子分裂來提升系統(tǒng)性能是非常有效的,并且系統(tǒng)的吞吐量幾乎是與算子A的并行度成正比,如圖8所示。
6.3 安全條件
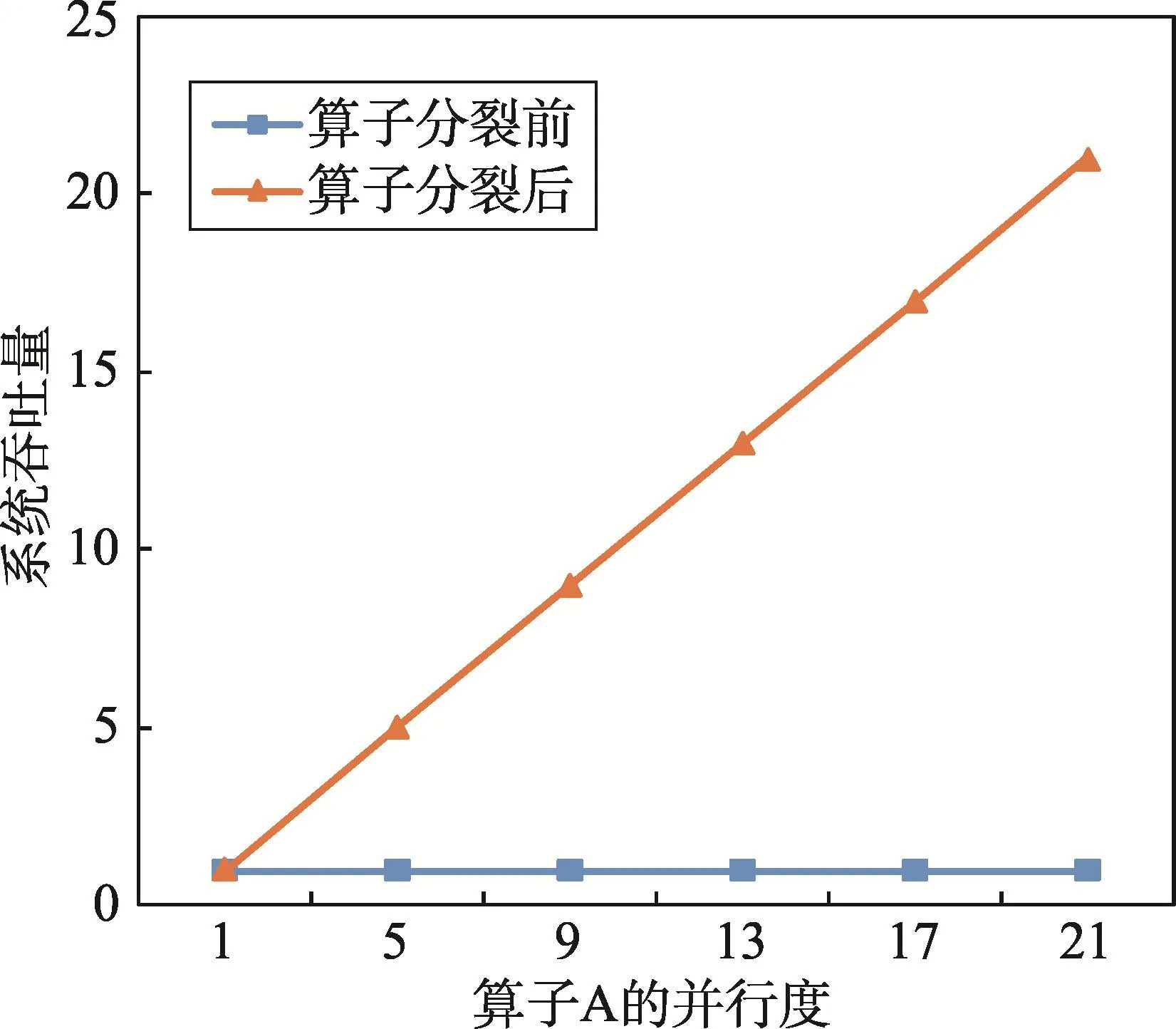
Fig.8 Influenceof throughputw ith operator fission圖8 算子分裂對吞吐量的影響
如果算子是有狀態(tài)的,那么要保證劃分的key是不相交的。無狀態(tài)算子的分裂顯然是安全的,算子分裂后也能夠得到正確的結(jié)果;如果算子是有狀態(tài)的,那么需要保證算子的狀態(tài)是基于劃分后的不同key,也就是說算子的狀態(tài)不依賴于整體的數(shù)據(jù),而是依賴于劃分到當(dāng)前算子的數(shù)據(jù)。例如,計算網(wǎng)站每個用戶消費的總金額,如果算子分裂是按照不同的用戶ID來劃分的,那么每個算子計算的總金額只與劃分到當(dāng)前算子的數(shù)據(jù)有關(guān)。
如果數(shù)據(jù)是有順序的,那么合并算子需要有序合并。對于有些應(yīng)用,它要求數(shù)據(jù)在算子分裂后和算子分裂前順序是一樣的。例如,一個流量還原應(yīng)用,要求處理后的流量和處理前一樣,是按照一定的順序排列的。對于這種情況,需要下游合并算子能夠使用一定策略保證合并后的數(shù)據(jù)依然是有序的。目前已經(jīng)有許多方法來處理這種情況,CQL(continue query language)使用邏輯時間戳來標(biāo)記不同的數(shù)據(jù)[14-15];Stream It用round-robin或者復(fù)制的方式[16-17];MapReduce沒有按原來的順序重排,而是使用了一個分布式的“sort”階段[18-19];Storm為用戶提供了Global Grouping接口和Fields Grouping接口,Global Grouping接口會把所有數(shù)據(jù)發(fā)送給同一個BOLT算子,雖然能夠保證整體有序,但是也失去了算子分裂的優(yōu)勢,F(xiàn)ields Grouping能夠保證每個Fields內(nèi)的數(shù)據(jù)有序。同時Storm支持用戶通過編程的方式,自己實現(xiàn)合并算子的有序性[20-21]。
6.4 動態(tài)性
在有些情況下,人們一開始并不知道算子分裂的并行度,在流處理應(yīng)用運行的過程中,可能隨著key的個數(shù)的增加需要動態(tài)地復(fù)制需要分裂的算子。SEDA(staged event-driven architecture)通過線程控制器做到了這一點,它把線程數(shù)保持到最大值之下[13,22]。Storm允許用戶通過手動調(diào)整流處理應(yīng)用的線程數(shù)或者進(jìn)程數(shù),從而動態(tài)地調(diào)整流處理應(yīng)用的并行度[23-24]。
7 算子負(fù)載均衡
算子負(fù)載均衡是根據(jù)算子運行情況,動態(tài)地把數(shù)據(jù)從高負(fù)載算子路由給空閑的算子,如圖9所示。與前面幾種算子優(yōu)化技術(shù)不一樣,該算子優(yōu)化技術(shù)不改變數(shù)據(jù)流圖,只是改變數(shù)據(jù)路由的去向[25-26]。
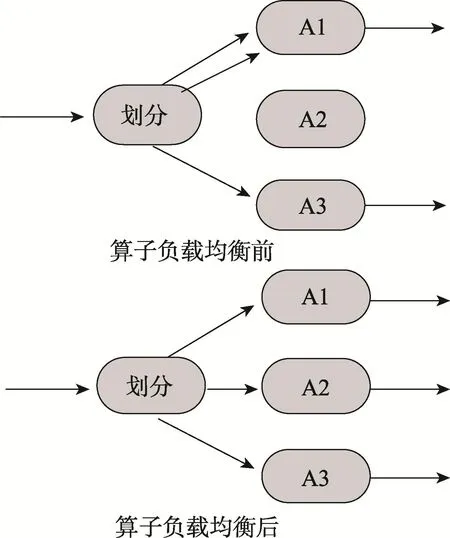
Fig.9 Operator load balance圖9 算子負(fù)載均衡示意圖
7.1 應(yīng)用舉例
算子負(fù)載均衡是在算子分裂基礎(chǔ)上采用的流處理算子優(yōu)化技術(shù)。假設(shè)有一個網(wǎng)絡(luò)流量監(jiān)控應(yīng)用,該應(yīng)用把流量的協(xié)議類型作為key來進(jìn)行算子分裂。在運行過程中,如果某種協(xié)議類型的流量突然增加,而其他的協(xié)議類型的流量突然減少,這樣會導(dǎo)致流量突增的算子過載,而流量減少的算子存在空閑。這種負(fù)載傾斜會降低應(yīng)用整體的吞吐量,甚至過載的算子會由于處理不及時而將數(shù)據(jù)丟棄。
在流處理應(yīng)用中,上面介紹的負(fù)載傾斜是很常見的,因為大多數(shù)數(shù)據(jù)的統(tǒng)計分布人們并不能事先知道。針對這種情況,如果采用算子負(fù)載均衡的話可以很好地解決這種問題[27]。
7.2 收益模型
負(fù)載傾斜會導(dǎo)致過載的算子成為整個流處理應(yīng)用的瓶頸,整個流處理的并行度不再取決于算子分裂復(fù)制的并行算子個數(shù),而是由過載算子決定。如果算子負(fù)載均衡能夠有效地解決數(shù)據(jù)劃分不均勻而引起的負(fù)載傾斜問題,那么算子負(fù)載均衡是有收益的。
假設(shè)過載算子需要處理的數(shù)據(jù)是所有數(shù)據(jù)的50%,盡管算子分裂帶來的并行度是N,那么整個流處理應(yīng)用的并行度其實是2。流處理應(yīng)用的并行度為,其中pi內(nèi)算子分裂中復(fù)制的算子所處理的負(fù)載占總的負(fù)載比值。從公式中可以看出,流處理應(yīng)用的整體并行度取決于過載算子所承擔(dān)的負(fù)載,如圖10所示。
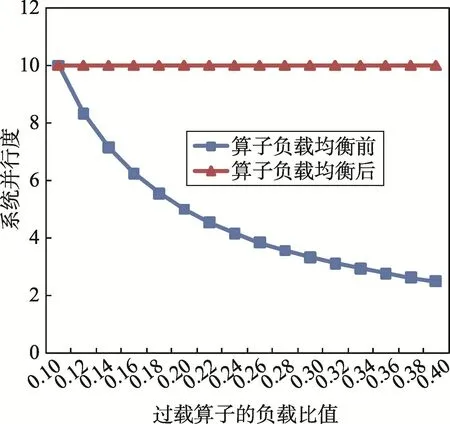
Fig.10 Influenceof system parallelism w ith operator load balance圖10 算子負(fù)載均衡對系統(tǒng)并行度的影響
7.3 安全條件
算子負(fù)載均衡是基于算子分裂的,因此算子負(fù)載均衡首先要滿足算子分裂的安全條件。
完全性:確保重新劃分的每一個數(shù)據(jù)都能被下游空閑算子處理。
兼容性:如果算子分裂是基于key劃分的,那么將多個key路由到下游同一個算子的時候,要確保該算子都能夠處理,即下游算子能夠處理不同key類型的數(shù)據(jù)。
7.4 動態(tài)性
根據(jù)算子負(fù)載均衡的定義,算子負(fù)載均衡是算子執(zhí)行時動態(tài)進(jìn)行的。因為負(fù)載傾斜是由數(shù)據(jù)分布不均勻?qū)е拢@就需要劃分算子在劃分?jǐn)?shù)據(jù)時統(tǒng)計歷史數(shù)據(jù),及時預(yù)測負(fù)載傾斜,并將數(shù)據(jù)路由到空閑算子上。
Vitorovic等人認(rèn)為基于Hash函數(shù)的劃分會產(chǎn)生負(fù)載傾斜問題,因此提出基于數(shù)據(jù)流數(shù)學(xué)統(tǒng)計分布特性來動態(tài)擴展相應(yīng)算子,能夠很好地解決負(fù)載傾斜問題[28]。
8 算子替換
算子替換是選擇具有更高效算法的算子來替換之前的算子,如圖11所示。
Fig.11 Operator replacing圖11 算子替換示意圖
8.1 應(yīng)用舉例
考慮這樣一個在數(shù)據(jù)流上的類SQL查詢,該查詢包含一個連接算子。連接算子有多種實現(xiàn)方法,最常見的3種是嵌套循環(huán)連接、哈希連接和排序連接。通常情況下用嵌套循環(huán)方法實現(xiàn)的連接算子磁盤I/O延遲很大,因此可以將嵌套循環(huán)方法實現(xiàn)的連接算子替換成哈希連接或者是排序連接算子。
8.2 收益模型
采用嵌套循環(huán)方法實現(xiàn)的連接算子的復(fù)雜度是O(n2),哈希連接算子的復(fù)雜度是線性的,而排序連接算子的復(fù)雜度介于嵌套循環(huán)連接算子和哈希連接算子之間。如果將一個高成本的算子替換成低成本的算子,那么收益顯然是存在的。
圖12顯示了不同連接算子的輸入數(shù)據(jù)規(guī)模n和算子執(zhí)行成本t的關(guān)系。其中算子執(zhí)行成本是算子執(zhí)行時間的近似值。

Fig.12 Execution costof different join operators圖12 不同連接算子的執(zhí)行成本
8.3 安全條件
確保算法等價性:對于要替換的兩個算子,要保證它們是等價的,即執(zhí)行這兩個算法得到的結(jié)果是一樣的。當(dāng)其中一個算子只能滿足特定的情況才能執(zhí)行時,算子替換時還要考慮特殊的情況。
8.4 動態(tài)性
當(dāng)算子替換用于對運行時狀況做出反饋時,那么它必須是動態(tài)的。SEDA的每個算子可以判定其過載的規(guī)則,其中的一個可選項是提供降級服務(wù)(即算子替換);在Borealis中,算子能夠控制輸入,例如為算子選擇不同的算法變體[28-30]。為了實現(xiàn)動態(tài)的算子替換,編譯器在靜態(tài)時提供算法的所有變體,運行時動態(tài)地選擇所需要的其中一個算法。換句話說,這種算子替換方式和Eddy為算子重排所做的方式是一樣,即靜態(tài)地插入一個動態(tài)路由組件[31-32]。
9 算子負(fù)載分流
算子負(fù)載分流是通過丟棄一部分?jǐn)?shù)據(jù)來提高系統(tǒng)吞吐量的算子優(yōu)化技術(shù),如圖13所示。
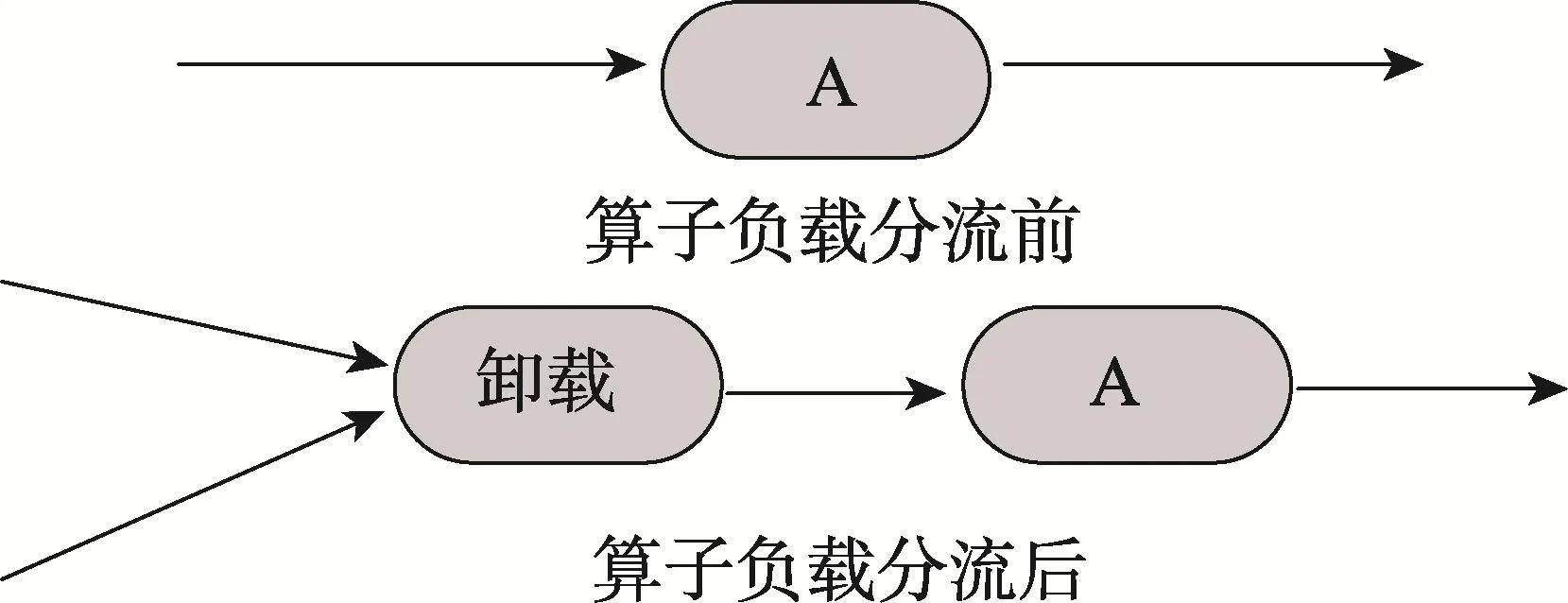
Fig.13 Operator load shedding圖13 算子負(fù)載分流示意圖
9.1 應(yīng)用舉例
負(fù)載分流一開始出現(xiàn)在電力供應(yīng)系統(tǒng),是指當(dāng)高峰期電力供應(yīng)不足時,通過燈火管制將部分地區(qū)的電力切斷,從而使其他大部分地區(qū)能夠正常電力供應(yīng)。同樣在流處理應(yīng)用中,算子負(fù)載分流是指丟棄部分待處理數(shù)據(jù),從而使應(yīng)用整體能夠正常運行。例如一個視頻請求應(yīng)用,當(dāng)高峰期來臨時,請求數(shù)量急劇增加,系統(tǒng)不能夠及時處理的話就會導(dǎo)致請求堆積,影響整個系統(tǒng)的使用,當(dāng)使用算子負(fù)載分流時,丟棄一部分用戶的請求,以達(dá)到系統(tǒng)的正常穩(wěn)定運行。
9.2 收益模型
根據(jù)算子負(fù)載分流的定義,算子負(fù)載分流會改變算子的語義。但是當(dāng)算子執(zhí)行結(jié)果不需要很精確或者不需要滿足每一個用戶請求的話,是可以通過算子負(fù)載分流來應(yīng)對高峰時期的情況。
算子負(fù)載分流的精確度是由卸載算子決定的,當(dāng)卸載算子的選擇度越大,算子負(fù)載分流的精確度就越大,反之算子負(fù)載分流的精確度就越小。圖14顯示了算子負(fù)載分流的精確度和卸載算子的選擇度之間的關(guān)系。
9.3 安全條件
從圖14中可以知道,卸載算子會導(dǎo)致算子負(fù)載分流的精確度下降,也就是說算子負(fù)載分流是不安全的。不同于本文描述的其他算子優(yōu)化技術(shù),算子負(fù)載分流技術(shù)是在性能和精確度之間進(jìn)行折中的一種優(yōu)化技術(shù),盡管這樣,有的流處理應(yīng)用是允許這種不精確的近似結(jié)果,例如傳感器網(wǎng)絡(luò)很多都是采集物理世界的模擬信號。大數(shù)據(jù)時代的到來也使人們從尋求因果關(guān)系中解脫出來,進(jìn)而探索更多的相關(guān)關(guān)系。
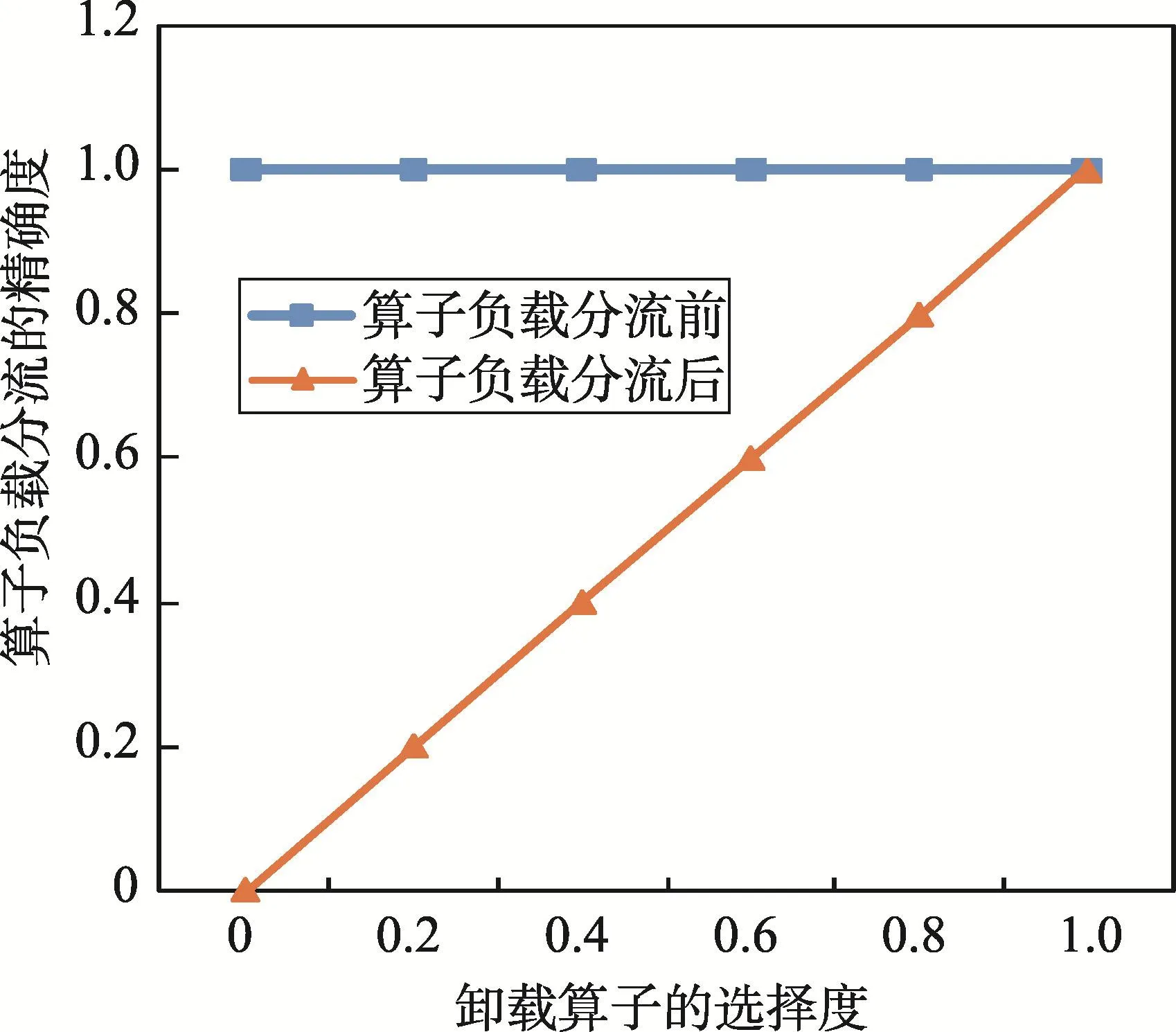
Fig.14 Influenceofaccuracyw ith differentselection degreesofoperatorshedding圖14 卸載算子選擇度對精確度的影響
9.4 動態(tài)性
根據(jù)定義,可以知道算子負(fù)載分流是動態(tài)進(jìn)行的,它在算子運行過程中,需要卸載算子動態(tài)監(jiān)測當(dāng)前的負(fù)載,當(dāng)負(fù)載超過算子的處理能力時,就采取一定的策略來卸載部分?jǐn)?shù)據(jù)。
10 結(jié)束語
本文調(diào)研學(xué)習(xí)了當(dāng)前比較新的流處理框架,結(jié)合實際流處理應(yīng)用,概括總結(jié)了其中最常見的8種流處理技術(shù),并且分析了這8種流處理技術(shù)的性能收益模型,從而對算子優(yōu)化技術(shù)的性能收益有一個更加直觀的認(rèn)識。同時為了能夠?qū)⑦@些算子優(yōu)化技術(shù)正確地應(yīng)用于實際,還從安全條件和動態(tài)性方面介紹了這8種算子優(yōu)化技術(shù)的特點。在實際應(yīng)用中,這些算子優(yōu)化技術(shù)的情況是復(fù)雜的,并且是可以結(jié)合起來同時使用的,具體采用哪種算子優(yōu)化技術(shù)要根據(jù)具體的條件和優(yōu)化目標(biāo)而定。
通過這篇綜述可以對算子優(yōu)化技術(shù)有一個比較全面的認(rèn)識,但是細(xì)化到具體的某一項算子優(yōu)化技術(shù),還是有很多需要開拓和改進(jìn)的地方。例如,在算子替換當(dāng)中,已經(jīng)有部分工作研究如何在流處理應(yīng)用中使用多路非等值連接(multi-way theta-join)[33-34]來處理更復(fù)雜的流處理情況;在算子分裂優(yōu)化技術(shù)中,如何保證在數(shù)據(jù)劃分后合并的整體有序性也是值得研究的問題。除了研究具體算子優(yōu)化技術(shù)的突破和改進(jìn),將算子優(yōu)化技術(shù)應(yīng)用于實際,開發(fā)出更高效可用的流處理系統(tǒng)也是未來工作的重要方向。
[1]Avnur R,Hellerstein JM.Eddies:continuously adaptive query processing[C]//Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data,Dallas,USA,May 15-18,2000.New York:ACM,2000:261-272.
[2]Babu S,Motwani R,Munagala K,et al.Adaptive ordering of pipelined stream filters[C]//Proceedingsof the 2004ACM SIGMOD International Conference on Managementof Data,Paris,Jun 13-18,2004.New York:ACM,2004:407-418.
[3]Arasu A,Babu S,Widom J.The CQL continuous query language:semantic foundations and query execution[J].The International Journal on Very Large Data Bases,2006,15(2):121-142.
[4]Pietzuch P,Ledlie J,Shneidman J,etal.Network-aware operator placement for stream-processing systems[C]//Proceedings of the 22nd International Conference on Data Engineering,Atlanta,USA,Apr 3-8,2006.Washington:IEEE Computer Society,2006:49.
[5]HirzelM,Andrade H,Gedik B,etal.IBM streamsprocessing language:analyzing big data in motion[J].IBM Journal of Research and Development,2013,57(3/4):7.
[6]HormatiA H,ChoiY,Kudlur M,etal.Flextream:adaptive compilation of stream ing applications for heterogeneous architectures[C]//Proceedings of the 18th International Conference on Parallel Architectures and Compilation Techniques,Raleigh,USA,Sep 12-16,2009.Washington:IEEE Computer Society,2009:214-223.
[7]Page L,Brin S,Motwani R,et al.The PageRank citation ranking:bringing order to theWeb[J].WorldWideWeb InternetandWeb Information Systems,1998,54:1-17.
[8]Gedik B,Schneider S,HirzelM,etal.Elastic scaling for data stream processing[J].IEEE Transactions on Parallel and Distributed Systems,2014,25(6):1447-1463.
[9]Gedik B,Wu K L,Yu PS.Efficient construction of compact shedding filters for data stream processing[C]//Proceedingsof the24th InternationalConference on Data Engineering,Cancún,México,Apr 7-12,2008.Piscataway,USA:IEEE,2008:396-405.
[10]Gordon M I,Thies W,Amarasinghe S.Exploiting coarsegrained task,data,and pipeline parallelism in stream programs[C]//Proceedings of the 12th International Conference on Architectural Support for Programm ing Languages and Operating Systems,San Jose,USA,Oct 21-25,2006.New York:ACM,2006:151-162.
[11]Coutts D,Leshchinskiy R,Stewart D.Stream fusion:from lists to streams to nothing atall[C]//Proceedings of the 12th ACM SIGPLAN International Conference on Functional Programming,Freiburg,Germany,Oct1-3,2007.New York:ACM,2007:315-326.
[12]Toshniwal A,Taneja S,Shukla A,etal.Storm@tw itter[C]//Proceedings of the 2014 ACM SIGMOD Iinternational Conference on Management of Data,Snowbird,USA,Jun 22-27,2014.New York:ACM,2014:147-156.
[13]Brito A,Fetzer C,Sturzrehm H,etal.Speculative out-of-order event processing w ith software transaction memory[C]//Proceedingsof the 2nd International Conference on Distributed Event-Based Systems,Rome,Italy,Jul1-4,2008.New York:ACM,2008:265-275.
[14]Okcan A,Riedewald M.Processing theta-joins using Map-Reduce[C]//Proceedings of the 2011 ACM SIGMOD International Conference on Managementof data,Athens,Greece,Jun 12-16,2011.New York:ACM,2011:949-960.
[15]Mayer R,Koldehofe B,Rothermel K.Meeting predictable buffer limits in the parallel execution of event processing operators[C]//Proceedingsof the 2014 International Conference on Big Data,Washington,Jun 27-Jul 2,2014.Piscataway,USA:IEEE,2014:402-411.
[16]BurchettK,Cooper G H,KrishnamurthiS.Lowering:a static optimization technique for transparent functional reactivity[C]//Proceedings of the 2007 ACM SIGPLAN Symposium on Partial Evaluation and Semantics-Based Program Manipulation,Nice,France,Jan 15-16,2007.New York:ACM,2007:71-80.
[17]Carney D,?etintemel U,Rasin A,etal.Operator scheduling in a data stream manager[C]//Proceedings of the 29th International Conference on Very Large Data Bases,Berlin,Sep 9-12,2003.New York:ACM,2003:838-849.
[18]Chen Jianjun,DeWitt D J,Tian Feng,et al.NiagaraCQ:a scalable continuous query system for Internetdatabases[C]//Proceedingsof the 2000ACM SIGMOD InternationalConference on Managementof Data,Dallas,USA,May 15-18,2000.New York:ACM,2000:379-390.
[19]Cortes C,Fisher K,Pregibon D,etal.Hancock:a language for analyzing transactional data streams[J].ACM Transactions on Programm ing Languages and Systems,2004,26(2):301-338.
[20]Amini L,Jain N,SehgalA,etal.Adaptive controlof extremescale stream processing systems[C]//Proceedings of the 26th International Conference on Distributed Computing Systems,Lisboa,Portugal,Jul 4-7,2006.Washington:IEEE Computer Society,2006:71.
[21]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[C]//Proceedings of the 6th Conference on Symposium on Opearting Systems Design&Implementation,San Francisco,USA,Dec 6-8,2004.Berkeley,USA:USENIX Association,2004:10.
[22]Kotto-KombiR,Lum ineau N,Lamarre P,etal.Parallel and distributed stream processing:systems classification and specific issues[EB/OL].(2015-10-13)[2016-12-20].https://hal.archives-ouvertes.fr/hal-01215287.
[23]Gordon M I,ThiesW,Karczmarek M,etal.A stream compiler for communication-exposed architectures[C]//Proceedings of the 10th International Conference on Architectural Support for Programm ing Languages and Operating Systems,San Jose,USA,Oct5-9,2002.New York:ACM,2002:291-303.
[24]Graefe G.Encapsulation of parallelism in the volcano query processing system[C]//Proceedings of the 1990 International Conference on Managementof Data,Atlantic City,USA,May 23-26,1990.New York:ACM,1990:102-111.
[25]Babcock B,DatarM,MotwaniR.Load shedding for aggregation queries over data streams[C]//Proceedings of the 20th International Conference on Data Engineering,Boston,USA,Mar 30-Apr 2,2004.Washington:IEEEComputer Society,2004:350-361.
[26]Barga R S,Goldstein J,A li M,et al.Consistent stream ing through time:a vision for event stream processing[C]//Proceedings of the 3rd Conference on Innovative Data Systems Research,Asilomar,USA,Jan 7-10,2007.New York:ACM,2007:363-373.
[27]Hueske F,PetersM,Sax M J,etal.Opening the black boxesin data flow optim ization[J].Proceedings of the VLDB Endowment,2012,5(11):1256-1267.
[28]Vitorovic A,Seidy M E,Guliyev KM O,etal.Squall:scalable real-time analytics[J].Proceedingsof the VLDB Endowment,2016,9(13):1553-1556
[29]AbadiD J,Ahmad Y,Balazinska M,etal.The design of the Borealis stream processing engine[C]//Proceedings of the 2nd Conference on Innovative Data Systems Research,Asilomar,USA,Jan 4-7,2005.New York:ACM,2005:277-289.
[30]Liu Bin,Zhu Yali,Rundensteiner E.Run-time operator state spilling formemory intensive long-running queries[C]//Proceedings of the 2006 International Conference on Management of Data,Chicago,USA,Jun 27-29,2006.New York:ACM,2006:347-358.
[31]Olston C,Jiang Jing,Widom J.Adaptive filters for continuous queries over distributed data streams[C]//Proceedings of the 2003 International Conference on Management of Data,San Diego,USA,Jun 9-12,2003.New York:ACM,2003:563-574.
[32]OttoniG,Rangan R,Stoler A,etal.Automatic thread extraction w ith decoupled software pipelining[C]//Proceedings of the 38th Annual IEEE/ACM International Symposium on M icroarchitecture,Barcelona,Spain,Nov 12-16,2005.Washington:IEEEComputer Society,2005:105-118.
[33]Hirzel M,SouléR,Schneider S,et al.A catalog of stream processing optimizations[J].ACM Computing Surveys,2014,46(4):46.
[34]Zhang Xiaofei,Chen Lei,Wang M in.Efficientmulti-way theta-join processing using MapReduce[J].Proceedings of the VLDB Endowment,2012,5(11):1184-1195.
TAN Guolin was born in 1992.He is a Ph.D.candidate atUniversity of Chinese Academy of Sciences.His research interests includebig dataand traffic analysis,etc.
檀國林(1992—),男,安徽安慶人,中國科學(xué)院大學(xué)博士研究生,主要研究領(lǐng)域為大數(shù)據(jù),流量分析等。

海玲(1982—),女,新疆瑪納斯人,工程碩士,新疆工程學(xué)院講師,主要研究領(lǐng)域為信號檢測與處理,數(shù)據(jù)流分析,并行計算等。

ZHANG Pengwasborn in 1984.He received the Ph.D.degree in data integration and service computing from Institute of Computing Technology,Chinese Academy of Sciences in 2013.Now he isan associate professorand M.S.supervisor at Institute of Information Engineering,Chinese Academy of Sciences.His research interests include largescale stream data processing and cyberspace security,etc.
張鵬(1984—),男,2013年于中國科學(xué)院計算技術(shù)研究所獲得博士學(xué)位,現(xiàn)為中國科學(xué)院信息工程研究所副研究員、碩士生導(dǎo)師,主要研究領(lǐng)域為大規(guī)模流數(shù)據(jù)處理,網(wǎng)絡(luò)空間安全等。

CHEN Zhipeng was born in 1989.He is a Ph.D.candidate at University of Chinese Academy of Sciences.His research interests include cyber security,big data processing and analysis,etc.
陳志鵬(1989—),男,山東威海人,中國科學(xué)院大學(xué)博士研究生,主要研究領(lǐng)域為網(wǎng)絡(luò)安全,大數(shù)據(jù)處理和分析等。
Survey of Stream Processing Operator Optim izations for PerformanceGain*
TAN Guolin1,2,3,HAILing4+,ZHANG Peng1,2,3,CHEN Zhipeng1,2,3
1.Institute of Information Engineering,ChineseAcademy of Sciences,Beijing 100093,China
2.NationalEngineering Laboratory for Information Security Technologies,Beijing 100093,China
3.University of ChineseAcademy of Sciences,Beijing 100049,China
4.Xinjiang Institute of Engineering,Urumchi830091,China
The arrival of the era of big data and mobile Internet lets people be in data torrent.Big datamake the need more and more urgent to process data efficiently and real-timely.And big data also prompt research teams around theworld to develop a lotof stream processing applications.The implementations of these stream processing applications use a variety of operator optim izations.Based on the research on these stream processing applications,this paper summarizes themost common eightoperator optim izations of stream processing applications.And combined w ith practicalexamples,this paper introduces the featuresof these operator optim izations from aspectsof performance gain,safety condition and dynam ic.Then this paper discusses the further research direction in the field of operatoroptimizationsand stream processing.
operatoroptim ization;stream processing;performancegain
as born in 1982.She
the M.S.degree from Dalian University of Technology.Now she is a lecturer at Xinjiang Institute of Engineering.Her research interests include signal detection and processing,stream data analysisand parallel computing,etc.
A
:TP311.1
*The NationalNatural Science Foundation of ChinaunderGrantNos.61402464,61402474,61602467(國家自然科學(xué)基金).Received 2017-01,Accepted 2017-03.
CNKI網(wǎng)絡(luò)優(yōu)先出版:2017-03-27,http://kns.cnki.net/kcms/detail/11.5602.TP.20170327.1932.002.htm l
摘 要:大數(shù)據(jù)移動互聯(lián)網(wǎng)時代的到來,數(shù)據(jù)量也越來越龐大,數(shù)據(jù)之大使得對數(shù)據(jù)進(jìn)行高效實時處理的需求也變得越來越迫切,促使國內(nèi)外的研究團(tuán)隊開發(fā)出許多流處理應(yīng)用。為了提高流處理應(yīng)用的性能,這些流處理應(yīng)用底層實現(xiàn)都采用了各種各樣復(fù)雜的流處理算子優(yōu)化技術(shù)。在調(diào)研學(xué)習(xí)這些流處理應(yīng)用的基礎(chǔ)上,概括總結(jié)了其中最常見的8種流處理算子優(yōu)化技術(shù),并結(jié)合實際例子,分別從性能收益、安全條件、動態(tài)性等方面詳細(xì)介紹了這些算子優(yōu)化技術(shù)的特點,并探討了算子優(yōu)化和流處理應(yīng)用領(lǐng)域進(jìn)一步的研究方向。
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50
今日農(nóng)業(yè)(2020年16期)2020-12-14 15:04:59
消費導(dǎo)刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(shù)(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
