一種改進的支持向量機參數尋優方法?
2017-08-01 13:49:54呂金銳
計算機與數字工程 2017年7期
呂金銳
(太原城市職業技術學院太原030027)
一種改進的支持向量機參數尋優方法?
呂金銳
(太原城市職業技術學院太原030027)
誤差懲罰參數和核參數是決定SVM泛化能力的主要因素,對這兩種參數的優化是SVM應用中需要解決的關鍵問題之一。論文在研究支持向量機理論的基礎上,利用一些標準的測試數據集研究了均勻設計方法在RBF核參數優化問題上的表現。通過對比尋優精度,發現和傳統均方設計方法相比,采用論文的方法能進一步提高精度。
SVM;均方設計;RBF核參數
Class NumberTP18
1 引言
支持向量機(SVM)是Vapnik等在COLT-92提出的一種新型的機器學習方法,其主要理論基礎為統計學習,并依據風險最小化原理推導而出。SVM在有限的樣本空間中進行統計分析,在模型的復雜性和機器的學習能力之間尋找最優路徑,從而得到最好的推廣能力[1~2]。與傳統的人工神經網絡、決策樹分類及Kmeans聚類等算法相比,不僅數據模型結構簡單,而且泛化推廣能力更高。
Vapnik及其合作者在統計研究中發現,SVM的核函數主要有四種,不同的核函數可以構造不同的SVM,但對SVM的分類結果影響極其有限,然而核函數參數的選擇卻是影響SVM性能的關鍵,也是影響其實用化的主要障礙之一。如何獲得最優的參數,必須借助相關的參數優化算法。本文在傳統的均方設計方法的基礎上設計了一種改進的算法,通過實驗分析表明,采用改進后的參數優化方法在尋優精度上有了提高。
2 支持向量機基本原理
支持向量機最初的設計是為解決線性(Linear)可分情況的。對兩類線性可分情況而言,需要找到一條最佳分類線,該分類線不僅要將兩類樣本數據無錯誤的分割開,而且必須滿足兩類樣本的分類間隔最大。
假設線性可分樣本集為{(xi,yi),i=1,2,3,…,n},xi∈Rd,yi∈{+1,-1},其中d代表d維空間,其線性(Linear)判別函數的表達式為g(x)=w·x+b,其分類面方程就是w·x+b=0。將判別函數進行歸一化處理,使兩類樣本都滿足||g(x)≥1的條件,由于任意點xi到H的距離為:這樣分類間隔。從表達式可以推導出,‖‖w最小,分類間隔最大。要求分類面將兩類樣本全部正確的分割,必須滿足:yi(w·xi+b)-1≥0,i=1,2,3,…,n。
計算支持向量機的過程就是求最佳分類面的過程。因此可以通過求解下面的二次優化問題獲得:
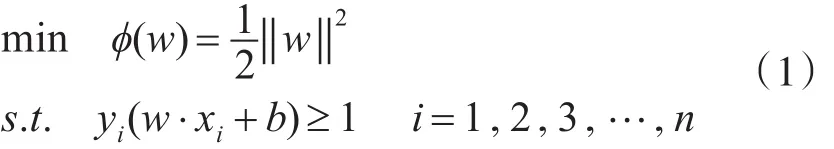
滿足yi(w·xi+b)=1的訓練樣本叫做支持向量。式(1)為在約束條件下求極值的過程,可以通過Lagrange優化方法將其轉化為對偶問題。具體過程是先求出原問題的Lagrange函數:,其中αi≥0為Lagrange乘子,再對式中的w和b求偏導并令其等于0。將得到的等式代回原Lagrange函數,從而得到對偶目標函數。
若α*i為最優解,則該分類面的權向量和偏移量分別為和b*=yi-w*·xi,這是一個二次規劃問題,存在唯一的解,即全局最優解。從表達式中可以推導出,α*i=0的樣本對w*不起作用,只有不等于0的樣本對w*起作用,從而影響分類結果。α*i≠0的樣本被定義為SV,因為它們支撐了整個最優分類面,所以叫支持向量。最終的決策函數為
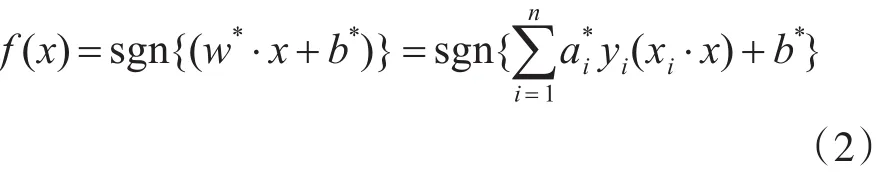
首先提取待分類樣本的特征向量,將特征向量輸入決策函數,輸出即為該樣本的分類結果。
考慮線性不可分的情況,可引入核函數的概念。其基本原理是在當前維度無法分割的樣本點映射到高緯度空間進行分割。在特征空間中構造最優分類超平面時,假設非線性映射為?,其訓練算法僅使用空間中的點積?(xi)·?(xj)。根據泛函的相關理論,只要某一函數K(xi,xj)滿足Mercer條件,即該函數為半正定函數,那么它就可以作為核函數,并且對應某一變換空間中的內積。因此選擇合適的核函數可實現空間變換后的線性分類,但模型的復雜度不變,此時的目標函數函數變換為
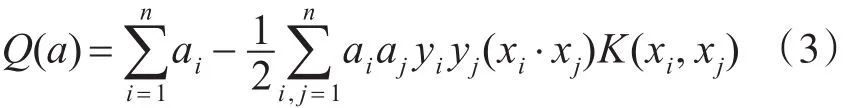
相應的決策函數為
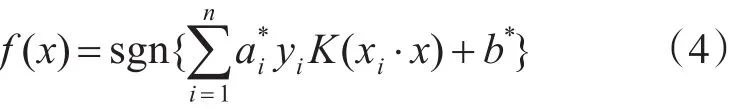
采用不同的內積函數將推導出不同的SVM表達形式,其內積函數也稱之為核函數,常用的核函數有線性核函數(linear)、多項式核函數(polynomi?al)、徑向基核函數(RBF)以及二層神經網絡核函數(Sigmoid tanh)等。
核函數K(xi,xj)、映射函數?(x)以及高維特征空間F是一一對應的,核函數直接影響支持向量機樣本點投影到高維空間的分布。支持向量機為了構造最優分類超平面,獲得較高的推廣性能,需要樣本數據點在高維特征空間有良好的分布。很多實驗結果表明,在沒有任何先驗知識的數據情況下,選擇RBF核進行支持向量機學習往往可以取得很好的分類效果;同時,目前針對RBF核SVM的研究比較多,各種實驗結果也較多,便于和本文的結果進行比較[4]。
3 支持向量機參數優化問題
在機器學習中,學習現有的規律進行總結并對未知的知識進行判斷決策,這樣的能力稱之為推廣性能。在SVM中,核參數λ和誤差懲罰參數C是影響其推廣性能的主要影響因素。核參數λ的改變可以影響映射函數,從而改變樣本在高維特征空間的分布,而對于支持向量機問題來說,在高維特征空間構造最優分類超平面直接影響其推廣性能,所以核參數λ對支持向量機的推廣性能影響巨大。誤差懲罰參數C的作用是確定針對出現誤差的容忍度[5~6],C越大,越不能容忍出現的誤差。
因此可以得出結論,選擇合適的參數,并對參數進行優化,是保證支持向量機進行機器學習并獲得優良推廣能力的前提條件。
常用的優化算法有網格搜索、均方設計方法、遺傳算法、核校準算法和雙線性搜索方法等。本文主要是通過研究均方設計方法,在此基礎上做了進一步改進。
均勻設計方法是在20世紀80年代由方開泰,王元等提出的指導試驗設計的方法。其目的是在多個影響因素,每個因素又有多個水平的情況下,通過在試驗范圍內挑選具有代表性的試驗點,以盡量少的試驗次數,達到最優效果。均勻設計思想的本質是在一個參數空間,挑選一些點,使其均勻分布在參數空間,這些均勻設計點可以代表整個參數空間的分布
要獲得均勻設計點,需要運用均勻設計表。均勻設計表取決于參數的因素數和水平數;在參數優化過程中,影響結果的參數即為因素;水平指每個因素在試驗允許范圍內選取的具有代表性的幾個取值。本文所要優化的參數是誤差懲罰參數和核參數,即因素數為2;參數搜索的區間為[2-15,215],水平數為31[7]。
均勻設計的實驗方法是:每個影響因素的每個水平線上只進行一次試驗;任何兩個影響因素的試驗點在平面方格的交叉點上,每一行每一列有且僅有一個試驗(交叉)點;其目的是保證實驗樣本在實驗范圍內的均勻分布。當影響因素的水平數增加時,試驗次數按照水平數的增加量而增加。
在支持向量機參數優化中執行均勻設計的算法步驟主要是:
1)根據參數和參數搜索區域,確定均方設計因素為2,水平數為31;
2)利用均方設計軟件,根據因素數和水平數生成均方設計表格;
3)根據均方設計表格,在參數空間選取31個均方設計點;
4)在均方設計點上涌支持向量機回歸(SVR)擬合曲面,以代表整個參數空間上的正確率情況;
5)計算生成曲面上每個參數點的5重交叉檢驗正確率,從而找出最佳的參數組。
在本文支持向量機參數優化實驗中,利用均勻設計方法,選出31個均勻設計點,計算5重交叉檢驗正確率,計算量為31×5,相比較網格搜索,均勻設計計算量大大減少,效率有很大的提高。
由于均勻設計方法是在均勻設計點上擬合曲面來代表整個參數區域上面的正確率分布情況,所以當均勻設計點取得過少時,有可能曲面的擬合精度不夠,所以針對這一問題,提出了一種改進的方法,如圖1所示。
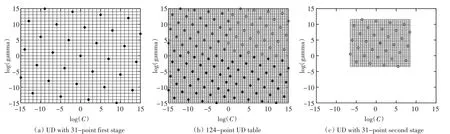
圖1SVM參數優化均勻設計改進方法
首先將原來的參數區間劃分為四個相同小區間,在每個區間上分別取31個均勻設計點。分別用四個區間中的點進行支持向量機(SVM)擬合曲面,在曲面上找出正確率最大的點,即得到局部最優點。
然后在這些局部最優點周圍建立一個小的搜索區間,對這四個小區間進行更精確地搜索,從而找出最優參數,即“嵌套式”均勻設計方法[8]。
本文通過調用標準數據集對該方法進行了驗證。標準數據集主要包括訓練數據和測試數據兩部分。訓練數據主要用于訓練生成支持向量機的模型;測試數據用來預測支持向量機的推廣性能。每一個數據點包括兩部分,樣本和標簽,對于兩類分類問題,數據點的標簽均為[-1,+1]。
本文中,采用以下標準數據集[9],這些數據集的輸入維數從2~60,訓練數據個數從140~1000,測試數據個數從75~7000均不等,且跨越范圍很大,使得本文更有說服力。
4 實驗結果分析
在實現優化算法的過程中,本文利用Matlab編程。本文試驗都是在配置為2.0GHz雙核處理器,1GB內存的計算機上進行。為了對比算法的精度,編程輸出支持向量機最優參數的5重交叉檢驗正確率。
由圖2可以發現,傳統均勻設計方法與改進后的優化方法所獲得的正確率差別不大,但是在小范圍內提高了正確率。由圖3可以看出均勻設計方法和改進方法在參數空間擬合的曲面正確率變化趨勢[10],在最優參數點附近都是基本相同的,而且均勻設計點有良好的空間覆蓋性,并且可以很好地代表空間的特性,可見改進后的方法是可行的。

圖2支持向量機最優參數的5重交叉檢驗正確率
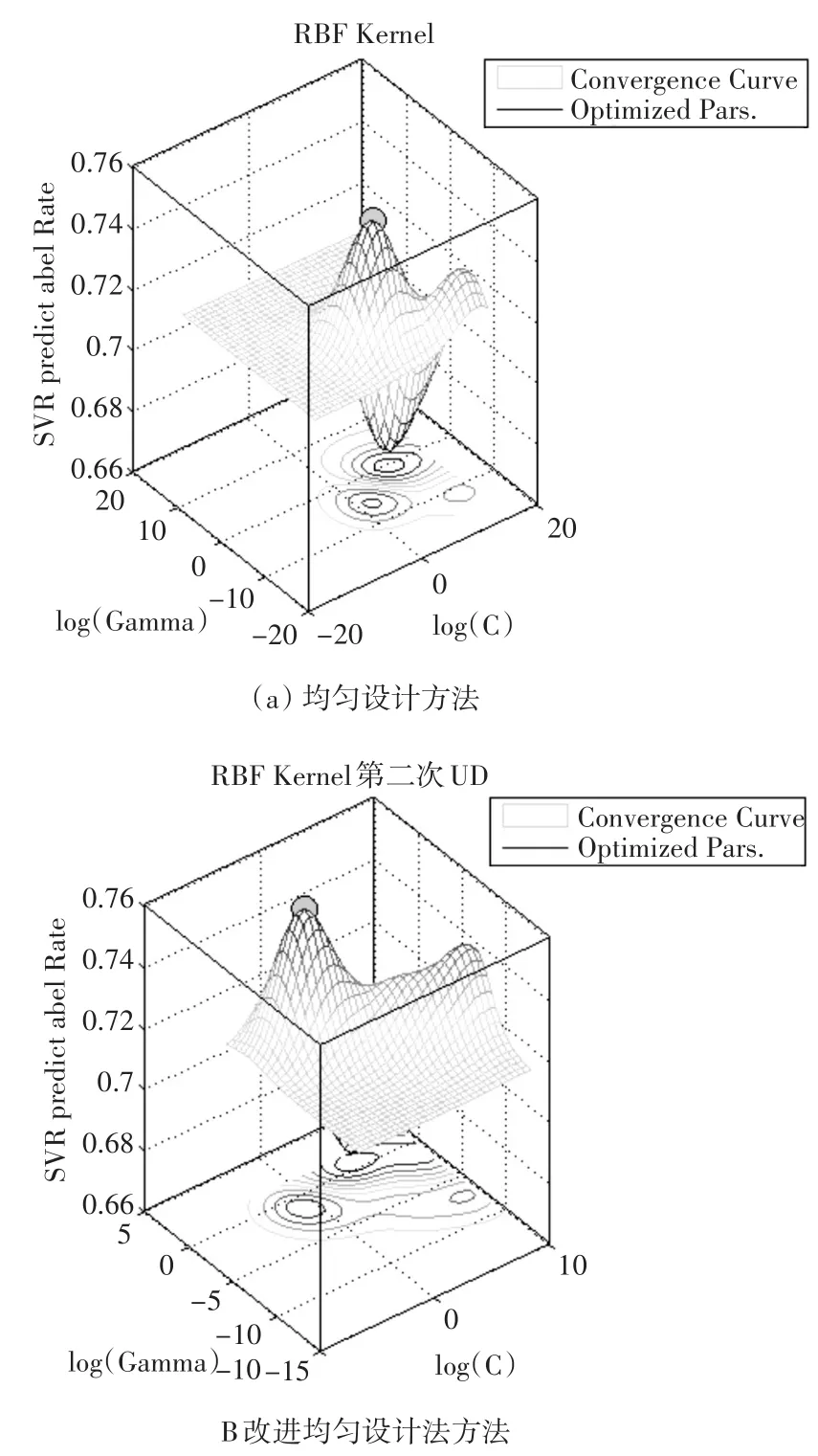
圖3數據集breast-cancer均勻設計方法比較
利用本文的方法對懲罰因子進行最優查找,采用本文的方法獲得最優懲罰因子為0.5,而傳統的均方設計方法獲得的最優懲罰因子為1。將獲得的懲罰因子進行支持向量機的圖像分割,由實驗結果可以發現,采用本文的方法能進一步提高分割精度,如圖4所示。

圖4懲罰因子尋優結果比較
通過分類示意圖,發現采用改進后的均方設計方法能小幅減少支持向量的個數,從而提高分類的精度,如圖5所示。

圖5分類示意圖
從圖5中可以發現,(a)為傳統均方設計方法,其支持向量的個數為24個,分類錯誤率為13.04%,采用改進的方法其支持向量的個數為21個,分類錯誤率為6.52%。
5 結語
懲罰因子C越大,對錯分樣本的懲罰度越大,錯分樣本數將減少,分類間隔將逐漸減小,分類器的維數越來越高,分類器的泛化性能將變差;反之,隨著懲罰因子C值的減小,對錯分樣本的懲罰度減小,錯分樣本數將增多,分類間隔逐漸增大,分類器的維數將逐漸減小,分類器的泛化性能也逐漸變差,因此需要在參數空間中進行最優查詢,而采用本文的參數尋優方法是可行的。
[1]鄧乃陽.數據挖掘中的新方法-支持向量機[M].北京:科學出版社,2003:63-64. DENG Naiyang.New method in data mining-support vec?tor machine[M].Beijing:Science Press,2003:63-64.
[2]Vapnik V.N.The Nature of Statistical Learning Theory[M].New York:Springer,2000:171-176.
[3]丁世飛,齊丙娟,譚紅艷.支持向量機理論與算法研究綜述[J].電子科技大學學報,2011(1):3-4. DING Shifei,QI Bingjuan,TAN Hongyan.An Overview on Theory and Algorithm of Support Vector Machines[J]. Journal of University of Electronic Science and Technolo?gy of China,2011(1):3-4.
[4]李俊飛.一種支持向量機在線學習分類算法[J].伊犁師范學院學報(自然科學版),2015(4):56-57. LI Junfei.An Online Learning Algorithm for Classifica?tion of Support Vector Machine[J].Journal of Yili Normal University(Natural Science Edition),2015(4):56-57.
[5]閆國華.支持向量機回歸的參數選擇方法[J].計算機工程,2009,35(13):218-220. YAN Guohua,ZHU Yongsheng.Parameters Selection Method for Support Vector Machine Regression[J].Com?puter Engineering,2009,35(13):218-220.
[6]Liu Yu-Hsin.Global maximum likelihood estimation pro?cedure multinomial probit(MNP)model parameters[J]. Transportation Research Part B:Methodological,2008,34(5):419-449.
[7]栗志意,張衛強,何亮,等.基于核函數的IVEC-SVM說話人識別系統研究[J].自動化學報,2014(4):780:782. LI Zhiyi,ZHANG Weiqiang,HE Liang.Speaker Recogni?tion with Kernel Based IVEC-SVM[J].Acta Automatica Sinica,2014(4):780:782.
[8]梁亮,楊敏華,李英芳.基于ICA與SVM算法的高光譜遙感影像分類[J].光譜學與光譜分析,2010,10(30):2724-2726. LIANG Liang,YANG Minhua,LI Yingfang.Hyperspectral Remote Sensing Image Classification Based on ICA and SVM[J].Algorithm.Spectroscopy and Spectral Analysis,2010,10(30):2724-2726.
[9]Hyvarinen.A.Fast and robust fixed-point algorithms for independent component analysis[J].IEEE Transactions on Neural Networks,1999,4:895-896.
[10]張倩,楊耀權.基于支持向量機核函數的研究[J].電力科學與工程,2012,5(28):42-43. ZHANG Qian,YANG Yaoquan.Research on the Kernel Function of Support Vector Machine[J].Electric Power Science and Engineering,2012,5(28):42-43.
An Improvement of Support Vector Machine Parameter Optimization Method
LV Jinrui
(Taiyuan City Vocational College,Taiyuan030027)
The penalty parameter and the kernel parameter are the main factors to determine SVMs'generalization perfor?mance and the optimization of these two parameters is one of the key issues,which needs to be solved in the application of SVM. Based on the research of SVM theory,through programming,the paper uses some standard test data sets to compare the perfor?mance of uniform design method in the RBF kernel SVM parameter optimization problems.Through the comparison of accuracy,it is showed that the further precision can be obtained compared with the traditional method.
SVM,uniform design,RBF kerne
TP18
10.3969/j.issn.1672-9722.2017.07.017
2017年1月3日,
2017年2月27日
呂金銳,男,碩士,研究方向:計算機網絡技術、數字圖像處理。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
