基于增量支持向量機的入侵檢測算法
2017-08-08 05:42:17杜紅樂
微型電腦應用 2017年7期
關鍵詞:分類
杜紅樂, 張 燕
(商洛學院 數學與計算機應用學院, 商洛 726000)
?
基于增量支持向量機的入侵檢測算法
杜紅樂, 張 燕
(商洛學院 數學與計算機應用學院, 商洛 726000)
針對網絡入侵檢測無法識別新的入侵行為,利用增量學習不斷完善分類器,使得分類器可以識別新的入侵行為。提出一種基于相似度的增量支持向量機算法,該算法依據新增樣本與支持向量之間的相似度來選擇樣本(當前分類器缺少該樣本的空間信息),然后加入訓練集中參加下一次迭代訓練。實驗結果表明,該算法能夠提高最終分類器的分類精度和算法的訓練速度。
支持向量機; 入侵檢測; 相似度
0 引言
支持向量機(support vector machine,簡稱SVM)[1]是在統計學習理論基礎上發展起來的一種新的機器學習方法,它基于結構風險最小化原則,在解決小樣本、非線性及高維模式識別問題中表現出許多特有的優勢,近年來,SVM在許多領域都取得廣泛的應用。
在實際的應用中往往無法一次性收集到完備的數據集,數據集是在使用的過程中逐漸收集的,例如入侵檢測中,入侵行為不斷更新,永遠無法收集完備的數據集,需要分類器在使用的過程中不斷學習新的數據,逐漸完善分類器,增量學習算法應運而生。支持向量機增量學習算法主要算法層面[1-5]和數據層面[6-15]兩種,算法層面主要是利用當前分類器的計算信息和新增樣本信息獲得新的分類器,無需迭代訓練;數據層面方法多是針每次迭代中原有樣本的篩選及對新增樣本的篩選,目的在于保證算法的速度,同時保證分類器的分類精度。對新增樣本通過一定方法,選擇樣本包含的空間信息是分類器缺少的樣本加入下一次訓練,從而把新增樣本中的空間信息逐漸納入到分類器中。文獻[6]充分利用KKT條件,利用最大似然確定邊界向量,然后把確定的邊界向量加入到訓練集中,進行下一次迭代;文獻[7]利用KKT條件及時淘汰對后續訓練影響不大的樣本,同時保留包含重要信息的樣本,可以有效提高算法的訓練速度;文獻[8]依據相似度選擇樣本,保證所選樣本的質量,同時利用誤差驅動的原則對原有樣本進行刪減,可以刪除包含空間信息少的以及噪聲樣本,可以提高算法速度;文獻[9]根據加入新增樣本后支持向量集的變化,淘汰那些對最終分類無用的樣本,提出基于密度法的支持向量機增量學習淘汰算法;文獻[10]提出球結構多類SVM 增量學習算法,該算法將新增樣本集中根據KKT條件選取部分樣本和原始訓練集中的支持向量以及分布在球體一定范圍內的樣本合并作為新的訓練集,完成分類器的重構;文獻[11]利用新增樣本到類中心的距離計算概率密度,依據概率密度選擇樣本加入下一次迭代,但是該方法每次需要計算到所有樣本的距離,會影響算法的速度。基于以上分析,通過計算每個新增樣本與正類支持向量及負類支持向量的相似度,然后利用相似度選擇加入下次迭代的樣本,把該算法叫作基于相似度的增量支持向量機算法,并把該算法應用到入侵檢測中,仿真實驗結果表明算法的有效性。
1 相似度
SVM為解決線性不可分問題,使用核函數將樣本從輸入空間映射到某一特征空間中,使得樣本在該特征空間中線性可分,設映射函數為:φ:Rk|→F,核函數為K(x,y)=<φ(x),φ(y)>,常采用的核函數有高斯核、多項式核、RBF核等等,SVM的計算過程是在核空間下進行的,因此為了更準確的描述樣本與支持向量之間的關系,在核空間下計算樣本與支持向量之間的距離,設樣本x、y,則兩樣本之間的距離d(x,y)在核空間下表示,為式(1)。
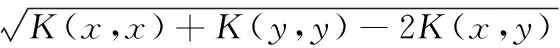
(1)
若采用RBF核函數,即K(x,y)=exp(-g||x-y||2),則兩樣本之間的距離為式(2)。
(2)
對于增量樣本的xi,對正支持向量和負支持向量的相似度用到達正負支持向量的平均距離的倒數表示,計算方法如式(3)。
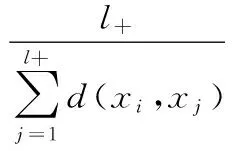

其中l+、l-分別表示正負支持向量數量,d(x,y)在核空間下計算,本文實驗中計算相似度的核函數與支持向量機采用相同的核函數,都采用的RBF核函數。
2 增量支持向量機算法
2.1 算法原理
增量學習為了減少每次迭代的訓練時間,需要選擇對分類器有改變的樣本進入訓練集,即選擇選擇的樣本所包含空間信息是當前分類器缺少的,例如依據KKT條件[9]、依據概率密度[10]等選擇樣本進行迭代。
對增量樣本集中的每個樣本,計算對正負支持向量的相似度,分別依據正負相似度進行排序,選擇K個相似度大的樣本,對于正相似度,若樣本的實際類別為正,則樣本不做處理,否則就把該樣本放入T中;對于負相似度,若樣本實際類別為正,則把該樣本放入T中,重新訓練得到新的分類器和支持向量。K值是為了控制算法速度,K值越大,每次迭代中的訓練集規模就越大,但迭代次數會減少;K值小,則迭代次數增加,迭代中訓練集規模減小。
2.2 算法步驟
算法:增量支持向量機算法SISVM
輸入:初始訓練集集T,增量樣本集U,選擇樣本數K
輸出:最終分類器
step1.用SVM對初始訓練集T進行訓練,得到分類器f和支持向量SV+和SV-;
step2.增量樣本選擇:
step2.1 判斷增量樣本集T是否為空,若為空則算法終止;否則,對T中的每個樣本,利用計算與正負支持向量的相似度;
step2.2 對正負支持向量相似度進行排序,選擇其中K個相似度值大的樣本,若S+(xi)≥S-(xi),且樣本的實際類別為負,則把該樣本放入Temp中;若S+(xi)≤S-(xi),且樣本實際類別為正,則把樣本放入Temp中,同時從U中刪除該樣本;
step2.3 判斷Temp是否為空,若不為空,則合并Temp和T,重新訓練得到新的分類器和支持向量集,返回step2;若為空,則直接返回step2;
step3. 得到最終分類器。
該方法與PISVM相比,PISVM需要計算每個增量樣本與當前訓練集中每個樣本的距離,而本文算法只需計算與支持向量之間的距離,而支持向量數量要小于訓練集,因此可以提高算法速度;PISVM算法每次迭代選擇1~2個樣本,而本文算法通過調控參數K控制每次選擇樣本的數量,引入S+(xi)≥S-(xi)和S+(xi)≤S-(xi)的判斷,確保被選擇樣本包含有分類器缺少的空間信息,提高準確度。
3 實驗及數據分析
本文中所做實驗是在Matlab 7.11.0環境下,結合臺灣林智仁老師的LIBSVM[16],主機為Intel Core i7 2.3GHz,4G內存,操作系統為Win7的PC機上完成。
3.1 數據集
KDDCUP1999[17]數據集是關于入侵檢測的標準數據集,包括訓練集和測試集,其中訓練集有494022條記錄,測試集有311030條記錄,訓練集中包含24種攻擊,而測試集有38種攻擊。本文算法是針對二類分類問題,把數據集也看作是兩類分類數據,把所有攻擊數據看作一類。KDDCUP99數據集的41個數據屬性中,有數值型,也有字符型,因此首先對數據集進行數值化和歸一化,數值化是對字符類型數據用數字進行簡單的替代,歸一化采用LIBSVM中的歸一化工具進行處理。為了驗證算法的有效性,從數據集中取了2組數據集data1和data2,每組實驗數據從訓練數據中去300條記錄作為初始訓練集(Train set),從測試數據集中取出1000條記錄作為增量樣本集,數據集1中的測試集是數據集2的增量樣本集,數據集2中的測試集用的是數據集1中的增量樣本集,詳細的數據集分布情況如表1所示。
3.2 實驗結果及分析
對于入侵檢測來說,為了更準確的描述算法的有效性,不僅要對比算法的整體準確率,還要綜合考慮對樣本的查準率和查全率,因此本文主要從準確率、查準率、查全率以及算法時間方面進行對比,驗證本文算法的有效性,其中算法PISVM來自于文獻[10] 。

表1 實驗數據集
從整體、正常行為、攻擊行為、已有攻擊、未知攻擊幾方面的分類準確率進行對比,如表2所示。
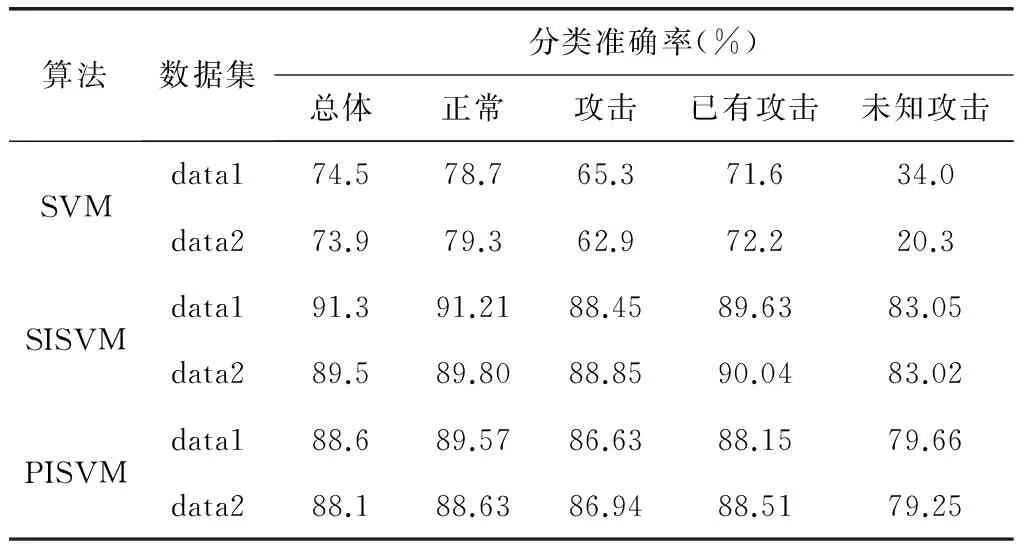
表2 準確率對比
查準率進行對比的結果,如表3所示。

表3 查準率對比
表3中,SVM算法結果是直接對300個樣本進行訓練,得到分類器對1000個測試樣本進行測試的結果,由于未能學到新攻擊類型數據的空間信息,導致對未知攻擊的分類準確率較低;PISVM算法是根據新增樣本到各類中心距離計算概率密度,然后依據概率密度選擇加入訓練集的樣本,用成對標注的直推式支持向量機算法,該算法的前提是兩類樣本數量相當,而實際的測試集中兩類樣本不均衡,因此,分類準確率仍不理想,但學習了測試樣本及未知攻擊類型的空間分布信息,因此分類準確率有了明顯的提升;TISVM是本文算法的分類結果,該算法可以盡快獲得無標簽樣本中的空間信息,減少錯誤的傳遞和累積,因此對分類準確率及未知攻擊的分類準確率都有了明顯的提高,實驗結果是K=2時候的結果,如表2、表3所示。
從實驗結果中可以看到,data1的實驗結果要比data2的結果好,無論是準確率海是查準率,分析數據可以看到,data1中的攻擊數據數量多于data2中,data1和data2都屬于不均衡數據,并且data1中未知攻擊數據也多于data2中,因此data1所得的實驗結果優于data2的實驗結果。
4 總結
入侵檢測要不斷適應新的攻擊行為,需要不斷完善分類器,增量學習可以很好解決這樣的問題,本文利用新增樣本與支持向量的相似度對新增樣本進行刪除,保留包含豐富空間信息的樣本,從而提高算法的速度和精度。然而不均衡數據下同樣會導致分類超平面的偏移,會使錯誤累積和傳遞,不均衡數據集下的增量學習將是下階段的主要工作。
[1] 權鑫,顧韻華,鄭關勝,等.一種增量式的代價敏感支持向量機[J].中國科學技術大學學報,2016,46(9):727-735.
[2] 王洪波,趙光宙,齊冬蓮,等.一類支持向量機的快速增量學習方法[J].浙江大學學報(工學版),2012,46(7):1327-1332.
[3] 郝運河,張浩峰.基于雙支持向量回歸機的增量學習算法[J].計算機科學,2016,43(2):230-234.
[4] 徐久成,劉洋洋,杜麗娜,等.基于三支決策的支持向量機增量學習方法[J].計算機科學,2016,42(6):82-87.
[5] 劉偉,謝興生,肖超峰.一種基于支持向量閾值控制的優化增量SVM算法[J].計算機工程與應用,2015,51(3):124-128.
[6] 曹健,孫世宇,段修生,等.基于KKT條件的SVM增量學習算法[J].火力與指揮控制,2014,39(7):139-143.
[7] 馬占飛,樊捷杰,張文興.廣義KKT約束的增量支持向量機建模研究[J].機械設計與建造,2015,(11):167-170.
[8] 豐文安,王建東,陳海燕.一種快速SVR增量學習算法[J].小型微型計算機系統,2015,36(1):162-166.
[9] 李娟,王宇平.基于樣本密度和分類錯誤率的增量學習矢量量化算法研究[J].自動化學報,2015,41(6):1187-1200.
[10] 潘世超,王文劍,郭虎升.基于概率密度分布的增量支持向量機算法[J].南京大學學報(自然科學版),2013,49(5):603-610.
[11] 王立梅,李金鳳,岳琪.基于k均值聚類的直推式支持向量機學習算法[J].計算機工程與應用,2013,49(14):144-146.
[12] 楊海濤,肖軍,王佩瑤,等.基于參數間隔孿生支持向量機的增量學習算法[J].信息與控制,2016,45(4):432-436.
[13] 郭虎升,王文劍, 潘世超.基于組合半監督的增量支持向量機學習算法[J].模式識別與人工智能,2016,29(6):504-510.
[14] 杜紅樂,滕少華,張燕.協同標注的直推式支持向量機算法[J].小型微型計算機系統.2016,37(11):2443-2447.
[15] Xie Zhiqiang, Gao Li, Yang Jing. Improved multi-class classification incremental learning algorithm based on sphere structured SVM [J]. Journal of Harbin Engineering University. 2009, 30(9):1041-1046.
[16] Chang C C, Lin C J. LIBSVM: A library for support vector machines. (2014-07-10). [EB/OL]. http://www.csie.ntu.tw/~cjlin/libsvm.
[17] http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html. 1999.
Intrusion Detection Based on Incremental Support Vector Machine
Du Hongle, Zhang Yan
(School of mathematics and computer application, Shangluo University, Shangluo 726000, China)
Because network intrusion detection system cannot identify new intrusion behavior, incremental learning can improve classifier, and classifier can identify the new intrusion behavior. This paper presents an incremental support vector machine algorithm based on similarity. The algorithm selects the sample according to the similarity between the new samples and support vectors. These samples contain the spatial information that the current classifier lacks. Then these samples are added to the training center for the next iteration. This algorithm can improve the training speed and classification accuracy. Finally, the experimental results show that the proposed algorithm can improve the classification accuracy and the training speed.
Support vector machine; Intrusion detection; Similarity
陜西省自然科學基礎研究計劃資助(2015JM6347)、陜西省教育廳科技計劃項目(15JK1218)、商洛學院科學與技術研究項目(15sky010)
杜紅樂(1979-),男,碩士,講師,研究方向:機器學習、數據挖掘。 張燕(1977-),女,碩士,講師,研究方向:模式識別、機器學習。
1007-757X(2017)07-0015-03
TP301.6
A
2016.10.30)
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
