基于隱式時間查詢的文檔排名方法
2017-09-09 01:38:06王晶晶
軟件導刊 2017年8期
王晶晶

摘 要:時態信息檢索是近年來的研究熱點,很多解決方案是在檢索模型中考慮時間相關性。提出一種支持隱式時間查詢的文檔排名方法,使用考慮內容相關性排名結果的前k個文檔分析查詢的時間意圖,然后使用排名模型計算各個文檔時間相關性得分。實驗結果表明,在排名模型中引入時間因素有利于提升檢索性能。
關鍵詞:隱式時間查詢;時態信息檢索;排名模型
DOIDOI:10.11907/rjdk.171275
中圖分類號:TP301
文獻標識碼:A 文章編號文章編號:1672-7800(2017)008-0012-03
0 引言
搜索引擎是目前最受歡迎的獲取信息方式之一,用戶可以通過搜索引擎在海量信息中方便地檢索到自己感興趣的主題,研究人員發現大約1.5%的查詢包含明確的時間約束[1],超過7%的查詢包含隱式時間意圖[2]。因此,在檢索模型中考慮時間因素,理解用戶查詢的潛在時間意圖,有利于提升搜索引擎的檢索性能。
1 相關工作
時態信息檢索 (Temporal Information Retrieval)[3]是信息檢索的一個重要分支。查詢某一個特定時間區間的文檔稱為時間敏感查詢(time-sensitive query)。顯式時間敏感查詢定義明確的時間約束,Berberich等[4]針對這類查詢提出一個考慮時間因素的檢索模型,把從文檔中提取的時間詞匯添加到語言模型中計算概率。Diaz和Jones[5]提出使用文檔的時間戳衡量檢索結果文檔在時間域上的分布,并創建一個查詢時間配置文件。隱式時間敏感查詢雖然沒有提供明確的時間標準,但與查詢相關的文檔大都發生在特定時間區間。解決此問題的方法之一是基于元數據,利用文檔發表日期等確定查詢的時間意圖。Kanhabua等[6]提出3種分析隱式時間查詢意圖的方法:①僅通過關鍵詞分析時間意圖;②使用僅考慮內容相關性排名結果的前k個文檔分析時間意圖;③通過前k個文檔的時間戳分析查詢的時間意圖。Dakka 等[7]在語言模型中加入時間因素,給每個時間段一個相關性評估分數,而有的文檔可能沒有可信的創建日期,且當文檔時間意圖和文檔創建時間相差很遠時,這種通過文檔創建日期分析查詢時間意圖的方法就不準確,可能降低檢索質量。Lin等[8]建立了一個時態信息的檢索模型TASE(Time-Aware Search Engine),此模型可以提取顯式和隱式表示時間的詞匯,計算網頁與每個時間表達式之間的相關評分,基于網頁和查詢之間的時間相關性和文本相關性對檢索結果重新排序。還有一種方法是基于用戶的查詢日志,如Metzler等[2]提出通過挖掘用戶日志以及分析不同時間的查詢頻率來識別與時間關聯較強的查詢。張曉娟等[9]的研究也是基于查詢日志,通過Sogou實驗室提供的查詢日志數據和新聞數據分析潛在時間意圖及其相關時間屬性,構建潛在時間意圖查詢檢索模型。
2 方法
包含時間意圖的查詢主要有兩種類型:①查詢中明確指定了時間約束,稱為顯式時間查詢;②用戶沒有提供明確的時間標準,但與查詢相關的結果都傾向于發生在某個特定的時間區間,稱為隱式時間查詢[6]。本文中,定義文檔集C是所有文檔的集合,C={d1,d2,d3,...,dn}。文檔di是一系列單詞的集合,di={w1,w2,w3,...,wm,t1,t2,t3,...,tn},其中wm 是文檔中沒有時間含義的詞匯,這些詞匯的集合記作dword; tn是文檔中表達時間的詞匯,這些詞匯的集合記作dtime,di={dword,dtime}。支持隱式時間查詢排名算法過程如下:①提交查詢到已建立索引的文檔集,得到僅考慮內容相關性的初始排名結果;②使用初始排名結果的前k個文檔,分析查詢的時間意圖;③在考慮查詢時間意圖的基礎上利用排名模型計算文檔的時間相關性得分;④結合內容相關性得分和時間相關性得分對結果重排,最后把新的排名結果返回給用戶。從以上工作流程可見,此算法主要有分析查詢的時間意圖和考慮時間因素的檢索模型這兩個主要模塊,下面對這兩個模塊進行詳細描述。
2.1 查詢時間意圖確定
本文提出一種分析隱式查詢時間意圖的方法。如果查詢的內容是關于著名人物或歷史上某個重大事件,通過前k個文檔內容時間確定查詢時間意圖,主要步驟如下:首先僅考慮內容相關性,在文檔集中檢索得到排名前k個文檔,這些文檔和查詢內容、時間相關的概率較大,所以前k個文檔的內容中某個時間點出現頻率越高,這個時間點屬于查詢時間意圖的可能性就越大。規定前k個結果中出現超過m(m≥0)次的時間點為用戶感興趣的一個時間點,這些時間點組成的集合為查詢q的時間意圖。過程如下:
INPUT:查詢qword,選取結果中前m個時間區間,文檔中時間點組成的集合DN OUTPUT: 符合查詢時間意圖的時間區間A A← HashMap map(key,value) //key:排名前k個結果中出現的時間點,value:時間點出現的頻率 DTopK ←retrieveTopKDoc (qword ,k) //僅考慮內容相關性檢索得到排名前k個文檔 for each {di∈DTopK} do for each {tj∈di} do if{tjkey} map.put(tj,1) else map.put(tj,value+1) end if end for end for A←map.selectTopMIntervals (m) //根據頻率選取前m個時間點 return A
2.2 檢索模型
隱式時間查詢q 由qword和時間意圖qtime組成,根據線性結合內容得分和時間相關性得分得到文檔d的最終得分S(q,d),公式如下:S(q,d)=α·S'(qword,dword)+(1-α)·S"(qtime,dtime)(1)endprint
α是調節內容相關性得分S'(qword,dword)和時間相關性得分S"(qtime,dtime)的參數。
由分析隱式時間意圖方法得到查詢的時間意圖qtime,qtime={t1',t2',t3',...,tn'},且t1'∩t2'∩t3'...∩tn'=。時間相關性得分S"(qtime,dtime)定義如下:S"(qtime,dtime)=P(qtime|dtime)=P(t1',t2',t3',...,tn'|dtime)(2)
qtime由一系列不重復的時間點組成,假設每個時間點彼此之間是相互獨立的,沒有依賴關系,則P(t1',t2',t3',...,tn'|dtime)=∏Q∈qtimeP(Q|dtime)(3)
相似地,文檔內容中也存在多個時間詞匯,dtime={t1,t2,...,tn},且t1∩t2∩...∩tn=。為了防止結果概率為0,使用Jelinek-Mercer 平滑方法。P(Q|dtime)計算公式如下: P(Q|dtime)=(1-λ)1|Dtime|∑T∈DtimeP(Q|T)+ λ1|dtime|∑T∈dtimeP(Q|T)(4)
λ∈[0,1],把整個文檔集當作一個文檔,|Dtime|是這個文檔中時間表達的個數,本文中所有的λ取值為0.85。時間點Q與時間點T表現形式不同,但可能指向同一個時間段,所以在計算P(Q|T)時需要考慮時間的不確定性。比較Q與T相差的時間天數,如果Q與T相差的時間在m天內(m≥0),P(Q|T)則為1,否則為0。P(Q|T)=1 (|Q-T|≤m),m≥00 否則 (5)
3 實驗
3.1 實驗設置
本文中使用的實驗數據是NTCIR-11 會議Temporal Information Access (Temporalia)任務中使用的文檔集,涵蓋了2011年5月到2013年3月約1 500個不同博客和新聞收集到的3.8M文檔[10]。使用Indri系統對文檔集構建索引,得到僅考慮內容相關性的排名結果。實驗使用方法定義如下:LMU-DIF方法利用公式(5)計算P(Q|T),并在此基礎上計算時間相關性得分,然后使用公式(6)對Indri系統的文檔原始得分0-1規范化,規范后的結果作為內容相關性得分。
Scorenorm=score-scoreminscoremax-scoremin(6)LMU-DIF-rankAdd和LMU-DIF計算時間相關性得分的方法相同,區別在于LMU-DIF-rankAdd方法使用公式(7)把Indri系統初始排名轉換為分數,然后把公式(6)規范后的結果作為內容相關性得分。
S"(qtime,dtime)=1rank+60(7)
3.2 實驗結果
本文使用平均查準率均值(MAP),前m個文檔的準確率(P@m)、前m個文檔的nDCG(nDCG@m)和前m個文檔的err(err@m)值來評價檢索結果質量。
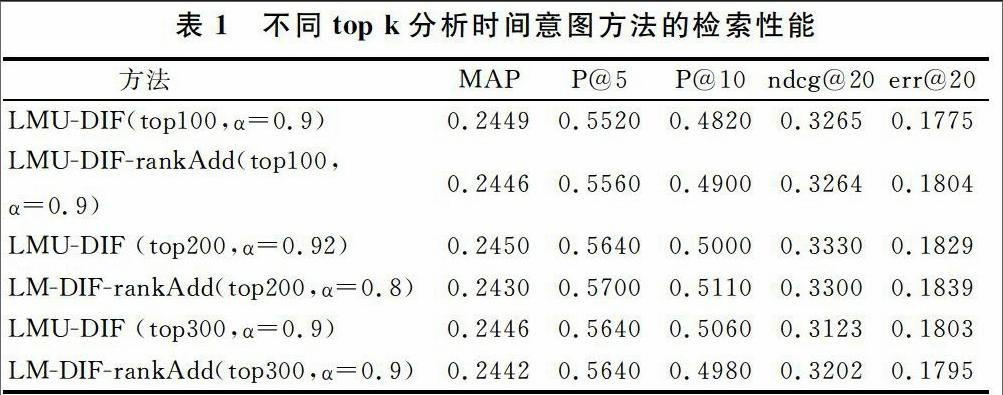
前面提出的一種分析時間意圖的方法是使用前k個文檔分析查詢時間意圖,k值的不同會影響檢索結果。表1列出不同k值對實驗結果的影響,可見1 000個文檔中取前200個文檔分析查詢時間意圖時檢索性能最好,所以本文實驗中值取200。
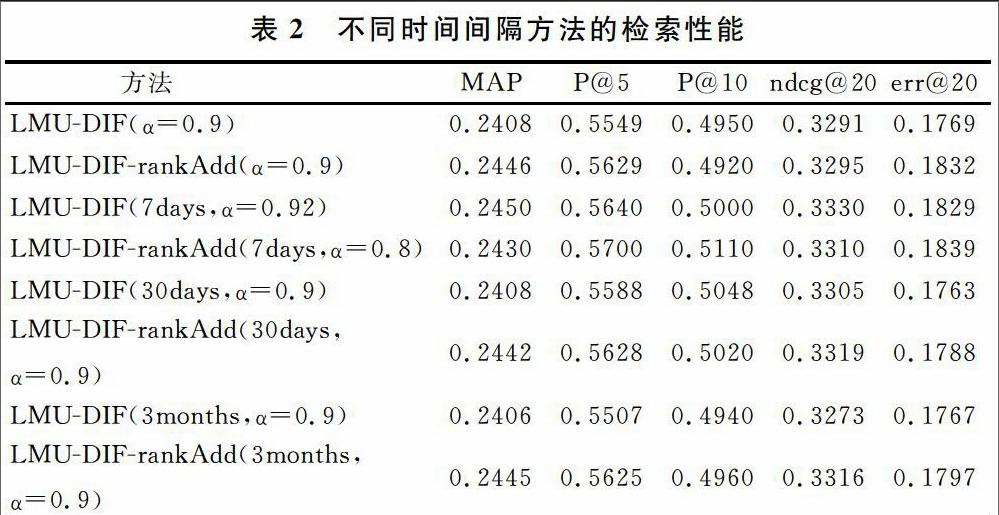
語言模型中計算值需要考慮時間不確定性,不同的時間間隔可能會影響排名結果。表2列出不同時間間隔(0天、7天、30天、3個月)下LMU-DIF和LMU-DIF-rankAdd方法的指標值。從表2可見,時間間隔取太大或太小都會降低結果性能,間隔7天時性能最好。
綜合上面的分析,表3列出了每個方法在參數配置最優情況下各指標的值,Baseline是僅考慮內容相關性的一個基準。總體上看,各種方法性能都有所提升,LMU-DIF-rankAdd方法比LMU-DIF更優,但都優于Baseline,表明本文提出的方法在改善搜索引擎性能方面有一定效果,排名模型需要考慮時間因素的影響。
4 結語
本文提出一種支持隱式時間查詢的文檔排名方法,該方法首先分析隱式查詢的時間意圖,在此基礎上線性計算時間相關性得分,結合時間相關性得分和內容相關性得分,把重排結果返回給用戶。實驗結果表明本方法具有一定的實用價值。
參考文獻:
[1] NUNES S, RGIO, RIBEIRO C, et al. Use of temporal expressions in web search, proceedings of the Ir research[C].European Conference on Advances in Information Retrieval,2008.
[2] METZLER D, JONES R, PENG F, et al. Improving search relevance for implicitly temporal queries [J]. Proceedings of Sigir, 2009(1):700-701.
[3] ALONSO O, STROTGEN J, BAEZA YATES R, et al. Temporal information retrieval:challenges and opportunities[J].Temporal Web Analytics Workshop at Www, 2011(1):8-9.
[4] BERBERICH K, BEDATHUR S, ALONSO O, et al. A language modeling approach for temporal information needs [M]. ECIR, 2010.
[5] JONES R, DIAZ F. Temporal profiles of queries [J]. Acm Transactions on Information Systems, 2007, 25(3): 14-16.
[6] KANHABUA N, NORVAG K. Determining time of queries for re-ranking search results[M].ECDL 2010.
[7] DAKKA W, GRAVANO L, IPEIROTIS P G. Answering general time-sensitive queries[J].Knowledge & Data Engineering IEEE Transactions on, 2012, 24(2): 220-350.
[8] LIN S, JIN P, ZHAO X, et al. Exploiting temporal information in Web search [J]. Expert Systems with Applications, 2014, 41(2): 331-411.
[9] 張曉娟, 陸偉, 周紅霞. 用戶查詢中潛在時間意圖分析及其檢索建模 [J]. 現代圖書情報技術, 2011(11): 38-43.
[10] JOHO H, JATOWT A, BLANCO R. NTCIR temporalia: a test collection for temporal information access research [M]. Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea,ACM,2014.endprint
