面向百度百科的化學(xué)知識(shí)圖譜構(gòu)建方法研究
2017-09-09 02:12:22鐘亮
軟件導(dǎo)刊 2017年8期
鐘亮
摘 要:針對(duì)百度百科這一數(shù)據(jù)源,構(gòu)建了化學(xué)知識(shí)圖譜。首先,利用網(wǎng)絡(luò)爬蟲技術(shù)對(duì)數(shù)據(jù)進(jìn)行采集與清洗;然后,采用中文分詞、實(shí)體識(shí)別、實(shí)體關(guān)系識(shí)別等技術(shù)對(duì)知識(shí)圖譜構(gòu)建方法進(jìn)行實(shí)證性研究,可視化實(shí)驗(yàn)所得實(shí)體及實(shí)體關(guān)系,并對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行了相關(guān)評(píng)價(jià)測(cè)試。最后,簡(jiǎn)要闡述了知識(shí)圖譜的應(yīng)用領(lǐng)域與發(fā)展優(yōu)勢(shì)。研究結(jié)果表明,實(shí)體關(guān)系識(shí)別的預(yù)測(cè)準(zhǔn)確率較高。
關(guān)鍵詞:百度百科; 知識(shí)圖譜; 網(wǎng)絡(luò)爬蟲; 實(shí)體識(shí)別
DOIDOI:10.11907/rjdk.172205
中圖分類號(hào):TP319
文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào)文章編號(hào):1672-7800(2017)008-0168-03
0 引言
知識(shí)圖譜(Mapping Knowledge Domains)是顯示科學(xué)知識(shí)發(fā)展進(jìn)程與結(jié)構(gòu)關(guān)系的譜系,具有“圖”、“譜”的雙重性質(zhì)和特征:既是可視化的知識(shí)圖形,又是序列化的知識(shí)譜系[1]。知識(shí)圖譜可以繪制、挖掘、分析和顯示科學(xué)技術(shù)知識(shí)以及它們之間的相互關(guān)系,是在大數(shù)據(jù)時(shí)代背景下產(chǎn)生的一種新型的海量知識(shí)管理與服務(wù)模式[2]。其研究目標(biāo)是借助現(xiàn)代技術(shù)與理論使知識(shí)可視化,讓人們更加方便、準(zhǔn)確地獲取知識(shí)。知識(shí)圖譜作為知識(shí)的載體,能用圖形化的方式將人們不易理解的信息形象地表示出來[3],通過內(nèi)容分析、引文分析、自然語言處理等方法和可視化的方式顯示知識(shí)結(jié)構(gòu)及其相互關(guān)系,既符合人類的認(rèn)知習(xí)慣,又充分利用了現(xiàn)代信息技術(shù);使用戶既能快速獲取知識(shí)及其之間的邏輯關(guān)系,又能從海量文獻(xiàn)中把握關(guān)鍵的知識(shí)點(diǎn)[4],還能從豐富的網(wǎng)絡(luò)知識(shí)庫中提取更多有效的知識(shí)進(jìn)行關(guān)系補(bǔ)充,從而更好地把握學(xué)科知識(shí)結(jié)構(gòu)。
隨著互聯(lián)網(wǎng)中用戶生成內(nèi)容和幵放鏈接數(shù)據(jù)等大量RDF數(shù)據(jù)被發(fā)布,互聯(lián)網(wǎng)逐步從僅包含網(wǎng)頁與網(wǎng)頁之間超鏈接的文檔萬維網(wǎng)轉(zhuǎn)變?yōu)榘罅棵枋龈鞣N實(shí)體和實(shí)體之間豐富關(guān)系的數(shù)據(jù)萬維網(wǎng)。在此背景下,Google公司于2012年推出了Google Knowledge Graph[5],其初衷是用于改善搜索結(jié)果。緊隨其后,國內(nèi)外的其它互聯(lián)網(wǎng)搜索引擎公司也紛紛構(gòu)建了自己的知識(shí)圖譜,例如微軟的Probase[6]、搜狗的“知立方”、百度的“知心”、清華大學(xué)構(gòu)建的XLore[7]、上海交通大學(xué)構(gòu)建的Zhishi.me[8]和復(fù)旦大學(xué)GDM實(shí)驗(yàn)室的“知識(shí)工場(chǎng)”等。
1 數(shù)據(jù)源分析
研究通過網(wǎng)絡(luò)爬蟲對(duì)百度百科中與“化學(xué)”主題相關(guān)的詞條信息進(jìn)行抓取,為知識(shí)抽取模塊產(chǎn)生原始數(shù)據(jù)基礎(chǔ)。在進(jìn)行爬蟲抓取和知識(shí)抽取時(shí)應(yīng)注意:百度百科中的基本單元為文章,一篇文章(消歧頁面除外)對(duì)應(yīng)一個(gè)實(shí)體,文章的標(biāo)題(title,即詞條名)通常為對(duì)應(yīng)實(shí)體的名稱;信息模塊以表格的形式存在,用于表述文章對(duì)應(yīng)實(shí)體的屬性;百度百科中存在重定向機(jī)制,用于當(dāng)用戶以不同的檢索條件檢索到同一篇文章時(shí)的定位;當(dāng)檢索條件蘊(yùn)含多種意義時(shí)進(jìn)行所有意義的列舉。
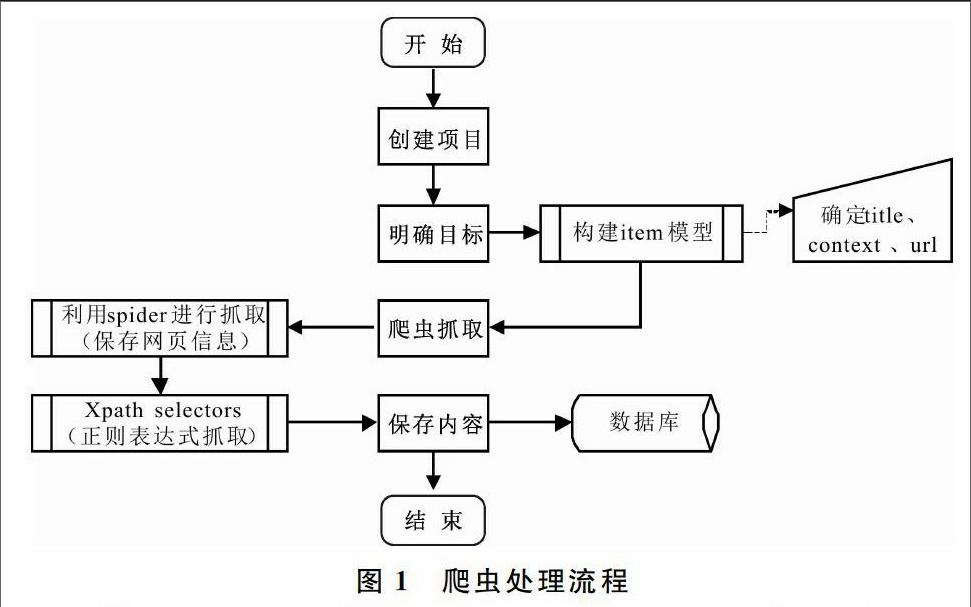
數(shù)據(jù)采集方式是運(yùn)用Java語言,通過網(wǎng)絡(luò)爬蟲的方式進(jìn)行的。其爬蟲抓取策略為:多線程、深度優(yōu)先遍歷、廣度優(yōu)先遍歷、反向連接數(shù)等策略,爬蟲處理流程如圖1所示。
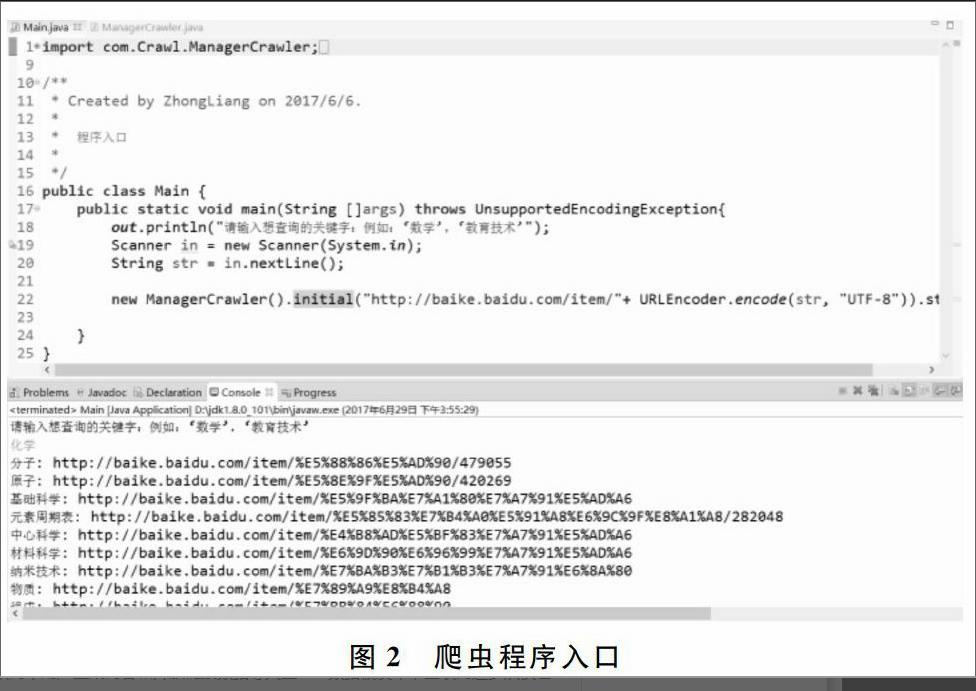
利用該爬蟲程序構(gòu)建了以“化學(xué)”這一關(guān)鍵詞為主題的百度百科數(shù)據(jù)集,并采用人工剔除的方式輔助篩選出了5 631個(gè)詞條信息(包括詞條名、詞條內(nèi)容與URL),其爬蟲程序入口如圖2所示。
2 知識(shí)圖譜構(gòu)建
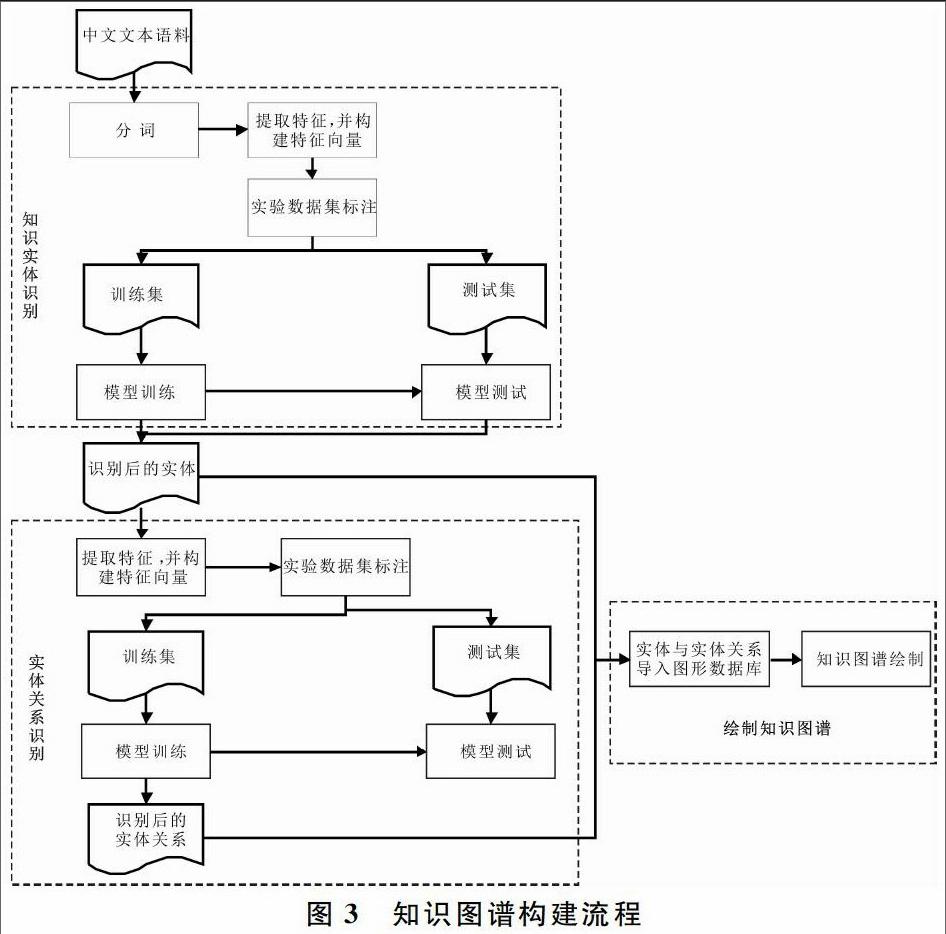
在知識(shí)圖譜構(gòu)建過程中,最重要的3個(gè)環(huán)節(jié)就是抽取知識(shí)實(shí)體、識(shí)別知識(shí)實(shí)體間關(guān)系與繪制知識(shí)圖譜。其中尤以知識(shí)實(shí)體抽取和知識(shí)實(shí)體間關(guān)系的識(shí)別最為關(guān)鍵。將知識(shí)單元抽取、知識(shí)間關(guān)系的識(shí)別映射為實(shí)體識(shí)別和實(shí)體關(guān)系識(shí)別后,就可以得到知識(shí)圖譜構(gòu)建流程,如圖3所示。
2.1 分詞
實(shí)驗(yàn)研究選擇R語言環(huán)境下的Rwordseg包進(jìn)行分詞。其中Rwordseg包是基于中科院的ICTCLAS中文分詞分析算法編寫而成的,可以實(shí)現(xiàn)中文分詞、關(guān)鍵詞提取、多級(jí)詞性標(biāo)注等功能,還可以導(dǎo)入自定義詞典進(jìn)行輔助分詞。分詞結(jié)果示例如圖4所示。
2.2 知識(shí)實(shí)體識(shí)別
在知識(shí)實(shí)體識(shí)別之前,需要對(duì)數(shù)據(jù)進(jìn)行預(yù)處理(包括語料的清洗、每個(gè)詞的上下文窗口詞提取、去除沒有實(shí)際意義的詞等),并進(jìn)行特征選擇(包括詞特征、詞性特征、詞典特征、上下文窗口特征、每個(gè)詞對(duì)應(yīng)的TF-IDF值等),構(gòu)建相應(yīng)的特征向量。
特征選擇過程中采用Python實(shí)現(xiàn)TF-IDF算法,其核心代碼如下:
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
將得到的詞語轉(zhuǎn)換為詞頻矩陣:
freWord = CountVectorizer()
統(tǒng)計(jì)每個(gè)詞語的tf-idf權(quán)值:
transformer = TfidfTransformer()
計(jì)算出tf-idf(第一個(gè)fit_transform),并將其轉(zhuǎn)換為tf-idf矩陣(第二個(gè)fit_transformer):
tfidf = transformer.fit_transform(freWord.fit_transform(data))
獲取詞袋模型中的所有詞語:
word = freWord.get_feature_names()
得到權(quán)重:
weight = tfidf.toarray()
2.3 實(shí)體關(guān)系識(shí)別
在知識(shí)實(shí)體識(shí)別之后,可以利用已識(shí)別的實(shí)體進(jìn)行實(shí)體間關(guān)系的識(shí)別。為了確保實(shí)體關(guān)系識(shí)別過程中所輸入信息的準(zhǔn)確性,仍需對(duì)實(shí)體識(shí)別結(jié)果進(jìn)行預(yù)處理(包括實(shí)體對(duì)提取與實(shí)體對(duì)標(biāo)注),最后針對(duì)預(yù)處理后的數(shù)據(jù)進(jìn)行特征選擇(包括實(shí)體特征、實(shí)體類型特征、實(shí)體相對(duì)位置特征、實(shí)體間距離特征、上下文窗口特征等)。endprint
2.4 實(shí)驗(yàn)結(jié)果分析
為了對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行評(píng)估,實(shí)驗(yàn)運(yùn)用了人工神經(jīng)網(wǎng)絡(luò)算法(ANN)對(duì)實(shí)驗(yàn)數(shù)據(jù)進(jìn)行訓(xùn)練和測(cè)試,實(shí)驗(yàn)評(píng)估納入3個(gè)評(píng)價(jià)指標(biāo),分別是準(zhǔn)確率、召回率與F-值,其計(jì)算公式如下:
準(zhǔn)確率=正確識(shí)別的實(shí)體數(shù)(正確識(shí)別的實(shí)體關(guān)系數(shù))識(shí)別出的實(shí)體總數(shù)(識(shí)別出的實(shí)體關(guān)系總數(shù))×100%(1)
召回率=正確識(shí)別的實(shí)體數(shù)(正確識(shí)別的實(shí)體關(guān)系數(shù))實(shí)際實(shí)體總數(shù)(實(shí)際實(shí)體關(guān)系總數(shù))×100%(2)
F=2×準(zhǔn)確率×召回率準(zhǔn)確率+召回率×100%(3)
分析結(jié)果見表1。
實(shí)驗(yàn)結(jié)果結(jié)果表明,實(shí)驗(yàn)對(duì)知識(shí)實(shí)體識(shí)別和實(shí)體關(guān)系識(shí)別效果有所不同,在知識(shí)實(shí)體判別中,F(xiàn)-值只有74.9%,而對(duì)于實(shí)體關(guān)系的判別,F(xiàn)-值達(dá)到了82.4%。從實(shí)驗(yàn)具體過程來看,主要有以下兩個(gè)原因:
①實(shí)驗(yàn)訓(xùn)練樣本較小。研究只篩選出5 631個(gè)實(shí)體參與樣本訓(xùn)練,影響了實(shí)驗(yàn)的實(shí)際效果。
②特征選擇粒度存在問題。此次實(shí)驗(yàn)在對(duì)特征進(jìn)行選擇時(shí),把詞作為特征提取單元,其目的是為了使上下文窗口涵蓋更多的信息。詞與單個(gè)字符比較而言,雖然包含的信息較多,但是粒度也相對(duì)較粗,在分析過程中可能會(huì)丟失一些比較重要的字符集信息。
2.5 知識(shí)圖譜繪制
實(shí)驗(yàn)獲得的實(shí)體和實(shí)體關(guān)系可用來繪制知識(shí)圖譜的知識(shí)單元和知識(shí)單元間的關(guān)系。研究采用NLPIR實(shí)體抽取系統(tǒng)中基于角色標(biāo)注的實(shí)體抽取方法對(duì)實(shí)體進(jìn)行抽取,并運(yùn)用基于POS-CBOW的Word2vec語義擴(kuò)展模型對(duì)實(shí)體關(guān)系進(jìn)行抽取,知識(shí)單元與知識(shí)單元關(guān)系抽取示例如圖5所示。
3 結(jié)語
研究構(gòu)建了面向百度百科的化學(xué)知識(shí)圖譜構(gòu)建方法,具體構(gòu)建過程包括知識(shí)實(shí)體抽取、實(shí)體間關(guān)系抽取和繪制知識(shí)圖譜3個(gè)步驟。
知識(shí)圖譜為互聯(lián)網(wǎng)上海量、異構(gòu)、動(dòng)態(tài)的大數(shù)據(jù)表達(dá)、組織、管理以及利用提供了一種更為有效的方式,使得網(wǎng)絡(luò)的智能化水平更高,更加接近于人類的認(rèn)知思維。目前,知識(shí)圖譜已在智能搜索、深度問答、社交網(wǎng)絡(luò)以及一些垂直行業(yè)中有所應(yīng)用[9]。但大規(guī)模知識(shí)圖譜的應(yīng)用場(chǎng)景和方式還比較有限,許多領(lǐng)域的應(yīng)用也只是處于初級(jí)階段,具有很大的可擴(kuò)展空間。人們?cè)谕诰蛐枨蟆⑻剿髦R(shí)圖譜的應(yīng)用場(chǎng)景時(shí),應(yīng)充分考慮知識(shí)圖譜的以下優(yōu)勢(shì):①對(duì)海量、動(dòng)態(tài)、異構(gòu)的半結(jié)構(gòu)化與非結(jié)構(gòu)化數(shù)據(jù)的有效組織和表達(dá)能力;②借助強(qiáng)大知識(shí)庫進(jìn)行深度知識(shí)推理的能力;③與類腦科學(xué)、深度學(xué)習(xí)等領(lǐng)域相結(jié)合,逐步擴(kuò)展人類認(rèn)知能力。
在熟練掌握知識(shí)圖譜相關(guān)理論與技術(shù)的基礎(chǔ)上,敏銳感知人們的需求,可以為大規(guī)模知識(shí)圖譜的應(yīng)用找到更寬廣的道路。
參考文獻(xiàn):
[1] 曾宜玲.淺析教育學(xué)知識(shí)圖譜的有用性[J].文學(xué)教育:中,2017,13(2): 112-112.
[2] 劉則淵, 陳悅, 侯海燕,等.科學(xué)知識(shí)圖譜: 方法與應(yīng)用[M].北京:人民出版社, 2008.
[3] 陳悅, 劉則淵, 陳勁,等.科學(xué)知識(shí)圖譜的發(fā)展歷程[J].科學(xué)學(xué)研究,2008,26(3):449-460.
[4] 唐欽能, 高峰, 王金平.知識(shí)地圖相關(guān)概念辨析及其研究進(jìn)展[J].情報(bào)理論與實(shí)踐,2011,34(1):121-125.
[5] STEINER T,VERBORGH R,GABARRO J, et al. Adding realtime coverage to the Google knowledge graph[C].The International Conference on Posters & Demonstrations Track. CEUR-WS.org, 2012: 65-68.
[6] WU W,LI H,WANG H, et al. Probase: a probabilistic taxonomy for text understanding[J]. In:SIGMOD,2012: 481-492.
[7] WANG Z,LI J,WANG Z,et al. XLore: a large-scale english-Chinese bilingual knowledge graph[C]. International Semantic Web Conference(Posters \\& Demos),2013: 121-124.
[8] XING NIU,XINRUO SUN,HAOFEN WANG,et al. Zhishi.me: weaving chinese linking open data[C]. International Conference on the Semantic Web. Springer-Verlag, 2011: 205-220.
[9] 徐增林, 盛泳潘, 賀麗榮, 等. 知識(shí)圖譜技術(shù)綜述[J].電子科技大學(xué)學(xué)報(bào), 2016, 45(4): 589-606.endprint
