基于組合增量聚類的數據流異常檢測研究?
2017-09-12 08:49:45許福徐建
計算機與數字工程 2017年8期
關鍵詞:檢測
許福徐建
基于組合增量聚類的數據流異常檢測研究?
許福徐建
(南京理工大學計算機科學與工程學院南京210094)
面向數據流的異常檢測方法在諸如實時監控、網絡入侵檢測等領域有著廣泛的應用。然而,數據流連續不斷的特點,以及數據流處理的特殊性和時效性等限制使得傳統的聚類算法已不再適用,因此增量聚類成為當前面向數據流異常檢測的研究熱點。論文在改進了兩類增量聚類方法的基礎上,針對單一增量聚類檢測率低,誤報率較高的問題,提出了一種基于組合增量聚類的數據流異常檢測方法,該方法以改進的增量聚類算法為基礎,設計了有效的共識函數對多種聚類算法的結果進行融合。實驗結果表明,改進的聚類算法在處理效率上有明顯提升,適用于增量聚類,并且提出的組合增量聚類相比于單一聚類方法,具有更好的聚類性能。
數據流;異常檢測;增量聚類;子空間聚類;聚類融合
Class NumberTP391
1引言
數據流異常檢測技術[14~15]是數據挖掘領域的研究熱點之一,在網絡安全、信用欺詐和金融分析等領域有著廣泛的應用。隨著大數據時代的到來,許多數據如電話記錄、網絡文件等都以數據流的形式出現,然而數據流具有的海量、概念漂移等特點對于現有的數據挖掘方法研究提出了一些新的挑戰。目前,研究人員針對數據流的上述特點,開展了不少研究工作來應對這些挑戰。例如,文獻[1]中提出基于CluStream算法的數據流聚類框架,引入了微簇和時間幀概念,將數據流聚類過程分為在線和離線兩個階段,在線部分實時處理流數據,離線部分提供所有時間的聚類結果。文獻[11]提出一種基于數據流聚類,盡管這些研究工作取得了不錯的檢測效果,然而仍然面臨著一些問題,比如聚類算法的處理效率不高,隨著新數據的不斷到來,需要不斷調整和更新聚類的結果,增量聚類[8]的效率不高等。此外,任何聚類算法本身都有一定的局限性,將不同聚類算法相結合,采用分階段、分層次的增量聚類,即將聚類對象加細,或者將同一時刻不同的聚類結果進行融合來考慮,有機會去進一步改善聚類的結果穩定性,提升聚類質量。基于上述分析,研究有效的增量聚類方法來進一步提升聚類的效率和檢測效果成為一個重要的研究課題。
本文針對傳統聚類方法[9,12]的局限性以及單一增量聚類方法存在的隨機性大、不穩定和準確性低等缺點,在比較分析不同聚類算法的思想、應用領域和應用特點的基礎上,提出一種基于組合增量聚類的數據流異常檢測方法,該方法以改進的子空間聚類算法和DBSCAN聚類作為基聚類算法,設計基于投票策略的共識函數用于實現不同聚類結果融合,并驗證了算法的有效性。
2改進的子空間聚類算法
在面向數據流異常檢測的聚類研究中,所要處理的數據通常是高維數據。作為一種有效的解決高維數據[6]聚類的方法,子空間聚類[2,5,10]在諸如圖像處理、計算機視覺等領域有著重要的應用。文獻[3]提出了一種基于稀疏表示的隱子空間聚類算法LSC(Latent Subspace Clustering),其使用K-SVD算法訓練字典,雖然字典有優秀的重構能力,但是缺乏足夠的判別信息,導致LSC算法的聚類精度不高。針對以上問題,Jiang等[7]提出了具有標簽一致性的LC-KSVD算法來改進字典訓練方法以提高LSC算法的聚類精度,然而,字典訓練階段的耗時也隨之大幅增加,數據流聚類受到時間和內存、CPU等資源的限制。為了緩解這些方面的限制,能將LSC應用于組合增量聚類方法中,本文提出了一種新的增量式字典訓練方法,使其效率能滿足增量聚類要求。
稀疏表示[17~18]是指用盡可能少的基或字典原子的線性組合表示數據,其目的在于刻畫數據的子空間特性,提供了一種高維數據在低維子空間表示的自然模型。字典訓練表示是從數據中學習稀疏表示下的最優表示,同時訓練初始字典使得字典的原子特性更接近于所需表示的原始信號,以此獲得誤差更小的新字典。LSC算法在構建字典的過程中具有一定的隨機性,使得訓練出的字典缺少足夠的重構能力和判別能力。為了改進這一缺陷,綜合考慮重構誤差,判別能力以及線性分類性能這三方面因素提出了新的學習模型:
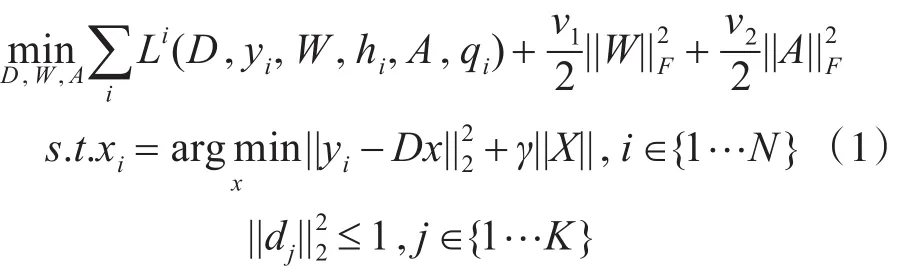
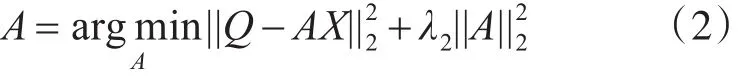
其解為
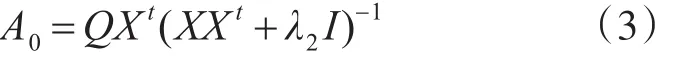
參數W的初始化與參數A類似,利用上訴模型求得如下的解:
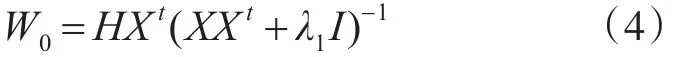
其中,參數X是在已知初始字典D0的情況下,使用K-SVD算法所求得的信號Y的稀疏表示系數矩陣。
具體的增量式字典訓練算法如算法1所示。
算法1增量式字典訓練算法
輸入:Y,m,D1,A1,W1,ρ,n,M,μ,v1,v2,b
輸出:測試信號Y2的聚類標簽
1)將信號Y分為Y1∈RK×T和Y2∈RK×N兩部分,Y1為帶有標簽信息的訓練信號用于訓練字典,Y2為不帶標簽信息的測試信號用于聚類算法。
2)求得訓練信號Y1的判別式稀疏編碼矩陣Q∈RM×T和類標矩陣H∈Rm×T。
3)增量式訓練字典D:
for i=1…n:
(1)依次從信號Y1中隨機抽取一批信號
其中D代表字典矩陣,X是稀疏表示稀疏矩陣,A=|X|,W是非負臨接矩陣,α和β是平滑因子,Q是關于信號Y的判別式稀疏編碼矩陣。
在使用字典學習模型時,需要對參數D,A,W進行初始化,具體方法如下:
對于字典D的初始化,針對每一類別的信號用K-SVD算法訓練得到各自類別的字典,再將訓練得到的字典合并為一個完整的初始字典D0,即所有類共享的字典。
對于參數A的初始化,使用多元嶺回歸正則化模型來求解其初始值,相應的目標函數如下計算其對應的qi∈Q和 hi∈H。
for j=1…T/b:
(2)計算y(i)的稀疏表示xi。
(3)根據xi中非零值的位置,得到索引集合Ai,并計算輔助變量φ1和φ2。
(4)選擇學習率ρi=min(ρ,ρi0/i)。
(5)通過公式更新參數D,A,W
end for
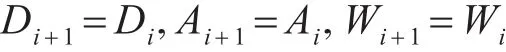
end for
4)使用OMP算法,利用字典D構建測試信號Y2的稀疏表示矩陣C∈RM×N,使得Y=D C。
5)構建矩陣A=|C|,計算度矩陣D1和D2,求得矩陣
6)使用SVD奇異值分解算法計算矩陣An的前[logm2]個左右奇異向量和
8)對logm2維數據集Z進行K-means[13]聚類,聚類標簽的最后N行是測試信號Y2的聚類結果。
在增量式字典訓練算法中,使用的字典訓練模型與LSC算法類似,但求解最優化的方式不同,使用增量式算法每次讀取一小批信號來訓練字典,并用梯度下降算法更新最優參數,由于梯度下降算法擁有較快的尋優速度,因此增量式字典訓練算法在保證字典判別性的同時,減少了字典訓練的耗時。
3增量DBSCAN聚類算法
DBSCAN[4]是代表性的基于密度的聚類算法,其顯著優點是聚類速度快且能夠有效處理噪聲點和發現任意形狀的空間聚類。然而,此算法[16]每次只能孤立地處理一個更新,存在太多的冗余操作,從而增量聚類的效率很低。為了克服上述缺點,本文提出一種支持批量更新的改進算法,該算法利用基于密度的聚類特性來提高增量聚類的效率。
·ε鄰域:以對象p為中心,ε為半徑的空間,其中ε>0;
·核心對象:如果對象p的ε鄰域內的樣本數大于等于Minpts,則稱p為核心對象;
·直接密度可達:如果對象p在核心對象k的ε鄰域內,則p是從k直接密度可達的;
·密度可達:存在對象鏈p1,p2,…,pn,pi+1是從pi直接密度可達,則pn從p1密度可達;
假設D為對象集合,p為插入或移除的對象,
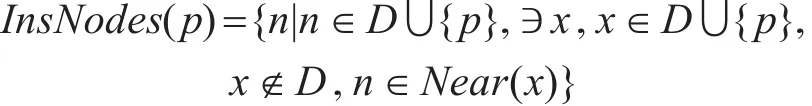
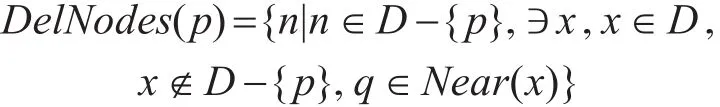
分別表示對象插入和移除操作,Near(x)表示x的鄰域對象,n與x均為核心對象。
在批量模式中,無論插入還是移除對象p時,都會影響其ε鄰域對象密度。插入對象時,可能會出現噪聲、新的聚類、歸入某一聚類、合并相鄰聚類等影響;而移除對象時,可能會出現噪聲、聚類撤銷、聚類對象減少、分裂聚類等影響。因此,下文依次闡述支持批量更新是對象插入和對象移除的方法。
假設批量插入對象集合為InsList。對象插入的處理過程如下:
1:forall p in InsList
2:If InsNod es(p)=φand Near(p)內無核心對象then p→噪聲
3:If核心對象in InsNodes(p)且不與任一聚類核心對象密度可達
4:then創建新聚類
5:If核心對象in InsNod es(p)均屬于同一個聚類,then將p歸入此聚類中
6:If核心對象in InsNod es(p)不屬于同一個聚類,且互相密度可達,
7:then合并這些聚類
8:end for
批量插入新對象時,算法以插入對象為核心點進行擴充,尋找從該對象出發的所有密度可達的數據點,與InsList順序無關,因此能較快發現新聚類中的對象,減少了聚類合并的處理。聚類合并時,算法也能快速發現不同聚類間的核心對象,減少了部分不必要的聚類生成再合并的處理,提高了聚類合并的效率。批量插入模式中,算法只需檢索一次插入對象,避免了更新對象的重復檢索。
刪除對象時,由于待刪除對象具有聚類的標識,可能會對原聚類產生影響,例如引起聚類分裂,此時處理方法為:記錄下密度不可達的點,找出所有可能引起分裂的核心對象后,再選擇任一核心對象檢索其密度可達對象,最終求出對象的直接密度可達對象。該方法最多檢索一遍聚類中的對象,就可得到聚類最后的分裂情況,提高了增量聚類的效率。
假設待刪除對象集合為DelList,其具體處理過程是:
1:從DelList中選取屬于同一個聚類的一組對象,設為S
2:forall p in S
3:If DelNodes(p)≠φand DelNod es(p)內對象彼此不能直接密度可達
4:then從對象集選取代表點加入到d_link
5:If p in d_link
6:if p有直接密度可達核心對象and D為p的直接密度可達核心對象集合
7:then從D中選擇任一對象替換p
8:else delete p from d_link(p直接密度可達的對象變為噪聲)
9:end for
10:while d_link≠φ(刪除對象p)
11:p=pop(d_link)p加入到分裂后形成的聚類Q R為p的密度可達對象集合
12:for q in R
13:ifq in d_link
14:then delete q and Q=Q+{q}
15:End for
16:end while
假設算法已有N個對象,增量插入M個對象時,原算法可能需要檢索M次已有對象集,時間復雜度為O(N*M),而以上算法的處理思路最多檢索一遍已有對象集即可得到最終分裂結果,時間復雜度為O(N),算法時間復雜度大大降低,提高了增量聚類的效率,同時該算法也消除了一些刪除對象的多余的密度可達關系的檢索。
4基于聚類融合的增量聚類算法
為了避免使用單一聚類算法的局限性,本文設計一種組合聚類分析算法,并以改進的子空間聚類算法和DBSCAN聚類算法作為基聚類算法,設計基于投票策略的共識函數實現不同聚類結果融合,綜合利用了不同聚類算法的優點,從不同角度對空間樣本進行全方位的聚類。
聚類融合是指將多個聚類算法或者同一個聚類算法不同參數下得到的聚類成員進行合并,其可形式化地表述為:假設有n個數據點x= {x1,x2,x3,…,xn},對數據集x使用H個聚類算法或用一個聚類算法運行H次得到H個聚類成員,H={h1,h2,h3,…,hH},其中hk(k=1,2,3,…,H)為對第k次聚類結果,然后設計一種有效的共識函數,將H個聚類成員的聚類結果進行合并,得到聚類融合的結果,具體過程如圖1所示。
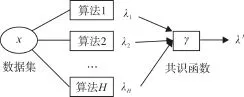
圖1 聚類融合過程
聚類融合[19~20]技術主要分為兩個階段:1)產生n個具有差異性的聚類結果,本文中主要采用兩種改進的聚類算法,對同一個數據集進行多次聚類得到;2)設計有效的共識函數,對聚類成員進行集成得到聚類結果。下面重點介紹共識函數的設計。
目前常用的共識函數構造方法主要有信息論方法、投票法、共聯矩陣法、超圖法和混合模型法等。本文采用基于投票策略的聚類融合策略,如算法2所示。
算法2:基于投票策略的聚類融合
輸入:數據集S,異常簇記錄數閾值θ,異常次數閾值λ
輸出:異常集OS
1:初始化la[N]=0 j=0
2:while j<h do
3:采用LSC/DBSCAN作為基聚類算法,生成簇集合C={C1,C2,…,Cw}
4:l=0
5:while l<w do
6:if|Cl|<θ
7:then Cl被標記為候選異常
8:?pi∈Cl(i∈[1,N])
9:la[i-1]++
10:end if
11:l++
12:end while
13:i=0,OS=?
14:while i<N do
15:if la[i]>λ
16:then pi被標記為真正的異常,O S=OS∪{pi}
17:end if
18:end while
其中,N表示記錄總數,h表示融合次數,元素la[i](i∈1,N)表示在h次不同劃分中對象pi被標記為異常的次數。以子空間聚類算法和DB?SCAN算法為基礎,對數據集進行多次聚類,將每次聚類形成的簇集合中包含對象數小于閾值θ的簇所有對象都作為候選異常點,統計異常次數加1。最后,將多次檢測結果進行融合,如果一個數據點的異常投票數超過異常閾值λ,這個數據點看作異常點。
5實驗
本文選用KDD Cup99數據集進行模型實驗。該數據集是麻省理工學院提供的網絡入侵檢測評估測試數據集,被廣泛應用于入侵檢測算法的檢驗。數據集收集了9個星期網絡連接和系統審計數據,大約500萬條連接記錄。本次實驗從KDD Cup99中隨機抽取40000條網絡連接記錄,分為四組數據子集test1,test2,test3,test4。每個測試集包含10000條網絡連接記錄,其中正常行為占90%,異常行為占10%。
為了評價和比較各種異常檢測方法的優劣,需要利用相關的評價指標體系來衡量。檢測率、誤報率,兩者是評價異常檢測最重要的指標。兩者具體用公式描述為


即
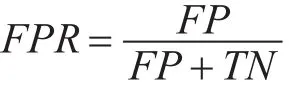
標準化信息(Normalized Mutual information,NMI)常用在聚類中,度量兩個聚類結果的相近程度。
為了驗證改進的子空間聚類算法的精度和運行時間開銷,將改進的增量子空間聚類與LSC算法進行比較。在字典訓練中,為了保證實驗的隨機性,實驗中隨機選取m=2,…,8類,即m個尺度劃分,每個類別選取T=60個信號構成包含T*m列的訓練數據集,用于字典訓練,剩余的信號構成測試數據集,用于測試。每個類別實驗重復40次,統計兩種聚類算法的整體耗時和聚類精度,實驗結果如圖2,圖3所示,增量LSC相比LSC不同類簇之間區分度更明顯,聚類效果更好,還能保證較快的運行速度。
即
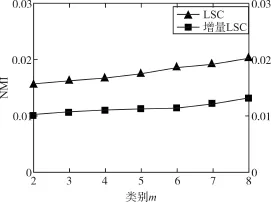
圖2 NMI值
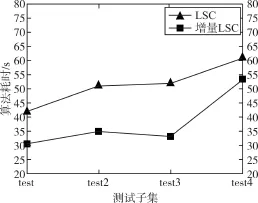
圖3 算法耗時
我們將本文提出的批量模式的DBSCAN與非批量的增量聚類進行比較。實驗每個測試集選取2000個對象進行DBSCAN聚類,然后模擬數據流批量插入新數據,進行增量聚類。如圖4所示,可以看出批量模式處理效率高于非批量模式,特別是隨著數據的不斷插入,當形成新聚類時或發生聚類合并時批量模式速度優勢更明顯,與預期結果相符合。
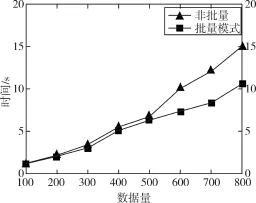
圖4 算法耗時
為了驗證本文提出的模型聚類效果優于單一聚類算法,將組合模型的聚類結果與單獨使用子空間聚類算法和DBSCAN算法的聚類結果進行了比較。為了保證實驗的正確性,針對每個模型每個測試子集進行了10次實驗,如圖5和圖6所示。
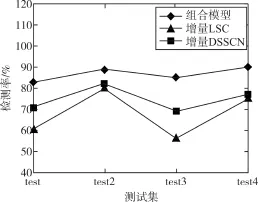
圖5 10次實驗檢測率平均值
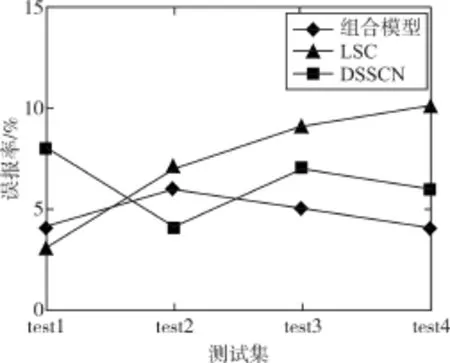
圖6 10次實驗誤報率平均值
從圖5和圖6可以看出,組合模型算法檢測率較高,誤報率較低,且對不同數據集的檢測率穩定,使用子空間聚類、密度聚類算法進行數據集的組合聚類分析,能夠在不改變原有數據屬性的情況下,通過多次和多角度的聚類,有效提高入侵行為的檢測率。
6結語
鑒于傳統增量聚類算法存在的不足,本文將聚類融合方法引入數據流增量聚類中,提出了基于聚類融合的數據流異常檢測方法,以避免由單一聚類帶來的局限性和隨機性的缺點。該算法由子空間聚類算法和DBSCAN聚類算法產生聚類成員,采用聚類融合方法進行融合,從而獲得聚類的結果。通過對KDD數據集進行實例分析,表明了改進的組合增量聚類算法能夠改善單一聚類不穩定性和隨機性,具有很好的聚類效果。
[1]Aggarwal C C,Yu P S.A Framework for Clustering Uncer?tain Data Streams[C]//IEEE,International Conference on Data Engineering.IEEE,2008:150-159.
[2]朱林,雷景生,畢忠勤,等.一種基于數據流的軟子空間聚類算法[J].軟件學報,2013(11):2610-2627.
ZHU Lin,LEI Jingsheng,BI Zhongqin,et al.Soft Sub? space Clustering Algorithm for Streaming Data[J].Journal of Software,2013(11):2610-2627.
[3]Adler A,Elad M,Hel-Or Y.Probabilistic Subspace Clus?tering Via Sparse Representations[J].IEEE Signal Pro?cessing Letters,2013,20(1):63-66.
[4]Ester M,Kriegel H P,Sander J,et al.Incremental Clus?tering for Mining in a Data Warehousing Environment[C]//VLDB'98,Proceedings of,International Conference on Very Large Data Bases,August 24-27,1998,New York City,New York,USA.1998:323-333.
[5]Ller E,Nnemann S,Assent I,etal.Evaluating clustering in subspace projections of high dimensional data[J].Pro?ceedings of the VLDB Endowment,2009,2(1):1270-1281.
[6]Kriegel H P,Ger P,Zimek A.Clustering high-dimension?al data:A survey on subspace clustering,pattern-based clustering,and correlation clustering[J].ACM Transac?tions on Knowledge Discovery from Data,2009,3(1):337-348.
[7]Karimian S H,Kelarestaghi M,Hashemi S.I-IncLOF:Im?proved incremental local outlier detection for data streams[M].2012.
[8]蔣盛益,楊博泓,王連喜.一種基于增量式譜聚類的動態社區自適應發現算法[J].自動化學報,2015(12):2017-2025.
JIANG Shengyi,YANG Bohong,WANG Lianxi.An Adap?tive Dynamic Community Detection Algorithm Based on Incremental Spectral Clustering[J].Acta Automatica Sini?ca,2015(12):2017-2025.
[9]李桃迎,陳燕,秦勝君,等.增量聚類算法綜述[J].科學技術與工程,2010(35):8752-8759.
LI Taoying,CHEN Yan,Qin Shengjun,etal.Review of In?cremental Clustering Algorithm[J].Science Technology and Engineering,2010(35):8752-8759.
[10]劉展杰,陳曉云.局部子空間聚類[J].自動化學報,2016,42(8):1238-1247.
LIU Zhanjie,CHEN Xiaoyun.Local Subspace Clustering[J].Journal of Automatica Sinica,2016,42(8):1238-1247.
[11]李艷紅,李德玉,崔夢天,等.基于數據流的網絡入侵實時檢測框架[J].計算機應用,2015,35(2):416-419.
LI Yanhong,LI Deyu,CUI Mengtian,et al.Real-time Detection Framework for Network Intrusion Based on Da?ta Stream[J].Computer Application,2015,35(2):416-419.
[12]Akter M,Rahman M O,Islam M N,et al.Incremental clustering-based object tracking in wireless sensor net?works[C]//International Conference on NETWORKING Systems and Security.IEEE,2015:1-6.
[13]Jonathan D A S,Hruschka E R.Extending k-Means-Based Algorithms for Evolving Data Streams with Variable Number of Clusters[C]//International Con?ference on Machine Learning and Applications and Workshops.IEEE Computer Society,2011:14-19.
[14]耿志強,姬威,韓永明,等.基于維度最大熵數據流聚類的異常檢測方法[J].控制與決策,2016(2):343-348.
GENG Zhiqiang,JI Wei,HAN Yongming,et al.Data Stream Clustering Algorithm Based on the Maximum En?tropy of Data Dimension and its Applications for Anoma?ly Detection[J].Control and Decision,2016(2):343-348.
[15]Sommer R,Paxson V.Outside the Closed World:On Us?ing Machine Learning for Network Intrusion Detection[C]//Security and Privacy.IEEE,2010:305-316.
[16]Patwary M M A,Palsetia D,Agrawal A,et al.A new scalable parallel DBSCAN algorithm using the dis?joint-setdata structure[C]//SC Conference,2012:1-11.
[17]Elhamifar E,Vidal R.Clustering disjoint subspaces via sparse representation[C]//Acoustics Speech and Signal Processing(ICASSP),2010 IEEE International Confer?ence on.IEEE,2010:1926-1929.
[18]Feng J,Lin Z,Xu H,etal.Robust Subspace Segmenta?tion with Block-Diagonal Prior[J].2014:3818-3825.
[19]周林,平西建,徐森,等.基于譜聚類的聚類集成算法[J].自動化學報,2012(8):1335-1342.
ZHOU Lin,PING Xijian,XU Sen,et al.Cluster Ensem?ble Based on Spectral Clustering[J].Acta Automatica Si?nica,2012(8):1335-1342.
[20]李桃迎,陳燕,張金松,等.基于聚類融合的混合屬性數據增量聚類算法[J].控制與決策,2012(4):603-608.
LI Taoying,CHEN Yan,ZHANG Jinsong,et al.Incre?mental Clustering Algorithm of Mixed Numericaland Cat?egorical Data Based on Clustering ensemble[J].Control and Decision,2012(4):603-608.
Research on Data Stream Amonaly Detection Using Incremental Clustering Ensemble
XU Fu XU Jian
(Schoolof Computer Science and Engineering,Nanjing University ofScience and Technology,Nanjing 210094)
Anomaly detection in data stream has gained a high attraction due to its applications,including real-time surveil?lance,network intrusion detection.However,traditionalclustering is no longer suitable due to the particularity and timeliness ofthe data stream and the continuous characteristics of the data flow.Therefore,incremental clustering has become the research hotspots towards anomaly detection in data stream.An anomaly detection modelin data stream is proposed based on two improved incremen?tal clustering aiming at the problem of low efficiency,high false positives and lack of pertinence of single clustering.The mothod is based on improved incrementalclustering and an effective consensus function is designed to merge the results ofa variety ofcluster?ing algorithms.The experimental results show that the improved clustering algorithms are applicable to incremental clustering and they have better efficiency and better clustering resultthan single clustering method.
data stream,anomaly detection,incrementalclustering,subspace clustering,clustering ensemble
TP391
10.3969/j.issn.1672-9722.2017.08.003
2017年3月19日,
2017年4月23日
國家自然科學基金項目“虛擬計算環境下的軟件自愈機理和方法研究”(編號:61300053)資助。
許福,男,碩士,研究方向:數據挖掘。徐建,副教授,博士,研究方向:數據挖掘。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
