基于聚類挖掘算法的微博用戶興趣發現的實現
2017-10-12 03:35:15鄭杰輝
網絡安全技術與應用 2017年10期
◆鄭杰輝
(廈門海洋職業技術學院 福建 361012)
基于聚類挖掘算法的微博用戶興趣發現的實現
◆鄭杰輝
(廈門海洋職業技術學院 福建 361012)
社會媒體是用戶分享與獲取信息的重要平臺,本文基于微博用戶數據,運用數據挖掘中的聚類算法,提出了微博用戶興趣的發現方法,實現了微博好友的分組和好友推薦,為新媒體社交網絡平臺上的新聞推薦和精準營銷,進行了有益的探索。在探索聚類算法的過程中,本文針對K-means算法的不足之處,結合粒子群算法的優勢,提出了改進后的粒子群K-means算法,該算法在微博用戶興趣發現中提高了聚類的效果。
微博用戶;聚類算法;PSO-kmeans;用戶興趣發現
0 引言
微博即微型博客,是一種以關注分享為模式的新興社交媒體,其內容少、發布快、形式多樣正好適應了人們對信息實時的、準確的、多樣的分享交流需求。微博可以讓用戶在任意時刻、地點分享和瀏覽相關信息,其他用戶也可以通過瀏覽微博平臺上的信息來了解最新的熱點問題和最有價值的信息。用戶在使用微博的時候,瀏覽什么樣的內容,關注什么樣的好友是根據其興趣、偏好、習慣來確定的。因此,對于有相似興趣和愛好的用戶,實施有效信息的推廣以及精準營銷等具有非常重要的價值。
1 數據挖掘技術
1.1 數據挖掘技術
伴隨著數據庫中數據量的飛速增長,數據量越來越大,形成了海量數據。這些海量數據中蘊含著大量的、潛在的知識,為了從海量數據中提取和挖掘有效的知識,數據挖掘技術應運而生。可以說,數據挖掘是綜合了多個學科、多個領域而誕生的一種新的技術,通過數據挖掘提高對信息的處理效率,從而挖掘出數據背后潛在的知識和價值,為管理者提供有效的決策。當然,對于數據挖掘,目前還沒有統一的界定,但是,在實踐中,一般包含以下過程:
(1)確定業務對象。需要明確挖掘的數據所屬領域,在此基礎上確定挖掘的主題。
(2)數據準備。通過數據源獲取需要挖掘的數據,然后對數據進行預處理,包括數據清洗、數據合并、數據轉換等。
(3)數據挖掘。使用數據挖掘的相關算法和方法,如關聯規則、分類、聚類等對數據進行挖掘,從數據中提取有價值的知識。
(4)知識的解釋和評估。通過挖掘獲取的結果是否有用,需要對知識進行解釋和評估,使得這些知識能夠被理解。
1.2 聚類分析
聚類分析是數據挖掘中重要的方法之一,是一種無需監督的自適應學習過程,該技術所分析的數據具有隨機性、不確定性等。對數據進行聚類分析的方法有很多種類,可以分為:劃分方法、層次方法、局部方法、模型方法等。針對劃分方法,涉及到的算法有:K-means算法、Pam算法、Clara算法等;針對基于層次的方法,具體有自上而下和自下而上的聚類算法;基于模型的方法有統計學方法和神經元網絡方法等。
1.3 聚類評價的比較
聚類評價可分為過程評價和結果評價,過程性評價要求聚類算法要具有較強的可伸縮性,要求算法能夠針對不同大小的數據量、不同的數據類型等具備相應的處理能力;而結果評價主要評價聚類結果的好壞,可分為監督的、非監督的和相對的。
2 基于微博的用戶興趣的發現
2.1 微博用戶興趣群發現與分類模型
事實上,通過閱讀微博用戶發布的微博信息可以了解該微博用戶的興趣愛好,同時,也可以通過微博用戶的基本信息獲知該用戶的喜好。本文利用微博用戶關注的具有明顯興趣愛好標識來獲取用戶興趣,進而構建用戶興趣分類模型。

2.2 微博文本聚類關鍵技術
本文所研究的對象是微博文本,相對于簡單的數值數據而言,文本是非結構化的數據。因此,在做文本聚類之前,需要對文本進行預處理,預處理包括:微博文本分詞、停用詞處理、特征選擇、文本表示等,在此基礎上,對微博用戶興趣數據進行標注,以便為用戶的興趣發現奠定良好的基礎。
跟英文單詞不同,中文中詞與詞之間是連續的,并且詞的意義跟上下文環境有很大的關系,因此,在做下一步處理之前需要對中文進行分詞。目前,分詞的方法和實現的算法有很多,比如機械匹配法、約束矩陣法、理解切分法等。當然,在分詞過程中,某些詞是沒有實際意義的,針對這些詞,需要做停用詞處理。
為了對文本進行特征選擇,本文采用目前應用最為廣泛的TF-IDF(Term Frequency - Inverse Document Frequency)。該方法能夠科學地界定一個詞在整個文本中的權重,權重越高,其區分能力越強,具體計算公式如下:

該公式中,t表示一個獨立的詞,TF(t)表示t在文本中出現的頻率,N表示總的詞條數目,DF(t)表示t在文本集合中出現過的次數。通過TF-IDF算法就可以實現文本的結構化表示。為了方便計算機進行有效識別和處理,需要對這些文本進行特定的表示,最常使用的是向量空間模型。基于該模型,對特征詞進行權重的度量,同時需要進行歸一化處理,這樣度量的特征詞更加準確,下面給出計算的公式:

2.3 基于數據挖掘的微博用戶興趣發現的實現
在上述工作的基礎上,本節采用聚類算法作用于樣本數據,實現微博用戶興趣的發現。
2.3.1樣本數據特點
跟分類不同,聚類數據沒有明顯的結果標簽,其聚類過程是一個沒有監督的學習過程。由于本文針對微博文本進行聚類,因此采集到的樣本數據具有以下特點:
(1)根據微博文章的特點,其字數一般介于100到1000之間,最為常見的約為300;
(2)微博文本經過預處理后,數據屬于間斷的、不連續的變量;
(3)微博文本數據類型非常豐富,因此沒有標準的聚類評價方法;
(4)微博文本的樣本變量之間的值波動范圍一般比較大,所以,在調用聚類算法之前,需要進行歸一化處理。
2.3.2聚類算法及其選擇
目前,聚類算法有很多,不同的聚類算法有不同的優缺點和適用的場景。為了更好地對微博數據進行聚類,本文在傳統k-means算法的基礎上,針對粒子群(PSO)算法具有較強的全局搜索能力的特點,提出了改進的基于改進粒子群優化的k-means算法(PSO-kmeans)。在此基礎上,分別運用 K-means和PSO-kmeans算法,發現聚類中心和數目,同時也充分體現了不同聚類算法的優勢,形成更好地聚類結果。下面給出K-means算法的執行流程,具體如圖1所示。
但是,K-means算法的缺點是族類k的設置比較隨意,對樣本的初始聚類中心敏感度較大,同時當數據量較大時執行效率比較低下。因此,在此引進PSO-kmeans算法。PSO-kmeans算法具體步驟如下:
(1)對粒子群進行初始化操作;
(2)執行粒子群算法進行粒子群迭代搜索;
(3)執行k-means算法,按類輸出最終的聚類結果。
2.3.3算法實現過程
PSO-kmeans算法實現步驟如下:
輸入:聚類數據集S、粒子群規模m、聚類數目b及最大迭代次數t;
處理原則:同一組數據相似度很高,不同組差異性很大;
輸出:聚類中心對應的數據集S中的t組族。
具體過程:
(1)對粒子群進行初始化操作;
(2)執行PSO算法進行粒子群迭代搜索;
(3)執行K-means算法,按類輸出最終的聚類結果。

圖1 K-means聚類算法
具體流程如圖2所示。
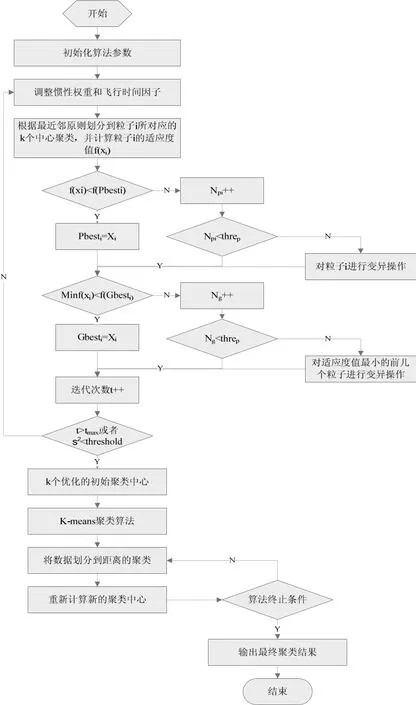
圖2 PSO-kmeans算法執行流程
在該流程圖中,Pbesti表示個體最優位置,Gbest表示群體最優位置,threp表示規定的閥值,σ2表示群體適應度方差,tmax表示最大迭代次數,Npi表示粒子i狀態無法得到改善的累計次數,Ng表示粒子群的狀態無法得到改善的累計次數。
3 實驗設計及結果分析
3.1 實驗過程設計
實驗過程設計如圖3所示。

圖3 實驗過程設計
從整個實驗過程來看,最為重要的是兩個環節,其一是數據預處理,其二是數據挖掘,產生聚類結果。
3.2 實驗數據處理
本文以新浪微博數據為處理對象,利用新浪微博API通過網絡爬蟲工具獲取用戶微博數據。獲取數據后,對其進行預處理,包括去重、提取關聯關系、過濾掉干擾信息等操作,使之形成有利于聚類分析的數據。
在此基礎上,分別運用K-means和PSO-Kmeans算法對數據進行聚類分析,產生如表1所示的聚類結果。

表1 聚類結果表

第4族:城鎮化 城鎮改革、推進城市發展、城鎮經濟、政府報告、宏觀政策
3.3 實驗結果分析
通過聚類結果對比發現兩點,其一:從聚類算法的角度來看,PSO-Kmeans算法能夠有效克服K-means算法的缺點,使得獲得的聚類結果更好,波動性較低。其二:從聚類結果分析,通過這些聚類族就可以對有相同興趣和喜好的用戶進行分組,從而實現好友分組、好友推薦和精準營銷等。
4 結束語
本文基于微博用戶和微博數據的特點,提出了微博用戶興趣的發現方法,并運用數據挖掘中的聚類算法對微博數據進行深入分析和挖掘,得到相似的微博用戶興趣群體,為網絡社交平臺的數據挖掘提供了有益的探索和借鑒。
[1]石偉杰,徐雅斌.微博用戶興趣發現研究[J].現代圖書情報技術,2015.
[2]牛朝林,高茂庭.基于模糊關聯規則的微博用戶潛在興趣發現[J].計算機系統應用,2016.
[3]徐雅斌,劉超,武裝.基于用戶興趣和推薦信任域的微博推薦[J].電信科學,2015.
[4]楊勇.基于 k-means算法在微博數據挖掘中的應用[D].天津工業大學,2015.
[5]曾珂.基于數據挖掘的微博用戶興趣群體發現與分類[D].華中師范大學,2014.
[6]宋巍,張宇,謝毓彬等.基于微博分類的用戶興趣識別[J].智能計算機與應用,2013.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
電力與能源(2017年6期)2017-05-14 06:19:37
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
信息通信技術(2015年6期)2015-12-26 01:16:46
創業家(2015年5期)2015-02-27 07:53:25
