基于壓縮感知的手寫漢字識別研究
2017-10-16 01:40:03張曼雪
西安航空學院學報 2017年5期
關鍵詞:信號
張 軍,張曼雪
(1.西安航空學院 士官學院,西安 710077;2.西安外國語大學 經濟金融學院,西安 710128)
基于壓縮感知的手寫漢字識別研究
張 軍1,張曼雪2
(1.西安航空學院 士官學院,西安 710077;2.西安外國語大學 經濟金融學院,西安 710128)
基于壓縮感知理論,提出一種手寫漢字識別的算法。該算法首先對手寫漢字圖像進行隨機采樣得到其特征,然后對其進行稀疏表示,并最小化其l1范數得到樣本的稀疏解,最后利用該稀疏解的系數判別測試樣本的類別。
手寫文字識別;壓縮感知;稀疏表示;l1范數最小化數
0 引言
模式識別就是通過計算機用數學技術方法來研究模式的自動處理和判讀,漢字識別是模式識別領域的一個重要分支。經過了幾十年的發展,字符識別已經取得了很多顯著的成果,如西文識別、用于郵政系統的識別系統等[1-2]。在漢字識別中,由于漢字類別多、結構復雜、相似字多、書寫差異大[3]等原因,使手寫漢字識別工作成為文字識別中的難點。雖然經過多年的研究,漢字識別已經有了許多成果,但是在實際應用中,提高漢字識別性能仍然是一個突出的問題。對于約束力較小的手寫漢字識別,目前沒有一種單一的實用方案能達到很高的識別精度與高準確度,當下研究人員正準備向更為實用、準確、錯誤率低的方向發展。一方面,盡量把新的知識運用到預判別及特點提取當中,如隱馬爾可夫、神經網絡、支持數學形態學、向量機等;另一方面,從多角度對手寫漢字進行全面分析,亦是當前的研究熱點。
近年來,在信息處理領域,稀疏線性計算問題即壓縮感知理論(Compressive Sensing)引起了廣大研究者的興趣[4-5]。壓縮感知理論在模式識別問題上也有應用,文獻[6]利用稀疏理論有效地實現了人臉識別,但不是使用基礎的超完備基,而是使用原始樣本作為超完備基。因為假如每類樣本素材足夠多的話,原始樣本可以線性組合為測試樣本,這對于所有的樣本資料來說,其表示方式必然是比較稀疏的,從而可以通過壓縮感知的方法來實現采樣。文獻[7]同樣利用這種方法,可以對手寫數字進行有效的識別。本文基于上述思想,將壓縮感知理論應用到更為困難的手寫漢字識別領域。
1 壓縮感知的基本理論
與傳統的奈奎斯特采樣定理不同,壓縮感知理論認為,信號的采樣速率并不僅僅取決于其帶寬,與信號的內容也有很大的關系。只要信號在某個變換區域是稀疏的或者是可壓縮的,那么就可以用一個獨立的觀測矩陣將變換所得信號投影到一個低維空間上,然后通過求解,進一步優化,從這些少量的投影中復現出原信號,可以證明這樣的投影包含了重現信號的足夠信息。
從上面壓縮感知理論的基本描述可以看出,該理論有三個要點要解決:(1)稀疏的定義;(2)觀測矩陣如何選取;(3)如何解決優化問題。
1.1 稀疏的基本慨念
從拉普拉斯變換、傅立葉變換、小波變換再到后來興起的多參數幾何分析,研究目的都是如何在不同的函數空間,為輸入信號提供一種更加簡潔、直接的分析方法,所有的變換都是在發掘原始信號的特征并稀疏表示,或者說都在提高非線性特性以便更好的逼近原始信號,進一步用函數空間的多重向量表示信號的稀疏程度。
稀疏的數學定義是:信號Y在正交基Ψ下的變換系數向量為Θ=ΨTY,假如對于0
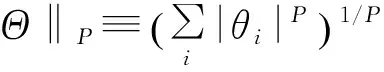
(1)
則說明系數向量Θ在某種意義下是稀疏的。
稀疏的另外一種定義方法是:如果變換系數θi=〈x,ψi〉的支撐域{i:θi≠0}小于等于K,則可以說信號X是K2項稀疏。
壓縮感知的基礎和前提是找到最佳的稀疏域,所以這是研究的重要方向。
1.2 如何選擇觀測矩陣
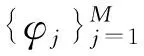
Y=φΘ=ΦΨTX=ACSX
(2)
對于給定的Y,從式(2)中求出Θ是一個線性計算問題,但因為M<
1.3 解決信號重構問題
從少量的投影中以高概率重構出原信號,這就是信號重構的問題。在壓縮感知理論中,由于觀測數量M遠小于信號長度N,因此不得不求解欠定方程組Y=ACSX。表面上看,欠定方程組求解似乎是無法完成,但是由于信號X是稀疏的或可壓縮的,這個特性從根本上改變了信號重構問題,使得方程可解。
為更好地描述壓縮感知理論的信號重構問題,首先定義向量X={X1,X2,…,Xn} 的p-范數為

(3)
當p=0時,得到0-范數,它實際上表示X中非零項的個數。于是,在信號X稀疏的前提下,求解方程組Y=ACSX的問題轉化為確定最小0-范數問題
min‖ΨTX‖0s.t.ACSX=ΦΨTX=Y
(4)
但是0-范數問題是一個所謂的非確定性的問題,求解l1優化問題可以得到近似的解,從而使得該問題可解。
2 壓縮感知在手寫漢字識別中的應用[7]
手寫漢字識別是確定當前輸入的樣本與訓練樣本之間的對應關系。我們假定系統的類別為K,每個類別對應的訓練樣本為N1,N2,…,Nk。對應于類別i,其特征矩陣Ai={vi1,vi2,…,viNi},則對于屬于i類的輸入測試樣本Y,有Y=k1·vi1+k2·vi2+…+kNi·viNi。所以在識別過程中,在類別未知的情況下,可以表述為Y=0·v11+…+0·vi-1,Ni-1+k1·vi1+k2·vi2+…+kNi·viN+0·vi+1,1+…+0·vK,Nk,ki,j∈R。
對于上面可以有如下的表達
Y=Ax
(5)
對于待分類樣本Y,x為稀疏系數,x=(k11,k12,…,kK,Nk)T,A為觀測矩陣,A=(A1,A2,…,AK)=(v11,v12,…,vK,Nk)。
為了用稀疏系數x來表達Y,需要解方程(5)。方程(5)中,A為M×N矩陣,其中N>>M,所以方程(5)是一個欠定方程組,有無窮組解。用最小l1范數來約束該問題,即
Y=Axs.t.x=argmin‖x‖1
(6)
在得到稀疏系數x后,用一個函數Ti(x)來計算用第i類恢復出來的Yi,Yi=ATi(x),其中
Ti(x)={0,0,…,kil,ki2,…,kiNi0,…,0}
(7)
最后分類用最小殘差來分類,即
minri(yi)=min‖y-AT(xi)‖
(8)
用壓縮感知進行手寫漢字識別的流程圖如圖1所示。
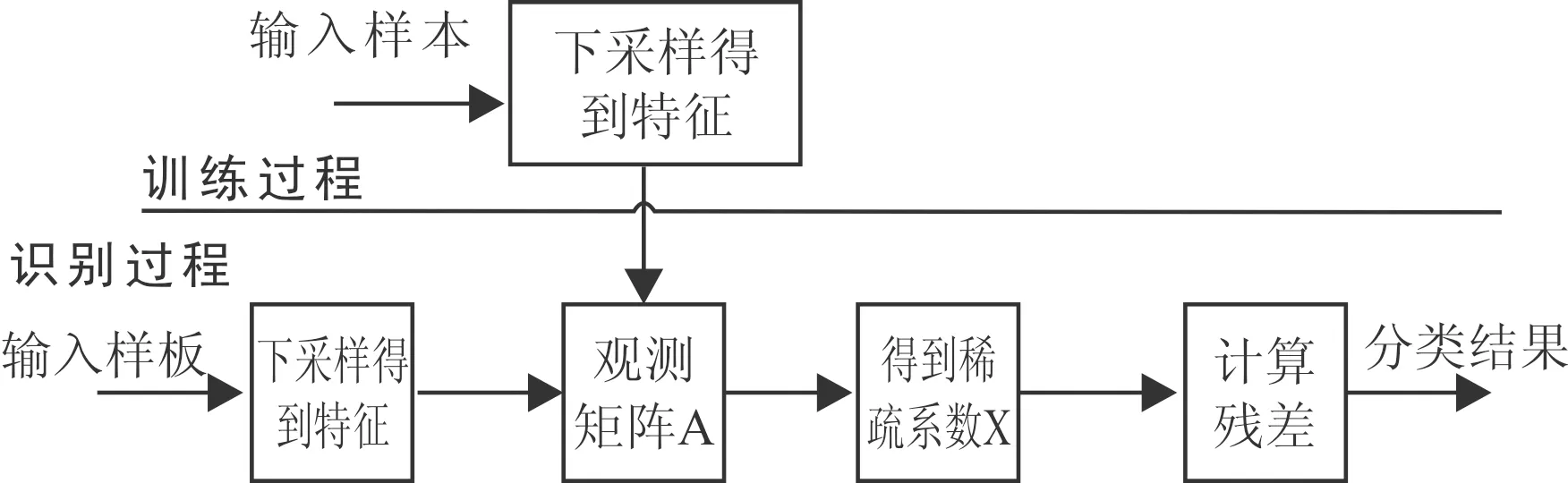
圖1 算法流程圖
3 實驗及結果
為了驗證算法的有效性,本文提出的方法在ETL9B手寫漢字庫上做了實驗。ETL9B是由日本JAIST采集的,包含3036個類別,每個類別由200個人書寫。圖2是該數據庫中的部分樣本示意圖。

圖2 ETL9B樣本示意
文章中的算法如下描述:首先對原始的文字圖像進行采樣,得到16×16 的圖像,然后將其直接拉伸成一個多維的一維向量,再用實際樣本組成觀測矩陣A。識別過程中,用待識別樣本在最小l1范數下計算稀疏系數x,利用公式(8)得到分類結果。
為了簡化實驗,所以只選了2965個漢字的200個類別用于實驗,圖2是測試樣本的示意圖,圖3是稀疏系數示意圖。實驗結果是最近中心的識別率為97.2%,最近鄰區域的識別率為98.9%,本文方法實驗區域的識別率為99.1%。
可以看出,本文提出的方法可以有效的鑒別文字圖像的類別信息,其中,最近中心(Nearest Mean)是用待分類樣本與每個類別的中心點的歐式距離來判斷樣本的類別。
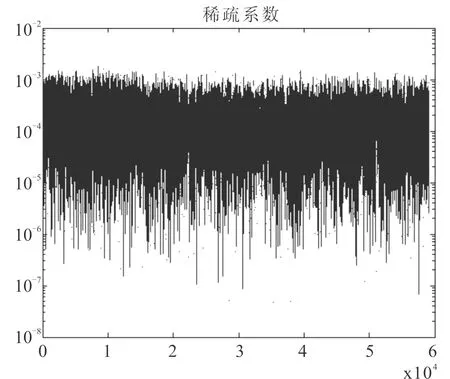
圖3 稀疏系數示意圖
4 結語
基于壓縮感知理論的手寫漢字識別,首先對手寫漢字圖像進行隨機采樣得到其特征;然后對其進行稀疏表示,并最小化其l1范數得到樣本的稀疏解;最后利用該稀疏解的系數判別測試樣本的類別。該方法的優勢在于:一是利用對信號的隨機采樣替代了傳統的特征提取方法,簡化了算法的實現過程。二是用所有的訓練樣本組成訓練字典,避免了復雜的訓練過程。
在手寫漢字數據庫ETL9B上的實驗結果表明了提出方法的有效性。在未來工作中,研究的重點將放在如何構建新的觀測矩陣,以節省存儲空間,提升計算效率。
[1] ARICA N,YARMAN-VURAL F T.An Overview of Character Recognition Focused on Off-line Handwriting[J].IEEE Transactions on Systems Man and Cybernetics Part C:Applications and Reviews,2011,31 (2):216-233.
[2] FUJISAWA H.Forty Years of Research in Character and Document Recognition-an Industrial Perspective[J].Pattern Recognition,2008,41(8):2435-2446.
[3] DAI R,LIU C,XIAO B.Chinese Character Recognition:History,Status and Prospects[J].Frontiers of Computer Science in China,2007,1(2):126-136.
[4] CAND E J,WAKIN M B.An Introduction to Compressive Sampling[J].IEEE Signal Processing Magazine,2008,25(2):21-30.
[5] ROMBERG J.Imaging via Compressive Sampling:Introduction to Compressive Sampling and Recovery via Convex Programming[J].IEEE Signal Processing Magazine,2008,25(2):14-20.
[6] 劉長紅,楊揚,陳勇.基于壓縮傳感的手寫字符識別方法[J].計算機應用,2009,29(8):2080-2082.
[7] 石光明,劉丹華,高大化,等. 壓縮感知理論及其研究進展[J].電子學報,2009,37(5):1070-1081.
[責任編輯、校對:東艷]
Abstract:A handwritten Chinese character recognition algorithm is presented on the basis of the compressive sensing theory.First of all,character images are sampled at random to form the feature vector,which is then expressed with sparse representation,and itsl1norm is minimized to obtain its sparse form.Finally,the coefficient of the sparse representation is adopted to judge the class of the samples.
Keywords:handwritten Chinese character recognition;compressive sensing;sparse representations;l1-minimization
HandwrittenCharacterRecognitionBasedonCompressiveSensing
ZHANGJun1,ZHANGMan-xue2
(1.School of Noncommissioned Officers,Xi′an Aeronautical University,Xi′an 710077,China; 2.School of Economics and Finance,Xi′an International Studies University,Xi′an 710128,China)
TP391.43
A
1008-9233(2017)05-0047-04
2017-05-11
陜西省教育廳專項科研計劃項目(14JK1362)
張軍(1968-),男,陜西大荔人,副教授,主要從事工業電氣自動化研究。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
