基于BP神經網絡的廣東省第三產業就業人口數量預測研究
2017-10-23 12:50:48劉天麒
無線互聯科技 2017年19期
劉天麒

摘 要:宏觀經濟政策的制定必然要參照各次產業發展水平,故研究產業發展規模變化趨勢就顯得十分必要。文章通過BP神經網絡,對廣東省第三產業就業人口數量進行分析,并以2016年的《廣東省統計年鑒》提供的數據為依據建立預測模型,結果表明:該模型最大誤差為5.26%,滿足預期要求,實際值和預測值的擬合關系較為理想,證實了所述方法的有效性。
關鍵詞:BP神經網絡;廣東省第三產業;就業人口數量;預測
近年來,隨著我國經濟實力的發展和產業結構的迅速升級,第三產業從業者數量在我國就業人口數量中所占比重逐漸增大,第三產業的興旺已成為現代經濟發展的重要特征。鑒于第三產業在國民經濟中的重要地位,本文以廣東省第三產業就業人口數量作為研究對象,使用反向傳播(Back Propagation,BP)神經網絡方法,研究了廣東省第三產業就業人口數量的預測模型。
目前國內關于就業人口數量的建模方法較多,應用較為廣泛的有灰色理論及神經網絡建立的就業預測模型[1],以及利用BP神經網絡預測大學生就業模型[2]。關于第三產業的相關建模方法也較為多見,但都集中在對第三產業GDP的建模研究,如采用時間序列法[3]、回歸分析法[4]對GDP進行建模,甚少涉及就業人口的建模研究。因此,本文利用BP神經網絡方法,結合廣東省近12年來第三產業就業人口數量,建立預測模型,以期為廣東省第三產業的未來發展趨勢提供理論依據。
1 BP神經網絡模型原理
1.1 BP神經網絡的結構
BP神經網絡是一種單向傳播的多層前饋網絡,在當前人工神經網絡算法中得到廣泛應用。它包括輸入層、隱含層和輸出層,同層節點之間互不相連,而層與層之間全互聯。輸入層和輸出層的節點個數由輸入、輸出向量的維數決定,隱含層節點個數沒有確定的標準,需通過反復試驗確定。理論表明,三層BP神經網絡能以任意精度逼近任何連續函數,其拓撲結構如圖1所示。因此,本文采用三層BP神經網絡對廣東省第三產業就業人口數量進行預測分析。
1.2 BP神經網絡的算法
BP算法也稱誤差反向傳播算法,它通過對各層之間神經元連接權值的反復學習,減小誤差,得到最終的神經網絡模型。對于如圖1所示的三層神經網絡,其算法計算步驟[5]如下:
(1)采用最小隨機數方法初始化所有的加權系數;
(2)提供輸入向量[x1,x2,…,xn]和輸出向量[y1,y2,…,ym]作為網絡訓練樣本;
(3)計算各神經元的實際輸出,如式(1)
(1)
(4)計算實際輸出值與期望值的誤差,如式(2)
(2)
(5)修正輸出層的權值Wim及隱含層的權值Wni;
(6)判斷是否滿足誤差要求(J≤ε),若滿足則結束,不滿足則返至第3步,直到滿足誤差要求。
圖1 BP神經網絡拓撲結構
2 BP神經網絡在廣東省第三產業就業人口預測中的應用2.1 樣本選取與預處理
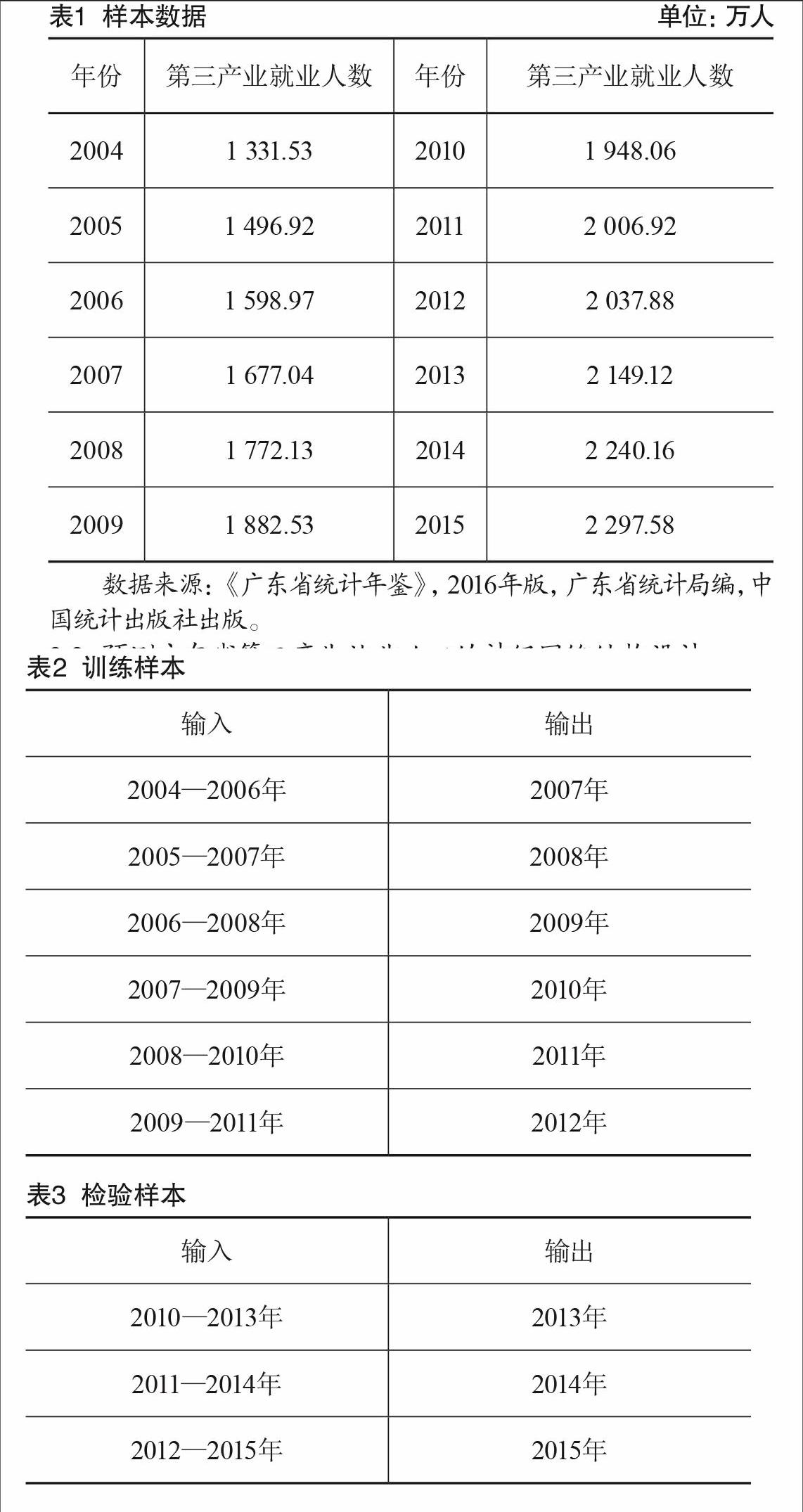
本文以廣東省2004—2015年的就業人員年末人數為建模樣本,進行預測研究,樣本數據如表1所示。
為了提高樣本數據對網絡的正確應答能力,需要將構造樣本中原始數據作歸一化預處理,采用線性歸一處理方法,即:
(3)
式中:i=1,2,…,,n;xi代表第i個樣本的取值大小;min(x)為所有樣本數據中的最小值;max(x)為所有樣本數據中的最大值。x'i的取值范圍為0~1。人口預測完畢后,再將歸一化后的數據按照反歸一化處理。
數據來源:《廣東省統計年鑒》,2016年版,廣東省統計局編,中國統計出版社出版。
2.2 預測廣東省第三產業就業人口的神經網絡結構設計
本文利用SPSS軟件對構建的BP神經網絡進行訓練,從2004年開始進行樣本輸入,每4年樣本作為一組,樣本數據共分為9組,每組中:前3年的數據作為輸入,第4年作為輸出。9組樣本數據中,前6組用于訓練神經網絡,后3組用于檢驗預測結果,訓練數據和檢驗數據如表2—3所示。
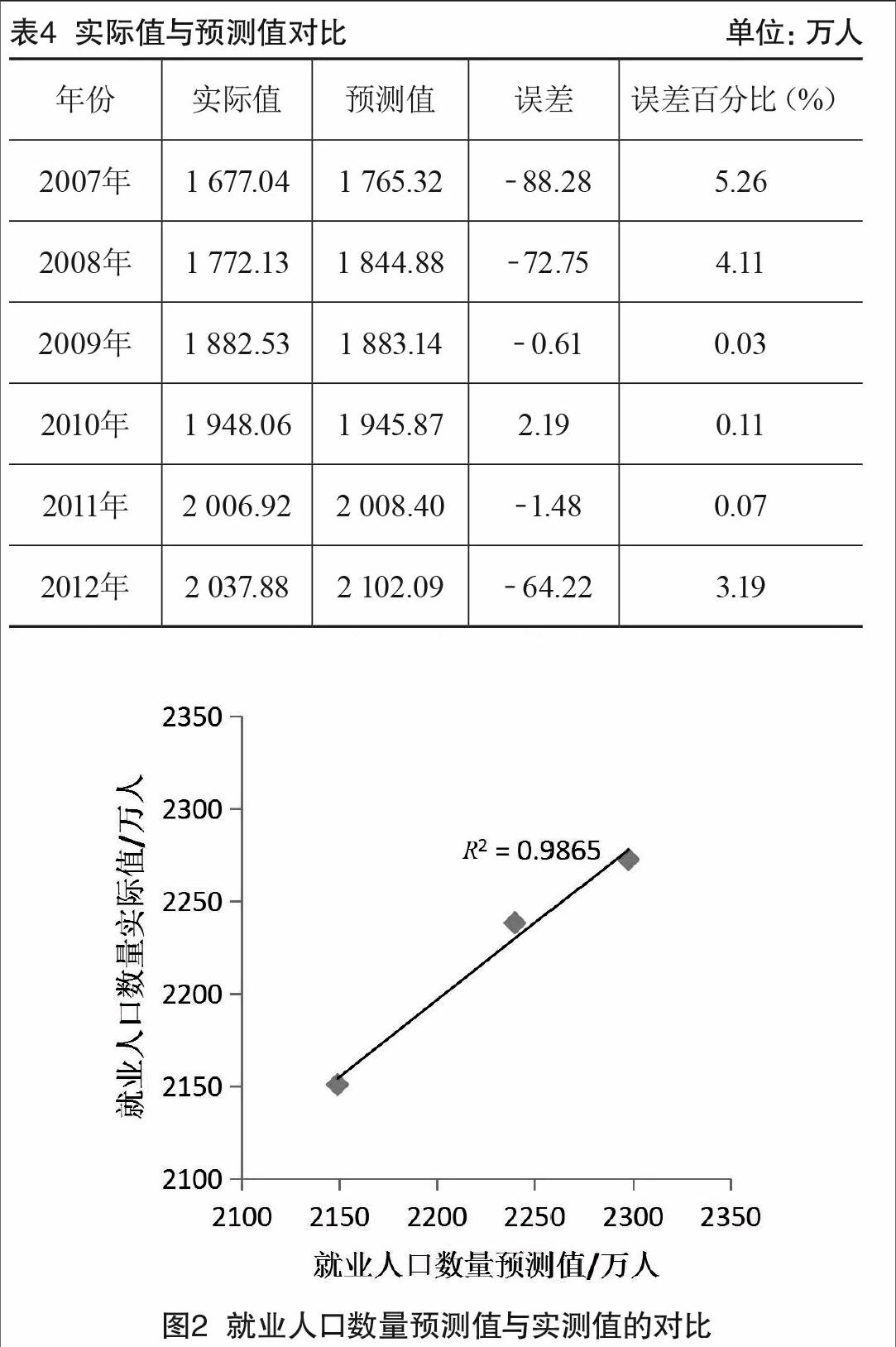
模型選用常見的3層結構,分別為輸入層、隱含層和輸出層。輸入層有3個神經元,輸出層有1個神經元,隱含層神經元經試算為20個。通過對BP神經網絡模型相關參數的不斷試驗和調整,最終確定了隱藏層采用logsig傳遞函數,輸出層采用purelin傳遞函數,網絡訓練算法采用traingd,選擇5 000作為最大訓練次數,0.001作為目標誤差值,0.05作為初始學習率。在構建BP神經網絡預測模型前,需要按照公式(3)對所有輸入數據進行歸一化處理,輸出數據后再進行反歸一化處理。實際值與預測值對比如表4所示。
由表4可知,所建立的BP神經網絡在預測2007—2012年廣東省第三產業就業人口數量時,最大誤差不超過5.26%,表明預測值與實測值之間有著很好的擬合精度,說明該模型可以良好地預測廣東省第三產業就業人口數量。
2.3 BP神經網絡對廣東省第三產業就業人口數量的預測
通過BP神經網絡預測模型,對廣東省2013—2015年第三產業就業人口數量進行預測,預測結果為2013年人口數量為2 150.82萬人,2014年人口數量為2 238.15萬人,2015年人口數量為2 272.47萬人,預測值與實際值對比如圖2所示。
從圖2可以看出,預測值與實測值都較為均勻地分布在1∶1線附近,兩者之間的決定系數R2=0.986 5,表明預測值與實測值之間有著很好的擬合精度,再一次驗證了BP神經網絡良好的預測能力。
3 結語
(1)本文以2004—2012年廣東省第三產業年末就業人數為依據,利用神經網絡建立了BP神經網絡預測模型。
(2)利用SPSS軟件對所建立的模型進行學習訓練,并對2013—2015年廣東省第三產業就業人口數量進行了預測。
(3)結果表明,本文所建模型行之有效,在廣東省第三產業就業人數預測方面具有較好的擬合度,具有廣闊的應用前景。但是,BP神經網絡是一個復雜網絡,由于其涉及隱含層節點個數難以確定、易陷入局部極小點等問題,在之后研究中,需要不斷完善該模型,以增加預測精度。另外,要訓練出更為精準的BP神經網絡模型,亦需要多年數據的支撐,以進一步提高本文方法的適用性。
[參考文獻]
[1]何運村,張柱華.灰色理論及神經網絡在就業預測中的應用研究[J].計算機與數字工程,2008(8):154-156.
[2]馬丹丹,于占龍,劉越.BP神經網絡在大學畢業生就業率預測中的研究與應用[J].佳木斯大學學報,2014(5):751-753.
[3]李戰江,曹海燕.使用ARIMA模型對內蒙古GDP進行時序建模及預測[J].內蒙古農業大學學報(自然科學版),2008(2):173-175.
[4]王建府.滬津GDP增長回歸模型比較及發展前景研究[J].科技情報開發與經濟,2005(3):121-123.
[5]吳昌友.神經網絡的研究及應用[D].哈爾濱:東北農業大學,2007.
