以第一性原理計算進行不同高性能計算集群架構性能測評*
2017-11-10 02:04:57張彥彬吳民耀石裕維肖熠琳任豪
自動化與信息工程 2017年5期
張彥彬 吳民耀 石裕維 肖熠琳 任豪
?
以第一性原理計算進行不同高性能計算集群架構性能測評*
張彥彬1吳民耀1石裕維1肖熠琳2任豪2
(1.廣州高能計算機科技有限公司 2.廣州市光機電技術研究院)
高性能計算集群平臺種類繁多,按處理器種類可分為貝奧武夫架構的個人計算機集群和服務器集群,目前對其性能測評的研究較少。以不同架構、不同網絡拓撲結構和不同網絡帶寬的高性能計算機集群為研究對象,利用第一性原理數值計算軟件為性能測評工具,對不同的計算集群進行性能測評,分析架構、拓撲結構、帶寬等因素對計算效能的影響。
性能測評;高性能計算集群;CPMD;VASP;第一性原理
0 引言
利用高性能計算集群進行科學模擬已成為現代科學研究主流,特別是利用高性能計算機仿真研究物質內部原子尺度的結構特性,已經成為物理、化學、生命與材料科學研究的有效方法。在諸多應用領域中,科學模擬取得的計算成果不僅可解釋實驗中觀察到的測量數據,還可預測一些材料的性質,甚至是設計和創造新材料。但高性能計算集群建置成本昂貴。因此,利用個人計算機組成的貝奧武夫(Beowulf)架構[1]建立的高性能計算集群得到了快速發展,其計算性能得到了用戶的肯定。但其具體計算性能與傳統服務器所搭建的集群對比研究較少,造成高性能計算集群選擇上的困難。鑒于此,本文針對3種不同硬件計算機集群(2種Beowulf架構,1種服務器架構)和3種不同的集群內部資源網絡連接方法做性能測評。
以密度泛函理論(density functional theory,DFT)為基礎的第一性原理計算,在解釋和預測材料結構特性方面有非常重要的作用[2]。本文選擇CPMD(Car-Parrinello Molecular Dynamics)[3]和VASP(Vienna Ab-initio Simulation Package)進行第一原理計算仿真,比較不同架構下高性能計算集群的性能表現。
CPMD是利用第一性原理分子動力學方法,結合密度泛函理論和古典分子動力學的計算機模擬技術[4]。
VASP[5]是維也納大學Hafner小組開發的進行電子結構計算和量子力學—分子動力學模擬軟件包。它是目前材料模擬和計算物質科學研究中最流行的商用軟件之一。
1 測試環境
1.1 貝奧武夫架構集群
本文關于貝奧武夫架構集群所使用的測試平臺為MCBW-I和MCBW-II高性能計算集群,其硬件和軟件配置如表1、2所示。

表1 MCBW- I硬件和軟件配置
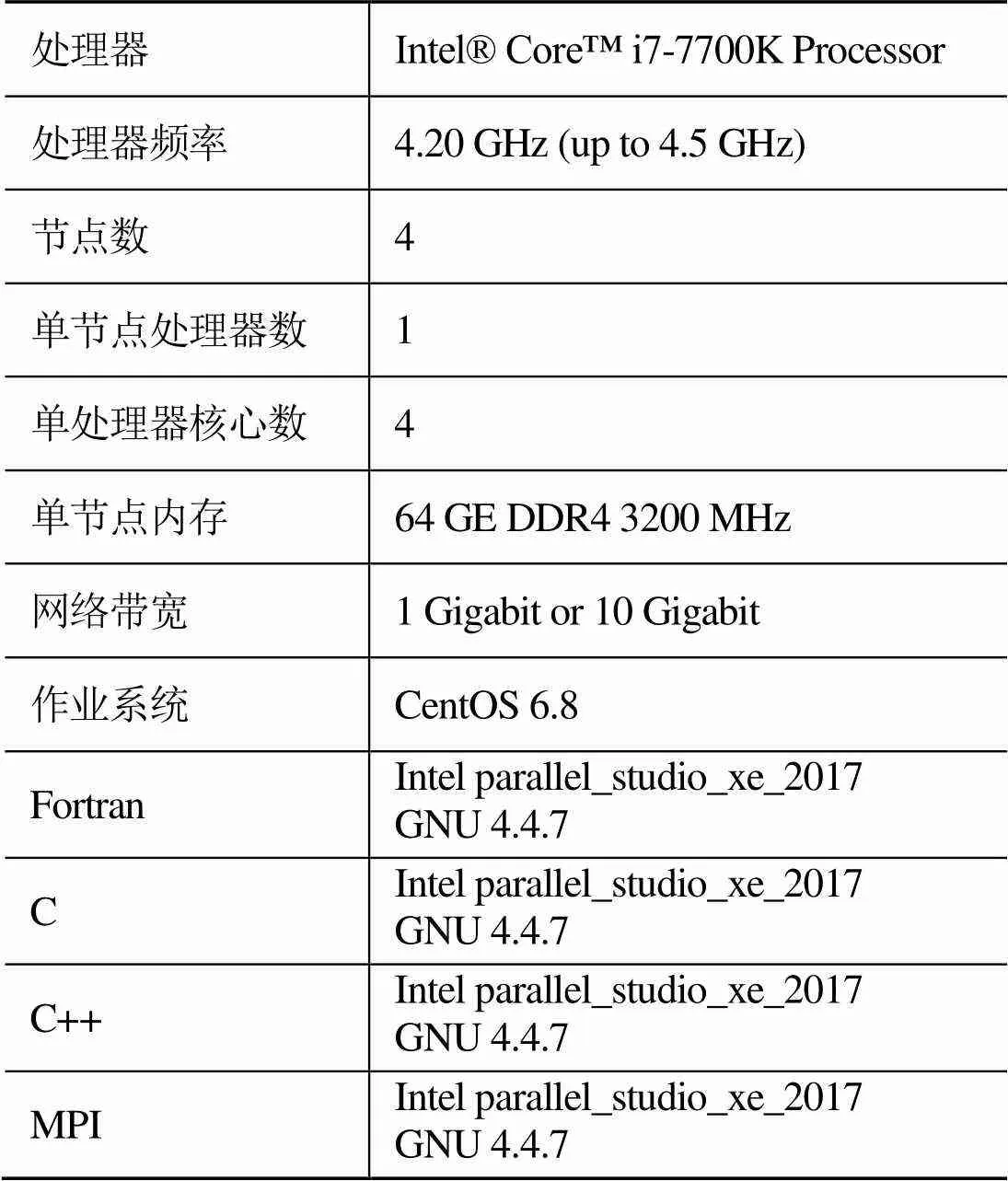
表2 MCBW-II硬件和軟件配置
1.2 服務器架構集群
本文關于服務器架構集群所使用的測試平臺為SFCS(switch free cluster system)高性能計算集群,其硬件和軟件配置如表3所示。

表3 SFCS硬件及軟件配置
1.3 網絡拓撲架構
本文測試全直連(見圖1)、星狀連接(見圖2)和網絡交換機(見圖3)3種不同的連接架構。
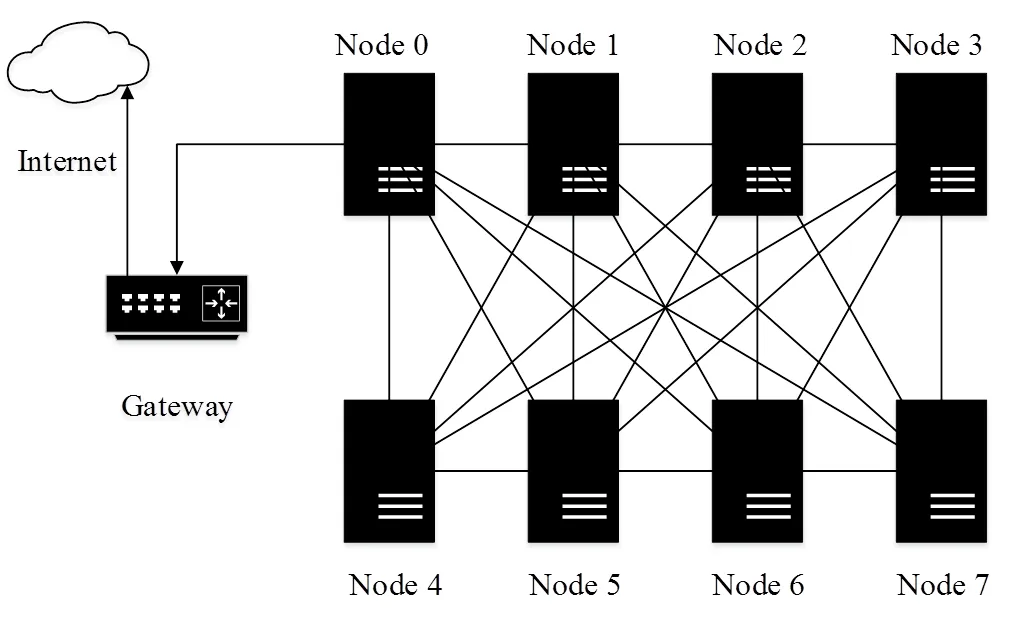
圖1 全直連系統架構
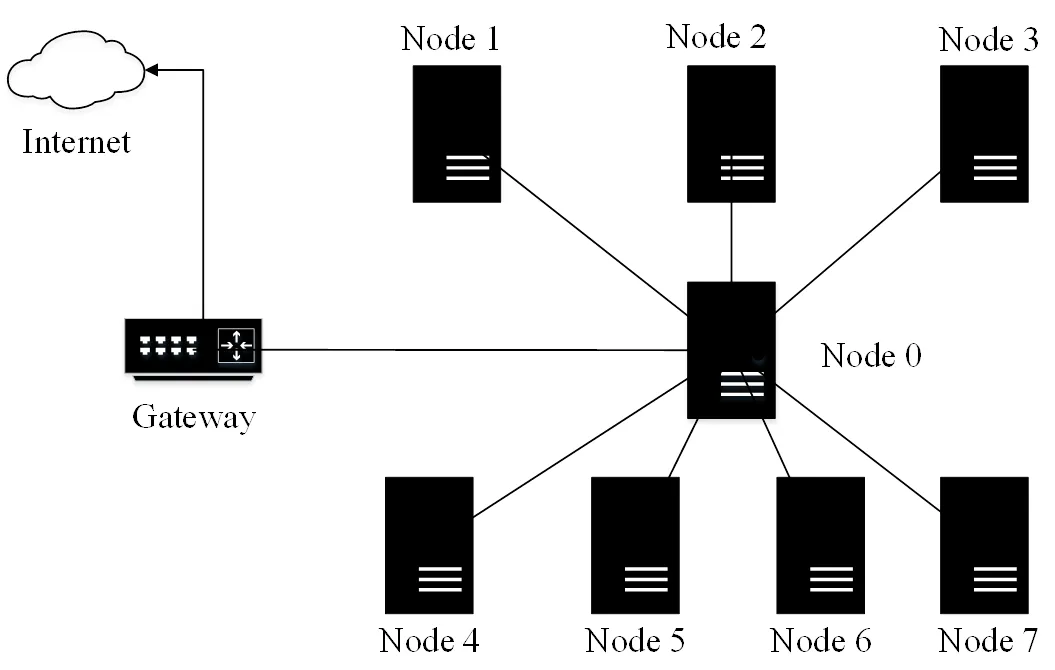
圖2 星狀連接系統架構
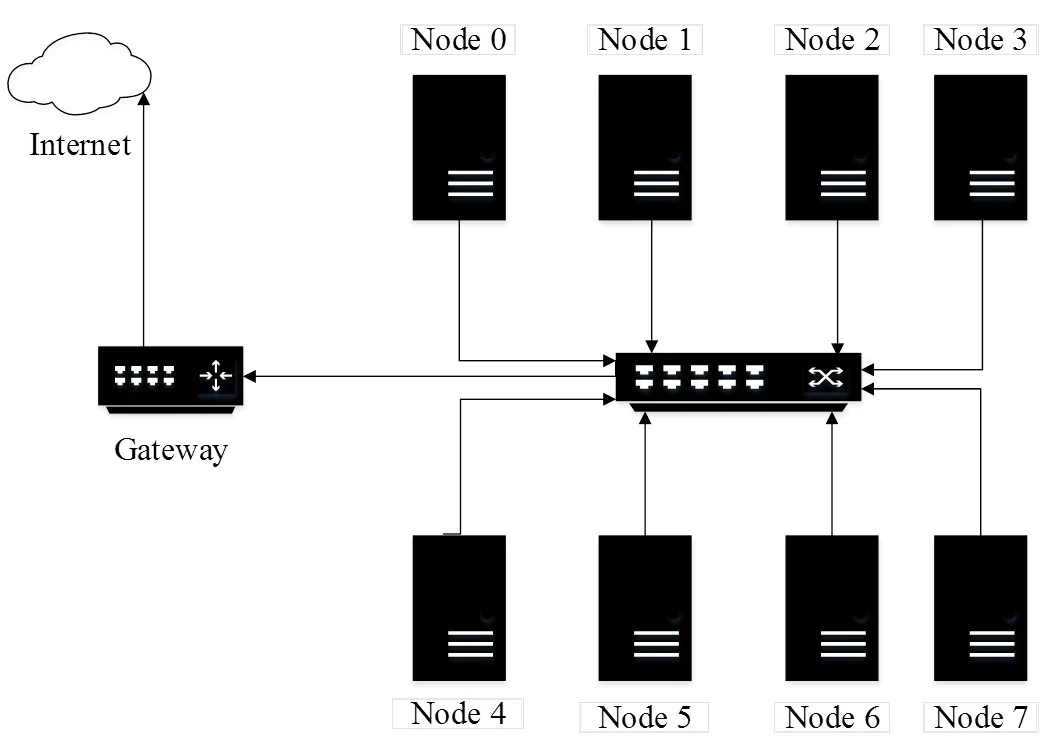
圖3 網絡交換機系統架構
其中全直連系統架構為每一個計算節點都與其他節點以直接鏈接的方式進行通訊;星狀連接系統架構為以一個計算節點為中心節點,與其他計算節點連結,中心節點的功能類似傳統網絡交換器;網絡交換機系統架構為計算節點之間利用交換器進行數據交換。為測試網絡帶寬對計算效能的影響,使用1 GE和10 GE 2種網絡帶寬進行測試。
2 測試結果
2.1 MCBW-I測試結果
在MCBW-I平臺上,利用CPMD計算碳60結構的基態能量,不同網絡拓撲架構和網絡帶寬的計算效能差異如圖4所示。其中,縱坐標加速比以單節點計算時間為基準。由圖4可知,第一影響因素是網絡帶寬;第二影響因素是網絡拓撲架構。
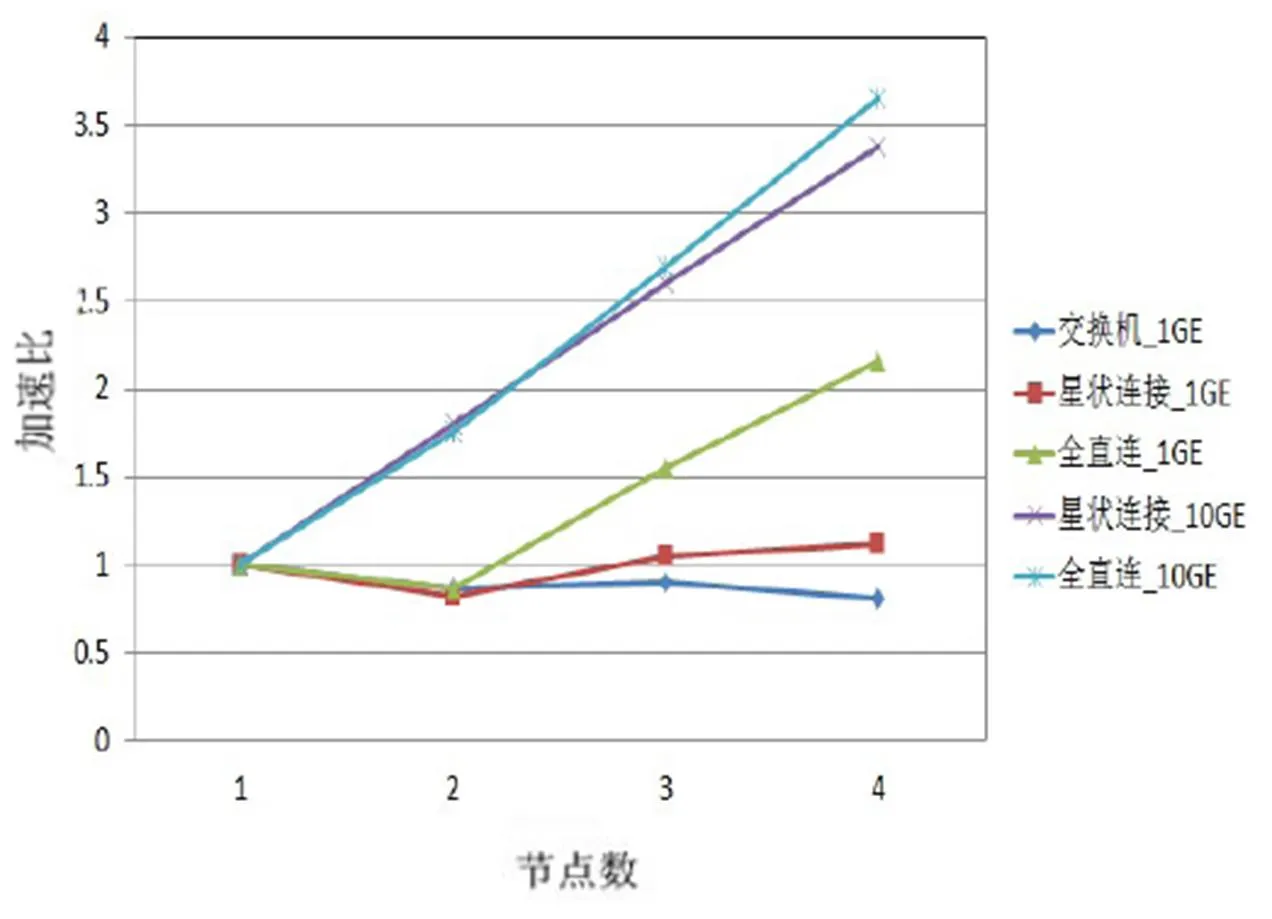
圖4 MCBW-I CPMD測試結果
當采用1 GE網絡帶寬時,CPMD跨節點計算效率不理想。雖然全直連系統可提供較大的網絡帶寬(每臺節點有3條網絡線連接),但4節點計算僅提供2倍的加速比。
當采用10 GE帶寬進行4節點計算時,星狀連接和全直連系統架構都提供超過3倍的加速比,效率超過80%。在節點增加時,全直連系統架構較星狀連接系統架構效能增加更明顯,這是由于在全直連系統架構下,計算節點以直接連結方式通訊;而星狀連接系統架構,除中心節點,其他計算節點至少需要經過1個計算節點才能與其他節點通訊,通信成本隨之增加。
在MCBW-I平臺上,利用VASP計算HfO2電子結構的跨機效能如圖5所示。VASP在1 GE帶寬下的跨機平行效率比CPMD高,全直連10 GE的4節點計算加速比最高,星狀連接10 GE以微小差距排第二。值得注意的是,VASP的計算會出現效率超過100%的情況,這是因為加速比以單計算節點的計算時間為基準。當單計算節點內存帶寬不足時,會出現如圖5所示情況。

圖5 MCBW- I VASP測試結果
2.2 SFCS測試結果
為研究服務器架構平臺在不同網絡拓撲架構和網絡帶寬下的跨機運算情況,進行了與圖4、圖5相同的計算。SFCS CPMD測試結果如圖6所示,與圖4的跨機效能趨勢一致,CPMD的跨機運算效能主要受到網絡帶寬的影響。SFCS VASP測試結果如圖7所示,全直連網絡拓撲架構可有效提升1GE網絡帶寬下的跨機運算效率。與CPMD計算相同,網絡帶寬主要決定了跨機運算效率,而全直連網絡拓撲架構的優勢會在計算節點增加時出現。
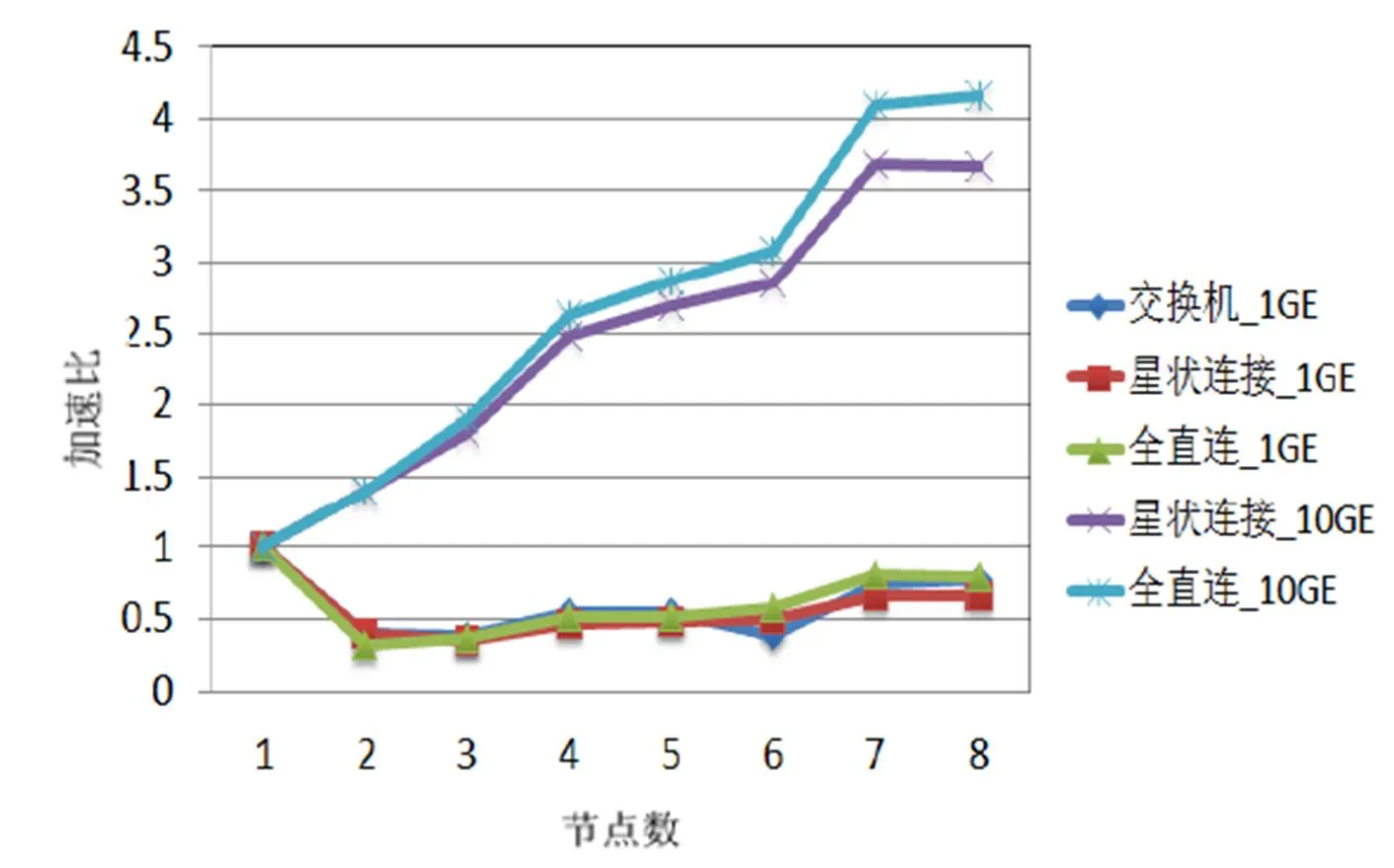
圖6 SFCS CPMD測試結果
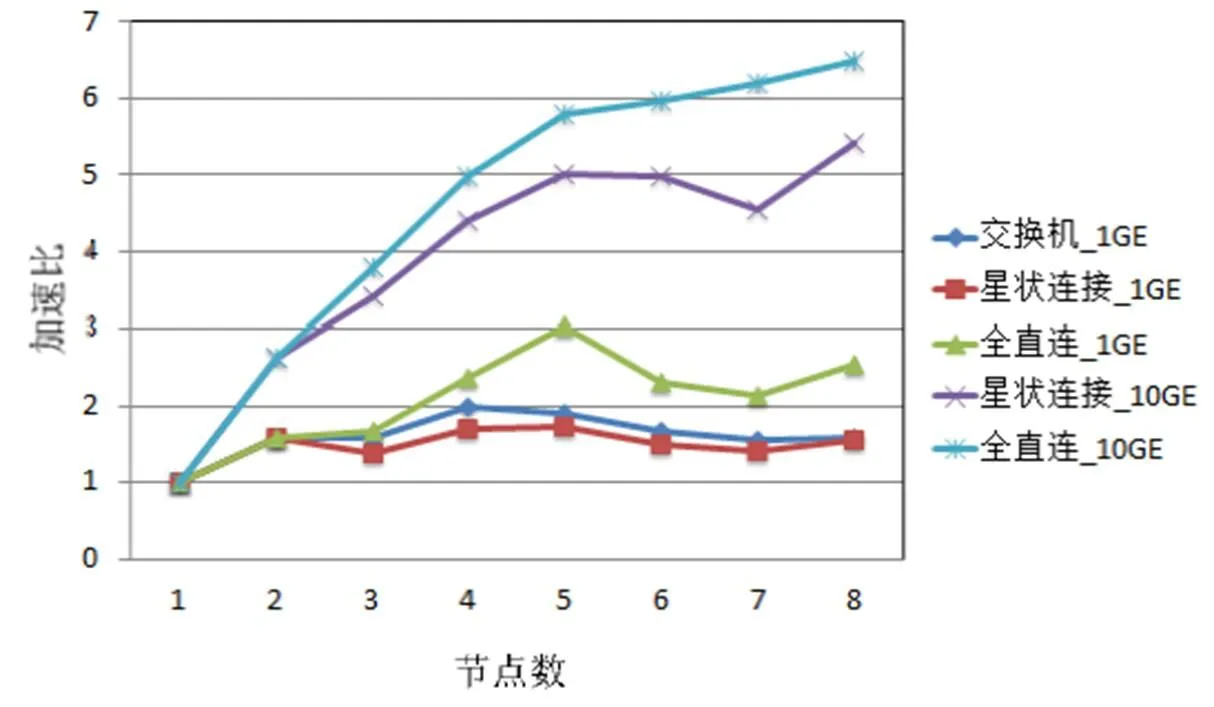
圖7 SFCS VASP測試結果
2.3 MCBW-II測試結果
MCBW-II為MCBW-I的二代版,主要差異為CPU頻率由4.0 GHz 提升到4.2 GHz,內存帶寬由2400 MHz提升到3200 MHz。CPU頻率的提升有助于提高單核的計算效能。MCBW-I和MCBW-II的計算效能測試結果如圖8、圖9所示。根據圖4、圖5的測試結果,在較少節點情況下,星狀連接系統架構和全直連系統架構的計算效能接近,且不同的網絡架構在1 GE帶寬下效能差別不大,所以接下來的測試將以星狀連接系統10 GE和1 GE網絡交換機系統架構為主。
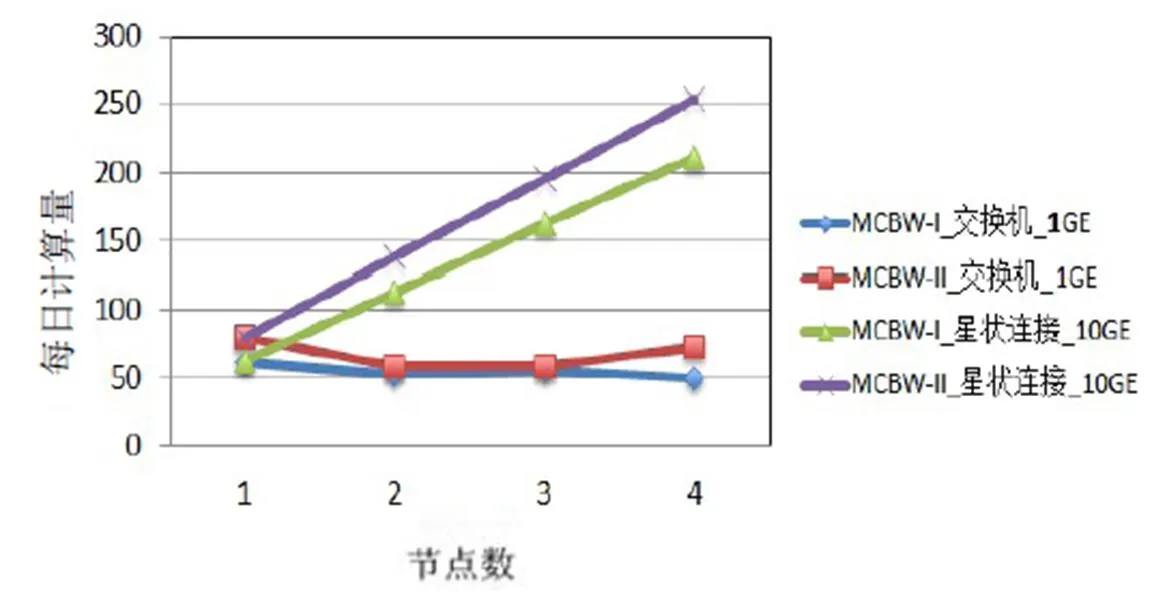
圖8 CPMD測試結果
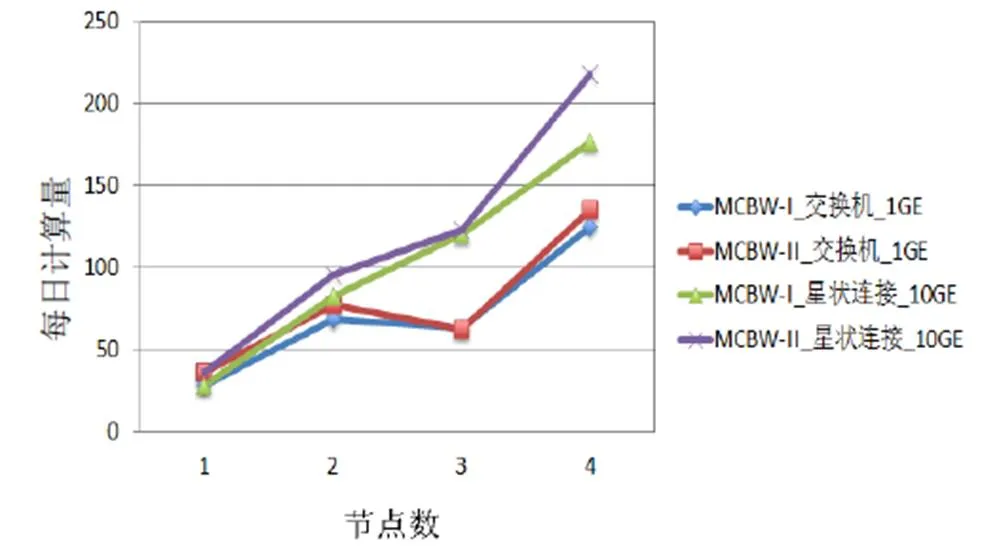
圖9 VASP測試結果
2.4 不同架構、網絡拓撲結構及網絡帶寬的計算機集群性能對比
由圖5和圖7可知,VASP跨機運算效率出現超過100%的情況,上文已經提到這現象與單機的內存帶寬有關。為證明這點,在MCBW-II的一個計算節點做測試:讓一個VASP僅使用單核進行計算,依次將相同的工作增加到4個。理想狀況下,一個計算節點擁有4個運算核心,一個節點執行一個工作和同時執行4個工作運算時間是一樣的。MCBW-II單節點進行VASP模擬的運行時間如圖10所示,發現由于受到內存帶寬和通信道數目的限制,同時執行4個工作所花的計算時間僅是執行1個工作的2.4倍。

圖10 MCBW-II單節點進行VASP模擬的運行時間
測試結果說明了多核計算由于內存帶寬和通信道數的限制,使得內存和CPU的通訊時間增長,最終造成運算時間增加。SFCS單節點VASP并行計算測試結果如圖11所示。

圖11 SFCS單節點VASP并行計算測試結果
由圖11可以看出,使用5個核心進行運算時,效能基本符合理論值,超過5個核心后,效能開始偏離理論值。由于SFCS每個計算節點具有2顆實體CPU(每顆CPU具有10個核心),除了內存信道數目和帶寬限制,2顆CPU之間通訊的帶寬也會限制多核心的運算效率。從圖5和圖7的測試結果顯示,跨機運算可以解決單機內存帶寬不足的限制。由圖10和圖11可知,以單計算節點的計算時間作為跨機效率的基準存在問題,利用單核的計算時間作為基準比較適合。
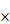
圖12 利用跨節點計算的方式有效增加內存帶寬提升多核運算效率
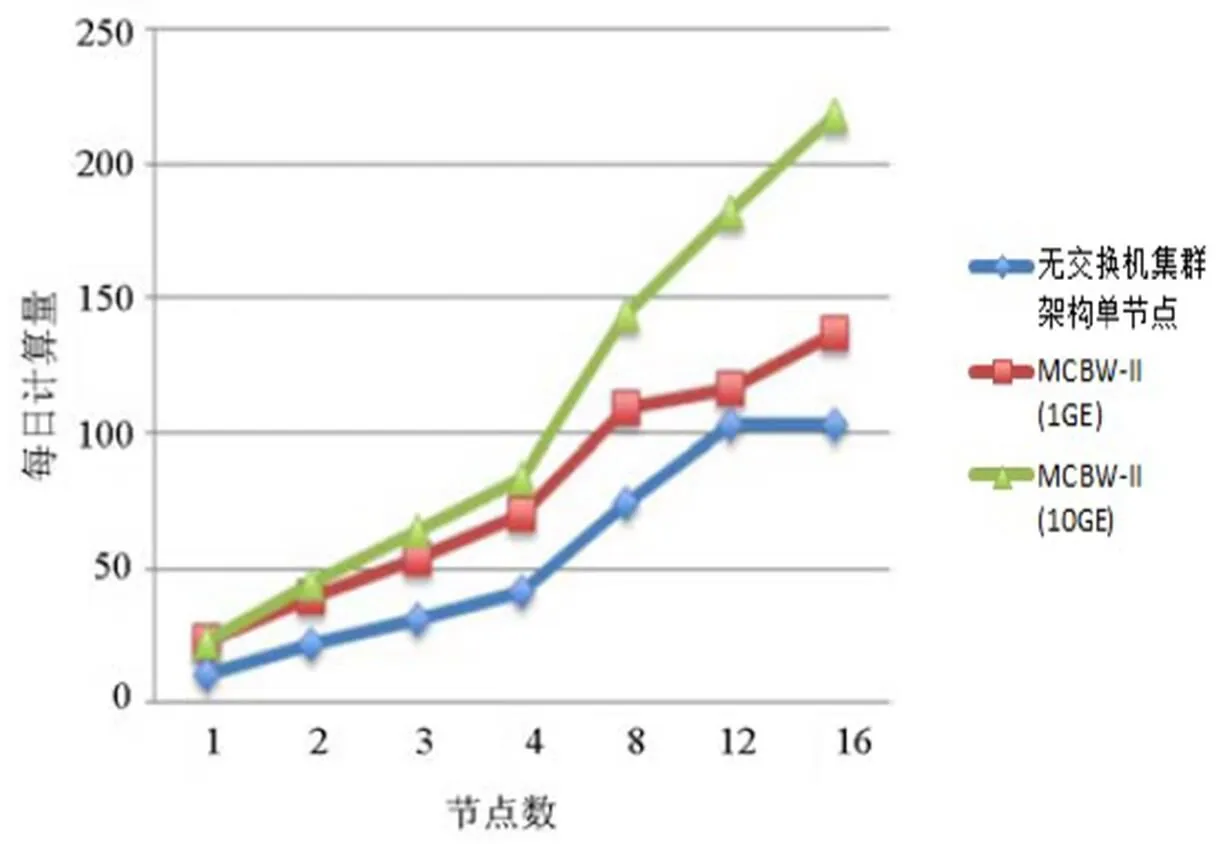
圖13 MCBW-II和SFCS單節點在相同核心數下運算效能比較圖
根據以上的測試結果可知,在網絡帶寬足夠的情況下,采用跨機運算的方式比單機增加CPU核心數目更能有效提升計算效能。
3 結論
本文通過3種不同的網絡架構對2大類型計算集群進行第一性原理計算分析,對于集群單節點性能、整體性能與網絡結構及帶寬影響有了整體了解,并得出以下結論:
1)全直連系統架構可在千兆帶寬時提供與交換機網絡架構相同的計算性能;
2)計算量較大時,采用直連萬兆帶寬可有效提升集群整體運算性能;
3)CPMD和VASP在跨機運算時需要非常大的網絡帶寬,除了采用10 GE網絡,搭配利用全直連系統或星狀連接系統的網絡拓撲架構可以進一步提升網絡帶寬;在第一性原理計算應用過程中,為有效提升計算效率,可采用跨界點的并行計算方法;
4)貝奧武夫集群可利用增加計算節點數的方式增加內存帶寬,計算效能可持續增加;服務器集群因受限內存和CPU之間通訊的帶寬,到16核心已出現效能飽和的情況,對計算效能提升并不明顯。
[1] Wikipedia. Beowulf Cluster[EB/OL]. [2017-08-28]. https://en. wikipedia.org/wiki/Beowulf_cluster.
[2] Marx D, Hutter J. Ab initio molecular dynamics: basic theory and advanced methods [J]. Cambridge University Press, Aug. 2011, 307:109-153.
[3] CPMD Org. CPMD [EB/OL]. [2017-08-28]. http://www.cpmd. org/Copyright IBM Corp 2000-2017.
[4] CPMD Org. CPMD manual[EB/OL]. [2017-08-28]. http://cpmd.org/downloadable-files/nouthentication/manual_v4_0_1.pdf.
[5] Xsede.org. VASP manual [EB/OL]. [2017-08-28]. https:// www.xsede.org/wwwteragrid/archive/web/user-support/vasp_ benchmark.html.
Performance Evaluation of Different HPC Cluster Architectures by Using First Principles Calculations
Zhang Yanbin1Ng Mingyaw1Shi Yuwei1Xiao Yilin2Ren Hao2
(1. Guangzhou HPC Technology Inc. 2. Guangzhou Research Institute of O-M-E Technology)
Currently, there are many kinds of high performance computing system. According to the division of processor types, it can be simplified into two types - Beowulf PC cluster architecture and server cluster, but there were less performance evaluation studies between these two kinds of system. This paper carried out the study on their properties, with different architectures interconnect topologies and bandwidth, use the 1stprinciple software as the performance evaluation tools. The results can be useful for the HPC users in the future.
Performance Evaluation; High Performance Computing Cluster; CPMD; VASP; First Principles
張彥彬,男,1978年生,碩士,主要研究方向:熱流分析、并行計算、網絡拓撲設計、分布式計算、高性能計算系統。 E-mail: johnson.z@hpctek.com
吳民耀,男,1979年生,博士,主要研究方向:近場光學,第二型半導體量子點的激子效應和納米材料的瞬時結構動力學。
石裕維,男,1993年生,本科,主要研究方向:高性能計算系統、并行計算、網絡架構。
肖熠琳,女,1982年生,碩士,高級工程師,主要研究方向:項目資源與作業管理、并行計算。
任豪,男,1972年生,博士后,教授級高工,主要研究方向:納米陶瓷薄膜材料。
廣州市科技計劃項目(201508030009);廣東省科技計劃項目(2017A010109077)。
