基于聚類分析的電子商務客戶忠誠度研究
2017-11-17 07:22:47廣東省經(jīng)濟貿易職業(yè)技術學校楊雄鋼
電子世界 2017年21期
廣東省經(jīng)濟貿易職業(yè)技術學校 楊雄鋼
基于聚類分析的電子商務客戶忠誠度研究
廣東省經(jīng)濟貿易職業(yè)技術學校 楊雄鋼
全面分析電子商務顧客忠誠度的影響因素,立足于經(jīng)典RFM客戶忠誠度模型,將RFMSA電子商務客戶忠誠度劃分模型有效地建立起來,借助聚類分析算法劃分顧客忠誠度,立足于經(jīng)典聚類分析法K-means,將分段確定初始聚類中心的改進算法提出,以此來劃分顧客的忠誠度.借助分析經(jīng)典樣本數(shù)據(jù),從實驗結果可以看成,通過對粗糙集K-means聚類算法進行改進后,可以將聚類的準確率有效提高.
聚類分析;電子商務;客戶忠誠度
在電子商務環(huán)境下,企業(yè)可以對互聯(lián)網(wǎng)進行利用將產(chǎn)品和服務提供給客戶.企業(yè)不認識顧客,顧客也不認識企業(yè),沒有當面交流過一句,所有客戶關系都通過網(wǎng)絡來進行維持.能夠讓消費者更好的進行對比、選擇以及提供各方面綜合程度較高的商品和企業(yè)即為互聯(lián)網(wǎng)的優(yōu)點,對互聯(lián)網(wǎng)進行利用,讓消費者更好的對信息進行搜索,這樣就可以利用相關企業(yè)在網(wǎng)上開設的商城,將商品的價格等相關信息獲取到,并且還可以和企業(yè)服務商進行對比,不僅可以在價格上進行比較,同時還可以在服務商進行比較,通過以上所講到的對比,消費者就會選擇和自己消費意象更相符的產(chǎn)品或商家,因此在電子商務中,客戶忠誠度基本較低,最終流失掉本有的客戶.怎樣才能將客戶的忠誠度提高是現(xiàn)階段電子商務迫切需要解決的問題.
一、電子商務客戶忠誠度模型研究
(一)RFM模型
在電子商務行業(yè)中,RFM模型是對客戶忠誠度進行分析時用得最多的一種模型,客戶真實的交易數(shù)據(jù)即為RFM數(shù)據(jù),因此,數(shù)據(jù)具有較強的準確性,客戶的個人隱私通常不會涵蓋在內,獲取較為容易.RFM模型在客戶忠誠度研究中得到了廣泛的運用,其以客戶的消費金額、購買頻率、購買時間間隔為基礎.
(二)RFMSA 模型
作為電子上我中對客戶行為的重要指標,RFMSA 模型將交易金額、交易頻率、交易時間、關注度、商品評價包括在內.在RFMSA 模型中,每一個屬性維度的重要程度都具有一定的差異性,也就是五個屬性維度的權重不同.五種指標所影響用戶忠誠度的程度不一樣,以綜合反映客戶忠誠度的指標CLV客戶終生價值指標為基礎,來定義RFMSA 模型,如式(1)所示:

其中i表示客戶中的第i個客戶,CLVi表示此客戶的忠誠度指標,Ri、Fi、Mi、Si、Ai分別表示此客戶RFMSA 指標的ωR、ωF、ωM、ωS、ωA分別表示五個指標的權重系數(shù)[1].在所有指標當中,CLV與購買時間成反比,而在另外四項指標方面都成正比.在將 RFMSA模型確立之后,應預先處理數(shù)據(jù),將其轉換成系統(tǒng)需要的 RFMSA數(shù)據(jù)并加以規(guī)范,然后在分析數(shù)據(jù),在對數(shù)據(jù)進行分析的過程當中,系統(tǒng)主要是通過采取聚類分析的方式,來實現(xiàn)數(shù)據(jù)集的分類.
二、以模糊集聚類算法為基礎的電子商務客戶忠誠度算法
(一)模糊K-means算法
微課可以使模糊聚類更好地實現(xiàn),以下設計和分析了模糊K-means算法,其具體描述如下所示:假設數(shù)據(jù)集集合為,數(shù)據(jù)集的簇數(shù)量為K個,第i個簇的中心即為mi,i=1,2,...k0uj(xi)表示K-means算法聚類過程中第x個樣本對第j類的隸屬度,模糊K-means算法的目標函數(shù)可以對以下式子予以使用來描述.
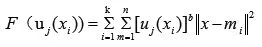
其中,b使一個可以對模糊聚類結果予以控制的模糊度常數(shù),通過模糊K-means均值隸屬度函數(shù)求導數(shù),就可以將K-means算法的最佳解放得到,如以式(2)、(3)所示:

在對K- means算法予以執(zhí)行時,能夠通過對上述兩個方程式予以實際的執(zhí)行,來得到一各具體的模糊K- means算法,這樣就能夠將其應用到實際數(shù)據(jù)劃分當中[2].給予模糊思想下的K- means算法,在對其進行具體描述時分為以下幾點:第一,對隨機初始法予以采用,以此作為數(shù)據(jù)集設定K個簇,并將各個簇的中心設定為mi;第二,對客戶的購買記錄數(shù)據(jù)集中所有的數(shù)據(jù)對象的隸屬函數(shù)進行計算,計算方式為(3);第三,將第二個步驟當中的隸屬函數(shù)作為基礎,來對所有簇的中心值mi予以計算,能夠通過算式(2)來進行;第四,遍歷數(shù)據(jù)集中所有數(shù)據(jù)對象,當隸屬度不再改變時,算法結束,不然就返回到步驟二.
(二)具體運用
本文所采用的系統(tǒng)實驗工具為Matlab2009程序處理平臺,而第五代智能英特爾酷睿i7處理器是本次實驗采用的服務器,i7一SSOOU為CPU的型號,主頻為2. 40GHz,4G內存,W in8是其操作系統(tǒng),在分析算法、實現(xiàn)算法、運行數(shù)據(jù)的準確性和有效性中得到了較好的運用.
實驗數(shù)據(jù)對中科院模式予以采用,對國家重點實驗室采集的SUNING、JD、TMALL等三個購物網(wǎng)站的用戶消費數(shù)據(jù)進行識別,使用BOW工作預處理數(shù)據(jù)集,所有的數(shù)據(jù)集中都將3萬條電子商務瀏覽記錄包括在其中,可以將其分為高、中、低三個客戶忠誠度的類別,黃金消費群體即為高忠誠度的客戶,其具有較高的交易頻率,每個月的消費金額較多,瀏覽了很多的商品,具有極高的潛在消費價值,其黏性較高;普通消費群體即是中忠誠度的客戶,商品流量的數(shù)量一般,不能確定出潛在消費價值和黏性;低忠誠度客戶也就是低值客戶,用戶對網(wǎng)站進行訪問的時間具有較長的間隔,交易很少能夠成功完成,消費額度極少.上述三個類別都其記錄都有1萬條.
為了能夠對改進的K- means算法的有效性進行評估,本文對召回率評估算法聚類的精確程度進行使用,其定義如式(4)所示.

其中,T和C分別表示的是改進的K-means的算法執(zhí)行結果的簇標號、實際客戶屬于的忠誠度類型的數(shù)目,A1(c,T )和A2(c,T )分別表示瀏覽記錄分到其歸宿的忠誠度類別T中的數(shù)目、瀏覽記錄C被錯誤地劃分到非歸屬忠誠度類別T中的數(shù)量.
通過以上三種算法運行在TMALL數(shù)據(jù)集上的結論可以看此,改進的K-means可以對軟化分的思想予以采用,可以以客戶需求為基礎,將數(shù)據(jù)準確的分為高、中、低三個忠誠度類群中[3].對于改進的k-means算法,相較于用戶興趣度模型,在高忠誠度準確度上提高了16%,相較于RFM模型,在中忠誠度準確度上和低忠誠度模型上分別提高了21.8%、25.7%,使電子商務網(wǎng)站忠誠度劃分準確度得到了有效提高,對弈檔次不同的數(shù)據(jù),可以采用不一樣的營銷方法,對客戶群體的消費能力進行維護.在JD數(shù)據(jù)集上,在中忠誠度上RFM模型所劃分的結果只有32.4%,低于在其它數(shù)據(jù)集上的劃分,極大的改變了數(shù)據(jù)劃分準確度;在高忠誠度上,用戶興趣度模型的劃分結果為43.4%,明顯低于在其它數(shù)據(jù)集上的劃分結果,也改變了數(shù)據(jù)劃分準確度.而在k-means模型進行了改進后,在山中數(shù)據(jù)集上的劃分結果沒有較大的差異,比較穩(wěn)定,由此可知,在不同的數(shù)據(jù)集上,改進的k-means模型魯棒性較高,能夠對用戶忠誠度進行有效獲取.在SUNING數(shù)據(jù)集上,RFM模型執(zhí)行時間為86ms,用戶興趣度模型執(zhí)行時間為87ms,通過改良折后K-means算法需要的執(zhí)行之間為63ms,因此能夠讓用戶忠誠度在劃分時間方面的效率得到較大的提升,能夠在很短的時間內得到準確的計算結果,進而使得電子商務網(wǎng)站在運行與推薦效率方面得到有效地提升,具體忠誠度模型見表1.

表1 SUNING數(shù)據(jù)忠誠度模型執(zhí)行時間
三、結語
大力發(fā)展的網(wǎng)絡技術,在各個領域得到了廣泛的應用,在此背景下,電子商務得到了極大的發(fā)展.電子商務網(wǎng)站要想在競爭激勵的市場中占據(jù)優(yōu)勢,就必須立足于先進的數(shù)據(jù)挖掘及時,和客戶保持良好的關系.本文為了達到將電子商務客戶忠誠度模型的準確性提高的目的,將模糊數(shù)學理論引入到了傳統(tǒng)的k-means算法中,使改進的k-means算法被提了出來,據(jù)實驗結果表明,這種算法可以將客戶忠誠度挖掘準確度提高,相較于用戶興趣度模型以及RFM模型,本文算法的魯棒性更好,應用的價值較高.
[1]牛詠梅.基于粗糙集的海量數(shù)據(jù)挖掘算法研究[J].現(xiàn)代電子技術,2016,39(7):115-119.
[2]王林彬,黎建輝,沈志宏.基于NoSQL的RBF數(shù)據(jù)存儲與查詢技術綜述[J].計算機應用研究,2015,32(2):1281-1286.
[3]謝麗.基于聚類分析的機場客戶細分服務系統(tǒng)的設計與實現(xiàn)[D].西安電子科技大學碩士論文,2014:15-17.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
