基于部件組合的聯機手寫“藏文—梵文”樣本生成
2017-11-27 08:57:49王維蘭盧小寶蔡正琦沈文韜才科扎西
中文信息學報 2017年5期
關鍵詞:信息
王維蘭 ,盧小寶 ,蔡正琦 ,沈文韜 ,付 吉,才科扎西
(1. 西北民族大學 數學與計算機科學學院,甘肅 蘭州 730030;2. 中國人民銀行 白銀中心支行,甘肅 白銀 730900)
基于部件組合的聯機手寫“藏文—梵文”樣本生成
王維蘭1,盧小寶2,蔡正琦1,沈文韜1,付 吉1,才科扎西1
(1. 西北民族大學 數學與計算機科學學院,甘肅 蘭州 730030;2. 中國人民銀行 白銀中心支行,甘肅 白銀 730900)
“藏文—梵文”包括500多個現代藏文、6 000多個梵音藏文,在文字識別領域屬于大類別的字符集,所以聯機手寫樣本采集是龐大而復雜的工程。鑒于此,提供了一種基于部件組合的“藏文—梵文”手寫樣本生成方法,主要包括: (1)確定“藏文—梵文”字符集和部件集;(2)獲取“藏文—梵文”字丁的部件位置信息;(3)采集聯機手寫“藏文—梵文”部件的樣本;(4)生成聯機手寫“藏文—梵文”字符集樣本庫。該文為聯機手寫“藏文—梵文”識別的研究提供字符訓練樣本庫和測試樣本庫,提高了手寫梵音藏文樣本采集效率,解決了樣本數量及多樣性問題,降低了樣本采集成本,為進一步聯機手寫梵音藏文識別的研究與系統開發奠定了基礎。
聯機手寫;藏文—梵文;字符集;部件組合;樣本生成
1 引言
藏文輸入與其他文字一樣,有鍵盤輸入、手寫識別輸入和掃描識別輸入等。現代藏文通常又稱為藏文,有500多個字丁。梵音藏文是梵文的藏文轉寫形式,有6 000多個字丁。本文所述的聯機手寫識別字符集包括: ISO/IEC 10646-1: Tibetan Character Collection[1]即藏文基本集中42個字丁、《信息技術 藏文編碼字符集(擴充集A)》[2]的1 536個字丁及《信息技術 藏文編碼字符集(擴充集B)》[3]的5 662個字丁,以下分別簡稱為: 基本集、擴充集A和擴充集B,藏文和梵音藏文共計7 240個字丁,本文中統稱為“藏文—梵文”識別字符集。“藏文—梵文”字符集的特點: 字符集大,在模式識別中就是 7 240 個類別。現代藏文和幾十個常用梵音藏文共592個字丁的印刷體識別已有較多研究[4-6],所開發的多字體印刷藏文字符識別系統已經得到廣泛的應用。近年來,我國少數民族文字的脫機手寫識別、聯機手寫識別成為新的研究熱點,在維吾爾文聯機手寫識別系統中分別使用GMM和HMM兩種模型進行建模并對其合并,確定最優識別結果[7]、手寫維吾爾文的預處理方法[8]。在脫機手寫藏文識別方面,選擇667個藏文字符作為識別對象,在樣本庫構建、預處理、特征提取、分類器設計及后處理等方面進行了深入研究[9]。2009年,我們完成了現代藏文517個字丁和常用梵音藏文45個共計562個字丁的聯機手寫輸入研發,并獲得“一種聯機手寫藏文字丁的識別方法”授權專利[10]。在近幾年的藏文識別研究中,中科院在基于部件的聯機手寫藏文識別方面取得一定成果[11-14]。目前,涵蓋擴充集A和擴充集B的梵音藏文的聯機手寫識別還未見相關報道。在實際應用過程中,現代藏文和梵音藏文混合使用,對于聯機手寫“藏文—梵文”識別軟件系統的研究與開發至關重要,其中聯機手寫字符樣本庫是數據基礎,且樣本庫的質量好壞也直接影響最后的識別效果。漢字的聯機手寫識別研究已有各類樣本庫[14-15],然而,目前還沒有包含擴充集A、擴充集B的藏文及梵音藏文字丁的聯機手寫樣本庫。當字符集“藏文—梵文”以字丁作為識別單位時,采集手寫樣本將是一項非常龐大和復雜的工程。鑒于此,我們提出了一種基于部件組合的“藏文—梵文”聯機手寫樣本生成的方法,生成了7 240個字符集的聯機手寫樣本庫。該方法不僅降低樣本采集的成本,也解決了大字符集“藏文—梵文”聯機手寫識別樣本的數量及樣本的多樣性問題,為進一步聯機手寫梵音藏文識別的研究與系統開發奠定了基礎。
論文第二部分是基于部件組合的聯機手寫“藏文—梵文”樣本生成構架;第三部分是字符集部件集的確定;第四部分為“藏文—梵文”字丁的部件位置信息獲取方法;第五部分是聯機手寫“藏文—梵文”部件的樣本采集;第六部分是最重要的部分,是聯機手寫“藏文—梵文”字丁樣本庫的生成;第七部分是訓練與測試的初步實驗分析;最后是結語。
2 基于部件組合的聯機手寫“藏文—梵文”樣本生成構架
基于部件組合的“藏文—梵文”聯機手寫樣本生成構架如圖1所示。
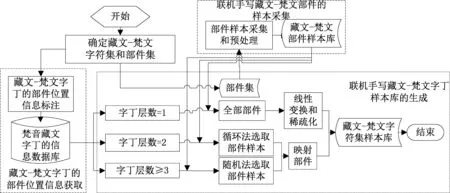
圖 1 基于部件組合的“藏文—梵文”聯機手寫樣本生成構架圖
根據圖1,主要內容有四個部分:
(1) 確定“藏文—梵文”字符集和部件集。“藏文—梵文”字符集由7 240個字丁組成,部件集由81個基本集字符和89個構件組成,形成170個部件的部件集。
(2) “藏文—梵文”字丁的部件位置信息獲取。將7 240個“藏文—梵文”的每一個字丁放置于xy平面的大小為M×N的框內,標注該字丁各個部件的外接矩形框,獲取并存儲該字丁各個部件的坐標數據信息。
(3) 聯機手寫“藏文—梵文”部件的樣本采集。設計部件樣本采集軟件,書寫者完成第1到第170個部件的采集和存儲,形成一套樣本,采集信息包括部件的BMP位圖文件和部件筆跡信息文件。獲取所有采集人員完成的樣本,得到部件樣本庫。
(4) 聯機手寫“藏文—梵文”字丁樣本庫的生成。設計樣本生成算法,根據步驟(2)所獲取的字丁各個部件的坐標數據信息,將字丁的部件樣本從部件樣本庫中取出,依次按照它們組成一個字丁的各部件位置信息,映射到對應的位置矩形,便得到字丁的樣本。生成7 240個“藏文—梵文”字丁的4 000~7 000套樣本。為聯機手寫“藏文—梵文”識別的研究與開發奠定字符集的樣本庫基礎。
3 “藏文—梵文”字符集和部件集
3.1 “藏文—梵文”字符集
“藏文—梵文”包括基本集、擴充集A、擴充集B中的字丁。在我們整理字符集時發現,擴充集A與擴充集B有一些重復的字丁,它們是:



擴充集B內部有兩個重復字丁,F1144和F1145完全一樣,如圖2所示。
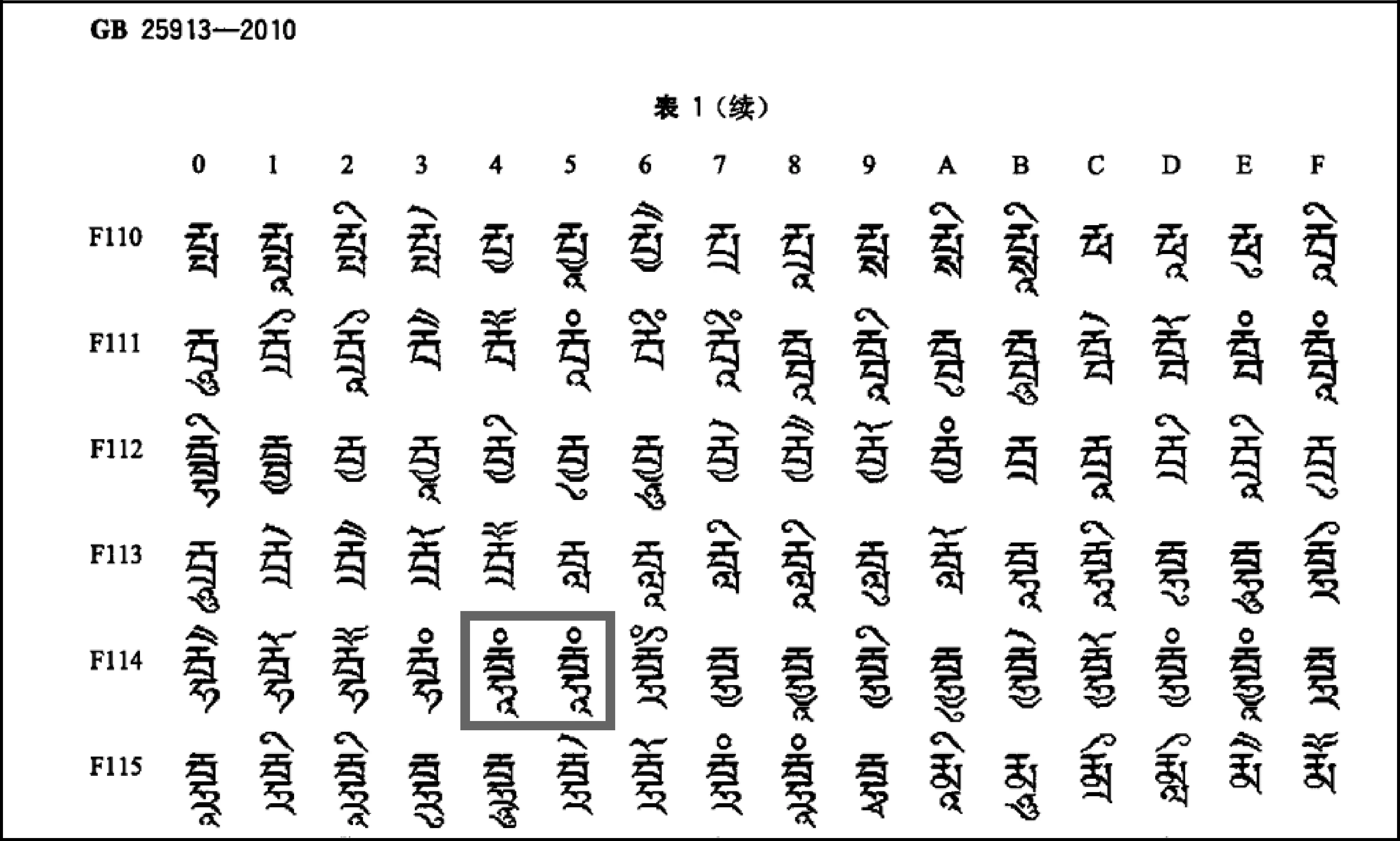
圖2 擴充集B中的兩個重復梵音藏文
刪除重復的字丁,最后確定“藏文—梵文”字符集包括基本集的42個、擴充集A的1 536個和擴充集B的5 662個,共計7 240個字丁。
3.2 “藏文—梵文”部件集
為了提高樣本質量和生成效率,降低采樣成本,本文提出了基于部件組合的聯機手寫“藏文—梵文”樣本生成方法。而“藏文—梵文”部件集的確定遵循三個原則:
(1) 部件集越小越好。因為“藏文—梵文”字丁就是基本集中一個部件上下疊加組合而成。




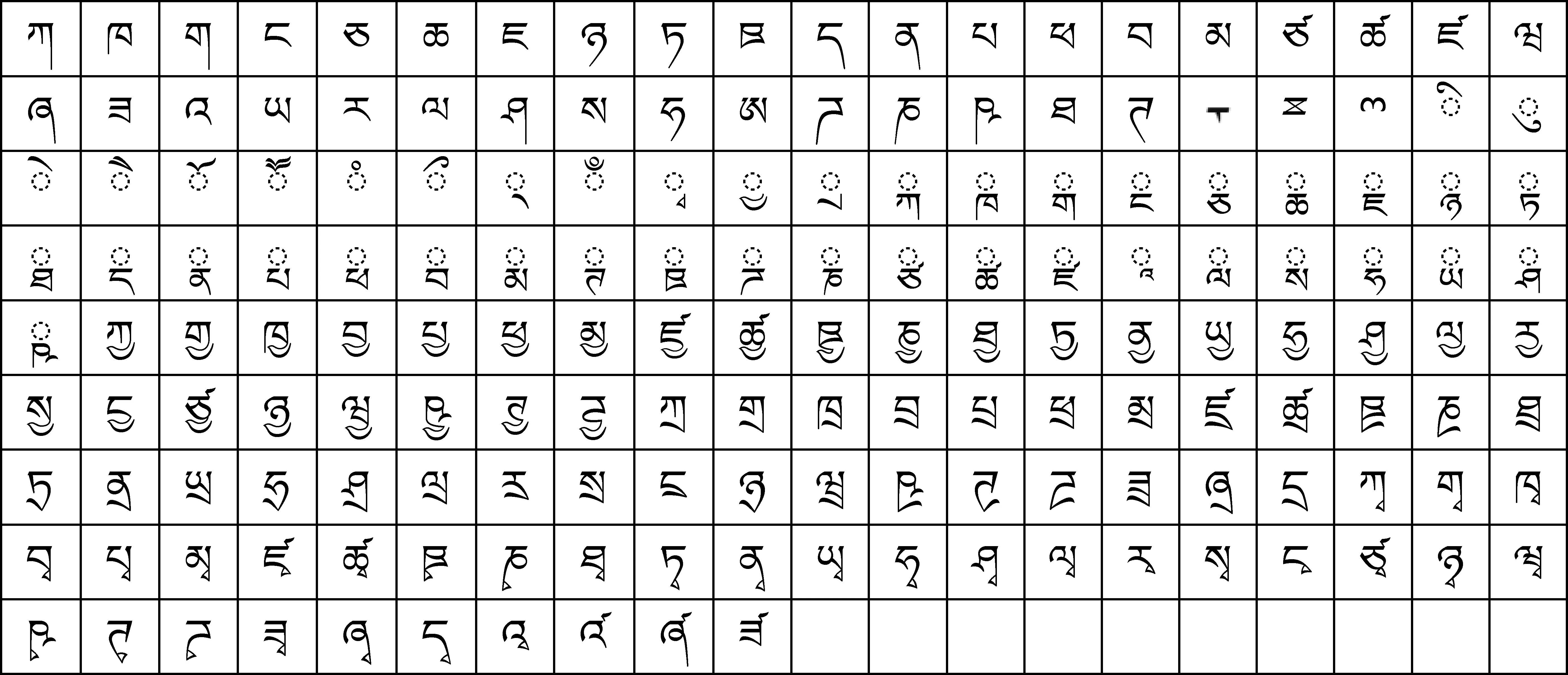
部件集由81個基本集字符和89個相連部件組成,表1所示為“藏文—梵文”的170個部件。
表1“藏文—梵文”170個部件
3.3 “藏文—梵文”部件組合信息的數據庫
擴充集A和擴充集B中的字丁都是基本集中的字符上下疊加組合而成的,字丁不等高,基于以上三個原則,根據所確定的部件集拆分“藏文—梵文”字符集,可將字丁拆分為由一至六個不等的部件構成,稱為一個字丁的部件個數或層數。同時,基于藏文編碼暨國際標準基本集ISO/IEC 10646-1和與之相一致的Unicode國際標準,使“藏文—梵文”字符集完全包括國際通用的內碼,字符集字丁的拆分信息包括序號、Unicode碼、藏文—梵文顯現、部件個數、部件1到部件6的編號、部件1到部件6的顯現等。表2所示為“藏文—梵文”字符集字丁的拆分信息表的格式及部分字符的拆分信息,分別列出了序號為1、2、43、853、4 619、7 240的藏文或梵音藏文,反映了這些字符從第一到第六個部件的拆分信息。
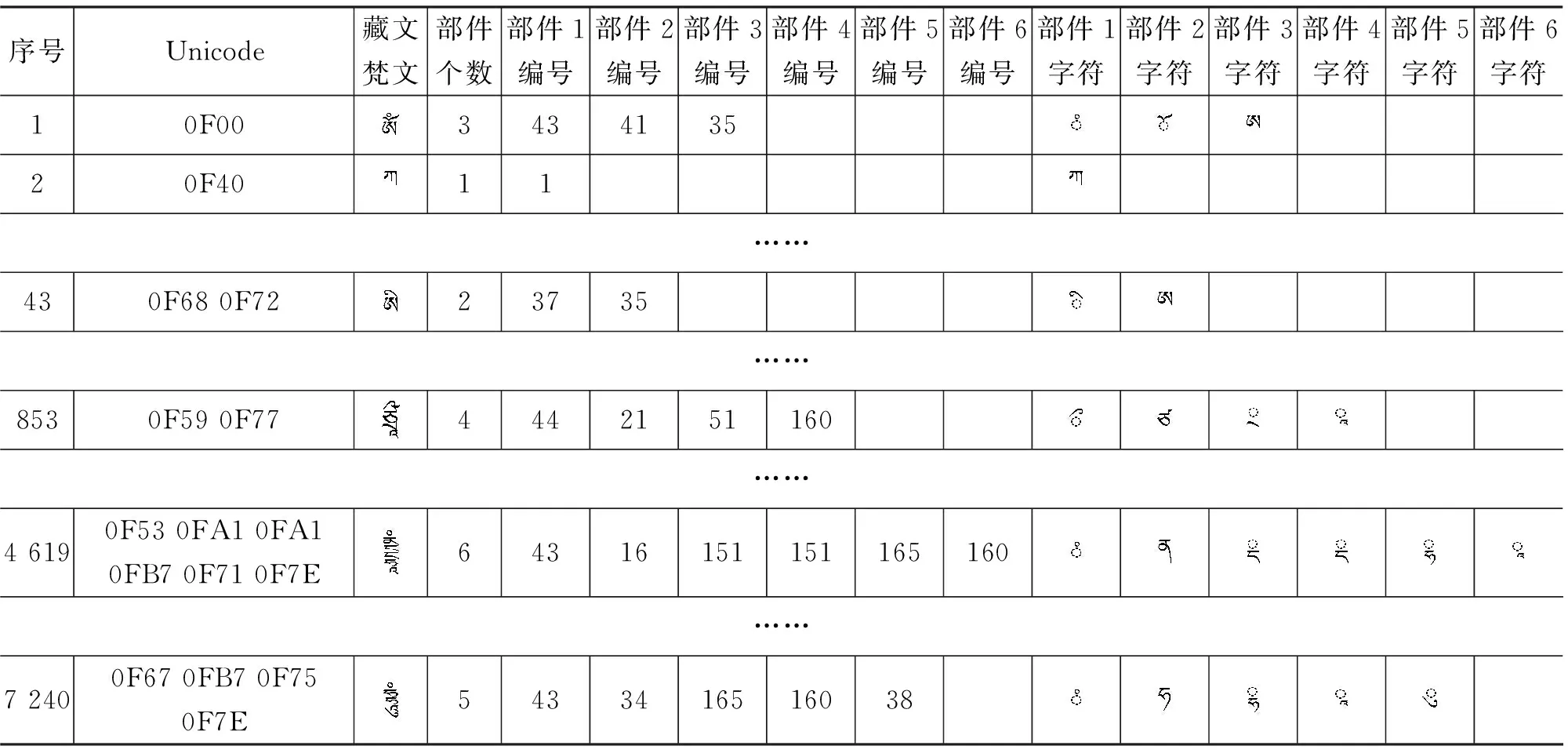
表2 “藏文—梵文”字符集字丁的拆分信息表
4 “藏文—梵文”的部件位置信息獲取
4.1 “藏文—梵文”字丁的空間位置
部件集為“藏文—梵文”字丁的部件構成奠定基礎,我們的思路是: 獲取印刷體“藏文—梵文”字丁各個部件及部件的空間位置信息,將一個字丁的聯機手寫部件,映射到對應位置便可得到該字丁的手寫樣本。
對同一字體、字號的7 240個“藏文—梵文”字丁都放置于xy平面的大小為MN的框內,所有字丁以基線對齊,基線之上有元音或者沒有。如圖3所示為四個字丁放置于xy平面MN框內的示意圖,這四個字丁只有第二個字丁有上元音。
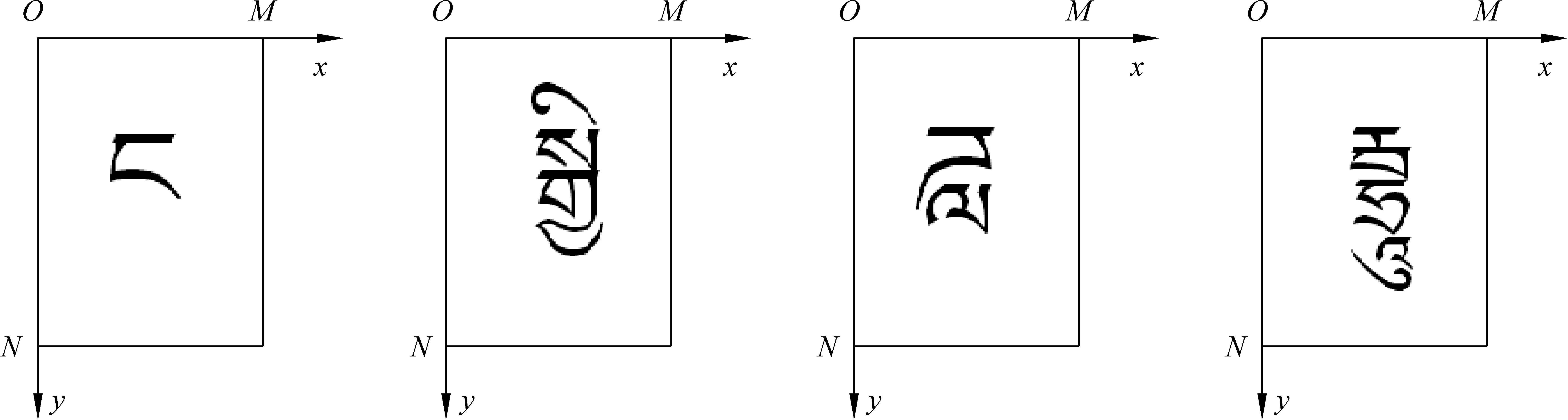
圖3 字符在xy平面、MN的框內
將待標注字丁顯示在MN的標注平面上,實際標注中寬M=240、高N=480,單位為像素。如圖4所示的字丁由兩個部件組成,上面部件位置矩形表示為Z(hd1,vd1,hd2,vd2),也就是標注每一個部件的外接矩形,獲得其左上角坐標(hd1,vd1)和右下角坐標(hd2,vd2),就獲得了該部件的位置信息。
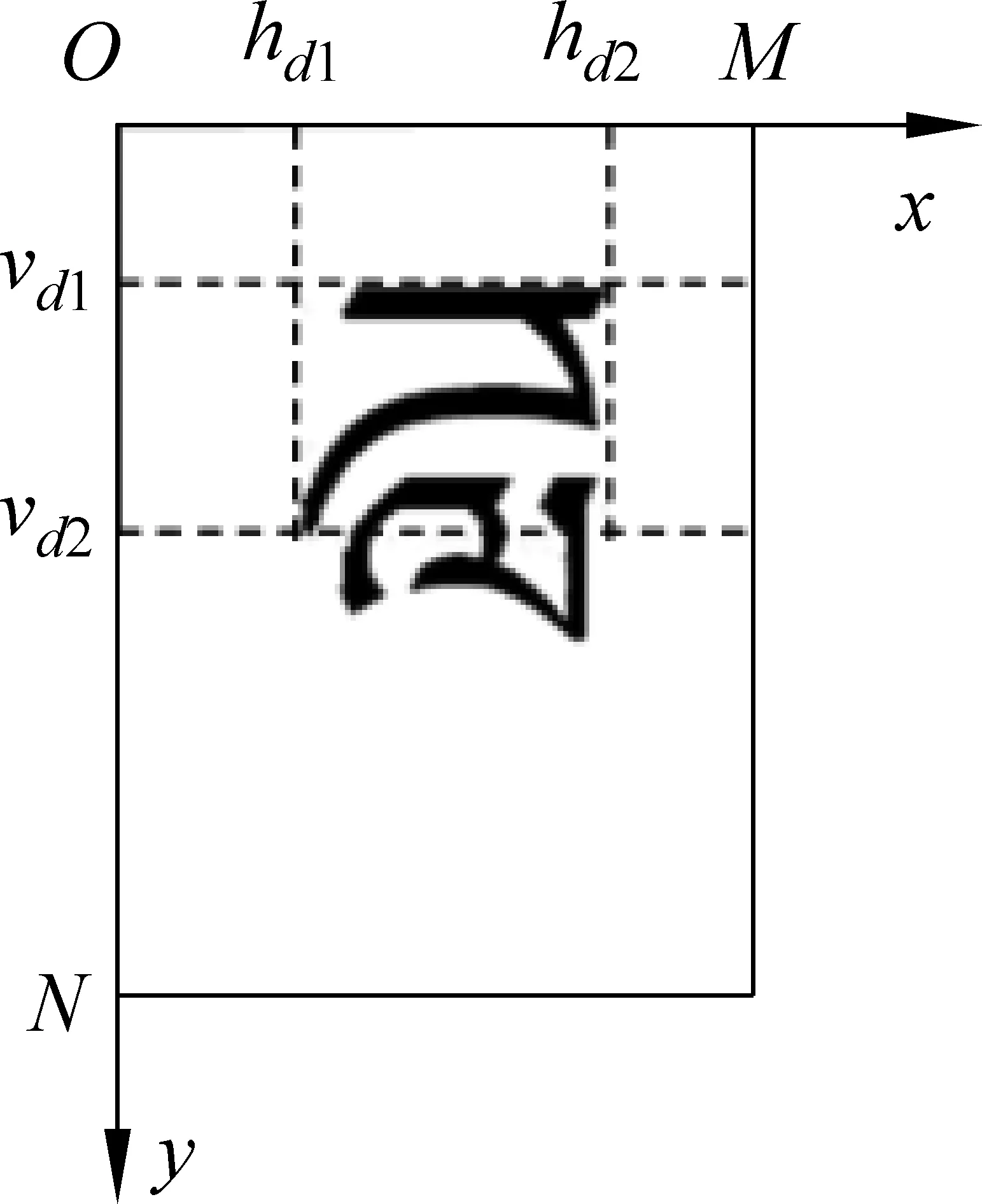
圖4 標注平面示意圖
4.2 “藏文—梵文”字丁的部件位置標注及其信息庫


圖5 部件標注過程
對7 240個“藏文—梵文”字丁進行部件位置信息的標注,并將標注過程中的信息存入數據庫,該數據庫存儲的信息包括: ID(數據行號)、Tibetan(“藏文—梵文”顯示)、Order(“藏文—梵文”序號)、Code(從上到下各部件的序號)、Sort(部件順序號),以及每個部件的左上角橫坐標X1和縱坐標Y1、右下角橫坐標X2和縱坐標Y2。表3所示為字符信息庫中

表3 字符信息庫中的部件位置信息(首、尾兩個字丁、)
5 聯機手寫“藏文—梵文”部件的樣本采集
5.1 部件的樣本采集設置、采集和存儲
為獲得自然、流暢、符合書寫習慣的部件樣本庫,我們設計了部件樣本采集軟件。在Android平臺的iPad上完成部件的樣本采集,采集信息包括部件的BMP位圖文件,圖6所示為一個采集者的部分部件樣本位圖。

圖6 一個采集者的部件位圖(部分)樣本
位圖文件便于查看,另一個存儲的是部件筆跡信息文件,筆跡信息文件中包含書寫時筆跡經過的點、筆畫結束和部件結束的標記信息:
(x11,y11) (x12,y12)…(x1n1,y1n1)(-1,-1),
(x21,y21) (x22,y22)…(x2n2,y2n2)(-1,-1),
……
(xt1,yt1) (xt2,yt2)…(xtnt,ytnt)(-1,-1)(-2,-2)
其中(xtnt,ytnt)表示第t個筆畫的第nt個點的坐標,(-1,-1)表示從落筆到抬筆一個筆畫的結束,(-2,-2)表示一個部件書寫結束。
5.2 部件樣本庫
每個人完成第1到第170個部件的采集和存儲,形成一套部件樣本,樣本的實際分布包括書寫者所在的地域、年齡、學歷等因素,共有300多人參加采集;為保證樣本的質量,還需要對部件樣本進行預處理,如去除或修正錯誤樣本,甚至整套刪除,以及去除孤立點、進行傾斜校正等,從而形成部件樣本庫。
6 聯機手寫“藏文—梵文”字丁樣本庫的生成
6.1 部件樣本到字丁樣本的映射
根據字丁拆分和位置矩形標注的結果,將構成字丁的部件樣本逐一從部件樣本庫中取出,依次按照其位置信息映射到對應位置矩形,便得到字丁的樣本;設“藏文—梵文”字丁Z由m個部件r1、r2、r3、…、rm-1、rm構成,構成字丁Z的部件中部件ri的樣本數為ksi,則字丁Z可生成的樣本有ks1×ks2×…×ksi×…×ksm種,實際中,部件樣本是成套采集的,因此ks1=ks2=…=ksi=…=ksm=k,其中k為部件樣本的套數。
“藏文—梵文”字丁(或其中的部件)相應位置如圖7所示,圖7(a)是部件樣本的位置矩形,位置矩形表示為Z(hsc1,vsc1;hsc2,vsc2),其中hsc1和vsc1為矩形左上角的橫坐標和縱坐標,hsc2和vsc2為矩形右下角的橫坐標和縱坐標,M'×N'是部件采集平面;圖7(b)是圖7(a)所對應部件映射平面的位置矩形,M"×N"為部件映射平面,圖7(b)中位置矩形,由“藏文—梵文”識別字符集信息庫中的部件位置信息,通過線性變換計算獲得,如式(1)所示。
這個變換確定了部件在映射平面中的位置,其中(hsc1,vsc1,hsc2,vsc2)為部件的位置信息。部件映射就是對采樣平面中位置矩形內的部件做線性變換,然后復制到映射平面的過程,線性變換參數,如式(2)所示。
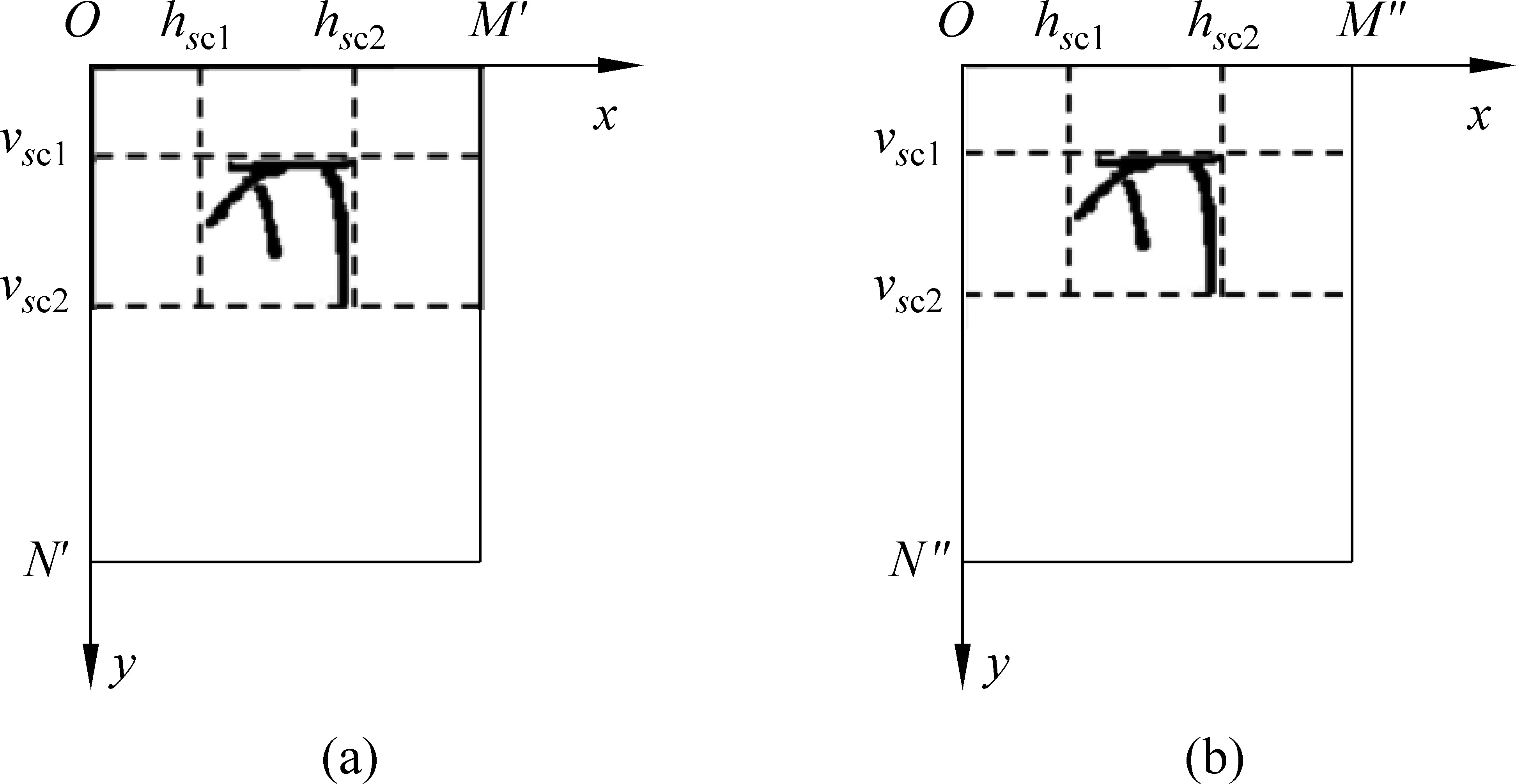
圖7 部件樣本映射到“藏文—梵文”字丁相應位置示意圖
圖8(a)、圖8(b)和圖8(c)是圖7(a)的部件樣本復制到映射平面的位置矩形后出現的三種情況,為了取得更好的字丁生成效果,需要校正部件在映射平面位置矩形內的數值。設部件樣本上的任一點為(x,y),對應校正后的點為(x’,y’),校正可分為三種情況:
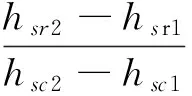

圖8 部件樣本到映射平面的位置情況示意圖
6.2 7 240個字丁樣本的生成
用于7 240個類別的識別問題,需要訓練樣本和測試樣本4 000~7 000套,本次實施過程生成了5 000套。
對單部件字丁的樣本,采用非同比伸縮變換、稀疏化的方法,通過改變字丁中點的空間位置信息來增加樣本的數量,但是同比伸縮變換的長寬比必須控制在一定范圍內,超出范圍將造成字符嚴重扭曲變形以致無法識別;稀疏化是一種類似于數據丟包的方法,通過隨機丟點的方法來改變字丁中筆畫的軌跡信息,丟點太多則有可能完全失去字符的空間信息,丟點太少則不足以改變字符的空間信息,選擇適當的范圍也是關鍵所在。線性變換、稀疏化算法如下:
(1) 采用線性變換
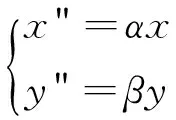
(2) 稀疏化算法
稀疏化分四步:
① 讀取所采集的字丁存入數組中;
② 設置丟點的數目υ并計算數組大小len,丟點的數目υ的范圍是: 0.05len≤υ≤0.3len;
③ 產生υ個數組索引隨機數rand,0≤rand≤len-1;
④ 刪除υ個隨機數索引對應的點,存儲新生成的字丁樣本。
“藏文—梵文”字丁樣本生成的算法如下:
S1. 判斷待生成字丁的部件層數;
S2. 如果字丁層數為1,則轉S3,如果字丁層數為2,則轉S4,如果字丁層數大于等于3,則轉S5;
S3. 將通過線性變換和稀疏化得到的樣本存放到一起,并隨機地將其分配到每一套“藏文—梵文”樣本中;
S4. 根據“藏文—梵文”字丁的部件位置信息標注結果,將一個字丁的兩個部件從上到下按照其編號和位置信息從得到的信息數據庫中讀取,并映射到大小為M×N的位置矩形中;
S5. 根據“藏文—梵文”字丁的部件位置信息標注結果,將組成字丁的部件從上到下均勻地從部件樣本庫中取出,然后映射到大小為M×N的位置矩陣中。
上述算法中,所謂均勻地從部件樣本庫中取出部件,方式如下:
通過以上過程,我們完成了7 240個類別聯機手寫“藏文—梵文”字符集樣本5 000套,共36 200 000個樣本。這些樣本再經過消除孤立點、筆速均勻化、歸一化等預處理就可用于聯機手寫“藏文—梵文”識別的研究。
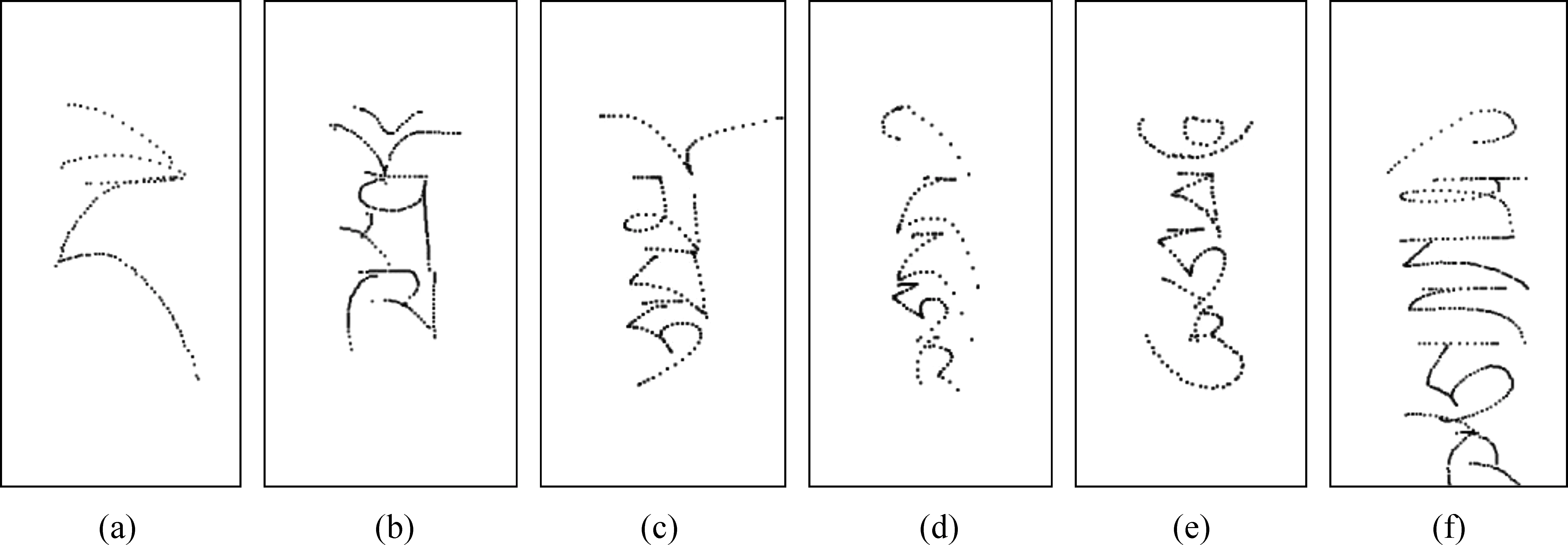
圖9 不同層數“藏文—梵文”字丁合成的樣本實例圖
7 訓練與測試的初步實驗分析
7.1562個字丁在不同測試樣本集上的識別結果比較
字丁預處理、特征提取與壓縮、分類器設計等采用原有的方法[11],同時,原來562個藏文字丁,315個人手寫完成315套作為訓練集、60人書寫的60套作為測試樣本集,首選、三選、五選和十選識別率如表4的第一行所示。新的方法所生成的樣本訓練的分類器,同樣取另外60套作為測試樣本集,測試的結果如表4的第三行所示。新的樣本集上測試識別率有較大幅度的提高。分析原因,一方面,可能原

表4 平均識別率比較
來采集樣本時,每個采集者書寫到后面相對都寫得比較潦草。
另外,562個字丁十選識別率的分布情況如表5所示。由表5可見,現在識別率在99%以上的占總字數的35.76%;識別率在98%以上的占總字數的61.38%;識別率在97%以上的占總字數的77.94%;全部的字丁識別率都在90%以上。此外,雖然現在識別率100%的字丁比原來多3個,但識別率99%以上的字丁大幅增加。表6是一套測試樣本中擴展集A的幾個字丁識別的前十選排序情況,其中前三行都是首選正確,即選項為1;然后是四個字丁的正確識別結果為第二選;最后兩行正確的識別結果分別在三選、四選。由表6可見,無論識別正確的是首選還是四選,前十個侯選序列基本都是極相似的字丁。
7.2 7 240個字丁的測試結果
7 240個字丁的5 000套樣本,隨意選取訓練集4 500套樣本、測試集500套。
對500套樣本進行測試,首選、三選、五選、十選

表5 十選識別率的分布情況
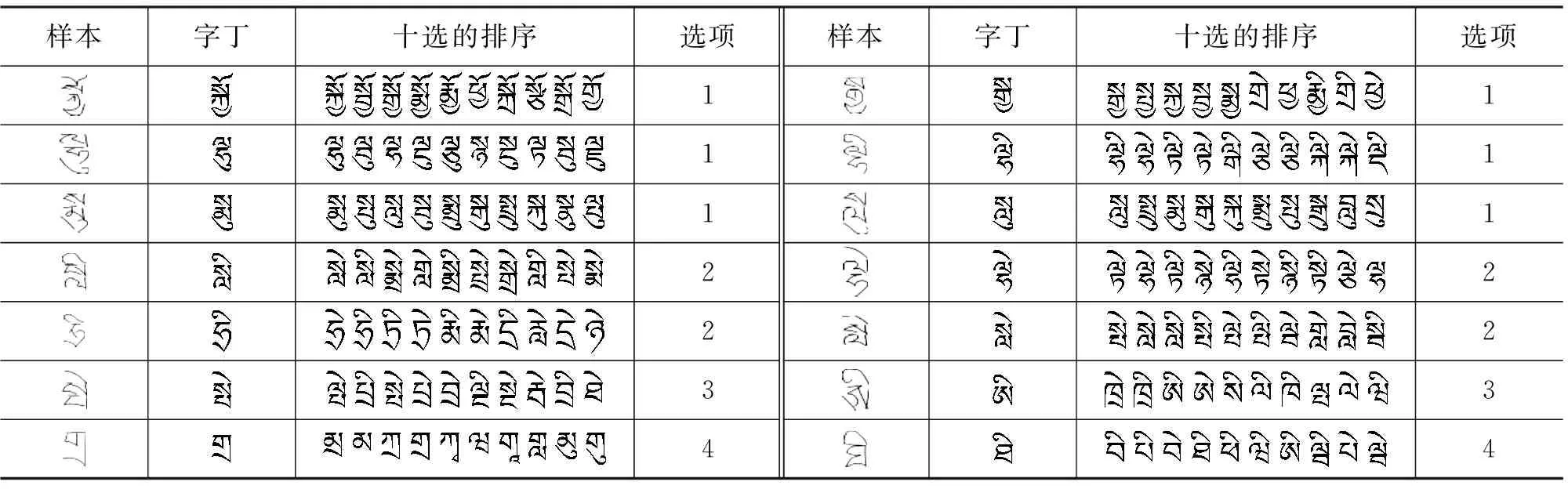
表6 一些擴充集A中的字丁測試識別情況


表7 7 240個字丁500套樣本的平均識別率

表8 7 240個字丁第十選識別率字分布情況
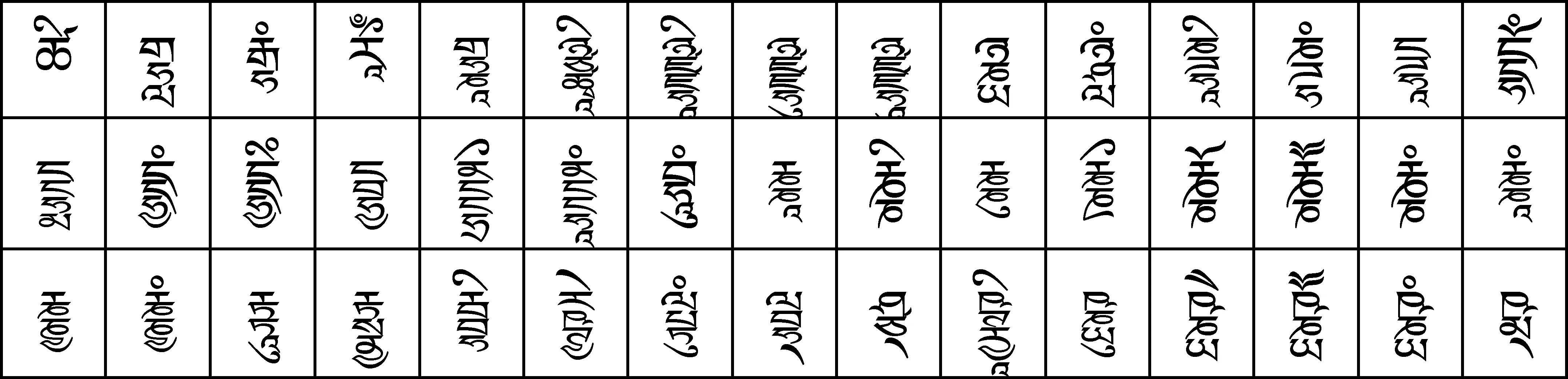
表9是十選識別率100%的45個字丁,前三個是擴充集A中的字丁,其余全部是擴展集B中的字丁,除第一個字丁是基字加元音筆劃簡單外,其他字丁都疊加層數多筆畫較為復雜。初步的判斷: 復雜字丁的識別率較簡單字丁的識別率高。
表9十選識別率100%的45個字丁
8 結語
根據藏文、梵音藏文的書寫習慣,確定170個部件的“藏文—梵文”部件集,以及“藏文—梵文”字符集7 240個類別;開發完成了“藏文—梵文”字丁的部件位置信息獲取軟件,形成該字符集各個字丁的部件位置信息數據庫;開發了聯機手寫“藏文—梵文”部件的樣本采集軟件,已采集了300多套部件樣本集;根據“藏文—梵文”部件位置信息數據庫、部件樣本集,設計字丁樣本生成的算法,完成了聯機手寫“藏文—梵文”字符集樣本庫生成軟件,現已生成7 240個聯機手寫“藏文—梵文”的樣本庫5 000套,用于聯機手寫“藏文—梵文”識別研究和開發的訓練樣本與測試樣本,提高了手寫樣本采集效率和樣本多樣性,降低了樣本采集成本。初步的訓練和測試結果: 對562個(現代藏文517個和常用梵音藏文45個)字丁,在所生成的樣本庫上進行訓練和測試,平均識別率有了較大的提高;7 240個字丁的十選識別率達到95.956 5%。在此基礎上,將進一步完善相關內容,完成聯機手寫“藏文—梵文”的識別系統。
[1] ISO/IEC 10646-1:Tibetan Character Collection[S].ISO/IEC JTC1/SC2/WG2,2000.
[2] 國家質量技術監督局.GB 22323—2008 信息技術藏文編碼字符集(基本集及擴充集A)[S].北京: 中國標準出版社,2008.
[3] 國家質量技術監督局.GB/T 25913—2010 信息技術 藏文編碼字符集(擴充集B)[S].北京: 中國標準出版社,2010.
[4] 王維蘭,丁曉青,祁坤鈺.藏文識別中相似字丁的區分研究[J].中文信息學報,2002,16(4):60-65.
[5] 王華,丁曉青.多字體印刷藏文字符識別[J].中文信息學報,2003,17(6):47-52.
[6] 丁曉青,王華,劉長松,等.多字體多字號印刷體藏文字符識別方法[D].ZL200410034107.4,2004.
[7] 熱依曼·吐爾遜,吾守爾·斯拉木.一種維吾爾語聯機手寫識別系統[J].中文信息學報,2014,28(3):112-115.
[8] 劉衛,李和成.基于多模板歸一化的維吾爾文字母識別算法[J].中文信息學報,2016,30(1):156-161.
[9] Huang Heming, Da Feipeng, Hang Xiaoxu. Wavelet transform and gradient direction based feature extraction method for off-line handwritten Tibetan letter recognition[J].Journal of Southeast University,2014(1):27-31.
[10] 王維蘭,錢建軍,多杰卓瑪,等.一種聯機手寫藏文字符的識別方法[P].中華人民共和國國家知識版權局. ZL200910128595.8, 2011.
[11] Ma L L,Wu J. Semi-automatic Tibetan component annotation from online handwritten Tibetan character database by optimizing segmentation hypotheses[C]//Proceedings of the International Conference on Document Analysis amp; Recognition, 2013:1340-1344.
[12] Ma L L, Wu J. A Tibetan component representation learning method for online handwritten Tibetan character recognition[C]//Proceedings of the International Conference on Frontiers in Handwriting Recognition, 2014:317-322.
[13] Ma L L, Wu J. Online handwritten Tibetan syllable recognition based on component segmentation method[C]//Proceedings of the International Conference on Document Analysis amp; Recognition,2015:46-50.
[14] Wang Dahan, Liu Chenglin, Yu Jinlun, et al. CASIA-OLHWDB1: A database of online handwritten Chinese characters[C]//Proceedings of the 10th International Conference on Document Analysis and Recognition, 2009:1206-1210.
[15] Jin L, Gao Y, Liu G, et al. SCUT-COUCH2009-A comprehensive online unconstrained Chinese handwriting database and benchmark evaluation[J]. International Journal on Document Analysis and Recognition,2011,14(1):53-64.

王維蘭(1961—),學士,教授,主要研究領域為圖像處理與模式識別、智能信息處理與應用軟件和藏文信息處理等。
E-mail: wangweilan@xbmu.edu.cn

盧小寶(1984—),碩士,工程師,主要研究領域為圖像處理與模式識別、網絡數據庫。
E-mail:lxb198416@163.com

蔡正琦(1974—),碩士,副教授,主要研究領域為圖像處理與模式識別。
E-mail:caizhengqi@126.com
OnlineHandwrittenSampleGeneratedBasedonComponentCombinationforTibetan-Sanskrit
WANG Weilan1, LU Xiaobao2, CAI Zhengqi1, SHEN Wentao1, FU Ji1, CAIKE Zhaxi1
(1. Department of Math and Computer Science,Northwest University for Nationalities, Lanzhou, Gansu 730030, China;2. Baiyin Center Subbranch, People’s Bank of China, Baiyin, Gansu 730900, China)
Tibetan-Sanskrit includes more than 500 Tibetan characters, and more than 6000 Sanskrit. Belonging to the large class of character set, the sample collection of the online handwritten is a large and complex project. We present an online handwriting character sample generation method based on component combination for Tibetan-Sanskrit. The proposed method includes four main parts: (1) to determine the Tibetan-Sanskrit character set and component set; (2) to get location information of Tibetan-Sanskrit characters; (3) to collect online handwritten sample of component set for Tibetan-Sanskrit; and (4) to generate sample database of online handwritten Tibetan-Sanskrit character set. This provides the character's training sample set and test sample set for online handwritten Tibetan-Sanskrit.
online handwritten; Tibetan-Sanskrit; character set; component combination; sample generation
1003-0077(2017)05-0064-10
TP391
A
2016-11-26定稿日期2017-03-17
國家自然科學基金(61375029);國家民委領軍人才計劃;西北民族大學中央高校基本科研業務費專項資金(31920170142)。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
