基于異構多核可重構系統的矩陣求逆設計與實現?
2017-11-28 01:57:55錢慶松
艦船電子工程 2017年10期
關鍵詞:系統
錢慶松
(昆明船舶設備研究試驗中心 昆明 650051)
基于異構多核可重構系統的矩陣求逆設計與實現?
錢慶松
(昆明船舶設備研究試驗中心 昆明 650051)
矩陣求逆是一種常見的計算密集型信號處理算法,廣泛應用于聲納探測、雷達等高實時性要求的數字信號處理領域。隨著多核芯片技術的成熟,其強大運算能力提供了一種全新的矩陣求解途徑。論文在基于NoC的異構多核可重構系統上,映射了一種高斯消去法與上下三角矩陣分解(LU分解)法相結合的矩陣求逆方法。通過權衡系統并行度,核內存儲空間和系統處理速度等多方面因素,進行并行算法分解、組合和任務分配,實現了64維以下任意維的復數矩陣求逆。
矩陣求逆;LU分解;異構多核;算法映射
1 引言
現代探測聲納發展呈現運算量大、實時性強及小型化的趨勢[1],因而對聲納的信號處理平臺提出了越來越高的要求,高性能處理器在聲納信號處理中發揮的作用日趨重要,對其運算能力和數據吞吐能力的要求也越來越高[2]。基于可重構技術的片上多核處理器是一種將可重構技術與片上多核系統(Multi Processor System-on-Chip,MPSoC)相結合的硬件方案,利用集成片內的可重構硬件的可編程特性,可以針對不同的應用特征,定制片上數據路徑。通過提高算法與硬件結構間的適配性,充分利用其并行計算處理能力,在確保數據吞吐率及處理速度情況下,具有更高的使用靈活性,有效地滿足數據密集型和計算密集型任務的要求[3~5]。
在數字信號處理領域,矩陣求逆運算是一項非常重要的基本操作,廣泛應用于通訊、導航、水下探測和雷達等領域。矩陣求逆的方法很多,比如初等變換法、伴隨矩陣法、分塊矩陣法等[6]。目前多使用定制專用硬件加速模塊方法實現其快速求解,矩陣求逆計算的強數據相關性的特點給算法在多核系統中的實現帶來了很大挑戰,這在處理大維數矩陣時表現的更加顯著[7~9]。本文在一種基于NoC的異構多核可重構系統,結合已有的三角矩陣求逆硬件實現方法、高斯消去法和矩陣的LU分解算法,探索了一種易在多核系統上以較高并行度執行的復數矩陣求逆方法。充分的利用異構多核系統的并行性,提高計算效率,保證計算結果具有較高精度。
2 算法分析
矩陣的一種比較常用的分解方法是矩陣的LU三角分解,將一個n階矩陣A分解為一個下三角矩陣L和一個上三角矩陣U的乘積[7]。對上下三角矩陣求逆是非常方便的,可以利用這一特性減少求任意n階矩陣A的逆矩陣的運算量和復雜度。具體的流程為:首先對矩陣進行LU分解,然后對L和U矩陣求逆得到L-1和U-1,最后通過矩陣乘積求得原始矩陣A的逆A-1=U-1L-1。
2.1 矩陣的LU分解[6]

高斯消去法可行的充要條件是方程(3)的系數矩陣A的所有順序主子式Di≠0,i=1,2,…,n,本文硬件求逆方法所適用的矩陣也需滿足這一條件。其中,高斯消去法包括消元和回代兩個過程,本文只利用了消元過程,故回代過程就不做贅述。
2.3 矩陣求逆
將待解矩陣A右接一單位矩陣E,得到(A,E)。利用矩陣的初等行變換對(A,E)進行高斯消元過程得到(U,B),易知B=L-1。同樣,將U右接一單位矩陣(U,E),進行初等變換得到(E,U-1),最終得到原始矩陣A的逆矩陣A-1=U-1L-1,完成整個矩陣求逆的過程。
3 異構多核可重構系統
ReMPSOC是一款可編程異構多核SoC處理系統,結構簡單,具有極大的數據吞吐量級計算核集成度,主要面向高密度計算應用。本系統不僅適用于某些特殊類型運算,并具有一定的通用性[10]。
系統結構圖[11]如圖1所示,系統中包含通信網絡、主控單元(MC)、計算單元(Cluster,C)、接口單元及存儲模塊(MEM),不同的功能單元(以下稱為簇)連接在不同的mesh網絡的路由節點上,完成控制、運算、接口通訊、訪存等任務。每個簇分別有一個狀態上傳接口、一個配置下達接口、PCC數據接口;簇間通過狀態網絡、系統主控制器及配置網絡傳遞控制信息;通過PCC網絡傳輸運算數據。運算簇實現數據運算,并提供符合IEEE 754標準的32位單精度浮點運算能力。運算簇包括兩種:可重構計算單元(RCU)運算簇、協處理器(COP)運算簇。
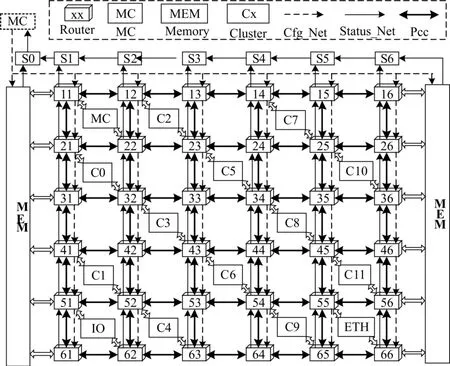
圖1 多核系統芯片結構示意圖
1)RCU運算簇[10]
RCU運算簇提供符合IEEE 754標準的32位浮點運算能力,主要完成規則的浮點復數∕實數運算,包括復數乘、復實乘、矩陣乘、乘法、加減法等運算。RCU運算簇具有可重構特性,采用2PE結構,支持存儲運算和流運算兩種運算模式。
2)COP運算簇
COP運算簇提供符合IEEE 754標準的32位浮點運算能力,主要完成非規則的浮點復數∕實數運算,包括:乘法、加減法、除法、開方、正余弦等運算。COP運算簇基于SIMD架構,采用Microblaze作為運算的控制單元,并采用符合Microblaze的DFSL接口協議的硬件浮點運算協處理器作為加速單元,能夠同時完成2路32位寬的浮點運算。
4 算法映射
本文映射的是基于高斯消元法和LU分解法的64維復數矩陣的求逆,分5個任務完成整個求逆過程,各個任務的源數據、結果數據和及功能可從圖2看出,其中Λ為一對角矩陣,U'為一下三角矩陣。通過修改配置信息和軟件代碼中的循環次數可實現64維以下任意維復數矩陣的求逆。
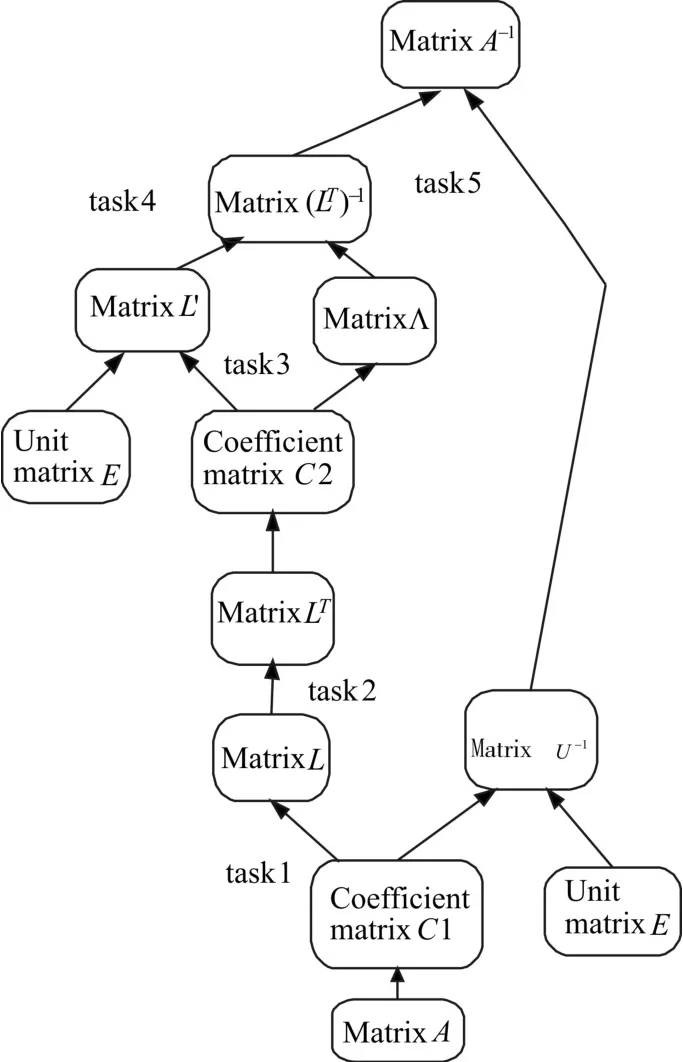
圖2 矩陣求逆流程圖
4.1 求解U-1和L過程的映射
為了方便起見,以式(3)中的 A=A(0)為例,task1為計算下三角矩陣L并根據消元過程中得到的系數矩陣,并根據系數矩陣對單位矩陣進行列變換得到U-1。計算下三角矩陣和進行列變換時,都是基于高斯消元方法,具體的計算過程是通過不斷地循環完成的,每一次循環完成對A矩陣中一列元素的消元。該過程屬于計算密集型運算,前后數據相關性大,計算不規則,因此采用具有較強的本地運算能力和靈活的地址控制機制COP完成主要操作。task1的任務映射圖如圖3所示。以64維矩陣為例進行說明,整個消元過程是通過63次大的循環完成的,以第一次循環為例:COP0首先向MEM存儲單元請求原始矩陣A,計算消元系數

將系數向量通過數據網絡傳遞給COP1、COP2同時寫回MEM存儲單元;COP1和COP0分別用于根據系數矩陣求下三角矩陣L和對單位陣進行列變換求U-1,避免對系數矩陣的重復讀取而降低運算效率。COP1、COP2進行復數乘,將對應的系數乘以第一列;RCU0、RCU1執行復數加即消元過程,當RCU0和RCU1復數加任務完成時也就說明第一列的消元已經全部完成,這時COP0會向MEM存儲單元請求新生成的矩陣執行第二次循環。圖4用偽碼表示了整個消元過程。

圖3 高斯消元過程偽碼

圖4 task1任務映射圖
4.2 求解LT過程的映射
task2對task1得到的L矩陣進行轉置操作。為了充分的利用系統中的運算簇以提高算法的執行效率,本文采用分塊轉置的方法,其公式如下。
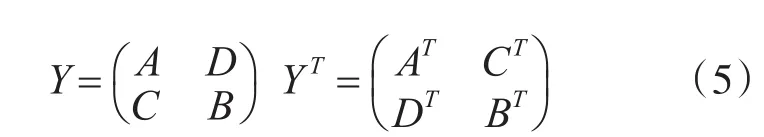
在轉置過程中將原矩陣分為四塊,對其中的每一塊進行轉置操作。在轉置任務時,使用具有靈活地址跳變規律的COP進行轉置運算,task2中使用4個COP并行執行轉置操作,每個COP對其中的矩陣中的一塊進行轉置,然后將計算完成的結果寫回DDR存儲單元,以作為后續操作的源數據。task2的任務映射圖如圖5所示。
圖5 task2任務映射圖
4.3 U-1L-1的映射
根據任務分解圖可以得知,task3與task1的操作基本相同,僅是源數據和結果數據不同,因此task3與task1的任務映射圖相同。task3根據task2轉置得到的LT,使用相同的計算方式得到一對角矩陣Λ和一下三角矩陣L'。task4將L'的每一列除以矩陣Λ相應行中對角線上的元素,得到(LT)-1在RCU和COP中,只有COP支持復數除法操作,為了提高運算效率,依然使用4個COP進行相除計算,任務映射圖與圖4基本相同。
task5將LU分解得到的兩個結果相乘,進行U-1L-1計算,完成整個求逆操作。在task4中得到的結果為(LT)-1,在計算過程中,不再對(LT)-1進行轉置操作,而是直接按其逆矩陣的形式取出與L-1執行矩陣乘操作。矩陣乘任務為比較規整的任務,為了充分的使用系統中的運算簇,此任務使用8個RCU執行并行計算,RCU根據其地址控制機制對輸入的數據進行乘累加,最后將A-1寫回MEM存儲單元。
5 實驗和結果分析
本次實驗是在Xilinx公司Virtex7系列的XC7V2000T FPGA芯片上實現的,工作頻率為100MHz。實驗結果通過網口簇上傳至主機,并與MATLAB軟件計算結果進行了對比,絕對誤差為10-4,整個計算過程共需要907222個時鐘周期,其中包括了數據傳輸時間。以下是各個任務所消耗周期數:

圖6 task5任務映射圖
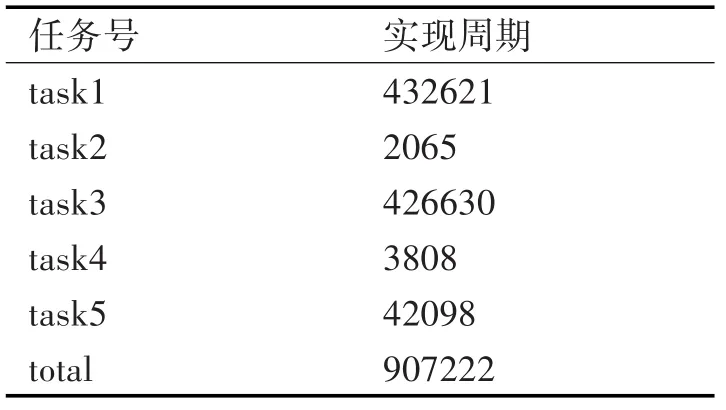
表1 矩陣求逆中各任務的計算時間
為了方便對實驗結果進行的分析,直觀的表示計算效率,以不同任務的并行度DP表示系統的計算效率,并行度定義如公式6所示[12]。
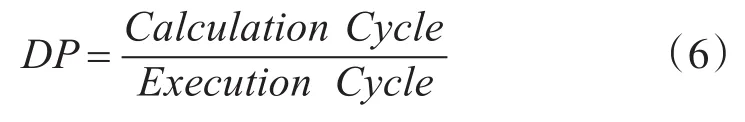
在公式中,Calculation Cycles表示任務計算過程中所需的計算周期,Execution Cycles表示完成整個任務所消耗的周期數。各任務的計算并行度如表2所示。
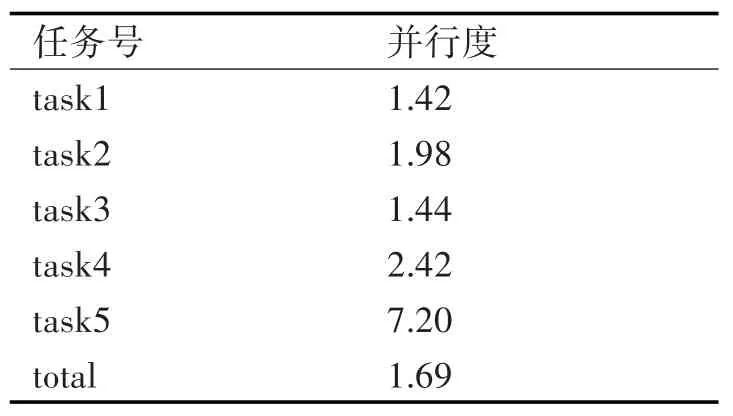
表2 矩陣求逆中各任務的并行度
在本文的映射方案中,對于64維以下的矩陣求逆只需改變task1中的循環次數及部分數據信息即可,具有較好的靈活性。計算過程中任務計算的并行度不僅與參與運算的運算簇有關,還與計算任務的類型有關,從表2可以看出,task1由于計算過程中前后數據相關性大,且整個計算過程需要不斷的循環完成,任務并行度相對較低。在task5中,計算過程中沒有數據相關性且充分的利用系統中的運算簇,任務并行度達到最高,也反應出系統對于規則運算的良好適應性及計算效率。
6 結語
在數字信號處理領域,研究在大維數矩陣求逆中減少運算時間,提高運算效率具有重要意義。本文通過對矩陣求逆算法的理論分析,提供了一種基于異構多核可重構系統的硬件復數矩陣求逆解決方案,并在FPGA開發板上驗證了其正確性。
通過實驗結果分析可得,系統性能仍有較大的提升空間,為了得到更高的處理速度和任務并行度,可以增強和改善多核系統中各個運算簇的功能,減少求逆過程中不必要的運算。進一步研究矩陣求逆的算法,加強矩陣求逆算法的并行度,提高加速效果等,對于研究多核芯片技術具有重要意義。
[1]任宇飛,袁俊舫,李崢,等.多核DSP在無人平臺探測聲納中的應用研究[J].應用聲學,2014,33(6):496-504.
[2]張曉燚.基于多核DSP的陣列信號處理系統設計[D].北京:中國科學院大學,2015.
[3]Chen F Y,Zhang D S,Wang Z Y.Research of the Heterogeneous Multi-Core Processor Architecture Design[J].Computer Engineeringamp;Science,2011,33(12):27-36.
[4] Ju R.A Hardware∕Software Method for Heterogeneous Cores Cooperating on Stream Architecture[J].Chinese Journal of Computers,2008,31(11):2038-2046.
[5]杜高明.MPSoC-NoC多核體系結構及原型芯片實現技術研究[D].合肥:合肥工業大學,2007.
[6]蘇育才.萎翠波,張躍輝.矩陣理論[M].北京:科學出版社,2006:166-172.
[7]郭春煊,毛志剛,謝憬,等.矩陣求逆運算的VLSI實現[J].計算機技術與發展,2008,18(5):219-223.
[8]王銳,胡永華,馬亮,等.任意維矩陣求逆的FPGA設計與實現[J].中國集成電路,2007,16(4):51-56.
[9]李濤,張忠培.矩陣求逆的FPGA實現[J].通信技術,2010,43(11):147-149.
[10]Wang Xing,Zhang Duoli,Song Yukun,et al.Design and Implementation of a reduced floating-point reconfigurable computing unit[C]∕International Conference on Computer,Network Security and Comunication Engineering,2014.
[11]SONG Y,JIAO R,ZHANG D,et al.Performance analysis for matrix-multiplication based on an heterogeneous multi-core SoC[C]∕ASIC,2015 IEEE 11th International Conference on.IEEE,2015:1-4.
[12]張多利,沈休壘,宋宇鯤,等.基于異構多核可編程系統的大點FFT卷積設計與實現[J].電子技術應用,2017,43(3):16-20.
Design and Implementation of Matrix Inversion on Heterogeneous Multicore Reconfigurable System
QIAN Qingsong
(Kunming Shipborne Equipment Research and Test Center,Kunming 650051)
Matrix inversion is a common computationally intensive signal processing algorithm,widely used in sonar detection,radar and other high real-time requirements of digital signal processing.With the maturity of multi-core chip technology,its powerful computing power provides a new matrix solution.In this paper,a matrix inversion method combining Gaussian elimination method with upper and lower triangular matrix decomposition(LU decomposition)is mapped on a heterogeneous multicore reconfigurable system based on NoC.The parallel algorithm is decomposed by combining the parallelism of the system,the memory space and the processing speed of the kernel.The parallel algorithm is decomposed by the parallel algorithm,and the complex matrix inverse of any dimension of 64 dimensions is realized.
matrix inversion,LU decomposition,heterogeneous multicore,algorithm mapping
TP301
10.3969∕j.issn.1672-9730.2017.10.009
Class Number TP301
2017年4月10日,
2017年5月28日
錢慶松,男,碩士,助理工程師,研究方向:水下信號處理。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
