基于隱馬爾可夫模型的web異常檢測案例分析
2017-12-07 02:03:27朱驪安
軟件 2017年11期
朱驪安
(北京郵電大學理學院,北京 100876)
基于隱馬爾可夫模型的web異常檢測案例分析
朱驪安
(北京郵電大學理學院,北京 100876)
如何將數據科學在網絡安全領域內應用一直是一個火熱的話題,本文介紹了如何用隱馬爾可夫模型(HMM)建立web參數模型,檢測注入類的web攻擊。以及這種方法在某航空公司的實施情況,準確率最終達到約80%。
隱馬爾可夫模型;異常檢測;隱含序列;概率模型;web威脅
0 引言
隨著互聯網的發展,企業的傳統網絡邊界在逐漸消失。工業界特別是大型互聯網公司,平均每日活躍用戶上千萬,每個應用系統的日志都會高達幾百G甚至上T字節。同時,以灰產,黑產為代表的惡意訪問占比依然居高不下,并且攻擊手段在不斷推陳出新。傳統web入侵檢測技術,無論是Firewall、Web應用防火墻(WAF)、入侵防御系統、入侵防御系統(IPS)還是入侵檢測系統(IDS)本質上都是依據白名單或已發現攻擊總結出的規則,通過維護規則集對入侵訪問進行攔截。一方面,硬規則在靈活的黑客面前,很容易被繞過,且基于以往知識的規則集難以應對攻擊;另一方面,攻防對抗水漲船高,防守方規則的構造和維護門檻高、成本大。
基于機器學習技術的新一代web入侵檢測技術有望彌補傳統規則集方法的不足,為web對抗的防守端帶來新的發展和突破。Web異常檢測歸根結底還是基于日志文本的分析,因而可以借鑒自然語言處理中的一些方法思路,進行文本分析建模。基于隱馬爾科夫模型(HMM)的參數值異常檢測,就是借助自然語言處理的方法,發現web日志中的異常序列,從而在線檢測出未知異常行為。
1 模型原理
1.1 隱馬爾可夫模型
隱馬爾可夫模型(HMM)是馬爾可夫鏈的一種,它的狀態不能直接觀察到,但能通過觀測向量序列觀察到,每一個觀測向量是由一個具有相應概率密度分布的狀態序列產生。
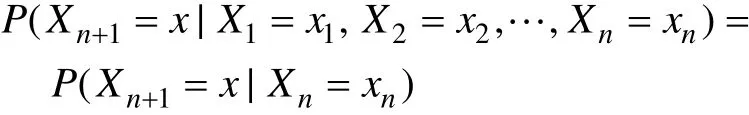
這里x為過程中的某個狀態。上面這個恒等式可以被看作是馬爾可夫性質[1]。
隨機過程是一連串隨機事件動態關系的定量描述。馬爾科夫過程是一種隨機過程,簡單地說,已知現在、將來與過去無關(條件獨立),則稱此過程為馬爾科夫過程[2]。
HMM 主要有以下三類應用:解碼問題,根據模型參數和觀測序列,找出該觀測序列最優的隱含狀態序列;評估問題,根據模型參數和觀測序列,計算該觀測序列是由該模型生成的概率;學習問題,根據一系列觀測序列,建立對應該系列序列最優的HMM 模型。這里我們只用得到后兩個。在訓練階段,對應學習問題,用大量正常的參數值訓練出站點下的參數id的HMM模型;在檢測階段,對應評估問題,待檢測的參數值帶入模型檢測是否是正常。
1.2 參數異常模型
Web威脅中的幾大類攻擊,SQL、XSS、RCE等雖然攻擊方式各不相同,但基本都有一個通用的模式,即通過對參數進行注入payload來進行攻擊,參數可能是出現在GET、POST、COOKIE、PATH等等位置。所以對于異常模型,能覆蓋掉參數中出現的異常,就能覆蓋掉很大一部分的常見的Web攻擊[3]。
假設有這樣一條url:www.xxx.com/index.php?id=123。通過對url的所有訪問記錄分析,不難發現:普通用戶的正常請求雖然不一定完全相同,但總是彼此相似;攻擊者的異常請求總是彼此各有不同,同時又明顯不同于正常請求。如下數據所示:
User: www.xxx.com/index.php?userid=admin123
www.xxx.com/index.php?userid=root
www.xxx.com/index.php?userid=hzq_2017
Attacker: www.xxx.com/index.php?userid= mai06’union select xxx from xxx
www.xxx.com/index.php?userid=%3Cscript%3E alert(‘XSS’)%3C
www.xxx.com/index.php?userid=125$%7B@prin t(md5(123))%7D
如果我們能夠搜集大量參數 id的正常的參數值,建立起一個能表達所有正常值的正常模型。由于,正常總是基本相似,異常卻各有各的異常。基于這樣一條觀測經驗,如果我們能夠搜集大量參數id的正常的參數值,建立起一個能表達所有正常值的正常模型,那么一切不滿足于該正常模型的參數值,即為異常。
2 工程實現
2.1 系統架構--組件選擇與模塊關系
模型訓練過程我們需要大量的正常歷史數據進行訓練、數據量會達千萬級別以上,因此我們需要一個大數據處理引擎;此外,檢測過程中我們希望能夠實時的檢測數據,及時的發現攻擊,這是一個流(streaming)計算過程,需要一個流計算引擎。綜合考慮,我們選擇 spark作為統一的數據處理引擎,即可以實現批處理,也可以使用spark streaming實現近實時的計算。
系統架構如下圖,需要在spark上運行三個任務:

圖1 系統架構圖Fig.1 Sy stem architecture diagram
①sparkstreaming將kafka中的數據實時的存入HDFS;
②訓練算法定期加載批量數據進行模型訓練,并將模型參數保存到HDFS;
③檢測算法加載模型,檢測實時數據,并將告警保存到ElasticSearch。
在我們的系統中,模型訓練算法是在 spark上開發完成的。用HDFS來存儲HTTP請求數據和模型數據。ElasticSearch在我們的系統架構中主要用來存儲、檢索、展示告警數據。
2.2 數據的采集與儲存
獲取http請求數據通常有兩種方式,第一種從web應用中采集日志,使用 logstash從日志文件中提取日志并泛化,寫入 Kafka;第二種可以從網絡流量中抓包提取http信息。我這里使用第二種,用python結合Tcpflow采集http數據,在數據量不大的情況下可穩定運行。
與 Tcpdump以包單位保存數據不同,Tcpflow是以流為單位保存數據內容,分析 http數據使用tcpflow會更便捷。Tcpflow在linux下可以監控網卡流量,將 tcp流保存到文件中,因此可以用 python的pyinotify模塊監控流文件,當流文件寫入結束后提取 http數據,寫入 Kafka。這樣數據的采集就完成了,下面開始數據的儲存。
開啟一個 SparkStreaming任務,從 kafka消費數據寫入Hdfs,Dstream的python API沒有好的入庫接口,需要將Dstream的RDD轉成DataFrame進行保存,保存為json文件。
2.3 數據的清洗與泛化
抽取器實現原始數據的參數提取和數據泛化,傳入一條json格式的http請求數據,可以返回所有參數的 id、參數類型、參數名、參數的觀察狀態序列 p_list。
2.3.1 拆解數據生成參數
將http請求數據用“請求的URL路徑”和“GET、POST的請求參數以及參數名本身”兩種方式進行拆解,提取相應的參數值。例如:提取源IP、目的IP、host[4]。這一步的難點在于如何正確的識別編碼方式并解碼。不同的參數,正常的值不同。同時,有參數傳遞的地方,就有可能發生參數注入型攻擊。所以,需要對站點下所有路徑下,所有GET、POST、PATH中的所有參數都訓練各自的正常模型。另外,對參數名本身,也訓練其正常的模型。
針對這些情況將參數分成三類:第一類,uri,將每條 uri的每一個參數對應的參數值泛化后做為p_state。第二類,uri_pname,將每條數據的所有的參數名拼接起來泛化作為p_state。第三類,uri_path,將每條數據的uri里面的路徑泛化作為p_state。
2.3.2 參數泛化
如果我們把參數 id的每個參數值看作一個序列,那么參數值中的每個字符就是這個序列中的一個狀態。同時,對于一個序列,為 123或者 345,其背后所表達的安全上的解釋都是:數字 數字 數字,我們用N來表示數字,這樣就得到了對應的隱含序列,取字符的unicode數值作為觀察序列[5]。泛化的方法如下:
1. 大小寫英文字母泛化為“A”,對應的unicode數值為65。2. 數字泛化為“N”,對應的unicode數值為78。3. 中文或中文字符泛化為“C”,對應的unicode數值為67。
4. 特殊字符和其他字符集的編碼不作泛化,直接取unicode數值。
5. 參數值為空的取0。
2.4 訓練任務
一個參數對應一條數據,其中包括:一個p_id與一個 p_state。這樣就得到了對應的隱含序列。Spark訓練任務抽取所有 http請求數據的參數,并按照參數ID(p_id)分組,分別進行訓練,將訓練模型保存到Hdfs。
2.4.1 得到模型輸入
我們需要對經過清洗與泛化(Extractor)后的數據進行分組,并存為字典p_dict。key值為參數ID,將 key值相同的數據的 p_state作為其 value值。p_dict的 key值有:p_id,p_name,p_type,p_state。由于模型的輸入規則,我們只需要參數ID(p_id)和隱含序列(p_State)。故將每個 p_dict中的 p_id和p_state抽取出來得到模型的輸入數據。
2.4.2 計算基線并保存--訓練器(Trainer)
傳入參數的所有觀察序列,訓練器完成對參數的訓練,返回訓練好的模型profile[6]。其中,HMM模型使用python下的hmmlearn模塊,profile取觀察序列的最小得分。由于我們假定進入模型的數據是正常數據,建立的是一個能表達所有正常值的正常模型,那么一切不滿足于該正常模型的參數值,即為異常。所以,profile取得是所有score的最小值。再將基線結果profile值保存起來[7-9]。
2.5 檢測任務
Spark Streaming檢測任務實時獲取kafka流數據,抽取出數據的參數,如果參數有訓練模型,就計算參數得分,小于基線輸出告警到Elasticsearch。將得分與基線相比較,低于基線的報警。
3 模型應用案例分析
3.1 背景
某航空公司門戶網站發現有不少攻擊嘗試行為,偶爾會發現有些網頁正常用戶在常規訪問的過程中會發現無法訪問的現象。經初步判定,很可能是攻擊用戶的異常請求造成的。為了進一步分析,航空公司運維人員提供了為期一個月的web訪問日志,需要把訪問日志中的異常行為數據篩選出來。
3.2 研究過程
3.2.1 數據情況
運維人員提供的是 IIS日志,對應的日志關鍵屬性如表1所示。
3.2.2 數據處理與建模
以第一周七天的數據作為訓練數據,一周數據大概1G左右,我們選擇通過spark程序把數據處理成我們建模需要的json格式,存入HDFS中。數據預處理完成后,我們執行訓練任務,建立模型。建模結果部分截圖如表2所示。
3.2.3 檢測與結果分析
由于目前拿到的數據都是歷史數據,所以我們對實時檢測程序HmmDetectionJob作了修改,修改sparkstreaming代碼為spark代碼,把數據源從kafka讀數據修改為從HDFS讀數據。
為了測試模型的準確性及程序的穩定性,我們選取第8天的數據為研究對象,用第8天數據進行檢測。第8天一共13萬條web日志,經過檢測告警的有50天,其中30條為有威脅數據,檢測準確率為60%。

表1 IIS 日志Tab.1 IIS Logs
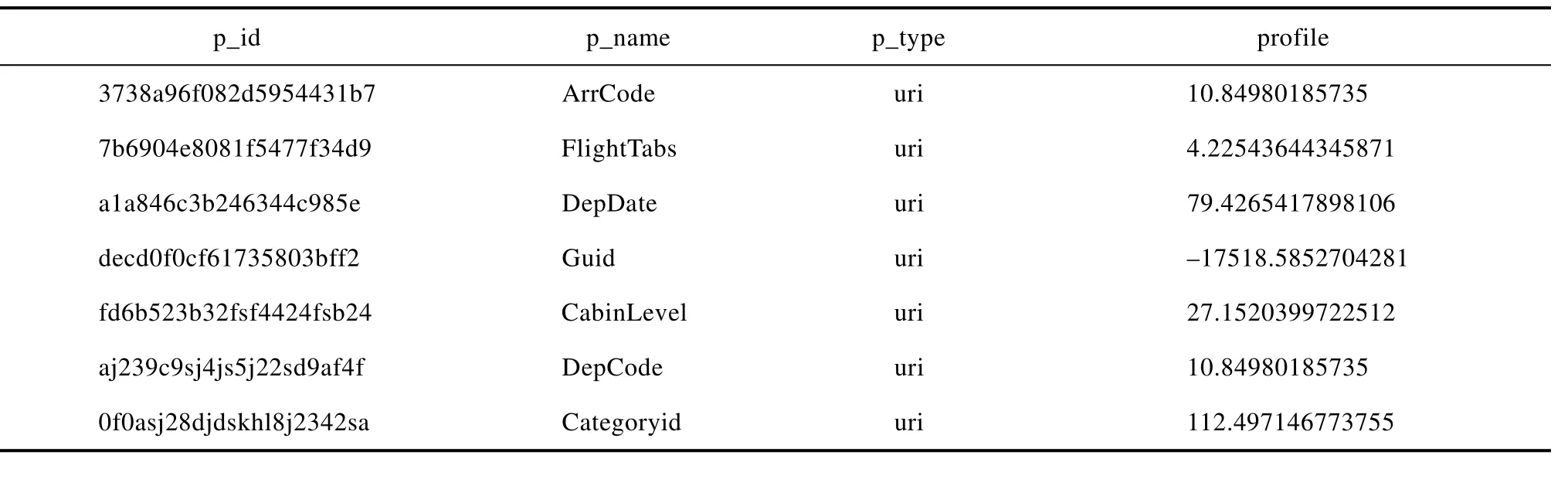
表2 建模結果Tab.2 Modeling results
3.2.4 問題與解決方案
通過對檢測結果與模型的對比分析,我們發現檢出準確率還有進一步提升的空間,主要原因是建模結果的準確率缺失造成的[10-12],原因如下:
1、樣本量偏小
隱馬爾可夫模型是一個概率模型,樣本量越大、涵蓋的url數據類型越多,模型的準確度越高。而我們這里只用了一周的web日志作為訓練數據,樣本量偏小,需要提高訓練模型的數據量。
2、訓練數據中有異常數據
通過對模型中基線分值異常偏低的模型結果所對應的訓練數據進一步分析,發現訓練數據中混入一些異常數據,主要有以下三種情況:少量未被認為篩選出的攻擊行為數據;中文亂碼數據;無法處理的加密數據。建模前我們需要設計一個過濾模塊,對這些異常數據進行過濾。
3、缺少避免模型基線過度偏小的修正模塊
在對模型基線值profile進行訓練的過程中,只是簡單的把正常數據中評分最低的值當做 profile,而在建模中并沒有加入修正過程。
通過對相同p_id所對應score的分析,我們發現score服從正態分布,利用正態分布的特性,我們profile 距離score分布的期望3倍方差以內為判斷條件,當不滿足時,剔除profile 對應的score重新訓練,直到滿足條件。
通過對以上問題的解決,我們最終把檢測準確率提高了85%以上,并準確的篩選出大量攻擊行為數據,部分數據截圖如表3所示。

表3 攻擊數據Table 3 Attact Data
[1] 施仁杰. 馬爾科夫鏈基礎及其應用[J]. 西安電子科技大學出版社, 1992.
[2] 李裕奇, 劉赪編. 隨機過程(第3版)習題解答[M]. 國防工業出版社,2014.09.
[3] 謝逸, 余順. 爭基于Web用戶瀏覽行為的統計異常檢測[J].軟件學報, 2007, 18(4):967-977
[4] DH Schneck, S Cherry,D Goodman.Web interface and method for accessing and displaying directory information[M].US, 2001.
[5] I Corona, D Ariu, G Giacinto. HMM-web: a framework for the detection of attacks against web applications[J]. IEEE International Conference on Communications , 2009 , 15 (1):747-752.
[6] 何強, 毛士藝, 張有為.多觀察序列連續隱含馬爾柯夫模型的無溢出參數重估[J].電子學報, 2000, 28(10): 98-101.[7] 岳峰, 左旺孟. 基于馬爾可夫隨機場的彈性掌紋匹配[J].新型工業化, 2012, 2(2): 52-61.
[8] 朱靖波, 肖桐. 句法統計機器翻譯的一些問題分析[J]. 新型工業化, 2012, 2(1): 1-11.
[9] 張元青, 聶蘭順. 一種BPMN到JPDL的模型轉換方法[J].新型工業化, 2012, 2(1): 23-31.
[10] 張彥. 動態Web 技術在實時監測系統中的實現[J]. 軟件,2013, 34(12): 265.
[11] 劉曉婉, 胡燕祝, 艾新波. 開源中文分詞器在web搜索引擎中的應用[J]. 軟件, 2013, 34(3): 80-83.
[12] 黃炳良, 張忠琳. 預測市場技術在機器學習中的應用[J].軟件, 2014, 35(11): 31-35.
Case Analysis of Web Anomaly Detection Based on Hidden Markov Model
ZHU Li-an
(1. Beijing University of Posts and Telecommunications, Beijing 100876, China;
How to apply data science in the field of network security has been a hot topic, This paper describes how to use the hidden Markov model (HMM) to establish a web parameter model to detect injection attacks. As well as the implementation of this method in an airline, the accuracy rate eventually reached about 80%.
Hidden markov model; Anomaly detection; Implicit sequence; Probability model; Web threat
TP181
A
10.3969/j.issn.1003-6970.2017.11.022
本文著錄格式:朱驪安. 基于隱馬爾可夫模型的web異常檢測案例分析[J]. 軟件,2017,38(11):114-118
朱驪安(1992-),女,研究生,主要研究方向:隨機排隊網絡、物流供應鏈管理。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
