基于編譯置換的指令隨機化系統設計與實現
2018-01-03 01:59:23何紅旗王奕森董衛宇朱懷東
計算機應用與軟件 2017年12期
何紅旗 王奕森 董衛宇 朱懷東
(信息工程大學數學工程與先進計算國家重點實驗室 河南 鄭州 450001)
基于編譯置換的指令隨機化系統設計與實現
何紅旗 王奕森 董衛宇 朱懷東
(信息工程大學數學工程與先進計算國家重點實驗室 河南 鄭州 450001)
指令集隨機化技術是一種通過隨機變換程序指令編碼來抵御代碼注入攻擊的新型防御技術。現有指令集隨機化技術還存在一定缺陷,如性能損耗大、指令數據混雜造成的編碼難等。針對這些問題,提出一種基于編譯置換的指令隨機化技術。該技術在不降低防御效果的同時減少了隨機化指令的數量,并在編譯過程中實現了關鍵指令的隨機置換,提高了指令隨機化的性能和編碼精確度。設計并實現了一套基于編譯置換的指令隨機化原型系統,驗證了該技術的有效性。
指令隨機化 編譯置換 ShellCode DynamoRIO 指令定位
0 引 言
隨著信息技術的快速發展,互聯網在給人們帶來便利的同時也帶來了巨大的威脅。各類硬件和軟件漏洞層出不窮,黑客為了獲得非法利益利用漏洞對目標用戶進行網絡攻擊,獲取網絡用戶隱私信息并出售。因此提升軟件的抗攻擊性能對提升互聯網的安全至關重要。根據OWASP組織在2013年公布的Web十大關鍵風險[1]顯示,注入型攻擊排名第一。代碼注入型攻擊是攻擊者通過改變控制流來執行惡意代碼從而達到攻擊目的,其破壞性很大。目前最常見的代碼注入型攻擊為緩沖區溢出攻擊(如棧溢出攻擊和堆溢出攻擊等)。
目前已經有很多針對緩沖區溢出攻擊行之有效的防御技術。對棧溢出攻擊的防御有在關鍵數據和緩沖區之間加入一個隨機的canary字的Stack Guard防御策略及其衍生出的防御策略;構建與普通棧隔絕的全局返回地址堆棧的Stack Shield防御策略;在棧幀中引入隨機長度的填充區使攻擊者無法準確定位函數返回地址或調用方函數EBP的防御策略。對堆溢出攻擊的防御有增加安全cookie;堆塊元數據加密;動態改變堆分配算法;函數替換與指針編碼等多種方法。
針對當前漏洞攻擊防御技術被動、易被繞過的現狀,安全人員希望研究出一種主動防御技術,能夠對已知和未知漏洞進行全方位防御,隨機化防御技術應運而生。隨機化技術通過對程序進行部分功能等價替換,模糊程序的控制流信息、地址信息和數據信息等,功能的等價替換可以打破漏洞利用所需要的穩態環境。現有的隨機化技術主要有地址空間布局隨機化(ASLR)、指令集隨機化(ISR)、數據隨機化(DR)和操作系統接口隨機化(OSIR),部分隨機化技術已經在漏洞攻擊防御中被廣泛使用,如地址空間隨機化技術已經在大多數現代操作系統中使用。
本文提出的隨機化技術是一種新型指令隨機化技術,與現有指令集隨機化技術不同,該技術在編譯階段實現了指令的隨機改變,可以在低性能損耗下防御代碼注入型攻擊。該技術解決了以下幾個問題:
(1) 對ShellCode執行模式進行分析,選取參與指令隨機化的關鍵指令。
(2) 在指令隨機化規則的指導下,編譯時對程序中的部分指令進行隨機置換。
(3) 實現隨機化程序的動態執行。
1 相關研究
在網絡攻防中攻擊者通常會利用逆向工程對源程序和程序補丁進行比對[2]來發現并利用程序漏洞,進而發動攻擊;也可以通過內存泄露信息學習目標系統的防御機制并繞過[3],對目標系統作進一步攻擊。1996年出現的代碼注入型攻擊很快成為了攻擊者的最愛。為了防御代碼注入型攻擊,現代操作系統采用了DEP防護,通過改變內存頁屬性,使內存頁不可同時具有寫與執行屬性。而隨即出現的代碼重用攻擊[4]即ROP攻擊可以成功繞過DEP防護。2010年出現了一種新型代碼注入型攻擊技術JIT spraying攻擊, 2013年Snow等提出的新型ROP攻擊技術[5],利用內存泄露信息獲得目標程序內的代碼布局,搜集代碼片段組合成攻擊代碼對目標系統進行攻擊,可以繞過系統的ASLR防護。內存信息泄露會對用戶安全造成很大威脅,如2014年爆發的OpenSSL心臟流血漏洞[6],讓整個世界的互聯網陷入不安全,黑客利用內存泄漏的漏洞從服務器中獲取64 KB的數據,里面可能包含用戶賬號、密碼等敏感資源。
面對不斷出現的攻擊技術,防御技術也在快速發展。1997年Forrest等闡述了多樣化技術的整體框架,首次提出數據隨機化和代碼布局隨機化的思想。2000年Cowan等根據隨機化所依賴的環境對隨機化技術進行了分類:接口隨機化技術和系統功能實現隨機化技術。1996年Cowan等提出數據布局隨機化技術,2002年Chew和Song利用系統調用多樣化技術成功防御了緩沖區溢出漏洞攻擊。2003年初次出現指令集隨機化技術,該技術可以防御大多數代碼注入型攻擊,但會帶來400%的性能損耗,同年,PaX小組提出地址空間布局隨機化(ASLR)技術。2010年Georgios等對ELF文件格式的程序實現了基于動態二進制分析平臺Pin的指令集隨機化。2012年Giuffrida等提出了粒度更細的地址空間隨機化技術[7]。ASLR技術可以防御代碼注入型、代碼重用型攻擊,被廣泛地應用在現代高級操作系統中,但可以通過內存泄露來繞過[8]。
指令集隨機化技術是一種基于加密實現的隨機化技術,經過國內外學者不斷的研究,目前指令集隨機化已經日趨成熟[9]。2003年Kc等提出了一種實現指令集隨機化的思路,與RISE相似,都是對二進制機器碼進行修改。2004年Boyd和Keromytis實現了SQL語言的隨機化,通過利用服務器上的代理應用實現。2012年Hiser等[10]設計了基于加密的代碼布局隨機化技術,同一年Shioji等[11]設計了基于加密的代碼地址隨機化技術,可以防御代碼注入型攻擊和細粒度的代碼重用攻擊。
數據結構隨機化技術也是當前研究的熱點,2009年Lin等開始使用編譯器對數據結構體變量進行更加細致的隨機化處理;2014年南京大學的辛知等[12]展開了自動的結構體隨機化工作的研究,將基于編譯器的結構體以及數據分布隨機化向前推進了一步;2012年Giuffrida等[7]的工作是將數據結構隨機化從應用程序擴展到了內核,實現了全空間的數據結構隨機化。
隨機化防御技術已經得到了很大的發展,在網絡安全領域發揮了巨大的作用,但仍然面臨防御攻擊單一、推廣代價大的問題,表1為主流的幾種隨機化技術性能統計表。現有的指令集隨機化技術可以防御大多數代碼注入型攻擊,但由于缺乏硬件支持,軟件實現還不成熟,因此沒有得到廣泛的推廣,但該技術的應用前景很好,具有很大的研究意義。
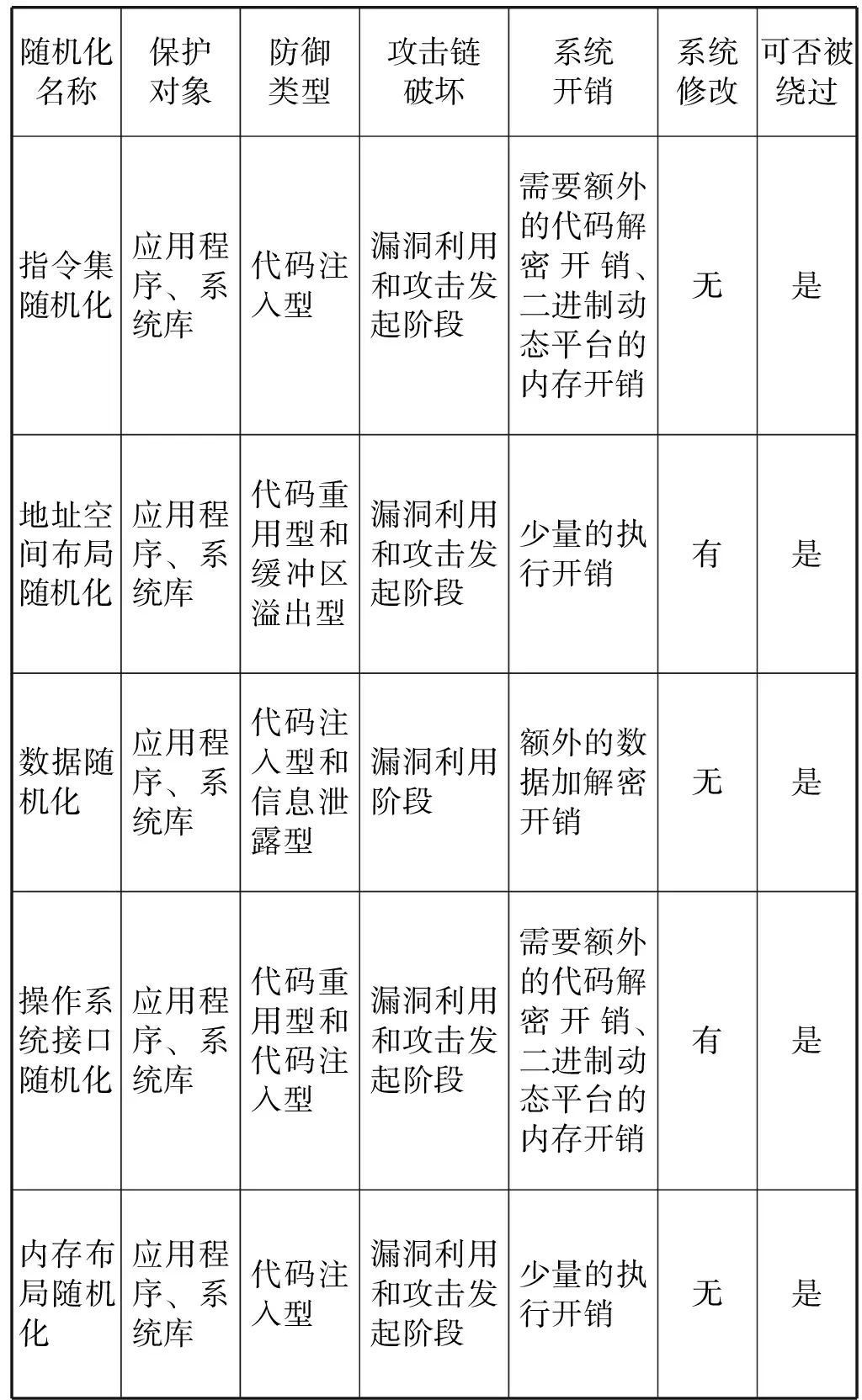
表1 隨機化技術性能統計表
2 基于編譯的指令置換技術
針對當前指令隨機化技術存在的不足,本文提出一種基于編譯置換的指令隨機化技術。該技術的實現思路為在程序編譯階段根據隨機化規則的指導對部分指令隨機置換,從而達到指令隨機化的目的。
2.1 Phoenix編譯器框架
Phoenix是由Microsoft公司提供的一套接口開放、擴展性強的編譯器框架,該框架支持多種計算機語言,可以幫助用戶開發新的編譯器或其他程序分析工具。Phoenix編譯器通過對程序源碼進行處理,將源碼表示成中間表示的形式,即IR (IntermediateRepresentation)的形式,Phoenix編譯器和各種基于Phoenix的工具對程序后期的處理工作都是在IR層次上進行的。Phoenix可以幫助用戶完成基本塊分析、內存跟蹤、代碼覆蓋、實時編譯和全系統優化等工作。圖1為Phoenix編譯器框架圖。
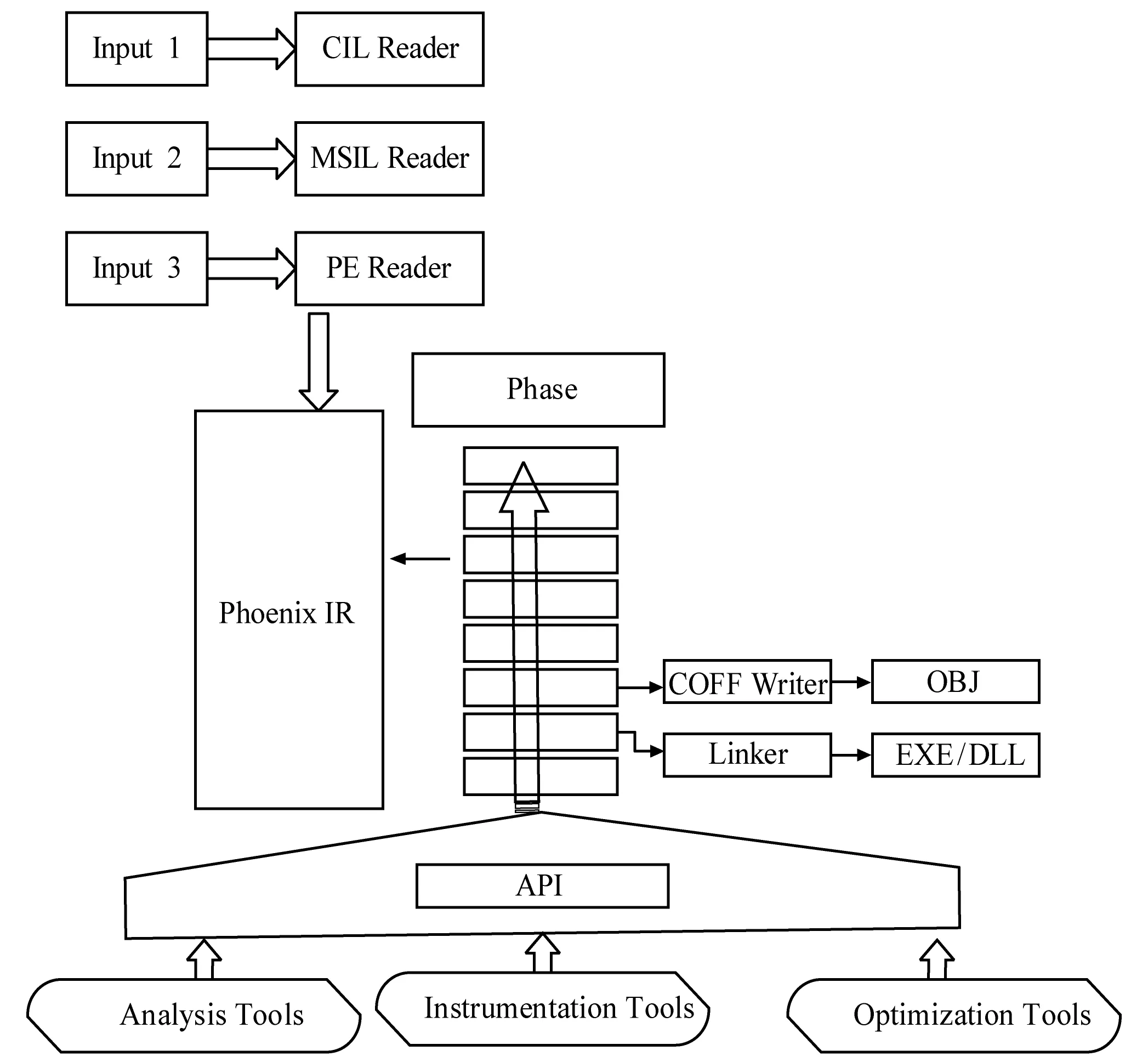
圖1 Phoenix編譯器框架圖
從框架圖可以看出Phoenix有三種輸入方式:CIL(Compiler Intermediate Language)、MSIL(Microsoft Intermediate Language)、PE(Portable Executable),Phoenix將這三種輸入文件轉換為中間表示(IR,Intermediate Representation)形式。Phoenix對外提供了一些API函數,用戶可以利用這些API函數來開發分析工具(Analysis Tools)、插樁工具(Instrumentation Tools)和優化工具(Optimization Tools)。Phoenix編譯器的編譯階段對外,開發人員可以在編譯的不同階段(Phases)裝入自己的分析工具或編寫插入自己的Phase對程序進行分析優化。最后可以根據不同的需要使用COFF Writer模塊生成目標對象文件Obj文件,或用連接器Linker生成EXE文件或者DLL文件。
2.2 隨機化指令篩選
指令隨機化技術是通過在動態執行過程中改變惡意代碼內指令的語義,使其無法正常執行,從而達到防御效果。因此,不需要對目標程序全部指令進行隨機化處理,只要使惡意代碼內關鍵指令語義發生改變即可阻止其正常執行。本文根據這一思路通過對惡意代碼構成規則進行分析,選擇出參加隨機化的關鍵指令。隨機化指令選擇的原則是使惡意代碼中指令的隨機化率盡可能高,同時用戶程序內指令的隨機化率盡可能低,使由指令隨機化帶來的性能損耗保持在一個可控范圍內。
通過對ShellCode執行模式進行分析,本文選取了參加指令隨機化的指令186條,除了ShellCode中出現的高頻關鍵指令,還摻加了部分程序中低頻出現的混淆指令,混淆指令的添加用很低的性能損耗提升了ShellCode的隨機化率。在編譯階段對指令隨即改變需遵守等長置換的原則,即在指令變換過程中不能改變指令的長度。如果不等長指令置換則會造成指令不完整或覆蓋相鄰指令,如將 inc eax (0x40) 置換為 call eax (oxFFD0) ,導致部分指令在動態執行時無法被識別而執行失敗。即使是操作碼等長指令,由于指令類型不同,有些指令有操作數,有些指令無操作數,如果相互置換也會在指令執行過程中出錯,如將指令 push eax (0x50)置換為jnc addr (0x73 + addr),雖然操作碼指令長度相同,但這兩條指令置換后動態執行時會出錯。因此本文對篩選出來的關鍵指令按照操作碼長度、是否有操作數進行了分類。表2列出了部分隨機化指令信息。
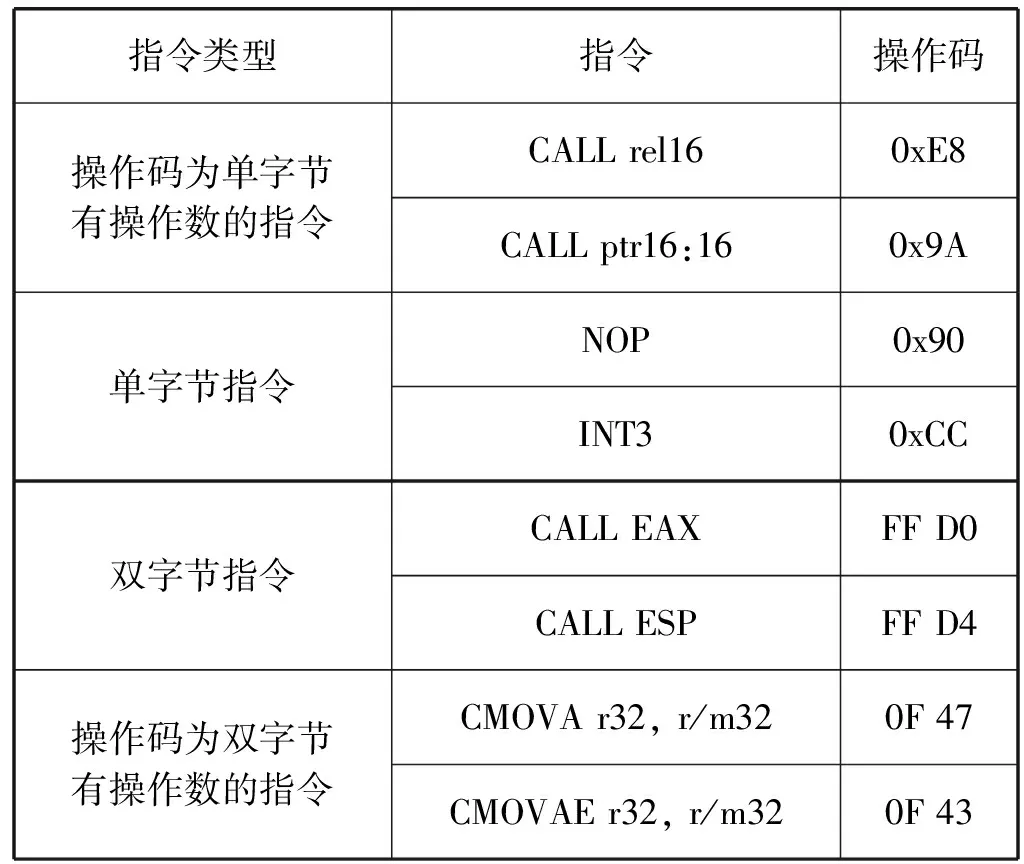
表2 部分隨機化指令信息
指令隨機化規則在程序編譯時指導指令的隨機置換,并在隨機化程序動態執行時指導隨機化指令的還原。規則制定需要滿足兩方面要求:指令變換后可以在動態執行時還原;指令變換隨機。因此制定的指令隨機化規則需要在等長置換的原則下對指令在不同集合下進行隨機配對,變換時根據配對相互置換。
2.3 前端編譯信息獲取
編譯器對程序編譯過程中會分為不同的編譯階段(Phases),每個Phase會執行特定的功能。Phoenix將編譯、優化等處理過程分成若干個Phases。Phoenix允許用戶制定Phase-List并開發特定功能的Phase,在編譯器下次編譯程序過程中,Phoenix編譯器框架會解析Phase-List并執行其中的Phase。圖2為Phoenix中Phase原理圖。
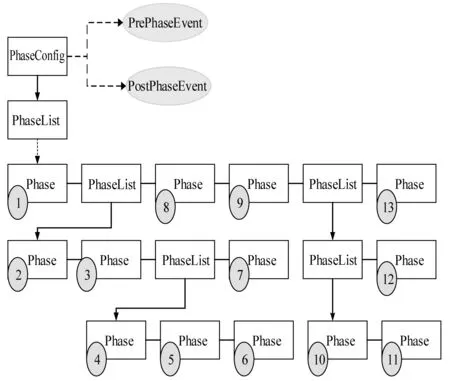
圖2 Phoenix中Phase原理圖
指令隨機化規則在程序編譯時指導指令的隨機置換,并在隨機化程序動態執行時指導隨機化指令的不同編譯階段完成不同的功能。為了實現隨機化分析框架的特定功能,需要在程序編譯過程中加入指令分析和處理的相關工作。因此設計編譯隨機化PhaseList,抽取Phoenix的 C2編譯器的前期處理階段,C2編譯器的前期處理階段主要完成各種檢查和編譯優化工作。圖3為本文構造的指令隨機化PhaseList。完成編譯前期階段工作后,按照PhaseList的順序,開始進入隨機化分析階段。可以通過phase.next與phase.previous查看當前phase的前一個與后一個phase。
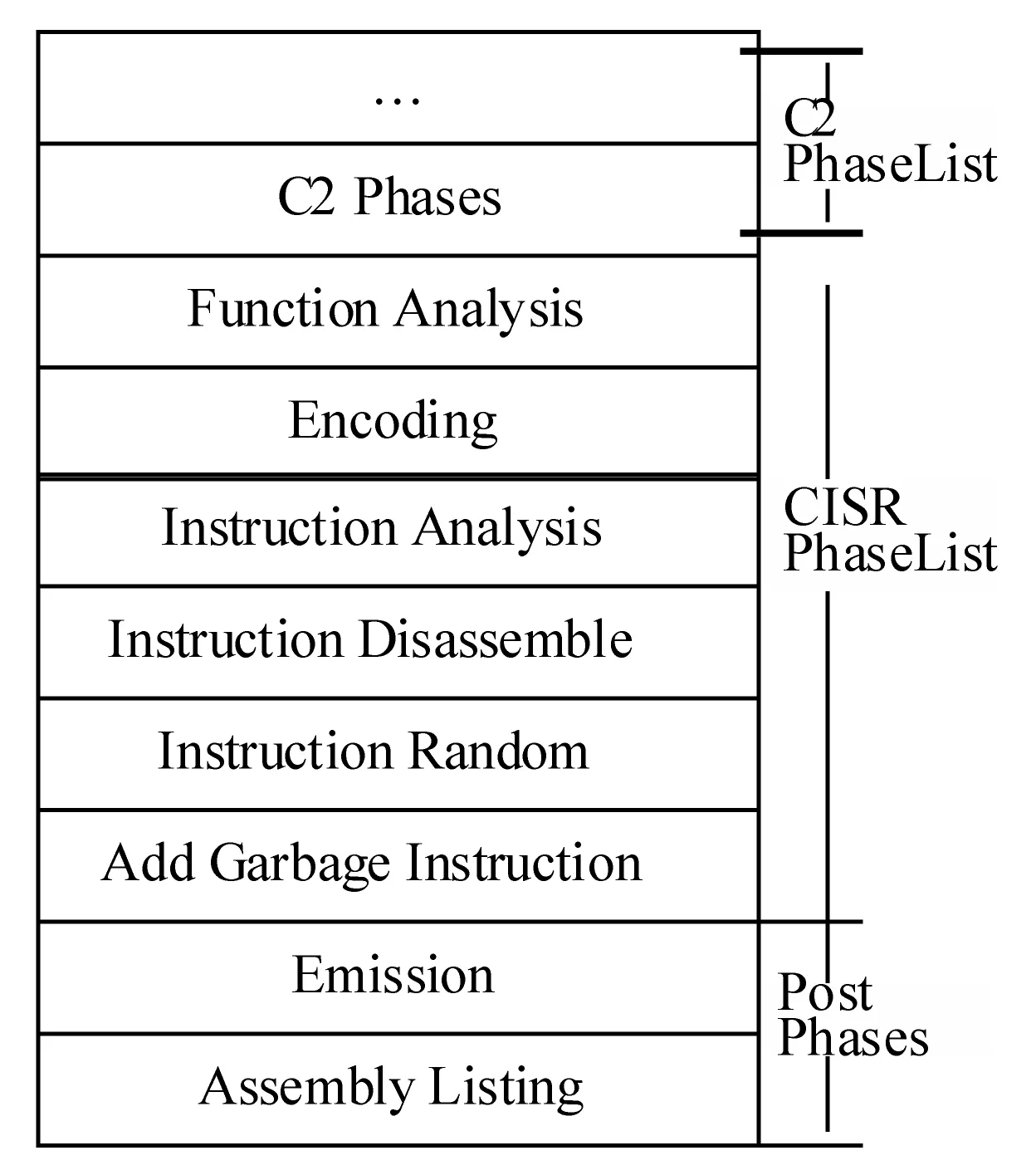
圖3 指令隨機化PhaseList
在指令隨機化PhaseList中包含了函數單元分析、指令流分析、編碼、反匯編、指令隨機化和垃圾指令注入等階段。其中函數單元分析和指令流分析是為了從編譯的中間表示信息中得到指令隨機化所需要的有用信息,編碼、反匯編和指令隨機化是指令隨機化技術需要完成的工作。
2.4 指令隨機置換技術
指令置換需要換的主體是指令的操作碼,對操作數暫時不作處理。
定位了指令在函數單元內的偏移并得到指令操作碼長度后,可以開始對指令進行隨機置換。指令隨機置換實現的思想是:在編譯的優化階段后,寫入目標文件前根據指令在函數單元內的偏移以及指令操作碼的長度提取指令的操作碼,將操作碼與相應的指令隨機化規則遍歷匹配,如果操作碼在規則內則按照規則進行置換,否則讀取下一條指令。指令隨機化依賴的條件有:
(1) Phase在編譯優化階段后,寫入目標文件前。指令的隨機化工作會對指令進行改變,如果在優化階段前進行,則改變的指令很可能被優化掉。如果編譯階段已經將機器碼寫入目標文件,則無法再進行指令置換。選取在Encoding階段之后即Post-compilation phases進行,這時IR為EIR形式,即最終寫入obj文件中的形式,而且在這個階段置換指令不會被優化掉。
(2) 規則指導。指令的隨機置換需要在一定的規則指導下進行,不能盲目置換,在動態執行階段需要再次根據規則將指令還原。
(3) 指令數據分開。指令數據混合會導致數據被當做指令,使隨機置換錯誤,只有在編譯階段才能做到指令與數據的嚴格分離。
(4) 指令在函數單元偏移。指令隨機化需要根據指令的偏移來確定指令位置,進而進行指令的隨機置換。
滿足以上四點要求后,可以開始指令的隨機置換。圖4為指令置換階段流程圖。指令置換的流程為:首先對EncodedIR內的機器碼進行反匯編,得到指令在函數單元內的偏移。根據偏移取出每條指令的操作碼并與相應的規則進行匹配,即遍歷規則判定操作碼是否在其中,若在則進行指令置換,并將置換結果回寫入EncodedIR;若不在則該指令不需進行隨機化處理,讀取下一條指令進行匹配,直到將函數單元內所有指令處理完,繼續處理下一個函數單元的指令。
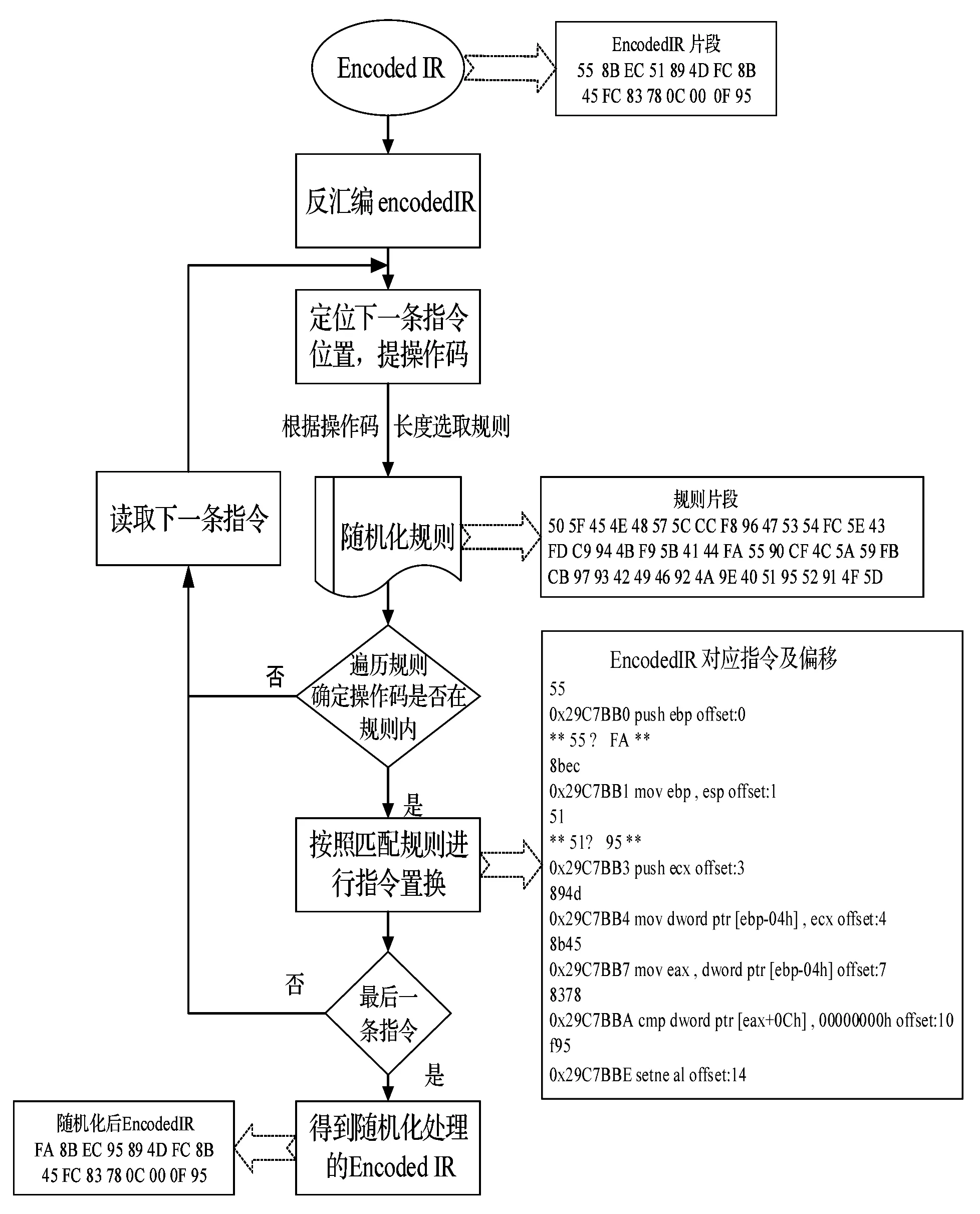
圖4 指令置換流程圖
2.5 隨機化程序執行
經過指令隨機化處理的程序在運行時需要進行指令回譯,通過指令回譯可以達到兩方面的目的:一方面使得用戶程序內被隨機化的指令還原為正常指令;另一方面防止惡意代碼的執行,如果攻擊者向用戶進程內注入惡意代碼,由于該惡意代碼沒有經過編譯期間的指令置換,則即使控制流轉移到惡意代碼,它也不能正常執行。
隨機化指令回譯需要在動態二進制分析平臺上利用指令級插樁來實現,選DynamoRIO作為隨機化指令回譯的動態二進制平臺。因為在編譯階段部分指令的語義發生了改變,只有在指令執行前將其語義還原才可正常執行,通過在指令執行前插入分析代碼來判斷指令是否被隨機化。基于以上思想,隨機化指令回譯的流程為從基本塊內讀取一條指令,判斷指令的操作碼長度,并與隨機化指令規則進行匹配,匹配規則分為操作碼長度決定,如果遍歷規則可以找到該操作碼,則根據規則構造指令并置換,如果不匹配則讀取下一條指令。如此循環直至基本塊內所有指令處理結束讀取下一基本塊。圖5為隨機化指令回譯流程圖。
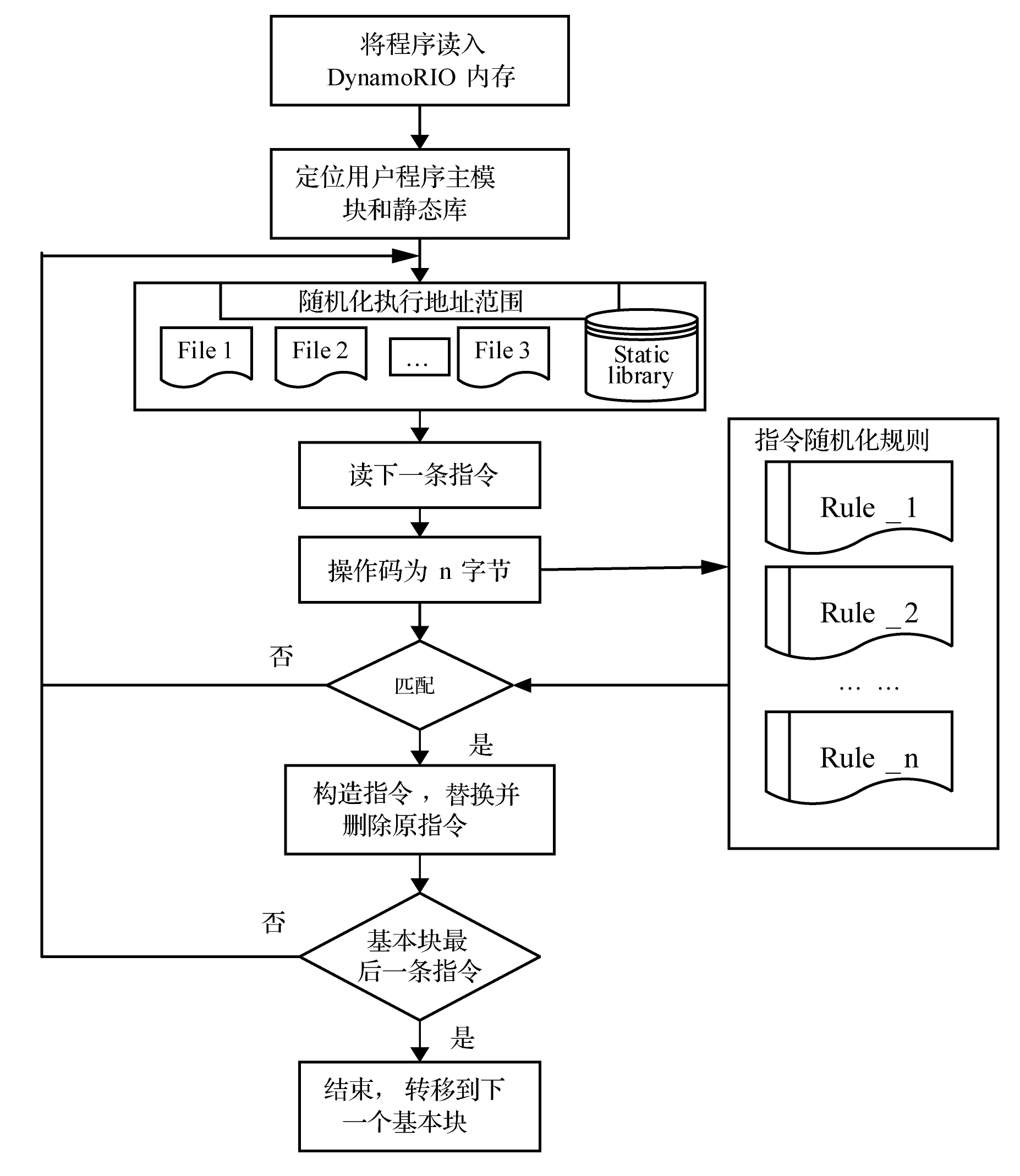
圖5 隨機化指令回譯流程圖
攻擊者如果在程序執行期間發起攻擊,注入惡意代碼并劫持控制流去執行惡意代碼,即使如此,攻擊者也會攻擊失敗。因為外部注入的惡意代碼沒有經過前期的隨機化處理,在執行時惡意代碼的關鍵指令會被變換為一個不可預知的指令,導致惡意代碼對系統攻擊成功的概率降低到一個極小的值。通過對單次隨機化程序執行來模擬被破壞的惡意代碼的執行環境,并對執行結果做了大量統計,被隨機化的指令執行結果可以分為三類:被隨機化為非法指令,執行時錯誤;被隨機化為合法指令,向下執行會進入一個死循環,或跳入一段合法代碼段;其他類型的錯誤。圖6為單個隨機化指令執行時的流向圖。
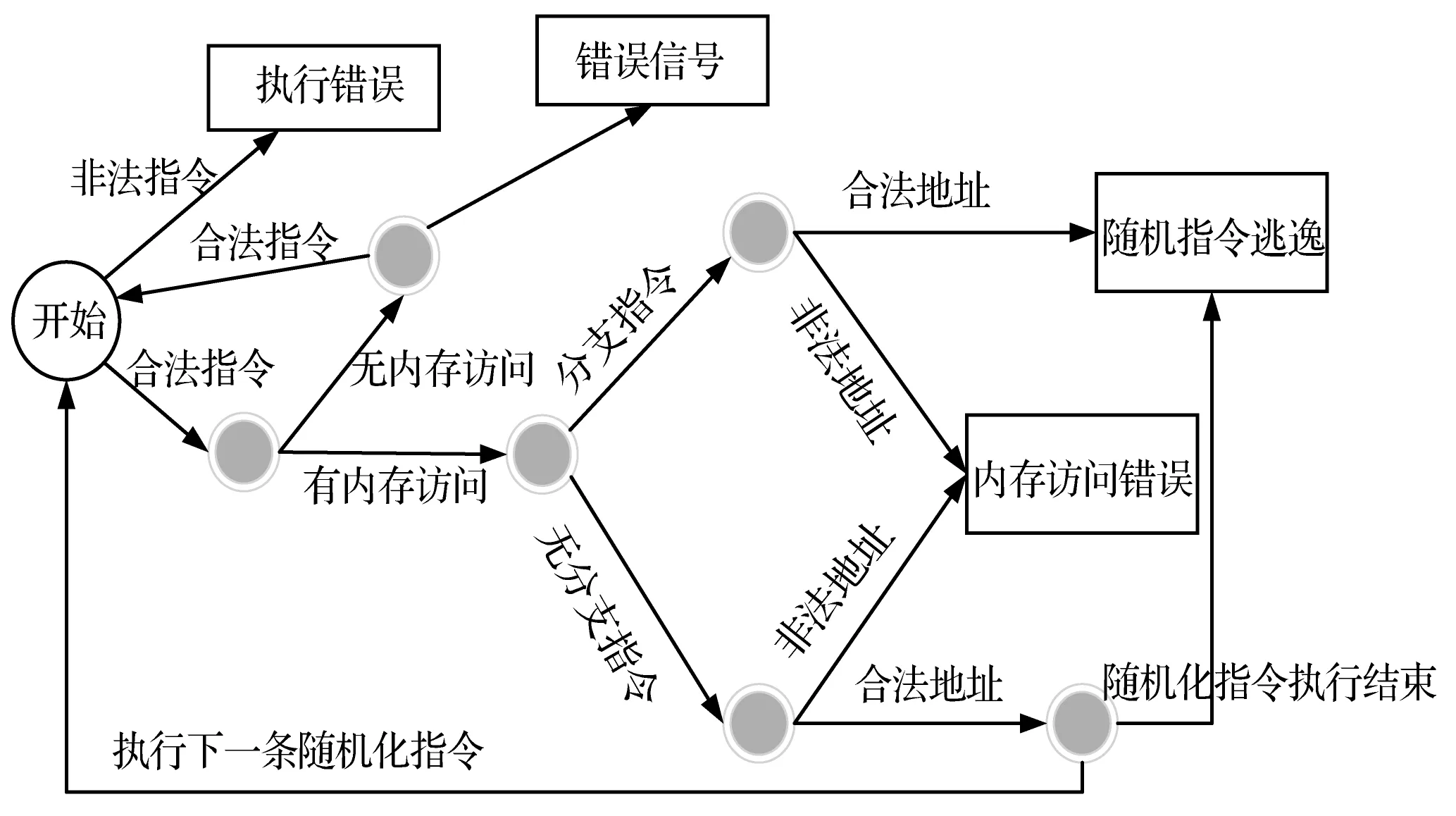
圖6 隨機化指令執行流向圖
如圖6所示,其中“隨機指令逃逸”狀態為分支指令跳轉到進程內的可執行內存中。單個隨機化指令執行時有三種流向:
1) 經過隨機化處理后指令發生改變,執行時產生錯誤信號。定義系統對這種類型的錯誤信號處理為直接終止執行。
2) 經過隨機化處理后的指令分支跳轉,控制流轉移到進程的可執行內存中,不產生錯誤信號。
3) 經過隨機化處理后的指令依然是可執行指令,正常執行。
3 實驗與分析
為了驗證所提技術的有效性,設計并實現了指令隨機化原型系統CIRE(Compiled Instruction Randomization Emulation)。該系統在編譯階段實現了指令的隨機變換,并在DynamoRIO上執行對隨機化程序,該系統可以防御絕大多數的已知和未知代碼注入型攻擊。為了驗證CIRE系統的有效性,從ShellCode指令隨機化率和防御攻擊效果兩個方面測試該系統的實用效果。實驗環境及配置如下:
硬件環境:
? 三臺PC機:攻擊機、防御機和ISR實驗用機
? AMD Athlon(tm) 3800+ 2.00 GHz,4.00 GB內存
軟件環境:
? 操作系統:WindowsXP 32位、Ubuntu12.04 32位
? 動態二進制分析平臺:DynamoRIO,Pin
? 漏洞檢測工具:Metasploit 4.13
? 靜態二進制分析工具:IDA 6.2
? 編譯器:Phoenix、Microsoft Visual Studio 2008
3.1 ShellCode隨機化率
為了增大CIRE的防御效果,同時控制由于指令隨機化帶來的效能損耗,根據ShellCode構造原理篩選出ShellCode常用的關鍵指令進行隨機化,CIRE盡量使ShellCode中指令隨機化比率盡量高而用戶程序內指令隨機化比率盡量低。為了驗證該思想的可行性,抽取Metasploit 4.13下470個ShellCode進行測試。分別將470個ShellCode機器碼與本文篩選出的隨機化指令進行比對,統計出ShellCode內指令的隨機化率,并對ShellCode進行調試,跟蹤變換后ShellCode的執行,分析隨機化后ShellCode的執行流向。表3為部分ShellCode隨機化率測試。
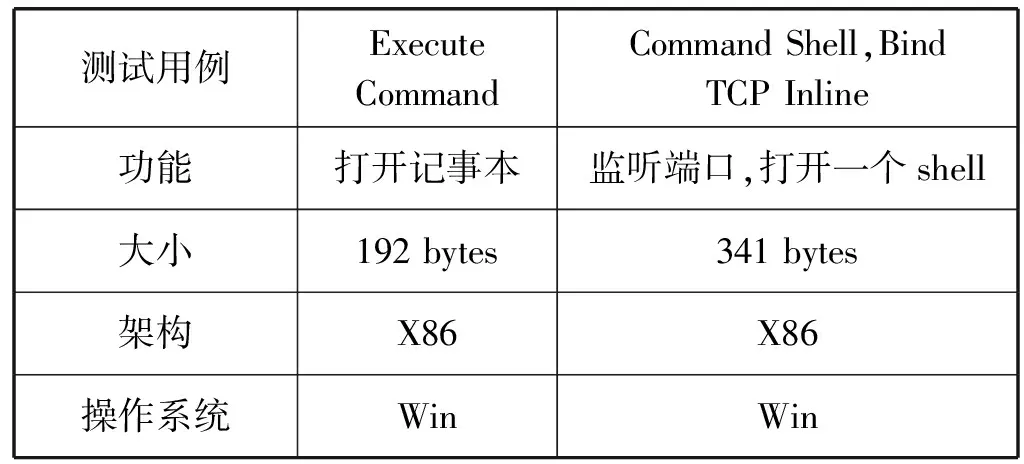
表3 部分ShellCode隨機化率測試
續表3
通過對470個目標ShellCode做統計,篩選出來的隨機化指令使得470個ShellCode的指令平均隨機化率為39%。
3.2 CIRE防御效果測試
為了驗證CIRE系統防御代碼注入型攻擊的防御效果,選取了100個開源樣本軟件,并在樣本程序中構造了緩沖區溢出漏洞。利用Metasploit對樣本程序分別在無CIRE保護和有CIRE保護下進行攻擊,每個樣本攻擊100次,并對結果進行統計,如表4所示。
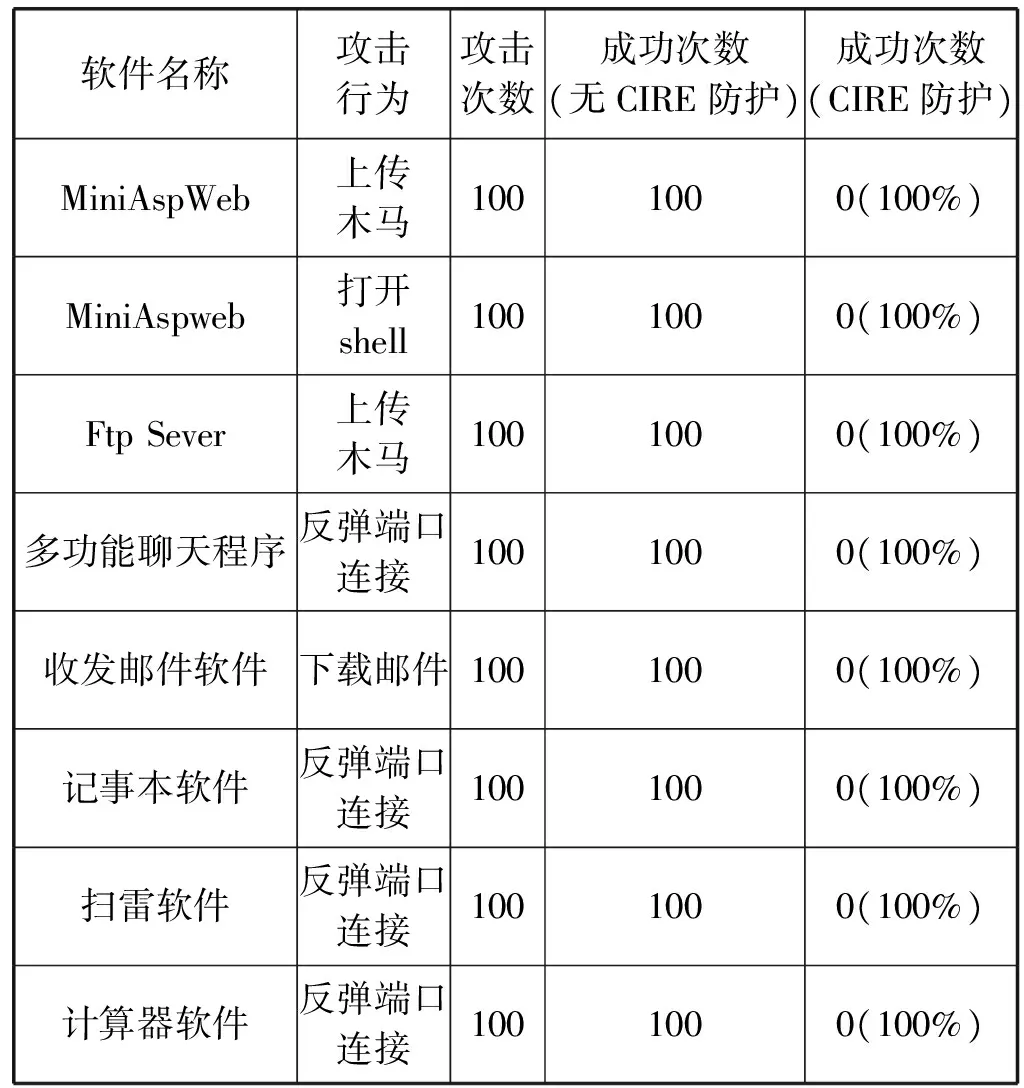
表4 CIRE防御效果部分統計表
理論上,在沒有其他安全加固的前提下,對含有緩沖區溢出漏洞的程序進行攻擊會100%成功,而通過指令隨機化處理后,由于關鍵指令發生了變化,攻擊會100%失敗。編寫自動化測試腳本,對網上搜集的100個開源Windows軟件和1 000個Microsoft Visual Studio編寫的程序進行測試。測試結果顯示,在沒有CIRE保護下,對樣本的攻擊成功率達到100%,而在CIRE保護下,對樣本的攻擊成功率為0,證明CIRE可以成功防御代碼注入型攻擊。
4 結 語
本文通過對傳統指令集隨機化技術的研究,針對其性能損耗大、安全性低及可擴展性差的缺點,提出一種基于編譯置換的新型指令隨機化技術。該技術在編譯階段對目標程序的部分指令在指令隨機化規則的指導下進行隨機置換,攻擊者不了解這套指令規則,無法構造與當前指令兼容的攻擊代碼,該技術可以防御絕大多數的外部代碼注入型攻擊。并在此基礎上,設計并實現了基于編譯置換的指令隨機化原型系統CIRE,經過大量測試,該系統可以在低開銷的情況下防御所有的測試攻擊,具有較高的實用性和有效性。
[1] OWASP T. Top 10-2013[EB]. The Ten Most Critical Web Application Security Risks, 2013.
[2] Coppens B, De Sutter B, De Bosschere K. Protecting your software updates[J]. IEEE Security & Privacy, 2013, 11(2): 47-54.
[3] Tang F Y, Feng C, Tang C J. Memory Vulnerability Diagnosis for Binary Program[C]//ITM Web of Conferences. EDP Sciences, 2016, 7: 03004.
[4] Davi L, Sadeghi A R. Background and Evolution of Code-Reuse Attacks[M]//Building Secure Defenses Against Code-Reuse Attacks. Springer International Publishing, 2015: 7-25.
[5] Snow K Z, Monrose F, Davi L, et al. Just-in-time code reuse: On the effectiveness of fine-grained address space layout randomization[C]//Security and Privacy (SP), 2013 IEEE Symposium on. IEEE, 2013: 574-588.
[6] Durumeric Z, Kasten J, Adrian D, et al. The matter of heartbleed[C]//Proceedings of the 2014 Conference on Internet Measurement Conference. ACM, 2014: 475-488.
[7] Giuffrida C, Kuijsten A, Tanenbaum A S. Enhanced Operating System Security Through Efficient and Fine-grained Address Space Randomization[C]// Security’12 Proceedings of the 21st USENIX conference on Security symposium. 2012: 475-490.
[8] Bittau A, Belay A, Mashtizadeh A, et al. Hacking blind[C]//Security and Privacy (SP), 2014 IEEE Symposium on. IEEE, 2014: 227-242.
[9] Sinha K, Kemerlis V, Pappas V, et al. Enhancing Security by Diversifying Instruction Sets[R]. Columbia University Computer Science Technical Reports,2014.
[10] Hiser J, Nguyen-Tuong A, Co M, et al. ILR: Where’d my gadgets go?[C]//Security and Privacy (SP), 2012 IEEE Symposium on. IEEE, 2012: 571-585.
[11] Shioji E, Kawakoya Y, Iwamura M, et al. Code shredding: byte-granular randomization of program layout for detecting code-reuse attacks[C]//Proceedings of the 28th Annual Computer Security Applications Conference. ACM, 2012: 309-318.
[12] 辛知, 陳惠宇, 韓浩, 等. 基于結構體隨機化的內核 Rootkit 防御技術[J]. 計算機學報, 2014, 37(5): 1100-1110.
DESIGNANDIMPLEMENTATIONOFINSTRUCTIONRANDOMIZATIONBASEDONCOMPILINGSUBSTITUTION
He Hongqi Wang Yisen Dong Weiyu Zhu Huaidong
(StateKeyLaboratoryofMathematicalEngineeringandAdvancedComputing,PLAInformationEngineeringUniversity,Zhengzhou450001,Henan,China)
Instruction set randomization technology is a new type of defense technology that protects against code injection attacks by random transformation program instruction coding. The existing instruction set randomization technology also has some defects, such as large performance loss, mixed instruction and data can enhance the difficult of encoding. In order to solve these problems, a randomization technique based on compiler permutation was proposed. This technique reduces the number of randomization instructions without reducing the defense effect, and achieves the random replacement of the critical instruction in the compiling process, which improves the performance and coding accuracy of the instruction randomization. This paper designed and implemented compiled instruction randomization emulation based on compiling substitution and verified the effectiveness of the technique.
Instruction randomization Compiling substitution Shellcode DynamoRIO Instruction addressing
2017-02-22。何紅旗,副教授,主研領域:信息安全。王奕森,博士生。董衛宇,副教授。朱懷東,碩士生。
TP309.1
A
10.3969/j.issn.1000-386x.2017.12.059
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
人大建設(2019年12期)2019-05-21 02:55:44
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
Coco薇(2017年11期)2018-01-03 20:59:57
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
