基于LOD的海量地形數據并行渲染技術①
2018-01-08 03:12:56王青云
計算機系統應用 2017年12期
王青云,羅 澤
1(中國科學院大學,北京 100049)
2(中國科學院 計算機網絡信息中心,北京 100190)
基于LOD的海量地形數據并行渲染技術①
王青云1,2,羅 澤2
1(中國科學院大學,北京 100049)
2(中國科學院 計算機網絡信息中心,北京 100190)
隨著地球空間信息技術的發展,建立具有海量空間數據的大規模虛擬地形場景越來越重要. 然而,面對海量的地形數據,如何簡化地形,提升繪制與渲染效率,是地形渲染的關鍵. 本文對LOD地形渲染技術、大規模數據集的分析與處理、并行計算等相關技術進行了研究,提出了基于LOD的海量地形數據并行渲染技術. 該技術首先使用LOD四叉樹簡化地形,其次結合多核CPU并行計算的方法提升效率,最后結合大規模數據調度策略,實現了海量地形數據的并行渲染,并分析對比了非并行和并行情況下的實驗結果. 本文所取得的理論與技術方面的成果可為大規模場景渲染提供新的技術思路.
LOD 技術; 并行計算; 海量數據; 地形渲染
1 引言
1.1 研究背景與意義
隨著地球空間信息技術的發展,建立具有海量空間數據的大規模虛擬地形場景越來越重要. 地形渲染是場景渲染的核心部分,一直是圖形學領域的熱點問題之一. 它是視頻游戲、地理信息系統(GIS)、虛擬現實(VR)系統中重要的組成部分[1]. 隨著遙感技術的發展,大范圍高分辨率的遙感數據已經可以被獲取,包含上千萬多邊形的場景變得越來越常見,遠遠超過圖形硬件的繪制能力. 如此大容量的數據要在應用中發揮實際作用,必須要有高效、快速的大規模地形渲染系統的支持. 因此,如何簡化地形,提升地形繪制與渲染效率,是實現一個大規模的地形渲染系統的關鍵.
提升地形繪制與渲染效率,主要從兩個方面著手:一方面是合理地組織地形數據,采用合理的數據模型和數據調度策略,在不影響視覺效果的前提下,減少需要渲染的三角形的數據量; 另外一方面是采用加速渲染算法,提高單位時間地形數據的處理量[2].
1.2 國內外研究現狀
減少需要渲染的地形數據方面,主要使用LOD(Level of detail) 多層次細節技術實現,LOD 技術是目前大規模的地形場景渲染的研究重點之一. 地形LOD技術是在不影響畫面視覺效果的前提條件下,根據地形的不同復雜程度和人眼觀察地形的特點,對地形的不同區域采取不同細節的描述和繪制. 通過逐次簡化景物的表面細節來減少場景的幾何復雜性,從而提高繪制算法的效率. LOD方法能夠靈活地調度資源,處理數據,既減少了運算量,又不會降低圖像的顯示效果[2-4].
目前LOD算法的主要實現方式有:靜態層次細節LOD技術和動態層次細節LOD技術. 靜態LOD技術是在進行地形渲染前,采用Top-down方式對地形進行化簡,從最高精度開始,從地形數據中逐層地去掉地形的頂點數據,每層數據對應一個分辨率. 動態LOD技術是用連續變化的分辨率根據當前視點位置的實時動態來繪制層次細節模型. 如表1是動態LOD與靜態LOD的區別.

表1 動態 LOD 與靜態 LOD 的區別
動態LOD技術的優點是更符合人眼觀察的特點,保證了地形渲染的連續性和一致性,同時也有效減少了地形數據的冗余. 缺點是在渲染過程中需要實時計算、繪制不同分辨率的地形模型,過程相對復雜,會占用一定的計算資源. 本文將主要研究基于四叉樹的動態LOD地形算法與其并行化實現.
加速渲染算法方面,主要是通過軟硬件加速算法實現的,如: 數據存儲訪問優化技術、GPU加速繪制技術及并行渲染技術等,其中并行渲染技術是軟件加速方法的重要組成部分之一.
隨著并行計算的發展以及多核CPU的出現,并行化成為了提高算法效率的重要手段之一. 在計算機圖形學中,根據不同的分類標準,并行渲染也有不同的分類體系. 根據數據調度和功能實現的方式分類,并行渲染算法可以分為數據并行算法和功能并行算法兩種.根據圖元歸屬判斷發生的方式和時機,Molnar等于1994年將并行圖形渲染系統劃分為Sort-first、Sortmiddle和Sort-last三種體系結構. 根據實現平臺分類,可分為高性能計算機、計算機集群和多核微機三種[3].
微機是個人用戶使用最多的三維瀏覽客戶端,隨著個人用戶對三維圖形逼真度要求的提高和微機硬件的升級,微機平臺上的并行渲染將成為研究的熱點之一. 目前基于多核微機平臺的并行渲染研究還處于起步階段,尚未出現令人滿意的并行渲染系統.
1.3 本文的主要內容
目前,對單機渲染系統采用流水線并行技術的應用較少,少部分實現了部分并行化效果. 三維地形渲染方面對于多核CPU并行計算挖掘不足,尚未能做到真正意義上的并行渲染[4,5]. 因此,基于多核CPU的并行計算對于提高算法效率具有非常重要的意義.
本文針對這一現狀,提出了一套完善的并行化處理算法,較為有效地實現了在個人計算機上的地形渲染并行化. 本文在研究DEM數據組織及數據調度的基礎上,實現基于緩存區間的大規模數據調度算法; 在地形繪制階段,本文提出四叉樹LOD算法,并基于多核CPU產生多線程并行處理地形數據,實現了地形LOD并行繪制算法,并測試性能. 本文所取得的理論與技術方面的成果可為大規模場景渲染提供新的思路.
本文的主要內容如下: 第一節主要是引言部分,介紹了大規模LOD地形渲染技術的研究背景意義與國內外研究現狀; 第二節主要是基于四叉樹LOD技術的并行化算法; 第三節主要是大規模DEM數據調度算法,提出了基于緩存區的數據調度及數據實時更新機制; 第四節主要是本文的實驗設計、性能分析等. 最后一節內容主要是結論與展望.
2 LOD 地形算法的并行化
2.1 四叉樹LOD算法
基于四叉樹的LOD方法是采用四叉樹結構存儲DEM數據,在進行地形渲染時,首先自頂向下遍歷四叉樹,再實時計算節點可見性,即判斷節點是否需要四叉分割.
在四叉樹結構表示地形模型的過程中,每一個地形塊都可以由四叉樹中的節點表示,每個節點都對應一個地形區域. 四叉樹的邏輯結構如圖1所示. 當一個節點被判斷為可見時,會被細分為8個三角形網格,并繼續往下一層判斷其子節點的可見性. 當一個節點不可見時,該節點細分為兩個三角形網格,不再繼續細分[6,7].

圖1 四叉樹的邏輯結構
在生成四叉樹,需要不斷地將節點細分,那么如何決定一個節點是否需要分割就是一個關鍵的問題. 節點評價標準決定了在某一時刻,該節點是否可見,也就是該節點是否需要細分. 這種標準通常有兩個決定性的因素. 其中之一是視點,離視點較近的部分分辨率較高,細節較多,反之,離視點較遠細節較少. 另外一個影響因素是地形本身的特征. 比如起伏不大的地表面分辨率較低,很少的細節就能很好地表現出來,而不平整的地表面則需要更多的細節來表現它的地理特征[8-10].
綜合考慮視距和地形特征,設觀察者所處位置為V(Vx,Vy,Vz),地形頂點坐標P(Px,Py,Pz). 則按照如下公式決定某個節點是否被激活:
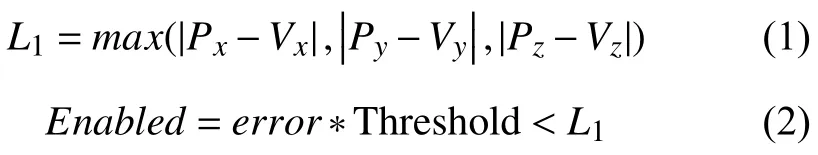
其中L1為視距的近似值,error為節點的頂點誤差,Threshold為細節閾值常量,細節閾值常量是人為設置的一個常量參數,它是LOD模型的分辨率的控制參數.Threshold越大,模型分辨率越高,反之分辨率越低.Enabled為節點激活標識,當 Enabled為 1時,表示該節點需要激活. 當 Enabled 不為 1 時,則屏蔽該點. 對四叉樹的每一個節點進行激活標志計算,得出節點可見性,這個過程稱為頂點測試.
為了減小計算量,在實時計算節點可見性的過程中,一般不會對每個節點進行頂點測試,而是對地形塊先進行盒測試. 類似于頂點測試,以地形塊為單位判斷該塊的可見性,再決定是否需要分割.
2.2 生產者消費者模型
在進行四叉樹裁剪的過程中,系統一方面要根據用戶控制下的視點,不斷的遍歷基于當前視點的四叉樹; 另一方面,要對四叉樹的每一個節點進行節點激活判斷,在本文中,四叉樹的深度最深可達到 19 層,總節點數目多達(219+1)*(219+1),系統需要實時遍歷節點,并計算每個節點的可見性,對系統的計算性能有很高的要求,因此,本文采用多線程并行化方法,以充分利用系統的計算資源.
本系統采用生產者消費者模型,生產者消費者模型是一個并行化處理中常用的模型,如圖2. 它擁有一個隊列容器,并借此來解決生產者和消費者的單線程轉換為多線程的并行化問題. 本文使用一個線程(生產者)用于遍歷四叉樹節點,和多個線程(消費者)用于計算四叉樹中的節點可見性.
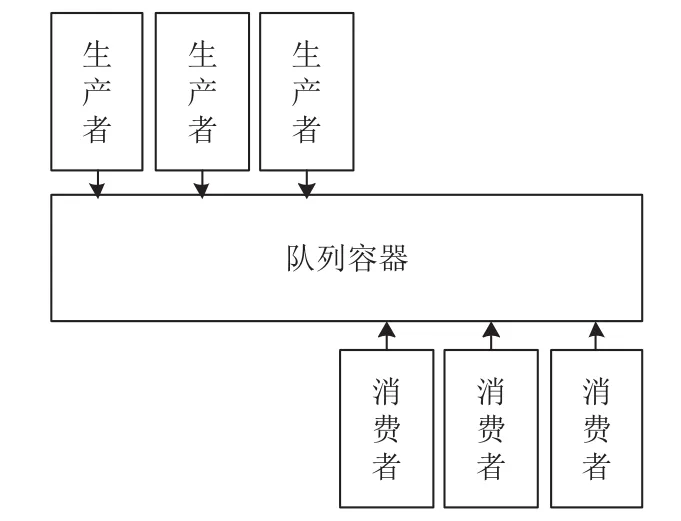
圖2 生產者消費者模型
生產者的具體職責是,將一份大量數據進行拆分,并產生多份待處理的數據. 而消費者的功能是逐份處理產生的多份待處理數據. 二者之間不直接傳遞數據,而是通過一個數據隊列來緩存待處理的數據. 所以,當生產者完成待處理數據的生產之后,不用等待消費者處理,而是直接將待處理數據放入緩存隊列,然后繼續生產下一份待處理數據. 消費者無需直接接觸海量數據,也不需要與生產者交換數據,而是從緩存隊列里直接取出待處理數據進行計算.
2.3 并行化算法
為了實現四叉樹LOD算法的并行化,可以建立一個節點隊列,用于儲存四叉樹節點的指針. 然后使用生產者線程,通過廣度遍歷算法不斷實時生成節點隊列.再使用多個消費者線程,在滿足節點父子順序的條件下,實時處理隊列中的節點(即判斷點的可見性),即可實現四叉樹節點可見性更新的并行化.
生產者線程的主要任務是根據隨著視點變換,從四叉樹根節點開始,通過廣度遍歷算法不斷實時生成節點隊列. 本文中生產者通過一個先進先出隊列存儲四叉樹的節點隊列. 獲取每個節點的激活標志,如果節點被激活,則該節點進行四叉分割,將四個子節點加入節點隊列; 反之,將該節點從節點隊列彈出. 重復以上操作,直到節點隊列為空為止.
消費者線程的主要任務是根據生產者生成的節點隊列,計算隊列中每個節點的可見性. 本文采用多個消費者,通過一個先進先出隊列,存儲節點隊列中每一個點的可見性,更新節點的激活標志. 直到節點隊列為空.
使用生產者-消費者模型進行LOD算法的并行化的關鍵在于如何解決多線程遍歷多叉樹的數據同步問題. 本文采用mutex互斥量來維持生產者與消費者線程之間的同步機制. 互斥量是一種表現互斥現象的數據結構,來保證共享數據操作的完整性. 本算法使用了兩類互斥鎖: 四叉樹節點隊列鎖mutex1和四叉樹中的節點鎖mutex2,分別用于來保證四叉樹節點隊列和四叉樹節點的數據操作完整性.
本系統中,結合生產者消費者模型的多線程四叉樹LOD并行算法流程圖如圖3所示. 其流程如下:
1) 每當視點變換時,緩存數據更新,四叉樹根節點對應的地形數據隨之更新,四叉樹也隨之更新.
2) 并行四叉樹LOD算法,激活多個線程(包含生產者、消費者).
3) 從根節點開始,首先生產者線程將根節點加入節點隊列,消費者從隊列中取出根節點,更新激活標志為可見.
4) 生產者判斷當前節點隊列是否為空,讀取當前節點隊列中最后一個節點的可見性,如果為可見,產生四個子節點,并加入節點隊列. 如果不可見,將該節點彈出隊列.
5) 消費者判斷當前節點隊列是否為空,從節點隊列中取出節點,并計算節點可見性,更新節點激活標志.
重復4)、5)直到節點隊列為空. 更新視圖模型并進行繪制.
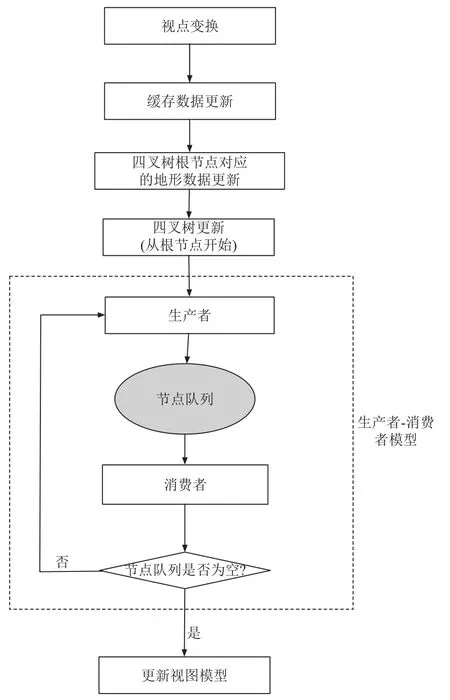
圖3 LOD 并行化算法流程圖
3 大規模 DEM 數據調度
3.1 GLSDEM數據集
全球地形數字高程模型(GLSDEM)是NASA和USGS組織公開的全球地形地貌空間數據,由多個數據集的綜合處理而成,它實現了覆蓋全球大部分地區的地形記錄. GLSDEM數據集的地形分辨率為3弧秒(90 m),地理坐標基于 WGS-84 標準. GLSDEM 數據集以GeoTIFF格式儲存. GLSDEM數據集包含了19234個GeoTIFF文件. 每一個GeoTIFF文件大小為2.75 MB,總數據量為51.8 GB.
文件讀取使用GDAL開源C++代碼庫后,讀取文件后可以得到每個GeoTIFF文件的地形分辨率,1201*1201,其覆蓋范圍為球面上邊長為1弧度的正方形. 根據GLSDEM數據集的數據結構可將三維空間坐標轉換為全球坐標.
3.2 大規模數據集調度算法
本文使用的地形數據集數據量巨大(大小為51.8 G),采用了數據分塊的組織方式,以GeoTIFF文件為單位,采用數組的數據結構存儲地形數據. 由于內存限制,普通電腦無法一次性將所有數據加載至內存供CPU使用. 此外,一次性加載所有地形數據,由于硬盤傳輸速度慢,會導致程序讀取全部地形數據時間過長,啟動速度極慢. 因此,為了實現實時讀取硬盤中大規模地形數據以及大量地形數據向三維空間的映射,本文設計了內存緩沖區和實時數據更新機制.
3.2.1 內存緩沖區
內存緩沖區用于緩存硬盤中的地形數據. 由于視點變換的需要,渲染完一幀以后需要重新加載新的一幀所需要的地形數據,新的地形數據便被讀取并加載至內存. 在渲染過程中,首先將地形數據加載到緩存區,一旦視點發生變化,內存數據需要更新,都是將緩存區作為數據源,而不是直接從外存讀取數據.
本文設置了300個文件單位的緩存區,約825 mb的緩存容量. 當視野發生變化時,載入視野范圍內的數據,刪除兩倍視野范圍以外的數據. 即保留了一倍視野范圍的緩沖. 本文的實現方式是首先在內存中分配一塊固定大小區域作為緩存區,然后通過GDAL庫的讀取波段數據接口函數RasterIO()從外存中讀取數據并存入緩存.
3.2.2 數據更新機制
在數據更新方面,本文采用的是根據視點變換,實時動態渲染地形數據塊. 視點的變換會導致視景體和緩存區的變化,使得內存數據和緩存數據發生變化.
本文將視點的變換歸納為旋轉、平移、縮放這三類. 本文通過調用OpenGL的視圖矩陣類ViewMatrix類,它會根據視點的位置、朝向等變化,實時更新視圖模型. 當鼠標或者鍵盤移動,視點發生變化,首先調用Glut庫的消息處理函數,監聽窗口大小改變、鍵盤和鼠標事件. 將這些用戶事件對應到不同類型的視點變換操作,接著根據視點變化類型,調用前面提到的的三種不同視點變換函數. 最后,根據視點位置的移動距離,方向,視角大小等計算出需要更新的視野范圍,實時更新模型視圖矩陣,然后調用glutSwapBuffers()方法將緩存數據加載到內存并進行渲染輸出.
3.2.3 數據調度算法
本文采用數組的數據結構存儲地形數據,并通過固定長度為300的一個先進先出隊列history,控制緩存區的大小. data 是所有的緩存文件數據,data[*]是一個文件數據,data[*][*]是一個DEM文件中的一個點.
視點的運動會導致緩存數據更新、視圖模型的更新. 需要采用一定的調度算法來保證內存數據和緩存數據的穩定. 本文釆用如圖4所述調度算法.
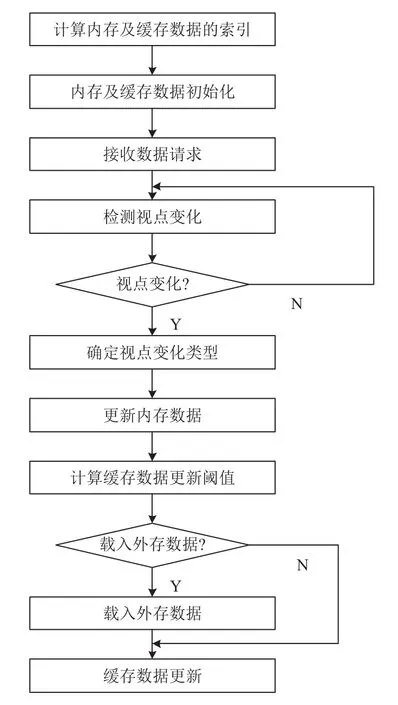
圖4 數據調度算法流程圖
1) 獲取當前視點位置,得出內存和緩存區需要加載的數據索引(地址).
2) 采用數組 data[*]存儲緩存區地形數據,并通過固定長度的先進先出隊列history,記錄被加載到緩存區的數據文件以控制緩存區的大小.
3) 當視點發生變化時,判斷是否需要更新內存數據.
4) 如果需要更新的內存數據在緩存區內,直接從緩存區讀取數據即可; 如果需要更新的內存數據不在緩存區內,需要先計算緩存數據更新范圍,清除緩存區中無用數據并載入外存數據至緩存區; 當視點發生變化時,載入視點可視范圍內的數據,刪除兩倍視野范圍以外的數據. 即保留了一倍視野范圍的緩存區. 重復3)和4).
4 試驗與總結
4.1 實驗設計
本文使用了C++作為開發語言,以OpenGL作為三維渲染引擎,在 Xcode的環境下,使用GLUT、GDAL庫,實現了基于四叉樹的LOD地形實時動態顯示系統. 本系統運行在雙核CPU的微機上,采用四線程,硬件配置如表2.

表2 開發環境配置
4.2 結果對比
如圖5、6、7所示,對應現實空間坐標點為北緯23度,東經121度,實際空間地理位置為臺灣的不同視點渲染效果圖.
4.3 性能分析
本文實現了基于四叉樹的LOD地形實時動態顯示系統,分別采用并行渲染的方式與非并行渲染的方式以進行性能比較(參見表3). 可以看出,采用并行渲染的幀率明顯高于非并行渲染幀率,內存占用量基本保持在825 M左右(300個緩存地形數據塊文件),說明多核CPU并行渲染可以有效的提高三維DEM渲染的性能,并且內存數據也穩定在合適的規模;釆用并行渲染的幀率遠遠高于非并行渲染方式,說明并行的效果顯著,達到了提高渲染性能的目標.
5 結語
本文利用多核CPU微機的并行計算能力,在大規模DEM三維地形數據渲染過程中,采用并行計算的方式,提高了系統的渲染效率. 本文所包含的工作主要分為以下幾個部分: 首先,實現了基于四叉樹的LOD地形渲染算法,基于此,結合并行計算方法,采用生產者消費者模型,實現了 LOD 算法的并行化. 除此之外,在研究并行技術的同時,研究了大規模地形渲染時的海量數據的組織與調度方法,通過設置一定區域的內存緩沖區以及數據更新機制實現了大規模數據的加載與處理.
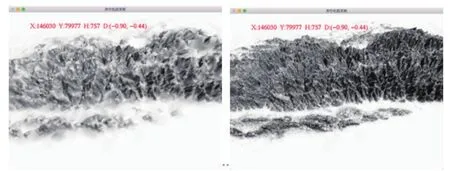
圖5 不同細節閾值對比圖

圖6 不同細節閾值對比圖(線框模式)

圖7 不同高度對比圖

表3 地形渲染實驗結果性能對比
地形渲染是大規模場景渲染的核心部分,隨著微機硬件的發展,在微機上實現大規模三維地圖渲染已經具有一定的硬件基礎. 本文基于多核CPU,實現了大規模地形數據渲染的實驗,所取得的理論與技術方面的成果可作為大規模場景渲染的理論基礎和技術基礎.
同時,關于大規模場景渲染,還有很多問題值得我們進一步研究與探討. 比如DEM三維可視化的仿真效果,如何更好的模擬真實的地理環境,在渲染地形數據的同時,也渲染出光照、紋理、陰影、不同的地貌特征等; 比如結合GPU和本文使用的多核CPU共同實現三維地形渲染,從而實現更高效率的并行計算,這些都是需要進一步開展的研究內容.
1陳路. 3D游戲引擎技術—大規模場景實時圖形渲染的研究與實現[碩士學位論文]. 成都: 電子科技大學,2005.
2陳景廣,佘江峰,宋曉群,等. 基于多核 CPU 的大規模DEM并行三維渲染. 武漢大學學報?信息科學版,2013,38(5): 618–621.
3Zhai R,Lu K,Pan WG,et al. GPU-based real-time terrain rendering: Design and implementation. Neurocomputing,2016,171: 1–8. [doi: 10.1016/j.neucom.2014.08.108]
4王沖. 大規模地形的快速幾何繪制與實時紋理映射技術研究[碩士學位論文]. 天津: 中國民航大學,2009.
5劉曉平,凌實,余燁,等. 面向大規模地形 LOD 模型的并行簡化算法. 工程圖學學報,2010,31(5): 16–21.
6周發亮. 基于四叉樹的LOD技術在地形渲染中的應用. 計算機仿真,2007,24(1): 188–191.
7Wu J,Yang YF,Gong SR,et al. A new quadtree-based terrain LOD algorithm. Journal of Software,2010,5(7):769–776.
8Yu WL,Zhang LM,Zhang BQ,et al. Large-scale LOD adaptive terrain rendering. Applied Mechanics and Materials,2012,220-223: 2450–2453. [doi: 10.4028/www.scientific.net/AMM.220-223]
9任宏萍,靳彪. 基于4叉樹的LOD地形實時渲染技術. 華中科技大學學報 (自然科學版),2011,39(2): 6–10.
10趙慶. 大規模地形數據調度與繪制技術研究與實現[碩士學位論文]. 成都: 電子科技大學,2011.
11鄭笈,李思昆,陸筱霞. 大規模場景繪制的存儲數據調度組織研究. 節能環保 和諧發展——2007中國科協年會論文集 (一). 武漢,中國. 2007. 6.
12Yang C,Dai SY,Wu LD,et al. Smoothly rendering of largescale vector data on virtual globe. Applied Mechanics and Materials,2014,631-632: 516–520. [doi: 10.4028/www.scientific.net/AMM.631-632]
Parallel Rendering of Massive Terrain Data Based on LOD
WANG Qing-Yun1,2,LUO Ze2
1(University of Cinese Academy of Sciences,Beijing 100049,China)
2(Computer Network Information Center,Chinese Academy of Sciences,Beijing 100190,China)
With the development of geo spatial information technology,it is more important to build large scale virtual terrain scene with massive spatial data. However,in the face of massive terrain data,how to simplify terrain,improve rendering and rendering efficiency,is the key to the terrain rendering. After the research of the terrain rendering technology of LOD,the analysis and processing of large scale data sets,parallel computing and other related technologies,the parallel rendering technology of massive terrain data based on LOD is proposed. At first,quadtree LOD is used to simplified terrain,secondly it is combined with multi-core CPU parallel computing method to enhance efficiency,then it is combined with the large data scheduling strategy,finally it realizes the parallel rendering of massive terrain data,and it analyzes the non-parallel and parallel experiments under the same conditions. The theoretical and technical achievements in the research can provide a new idea for large scale scene rendering.
LOD technology; parallel computing; massive data; terrain render
王青云,羅澤.基于LOD的海量地形數據并行渲染技術.計算機系統應用,2017,26(12):200–206. http://www.c-s-a.org.cn/1003-3254/6113.html
2017-03-15; 修改時間: 2017-03-31; 采用時間: 2017-04-10
