基于迭代重加權的高階張量圖匹配算法
2018-01-26 07:32:10徐國夏韓立新石冰
微型電腦應用 2018年1期
徐國夏, 韓立新, 石冰,2
(1.河海大學 計算機與信息學院, 南京 211100; 2.安慶師范大學 計算機與信息學院, 安慶 246000)
0 引言
圖匹配問題在計算機視覺和模式識別中是一個非常基礎且重要的問題。圖匹配作為圖像相似性度量的一種方法,多用于圖像分析處理等任務。例如遙感圖像融合處理、醫學圖像處理,航空影像自動制圖等方面。在諸多應用驅動下產生了一系列實際場景,例如圖像檢索[1]、形狀匹配[2]、目標追蹤[3]等。圖匹配基于圖模型描述圖像特征,通過節點和邊來表示圖像特征元素和圖像特征元素之間的關系。這是對圖像從像素級特征表示到高級語義級特征表示的拓展,具有表示復雜視覺模式的能力。近年來,研究工作者逐漸開始關注高階圖匹配,其利用張量的結構表示特征點集間的高階圖結構關系,能更好地解決圖像特征表示與建模的歧義性問題。高階圖匹配[7]利用超圖(Hyper-graph)來對應構建視覺特征集之間的關系,超圖是3個特征點或者是3個以上特征點集對之間的關系。
從優化角度來說,圖匹配問題其本質上是一種離散組合優化問題,其本身具有NP(non-deterministic polynomial) hard性質。因此大多數圖匹配的解決方案是從優化角度出發尋找有效的近似算法[4],首先對匹配問題的離散約束進行一定程度上的松弛,再對松弛后的問題利用優化方法進行求解。圖匹配方法中比較有代表性的方法有:基于譜方法,Leordanu等[5]提出了譜匹配SM(Spectral Matching)方法。 基于雙隨機約束松弛方法,Zaslavskiy等[6]基于凹凸松弛提出了一種(path-following)的方法,將圖匹配問題松弛成了目標函數的凸和凹松弛問題。但是基于譜方法和雙隨機約束松弛的方法忽視了匹配問題的離散約束性,故越來越多基于稀疏約束的匹配方法增加稀疏約束來獲得更有效的稀疏優化解。
Duchenne等[7]將高階圖匹配TM(Tensor Matching)問題形式化成一個三階張量的目標函數,結合L1范數并得到匹配的稀疏解。文獻[9]證明了L1/2范數其具有無偏性、稀疏性等良好的理論性質,其在變量選擇和特征提取上的表現優于L1范數和L2范數。為進一步探索稀疏優化技術在圖匹配中的應用,本文將高階張量圖匹配模型與L1/2范數結合,通過迭代重加權的優化方式近似求解該正則子,提出了基于L1/2范數重加權改進的高階圖匹配算法(Iterative Reweight High-order Graph Matching, IRHGM),力求在所構建的非凸非光滑的模型上取得最優的解稀疏性和噪聲魯棒性。實驗證明本文的算法比傳統方法具有更高的匹配正確率及更強的魯棒性。
1 原理背景
1.1 基于張量高階圖匹配模型
基于張量的高階圖匹配算法在二階譜匹配的基礎上拓展而來,從點對點(point-to-point)、線對線(line-to-line)拓展到三角結構到三角結構(triple-to-triple)。拓展的不僅僅是比較的數量級,更多的是在模型上從原來的線性向非線性的推廣。利用三階張量結構信息更能覆蓋目標特征點之間的多重幾何組合關系,對噪聲、尺度不變性、仿射不變性、分辨率、視角變化等的干擾具有更強的魯棒性。張量(tensor)[8]是多維矩陣的拓展,張量可以由諸多基于若干個坐標系中發生轉換關系改變的集合分量定義。N階張量表示為A∈RL1×L2×…×LN,A中的元素表示為xl1l2…ln。與矩陣的Frobenius范數類似,張量的F范數可以表示成式(1)。
(1)

高階圖匹配中利用高階圖結構信息來構建關系張量A,首先在特征點集中選取(i,j,k) 三個點,組成一個點集元組,該元組相似度量值由其組成的三角形結構信息fi,j,k,和另一個相對應元組fi′,j′,k′來度量為式(2)。

(2)
關系張量A是一個超對稱的張量,以稀疏存儲的方式存儲坐標及相對應度量值。基于張量表示的高階圖匹配模型能夠自然地對高階結構內在的幾何結構和關聯關系進行描述,解決了圖像特征表示的結構化建模。
基于候選匹配進行矩陣約束可以將其劃分成一個二次分配問題,該目標函數通過對關系矩陣的行列約束得到最優匹配結果為式(3)。
(3)
高階圖匹配問題是在矩陣基礎上推廣成高階張量表達,定義了與張量有關的目標函數為式(4)。
(4)
在兩組點集中{P}和{Q},其點集中特征點個數分別是p,q。該高階匹配模型的目標是在點集中找到相對應的點集對關系,匹配解X是由0,1組成的分配矩陣。高階匹配模型是在三組約束下,通過尋找相似三角形對來得到最優匹配結果。將分配矩陣X重新向量化為x=vec(X),大小為N=pq。模型(4)可以用tensor-vector乘法的定義為式(5)。
?ixi?jxj?kxk
(5)
?表示為Kronecker積的形式表達。
1.2L1/2范數
近些年發展起來的正則化方法在變量選擇和特征提取等工作上得到廣泛應用。如圖1所示。

使用等距角度,將這些點投射在球上。使用標準圖的連接線繪制排序點,以前在2-norm或者1-norm球上的等距點現在非常稀疏接近0.5-norm球。從直觀的幾何角度分析上來看,L1/2范數與L2、L1范數相比較曲線更加平緩,處在兩者之下,更易于相交于等高線。因此L1/2范數的解會比其余兩者更具稀疏性。
在諸多范數中,L0對應的是最優的變量選擇結果,但是它本身就是一個NP問題。故一些工作已經證明L1已經在某種意義下是等價于L0的。L1/2范數是更具有應用價值的。Ochs等[10]研究將L1/2范數近似為重加權L1范數,更能產生稀疏的解。同時在求解L1/2范數的迭代算法問題上,利用已有的L1范數進行賦權求解。并且也證明了L1/2范數收斂性。
求解L1/2范數的算法流程如式(16)。
步驟1:初始化模型:
xt=(1,…,1)T,t=0
(6)
步驟2: 轉化為模型:

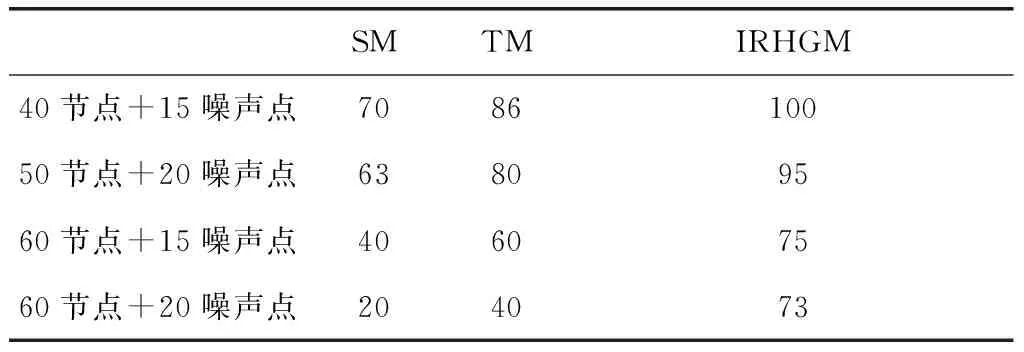
步驟3:當t s.t.?x∈[0,1] (7) 模型(7)對分配矩陣X中的每個列分量xi進行約束,約束每一變量值在[0, 1]之間,λ控制模型復雜度。模型(7)是一個非凸非光滑的目標函數,相較于原始模型,通過L1/2范數控制解的稀疏性。同時本文也提出相對應的基于迭代重加權方法估計非光滑范數,將其近似為加權L1范數,如式(8)。 s.t.?x∈[0,1] (8) 對于該模型的加權的L1范數,繼續利用張量冪迭代進行推導。基于張量冪迭代的約束優化問題(8)的Lagrange函數定義為式(9)。 (9) (10) 算法1:基于迭代重加權的高階圖匹配算法(IRHGM) 輸出:分配矩陣X 1) 初始化X={1,…,1}T 直到收斂 本文提出的基于L1/2范數的IRHGM算法,實驗對象在House dataset標準數據集進行驗證。本算法實驗平臺Intel(R) Xeon(R), 3.47GHz,CPU,Window7操作系統的PC,算法使用Matlab+Mex混合編程實現。本文提出的算法在下列3個方面均衡評價,對解集稀疏性,匹配準確率和抗噪魯邦性進行實驗比較。對比了基于L1范數張量匹配方法TM(Tensor Matching)[6]和基于L2范數譜匹配方法SM(Spectral Matching)[8]。 首先實驗利用在準備實驗數據點的時候,利用SIFT描述子提取候選備用點,分別提取30,40,50,60個實驗節點。然后利用knn算法尋找出盡可能相似的三角形組合,分別可以尋找出630000,1120000,1892800,2520000個組合。在此基礎上構建稀疏張量,這是一個非常大的稀疏張量,在這個張量空間中挖掘匹配結果。匹配準確率結果,如圖2所示。 圖2 不同實驗節點個數下相應TM,SM, L1/2范數的高階圖匹配模型IRHGM的匹配準確率結果要優于其他算法。 分配矩陣X的稀疏性結果比較,如圖3所示。 表明了IRHGM優于TM(基于L1范數)算法收斂得到的解,體現了本文提出算法的優越性。同時IRHGM稀疏性越高的基礎也提高了匹配準確率。 本文同時在模型和優化方法上進行完善,該算法不僅考慮了解的稀疏保持性,同時更能抵抗匹配噪聲,體現了算法的魯棒性。在待匹配數據中增加了隨機噪聲,如圖4所示。 圖4中右邊圖片增加隨機噪聲點。不同實驗節點再增加噪聲點的實驗對比,比較匹配準確率。可以看出IRHGM在整體準確率上優于其余算法,對存在噪聲點的情況下仍然不會降低匹配準確率,如表1所示。 圖3 本文提出的IRHGM匹配算法與TM匹配算法的解即對分配矩陣X的稀疏性結果比較圖(IRHGM匹配正確率93%,TM匹配正確率83%,50個節點) L1/2norm L1 norm 圖4 本文提出的IRHGM匹配算法和TM匹配算法結果示意圖(連接線兩端指向相同數字代表匹配正確,數字不相同和沒有數字都代表沒匹配上,且出現了一對多的誤匹配)。 本文提出的算法IRHGM融合了高階張量模型和更稀疏的L1/2范數稀疏約束,在保證全局優化基礎上得到有效且稀疏的解,并且實驗結果也驗證了算法對于噪聲的魯棒性。 表1 在不同噪聲點不同算法的準確率比較(%) 圖匹配問題一直是計算機視覺中的基礎問題,本文利用高階張量超圖模型和L1/2范數,提出了基于L1/2范數的迭代重加權高階圖匹配算法,以迭代重加權的方式近似求解賦權L1范數,優化高階圖匹配模型。實驗證明本算法不僅得到了更優的解稀疏性,更增強了對匹配噪聲的魯棒性,與相關算法比,得到了更高的匹配準確率,能夠更好的將匹配算法輔助運用到其他計算機視覺場景[12][13]中。未來我們考慮將稀疏約束引入多圖匹配中的相關算法,進一步地提升多圖匹配的匹配準確率。 [1] Helala M A E, Selim M M, Zayed H H. An Image Retrieval Approach Based on Composite Features and Graph Matching[C]. IEEE, International Conference on Computer and Electrical Engineering. 2009, pp:466-473. [2] Ngo, Quoc-Tao, Duc-Dung Nguyen, and Shu-Chuan Chu. Similarity Shape Based on Skeleton Graph Matching. [J] Journal Info. Multi. Signal Processing, 2016 7(6):1254-1264. [3] 王治丹, 蔣建國, 齊美彬. 基于最大池圖匹配的形變目標跟蹤方法[J]. 電子學報, 2017, 45(3):704-711. [4] 江波, 湯進, 羅斌. 計算機視覺中的圖匹配方法研究綜述[J]. 安徽大學學報(自科版), 2017, 41(1):29-36. [5] M. Leordeanu and M. Hebert. A spectral technique for correspondence problems using pairwise constraints [C]. IEEE International Conference on Computer Vision, Beijing, China, October, 2005, pp:1482-1489. [6] M. Zaslavskiy, F. Bach, and J. Vert. A path following algorithm for the graph matching problem [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12):2227-2242. [7] O. Duchenne, F. Bach, I.-S. Kweon, and J. Ponce. A tensor-based algorithm for high-order graph matching [J]. IEEE transactions on pattern analysis and machine intelligence, 2011, 33(12):2383-2395. [8] Papalexakis E E, Faloutsos C, Sidiropoulos N D. Tensors for Data Mining and Data Fusion: Models, Applications, and Scalable Algorithms[M]. ACM, 2016. [9] 張海, 王堯, 常象宇,和徐宗本. L_(1/2)正則化[J]. 中國科學:信息科學, vol.40, no.3, pp:412-420, 2010. [10] P. Ochs A. Dosovitskiy, T. Brox, and T. Pock. On Iteratively Reweighted Algorithms for Nonsmooth Nonconvex Optimization in Computer Vision [J]. Siam Journal on Imaging Sciences, 2015, 8(1):331-372. [11] Lathauwer L D, Moor B D, Vandewalle J. On the best rank-1 and rank-(R1, R2. . ,RN ) approximation of higher-order tensor[J]. Siam Journal on Matrix Analysis & Applications, 2000, 21(4):1324-1342. [12] Du D, Qi H, Li W, Huang Q and Lyu S. Online Deformable Object Tracking Based on Structure-Aware Hyper-Graph[J]. IEEE Transactions on Image Processing, 2016, 25(8):3572. [13] Dutta, Anjan, Josep Lladós, Horst Bunke, and Umapada Pal. Product Graph-based Higher Order Contextual Similarities for Inexact Subgraph Matching[OJ]. 2017. arXiv preprint arXiv:1702.003912 改進的基于L1/2范數的迭代重加權高階張量圖匹配模型





3 實驗結果及分析





4 總結
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
