LGM模型中缺失數(shù)據(jù)處理方法的比較:ML方法與Diggle-Kenward選擇模型*
2018-01-31 23:36:36張杉杉劉紅云
心理學(xué)報(bào) 2017年5期
張杉杉 陳 楠 劉紅云
(1首都經(jīng)濟(jì)貿(mào)易大學(xué)勞動(dòng)經(jīng)濟(jì)學(xué)院,北京 100070)(2北京師范大學(xué)心理學(xué)院應(yīng)用實(shí)驗(yàn)心理北京市重點(diǎn)實(shí)驗(yàn)室,北京 100875)(3艾美仕市場(chǎng)調(diào)研咨詢(上海)有限公司,北京 100005)
1 引言
追蹤研究(Longitudinal Study)通過(guò)在一段時(shí)間內(nèi),對(duì)個(gè)體的某種或某些特征進(jìn)行有系統(tǒng)的、定期的觀測(cè),來(lái)探討特質(zhì)發(fā)生、發(fā)展以及變化的特點(diǎn)。在追蹤研究中,研究者雖盡量使得前后觀測(cè)樣本相同,但是由于追蹤研究耗時(shí)較長(zhǎng),被試常常會(huì)因?yàn)閭€(gè)體特質(zhì)或者其他外部影響因素而退出實(shí)驗(yàn),造成大量的缺失情況。追蹤研究中數(shù)據(jù)的缺失是研究者普遍會(huì)面臨的問(wèn)題,但是如何選取合適的處理方法并不容易。
缺失數(shù)據(jù)處理方法的選擇依賴于缺失數(shù)據(jù)產(chǎn)生的機(jī)制以及缺失模式。缺失數(shù)據(jù)機(jī)制描述了缺失數(shù)據(jù)與該數(shù)據(jù)集中變量的真實(shí)值之間,以及與協(xié)變量之間的關(guān)系,主要有完全隨機(jī)缺失(Missing Completely at Random,MCAR)、隨機(jī)缺失(Missing at Random,MAR)和非隨機(jī)缺失(Missing Not at Random,MNAR)三種。前兩種情況下缺失值被視為可忽略的(Little &Rubin,2002),而非隨機(jī)缺失機(jī)制常被視為是不可忽略的(Power et al.,2012),所謂“不可忽略”,指的是非隨機(jī)缺失的數(shù)據(jù)不能夠作為其來(lái)源完整數(shù)據(jù)的有效代表,因此如果僅用非隨機(jī)缺失后的完整數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析,將得到有偏的參數(shù)估計(jì)結(jié)果,甚至可能得到無(wú)效的結(jié)論 (Schafer &Graham,2002;Little &Rubin,2002)。
關(guān)于缺失數(shù)據(jù)處理方法的研究頗受重視,大量的研究表明,研究者常用的一些簡(jiǎn)單的缺失數(shù)據(jù)處理方法,如列刪除(Listwise Deletion)和對(duì)刪除(Pairwise Deletion),單一插補(bǔ)的方法,由于其得到的參數(shù)估計(jì)結(jié)果有偏,檢驗(yàn)力下降等種種局限性,并不推薦使用(Enders,2010)。近年來(lái),關(guān)于缺失數(shù)據(jù)處理方法的研究主要集中在MAR缺失機(jī)制下的探討,其中多重插補(bǔ)法和極大似然估計(jì)法是應(yīng)用最廣泛的兩種方法(Rotnitzky,2009)。對(duì)于MNAR缺失機(jī)制的數(shù)據(jù),研究者也提出了一系列的處理方法(Albert &Follmann,2009;Enders,2011a,2011b )。
對(duì)于非隨機(jī)缺失數(shù)據(jù)的處理,由于需要描述缺失機(jī)制與目標(biāo)變量的關(guān)系,其處理方法大多是采用基于模型的方法 (Little &Rubin,2002)。對(duì)于有非隨機(jī)缺失的追蹤數(shù)據(jù)的分析過(guò)程,則是在增長(zhǎng)模型的基礎(chǔ)上加入一個(gè)描述缺失特征的模型來(lái)矯正偏差(葉素靜,唐文清,張敏強(qiáng),曹魏聰,2014)。Heckman (1976)首先將選擇模型作為處理追蹤數(shù)據(jù)中MNAR缺失的方法,此后引起研究者廣泛關(guān)注。Little 和 Rubin (2002)、Schafer和 Graham (2002)推薦使用選擇模型(Selection Modeling)和模式混合模型(Pattern-Mixture Modeling)來(lái)處理MNAR缺失數(shù)據(jù)。基于潛變量增長(zhǎng)模型衍生出不同的處理非隨機(jī)缺失數(shù)據(jù)的模型,如Wu和Carroll (1988)模型、Diggle和Kenward (1994)選擇模型(以下簡(jiǎn)稱D-K選擇模型)等,進(jìn)一步在這些模型的基礎(chǔ)上添加潛類別變量,可以更加完善地處理帶有 MNAR缺失數(shù)據(jù)的增長(zhǎng)模型,如Beunckens,Molenberghs,Verbeke和Mallinckrodt (2008)潛類別選擇模型、D-K潛類別選擇模型(Muthén,Asparouhov,Hunter,&Leuchter,2011)、Roy(2003)潛類別模式混合模型和 Muthén-Roy潛類別模式混合模型模型(Muthén et al.,2011)等。這些基于模型的 NMAR處理方法也逐漸用于應(yīng)用研究中。但在實(shí)際應(yīng)用中,由于選擇模型和模式混合模型基于不同的缺失機(jī)制的假設(shè),且這些假設(shè)本身無(wú)法檢驗(yàn),因此很難對(duì)兩類方法進(jìn)行比較。本研究主要考慮選擇模型非隨機(jī)缺失機(jī)制的假設(shè)條件下,探討D-K模型在處理缺失數(shù)據(jù)時(shí)的表現(xiàn)。
2 問(wèn)題提出
雖然目前已有許多 MNAR數(shù)據(jù)的處理方法,在實(shí)際研究中也得以應(yīng)用,但 MNAR數(shù)據(jù)處理方法的選擇對(duì)研究者來(lái)說(shuō)仍存在困難。首先,在MNAR機(jī)制下各類處理方法都需要滿足一定的前提假設(shè),有研究者指出基于 MNAR機(jī)制下的處理方法可能會(huì)對(duì)缺失機(jī)制和正態(tài)分布的假設(shè)比較敏感(Enders,2011a,2011b)。但這一結(jié)論尚缺乏實(shí)證研究的證據(jù)。另外,對(duì)于MNAR缺失數(shù)據(jù),如果正態(tài)性假設(shè)不滿足,這些基于模型的處理方法是否具有穩(wěn)健性仍需要進(jìn)一步研究。同時(shí),實(shí)際中MNAR缺失下方法選擇的問(wèn)題,仍存在爭(zhēng)論。有研究者指出,如果忽略MNAR缺失機(jī)制而使用MAR假設(shè)下的模型會(huì)帶來(lái)估計(jì)上的偏差;但也有觀點(diǎn)認(rèn)為,即使在違背假設(shè)的情況下,一個(gè)好的 MAR模型仍然要優(yōu)于差的MNAR模型(Schafer,2003)。因此,在MNAR機(jī)制下,如果采用了基于MAR的穩(wěn)健極大似然估計(jì),其結(jié)果與基于 MNAR的模型分析方法相比,其表現(xiàn)是否也不遜色?另一方面,在 MAR機(jī)制下,如果采用基于MNAR的模型處理方法,其結(jié)果與 MAR下的穩(wěn)健極大似然估計(jì)是否存在差異。在目前尚無(wú)明確的檢驗(yàn)數(shù)據(jù)MAR和MNAR缺失機(jī)制的方法下,對(duì)這些問(wèn)題的探討,無(wú)疑對(duì)實(shí)際追蹤研究中,缺失數(shù)據(jù)處理方法的選擇很有價(jià)值。
基于上述問(wèn)題,本文主要通過(guò)模擬研究的方法探討以下幾個(gè)問(wèn)題:(1)在 MNAR缺失數(shù)據(jù)下,當(dāng)目標(biāo)變量不服從正態(tài)分布時(shí),D-K選擇模型的參數(shù)估計(jì)是否具有穩(wěn)健性;(2)追蹤數(shù)據(jù)中含有不同缺失機(jī)制的數(shù)據(jù),且目標(biāo)變量不滿足正態(tài)分布時(shí),基于增長(zhǎng)模型的穩(wěn)健極大似然(MLR)方法與 D-K選擇模型相比兩者是否存在差異。同時(shí),考慮數(shù)據(jù)偏離正態(tài)的程度、數(shù)據(jù)缺失比例、樣本量對(duì)不同方法的影響,并據(jù)此提供一些方法選擇和使用上的建議。
3 基于增長(zhǎng)模型的缺失數(shù)據(jù)處理方法
潛變量增長(zhǎng)模型(Latent Growth Curve Model,LGM)是處理追蹤數(shù)據(jù)的一種常用方法。該模型在結(jié)構(gòu)方程模型(Structural Equation Modeling,SEM)的視角下定義發(fā)展趨勢(shì)(McArdle &Epstein,1987;Meredith &Tisak,1990),通過(guò)潛變量(截距和斜率)來(lái)描述重復(fù)測(cè)量變量的發(fā)展特征。潛變量增長(zhǎng)模型中不僅關(guān)注潛變量的均值,同時(shí)關(guān)注其方差;前者描述了整體的增長(zhǎng)趨勢(shì),后者則代表增長(zhǎng)趨勢(shì)存在的個(gè)體差異。
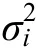
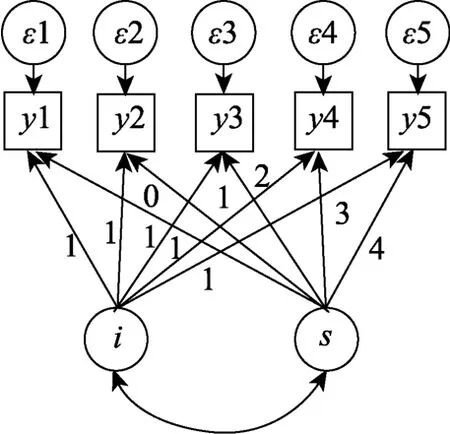
圖1 潛變量增長(zhǎng)模型
3.1 基于MAR假設(shè)的極大似然估計(jì)
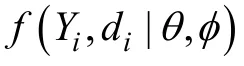
由于在MAR機(jī)制下,ML方法得到的參數(shù)估計(jì)是無(wú)偏的,而且與其他傳統(tǒng)的處理方法(如列刪除、對(duì)刪除和單一插補(bǔ)等)相比更加有效,方法學(xué)家們認(rèn)為其是一種先進(jìn)的處理缺失數(shù)據(jù)的技術(shù)(“a stateof-art missing data technique”.Schafer &Graham,2002)。甚至在MCAR機(jī)制下,ML方法也會(huì)比其他處理方法產(chǎn)生更優(yōu)良的統(tǒng)計(jì)量,因?yàn)樗ㄟ^(guò)從觀測(cè)數(shù)據(jù)中“借取”信息而使得統(tǒng)計(jì)檢驗(yàn)力最大化(Enders &Bandalos,2001)。雖然理想的極大似然估計(jì)假設(shè)數(shù)據(jù)服從正態(tài)分布,但是大量的研究結(jié)果表明,非正態(tài)校正的穩(wěn)健極大似然估計(jì)(robust ML;Yuan &Bentler,2000)即使在非正態(tài)的情況下,也可以得到近似無(wú)偏的結(jié)果。
3.2 Digg le-Kenward選擇模型
選擇模型(Selection Modeling)(Glynn,Laird,&Rubin,1986;Little,1993,1995)將數(shù)據(jù)和缺失概率的聯(lián)合分布分解為邊緣分布和條件分布的乘積:
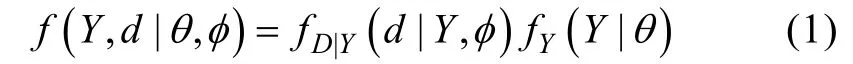
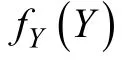
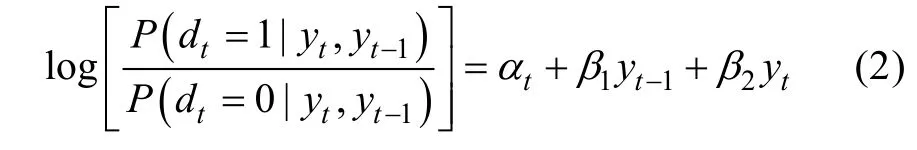
以Probit回歸模型定義的MNAR缺失機(jī)制可以用公式表示為:
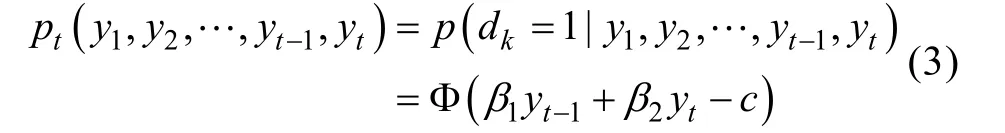
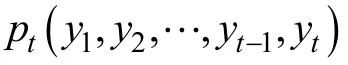
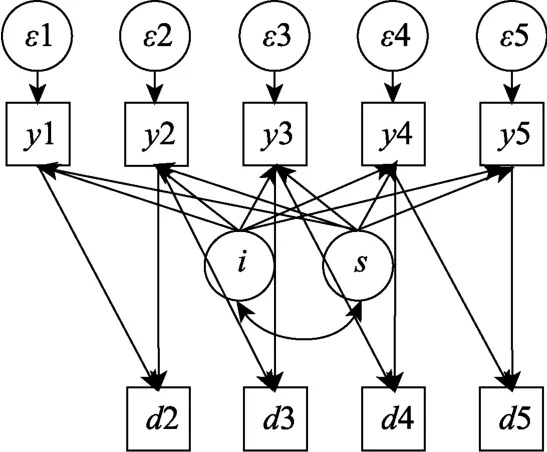
圖2 Diggle-Kenward選擇模型
4 研究方法
4.1 模擬設(shè)計(jì)
為了便于考察影響模型參數(shù)估計(jì)的因素,參考于以往研究者(Soullier,de La Rochebrochard,&Bouyer,2010;Yuan,Yang-Wallentin,&Bentler,2012)在模擬研究中考慮的影響因素,模擬設(shè)計(jì)如下:
(1)樣本量,根據(jù)前人研究(Zhang &Willson,2006)的建議,增長(zhǎng)模型的最小樣本量不低于 50,因此取100、300、500、1000四個(gè)水平,依次代表從小到大的樣本量。
(2)數(shù)據(jù)永久缺失比例,取5%、10%、20%、40%四個(gè)水平,依次代表由少至多的永久缺失數(shù)量。設(shè)定在某時(shí)間點(diǎn)永久缺失的個(gè)體在隨后時(shí)間點(diǎn)均保持缺失,則該比例代表在此時(shí)間點(diǎn)剔除此前已退出的個(gè)體后,剩余的個(gè)體中發(fā)生永久缺失的比例。
(3)目標(biāo)變量分布的偏態(tài)程度,取正態(tài)、輕微偏態(tài)、中度偏態(tài)和嚴(yán)重偏態(tài)四個(gè)水平。設(shè)定輕微偏態(tài)分布的偏度為0.5,峰度為3;中度偏態(tài)的偏度為2,峰度為12;嚴(yán)重偏態(tài)的偏度為3,峰度為30。
(4)考慮MNAR和MAR兩種缺失機(jī)制。
研究共包括4×4×4×2=128種實(shí)驗(yàn)處理,每種實(shí)驗(yàn)處理重復(fù) 500次。應(yīng)用 Mplus軟件(Muthén,&Muthén,2007)進(jìn)行分析。分析所用的語(yǔ)句見(jiàn)附錄1和附錄2。
4.2 數(shù)據(jù)生成與分析
本研究采用 R語(yǔ)言生成符合不同模型假設(shè)并帶有不同缺失模式的縱向數(shù)據(jù)集。數(shù)據(jù)生成過(guò)程如下:
第一步:生成完整的縱向數(shù)據(jù)集。
模擬的數(shù)據(jù)集代表對(duì)n
個(gè)被試重復(fù)測(cè)量t
(t
=5)次的追蹤研究,每次測(cè)量得到一個(gè)觀測(cè)值。采用潛變量增長(zhǎng)模型來(lái)生成滿足目標(biāo)變量分布特點(diǎn)的每個(gè)被試在各個(gè)時(shí)間點(diǎn)的觀測(cè)值y
,其中,j
=1,…,t
。對(duì)增長(zhǎng)模型中的參數(shù)設(shè)定如下:截距i
服從正態(tài)分布,其均值為?1,方差為 0.50;斜率 s服從正態(tài)分布,其均值為0.5,方差為0.02;殘差之間相互獨(dú)立,且服從正態(tài)分布,其均值為0,5次測(cè)量殘差的方差分別為:0.50,0.48,0.42,0.32,0.18。其中非正態(tài)數(shù)據(jù)的生成借助于廣義Lambda分布生成(Headrick &Mugdadi,2006)。第二步:生成永久缺失模式的數(shù)據(jù)集。
對(duì)于永久缺失模式為 MNAR的情況,考查其符合D-K選擇模型假設(shè)下的缺失機(jī)制,即目標(biāo)變量在某一時(shí)間點(diǎn)的缺失概率同時(shí)受當(dāng)次觀測(cè)值和前一次觀測(cè)值的影響。對(duì)于永久缺失模式為MAR的情況,考查符合 ML方法假設(shè)下的缺失機(jī)制,即目標(biāo)變量在某一時(shí)間點(diǎn)的缺失概率與上一時(shí)間點(diǎn)的觀測(cè)值有關(guān),而與當(dāng)次觀測(cè)值無(wú)關(guān)。具體來(lái)說(shuō),在D-K選擇模型的 MNAR機(jī)制假設(shè)下,使得目標(biāo)變量在某一時(shí)間點(diǎn)的缺失概率與當(dāng)次觀測(cè)值的大小成正比例關(guān)系,與上一時(shí)間點(diǎn)的觀測(cè)值成反比例關(guān)系;在 ML方法的 MAR機(jī)制假設(shè)下,使得目標(biāo)變量在某一時(shí)間點(diǎn)的缺失概率與上一時(shí)間點(diǎn)的觀測(cè)值大小成反比例關(guān)系,而與當(dāng)次觀測(cè)值無(wú)關(guān)。
4.3 評(píng)價(jià)標(biāo)準(zhǔn)
對(duì)于不同的處理方法的評(píng)價(jià)標(biāo)準(zhǔn),主要從參數(shù)估計(jì)精度和 95%置信區(qū)間對(duì)真值的覆蓋比率兩個(gè)方面來(lái)進(jìn)行比較和評(píng)價(jià)。
(1)誤差均方根(Root Mean Square Error,RMSE)。RMSE描述了參數(shù)估計(jì)值與真值之間的差異大小,其值越小表示得到的參數(shù)估計(jì)值與真值的偏差越小。RMSE的計(jì)算公式為:
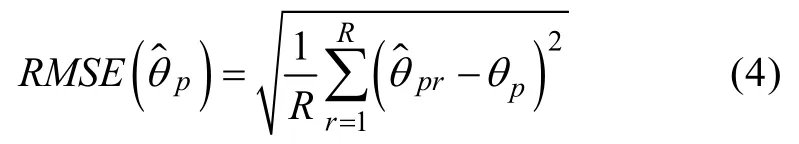
(2)95%置信區(qū)間對(duì)真值的覆蓋比率(Coverage Probability,CP)。該指標(biāo)體現(xiàn)了估計(jì)的準(zhǔn)確性,能在一定程度上反映參數(shù)估計(jì)精度和對(duì)應(yīng)的標(biāo)準(zhǔn)誤估計(jì)值的情況。其計(jì)算公式為:
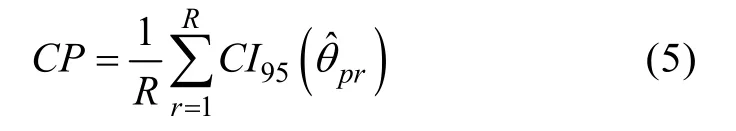
5 研究結(jié)果
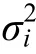
5.1 參數(shù)估計(jì)精度
在缺失機(jī)制為 MAR的情況下,基于 MAR的ML方法得到的參數(shù)估計(jì)的精度都略好于D-K選擇模型;而在缺失機(jī)制為 MNAR的情況下,基于MNAR的D-K選擇模型都優(yōu)于ML方法。這主要是由于MAR的缺失機(jī)制更符合ML方法對(duì)缺失機(jī)制的假設(shè),而MNAR的機(jī)制更符合D-K選擇模型對(duì)數(shù)據(jù)缺失機(jī)制的假設(shè)。
(1)截距均值的估計(jì)精度及影響因素
從圖3的結(jié)果可以看出,兩種缺失模式下,對(duì)于兩種處理缺失數(shù)據(jù)的方法,隨著樣本量的增大,參數(shù)估計(jì)的精度越來(lái)越高。從圖3(a)和圖3(b)可以看出,在MAR缺失模式下,D-K選擇模型和ML方法不存在差異,截距均值的估計(jì)精度不受缺失比例大小的影響;而在MNAR的缺失模式下,D-K選擇模型和ML方法存在差異,且隨著缺失比例的增加,兩種方法之間的差異越來(lái)越大。從圖3(c)和圖3(d)可以看出,在 MAR缺失模式下,截距均值的估計(jì)精度方法間不存在差異,也不受目標(biāo)變量偏態(tài)程度的影響;而在MNAR的缺失模式下,兩種方法存在差異,但差異程度的大小不受目標(biāo)變量偏態(tài)程度影響。綜合圖3的結(jié)果,對(duì)于截距均值的估計(jì),D-K選擇模型的參數(shù)估計(jì)精度即使在MAR缺失機(jī)制下仍具有穩(wěn)健性,而對(duì)于ML方法,在MNAR缺失機(jī)制下,只有缺失比例較小(低于 10%)時(shí),參數(shù)估計(jì)具有穩(wěn)健性。兩種方法對(duì)截距均值的估計(jì)精度均不受目標(biāo)變量偏態(tài)程度的影響。
(2)斜率均值的估計(jì)精度及影響因素
圖3 截距均值估計(jì)精度及其影響因素
圖4結(jié)果表明,對(duì)于斜率均值的估計(jì),兩種方法間存在差異,MAR缺失機(jī)制下,ML方法優(yōu)于D-K選擇模型,MNAR缺失機(jī)制下,D-K選擇模型優(yōu)于ML方法。
從圖4(a)和圖4(b)可以看出,無(wú)論那種缺失機(jī)制,隨著缺失比例的增加,兩種方法的差異增大。但在 MAR缺失機(jī)制下,隨著樣本量的增大,兩種方法的差異有減小的趨勢(shì),MAR缺失比例較大時(shí),隨著樣本量的增加兩種方法估計(jì)的精度均越來(lái)越高,且兩種方法之間的差異越來(lái)越小。在MNAR缺失機(jī)制下,隨著樣本量的增加D-K選擇模型估計(jì)的精度越來(lái)越高,而隨著樣本量的增大ML方法估計(jì)的精度并沒(méi)有明顯的改變,且兩種方法之間的差異隨著樣本量的增大越來(lái)越大。這說(shuō)明在 MNAR缺失機(jī)制下對(duì)于斜率均值的估計(jì),當(dāng)缺失比例較大時(shí)即使增大樣本量ML方法的估計(jì)精度依然很低。
從圖4(c)和圖4(d)可以看出,無(wú)論那種缺失機(jī)制,ML方法估計(jì)的精度幾乎不受目標(biāo)變量偏態(tài)程度的影響,而D-K選擇模型隨著目標(biāo)變量偏態(tài)程度的增加,估計(jì)精度有下降的趨勢(shì)。在 MAR缺失機(jī)制下,隨著目標(biāo)變量偏離正態(tài)分布程度的增加兩種方法之間的差異增大;同時(shí),隨著樣本量的增加,D-K選擇模型估計(jì)精度增加,兩種方法之間的差異減小。在MNAR缺失機(jī)制下,不論樣本量大小ML方法的估計(jì)精度都較低;D-K選擇模型對(duì)斜率均值估計(jì)精度受到目標(biāo)變量分布偏態(tài)程度的影響,當(dāng)分布偏態(tài)程度增加時(shí),D-K選擇模型估計(jì)精度變差。總體來(lái)講在 MNAR缺失機(jī)制下,無(wú)論目標(biāo)變量偏離正態(tài)分布的程度大小,即使增大樣本量也不能有效提高M(jìn)L方法的精度;D-K選擇模型對(duì)斜率均值的估計(jì)精度受目標(biāo)變量分布偏態(tài)程度的影響。
(3)截距方差的估計(jì)精度及影響因素
(4)斜率方差的估計(jì)精度及影響因素
5.2 95%置信區(qū)間對(duì)真值的覆蓋比率
使用正態(tài)分布的方法構(gòu)建各增長(zhǎng)參數(shù)的均值和方差估計(jì)的95%置信區(qū)間。表1分別給出不同模擬條件下兩種方法得到的95%置信區(qū)間對(duì)真值的覆蓋比率。
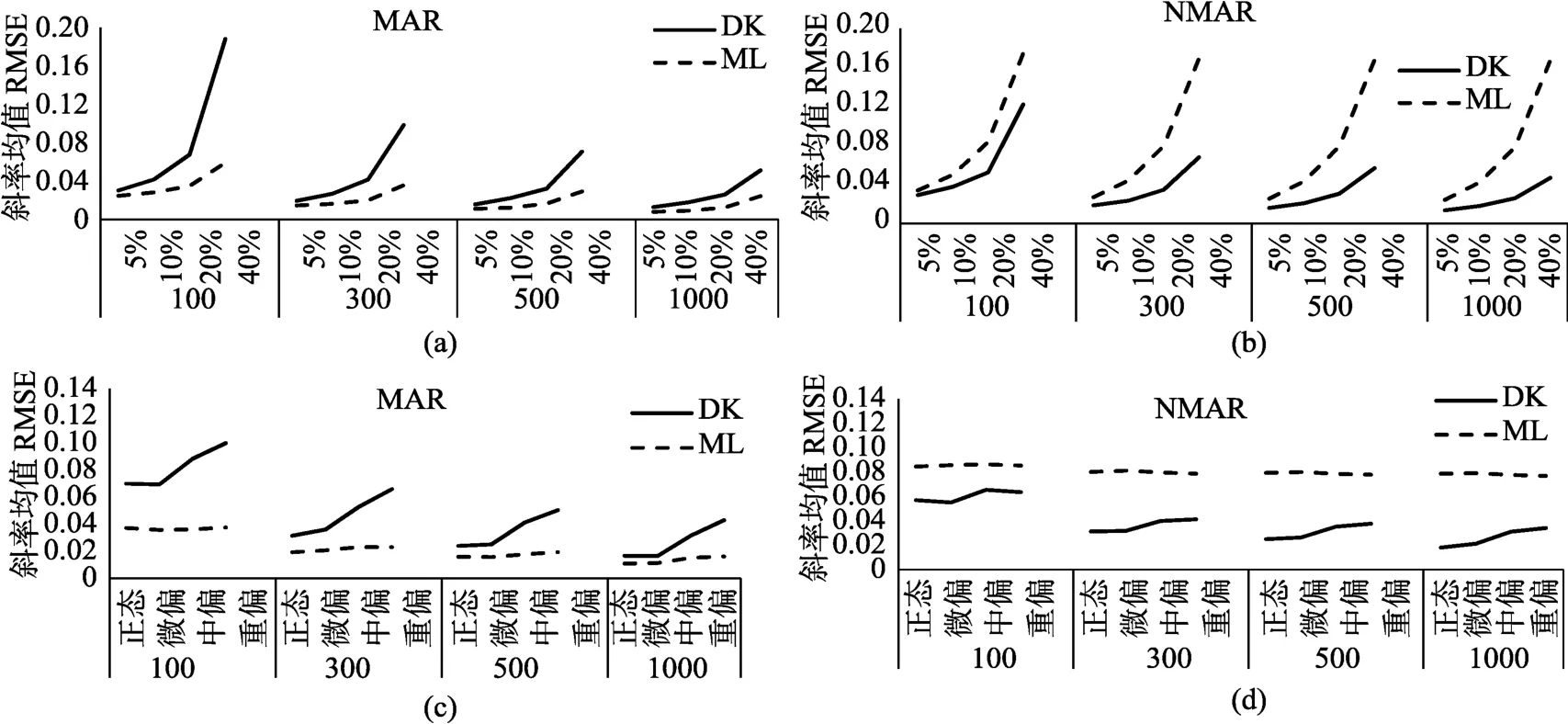
圖4 斜率均值估計(jì)精度及其影響因素
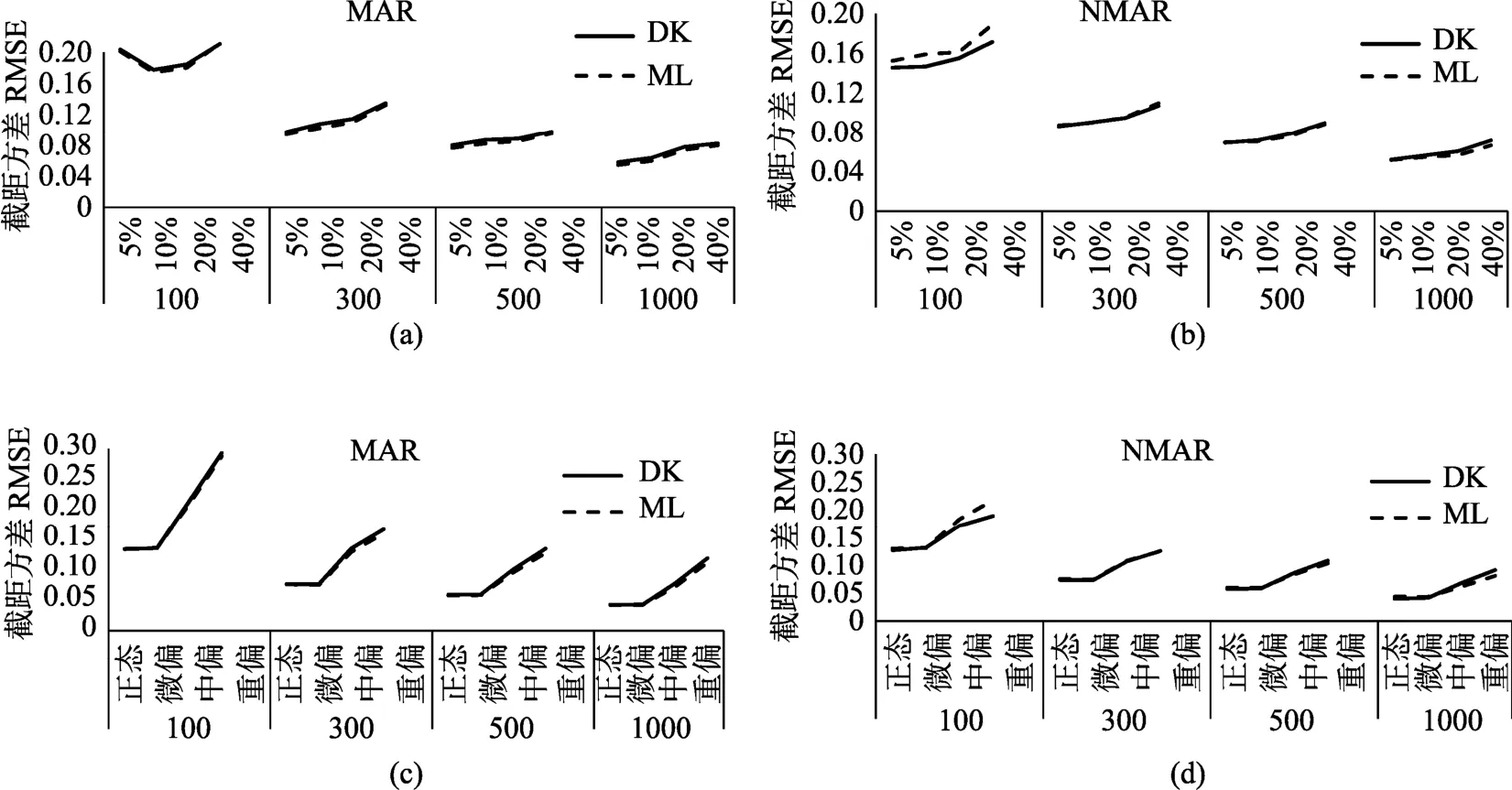
圖5 截距方差估計(jì)精度及其影響因素
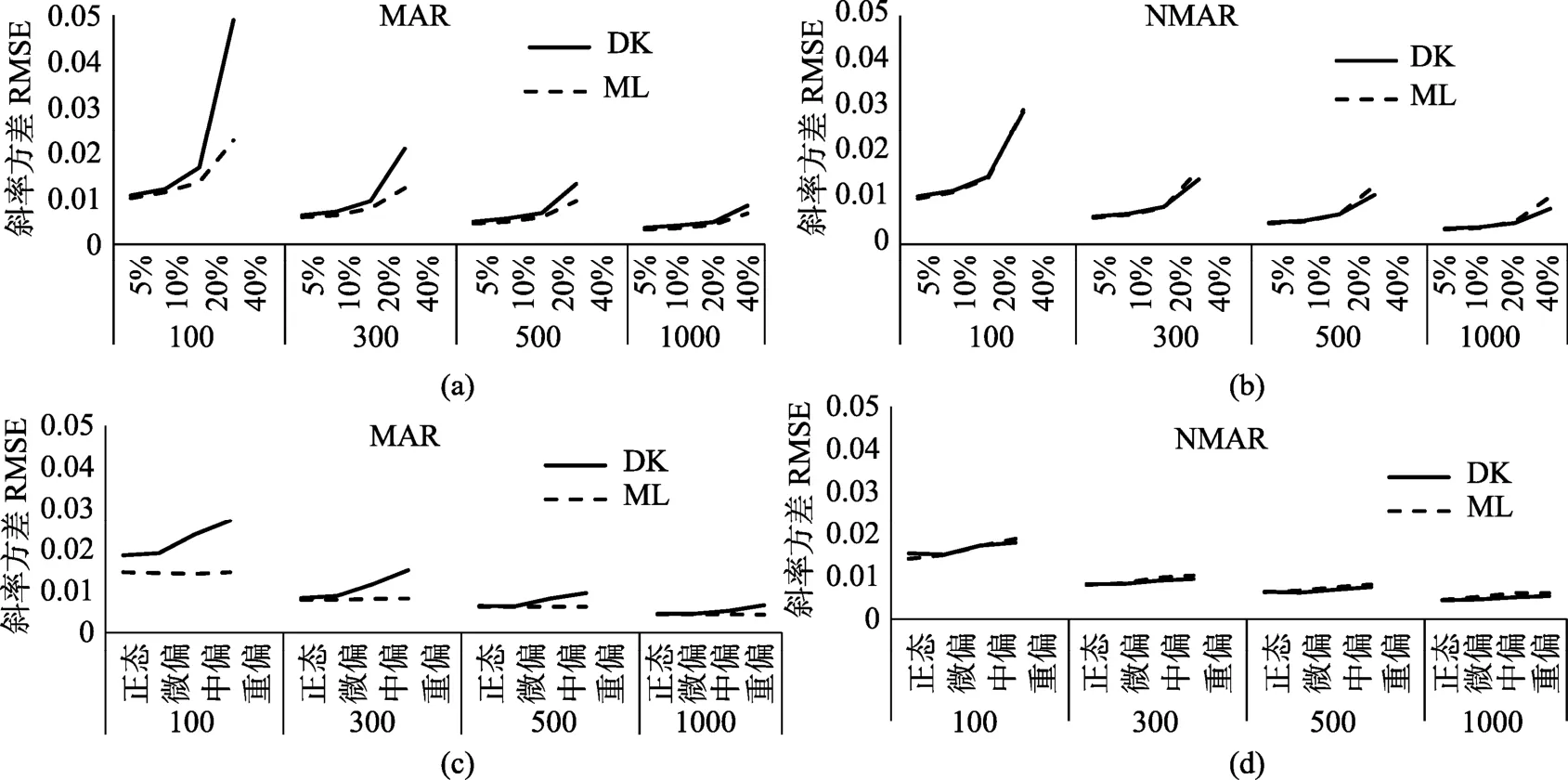
圖6 斜率方差估計(jì)精度及其影響因素
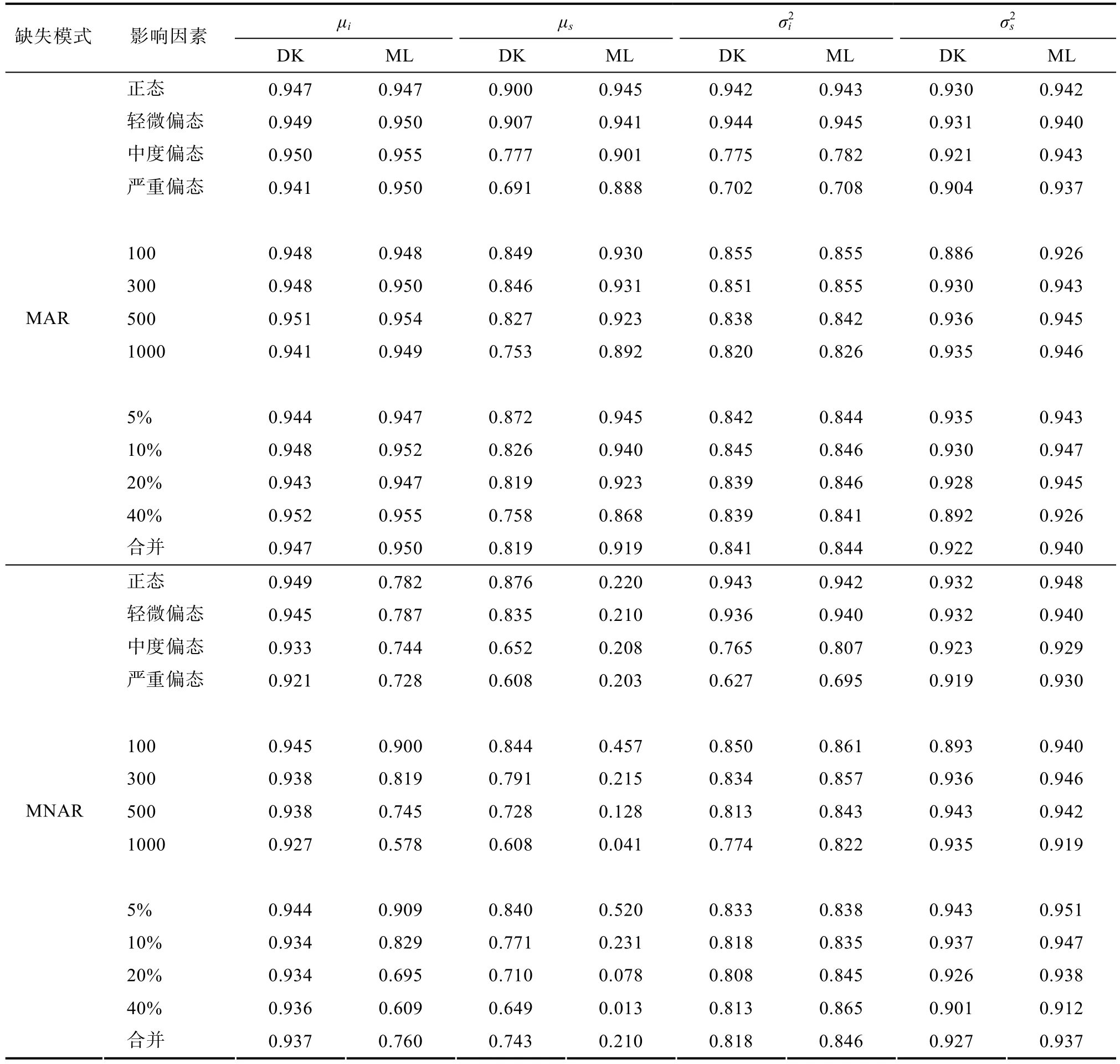
表1 95% 置信區(qū)間覆蓋比率
對(duì)于截距均值的估計(jì),在 MAR缺失機(jī)制下,兩種方法得到的 95%置信區(qū)間覆蓋比率差異很小;在MNAR缺失機(jī)制下,95%置信區(qū)間覆蓋比率ML方法遠(yuǎn)低于D-K選擇模型。在MAR下,ML方法和D-K選擇模型幾乎不受樣本量、目標(biāo)變量偏態(tài)程度和缺失比例的影響。而在MNAR下,隨著分布偏態(tài)程度的增大,各方法得到的95%置信區(qū)間對(duì)真值的覆蓋比率均有下降的趨勢(shì),但下降幅度不大。D-K選擇模型幾乎不受樣本量和缺失比例的影響,但是ML方法隨著樣本量增大和缺失比例的增加,置信區(qū)間覆蓋比率顯著下降。
對(duì)于斜率均值的估計(jì),在 MAR缺失機(jī)制下,ML方法優(yōu)于D-K選擇模型;在MNAR缺失機(jī)制下,ML方法得到的 95%置信區(qū)間覆蓋比率遠(yuǎn)遠(yuǎn)低于MAR缺失機(jī)制下D-K選擇模型。隨著偏態(tài)程度增大,D-K選擇模型和ML方法得到的95%置信區(qū)間覆蓋比率有所降低,D-K選擇模型的下降速度較明顯,而ML方法下降不明顯。在MNAR缺失機(jī)制下,隨著偏態(tài)程度增大,D-K選擇模型得到的95%置信區(qū)間覆蓋比率有明顯的降低,ML方法得到的結(jié)果雖有下降趨勢(shì)但相對(duì)很小。隨著樣本量增大和缺失比例的增加,兩種方法得到的95%置信區(qū)間覆蓋比率均有下降的趨勢(shì)。但是在MAR缺失模式下D-K選擇模型受樣本量和缺失比例的影響更大;而在MNAR缺失模式下,ML方法受樣本量和缺失比例的影響更大。
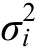
對(duì)于斜率方差的估計(jì),兩種缺失機(jī)制下,兩種方法得到的置信區(qū)間覆蓋比率幾乎沒(méi)有差異。兩種方法得到的 95%置信區(qū)間覆蓋比率幾乎不受目標(biāo)變量分布偏態(tài)程度、樣本量和缺失比例的影響。
6 討論與建議
6.1 討論
本文重點(diǎn)解決了三個(gè)方面的問(wèn)題,一是在MAR缺失機(jī)制下,基于MNAR的D-K選擇模型是否可以得到與ML方法近似的結(jié)果;二是在MNAR缺失機(jī)制下,基于MAR的ML方法是否可以得到與 D-K選擇模型近似的結(jié)果;三是在目標(biāo)變量正態(tài)分布的假設(shè)不滿足時(shí),不同缺失機(jī)制下兩種方法是否具有穩(wěn)健性。
(1)基于MAR的ML方法與基于MNAR的D-K選擇模型的比較
無(wú)論是從參數(shù)估計(jì)的精度還是從 95%置信區(qū)間對(duì)真值的覆蓋比率,在 MAR的缺失機(jī)制下基于MAR的ML方法得到了比D-K選擇模型更優(yōu)的結(jié)果,而在MNAR的缺失機(jī)制下基于MNAR的D-K選擇模型的結(jié)果優(yōu)于ML方法。
在 MAR的缺失機(jī)制下,對(duì)于潛變量增長(zhǎng)模型關(guān)心的參數(shù)截距均值、截距方差和斜率方差這3個(gè)參數(shù),兩種方法得到的差異很小,尤其是在大樣本量的情況下。這就說(shuō)明即使數(shù)據(jù)是MAR的缺失機(jī)制,采用D-K選擇模型對(duì)截距均值、截距方差和斜率方差的估計(jì)也不會(huì)帶來(lái)非常嚴(yán)重的偏差,95%置信區(qū)間的覆蓋比率的結(jié)果也說(shuō)明了兩種方法的差異不大;對(duì)于斜率的均值,兩種方法存在差異,但是當(dāng)樣本量較大時(shí),兩種方法的差異逐漸減小,也就是說(shuō),在大樣本的情況下,D-K選擇模型相對(duì)于MAR機(jī)制的缺失數(shù)據(jù),對(duì)斜率均值的估計(jì)具有一定的穩(wěn)健性,不過(guò)值得注意的是此時(shí)得到的95%置信區(qū)間的覆蓋比率略低于 ML方法。ML方法在MAR下得到較好的參數(shù)估計(jì)結(jié)果的結(jié)論與以往這一領(lǐng)域的研究所得到的結(jié)論一致,樣本量和缺失比例的影響也得到了相似的結(jié)論(Enders &Bandalos,2001,2011a;Yuan,Yang-Wallentin,&Benter,2012;Lu,Zhang,&Cohen,2013)。
在 MNAR的缺失機(jī)制下,對(duì)于潛變量增長(zhǎng)模型關(guān)心的截距方差和斜率方差這兩個(gè)參數(shù),兩種方法得到的差異很小。這就說(shuō)明即使數(shù)據(jù)是 MNAR的缺失機(jī)制,采用ML方法對(duì)截距方差和斜率方差的估計(jì)也不會(huì)帶來(lái)非常嚴(yán)重的偏差,95%置信區(qū)間的覆蓋比率的結(jié)果也說(shuō)明了兩種方法的差異不大;但是對(duì)于截距均值和斜率均值的估計(jì),兩種方法存在明顯差異,且隨著樣本量增大,兩種方法的差異越來(lái)越大。這就說(shuō)明,即使在大樣本的情況下,ML方法相對(duì)于 MNAR機(jī)制的缺失數(shù)據(jù),對(duì)截距均值和斜率均值的估計(jì)仍存在較大偏差,95%置信區(qū)間的覆蓋比率也可以得到類似的結(jié)論,尤其是對(duì)于斜率均值的估計(jì);值得注意的是,當(dāng)缺失比例很小時(shí)(如5%),兩種方法的差異很小。綜合來(lái)看,MNAR下的D-K選擇模型較小受到缺失機(jī)制的影響,但是在實(shí)際應(yīng)用中應(yīng)結(jié)合樣本量、目標(biāo)變量的偏態(tài)程度和缺失比例的高低選擇分析方法。Lu等(2013)和Lu和 Zhang (2014)分別基于潛變量增長(zhǎng)模性和潛變量混合增長(zhǎng)模型也發(fā)現(xiàn)缺失機(jī)制錯(cuò)誤的定義可能會(huì)導(dǎo)致錯(cuò)誤的結(jié)論,與本得到的結(jié)果一致。進(jìn)一步證實(shí)了在缺失數(shù)據(jù)處理過(guò)程中選擇正確模型的重要性。
(2)不同方法對(duì)目標(biāo)變量分布形態(tài)的穩(wěn)健性
考慮在違背模型對(duì)目標(biāo)變量分布形態(tài)的假設(shè)時(shí),各模型的估計(jì)表現(xiàn)如何。對(duì)于截距均值偏態(tài)程度對(duì)兩種方法參數(shù)估計(jì)精度的影響均很小,對(duì)95%置信區(qū)間的覆蓋比率的影響也很小。對(duì)于斜率均值,D-K選擇模型在ML方法的假設(shè)下受到偏態(tài)程度的影響更大,且此時(shí)永久缺失比例與偏態(tài)程度之間存在明顯的交互作用,在永久缺失比例大的情況下,其參數(shù)估計(jì)精度受偏態(tài)程度影響更敏感;與以往研究結(jié)果相同(Yuan &Lu,2008;Yuan,Yang-Wallentin,&Benter,2012;Enders &Bandalos,2001;Shin,Davison,&Long,2009),ML方法不受目標(biāo)變量分布偏態(tài)程度的影響;95%置信區(qū)間的覆蓋比率的結(jié)果也表明,其結(jié)果受偏態(tài)程度的影響,偏態(tài)程度越大,真值置信區(qū)間覆蓋比率越低。對(duì)于截距方差的估計(jì),各方法受到偏態(tài)程度的影響都較大,且樣本量與偏態(tài)程度之間均存在顯著的交互作用,在樣本量小的情況下,得到的參數(shù)估計(jì)精度受偏態(tài)程度的影響更敏感。對(duì)于斜率方差的估計(jì),MAR缺失機(jī)制下,D-K選擇模型受偏態(tài)程度的影響最明顯,且樣本量與偏態(tài)程度之間存在明顯的交互作用,當(dāng)樣本量小的時(shí)候,其參數(shù)估計(jì)精度受偏態(tài)程度的影響更敏感。而ML方法僅在 MNAR缺失機(jī)制下輕微受偏態(tài)程度的影響。總體來(lái)講,D-K選擇模型更容易受到目標(biāo)變量分布偏態(tài)程度的影響,在樣本量較大時(shí),偏態(tài)程度的影響會(huì)減弱,尤其是對(duì)于截距均值、截距方差和斜率方差的估計(jì)結(jié)果。正如 Muthén等(2011)指出的對(duì)于非隨機(jī)缺失的數(shù)據(jù),由于缺失機(jī)制依賴于變量的分布,參數(shù)估計(jì)結(jié)果就會(huì)更多的依賴正態(tài)性的條件。
對(duì)于缺失數(shù)據(jù)處理模型的選擇,應(yīng)該綜合考慮多種情況。其一,如果不能保證缺失數(shù)據(jù)的機(jī)制為MAR,則應(yīng)注意到,非隨機(jī)缺失的處理方法會(huì)依賴于目標(biāo)變量的分布的這一結(jié)論,可以通過(guò)一系列的轉(zhuǎn)換將其盡量轉(zhuǎn)換為正態(tài)分布。其二應(yīng)盡量讓數(shù)據(jù)的缺失機(jī)制接近于 MAR,主要是因?yàn)?ML方法在MAR缺失機(jī)制下,即使對(duì)于非正態(tài)的數(shù)據(jù)也可以得到一致的參數(shù)估計(jì)結(jié)果Yuan和Lu (2008)。但是在實(shí)際應(yīng)用中,往往很難驗(yàn)證數(shù)據(jù)的缺失機(jī)制是MAR,以往研究者建議在研究中盡量包含較多的變量個(gè)數(shù),以便使得缺失數(shù)據(jù)的機(jī)制接近 MAR,二階段的ML方法也是常用的方法(Graham,2003)。Yuan和Lu (2008)的研究表明,如果目標(biāo)變量服從的分布未知或非正態(tài),兩階段的ML方法是一個(gè)明智的選擇。同時(shí),也可以采用多個(gè)模型對(duì)數(shù)據(jù)進(jìn)行分析,采用一系列模型擬合的指標(biāo),如 AIC,BIC,CAIC,BIC和DIC幫助選擇合適的模型,具體內(nèi)容可以參考Lu等(2013)以及Lu和Zhang (2014)的研究。
6.2 建議
由于MNAR缺失機(jī)制的理論假設(shè)較MCAR和MAR而言更為復(fù)雜,因此在實(shí)際應(yīng)用中對(duì) MNAR機(jī)制缺失數(shù)據(jù)處理方法的選擇更要慎重。對(duì)于含有缺失值的研究數(shù)據(jù),在數(shù)據(jù)處理過(guò)程中要充分了解可能造成數(shù)據(jù)缺失的各種原因,遵循一定的分析過(guò)程對(duì)數(shù)據(jù)做全面的分析和了解。結(jié)合模擬研究的結(jié)果,本文建議在進(jìn)行敏感性分析時(shí)應(yīng)同步注意考慮目標(biāo)變量分布的偏態(tài)程度、缺失比例及樣本量的大小可能對(duì)參數(shù)估計(jì)造成的影響,基于此建議處理含有缺失的追蹤數(shù)據(jù)時(shí),采用以下的處理步驟:
(1)首先檢驗(yàn)?zāi)繕?biāo)變量是否服從正態(tài)分布,如果不服從正態(tài)分布,且偏離正態(tài)分布的程度為中等或較嚴(yán)重,則需要通過(guò)一些轉(zhuǎn)換將其轉(zhuǎn)換為正態(tài)分布,常用的轉(zhuǎn)換方法有對(duì)數(shù)轉(zhuǎn)換、指數(shù)冪轉(zhuǎn)換等。
(2)檢查數(shù)據(jù)的缺失模式。目前僅有完全隨機(jī)缺失(MCAR)機(jī)制可以通過(guò)檢驗(yàn)確定,方法包括進(jìn)行一系列獨(dú)立的t檢驗(yàn)(Dixon,1988)、Little的MCAR檢驗(yàn)(Little,1988)等。如果確信數(shù)據(jù)的缺失機(jī)制為MCAR,則可以采用基于完全隨機(jī)缺失的傳統(tǒng)處理方法,可參考Little和Rubin (2002)、Enders (2010,2011a)等人的介紹。
(3)如果不確定數(shù)據(jù)的缺失機(jī)制為 MCAR,檢驗(yàn)缺失比例的高低,如果缺失比例不超過(guò) 10%,根據(jù)模型省簡(jiǎn)的原則,則可以采用基于 MAR的 ML方法。
(4)如果不確定數(shù)據(jù)的缺失機(jī)制為 MCAR,根據(jù)已有的研究或經(jīng)驗(yàn)判斷可能會(huì)存在非隨機(jī)缺失,且數(shù)據(jù)缺失的比例較高,則需要對(duì)數(shù)據(jù)進(jìn)行敏感性分析(sensitivity analysis)(Carpenter,Kenward,&White,2007;Graham,Hofer,Donaldson,MacKinnon,&Schafer,1997;Jamshidian &Yuan,2013;Moreno-Betancur &Chavance,2016)。眾多方法學(xué)家建議研究者應(yīng)用不同的模型或方法對(duì)可能含有 MNAR機(jī)制缺失的數(shù)據(jù)進(jìn)行分析,檢查不同方法下結(jié)果的差異(Muthén et al.,2011)。結(jié)合本研究結(jié)果,建議對(duì)帶有缺失的數(shù)據(jù)分別采用MAR假設(shè)下方法(如ML方法)和 MNAR假設(shè)下的基于模型的方法(如 D-K選擇模型,模式混合模型等)進(jìn)行分析。
(5)將不同方法得到的結(jié)果進(jìn)行比較,結(jié)合模型擬合指標(biāo)(AIC,BIC,CAIC,BIC和DIC)選擇一個(gè)最合理的假設(shè)對(duì)其數(shù)據(jù)的分析結(jié)果進(jìn)行解釋說(shuō)明:如果結(jié)論在兩類方法間一致,則認(rèn)為選擇MAR下的分析結(jié)果進(jìn)行呈現(xiàn)也是可靠的;如果 MNAR假設(shè)下得到的結(jié)論與 MAR假設(shè)下的結(jié)論不一致,那么認(rèn)為MNAR下的結(jié)果更可信。
(6)即使是基于 MNAR機(jī)制的分析,也存在不同的模型,不同模型的假設(shè)和分析結(jié)果若存在較大差異,則需要根據(jù)理論的進(jìn)一步分析做出判斷。
6.3 研究局限性
本研究主要探討了MAR缺失機(jī)制假設(shè)下ML方法與MNAR缺失機(jī)制假設(shè)下D-K選擇模型的比較,對(duì)于追蹤研究中非隨機(jī)缺失數(shù)據(jù)假設(shè)下的處理模型有多個(gè)(如模式混合模型),并且這些模型也有不同程度的拓展。本研究未能就更多的 MNAR缺失機(jī)制下的處理方法進(jìn)行比較,在未來(lái)的研究中,可以進(jìn)一步比較用于處理 MNAR缺失機(jī)制的不同模型間的比較。另外,本研究基于簡(jiǎn)單的 LGM 模型,在后續(xù)研究中可以考慮更復(fù)雜的基本模型,如存在潛類別的混合增長(zhǎng)模型情境下,不同缺失值處理方法的比較。同時(shí),在估計(jì)方法上,也應(yīng)進(jìn)一步考慮更多的方法,如二階段ML方法和貝葉斯方法。
7 研究結(jié)論
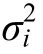
(3)永久缺失比例是影響模型參數(shù)估計(jì)精度的主要因素;樣本量增大會(huì)提高參數(shù)估計(jì)精度;偏態(tài)程度與永久缺失比例、偏態(tài)程度與樣本量之間存在一定的交互作用。
Albert,P.S.,&Follman,D.A.(2009).Shared-parameter models.In G.Fitzmaurice,M.Davidian,G.Verbeke,&G.Molenberghs (Eds.),Longitudinal data analysis
(pp.433?452).Boca Raton:Chapman &Hall/CRC Press.Beunckens,C.,Molenberghs,G.,Verbeke,G.,&Mallinckrodt,C.(2008).A latent-class mixture model for incomplete longitudinal Gaussian data.Biometrics,64
(1),96?105.Carpenter,J.R.,Kenward,M.G.,&White,I.R.(2007).Sensitivity analysis after multiple imputation under missing at random:A weighting approach.Statistical Methods in Medical Research,16
(3),259?275.Diggle,P.,&Kenward,M.G.(1994).Informative drop-out in longitudinal data analysis.Applied Statistics-Journal of the Royal Statistical Society Series C,43
(1),49?93.Dixon,W.J.(1988).BMDP statistical software manual:To accompany the 1988 software release
.California:University of California Press.Enders,C.K.(2011a).Analyzing longitudinal data with missing values.Rehabilitation Psychology,56
(4),267?288.Enders,C.K.(2011b).Missing not at random models for latent growth curve analyses.Psychological Methods,16
(1),1?16.Enders,C.K.(2010).Applied missing data analysis
.New York:The Guilford Press.Enders,C.K.,&Bandalos,D.L.(2001).The relative performance of full information maximum likelihood estimation for missing data in structural equation models.Structural Equation Modeling,8
(3),430?457.Glynn,R.J.,Laird,N.M.,&Rubin,D.B.(1986).Selection modeling versus mixture modeling with nonignorable nonresponse.In H.Wainer (Ed.),Drawing inferences from self-selected samples
(pp.115?142).New York:Springer.Graham,J.W.(2003).Adding missing-data-relevant variables to FIML-basedstructural equation models.Structural Equation Modeling,10
,80–100.Graham,J.W.,Hofer,S.M.,Donaldson,S.I.,MacKinnon,D.P.,&Schafer,J.L.(1997).Analysis with missing data in prevention research.In K.J.Bryant,M.Windle,&S.G.West (Eds.),The science of prevention:Methodological advances from alcohol and substance abuse research
(pp.325?366).Washington,DC,US:American Psychological Association.Headrick,T.C.,&Mugdadi,A.(2006).On simulating multivariate non-normal distributions from the generalized lambda distribution.Computational Statistics &Data Analysis,50
(11),3343?3353.Heckman,J.J.(1976).The common structure of statistical models of truncation,sample selection and limited dependent variables and a simple estimator for such models.Annals of Economic and Social Measurement,5
(4),475?492.Jamshidian,M.,&Yuan,K.H.(2013).Data-driven sensitivity analysis to detect missing data mechanism with applications to structural equation modelling.Journal of Statistical Computation and Simulation,83
,1344?1362.Little,R.J.A.(1988).A test of missing completely at random for multivariate data with missing values.Journal of the American Statistical Association,83
(404),1198?1202.Little,R.J.A.(1993).Pattern-mixture models for multivariate incomplete data.Journal of the American Statistical Association,88
(421),125?134.Little,R.J.A.(1995).Modeling the drop-out mechanism in repeated-measures studies.Journal of the American Statistical Association,90
(431),1112?1121.Little,R.J.A.,&Rubin,D.B.(2002).Statistical analysis with missing data
(2nd ed.).Hoboken,NJ:Wiley.Lu,Z.Q.,Zhang,Z.Y.,&Cohen A.(2013).Bayesian methods and model selection for latent growth curve models with missing data.In R.E.Millsap,L.A.van der Ark,D.M.Bolt,&C.M.Woods (Eds.),New developments in quantitative psychology
(pp.275?304).New York:Springer.Lu,Z.Q.,&Zhang,Z.Y.(2014).Robust growth mixture models with non-ignorable missingness:Models,estimation,selection,and application.Computational Statistics &Data Analysis,71
,220?240.McArdle,J.J.,&Epstein,D.(1987).Latent growth curves within developmental structural equation models.Child Development,58
,110?133.Meredith,W.,&Tisak,J.(1990).Latent curve analysis.Psychometrika,
55(1),107?122.Moreno-Betancur,M.,&Chavance,M.(2016).Sensitivity analysis of incomplete longitudinal data departing from the missing at random assumption:Methodology and application in a clinical trial with drop-outs.Statistical Methods in Medical Research,25
(4),1471–1489.Muthén,B.,&Masyn,K.(2005).Discrete-time survival mixture analysis.Journal of Educational and Behavioral Statistics,30
(1),27?58.Muthén,B.,Asparouhov,T.,Hunter,A.,&Leuchter,A.(2011).Growth modeling with non-ignorable dropout:Alternative analyses of the STAR*D antidepressant trial.Psychological
Methods,16
(1),17?33.Muthén,L.K.,&Muthén,B.O.(2007).Mplus user’s guide
(5th ed.).Los Angeles,CA:Muthén &Muthén.Power,R.A.,Muthén,B.,Henigsberg,N.,Mors,O.,Placentino,A.,Mendlewicz,J.,… Uher,R.(2012).Nonrandom dropout and the relative efficacy of escitalopram and nortriptyline in treating major depressive disorder.Journal of Psychiatric Research,46
(10),1333?1338.Rotnitzky,A.(2009).Inverse probability weighted methods.In G.Fitzmaurice,M.Davidian,G.Verbeke,&G.Molenberghs(Eds.),Longitudinal data analysis
(pp.453–476).Boca Raton,FL:Chapman &Hall.Roy,J.(2003).Modeling longitudinal data with nonignorable dropouts using a latent dropout class model.Biometrics,59
(4),829?836.Schafer,J.L.(2003).Multiple imputation in multivariate problems when the imputation and analysis models differ.Statistica Neerlandica,57
(1),19–35.Schafer,J.L.,&Graham,J.W.(2002).Missing data:Our view of the state of the art.Psychological Methods,7
(2),147?177.Shin,T.,Davison,M.L.,&Long,J.D.(2009).Effects of missing data methods in structural equation modeling with nonnormal longitudinal data.Structural Equation Modeling:A Multidisciplinary Journal,16
,70?98.Soullier,N.,de La Rochebrochard,E.,&Bouyer,J.(2010).Multiple imputation for estimation of an occurrence rate in cohorts with attrition and discrete follow-up time points:A simulation study.BMC Medical Research Methodology,10
,79.Wu,M.C.,&Carroll,R.J.(1988).Estimation and comparison of changes in the presence of informative right censoring by modeling the censoring process.Biometrics,44
(1),175?188.Ye,S.J.,Tang,W.Q.,Zhang,M.Q.,&Cao,W.C.(2014).Techniques for missing data in longitudinal studies and its application.Advances in Psychological Science,22
(12),1985?1994.[葉素靜,唐文清,張敏強(qiáng),曹魏聰.(2014).追蹤研究中缺失數(shù)據(jù)處理方法及應(yīng)用現(xiàn)狀分析.心理科學(xué)進(jìn)展,22
(12),1985?1994.]Yuan,K.H.,&Bentler,P.M.(2000).Three likelihood-based methods for mean and covariance structure analysis with nonnormal missing data.Sociological Methodology,30
(1),165?200.Yuan,K.H.,&Lu,L.(2008).SEM with missing data and unknown population distributions using two-stage ML:Theory and its application.Multivariate Behavioral Research,43
,621?652.Yuan,K.H.,Yang-Wallentin,F.,&Bentler,P.M.(2012).ML versus MI for missing data with violation of distribution conditions.Sociological Methods &Research,41
(4),598?629.Zhang,D.,&Willson,V.L.(2006).Comparing empirical power of multilevel structural equation models and hierarchical linear models:Understanding cross-level interactions.Structural Equation Modeling,13
(4),615?630.附錄1:ML方法的Monte Carlo 模擬的語(yǔ)句
TITLE:
ML-mnar-mar-n-40001000
DATA:
FILE=mnarmar40001000replist.dat; !指定每種模擬條件下的500個(gè)數(shù)據(jù)集文件名列表;
TYPE=MONTECARLO;!指定了分析類型為Monte Carlo模擬研究;
VARIABLE:
NAMES=m1-m5 y1-y5;
USEVARIABLES=y1-y5;
MISSING=ALL (999);
ANALYSIS:
ESTIMATOR=ML;
MODEL:
i s|y1@0 y2@1 y3@2 y4@3 y5@4;
i WITH s*0;
i*0.5 s*.02;
[i*-1 s*0.5];
y1*.5 y2*.48 y3*.42 y4*.32 y5*0.18;
SAVEDATA:
RESULTS are ml40201000results.dat;
附錄2: D-K 選擇模型的Monte Carlo 模擬的語(yǔ)句
TITLE:
DK-mnar-mar-n-40201000
DATA:
FILE=mnarmar40201000replist.dat;
TYPE=MONTECARLO;
VARIABLE:
NAMES=m1-m5 y1-y5;
USEVARIABLES=y1-y5 d2-d5;
MISSING=ALL (999);
CATEGORICAL=d2-d5;
DATA MISSING:
NAMES=y1-y5;
TYPE=SDROPOUT;
BINARY=d2-d5;
ANALYSIS:
ESTIMATOR=ML;
LINK=PROBIT;
ALGORITHM=INTEGRATION;
INTEGRATION=MONTECARLO;
PROCESSORS=2;
MODEL:
i s|y1@0 y2@1 y3@2 y4@3 y5@4;
i WITH s*0;
i*0.5 s*.02;
[i*-1 s*0.5];
y1*.5 y2*.48 y3*.42 y4*.32 y5*0.18;
[d2$1*1.1134 d3$1*1.3506 d4$1*1.5745 d5$1*1.7842 ];
d2 on y1*-0.5 (11)
y2*1 (12);
d3 on y2*-0.5 (11)
y3*1 (12);
d4 on y3*-0.5 (11)
y4*1 (12);
d5 on y4*-0.5 (11)
y5*1 (12);
SAVEDATA:
RESULTS are dk40201000results.dat;
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
中國(guó)衛(wèi)生(2015年9期)2015-11-10 03:11:12
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
中國(guó)衛(wèi)生(2014年3期)2014-11-12 13:18:12
