基于用戶評論的自動化音樂分類方法①
2018-02-07 02:41:42郝建林黃章進顧乃杰
計算機系統(tǒng)應用 2018年1期
郝建林,黃章進,顧乃杰
(中國科學技術大學 計算機科學與技術學院,合肥 230027)(中國科學技術大學 安徽省計算與通信重點實驗室,合肥 230027)(中國科學技術大學 先進技術研究院,合肥 230027)
1 系統(tǒng)概述
隨著多媒體技術的發(fā)展,音樂已經(jīng)發(fā)展成人們日常生活中必不可少的一部分.現(xiàn)有的音樂平臺,如網(wǎng)易云、蝦米、酷狗等為我們提供了更便捷的獲取音樂的途徑.但由于分類模型的限制,這些音樂平臺的音樂檢索方式仍局限于已有的音樂流派、藝術家、專輯等.用戶無法通過輸入個性化的內容檢索到期望的音樂列表.為了提高用戶的檢索體驗,則需要引入新的音樂分類模型.
現(xiàn)有的音樂分類模型主要從4個角度進行分類,分別為流派、情感、樂器、注解.
第一類為基于流派的音樂分類,這類方法將提取的音頻特征作為流派分類的依據(jù).Tzanetakis[1]提供了一個測試數(shù)據(jù)集,將1000首歌音頻分為10個對應的音樂流派.此后出現(xiàn)的ISMIR[2]和Dortmund[3]數(shù)據(jù)集為這類研究的衡量提供了基礎.Li等[4]提出了DWCHs模型,通過計算音頻的Daubechies小波系數(shù)的直方圖對音樂進行自動化分類.Lidy等人[5]發(fā)現(xiàn)了心理聲學變換對音頻特征提取的影響,使用兩個特征表示統(tǒng)計頻譜描述子和音樂韻律直方圖特征,提升了分類準確率.
第二類為基于情感的音樂分類方法,這類方法將音樂分成開心、傷心、感動等多個類別,主觀性較強,類別之間有交叉,沒有標準的測試數(shù)據(jù)集,模型間的對比較為困難.Yang等人[6]使用人工和軟件代理結合的方式確定音樂的情感類別,減少人類的主觀影響.Yang等人[7]嘗試對情感進行量化,建立美學情感中的評價值和喚起程度值平面,平面上點的位置對應不同的情感類別.
第三類為基于樂器的分類,這類方法為識別出音頻中使用的樂器種類,然后通過樂器種類對音樂進行分類.早期的樂器識別主要對一件樂器獨奏的音頻進行識別,比如Marques等人[8]基于高斯混合模型和SVM支持向量機、Agosfini等人[9]基于音頻的頻譜特征的樂器識別方法等.現(xiàn)在的研究方法已轉到對復調音樂中樂器的識別.Essid等人[10]利用概率距離對音頻進行分層聚簇,每層簇的中心對應一類樂器.
第四類為基于注解的分類,即為基于標簽的分類.此類方法為將音頻關聯(lián)相應的文本內容后,再用于音樂分類,最初由Slaney[11]提出.Wang等人[12]提出利用音頻和與音頻相關的社交信息將音樂關聯(lián)對應的標簽,再按照音樂標簽進行分類.
前三類為基于音頻的分類模型,第四類為基于文本和基于音頻的分類模型.基于流派的音樂分類,現(xiàn)已在各大平臺有了較為成熟的應用,但均沒有用于音樂檢索.基于情感的音樂分類,分類類別之間有交叉,分類界限模糊,故分類模型的建立難度較大.基于樂器的音樂分類,對于多樂器合成的音樂,難以準確的識別全部樂器.基于注解的音樂分類,其分類準確率依賴于獲取的音樂標簽的準確率.
考慮以下需求:用戶希望獲取某個音樂,但是對這個音樂不了解,通常會輸入一些相關的個性化描述來檢索期望的音樂.前三類分類模型的分類類別較為固定,難以用于個性化的用戶檢索需求.第四類分類模型在文本較為豐富的情況下,如果能精確的挖掘出于其中蘊含的音樂標簽,那么用戶的個性化檢索需求就更可能得到滿足.
本文為基于注解的音樂分類方法,通過分析用戶對音樂的評論信息,提出了一種使用個性化標簽對音樂進行分類的方法.該方法的出發(fā)點為:如果用戶對音樂的較為熟悉,那么當其對音樂進行評論時,其對音樂的描述將更加的深入.這些評論內容中將含有較多個性化的信息.只要將這些信息挖掘出來,將對個性化音樂檢索和音樂推薦帶來更好的用戶體驗.該方法采用無監(jiān)督的方式為音樂關聯(lián)多個標簽,以這些標簽進行音樂分類,無需預先對音樂進行標簽標注.
本文的組織結構如下:第2節(jié)介紹了該音樂分類算法的相關背景;第3節(jié)介紹提出的音樂分類算法的具體框架和實現(xiàn);第4節(jié)為實驗與分析;第5節(jié)對本文進行總結和下一步展望.
2 理論分析
2.1 標簽提取
該音樂分類算法的核心為關聯(lián)標簽的提取.關聯(lián)標簽提取過程即為關鍵詞的抽取過程.關鍵詞提取主要包括關鍵詞抽取和關鍵詞分配兩種方式.
關鍵詞抽取,先提取文檔中所有的候選關鍵詞再推薦關鍵詞.此類方式需要分詞并選擇合適的抽取方法.抽取方法有很多,如 TFIDF[13,14]、TextRank[15]等.
關鍵詞分配,先預先定義一個受控詞表,然后分析文檔,再推薦受控詞表中的部分關鍵詞.此種方式需要定義并擴充受控詞表,然后選擇分配算法.詞表擴充的方式一般采用種子擴充.
一般來說,關鍵詞抽取要比關鍵詞分配的提取準確率要高,主要原因在于建立完善的受控詞表難度較大,并且分配的關鍵詞可能不會出現(xiàn)在文檔中,分配算法的準確率難以保證.因此,本文的音樂分類方法中采用關鍵詞抽取的方式獲取音樂標簽.
2.2 中文分詞
現(xiàn)有使用的中文分詞方法主要可以分為三類:基于匹配、基于統(tǒng)計和基于社交網(wǎng)絡的分詞.
基于字符串匹配的分詞方法是將漢字串與詞典中的詞條做匹配,在匹配過程中可以加入匹配規(guī)則.分詞方法包括:正向最大匹配(FMM)、逆向最大匹配(RMM)、MMSEG[16]等.該類分詞模型的準確率依賴于字典的豐富程度.
基于統(tǒng)計的分詞模型從詞頻出發(fā)進行分詞,包括linear CRF模型[17]、隱馬爾科夫模型[18],等.該類模型準確率依賴于標注語料的豐富程度.
基于社交網(wǎng)絡的分詞模型是在n元取詞的基礎上進行分詞.其核心在于分析n元串成詞的可能性,通常使用緊密度分析判定.該類模型準確率依賴于緊密度分析方法和語料的豐富程度.
本文的分詞方法綜合了三類分詞模型的優(yōu)點,使用N元取詞方法和linear CRF進行字典擴充,然后使用linear CRF進行分詞,MMSEG和緊密度分析進行分詞修正.
3 音樂分類算法
本文提出的音樂分類方法主要分為以下幾個部分,如圖1所示.
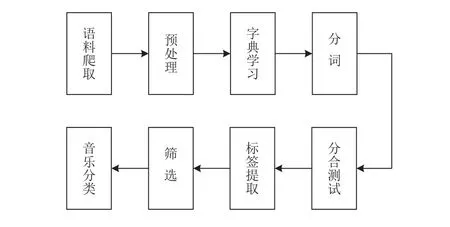
圖1 音樂分類算法框架
預處理為刪除一些無用的音樂評論信息,減少對后續(xù)處理過程的干擾.字典學習是為了得到一個適合音樂語料分詞的字典,提高分詞準確率.分詞是將音樂語料切分成單個詞語,以便提取音樂標簽.分合測試是用來修正誤分詞結果,同時提高對短語的識別率.標簽提取是為了從分詞結果中選取與音樂相關的候選標簽.篩選的目的為過濾掉一些可能錯選的音樂標簽.最后使用關聯(lián)的標簽為音樂進行分類.
3.1 語料爬取和預處理
本文爬取的音樂評論語料為網(wǎng)易云音樂平臺(國內最大的音樂平臺)官方推薦專輯中的音樂評論,共1459個專輯,128 542首歌曲,92 110 590條評論.
對音樂評論語料按以下步驟進行預處理:
1)含有臟話的評論參考價值較低,所以將含有臟話的評論刪除.
2)數(shù)字大多沒有實際意義,所以將數(shù)字“233”、“666”等用空格代替,對只含有數(shù)字的評論直接刪除.
3)表情符一般表示心情,但是表情符過于多樣,例如,網(wǎng)易云音樂自帶表情和emoji表情編碼方式不同,統(tǒng)一混用在評論中識別難度較大.因此將表情符用空格代替.將只含有表情符的評論刪除.
4)過多的重復評論會也會影響提取的音樂標簽的準確率.例如,一個音樂的評論中含有較多的“路過”,則“路過”很可能成為關鍵詞,但是這種詞應該忽略.為防止誤判,相同的評論中保留一條.
5)刪除評論內容較少的音樂,評論內容過少則評論可參考性較低.
6)刪除評論數(shù)過少的音樂,評論數(shù)過少則評論的范圍過于分散,提取的音樂標簽可信度較低.
3.2 字典學習
字典學習首先通過外部信息獲取部分詞匯,然后以種子生成的思想擴充字典,如圖2所示.
具體步驟如下:
1)從1998年和2014年的人民日報中文語料以及微軟的中文分詞標注語料庫中提取部分詞語,然后爬取百度百科和搜狗詞庫中的常用詞匯加入到參照詞典D’.對于中國自然語言開源組織提供的8萬多部小說,使用ansj分詞工具進行分詞,選出詞頻頻率高于閾值α的詞匯加入到參照字典D’中.
2)先使用n元分詞對音樂語料做處理,獲取所有的2字和3字詞串.先使用緊密度分析,過濾掉明顯不是詞的串.找出剩余在參照字典D′中的詞,加入到字典D中.
3)基于上述獲得的字典D,統(tǒng)計其中每個詞出現(xiàn)的頻數(shù).然后建立用于linear CRF學習模型的標注語料.最后用linear CRF學習后的模型進行分詞.
4)過濾掉詞頻低的詞匯、非專有名詞和單字.對剩余切分詞語進行緊密度分析.如果詞語緊密度高于閾值β,則加入字典D.
5)重復步驟3,4,直至字典D不再增大.
α和β值的確定可以通過k-means(k=2)算法聚類確定.
關于音樂標簽,我們關注的詞性主要是一些專有名詞或者名詞性短語,比如人名、地名、歌曲名、專輯名、電影名、書名等,而不關注其他的詞性,故需要盡量確保分詞結果中所關注詞性的詞語的正確性.可以預先根據(jù)它們在評論語料中出現(xiàn)的特點,按特定的規(guī)則進行抽取,加入字典D.

圖2 字典學習算法
3.3 音樂語料分詞
本文在使用過程中采用linear CRF和字典相結合的方式進行中文分詞.
由于linear CRF模型分詞的準確率依賴于標注語料的規(guī)模和豐富程度,適合音樂語料分詞的標注語料并不存在,因此使用3.2節(jié)獲取的字典D進行l(wèi)inear CRF模型的訓練,使用Viterbi算法進行標注.其分詞設置的獲取特征函數(shù)的特征模板如圖3所示.

圖3 linear CRF特征函數(shù)模板
3.4 分合測試
分詞后的結果對存在于字典中的詞相對準確,對于不存在的詞需要進行分離,對于分開的短語需要合并.在此,使用聚合度判定被切分為詞語的漢字串是否應該分離,使用自由度判定多個詞語是否應該合并.
聚合度(Degree of Polymerization,DoP)用來衡量詞語內部組合的緊密程度.字串w的聚合度用其中字ai的方差表示,具體如公式(1)所示.

自由度(Degree of Freedom,DoF)來衡量詞語和上下文之間的關系.此關系用該詞左右的字的豐富程度來衡量.字串w的自由度由其左邊字li和右邊字ri的熵確定,具體如公式(2)所示.

綜合考慮詞頻、聚合度和自由度,得到分合測試的衡量方法,如公式(3)所示.詞頻取對數(shù)是為了處理詞頻過大而無法拆分的偽詞匯.

對于未通過分合測試的句子使用MMSEG模型進行修正處理.
3.5 標簽提取
標簽提取類似于關鍵詞提取,從音樂的評論語料中提取與之關聯(lián)程度最高的一個或者多個詞或短語.
在3.4節(jié)分詞后得到的詞頻統(tǒng)計結果,其TopN可能并不是我們所需要的音樂標簽.下面取出周杰倫的歌曲“晴天”的分詞結果中詞頻Top 20進行分析,如表1所示.左側是Top 10 頻數(shù)的詞語,右側為Top 11到Top 20的結果.

表1 歌曲晴天評論分詞結果Top 20
對比關鍵詞抽取算法,實驗發(fā)現(xiàn)TFIDF算法抽取標簽準確率最高,故選取TFIDF算法.TFIDF算法如公式(4)所示.

在實驗過程中,直接使用TFIDF并不能急速降低表1中“評論”、“個人”這類詞匯被選中的可能性,原因為log函數(shù)在n>1時變化率太低.
2型糖尿病患者外周血液指標的變化及其與頸動脈硬化的相關性…………………… 趙梁燕 高倩 陳將南 等(3)360
故為模型選擇變化率大的函數(shù)或對詞匯的特點做一些限制來過濾掉這些無用的詞匯.
根據(jù)標簽的特性做以下兩個假設:
假設一.一個標簽出現(xiàn)的頻率在音樂評論中不能低于音樂評論總數(shù)的α倍,0<α<1.
假設二.一個標簽關聯(lián)的音樂數(shù)量不能超過音樂總數(shù)的β倍,0<β<1.
假設一是為了降低詞頻過低的詞語被選為標簽的可能性.例如,“劉德華”在音樂“狂風里擁抱”中出現(xiàn)了一次,出現(xiàn)的內容為“@Andy不是劉德華”,該詞不可能作為標簽.但是由于其在較多的音樂評論中出現(xiàn),導致逆文檔頻率較大,容易被誤選為標簽.為降低這種誤選的可能性,因此使用假設一過濾.
假設二是為了降低詞頻過高的常用詞被選為標簽的可能性.例如,“評論”在音樂“晴天”中出現(xiàn)了63 242次,共出現(xiàn)在89 297首音樂的評論中,這類的TFIDF值過大,會被誤選為標簽.顯然,其不應該作為音樂標簽,需要過濾掉.為降低這種詞被誤選的可能性,因此使用假設二進行過濾.
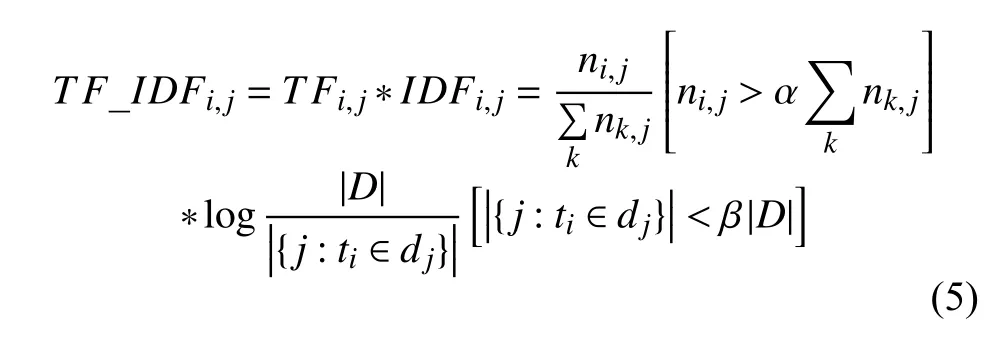
α和β值的確定可以通過k-means(k=2)算法聚類確定.
優(yōu)化后的TFIDF降低了常用詞匯被選中的概率,提高了其它詞匯被選中的概率.優(yōu)化后的TFIDF得到的候選標簽,如表2所示.
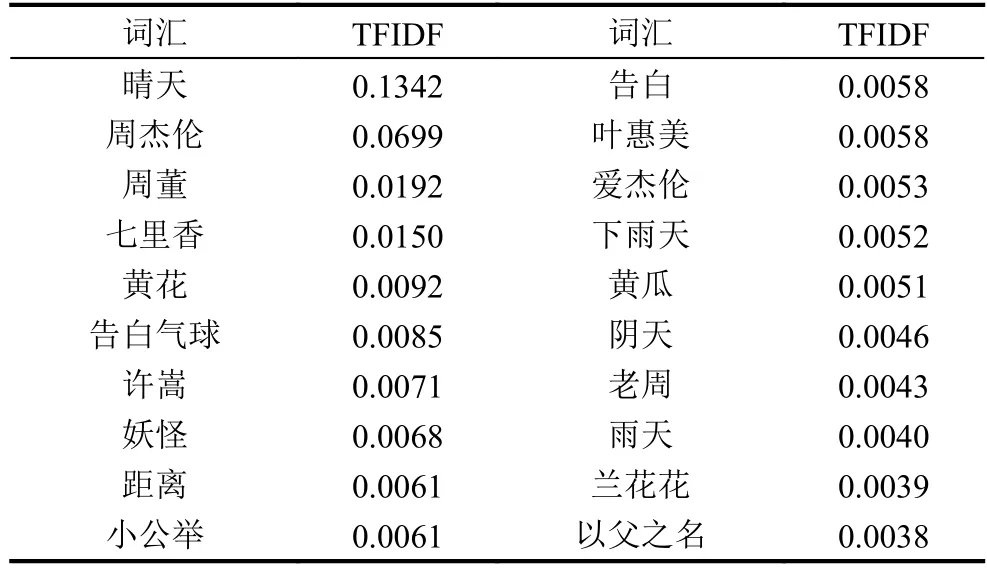
表2 優(yōu)化后TFIDF得到的候選標簽Top 20
3.6 標簽篩選
由于優(yōu)化后的TFIDF算法獲取的候選標簽可能出現(xiàn)提取的標簽依然出錯的情況.因此,考慮刪除這些錯誤的標簽.
由于每個標簽不可能只出現(xiàn)γ個文檔,γ為0鄰域范圍內的值.因此可以將出現(xiàn)的文檔數(shù)小于γ的標簽全部刪除.γ值依然可以通過k-means(k=2)獲取.
3.7 音樂分類模型
在此建立音樂和關聯(lián)標簽的網(wǎng)絡模型.圖4給出了一個n標簽關聯(lián)的網(wǎng)絡,音樂Si用正方形表示,標簽用 圓形表示,音樂Si和標簽的關聯(lián)程度用邊上的權值表示,可以通過標簽頻數(shù)歸一化得到.
使用公式(6)進行相似度分析,如果相似度高于某個閾值,則認為兩首歌曲可以歸為一類.



圖4 音樂分類概率網(wǎng)絡
4 實驗和分析
本節(jié)將對第3節(jié)中提出的分類算法進行實驗.實驗一是為了驗證MMSEG、HMM、CRF模型分詞效果的優(yōu)劣.實驗二是為了選取合適關鍵詞抽取算法并驗證其優(yōu)化算法的有效性.實驗三是為了驗證該音樂分類算法分類結果的有效性.
4.1 分詞模型準確率對比
選取9首歌曲23614條評論內容作為樣本,對其進行分詞標注.各種模型的分詞準確率如圖5所示.

圖5 分詞模型準確率對比
從圖5中可以看出MMSEG模型由于通用字典的局限性,導致其對人名的識別率不高,遠低于HMM模型和我們的混合模型.由于不存在用于音樂語料的標注集合,HMM模型未加入訓練樣本直接進行分詞,導致分出的單字較多,因此對其它詞語切分準確率略差.使用MMSEG+linear CRF+字典的分詞結果,其綜合了MMSEG消除歧義的特點和linear CRF發(fā)現(xiàn)未登錄詞的特點.詞典的創(chuàng)建和分合測試提高了分詞的準確率,同時減小了linear CRF出現(xiàn)單字的可能性,因此其準確率均比MMSEG和HMM模型都高.
4.2 標簽提取算法對比
使用TFIDF算法和TextRank算法進行關鍵詞抽取實驗,實驗數(shù)據(jù)選用 “周星馳版唐伯虎點秋香”背景音樂“勇往直前”的評論語料.結果如表3所示.可以看出,TFIDF獲取的標簽的關聯(lián)程度遠高于TextRank.

表3 TextRank和our TFIDF候選標簽Top 10對比
為了進一步驗證優(yōu)化方案的有效性,隨機取10首音樂,每首音樂選取候選標簽的Top 10進行準確率標注,10首音樂標簽準確率按評論數(shù)做加權平均,實驗結果如圖6所示.

圖6 標簽提取算法準確率對比
容易看出,優(yōu)化后的TFIDF算法的標簽提取準確率要比TFIDF和TextRank都高.TFIDF參考了其它音樂評論抽取的結果,雖然不能過濾掉所有頻數(shù)過高的常用詞語,但是能過濾掉部分.TextRank由于沒有停用詞典,其抽取結果偏向于高頻詞匯.優(yōu)化后的TFIDF考慮到高頻詞和逆文檔詞頻之間的影響,因此,對高頻詞和低頻詞的過濾效果較好.
4.3 音樂分類結果對比
對最初爬取66 198首歌曲,再次爬取這些歌曲在網(wǎng)易云音樂平臺推薦的相似音樂.得到一個相似音樂表T,共189 625條相似記錄.由于網(wǎng)易云音樂的推薦列表基于大量的用戶數(shù)據(jù),可以認為其推薦的音樂可信度較高.如果將相似的音樂可以分為一類,過濾掉其中不屬于已爬取的音樂列表中的音樂,那么相似音樂表T就可以作為音樂分類標準測試集.
相似音樂表中每個音樂取TopN標簽,建立圖4所示的音樂分類概率網(wǎng)絡,使用公式6做相似度分析,測試算法分類準確率.對比HiSVM[12]分類結果,如圖7所示.
從圖7中可以看出算法的在標簽數(shù)在25后準確率逐步穩(wěn)定,最終穩(wěn)定在87.96%.實驗表明,關聯(lián)標簽數(shù)量低于20時,關聯(lián)準確率高于80%,因此認為Top 20標簽可信度較高.而在標簽數(shù)為20時,分類結果的準確率在82.58%,而HiSVM的準確率不足60%.因此,可以認為該音樂分類算法具有很高的有效性.
5 結語
針對當前音樂平臺音樂分類結果固定單一、搜索平臺搜索效果差的問題,本文提出了一種基于用戶評論的自動化音樂分類算法.該算法優(yōu)化了已有的分詞模型和關鍵詞提取算法TFIDF,提升了分詞的準確率和關鍵詞提取算法的準確率,建立了基于關聯(lián)標簽的多標簽音樂分類模型.實驗結果表明,該音樂分類算法的準確率較高,獲取的標簽關聯(lián)度高而且更加個性化,可以帶來更好的音樂檢索體驗.
本文下一步工作為解決音樂評論過少或不存在的音樂分類問題,以提高該分類算法的擴展性.
1 Tzanetakis G,Cook P.Musical genre classification of audio signals.IEEE Transactions on Speech and Audio Processing,2002,10(5):293–302.[doi:10.1109/TSA.2002.800560]
2 Cano P,Gómez E,Gouyon F,et al.ISMIR 2004 audio description contest.MTG-TR-2006-02,Stanford,CA:MTG,2006.
3 Homburg H,Mierswa I,M?ller B,et al.A benchmark dataset for audio classification and clustering.Proceedings of the 6th International Conference on Music Information Retrieval.London,UK.2005.528–531.
4 Li T,Ogihara M,Li Q.A comparative study on contentbased music genre classification.Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval.Toronto,Canada.2003.282–289.
5 Lidy T,Rauber A.Evaluation of feature extractors and psycho-acoustic transformations for music genre classification.Proceedings of the 6th International Conference on Music Information Retrieva.London,UK.2005.34–41.
6 Yang D,Lee WS.Disambiguating music emotion using software agents.Proceedings of the 5th International Conference on Music Information Retrieval.Barcelona,Spain.2004.218–223.
7 Yang YH,Lin YC,Su YF,et al.A regression approach to music emotion recognition.IEEE Transactions on Audio,Speech,and Language Processing,2008,16(2):448–457.[doi:10.1109/TASL.2007.911513]
8 Marques J,Moreno PJ.A study of musical instrument classification using gaussian mixture models and support vector machines.CRL 99/4,Cambridge,Massachusetts:Compaq Computer Corporation,1999.
9 Agostini G,Longari M,Pollastri E.Musical instrument timbres classification with spectral features.EURASIP Journal on Applied Signal Processing,2003,(2003):5–14.[doi:10.1155/S1110865703210118]
10 Essid S,Richard G,David B.Instrument recognition in polyphonic music based on automatic taxonomies.IEEE Transactions on Audio,Speech,and Language Processing,2006,14(1):68–80.[doi:10.1109/TSA.2005.860351]
11 Slaney M.Semantic-audio retrieval.2002 IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP).Orlando,FL,USA.2002.IV-4108–IV-4111.
12 Wang F,Wang X,Shao B,et al.Tag integrated multi-label music style classification with hypergraph.Proceedings of the 10th International Society for Music Information Retrieval Conference.Kobe,Japan.2009.363–368.
13 Luhn HP.A statistical approach to mechanized encoding and searching of literary information.IBM Journal of Research and Development,1957,1(4):309–317.[doi:10.1147/rd.14.0309]
14 Jones SK.A statistical interpretation of term specificity and its application in retrieval.Journal of Documentation,1972,28(1):11–21.[doi:10.1108/eb026526]
15 Mihalcea R,Tarau P.TextRank:Bringing order into texts.Proceedings of Empirical Methods in Natural Language Processing.Barcelona,Spain.2004.404–411.
16 Tsai CH.MMSEG:A word identification system for Mandarin Chinese text based on two variants of the maximum matching algorithm. http://www.geocities.com/hao510/mmseg.html [2000-03-12].
17 Tseng H,Chang PC,Andrew G,et al.A conditional random field word segmenter for sighan bakeoff 2005.Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing.Jeju Island,Korea.2005.161–164.
18 Eddy SR.Hidden markov models.Current Opinion in Structural Biology,1996,6(3):361–365.[doi:10.1016/S0959-440X(96)80056-X]
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
兒童繪本(2017年24期)2018-01-07 15:51:37
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
東方藝術·大家(2016年6期)2016-09-05 07:30:56
