主題模型在檢索結(jié)果聚類(lèi)中的應(yīng)用
2018-02-12 12:24:56蔣宗禮趙思露
軟件導(dǎo)刊
2018年12期
蔣宗禮 趙思露


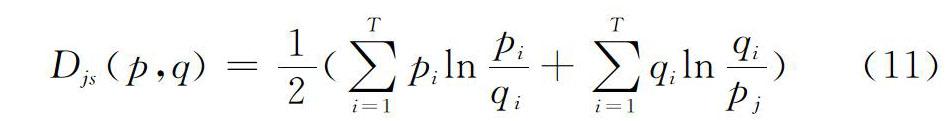
摘要:檢索結(jié)果聚類(lèi)能夠有效幫助提高獲取信息的效率和質(zhì)量。針對(duì)傳統(tǒng)文本聚類(lèi)模型存在數(shù)據(jù)維數(shù)過(guò)高、缺乏語(yǔ)義理解等問(wèn)題,提出一種面向檢索結(jié)果聚類(lèi)的融合共現(xiàn)分析主題建模算法。基于改進(jìn)的LDA模型,對(duì)得到的“文檔-主題”概率分布進(jìn)行聚類(lèi)分析,采用K-means算法完成聚類(lèi)過(guò)程,最后提出根據(jù)聚類(lèi)中心提取主題詞作為類(lèi)簇標(biāo)簽。實(shí)驗(yàn)結(jié)果表明,改進(jìn)的LDA算法在檢索結(jié)果聚類(lèi)應(yīng)用上不僅獲得了很好的聚類(lèi)效果,類(lèi)簇標(biāo)簽也有良好的可讀性。
關(guān)鍵詞:LDA;共現(xiàn)分析;檢索結(jié)果聚類(lèi);類(lèi)簇標(biāo)簽
Research on Application of Topic Model in Clustering Search Results
JIANG Zong?li,ZHAO Si?lu
(Faculty of Information Technology,Beijing University of Technology,Beijing 100124,China)
Abstract:The clustering of search results can effectively help improve the efficiency and quality of information retrieval. Aiming at the problems of traditional data clustering models such as high data dimension and lack of semantic understanding, this paper proposes a fusion co?occurrence analysis topic modeling algorithm oriented to the retrieval of results clustering.Based on the improved LDA model, the obtained “document?subject” probability distribution is clustered, the K?means algorithm is used to complete the clustering process, and finally the clustering center is used to extract topic words as cluster?like tags. The experimental results show that the improved LDA algorithm not only has a good clustering effect on the clustering of search results, but also has a good readability of cluster labels.
Key Words:LDA;co?occurrence analysis;clustering of search results;cluster label
0?引言
網(wǎng)絡(luò)資源的不斷增長(zhǎng)使檢索得到的返回結(jié)果數(shù)量龐大,而且根據(jù)檢索相關(guān)性算法與排序算法的不同,返回的結(jié)果也具有一定差異性。檢索結(jié)果聚類(lèi)可以對(duì)得到的檢索結(jié)果進(jìn)行挖掘與組織,對(duì)信息進(jìn)行合理總結(jié)與描述,從而有效提高了用戶獲取信息的效率和質(zhì)量。它通過(guò)聚類(lèi)技術(shù)將檢索結(jié)果依據(jù)主題相似性劃分到不同類(lèi)簇,并提供類(lèi)簇標(biāo)簽,使用戶根據(jù)標(biāo)簽快速、準(zhǔn)確定位到感興趣信息所在的類(lèi)別[1]。其主要有以下3個(gè)特征:①檢索結(jié)果聚類(lèi)不僅需要得到高質(zhì)量的類(lèi)簇,還需要描述每個(gè)類(lèi)簇主題的可讀標(biāo)簽;②檢索結(jié)果聚類(lèi)有許多可利用的信息,例如查詢?cè)~信息、相關(guān)文檔集信息等;③檢索結(jié)果集本身就是一個(gè)以查詢?cè)~為主題的大類(lèi)簇,聚類(lèi)后的類(lèi)簇為查詢?cè)~相關(guān)子主題的類(lèi)簇。
傳統(tǒng)基于VSM的聚類(lèi)分析方法由于沒(méi)有考慮文本中潛在的語(yǔ)義關(guān)聯(lián),不僅聚類(lèi)效果受到限制,也使得到的類(lèi)簇標(biāo)簽可讀性差。……
登錄APP查看全文
