基于電化學機理模型的鋰離子電池參數辨識及SOC 估計
2018-02-25 05:43:56鄧忠偉李冬冬蔡亦山羌嘉曦
上海理工大學學報 2018年6期
鄧 昊,楊 林,鄧忠偉,李冬冬,楊 洋,蔡亦山,羌嘉曦
(1.上海交通大學 機械與動力工程學院,上海 200240;2.上海凌翼動力科技有限公司,上海 200240)
電動汽車已成為國內外汽車科技發展的重點。如何準確估計SOC(電池電量),是電動汽車發展中亟待解決的關鍵問題。現有的SOC 估計方法,除基于完全依賴實驗數據的數據模型外,主要基于等效電路模型(ECM),其具有模型簡單、計算方便的優點[1-2]。但數據模型的實驗工作量大、難于全覆蓋電池在電動汽車等應用的全部工況,等效電路模型亦屬于經驗模型,不能體現電池實際的物理參數,因而無法描述電池內部的電化學行為與物理特性。相比而言,電化學機理模型(如P2D,pseudo-two-dimensional)[3]是根據電池內部機理建立電化學動力和傳輸方程組,因此,可以更準確地描述電池的運行狀態、健康狀態,提高了電池SOC 估計的準確性。但P2D 模型的控制方程[4]之間的耦合程度高、計算量大。需要對P2D 模型進行合理簡化,才能用于電池管理系統(BMS)等實時應用中。而簡化后的SP2D(simple pseudo-twodimensional)模型仍然參數過多[5-6],且各參數對電池輸出電壓的敏感度不同,難以準確辨識全部參數,因而依然難以解決SOC 在線估計的問題。
本文將在簡化P2D 模型(SP2D)的基礎上,提出基于模型參數可辨識性分析的最優辨識參數組及參數辨識方法,解決參數辨識問題;進而研究基于SP2D 的SOC 自適應卡爾曼濾波(adaptive extended Kalman filter,AEKF)估計算法,實現對SOC 的準確在線估計;并通過對某款車用磷酸鐵鋰電池(容量為94 AH,具體參數由電池生產企業提供,如表1 所示)的實驗,對比基于ECM 和SP2D 兩種模型的SOC 估計方法,驗證本文方法的有效性。θ 為電荷比。

表1 實驗電池參數Tab.1 Parameters of the experimental battery
1 鋰離子電池電化學機理模型SP2D
電池P2D 模型由4 個偏微分方程和1 個代數方程組成[7]。分析表明,簡化P2D 模型中液相濃度、固相表面濃度和反應電流的計算,是簡化P2D 模型的關鍵。為此,在SP2D 模型中分別利用了多項式近似的方法來計算這3 項的分布(表2)。圖1 是模型的坐標基準。Lp為電池正極部分的長度;Ls為隔膜部分的長度。在表2 中,液相濃度ce由式(1)表示,通過對式(2)進行離散化,迭代求解液相濃度積分Qe,n[6],得到每一個時刻液相濃度 ce的 分布。反應電流 jf用三階多項式(式(3))近似求得,通過取式(4)在y=0,, Ln時[5]建立的3 個方程迭代求解。其中,y 為電池各部分相應的位置坐標,Ln為電池負極部分的長度, κeff為有效液相電導率,σeff為有效固相電導率。考慮到電極的多孔性,取Bruggeman 系數得 κeff=κε1e.5,σeff=σε1s.5。固相表面濃度采用PP 方法(曲線近似方法)[7],將粒子固相濃度 cs以多項式(6)近似求得,通過表面濃度 cs,sur,平均濃度 cs以 及體積平均濃度流 q 建立式(7)來求解得到。由于這3 個參數只和反應電流 jf有關,因此,代入 jf即可以得到固相表面濃度cs,sur的分布。表2 中的公式只給出了負極部分這3 個分布的求解方法,正極與隔膜部分的求解方法與此類似。 ?s(y),?e(y),U(y)分別為固相電勢、液相電勢、平衡電勢,T 為絕對溫度,F 為法拉第常數,De,n,eff為有效液相擴散系數,R 為粒子半徑,I 為電流,I0為反應電流密度。

圖1 模型坐標基準Fig.1 Model coordinate baseline

表2 電化學機理SP2D 模型方程Tab.2 Equations of the electrochemical SP2D model
電池SP2D 模型的電壓輸出由式(8)表示[6],式中,第1 部分為平衡電勢引起的壓降,第2 部分為過電勢引起的壓降,第3 部分為電解液電勢引起的壓降,第4 部分為SEI 膜的反應電流(固體電解質界面膜)引起的壓降。其中:由 jf分布可以得到式(8)的第2,4 部分;由固相表面濃度 cs,sur代入式(5),可以得到方程的第1 部分;利用 jf和ce可求得方程的第3 部分。
基于該簡化模型,可以解除P2D 控制方程間的高度耦合,減少模型計算量。在仿真步長為1 s,工況采用美國聯邦城市標準(Federal Urban Driving Schedule,FUDS),循環時間7 500 s 下,P2D 模 型 計 算 時 間 為357 s,而SP2D 只 需 要4.7 s,計算時間大大縮短,僅為P2D 模型的1.3%。如按單步計算,則SP2D 每步計算僅需0.63 ms,模型本身可以滿足BMS(電池管理系統)實時應用的要求。
2 模型參數敏感度分析及辨識
2.1 Fisher 信息矩陣和準則數RDE
參數辨識的準確性直接影響模型的精度。由于SP2D 模型中的參數有30 多個(表1),除去容易辨識的參數后也多達17 個(表3 中參數組A-A,記為Par17)。Rint為電池的內阻。研究表明,這些參數對電池電壓的敏感度差異較大,難以同時辨識所有參數。因此,本文使用Fisher 信息矩陣進行參數可辨識性分析,并對分析出的最優辨識參數組進行辨識,解決模型參數辨識的準確性問題。
假定電池模型輸出電壓 V 和模型參數的關系符合正態分布,可得式(9)。其中,Ψ ,Z 為正態分布的期望值和方差, Par為模型參數組向量,t 為時間,概率密度

進一步得參數組向量 Par下 輸出 V的概率,即聯合概率密度P(式(10))。為求解方便,將P 寫成對數形式,從而將連乘和指數消除。

表3 參數敏感度排序表Tab.3 Parameters sensitivity list

Fisher 信息矩陣是有關P 的期望,可由式(11)表示。根據文獻[8]可進一步得到式(12)。可見,Fisher 信息矩陣的值 FIM越大,說明P 越大,輸出V的概率越大,表明對該參數組的辨識結果越可靠。

文獻[8?9]給出了判斷可辨識性的RDE 準則(使得參數組出現概率最大化的計算準則)。

式中:Si為相對敏感度; ∥Par∥2為歐式2 范數,用于將參數向量 X歸一化,消除不同參數的不同數量級對RDE 的影響;分子為FIM 矩陣的行列式值D 和 ∥Par∥2的 乘 積;分 母 為FIM 矩 陣 的 條 件 數mod E,由矩陣的最大特征值與最小特征值的比值得出,用于判斷參數之間的相關性。
當D 越大,mod E越小,即RDE 越大時,獲得的辨識參數組越優。
參數敏感性分析步驟如圖2 所示,首先排除表1 中的電池尺寸參數 L , A,以及其他容易獲得的 參 數 θ0,θ100,σ,k 和 α。將SP2D 模 型 中 剩 余的17 個參數(對應A-A 中的參數)隨機組合進行計算。K 為卡爾曼增益系數,S 為電池電量。圖3 是以不同參數為基參數的參數組的RDE。可見,不論以哪個參數為基參數,隨著參數數量的增加,RDE 均呈先增大再減小,且在10 個參數數量時達到最大。以RDE 最大的參數組為最優參數組,即表3 中的參數組B-B。在表3 中,參數組C-C 為辨識性差的參數組。
2.2 參數辨識
根據參數可辨識性分析結果,對最優辨識參數組B-B 采用非線性最小二乘法進行辨識,式(14)為目標函數。其中, Vm為電池模型輸出的電壓,Vref為參考電壓, J為雅可比矩陣。利用預測電壓和參考電壓的誤差修正參數,式(15)為誤差修正的迭代公式。
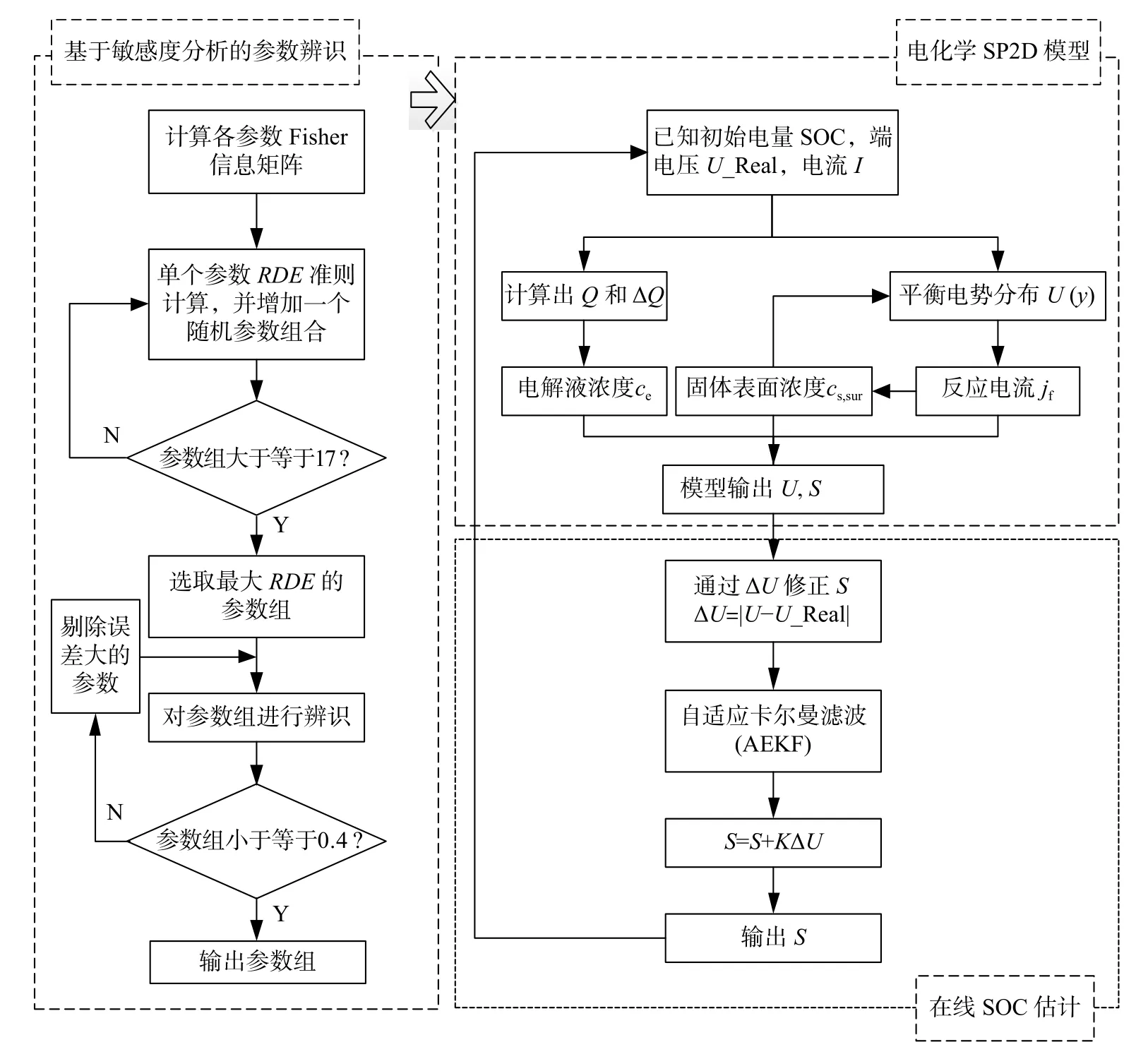
圖2 基于SP2D 模型的SOC 估計策略Fig.2 SOC estimation strategy based on the SP2D model
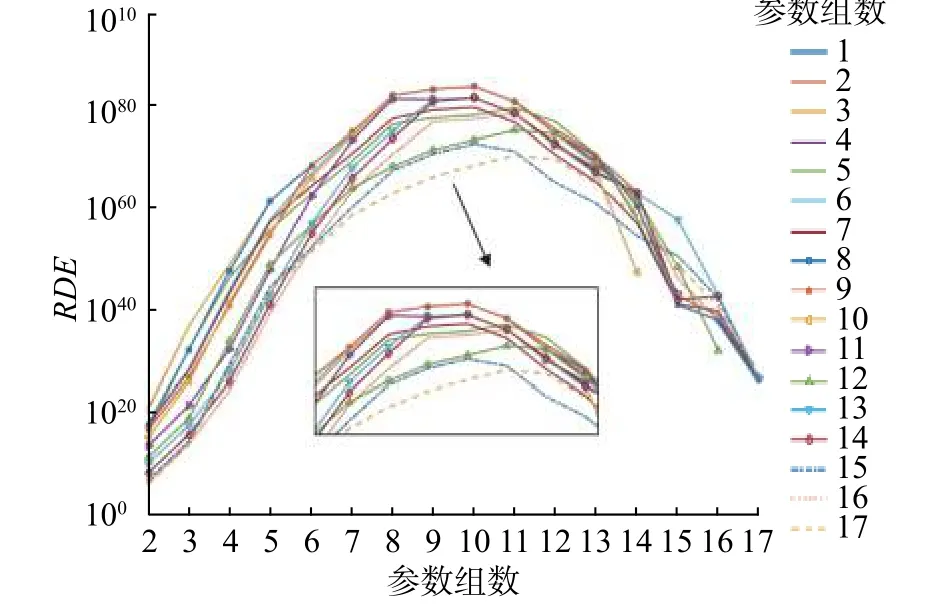
圖3 參數組敏感度分析Fig.3 Parameters sensitivity analysis
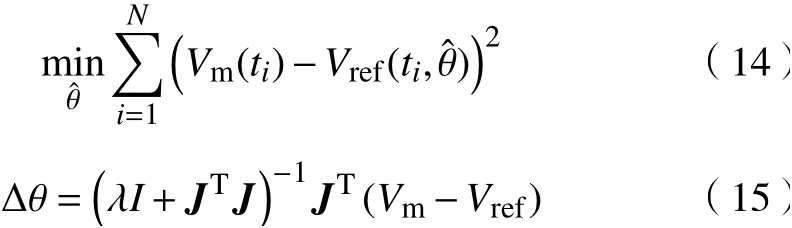
式中: ?θ為 誤差修正量; λ為時間步長。
假定表1 中的參數值為真值,可將SP2D 模型在真值參數下的輸出電壓作為參考電壓。這里為了單純驗證本文的參數辨識方法,人為使參數組B-B 中待辨識參數存在明顯誤差,將其初值設為真值的5 倍(記為 Pare)。選擇FUDS 工況下,對2 個相同的SP2D 模型進行比較。考慮到本文中的電池為鋰離子電池,在放電中期存在電壓平臺,可辨識性較差,因此,宜選取放電初期或充電初期(本文選擇測試工況的前1 200 s,初始S=1)進行參數辨識。
為了闡述方便,將最優參數組B-B 表示為向量 Par10=[ εe,p, εe,s, kp, Ds,n, kn, ce,0, cs,max,n, Ds,p, Rint,De]。辨識策略,如圖2 所示,辨識結果如圖4 所示。圖4(a),4(b),4(c),4(d)分別對應向量Par10 ,Par9(去 掉 Par10中 的 ce,0),Par8( 去 掉 Par10中的 Ds,p)和 Par7( 去掉 Par10中 的 cs,max,n)的辨識結果,橫坐標為參數組數(按照向量中參數的順序),縱坐標為參數誤差,用差值的絕對值與真值的比值來表示。隨著參數減少,辨識誤差減小。當參數組減為 Par7時,平均誤差和最大誤差分別小于3%和15%(圖4(d)),說明這組參數組通過辨識,可以獲得和真值很接近的辨識結果。
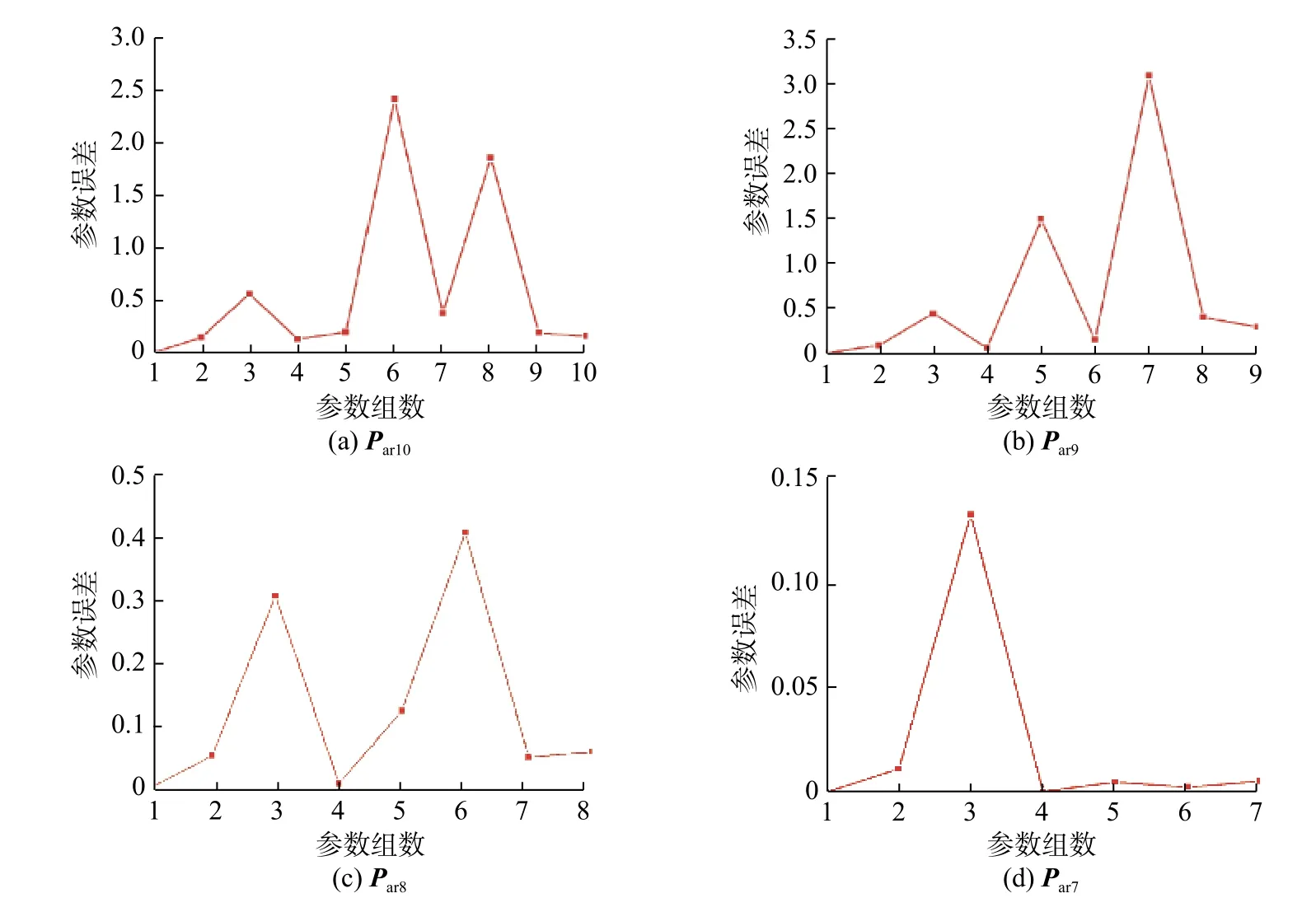
圖4 辨識結果誤差分析Fig.4 Error analysis of the identification results
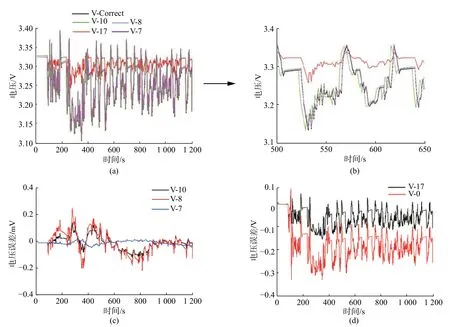
圖5 SP2D 模型在辨識參數與真值參數下的輸出電壓對比Fig.5 Comparison between the output voltages of the SP2D model with identified parameters and original parameters
圖5 為不同辨識參數組下SP2D 模型的輸出電壓和參考電壓的對比分析。圖5(b)是圖5(a)的局部放大。其中,V-Correct 為參考電壓Vref,V-17,V-10,V-8,V-7 和V-0 分別是辨識參數組 Par17,Par10,Par8,Par7,Pare后 的電壓 Vm曲線,Verr 為電壓誤差。可見,在17 個參數同時辨識下(圖5(d)),模型輸出電壓與參考電壓的誤差雖比使用錯誤參數Pare時達到300 mV 的誤差有所改善,但仍達100 mV,這是由于有些參數可辨識性差,難以準確辨識,同時也會影響其他可辨識性好的參數的辨識,使得模型估計不準。而采用可辨識性分析后的參數組 Par10和 Par8進行辨識時,誤差明顯減少(圖5(b)和5(c)),最大誤差只有0.3 mV。當只辨識 Par7時,模型輸出電壓與真值參數下的模型輸出電壓基本一致,可將誤差進一步顯著減小至0.05 mV 以內。
3 基于SP2D 模型的電池SOC 估計及實驗驗證
3.1 SOC 在線估計
基于SP2D 模型與參數辨識,采用自適應卡爾曼濾波進行SOC 估計。
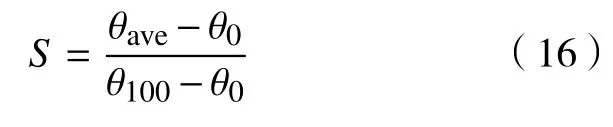
式中: θave為粒子平均濃度與最大濃度的比值;qn, qp為負極和正極的固相體積平均濃度流。
取 狀態 參 數 x=[S,qn,qp]。一般 情況 下,卡 爾曼濾波可表達為[8]

式中:A 為狀態轉移矩陣;B 為輸入矩陣;C,D 為 預 測 矩 陣; wk?1為 過 程 噪 聲; vk?1為 觀 測 噪聲; N(0,Q)表 示正態分布; Kk為卡爾曼濾波系數; P?k為 協方差;u 為輸入(取電流值); V為輸出值;k 為迭代次數; ∧符號表示預測值。
由 于 在 實 際 應 用 中,wk?1,vk?1不 能 準 確 知道,其偏差隨著數據量的增加會累積,影響估計精度。因此,本文采用自適應卡爾曼濾波的方法[10],根據預測與實測數據的誤差 ε修 正 wk?1,vk?1的值,來降低噪聲對預測的影響,遞推公式為
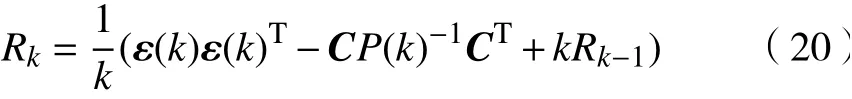
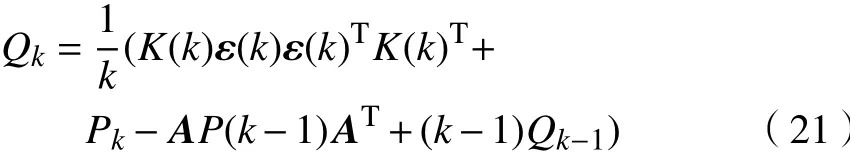
式中: ε為誤差向量; Q,R為噪聲的方差。
3.2 實驗驗證
采用Digatron Firing Circuit(德國)公司生產的Digatron 多功能電池測試儀UBT300-060,將電池放置在25 ℃恒溫箱內,選擇FUDS 循環工況,先將電池充滿(S=1)后測試直到截至電壓(S=0),將采集得到的電壓及電流作為模型參考電壓及輸入電流。
圖6 為模型輸出與實驗值的對比。其中,Real-U 和SOCr 分別表示為電池輸出電壓和SOC實測的實驗值;U 和SOC 分別表示為基于表1 中參數的SP2D 模型的輸出電壓和SOC 估計值;UIden 和SOC-Iden 分別表示采用本文參數辨識策略,以Real-U 為參考電壓,對參數向量 Par7進行辨識后的模型(SP2D-Iden)輸出電壓和SOC 估計值。Ue為電壓誤差,Ue-Iden 為參數辨識后的電壓誤差。由圖6 可見,辨識參數后,SP2D 模型提高了精度,電壓曲線更加接近實際曲線,平均誤差由50 mV 降到了18 mV,而SOC 也與實際值基本一致,平均誤差小于0.1%。上述結果驗證了本文提出的參數辨識策略應用在實際電池上的有效性。
為了考察對初始SOC 誤差的校正能力,設定初始誤差為0.2,再基于SP2D-Iden 模型進行SOC在線估計,并對比基于等效電路模型(一階ECM)下的SOC 估計方法,如圖7 所示。SP2D-Iden比ECM 的電壓預測精度更高,2 個模型的電壓平均誤差分別為19 mV 和37 mV。且基于SP2DIden 的SOC 平 均 誤 差 為1.2%, 基 于ECM 的SOC 平均誤差為1.7%。即基于SP2D-Iden 可將電壓平均誤差減小48.6%,SOC 平均誤差減小29.4%。這里等效電路模型采用的是常用的一階RC 模型(電阻電容回路模型),其電壓預測的誤差較大。使用二階或者更復雜的等效電路模型,電壓精度可以接近SP2D 模型的精度。
進一步分析可知,2 種方法下SOC 都能快速修正到正確值附近,但對影響電池容量利用率的關鍵階段——電池放電的中后期(S<0.4):基于ECM的SOC 估計誤差較大,SOC 平均誤差為2%,最大誤差達4.4%;而SP2D-Iden 模型在此較低的SOC 區間也能夠保持很好的估計精度,SOC 平均誤差僅0.7%,最大誤差1.8%。即在電池放電的中后期,基于SP2D-Iden 模型可將電池SOC 估計的平均誤差、最大誤差分別減小65%和59.1%。這說明本文方法可明顯減小電池在整個工作范圍內的SOC 估計誤差。

圖6 SP2D-iden 模型與電池實驗對比Fig.6 Comparative analysis between the results of the SP2D-Iden model and battery experiments

圖7 SP2D-iden 模型與等效電路模型對比Fig.7 Comparative analysis between the results of the SP2D-Iden model and equivalent circuit model
4 結 論
在電池SP2D 模型的基礎上,對模型參數進行可辨識性分析,提出了利用非線性最小二乘法結合Fisher 信息矩陣的參數辨識方法。仿真結果表明,該辨識方法可以減小參數辨識的誤差,使平均誤差減小至3%以內,進而提出了基于電化學SP2D-Iden 模型的SOC 在線估計方法。實驗表明,相比目前常用的基于ECM(一階RC)的SOC估計方法,本文SP2D-Iden 模型可將電池電壓平均誤差減小近50%,同時提高SOC 估計精度近30%。而在電池放電中后期(S<0.4)SP2D-Iden 模型仍能保持較高精度,相比ECM 模型,SOC 估計精度提高了60%以上,這證明了本文SOC 估計方法對整個SOC 范圍內的高精度估計特點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
