基于Docker的分布式環境快速搭建
2018-02-27 13:29:44鄒行健王同喜
電腦知識與技術 2018年35期
鄒行健 王同喜

摘要:隨著大數據熱度的不斷提升,大數據學習的熱潮已然來臨。然而在學習大數據的過程中,常常由于各種原因需要重新配置相應的實驗環境,這會浪費大量的時間。該文針對大數據實驗環境的部署,提出一種基于容器技術在單臺或多臺計算機上搭建Hadoop集群的方法,為短時間搭建分布式實驗環境提供參考。
關鍵詞:Docker;Hadoop;分布式;環境搭建
中圖分類號:TP393? ? ?文獻標識碼:A? ? ? 文章編號:1009-3044(2018)35-0024-03
1 背景
作為開源的大數據平臺,Apache Hadoop已經形成了完善的生態圈。它集成了存儲和數學數據,系統管理等功能,并在海量數據存儲和處理,并行計算和數據挖掘領域具有交叉擴展功能。目前而言,Apache Hadoop已經成為大數據領域實際上的標準[1]。與此同時,Hadoop平臺的多節點特性、復雜配置等特點,對大數據、Hadoop的學習人員帶來了一些困難,例如計算機不夠,或是配置失敗只能重新開始配置,甚至在多處進行相同的復雜配置。
對于計算機不夠的問題,學習人員有的借助學校的多臺學生機,在上面安裝Linux系統,以此搭建完整的Hadoop平臺;有的在單臺計算機上安裝多臺虛擬機進行配置,這對計算機性能有較高要求,并且對宿主機的硬件利用率較低,無法達到真實物理機的水平。而對于配置失敗的問題,只能多次嘗試,在搭建環境的過程中浪費較多時間。
Docker借助LXC(Linux Container)技術和AUFS(Advanced Union File System)技術,可以憑借極低的額外開銷換取隔離性的運行環境。一臺普通服務器就能運行數百個容器(Container)[2]。
2 Docker容器技術
Docker 是一個開源的應用容器引擎。Docker可以使用分層鏡像標準化與內核虛擬化技術,將開放環境、依賴包體、應用軟件等制作成鏡像,并發布到任何一臺安裝有Docker的不限制系統的計算機上。
2.1 Docker的優勢
Docker采用了LXC內核虛擬化技術,而不是對硬件虛擬層有較高依賴的傳統虛擬化技術。它不提供指令解釋機制和全虛擬化的其他復雜性,也不需要完整的硬件虛擬層,從而省去了虛擬化層調度硬件的開銷。這使得Docker容器擁有高于傳統虛擬機的資源利用率和執行效率,接近于真實的物理機[3]。
Docker采用了聯合文件系統(UnionFS)技術,并對其變體也有較高兼容性,如AUFS、btrfs、vfs和DeviceMapper。這種通過創建圖層進行操作的文件系統使得它能實現容器對基礎鏡像的共享。運行容器時,最底層的操作系統鏡像作為只讀層掛載,其上層設置有頂層的可寫層供寫入數據。通過這種圖層結構,docker不僅可以將多個具有層級關系的應用服務集成為新的鏡像,還可以將鏡像部署到他處,而不需要重復安裝。
基于以上兩點,作為面向應用的虛擬化技術[4],docker在啟動速度、磁盤占用、硬件資源利用率等方面有很大優勢。
2.2 鏡像與容器
在Docker技術中,鏡像與容器是兩個最為重要的概念。
鏡像相似于虛擬機模板。以一個原生系統作為模板,然后在其中可以進行部署開發環境、安裝應用、修改系統參數等操作,最后打包形成一個新的鏡像。這種繼承關系可以是多層的。
容器是基于鏡像創建的實例。對容器而言,鏡像是只讀的。在運行容器時,將首先在鏡像層之上新增一層,這一層是可寫的。此時,對該容器一切操作都會保存到這個可寫層的文件系統中,而不是鏡像中。因此,基于相同的一個鏡像可以創建多個彼此之間相互隔離的容器。
2.3 DockerSwarm
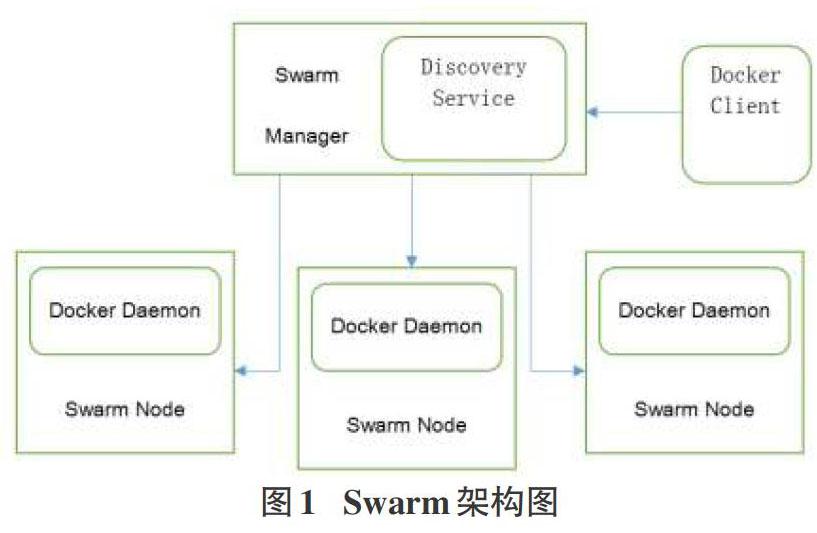
Swarm是一套集群管理工具。Docker Swarm能將若干Docker宿主機虛擬化為一臺獨立的Docker主機。Swarm使用了標準的Docker API接口,這意味著它兼容任何支持標準API的docker客戶端。
Swarm daemon在整個架構匯中起到了路由器與調度器的作用。Swarm負責連通整個網絡與分配任務。每當收到來自Client的請求時,Swarm將容器分配到空閑的或者合適的節點上。當Swarm的daemon進程意外中止時,其他節點依然會正常運行。而后,當Swarm進程恢復時,它會收集相關信息以重建集群日志。
圖1為Swarm架構圖。
2.4 DockerHub和Register
Docker Hub可看做官方提供的一個在線鏡像倉庫。DockerHub中存放了各種原生系統與用戶們自行修改的定制系統與框架。Docker Register組件提供了一組API服務,用于鏡像的存儲、搜索、上傳、下載等。任何個人或組織都可以在Docker Hub獲取已經發布的鏡像,或創建和發布自己的鏡像,以供后續重復使用或分享給其他人使用。
2.5 Dockerfile
為了方便用戶制作自己的鏡像,Docker提供給用戶兩種方法:一種是基于官方鏡像,按照生產環境的需求編寫Dockerfile文件,以此作為依據生成新的鏡像;另一種是基于官方鏡像創建容器后進行相關環境的部署,然后使用commit命令將配置好的容器封裝成一個新的鏡像。
Dockerfile是基于DSL(Domain Specific Language,特定領域語言)的腳本, 由命令行組成。其中的每條語句都對應了一條Linux命令, Docker引擎則將這些語句翻譯成對應的命令。相比于直接從Hub拉取鏡像,Dockerfile腳本清晰地表明鏡像相比于原生系統做了哪些配置, 如果需要進行其他修改, 只需要添加或修改Dockerfile中的命令即可。該文將使用這種方法制作鏡像。
3 制作Hadoop鏡像
在編碼制作Hadoop鏡像的Dockerfile文件時,主要有以下步驟:
1) 聲明原始鏡像;
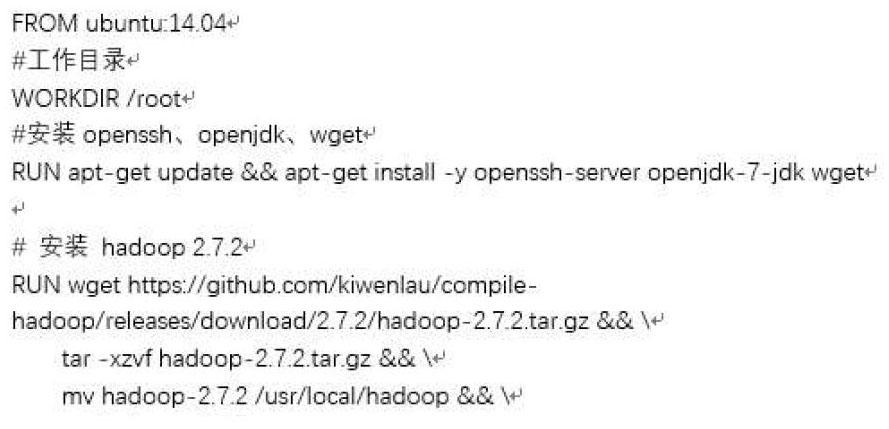
2) 聲明工作環境;
3) 安裝openssh、openjdk、wget;
4) 安裝Hadoop;
5) 配置環境變量;
6) 配置無密碼訪問;
7) 配置Hadoop,將下列修改好的配置文件拷貝至Hadoop目錄;
8) 格式化namenode;
9) 如果要加入eclipse等應用,與上面同理。
4 分布式環境搭建
得益于進程級虛擬化技術, Docker以應用為中心, 輕巧便捷,適合用于需要橫向擴展的應用。運行集成了Hadoop的容器,即可在計算機上快速部署Hadoop集群環境。
4.1 環境部署
1) 準備好一臺或多臺準備作為Hadoop節點的計算機,并在每臺計算機上安裝好Docker。
2) 在主節點(master)上獲取Hadoop鏡像,pull后面是制作好的鏡像的名字。
3) 建立Swarm網絡,在master節點運行以下命令,以此獲得用于加入swarm網絡的令牌。將獲取的令牌整個粘貼到每個slave節點上運行。如果僅有一臺計算機則可以跳過此步驟。
4) 為Hadoop集群創建一個專用網絡。一般來說,實驗不會直接使用swarm的默認網絡,用以下命令新建一個hadoop專用網絡。
4.2 啟動容器服務
如果是多PC節點,則在主節點上運行以下命令,然后查看docker的運行服務列表。可以發現Hadoop的三個節點已經分別分配到三個PC節點上了。
如果只有一臺PC,則在作為主節點(master)的容器上運行:
在每個作為從節點(slave)的容器上運行:
其中[slavename]替換成slave節點的名字。
4.3 啟動并驗證Hadoop
在master節點用ps命令查看并確認容器ID,而后用exec命令進入Hadoop集群的主節點。在每臺計算機上使用ping命令,測試它們之間的網絡是否正常;用ssh連接每個從節點以確認無密碼訪問是否正常。若無問題,則可以找到start腳本來啟動Hadoop集群。
如果啟動過程中沒有生成錯誤日志,則可以認為集群運行成功。接下來測試啟動過程是否出錯。運行Hadoop自帶的字數統計腳本(run-wordcount.sh),查看輸出;用jps命令查看每個容器節點的進程確認是否正常。下圖為驗證結果:
5 鏡像遷移
不同于傳統的虛擬機環境或固定的集群環境,當Docker下的Hadoop集群需要進行遷移時,只需要將原環境打包成鏡像發布到Docker Hub上,然后在新環境上下載,重新運行容器即可,極大簡化了應用程序的安裝與管理。
6 結束語
在大數據的學習與研究過程中,分布式環境是不可或缺的一部分。Docker可以在多種平臺上搭建Hadoop集群,這為廣大學習者節省了大量學習成本,且經長時間使用測試證明運行穩定,可供其他人進行參考。
參考文獻:
[1] 孟小峰, 慈祥. 大數據管理:概念、技術與挑戰[J]. 計算機研究與發展, 2013(1):146-169.
[2] 強焜. 基于Docker的舊機房虛擬化改造探討[J]. 科技創新與應用, 2016(35):58.
[3] 謝超群. Docker容器技術在高校數據中心的應用[J]. 貴陽學院學報: 自然科學版, 2015,10(4):27-29.
[4] 汪愷, 張功萱, 周秀敏. 基于容器虛擬化技術研究[J]. 計算機技術與發展, 2015,25(8):138-141.
+[通聯編輯:謝媛媛]
