基于約簡矩陣和C4.5決策樹的故障診斷方法
2018-03-05 02:40:29徐曌,張斌
計算機技術與發展 2018年2期
徐 曌,張 斌
(桂林電子科技大學 計算機與信息安全學院,廣西 桂林 541000)
0 引 言
工業4.0環境下,智能設備通過多種傳感器采集實時參數產生大量的數據。利用數據挖掘進行故障診斷就是將狀態參數進行關聯、分類、推理,得到決策樹[1],并利用決策樹對智能設備進行故障診斷。相關研究表明:工業機械遇到故障時,技術人員需要花70%~90%的時間來尋找故障原因和部位,而故障維修只占10%~30%的時間;在維修成本方面,預測維修成本只占故障后維修成本的40%[2]。
機械設備結構功能的逐漸增強,使得現階段故障診斷的難度不斷提高。文獻[3]是基于知識庫邏輯理論對規則進行處理,但沒有給出規則間的相互關系,診斷效率不高。文獻[4]是基于知識庫邏輯理論,利用粗糙集直接從故障樣本中得到診斷規則,效率不高;并且在缺乏屬性間的關系時,必須對整個規則庫遍歷搜索,而且當缺失某些關鍵信息時診斷結果會受到影響。文獻[5]結合了故障樹與模糊推理用于動態系統的故障診斷;文獻[6]利用粗糙集研究了故障樹基本事件的排序問題。當系統比較復雜時,這類方法的搜索過程也變得非常復雜,診斷結果的準確性也不高。
為解決上述問題,文中結合可辨識矩陣與決策樹的特點,提出基于可辨識矩陣約簡和C4.5決策樹的故障診斷方法,并對其進行了驗證。
1 約簡決策樹故障診斷方法
首先確定故障診斷的訓練樣本集,接著對訓練樣本集里的連續屬性進行離散化處理,得到離散樣本集。然后用可辨識矩陣約簡算法對離散樣本集進行屬性約簡,并根據聚類比選擇出最佳約簡矩陣,得到最佳約簡樣本集。再用C4.5算法對最佳約簡樣本集進行分析,生成最終決策樹。最后通過測試樣本集驗證決策樹的故障診斷準確性。
訓練樣本需要全面反映設備的情況,這樣的樣本經過訓練后生成的決策才能對新的數據做出正確的判斷。以轉子磨粉機為例,有轉子不平衡、轉子不對中、油膜振蕩三種常見機械故障。由歷史振動波形測量數據建立如表1所示的樣本訓練集T'=
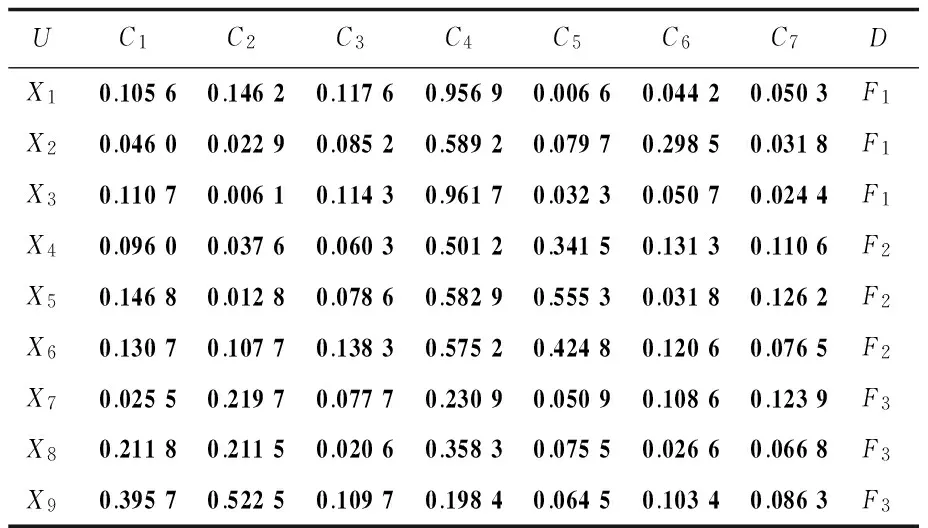
表1 訓練樣本集T'
2 連續屬性離散化算法
連續屬性的離散化是非常必要的,因為粗糙集理論以及多種離散型數據挖掘算法只能解決離散數據,因此需要對訓練樣本集進行離散化處理。離散化方法主要包括兩大類:無監督的離散化方法和有監督的離散化方法。基于熵的離散化方法就是在處理數據時考慮了條件屬性和決策屬性之間的依賴關系。
假設樣本集有N個故障樣本Xj(j=1,2,…,N),M個故障條件屬性,K個故障類型。應用一種基于最小熵原理的離散算法將樣本集中的連續屬性Ci進行離散化處理[7]。步驟如下:

步驟2:離散分類數r=3。
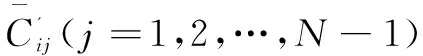
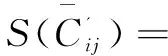
(1)

(2)

(3)
(4)
(5)
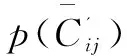

步驟5:根據最大隸屬度原則,將樣本集中的連續屬性值按照式(6)進行離散化處理,處理過后的條件屬性值記為CdiN(N=1,2…):
(6)
其中,P1i和P2i是連續屬性離散化過程中的兩個斷點值,其中P1i=(SEC1i+PRIi)/2,P2i=(SEC2i+PRIi)/2,j=1,2,…,N。
將樣本訓練集T'中連續屬性進行離散化處理后得到離散樣本集T''。
3 屬性約簡及最佳約簡優選
粗糙集理論[8]可以在缺乏先驗知識的前提下,以分類能力為基礎很好地進行模糊數據的分類和處理。粗糙集的關鍵內容是屬性約簡,能夠有效地刪除樣本集中的冗余信息,形成精簡的規則庫,提高規則庫的讀取使用效率[9]。文中使用可辨別矩陣作為樣本集屬性的約簡算法。
假設T''=(U',C',D),其中包括N個經過離散化處理的樣本Yj(j=1,2,…,N),M個條件屬性和K個故障類型。基于可辨別矩陣約簡[10]和最大集群比[11]原則,文中采用如下算法對T''進行約簡并選擇出聚類率最高的屬性組合。
步驟1:按照式(7)計算出T''的可辨識矩陣C=(cij)N×N。
C(i,j)=
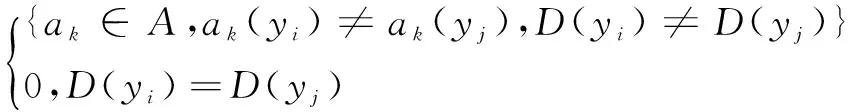
(7)
步驟4:輸出屬性約簡結果。
步驟5:按照式(8)計算步驟5中得到的所有約簡集的聚類比。最佳約簡集即為聚類比Ra最大的一組。
Ra=(N-NR)/N-1
(8)
其中,N為規則表中離散化的樣本數目;NR為T''約簡過后的論域個數。
用步驟1對離散樣本集T''進行處理,得到對應的可辨識矩陣,如表2所示。

表2 對應于T''的可辨識矩陣
根據步驟2~4進一步對T''各個屬性進行約簡,可得:{C3,C4,C7},{C2,C4,C6,C7},{C1,C2,C4,C7},{C1,C5,C6,C7},{C4,C5,C7},{C1,C2,C4,C5},{C2,C3,C4,C5,C7},其中{C3,C4,C7}的聚類率最大,所以把{C3,C4,C7}作為最佳約簡集,從而得到最優約簡診斷決策表T''',如表3所示。
4 C4.5故障決策樹算法
4.1 C4.5算法
C4.5算法[12]是目前最具影響的決策樹算法之一,以信息增益率作為確定分支屬性的標準,更好地處理算法在使用信息增益選擇分支屬性時偏向于取值較多的屬性的缺陷[13]。核心思想是通過分析訓練集的數據,在數據集上遞歸地建立一個決策樹,該決策樹由一組規劃來表示,尤其是被識別的模式有連續特征值屬性時,甚至是在缺失某些重要特征屬性時,C4.5算法也是有效的。該算法用已知故障類別的樣本得到順序測試特征,直到所有特征被正確歸類。在得到決策樹之后,只需要判斷部分的條件屬性,即可得到正確的故障類型[14]。C4.5算法使用后剪枝方法簡化決策樹,從而提高多特征下的辨識效果。過程如下:
表3最優約簡診斷決策表T'''
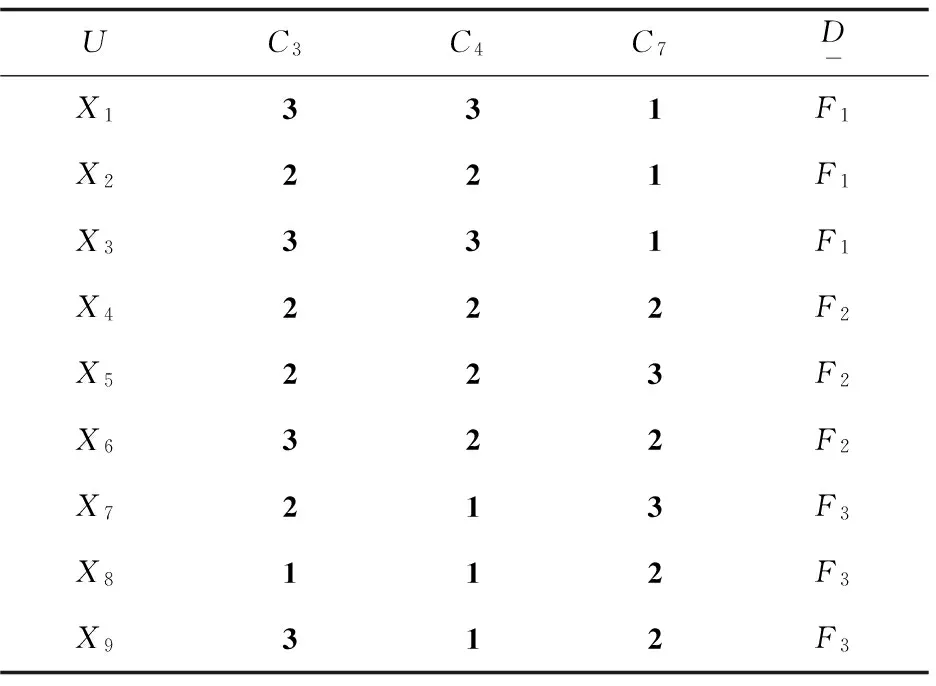
UC3C4C7D-X1331F1X2221F1X3331F1X4222F2X5223F2X6322F2X7213F3X8112F3X9312F3
步驟1:計算所有屬性的信息增益率,選擇具有最大信息增益率的屬性作為根節點的分支屬性。
(1)設數據集為T,|T|作為數據集T的樣本數,共有k個類。|Ci|是T中屬于類別Ci的樣本數,先驗概率可以表示為Pi=|Ci|/|T|,并且對T分類的信息熵為:
(9)
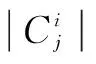
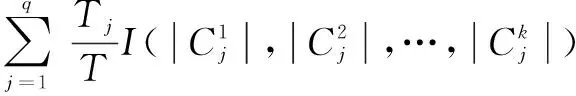
(10)
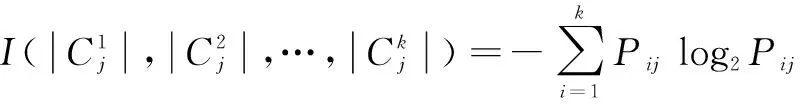
(11)
并由式(9)~(11)可以得到按照Ak劃分數據集的信息增益為:
(12)
其中Ak的信息熵為:
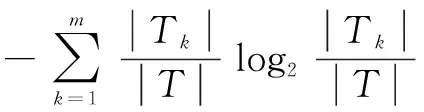
(13)
最終由式(12)、(13)得到Ak的信息增益率為:
(14)
步驟2:不斷利用上述方法建立樹的分支,將信息增益率最大的屬性作為子節點,直到完成決策樹的創建為止。
4.2 生成故障診斷決策樹
利用C4.5算法對T'''進行分析,計算可得C4的信息增益率為0.8,同理可得C3和C7的信息增益率分別為0.18和0.6。因為C4的信息增益率最大,所以將C4作為根節點建立決策樹,并且在每個節點使用C4.5算法進行分析,最后生成的決策樹如圖1所示。使用C4.5算法直接對T'''進行分析,得到的決策樹如圖2所示。并且用離散化測試樣本對最終決策樹和C4.5算法生成的決策樹進行效果驗證。
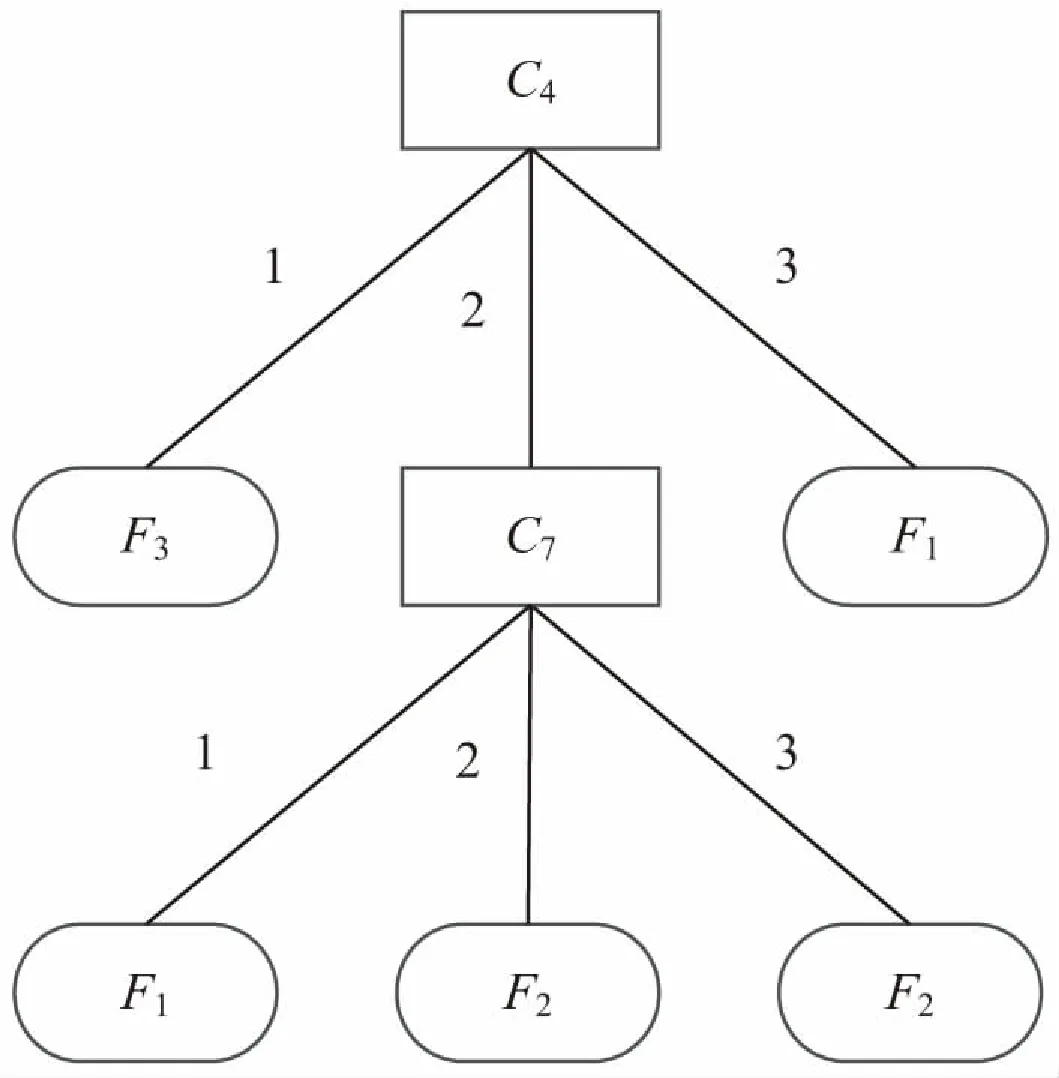
圖1 約簡的決策樹(文中算法)
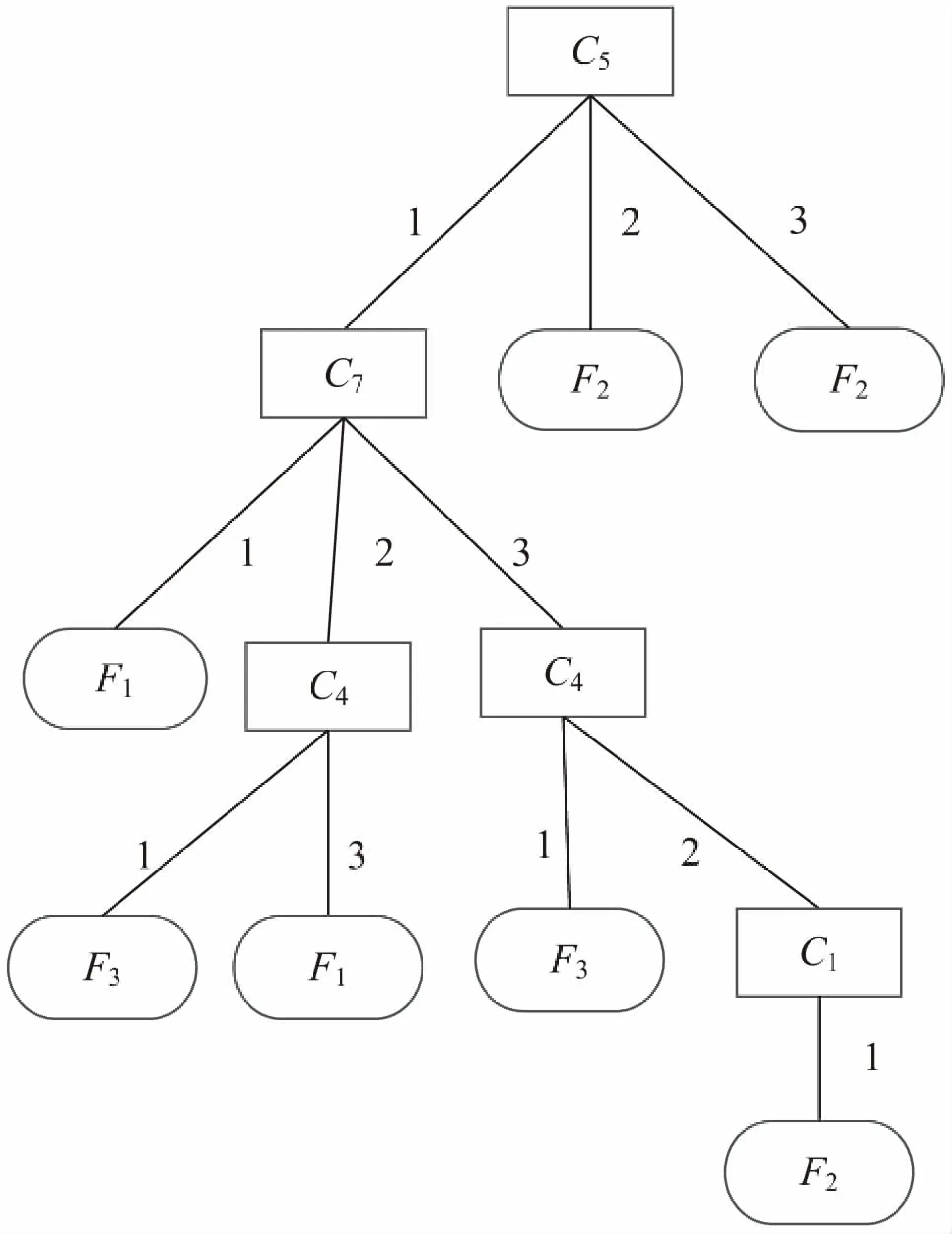
圖2 C4.5算法決策樹
5 實驗結果及分析
(1)決策樹構建速度的比較。
5次使用相同訓練數據集得到決策樹的時間,可以得出文中方法生成決策樹的平均時間比直接使用C4.5算法快約31%。
(2)決策樹復雜度的比較。
首先,直接使用C4.5算法生成的決策樹(圖2)所需要的故障特征向量為4維,而文中方法(圖1)僅需故障特征向量為2維。證明文中方法在保證的診斷準確性的同時,有效地減少了故障特征數據獲取的工作量,并且降低了決策樹的復雜度。
(3)故障診斷準確率的比較。
使用兩個決策樹對相同故障數據進行準確性測試,如圖3所示。其中對于F1故障類型的診斷準確率基本相同,達到了95.3%。C4.5算法對于F2故障類型診斷正確率為95.3%,而文中方法的診斷準確率達到了96%。C4.5算法對于F3故障類型的診斷正確率為96.5%,而文中方法的診斷準確率達到了97.8%。兩種方法的準確率出現了較為明顯的差異。其次,文中方法可以準確識別故障類型,說明將粗糙集和決策樹結合的方法不僅減少了規則庫搜索的步驟,同時具有很強的容錯能力。
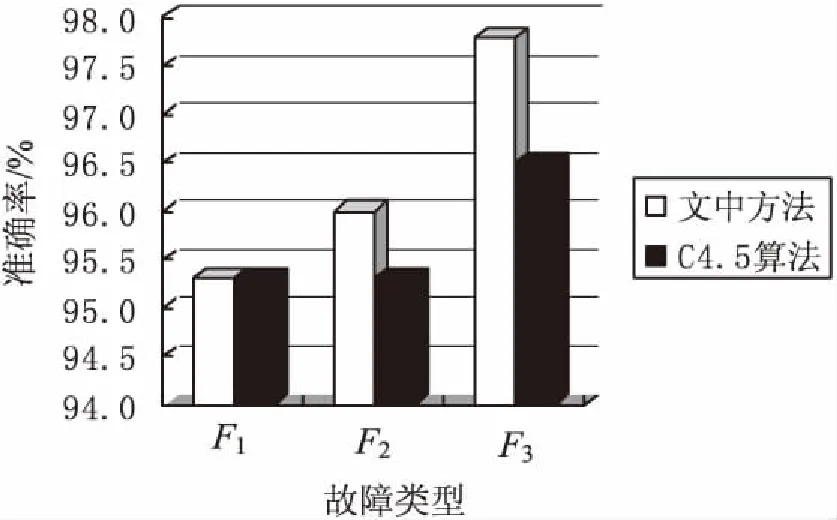
圖3 故障診斷準確率
綜上可以證明,文中方法不僅在降低最終決策樹復雜度的基礎上提高了決策樹的構建速率,還提高了對部分故障類型的診斷準確率。
6 結束語
應用可辨識矩陣約簡算法和決策樹結合的方法能有效地對條件屬性進行約簡,消除冗余信息,并減少決策樹的節點數,降低決策樹復雜度,最終高效率地構建決策樹,實現對機械快速準確的故障識別。然而,數據挖掘技術是建立在海量的數據樣本的基礎上[15],文中的故障樣本數據是比較典型的故障類別數據,不排除存在具有兩種甚至更多的故障特征數據。當樣本數據更加充足時,決策規則庫也將有更強的工程實用性。
[1] 陳紹煒,王 聰,趙 帥.決策樹算法在電路故障診斷中的應用[J].計算機工程與應用,2013,49(12):233-236.
[2] GILLUM M N,ARMIJO C B.Optimizing the frequency of the rotary knife on a roller gin stand[J].Hydrobiologia,2000,43(4):809-817.
[3] 王 慶,巴德純,王曉冬.智能故障診斷的粗糙決策模型[J].東北大學學報:自然科學版,2005,26(1):80-83.
[4] 束洪春,孫向飛,司大軍.基于粗糙集理論的配電網故障診斷研究[J].中國電機工程學報,2001,21(10):73-77.
[5] CHANG S Y,LIN C R,CHANG C T.A fuzzy diagnosis approach using dynamic fault trees[J].Chemical Engineering Science,2002,57(15):2971-2985.
[6] KHOO L P,TOR S B,LI J R.A rough set approach to the ordering of basic events in a fault tree for fault diagnosis[J].International Journal of Advanced Manufacturing Technology,2001,17(10):769-774.
[7] 賈智皓,劉 方.服務于粗糙集信息處理的數據離散化技術[J].數字技術與應用,2014(11):77-79.
[8] 馬文萍,黃媛媛,李 豪,等.基于粗糙集與差分免疫模糊聚類算法的圖像分割[J].軟件學報,2014,25(11):2675-2689.
[9] 李明祥.基于粗糙集理論的數據挖掘方法的研究[D].青島:山東科技大學,2003.
[10] 武志峰,吉根林.一種基于決策矩陣的屬性約簡及規則提取算法[J].計算機應用,2005,25(3):639-642.
[11] 滕書華,魯 敏,楊阿鋒,等.基于一般二元關系的粗糙集加權不確定性度量[J].計算機學報,2014,37(3):649-665.
[12] 徐 鵬,林 森.基于C4.5決策樹的流量分類方法[J].軟件學報,2009,20(10):2692-2704.
[13] 李學明,李海瑞,薛 亮,等.基于信息增益與信息熵的TFIDF算法[J].計算機工程,2012,38(8):37-40.
[14] 黃愛輝.決策樹C4.5算法的改進及應用[J].科學技術與工程,2009,9(1):34-36.
[15] 云玉屏.基于C4.5算法的數據挖掘應用研究[D].哈爾濱:哈爾濱理工大學,2008.
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
