基于日志挖掘的電商查詢建議方法
2018-03-06 11:05:23王若飛
計(jì)算機(jī)工程與科學(xué) 2018年2期
王 菁,王若飛
(1.大規(guī)模流數(shù)據(jù)集成與分析技術(shù)北京市重點(diǎn)實(shí)驗(yàn)室,北京 100144;2.北方工業(yè)大學(xué)數(shù)據(jù)工程研究院,北京 100144)
1 引言
在電子商務(wù)以及網(wǎng)頁搜索領(lǐng)域,查詢建議是一個(gè)重要的輔助功能[1]。所謂“查詢建議”是指用戶在搜索框輸入查詢詞的同時(shí),會在輸入框的下面彈出一組建議查詢詞,例如搜索“連衣”,會彈出“連衣裙”“黑色連衣裙”“短袖連衣裙”等建議查詢詞供用戶選擇。這一方面可以減少用戶輸入,不需要用戶輸入完整的查詢詞即可得到所需的搜索結(jié)果,可帶給用戶便捷的搜索體驗(yàn);另一方面也可以有效消除查詢詞不完全,存在同義、歧義等現(xiàn)象,提高信息檢索的準(zhǔn)確率。
據(jù)中國互聯(lián)網(wǎng)絡(luò)信息中心CNNIC發(fā)布的《第39次中國互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r統(tǒng)計(jì)報(bào)告》[2]顯示,截止2016年12月,我國網(wǎng)絡(luò)購物用戶規(guī)模達(dá)到4.67億,占網(wǎng)民比例為63.8%,較2015年增長12.9%。據(jù)CNNIC調(diào)查顯示:74.3%的用戶習(xí)慣通過輸入關(guān)鍵字進(jìn)行檢索,人們輸入檢索關(guān)鍵字的平均長度僅為2~3個(gè)字。查詢建議即是在用戶輸入的有限、不完整的查詢詞與系統(tǒng)內(nèi)待檢索對象(網(wǎng)頁、商品等)所包含的專業(yè)查詢詞之間建立映射,為非專業(yè)用戶推薦與原始查詢詞相關(guān)的專業(yè)查詢詞,從而幫助用戶快速找到所需的結(jié)果。
在基于互聯(lián)網(wǎng)的線上購物型應(yīng)用中,由于沒有傳統(tǒng)行業(yè)的導(dǎo)購與用戶進(jìn)行面對面交流,用戶只能通過搜索框與系統(tǒng)進(jìn)行實(shí)時(shí)交互,查詢建議是否能快速準(zhǔn)確地滿足用戶需求對電商應(yīng)用的用戶體驗(yàn)具有很重要的影響。由于電子商務(wù)領(lǐng)域的特性,提供合適的查詢建議需要解決以下幾方面的問題:
首先,如何構(gòu)建合適的查詢建議詞庫?用戶輸入的短關(guān)鍵字查詢本身由于短關(guān)鍵字與檢索系統(tǒng)構(gòu)造的詞庫不一定完全匹配,容易造成信息檢索不完全不準(zhǔn)確。很多研究工作從用戶搜索日志出發(fā),而由于搜索日志的稀疏性,以及電商商品具有時(shí)效性,經(jīng)常根據(jù)季節(jié)變化、時(shí)尚趨勢進(jìn)行變動,導(dǎo)致傳統(tǒng)面向Web搜索的方法在電商領(lǐng)域并不完全適用。
其次,如何評價(jià)查詢建議詞的質(zhì)量?高質(zhì)量的查詢建議詞可以引導(dǎo)用戶快速找到所需商品,提高用戶滿意度,促進(jìn)電商應(yīng)用的銷售額增長。因此,不同于Web搜索僅考慮網(wǎng)頁點(diǎn)擊率,電商應(yīng)用還需要考慮與用戶的購物行為相關(guān)的影響因素,用于對查詢建議詞的質(zhì)量評估,盡量為用戶提供可促進(jìn)商品銷售的查詢建議詞,提高商城銷量。
第三,如何保證系統(tǒng)響應(yīng)的實(shí)時(shí)性?良好的查詢建議需要用戶每次輸入一個(gè)單字后快速返回結(jié)果,提供良好的用戶體驗(yàn)。而面向大規(guī)模數(shù)據(jù)的挖掘算法都需要消耗一定時(shí)間才能得到計(jì)算結(jié)果,因此需要研究合適的離線與在線相結(jié)合的計(jì)算方法,保障系統(tǒng)的實(shí)時(shí)響應(yīng)。
針對上述電商領(lǐng)域的查詢建議存在的問題,本文綜合考慮用戶的搜索行為以及購物行為,運(yùn)用MapReduce技術(shù)對用戶日志進(jìn)行挖掘,提取查詢詞并計(jì)算權(quán)重,以此生成檢索詞詞庫;并通過在線計(jì)算與離線計(jì)算結(jié)合的方法,為用戶提供實(shí)時(shí)查詢建議。實(shí)驗(yàn)結(jié)果表明,本文提出的基于日志挖掘的電商查詢建議方法能有效提高查詢建議的準(zhǔn)確率,并且具有良好的處理性能。
本文的組織如下:第1節(jié)為引言部分,提出本文需要解決的問題。第2節(jié)介紹查詢建議技術(shù)的相關(guān)工作。第3節(jié)詳細(xì)介紹了本文提出的基于日志的電商查詢建議的系統(tǒng)架構(gòu)。第4節(jié)為系統(tǒng)原理介紹。第5節(jié)為實(shí)驗(yàn)設(shè)計(jì)和驗(yàn)證部分。第6節(jié)對本文進(jìn)行總結(jié)。
2 相關(guān)工作
國內(nèi)外的學(xué)者在優(yōu)化用戶查詢建議方面做了大量的研究和實(shí)踐工作。2008年,Google率先推出了搜索關(guān)鍵詞建議服務(wù)。百度和雅虎也分別在2009年和2010年推出了各自的搜索關(guān)鍵詞建議服務(wù)。在學(xué)術(shù)界,查詢建議也是文檔檢索、Web搜索等相關(guān)領(lǐng)域內(nèi)活躍的研究主題。
基于查詢建議的目標(biāo)之一是為非專業(yè)用戶推薦與原始查詢詞相關(guān)的專業(yè)查詢詞,早在60年代就有學(xué)者提出了利用知識模型來為用戶提供查詢詞擴(kuò)展的方法。其基本思想是建立查詢詞聚類,根據(jù)查詢詞所映射到的聚類內(nèi)包含的其他詞匯進(jìn)行查詢擴(kuò)展[3]。知識模型的構(gòu)建又可分為人工構(gòu)建和自動聚類兩類。人工建立詞匯聚類模型是個(gè)繁瑣的過程,典型工作是利用WorkNet作為基礎(chǔ)[4]。大部分工作研究根據(jù)待檢索文檔進(jìn)行自動聚類的方法,如文獻(xiàn)[5]提出了全局和局部分析兩種方法,全局分析指對全部文檔中出現(xiàn)的詞按共同發(fā)生的頻率進(jìn)行聚類,而局部分析僅利用檢索文檔中的一個(gè)子集進(jìn)行計(jì)算,可以獲得更好的計(jì)算效率和檢索性能。
另一類工作從用戶的查詢?nèi)罩境霭l(fā)開展研究。用戶查詢?nèi)罩臼潜姸嘤脩羰褂糜涗浀姆e累,從日志中進(jìn)行挖掘分析,相當(dāng)于使用大量的用戶相關(guān)反饋,可獲取到查詢詞、查詢詞的質(zhì)量以及查詢詞之間的關(guān)系。文獻(xiàn)[6]對基于日志的查詢建議方法進(jìn)行了研究,查詢建議基于用戶的查詢與查詢推薦之間的聯(lián)系的權(quán)重,以及用戶對以前查詢推薦的滿意度。文獻(xiàn)[7]提出一種基于用戶日志挖掘的查詢擴(kuò)展統(tǒng)計(jì)模型,將用戶查詢中使用的詞或短語與文檔中出現(xiàn)的相應(yīng)的詞或短語以條件概率的形式連接,利用貝葉斯公式挑選出文檔中與該查詢關(guān)聯(lián)最緊密的詞加入原查詢,以達(dá)到擴(kuò)展優(yōu)化的目的。文獻(xiàn)[8]研究日志中查詢詞的主題聚類方法,查詢詞之間的主題相似度可以通過檢索過程點(diǎn)擊的文檔的相關(guān)程度來度量,這種聚類技術(shù)可以揭示查詢詞之間潛在的關(guān)聯(lián)關(guān)系,這種關(guān)系在查詢推薦中也得到了應(yīng)用[9]。文獻(xiàn)[10]通過挖掘用戶日志中查詢詞的關(guān)聯(lián)關(guān)系來進(jìn)行查詢建議,擴(kuò)展詞的選取來自于以往的檢索用詞。文獻(xiàn)[11]提出一個(gè)基于查詢?nèi)罩窘⒌牟樵兞鞒虉D系統(tǒng),在查詢流程圖中,每一個(gè)頂點(diǎn)代表著一個(gè)查詢詞條,每一條邊代表著會話之中的查詢轉(zhuǎn)換。不同于以上基于用戶查詢歷史的日志挖掘研究,文獻(xiàn)[12]和文獻(xiàn)[13]適當(dāng)?shù)丶尤肓藢τ脩羝渌袨榈难芯浚瑢τ脩舻念I(lǐng)域相關(guān)的其他操作進(jìn)行了定義分析,以改善查詢詞的質(zhì)量。
上面所述工作大多集中于傳統(tǒng)文檔檢索和Web網(wǎng)頁檢索領(lǐng)域,而針對電商領(lǐng)域應(yīng)用需求的研究工作較少。從詞匯模型角度,電商網(wǎng)站的搜索詞和網(wǎng)站內(nèi)的商品相關(guān);從用戶行為角度,電商領(lǐng)域內(nèi)的用戶行為除了搜索行為之外,還有添加購物車、下單等購物相關(guān)行為,日志中可供挖掘的信息更多。本文綜合上述兩種方法的優(yōu)點(diǎn),研究面向電商商品的查詢建議算法,以提高查詢建議的準(zhǔn)確率。
3 系統(tǒng)架構(gòu)
由于電商應(yīng)用的日志量大,查詢建議時(shí)用戶反饋要求實(shí)時(shí)性高,而面向大規(guī)模數(shù)據(jù)的挖掘算法都需要消耗一定時(shí)間才能得到計(jì)算結(jié)果,不能實(shí)時(shí)對日志數(shù)據(jù)進(jìn)行分析。因此,本文將查詢建議系統(tǒng)劃分為在線和離線兩個(gè)部分,離線部分先對系統(tǒng)之前產(chǎn)生的日志進(jìn)行分析計(jì)算,將計(jì)算結(jié)果存入檢索詞詞庫,在線部分通過向檢索詞詞庫發(fā)送用戶輸入的檢索詞,獲取相關(guān)檢索詞結(jié)果,以保證實(shí)時(shí)性。系統(tǒng)架構(gòu)如圖1所示。
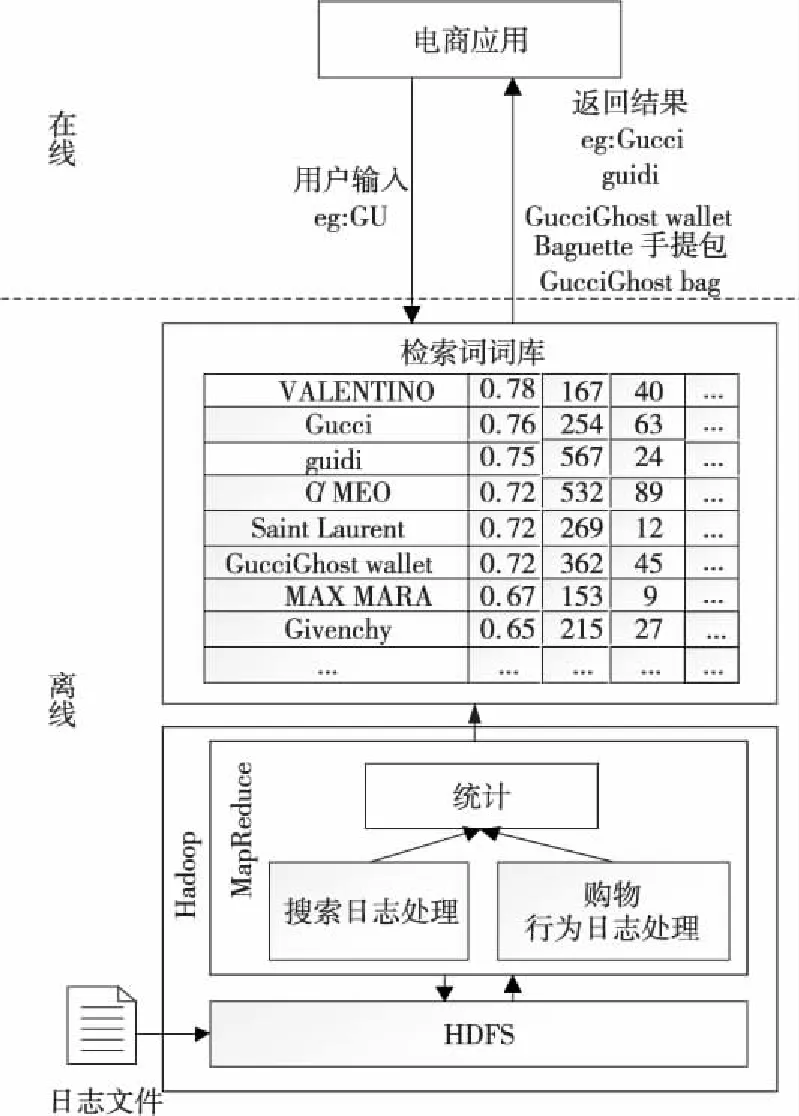
Figure 1 System architecture圖1 系統(tǒng)架構(gòu)圖
本文重點(diǎn)討論的是離線部分,離線部分分為HDFS(Hadoop Distributed File System)文件存儲、搜索日志處理、購物行為日志處理和結(jié)果統(tǒng)計(jì)四部分。
(1)HDFS文件存儲。
由于日志文件規(guī)模較大,因此采用HDFS進(jìn)行日志文件的存儲。HDFS將讀入的日志文件進(jìn)行分塊存儲,可提供良好的可擴(kuò)展性和可靠性。
(2)搜索日志處理。
搜索日志處理模塊主要處理日志中用戶搜索行為產(chǎn)生的關(guān)鍵字,將這些關(guān)鍵字記錄作為候選的檢索詞。此模塊對應(yīng)MapReduce中的Map階段,可在Hadoop集群中進(jìn)行并行計(jì)算。
(3)購物行為日志處理。
用戶的購物行為指用戶瀏覽商品、收藏商品、添加購物車以及下訂單等行為,在這部分將對這些用戶行為所對應(yīng)的關(guān)鍵字進(jìn)行分析,并且給這些關(guān)鍵字分類并進(jìn)行記錄。此模塊也在MapReduce中的Map階段進(jìn)行并行計(jì)算。
(4)結(jié)果統(tǒng)計(jì)。
結(jié)果統(tǒng)計(jì)模塊對應(yīng)MapReduce中的Reduce階段,將搜索日志和購物行為日志處理的結(jié)果進(jìn)行合并統(tǒng)計(jì),最終生成檢索詞詞庫。
在線部分主要是用戶部分或者全部輸入關(guān)鍵字的同時(shí),運(yùn)用ajax異步請求將用戶輸入的關(guān)鍵字發(fā)送至服務(wù)端,服務(wù)端拿到關(guān)鍵字通過與檢索詞詞庫的檢索詞匹配,將與關(guān)鍵字有包含關(guān)系的檢索詞按照權(quán)重由高到低的順序返回客戶端,顯示在輸入框的下方。
4 系統(tǒng)原理
本系統(tǒng)采用Hadoop平臺的MapReduce并行計(jì)算框架對用戶的歷史日志進(jìn)行分析,如果是用戶的搜索日志,需要從日志中提取搜索詞,統(tǒng)計(jì)搜索詞出現(xiàn)的次數(shù),對搜索詞進(jìn)行打分;如果是用戶的購物行為日志,需要提取日志中四個(gè)典型事件,分別是瀏覽、收藏、添加購物車和下單。根據(jù)前人的研究以及商城運(yùn)營的經(jīng)驗(yàn),為這四個(gè)事件設(shè)置權(quán)重。對出現(xiàn)在這四個(gè)事件中的商品,以各事件的權(quán)重進(jìn)行統(tǒng)計(jì)。
4.1 算法原理
定義1由于算法中需要對關(guān)鍵字在日志中以及在用戶行為事件中出現(xiàn)的次數(shù)進(jìn)行統(tǒng)計(jì)、計(jì)算,因此檢索詞詞庫中的每一個(gè)關(guān)鍵字可以定義為一個(gè)七元組:
RWT=(K,S,QC,BC,F(xiàn)C,AC,OC)
各屬性含義如下:
(1)K表示檢索詞詞庫中的關(guān)鍵字;
(2)S表示該關(guān)鍵字最終的得分;
(3)QC表示該關(guān)鍵字在搜索日志中出現(xiàn)的次數(shù);
(4)BC表示該關(guān)鍵字在瀏覽事件中出現(xiàn)的次數(shù);
(5)FC表示該關(guān)鍵字在收藏事件中出現(xiàn)的次數(shù);
(6)AC表示該關(guān)鍵字在加入購物車事件中出現(xiàn)的次數(shù);
(7)OC表示該關(guān)鍵字在下訂單事件中出現(xiàn)的次數(shù)。
定義2設(shè)對于每一個(gè)關(guān)鍵字q,其在搜索日志中出現(xiàn)的次數(shù)為QC,所有關(guān)鍵字在日志文件中出現(xiàn)的次數(shù)為SUMQC,則該關(guān)鍵字在搜索日志中的得分為:
對于搜索日志中出現(xiàn)的關(guān)鍵字、品牌名、分類名等數(shù)據(jù),我們直接統(tǒng)計(jì)其出現(xiàn)的頻率,按照關(guān)鍵字(包括品牌、分類等)出現(xiàn)一次記一分的規(guī)則,將日志中出現(xiàn)的關(guān)鍵字及其出現(xiàn)的次數(shù)存入表1中。
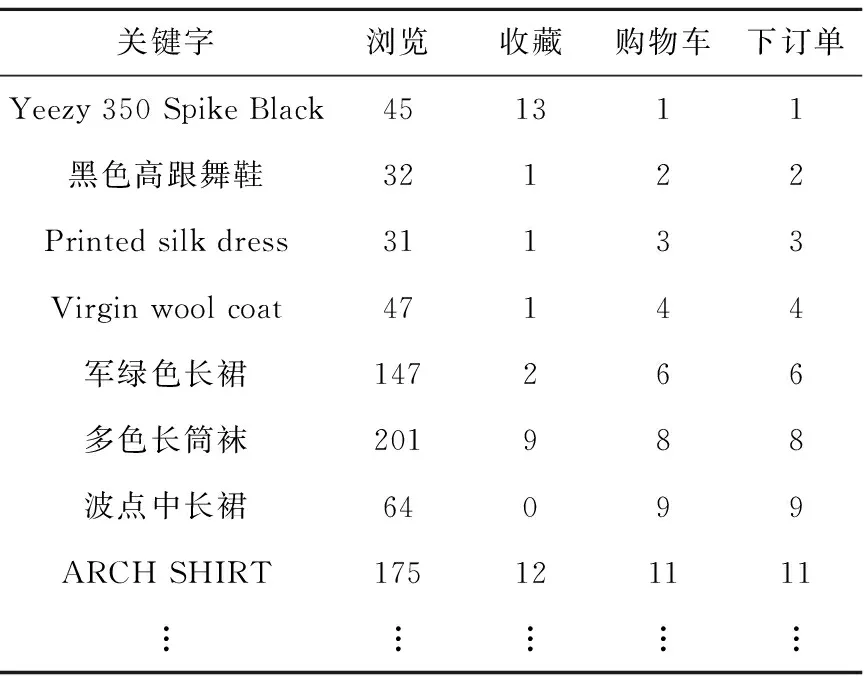
Table 1 Keywords of event
值得注意的是,輸入的關(guān)鍵字中可能存在包含現(xiàn)象,比如:“Adidas”?“Adidas Kanye West”“BURBERRY”?“BURBERRY PRORSUM”“Yeezy”?“Yeezy 350 Spike Black”等,對于這種情況,我們將同時(shí)給包含詞和被包含詞各記一分,即如果出現(xiàn)的關(guān)鍵字是“Adidas Kanye West”,我們將給關(guān)鍵字“Adidas Kanye West”和“Adidas”各加一分;反之,如果出現(xiàn)的關(guān)鍵字是“Adidas”,我們將只給“Adidas”加分。
定義3設(shè)B、F、A、O分別表示與購物相關(guān)的瀏覽行為、收藏行為、添加購物車行為、下訂單行為,其對應(yīng)的行為權(quán)重分別是wB、wF、wA、wO,對于某一種商品關(guān)鍵字q,其在某個(gè)行為中出現(xiàn)的頻率是fEq(E分別表示B、F、A、O),則根據(jù)數(shù)據(jù)庫及日志中的相關(guān)記錄,其在與購物相關(guān)的各個(gè)行為中的得分為:
SEq=wB*fBq+wF*fFq+wA*fAq+wO*fOq=
對于用戶查看商品詳情的記錄、用戶將商品加入購物車的記錄、用戶收藏商品的記錄以及用戶的購買記錄等數(shù)據(jù),不能直接產(chǎn)生關(guān)鍵字與得分,我們將通過一個(gè)中間表(如表1所示)進(jìn)行計(jì)算:首先,我們將與購買相關(guān)的各個(gè)操作定義成購物相關(guān)行為,這些行為包括“瀏覽”“收藏”“添加購物車”“下訂單”。然后,通過分析日志以及相關(guān)的記錄,設(shè)置各個(gè)行為的權(quán)重(各行為最優(yōu)權(quán)重的計(jì)算方法將在4.2節(jié)進(jìn)行說明)。最后,將關(guān)鍵字出現(xiàn)的頻率與對應(yīng)行為的權(quán)重相乘,得到關(guān)鍵字在某一類行為中的得分,再將關(guān)鍵字在各類行為中的得分求和,得到該關(guān)鍵字在所有購物相關(guān)行為中的總分。
定義4設(shè)對于每個(gè)關(guān)鍵字q,其最終的得分Sq為:
Sq=wL*SLq+wE*SEq
其中,SLq為q在搜索日志中的得分,wL為其對應(yīng)的權(quán)重,SEq為q在購物行為中的得分,wE為其對應(yīng)的權(quán)重。
通過上述計(jì)算,對于每一個(gè)q最終都會有一個(gè)最終的得分Sq與之相對應(yīng),隨著用戶在前端關(guān)鍵字的鍵入,程序?qū)脩糨斎氲年P(guān)鍵字按得分由高到低返回給用戶。
4.2 日志數(shù)據(jù)
我們使用某電商平臺的日志數(shù)據(jù),包括用戶的關(guān)鍵字搜索日志和用戶的購物行為日志。
關(guān)鍵字搜索日志如下所示:
[INFO][2017/05/1023:00:41225][net.shop.controller.shop.ProductController.criteria(ProductController.java:220)]member:8222 keywords:inspire
各屬性含義如下:
member:用戶ID
keywords:用戶搜索關(guān)鍵字
購物行為日志如下所示:
[INFO][2017/06/11 19:11:67210][net.shop.controller.shop.ProductController.listProductById(ProductController.java:515)]member:3785 product_sn:2017052626261
[INFO][2017/06/11 19:23:32240][net.shop.controller.shop.ProductController.favorite(ProductController.java:952)]member:9723 product_sn:2017031362898
[INFO][2017/06/11 19:42:41352][net.shop.controller.shop.CartController.add(CartController.java:86)]member:5627 product_sn:2017060182659
[INFO][2017/06/11 20:01:31250][net.shop.controller.order.OrderController.create(OrderController.java:443)]member:6245 order_sn:201706117488
各屬性含義如下:
net.shop.controller.shop.ProductController.listProductById:瀏覽商品;
net.shop.controller.shop.ProductController.favorite:收藏商品;
net.shop.controller.shop.CartController.add:添加購物車;
net.shop.controller.order.OrderController.create:創(chuàng)建訂單;
product_sn:商品編號;
order_sn:訂單編號。
4.3 MapReduce日志處理流程
MapReduce 是目前比較流行的一個(gè)簡化大規(guī)模數(shù)據(jù)處理的并行計(jì)算框架,用戶通過該框架提供的一些簡單的編程接口,就能方便地對大規(guī)模數(shù)據(jù)進(jìn)行處理[14]。結(jié)合電商查詢建議的需求,本文提出了一種查詢建議QSLM(Query Suggestion based on Log Mining)算法。
QSLM算法中MapReduce的Map函數(shù)和Reduce函數(shù)的詳細(xì)內(nèi)容介紹如下:Map(映射)函數(shù),用來把一組鍵值對映射成一組新的鍵值對,指定并發(fā)的Reduce(歸約)函數(shù),用來合并key值相同的鍵值對。在Map階段是從日志文件中讀取記錄,對于關(guān)鍵字搜索記錄,提取日志中的keywords,以keywords作為Map()方法的key,將關(guān)鍵字權(quán)重作為value;對于用戶行為記錄,提取日志中四類典型購物行為,分別是瀏覽、收藏、添加購物車和下單。根據(jù)前人的研究以及商城運(yùn)營的經(jīng)驗(yàn),為這四類行為設(shè)置權(quán)重。以相關(guān)商品的名稱的分詞作為Map()的key,以各類行為對應(yīng)的權(quán)重作為value。
在Reduce階段,先對Map階段傳過來的鍵值對進(jìn)行分析,根據(jù)value的值即可得知這個(gè)關(guān)鍵字所屬的類型,將同類型的所有關(guān)鍵字求和,然后再與檢索詞詞庫中的歷史數(shù)據(jù)求和,更新檢索詞詞庫。對檢索詞詞庫進(jìn)行遍歷,通過對詞庫中的各類型數(shù)據(jù)加權(quán)、歸一化,生成關(guān)鍵字最后的得分。
QSLM算法的MapReduce處理流程圖2所示。
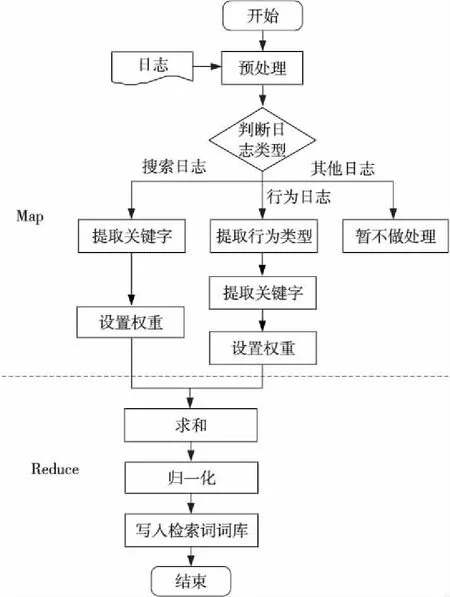
Figure 2 Process of MapReduce圖2 MapReduce處理流程圖
算法偽代碼描述如下:
算法1QSLM算法
輸入:日志文件;
輸出:檢索詞詞庫。
Map()函數(shù):
1.While (讀取日志中的記錄)
2.Regex.matcher();∥正則匹配記錄
3. If 數(shù)據(jù)是搜索記錄
4.Output〈key,value〉=〈搜索詞,關(guān)鍵字權(quán)重〉;
5. Else If數(shù)據(jù)是購物行為記錄
6.names[]=segmentation(商品名稱);/*對商品名稱進(jìn)行分詞*/
7. Fori=0 tonames[].length
8.Output〈key,value〉=〈names[i],購物行為權(quán)重〉;
9. End For
10. End If
11.End while
Reduce()函數(shù):
1.While(讀入鍵值對列表〈key,value〉)
2.type=classify(value);/*根據(jù)value判斷類型,包括Q、B、F、A、O五類*/
3.sumtype=sum(keytype);
4.newtype=sum(sumtype,oldtype);/*newtype,oldtype表示某檢索詞type類型的數(shù)據(jù)在檢索詞詞庫中的新統(tǒng)計(jì)值與舊統(tǒng)計(jì)值*/
5. 將newtype寫入檢索詞詞庫;
6.End while
7.Fori=0 to 檢索詞詞條數(shù)
8.S=Normalization(QC,BC,FC,AC,OC);/*歸一化檢索詞的各個(gè)數(shù)據(jù)*/
9.將S寫入檢索詞詞庫最終得分欄;
10.End For
5 實(shí)驗(yàn)與分析
5.1 實(shí)驗(yàn)環(huán)境
為了驗(yàn)證QSLM算法是否有效,我們搭建了一套實(shí)驗(yàn)環(huán)境進(jìn)行實(shí)驗(yàn)驗(yàn)證。實(shí)驗(yàn)配置為:cnetos 6.5 版本的Linux 操作系統(tǒng),jdk 1.7,Hadoop 版本為 2.3.0。實(shí)驗(yàn)搭建的Hadoop集群為1個(gè)master結(jié)點(diǎn)和4個(gè)worker結(jié)點(diǎn),并開啟了共16個(gè)線程。本文所用實(shí)驗(yàn)數(shù)據(jù)來自于某電商平臺從2015年1月1日~2017年6月5日所產(chǎn)生的日志數(shù)據(jù)。
5.2 評價(jià)指標(biāo)
信息檢索領(lǐng)域最廣為人知的評價(jià)指標(biāo)為Precision-Recall(準(zhǔn)確率-召回率)方法。召回率(Recall)衡量一個(gè)查詢搜索到所有相關(guān)文檔的能力,而準(zhǔn)確率(Precision)衡量搜索系統(tǒng)排除不相關(guān)文檔的能力。
MAP(Mean Average Precison)方法即平均準(zhǔn)確率法的簡稱,其定義為求每個(gè)相關(guān)文檔檢索出后的準(zhǔn)確率的平均值(即Average Precision)的算術(shù)平均值(Mean)。這里對準(zhǔn)確率求了兩次平均,因此稱為Mean Average Precision。MAP是反映系統(tǒng)在全部相關(guān)文檔上性能的單值指標(biāo)。
5.3 實(shí)驗(yàn)內(nèi)容以及結(jié)果分析
實(shí)驗(yàn)1QSLM算法驗(yàn)證。
本實(shí)驗(yàn)以某電商購物網(wǎng)站2017年1月1日~2017年5月31日5個(gè)月的日志數(shù)據(jù)為實(shí)驗(yàn)數(shù)據(jù),以2017年6月1日~2017年6月5日5天的日志數(shù)據(jù)為驗(yàn)證數(shù)據(jù)。通過QSLM算法和基于用戶搜索日志的數(shù)據(jù)挖掘算法對這5天的日志數(shù)據(jù)準(zhǔn)確率、召回率和MAP的比較,驗(yàn)證日志挖掘算法在查詢建議系統(tǒng)中的科學(xué)性與實(shí)用性。實(shí)驗(yàn)數(shù)據(jù)如圖3所示。
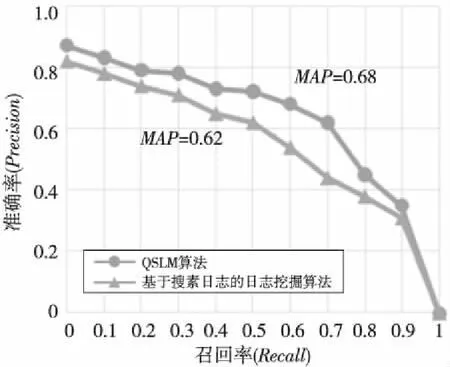
Figure 3 Precision and recall of algorithms圖3 算法準(zhǔn)確率與召回率
從實(shí)驗(yàn)的比較中可以清楚地看到,采用QSLM算法的系統(tǒng)的準(zhǔn)確率和召回率比起基于搜索日志的日志挖掘算法有大幅提高,采用QSLM算法的MAP達(dá)到了0.68,比基于搜索日志的日志挖掘算法的MAP提高了6%。從而驗(yàn)證了QSLM算法在查詢建議系統(tǒng)的高效性。
實(shí)驗(yàn)2Hadoop性能驗(yàn)證。
本實(shí)驗(yàn)將通過比較程序在與Hadoop集群節(jié)點(diǎn)配置完全相同的單機(jī)環(huán)境和Hadoop集群環(huán)境下,分別在4萬、16萬、32萬、64萬日志數(shù)據(jù)中,生成關(guān)鍵字表所用的時(shí)間,說明集群環(huán)境的性能優(yōu)勢。實(shí)驗(yàn)結(jié)果如圖4所示。
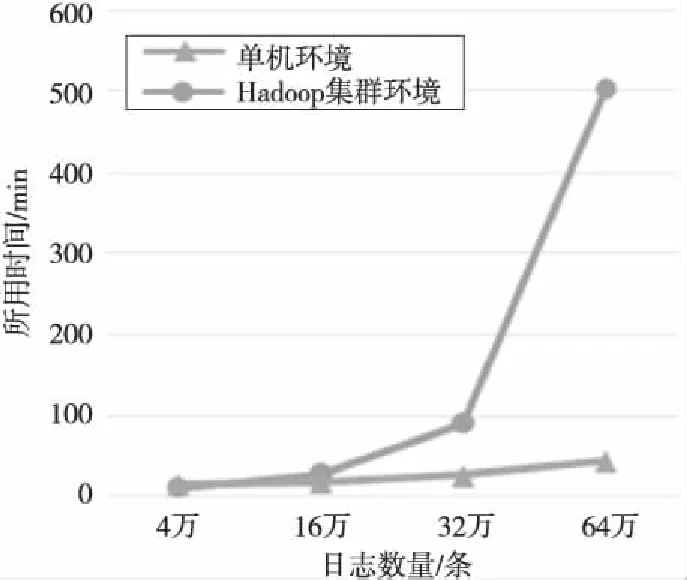
Figure 4 Comparison between single machine and Hadoop圖4 單機(jī)與集群性能對比
通過以上實(shí)驗(yàn),我們發(fā)現(xiàn),當(dāng)數(shù)據(jù)量不大時(shí),Hadoop集群環(huán)境的運(yùn)算速度比單機(jī)環(huán)境下的運(yùn)算速度要慢,但是當(dāng)數(shù)據(jù)量成倍增長時(shí),單機(jī)環(huán)境的運(yùn)行時(shí)間幾乎呈指數(shù)增長,而Hadoop集群環(huán)境的運(yùn)行時(shí)間卻沒有太大的變化。實(shí)驗(yàn)結(jié)果說明了在大規(guī)模日志數(shù)據(jù)的挖掘中,使用集群并行計(jì)算的必要性。
6 結(jié)束語
目前,查詢建議廣泛應(yīng)用于各種搜索引擎。本文針對電商這一特定領(lǐng)域,在總結(jié)前人研究的基礎(chǔ)上,提出了一種基于日志挖掘的電商查詢建議方法,綜合考慮用戶的搜索行為以及購物行為,運(yùn)用MapReduce技術(shù)對用戶日志進(jìn)行挖掘,提取查詢詞并計(jì)算權(quán)重,以此生成檢索詞詞庫;并通過在線計(jì)算與離線計(jì)算結(jié)合的方法,為用戶提供實(shí)時(shí)查詢建議。實(shí)驗(yàn)結(jié)果表明,本文提出的基于日志挖掘的電商查詢建議算法能有效提高查詢建議的準(zhǔn)確率,并且具有良好的處理性能。當(dāng)然本算法還有許多需要改進(jìn)的地方,后續(xù)我們將進(jìn)一步考慮商品庫存、商品時(shí)效性等因素,優(yōu)化檢索詞庫的檢索詞提取以及評分機(jī)制。
[1] Ooi J,Ma X,Qin H,et al.A survey of query expansion,query suggestion and query refinement techniques[C]∥Proc of International Conference on Software Engineering and Computer Systems,2015:112-117.
[2] China Internet Network Information Center. The 39th 《China Statistical Report on Internet Development》[EB/OL].[2017-01-22].http:∥www.cnnic.net.cn.(in Chinese)
[3] Peat H J,Willett P.The limitations of term co-occurrence data for query expansion in document retrieval systems[J].Journal of the Association for Information Science & Technology,1991,42(5):378-383.
[4] Fox E A.Lexical relations:Enhancing effectiveness of information retrieval systems[J].ACM Sigir Forum,1980,15(3):5-36.
[5] Vechtomova O, Robertson S, Jones S. Query expansion with long-span collocates[J].Information Retrieval,2003,6(2):251-273.
[6] Baeza-Yates R,Hurtado C,Mendoza M.Query recommendation using query logs in search engines[C]∥Proc of EDBT 2004,2004:588-596.
[7] Cui Hang, Wen Ji-rong, Li Min-qiang, et al.A statistical query expansion model based on query logs[J].Journal of Software,2003,14(9):1593-1599.(in Chinese)
[8] Wen J,Nie J Y,Zhang H.Query clustering using user logs[J].ACM Transactions on Information Systems,2002,20(1):59-81.
[9] Zhang Z,Nasraoui O.Mining search engine query logs for query recommendation[C]∥Proc of International Conference on World Wide Web,2006:1039-1040.
[10] Billerbeck B,Scholer F,Williams H E,et al.Query expansion using associated queries[C]∥Proc of International Conference on Information & Knowledge Management,2003:2-9.
[11] Hasan M A,Parikh N,Singh G,et al.Query suggestion for E-commerce sites[C]∥Proc of WSDM 2001,2011:765-774.
[12] Yang Q, Ling C X,Gao J.Mining web logs for actionable knowledge[M]∥Intelligent Technologies for Information Analysis.Berlin:Springer,2004:169-191.
[13] Chen Z, Yamamoto T, Tanaka K.Query suggestion for struggling search by struggling flow graph[C]∥Proc of International Conference on Web Intelligence,2017:224-231.
[14] Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[J].Communicatons of the ACM,2008,50(1):107-113.
附中文參考文獻(xiàn):
[2] 中國互聯(lián)網(wǎng)絡(luò)信息中心.第39次《中國互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r統(tǒng)計(jì)報(bào)告》[EB/OL].[2017-01-22].http:∥www.cnnic.net.cn.
[7] 崔航,文繼榮,李敏強(qiáng).基于用戶日志的查詢擴(kuò)展統(tǒng)計(jì)模型[J].軟件學(xué)報(bào),2003,14(9):1593-1599.
猜你喜歡
學(xué)生天地(2020年32期)2020-06-09 02:57:54
人大建設(shè)(2018年9期)2018-11-18 21:59:16
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2017年5期)2017-08-15 00:53:19
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
浙江人大(2014年4期)2014-03-20 16:20:16
