基于最大最小距離的高光譜遙感圖像波段選擇
2018-03-12 01:45:05王立國趙亮石瑤
智能系統學報 2018年1期
關鍵詞:方法
王立國,趙亮,石瑤
(哈爾濱工程大學 信息與通信工程學院,黑龍江 哈爾濱 150001)
隨著遙感技術的快速發展,高光譜圖像分析也有了重大進展。高光譜數據因其波段眾多可以提供地物更精確詳盡的信息,但與此同時也帶來了信息冗余,因而在對數據分析時會產生較高的計算復雜度以及Hughes現象,所以在高光譜圖像處理過程中,降維是其重要環節。遙感數據降維有兩種方法:特征提取和波段選擇。特征提取是用映射的方法將原始數據變換為較少的新特征,常用的方法有主成分分析、獨立成分分析、局部線性嵌入等[1-3]。與特征提取不同,波段選擇依據高光譜遙感數據的特點從原始數據集中選擇合適的波段子集,在不改變原始數據的物理意義及光譜特性的同時降低數據維度,是一種有效的高光譜圖像降維技術。
按照先驗信息的有無,高光譜圖像波段選擇方法可分為監督波段選擇和無監督波段選擇[4]。監督波段選擇一般用一個準則函數來衡量已選波段與帶標簽數據之間的相似度,然后通過一些優化策略來搜索最優波段子集[5]。無監督波段選擇則只需要地物的原始高光譜圖像信息,而無需帶標簽樣本,因而更具有普適性,因此本文主要研究無監督的波段選擇。
無監督的波段選擇方法一般可分為如下幾類:一類是按照信息量以及波段間相關程度排序的方法,一類是基于聚類的方法,此外由于端元選擇與波段選擇問題在模型上具有共性,一些端元選擇方法也用于波段選擇中[6]。最大方差主成分分析方法(maximum-variance principle component analysis,MVPCA)是一種經典的基于信息量的方法,它利用PCA變換獲取各波段的方差,將方差作為信息量的考量標準,然后按照方差的大小進行排序,以確定波段的優先級[7]。基于信息散度(information divergence, ID)的波段選擇方法是用信息散度對全波段計算概率密度分布與其所對應的高斯分布的偏離度,按照偏離度從大到小的順序對波段進行排序,得到所需數目的波段子集[8]。但鑒于高光譜數據的相鄰波段具有較大相關性,按照信息量排序所選定的某波段,其相鄰的波段也極有可能具有相近的信息量,因此也會被選入波段子集,造成冗余。于是,一些同時考慮信息量與相關系數的無監督波段選擇方法被提出來,如最佳指數因子(optimal index factor, OIF)法計算波段的方差與相關系數的比值,再用這個數值來衡量波段的優先次序。但是OIF方法需要多次計算波段間的OIF,因此計算量龐大。自適應波段選擇方法(adaptive band selection,ABS)與OIF方法類似,采用標準差與相關系數的比值作為考量標準,但較之OIF,ABS只計算相鄰波段的相關系數,雖然計算復雜度較低,卻忽視了所選波段子集的整體相關性[9]。近些年,一些學者用聚類的方法進行波段選擇,即將波段按照某衡量準則分成多個子集,用聚類中心代表子集內的其他波段,聚類數目根據所需的波段數確定。具有代表性的方法如基于K均值(K-means)算法的波段選擇,基于譜聚類(spectral clustering, SC)的波段選擇,使用仿射傳播(affinity propagation, AP)的波段選擇等[10-12]。K均值算法簡單易行,但是容易受初值影響,并且所選擇的聚類中心是算術平均的位置,需要進一步處理。基于K-meDOIds的聚類直接選取候選波段作為波段的聚類中心,具有很好的魯棒性,但該方法同樣易受初始值影響,隨著初值的不同而導致最后的聚類中心不同。基于SC的波段選擇方法采用類內波段算術均值而非現實中存在的波段,對噪聲敏感,且每類中隨機選取的波段不一定能夠最好地代表所在的類。基于AP算法的波段選擇方法將每個樣本點都視為候選類代表點,不受初始點選擇的困擾,但相似矩陣的計算復雜度較高。而最大最小距離算法是一種基于試探的聚類算法,它以某種距離作為衡量標準,采用相距盡量遠的樣本作為聚類中心點,可以避免隨機選取的初始聚類中心相距太近的情況[13]。針對現有波段選擇方法的不足,本文提出了一種基于最大最小距離的波段選擇方法,該方法通過迭代計算得到一組初始的距離較遠的波段子集,然后以這些波段為基礎進行聚類更新,獲取具有代表性的波段子集。
1 波段聚類的基礎
高光譜數據的特點是具有極高的光譜分辨率,其相鄰波段間具有較強的相關性,這里的譜間相關性就是指,對空間上某一相同位置,相鄰波段的波段圖像具有相似性。具有這種相似的原因主要是:同一地物在相鄰波段的光反射率是非常相近的,因此產生了一定的相關性。這種相關性可以用相關系數矩陣來描述[14],以AVIRIS采集的印第安農林數據為例,計算其相關系數矩陣和相關系數向量,并將得到的矩陣和向量進行可視化,如圖1。

圖 1 Indian數據譜間相關性的可視化Fig. 1 Visualization of spectral correlation of Indian Pines
圖1中,(a)是以灰度圖像的形式呈現,由灰度圖像的取值特點可知,越明亮的區域其相關系數越大,而明亮區域主要集中于主對角線,因此可以說明相鄰波段間的相關性更強,而從圖1(b)可以直觀看到相關性較強的各個波段范圍。鑒于高光譜圖像波段間具有的這種聚集特性,可以將其看作波段聚類問題,即將波段劃分為具有相似特性的波段組成的集合,選擇這些波段集合中具有代表性的聚類中心,就可以得到數據的一個波段子集,從而完成波段選擇過程。
2 基于最大最小距離的波段選擇
最大最小距離法是模式識別中一種基于試探的
聚類算法,它以歐氏距離為基礎,取盡可能遠的對象作為聚類中心。因此它可以避免K-means算法初值選取時可能出現的聚類種子過于臨近的情況,它不僅能智能確定初始聚類種子的個數,而且提高了劃分初始數據集的效率。所以,本文嘗試利用最大最小距離法進行高光譜圖像的波段選擇,以方差最大的波段作為第一個聚類中心,不斷迭代計算最大最小距離獲取所需數目的聚類中心集合,進而對集合外的剩余波段聚類,最后以K-medoids方法對聚類中心進行更新,獲取最終波段子集,具體描述如下。
2.1 初始化聚類中心
2.1.1 第一個聚類中心的選取
在數據處理上,高光譜圖像用集合B={b1,b2,···,bn}表示,其中,n為波段個數, bi(i=1,2,···,m)為m行的列向量,代表第i個波段,m為波段圖像包含的像素個數,則波段i的標準差值為
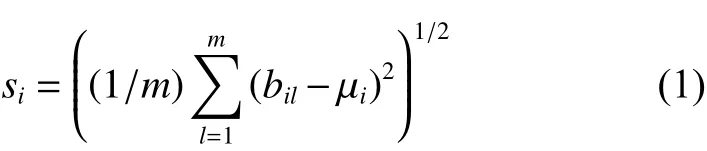
式中 μi為波段i的均值,即
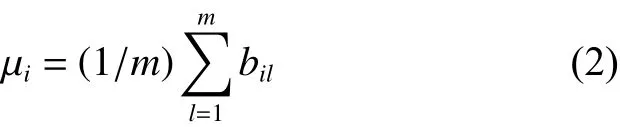
波段均值 μi可以用于表征波段i各地物的平均強度;波段標準差 si可以反應波段i中像素強度與均值的偏離程度,一定程度上反映各波段圖像的信息量,圖像標準差越大,其所包含的信息越豐富,因此可以采用標準差值定量表示波段包含的信息量,并用標準差最大的波段作為最大最小距離算法第1個聚類中心。
2.1.2 其他聚類中心的迭代選取
則Bs={B1}。然后計算B中其他波段與B1的距離,選擇距離最大的波段作為第2個類的聚類中心B2,可表示為


這里 d(·)表示某種距離測度, 則 Bs更新為 {B1,B2}。
當k大于2時,則第k個聚類中心 Bk為B中剩余波段中 bi與 Bs中的波段的最大最小距離,表示為

式中 MINk?1=min{d(bi,B1),d(bi,B2),···,d(bi,Bk?1)},此時 Bs更新為 { B1,B2,···,Bk}。
2.2 更新聚類中心
通過最大最小距離方法得到了相互距離較遠的一組波段,在原本的最大最小距離算法中會將這組波段作為聚類中心,然后計算其他波段與這些中心的距離,以距離最小為原則劃分類別。雖然這些波段間的區分度較高,但會導致聚類中心與簇內相距較遠波段的相關性較低,而對于波段選擇來說,其最終得到的應該是具有代表性的波段,也就是說,該波段到簇內其他波段間的代價函數應該最小。因此將這些“激進”但區分度又高的波段組合作為一個初始的聚類中心,然后采用對噪聲較不敏感的K-meDOIds算法更新聚類中心,得到最終的波段組合。具體的步驟如下:
3)在每一個類內,選擇代價函數最小的波段作為新的聚類中心;
4)重復2)、3)直至各類的中心點穩定,此時算法結束。
算法的整體流程如下。
算法 基于最大最小距離的波段選擇方法
輸入 給定所需的波段數目k。
1)根據式(1)、(2)計算每個波段的標準差si,取標準差最大的波段作為1個聚類中心;
5)用K-meDOIds算法更新聚類中心,輸出最終的波段組合。
3 實驗與分析
為驗證本文算法的有效性,采用真實高光譜數據進行了仿真實驗,同時與基于K-meDOIds,基于AP,以及基于ABS的典型波段選擇算法進行比較。第1種和第2種是基于聚類方法的波段選擇,第3種是同時考量了信息量與相關性的波段選擇方法。實驗環境為AMD雙核處理器,主頻2.47 Hz,有效內存3 GB,開發環境為MATLAB R2008a。
實驗數據為去除噪聲波段的200波段的AVIRIS印第安農林數據和103波段的ROSIS帕維亞大學數據:
1)印第安農林數據的波長范圍為0.4~2.5 μm,空間分辨率為17 m,共有144×144個像素點。數據中剔除背景共包含16類地物,主要農作物是生長期的玉米和大豆,結合地面實際測量數據,其中7種地物樣本量過少,對于該數據不具有代表性,因此選取另9種樣本數目較多的主要類型地物用于實驗。
2)帕維亞大學數據波長范圍為0.43~0.86 μm,空間分辨率為1.3 m,共有610×340個像素點,共包含9類地物,實驗中9種地物均用于實驗。兩組數據所對應的地物真實情況如圖2、圖3所示,9種地物類型及數目如表1所示。

圖 2 Indian數據Fig. 2 Land covers at Indian pines

圖 3 PaviaU數據Fig. 3 Land covers at university of Pavia
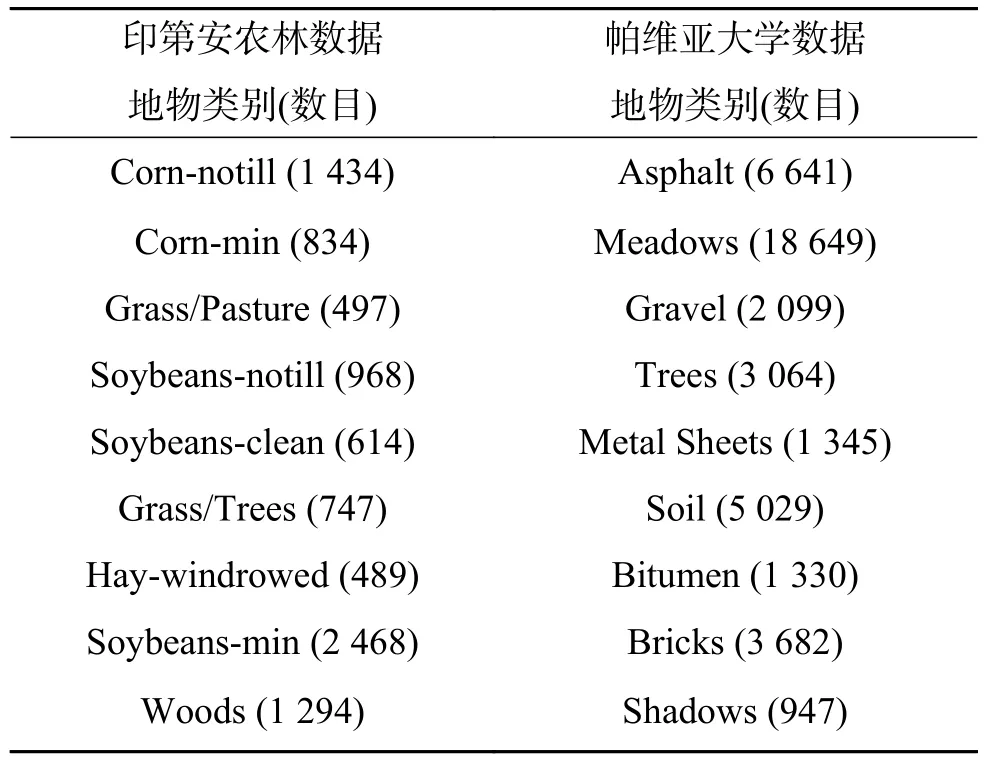
表 1 印第安農林數據和帕維亞大學數據地物類別Table 1 Land covers at Indian pines and university of pavia
3.1 評價標準
對于高光譜遙感圖像,一般評價所選波段組合的優劣主要是面向應用的角度,其中地物的分類是一個重要的應用方法,因此本文以總體分類精度(overall accuracy, OA)為主評價波段選擇方法的質量,同時輔助地考慮波段子集的平均相關性、信息貢獻率、最佳指數(optimum index factor, OIF),計算公式為

式中:C為樣本總數,Rij為波段i和波段j的相關系數,計算公式為


式中:n為波段總數,m為所選波段的個數,通常m≤n ,λg(g=1,2,···,m)是所選波段經主成分變換后的特征值;λk(k=1,2,···,n)是全波段主成分變換得到的特征值。

式中:Si是第i波段的標準差。

式中:mii為第i類測試樣本被正確分類的樣本數,c為樣本類別數[15]。
3.2 結果分析
為定量比較幾種波段選擇方法隨所選波段數目的變化趨勢,所以選擇連續變化的波段數目。分類采用最大似然分類法,訓練樣本數目與測試樣本數目各占總樣本數目的一半。同時,也將只進行最大最小距離選擇而未更新聚類中心的結果進行比較,在效果評價圖中用MMD表示,本文算法記作MMDK。各波段選擇算法在兩組數據上所選波段子集的總體分類精度、最佳指數、信息貢獻率、平均相關性和總體分類精度的結果分別繪制于圖4、5中。下面分別對兩組數據的實驗結果進行分析。
3.2.1 Indian數據集
Indian數據集所選的波段數目為5~15,從兩方面分析各算法在該數據集上所選波段的性能。

圖 4 不同波段選擇方法在Indian數據的效果評價Fig. 4 Evaluation of effects of different wavelength selection methods for Indian data
1)分類結果分析
從圖4(a)中可以看到,AP、ABS、MMD和本文所提算法所得波段的總體分類精度隨波段數目的增加而穩定上升,但無論所選的波段數目是多少,本文所提算法獲取的波段組合總能夠得到最高的分類精度。而MMD雖然選擇了光譜維度上“距離”較遠的波段,但分類效果并不理想,這也說明“激進”的波段并不能代表其所在的聚類,需要進一步更新聚類中心。K-meDOIds算法所選的波段組合隨波段數目的增加具有波動性,再一次證明初始聚類中心對于保證波段選擇效果的重要性。

圖 5 不同波段選擇方法在PaviaU數據的效果評價Fig. 5 Evaluation of effects of different wavelength selection methods for PaviaU data
2)信息量與相關性結果分析
對于信息量與相關性的考量則需要結合圖4(b)、(c)、(d)一起分析。從圖4中可以看出,ABS算法在信息量及綜合考慮二者的OIF上均表現得很優秀,這是由于ABS是基于OIF而進行的改進,采用標準差與相關系數的比值作為考量標準,但ABS相較OIF是只計算相鄰波段的相關系數,忽視了所選波段子集的整體相關性,因此其平均相關性較低。K-meDOIds算法受隨機初始化的影響,所選的波段組合依然不穩定。本文所提算法在平均相關性與信息量上結果居中,與MMDK相比平均相關性稍高,信息量也較小,但卻說明一個問題: 具有高信息量與低相關性的波段組合不一定是最能體現各波段聚類的,并且應用到實際問題中時的表現也不一定最優。這是因為,若以信息量大小排序來選擇波段,當某波段入選,則相鄰波段由于具有與其近似的波段圖像,因此相鄰波段也具有較高的入選優先性。雖然OIF考慮了相關性,但直接用方差與相關系數的比值來全面衡量二者,其結果較為生硬。
3.2.2 PaviaU數據集
PaviaU數據集所選的波段數目為3~13,同樣從兩方面分析各算法在該數據集上所選波段的性能。
1) 分類性能分析
因為PaviaU數據集的空間分辨率較高,混合像素較少,并且地物種類與Indian數據相比,類別差異性更大,相對而言更容易區分,分類精度也更高。圖5(a)中MMDK算法始終保持著較高的分類精度,而ABS算法在波段數目為3時分類精度較低,這是由于ABS算法雖以信息量與相關性為選擇波段的標準,但其為計算便捷,會忽略波段組合整體相關性,因此容易選出相關性較高的波段子集,當所選波段數據較少時,這種差異性較其他方法會更明顯。隨機選擇初始聚類中心的K-meDOIds算法整體依然存在波動性。AP算法在波段數目3~6區間時,具有較好的分類精度,但當大于6時相較MMDK分類精度低,這與AP算法中參考度p有關,p代表著相似度值,其值越大則簇越多,所以需要較多的簇時,p就需要取較大的相似度值,使得其各簇中心相似度較高,而對于波段選擇來說,這是不利的。MMD算法整體分類精度與MMDK相仿,這主要是由于該數據相似波段之間距離較小,波段聚集密度較高,所以二者具有水平相當的分類能力。
2)信息量與相關性結果分析
結合圖5(b)、(c)、(d)來分析各算法在PaviaU數據集所選波段子集包含的信息量與平均相關性可以看到,ABS算法在OIF值上依然整體占優,其他幾種算法有著接近的OIF值。在信息量貢獻率上ABS同樣較其他算法得到較高的貢獻率,但其平均相關性也更高,這依然由ABS算法優先將近似的但擁有較大信息量的波段選擇到子集中,忽略波段子集的整體相關性導致。其他幾種聚類算法除K-meDOIds具有波動性外,在各評價函數上均相差不大,這是由于PaviaU數據各波段簇較緊密所致。
通過兩組數據的實驗可以看出,MMDK算法所選的波段子集在兩種數據集上均獲得較高的分類精度,且其各性能隨波段數目的增加均呈現平穩趨勢,證明了算法的有效性與穩定性。而基于聚類的波段選擇與基于信息屬性的波段選擇方法也有不同,基于聚類的波段選擇更傾向于選擇最具代表性的,而不是波段本身差異性大的,因此波段子集的信息量較基于信息屬性所選擇的波段子集低。而MMDK在信息量與相關性的評價中,雖始終居中,但這符合波段聚類中心需要更有代表性,而不是差異性大的選擇標準。綜上,可以得出結論,MMDK算法是一種行之有效的波段選擇方法。
4 結束語
本文針對高光譜圖像波段冗余問題,提出了基于最大最小距離的波段選擇算法,該算法只需要輸入待選波段的數目,不需要進行其他參數的設置,通過迭代計算已選波段與待選波段間的最大最小距離獲取初始的聚類中心,然后用K-meDOIds更新此聚類中心,最終輸出波段子集。此方法物理意義明確,便于實現。與基于K-meDOIds算法、基于AP算法、基于ABS算法的波段選擇方法所進行的對比實驗表明,基于MMDK算法的波段選擇方法較其他3種典型波段選擇算法在分類精度方面更理想,生成的波段組合也更穩定,更加能夠滿足實際需求。
未來的研究工作可從如下兩方面展開:1)本文在計算距離時,采用的是歐氏距離,而衡量波段間區分性的還有光譜角距離、Bhattacharyya距離、JM距離等,不同的距離計算方式對聚類結果的影響如何,有待討論;2)文中是通過給定波段子集大小的方式確定聚類中心的個數,而若給定的數目太小則不足以描述數據,給定的數目過多又會造成冗余,同樣影響后續應用的效果,因此如何自動地確定不同數據集所需的波段數目也是一個值得研究的問題。
[1]AGARWAL A, EL-GHAZAWI T, EL-ASKARY H, et al.Efficient hierarchical-PCA dimension reduction for hyperspectral imagery[C]//Proceedings of 2007 IEEE International Symposium on Signal Processing and Information Technology. Giza, Egypt, 2007: 353–356.
[2]WANG Jing, CHANG C I. Independent component analysis-based dimensionality reduction with applications in hyperspectral image analysis[J]. IEEE transactions on geoscience and remote sensing, 2006, 44(6): 1586–1600.
[3]LI Wei, PRASAD S, FOWLER J E, et al. Locality-preserving dimensionality reduction and classification for hyperspectral image analysis[J]. IEEE transactions on geoscience and remote sensing, 2012, 50(4): 1185–1198.
[4]劉雪松, 葛亮, 王斌, 等. 基于最大信息量的高光譜遙感圖像無監督波段選擇方法[J]. 紅外與毫米波學報, 2012,31(2): 166–170, 176.LIU Xuesong, GE Liang, WANG Bin, et al. An unsupervised band selection algorithm for hyperspectral imagery based on maximal information[J]. Journal of infrared and millimeter waves, 2012, 31(2): 166–170, 176.
[5]FENG Jie, JIAO L C, ZHANG Xiangrong, et al. Hyperspectral band selection based on trivariate mutual information and clonal selection[J]. IEEE transactions on geoscience and remote sensing, 2014, 52(7): 4092–4105.
[6]王立國, 鄧祿群, 張晶. 改進的SGA端元選擇的快速方法[J]. 應用科技, 2010, 37(4): 1–22.WANG Liguo, DENG Luqun, ZHANG Jing. A fast endmember selection method based on simplex growing algorithm[J]. Applied science and technology, 2010, 37(4):1–22.
[7]CHANG C I, DU Qian, SUN T L, et al. A joint band prioritization and band-decorrelation approach to band selection for hyperspectral image classification[J]. IEEE transactions on geoscience and remote sensing, 1999, 37(6): 2631–2641.
[8]CHANG C I, WANG Su. Constrained band selection for hyperspectral imagery[J]. IEEE transactions on geoscience and remote sensing, 2006, 44(6): 1575–1585.
[9]劉春紅, 趙春暉, 張凌雁. 一種新的高光譜遙感圖像降維方法[J]. 中國圖象圖形學報, 2015, 10(2): 218–222.LIU Chunhong, ZHAO Chunhui, ZHANG Lingyan. A new method of hyperspectral remote sensing image dimensional reduction[J]. Journal of image and graphics, 2015, 10(2):218–222.
[10]AHMAD M, HAQ I U, MUSHTAQ Q, et al. A new statistical approach for band clustering and band selection using K-means clustering[J]. IACSIT international journal of engineering and technology, 2011, 3(6): 606–614.
[11]秦方普, 張愛武, 王書民, 等. 基于譜聚類與類間可分性因子的高光譜波段選擇[J]. 光譜學與光譜分析, 2015,35(5): 1357–1364.QIN Fangpu, ZHANG Aiwu, WANG Shumin, et al. Hyperspectral band selection based on spectral clustering and inter-class separability factor[J]. Spectroscopy and spectral analysis, 2015, 35(5): 1357–1364.
[12]DUECK D. Affinity propagation: clustering data by passing messages[D]. Toronto, Canada: University of Toronto, 2009.
[13]成衛青, 盧艷虹. 一種基于最大最小距離和SSE的自適應聚類算法[J]. 南京郵電大學學報: 自然科學版, 2015,35(2): 102–107.CHENG Weiqing, LU Yanhong. Adaptive clustering algorithm based on maximum and minmum distances, and SSE[J]. Journal of Nanjing university of posts and telecommunications: natural science edition, 2015, 35(2): 102–107.
[14]劉穎, 谷延鋒, 張曄, 等. 一種高光譜圖像波段選擇的快速混合搜索算法[J]. 光學技術, 2007, 33(2): 258–261,265.LIU Ying, GU Yanfeng, ZHANG Ye, et al. A fast hybrid search algorithm for band selection in hyperspectral images[J]. Optical technique, 2007, 33(2): 258–261, 265.
[15]王立國, 肖倩. 結合Gabor濾波和同質性判定的高光譜圖像分類[J]. 應用科技, 2013, 40(4): 21–26.WANG Liguo, XIAO Qian. Hyperspectral imagery classification combined with Gabor filtering and homogeneity discrimination[J]. Applied science and technology, 2013,40(4): 21–26.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
