基于交叉熵和空間分割的全局可靠性靈敏度分析
2018-03-15 10:14:35趙翔李洪雙
航空學報 2018年2期
關鍵詞:方法
趙翔,李洪雙
南京航空航天大學 航空宇航學院,南京 210016
在結構和系統隨機不確定性分析領域,靈敏度分析作為一個新熱點,旨在研究輸入不確定性如何影響系統的輸出不確定性[1]。靈敏度分析可分為局部靈敏度[2]和全局靈敏度[3]兩種。局部靈敏度通常定義為輸入變量取名義值時系統功能函數對該變量的偏導數[2],因而其不能反映輸入變量的完整不確定性范圍對輸出響應不確定性的影響。全局靈敏度可以從輸入變量的整個定義范圍衡量該變量對輸出不確定性的貢獻程度,因此更加具有實際應用潛能。
全局靈敏度能夠基于輸入變量對輸出響應不確定性影響程度的大小,對它們進行重要度排序,從而對結構和系統可靠性分析、預測與優化提供指導。全局靈敏度分析方法主要包括:非參數方法[4-5]、基于方差的方法[6-7]以及矩獨立方法[8]。非參數方法僅適用于線性輸入輸出關系,缺乏模型的獨立性。雖然基于方差的方法滿足全局靈敏度指標的定義標準,即全局性、可量化性和通用性[3],但該方法使用方差(即二階矩)來表征不確定性信息,不可避免地會帶來分布信息的損失[9]。為了反映輸入變量對輸出響應整個分布的影響,Borgonovo[8]提出了矩獨立全局靈敏度指標,該指標不僅滿足“全局性、可量化性、通用性”,同時也滿足“矩獨立性”。在矩獨立靈敏度指標的基礎上,Cui等[10]提出了基于失效概率的全局靈敏度指標,即全局可靠性靈敏度指標,以此來衡量輸入變量的不確定性對結構失效概率的影響程度。Li等[11]推導了該指標與基于方差的重要度指標之間的關系,為可靠性靈敏度分析的計算提供了一條可行的新途徑。然而,如何高效準確地計算全局可靠性靈敏度指標仍是目前亟待解決的問題。
目前基本求解方法主要分為兩種:代理模型方法[12]和數字模擬方法[13]。前者使用代理模型逼近系統的輸入隨機變量與輸出響應之間的關系,之后基于該代理模型計算靈敏度指標,該方法極大地提高了計算效率,但其計算精度主要依賴于代理模型的準確性。數字模擬法在失效概率評估和重要度分析上具有較好的相容性,因此在基于失效概率的全局靈敏度研究中,數字模擬法更為通用。Wei等[13]給出了3種計算基于失效概率的全局重要度的數字模擬法,包括蒙特卡羅仿真(Monte Carlo Simulation,MCS)法、重要抽樣(Importance Sampling,IS)法和截斷重要抽樣(Truncated Importance Sampling,TIS)法。3種方法之中,重要抽樣方法和截斷重要抽樣方法計算效率較高,但是設計點個數及其位置求解困難,以致重要抽樣密度函數難以確定,導致應用范圍受到限制。在文獻[13]的基礎上,任超和李洪雙[14]使用交叉熵方法計算失效概率全局靈敏度指標,有效地解決了傳統重要抽樣法中重要抽樣函數難以確定的困難,但此算法的計算量仍然與輸入隨機變量的維數相關,對于高維問題以及復雜的工程模型,計算量依然是一個巨大的挑戰。顯然,在數字模擬法中,每個樣本均包含所有輸入變量的相關信息,但以往的處理方法不能最大限度地利用每個樣本所包含的信息,樣本利用率低,導致計算量與問題維數有關。
針對現有方法的不足,本文提出一種將交叉熵方法[15-16]和空間分割方法[17-20]相結合的新全局可靠性靈敏度分析方法。該方法使用交叉熵方法自適應的確定重要抽樣密度函數,從而避免確定設計點個數及位置。通過新重要抽樣密度函數增加樣本落入失效域的概率,提高抽樣效率。再對所得的重要抽樣樣本進行不同的劃分進而得到各個變量的全局靈敏度指標。通過數值算例和工程算例的計算結果可以看出:本文所提方法解決了重要抽樣函數難以確定的問題,并且只需重復利用一組樣本,即可計算出所有變量的可靠性靈敏度指標,計算量與問題維數無關,大大提高了樣本利用率。
1 基于失效概率的全局靈敏度分析
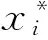
(1)
式中:E(·)為期望算子;fXi(xi)為輸入隨機變量Xi的概率密度函數。失效概率PfY的定義為
(2)
式中:fX(x)為輸入隨機變量X的聯合概率密度函數,IF為失效域指示函數,其定義為
IF=1g(X)≤0
0g(X)>0
(3)
類似于無條件失效概率,條件失效概率PfY|Xi可以表示為
PfY|Xi=E(IF|Xi)
(4)
將式(2)和式(4)代入式(1)中,可將基于失效概率的全局靈敏度指標轉變為以IF為輸出的基于方差的全局靈敏度指標[11]:
V(E(IF|Xi))
(5)
式中:V(·)為方差算子。
Wei等[13]通過添加一個常數項V(IF),使得基于失效概率的全局靈敏度分析和基于方差的全局靈敏度分析在形式上得到統一,即基于失效概率的全局靈敏度指標的方差形式:
(6)
式中:Si為一階靈敏度指標。
對式(6)使用全期望公式和全方差公式,式(6)可進一步化為
(7)
2 新全局可靠性靈敏度分析方法
由第1節可知:式(1)轉化為式(6)的形式后,可以將基于方差的重要度指標計算方法應用至全局可靠性靈敏度指標的計算之中。因此,可以使用高效的抽樣算法計算原本比較難以求解的積分問題。進一步,由式(7)可知:選用一種能夠高效計算失效概率PfY的抽樣方法,可以大大降低計算量。
直接使用蒙特卡羅法,概念簡單,容易編程實現,適應范圍廣,對問題的維數和復雜性沒有特殊要求。但是對于失效概率很小的結構或者系統,直接蒙特卡羅方法必須使用大量的隨機樣本才能保證估計值收斂,計算效率低下。
重要抽樣法在直接蒙特卡羅方法的基礎上引入重要抽樣密度函數hX(x),提高了隨機樣本出現在“失效域”的頻率,進而提高了抽樣效率。式(2)所示的概率積分可以表示為
(8)
重要抽樣法通常是將抽樣中心選擇在設計點處,使更多的樣本點落入失效域,因此有著較高的抽樣效率。但在實際應用過程中,該方法對于多設計點問題或者非線性程度較大的情況,設計點難以求解,重要抽樣密度函數構造困難。然而實際上重要抽樣密度函數的好壞將直接影響計算結果的精度和效率。
交叉熵方法(Cross Entropy Method)是一種自適應的重要抽樣法,其概念由Rubinstein[15]于1997年最先提出用于稀疏事件的模擬,隨后Rubinstein[16]又將其拓展為隨機優化方法。交叉熵方法的主要思想是移動抽樣中心至對失效概率貢獻較大的區域,這與傳統重要抽樣方法相同。不同之處在于:交叉熵方法采用序貫方式確定重要抽樣密度函數,避免了重要抽樣法中重要抽樣密度函數難以確定的困難。
2.1 交叉熵方法
設fX(x)和hX(x)是給定的2個概率密度函數,則fX(x)和hX(x)對于fX(x)的交叉熵定義為2個概率密度函數比值對數的期望,即
(9)
式中:D(·,·)為交叉熵。
由式(9)可知:當fX(x)=hX(x)時,D(f,h)=0。設fX(x;θ)為基本輸入隨機變量的概率密度函數,其中θ為分布參數。根據重要抽樣法相關結論,最優重要抽樣密度函數為[21]
(10)
(11)
式(11)中,右端第一項為定值,因此最小化D(h*,h)等價于
maxE[IF(x)ln(hX(x;v))]
(12)
對于式(12)的最大化問題,通常情況下,沒有解析解,因此需要采用隨機抽樣方法進行求解。使用直接蒙特卡羅方法,根據原分布fX(x;θ),抽取N個隨機樣本(x1,x2,…,xN),式(12)可以轉化為
(13)
對于稀疏事件,仍然存在大部分示性函數IF(xi)=0的困難。因此,可以引入另一個重要抽樣過程,其重要抽樣密度函數為hX(x;w),定義權函數為
(14)
式中:w為分布參數。
則式(12)轉變為
maxE[IF(x)W(x)ln(fX(x;v))]
(15)
從重要抽樣密度函數hX(x;w)中抽取N個隨機樣本點(x1,x2,…,xN),則式(15)的隨機對應問題變為
(16)
可以證明式(16)的優化問題關于v是凸且可微的,并且對于常用的正態分布、指數分布和威布爾分布等自然指數分布族,式(16)存在解析解。考慮一維正態分布,分布參數為(μ,σ),式(16)與式(17)的最小化問題等價[21]:
(17)
很容易可以得出最小化問題的最優解為[21]
(18)
(19)
式中:Ii=IF(xi)。
可以將式(18)和式(19)直接拓展至多維隨機正態向量的情況。然而當失效概率非常小時,應用以上結果仍然很困難,主要是因為大部分的隨機樣本還是落在失效域之外。因此Rubinstein[15-16]提出了多層交叉熵方法(Multi-Level Cross Entropy Method)。該方法是通過增加一個控制參數ρ——中間失效概率,產生中間失效事件,并使得中間失效事件逐漸向失效域靠近。由此構建交叉熵算法:
1) 初始化待定分布參數v0=θ,迭代計數j=0。
2) 從hX(x;vj)產生N個隨機樣本(x1,x2,…,xN),計算功能函數值(g(xi)),并且對(g(xi))從小到大排序,得到(gi),求得功能函數值次序統計量的ρ分位數bj=g[ρN]。
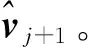
4) 若bj>0,設j=j+1,轉步驟2)。
5) 基于最終的重要抽樣密度函數,生成隨機樣本。
文獻[14]所提方法通過交叉熵方法確定重要抽樣密度函數之后,為求得所有輸入隨機變量的可靠性靈敏度指標,首先抽樣兩個N×n的樣本矩陣A和B,然后構造矩陣Ci(i=1,2,…,n),該矩陣為B的第i列被A的第i列替代后的矩陣,最后根據樣本矩陣A、B、Ci(i=1,2,…,n)計算可靠性靈敏度指標,具體計算細節見文獻[14]。使用該方法計算靈敏度指標的總的計算量為N(n+2)+Nce,其中,Nce為使用交叉熵方法確定抽樣中心所需樣本數。可以看出,文獻[14]所提方法的計算量與問題的維數相關,模型維數增加,其計算量也隨之增加。
2.2 基于交叉熵和空間分割的Si的近似計算
本節參考Zhai等在文獻[17]中所提的基于方差的空間分割方法,給出基于失效概率的全局靈敏度指標的高效計算方法,該算法的計算量與問題維數無關。根據式(7)可知,可以通過計算E[E2(IF|Xi)]進而得到Si的估計值:
(20)
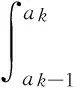
(21)
由式(21)可知,只需計算出Pk、E(IF|Xi∈Ak)和PfY,便可得到隨機變量的可靠性靈敏度指標Si。其中Pk和PfY的計算前文已經提到,下面著重推導E(IF|Xi∈Ak)的計算:
(22)
至此,將式(22)代入式(21)中即可得到失效概率矩陣獨立全局靈敏度指標。2.3節將給出本文所提方法的具體計算流程。
2.3 基于失效概率的全局靈敏度的計算流程
步驟1根據交叉熵方法確定重要抽樣函數,具體實施過程見2.1節。
步驟2基于步驟1所得的重要抽樣密度函數hX(x),抽樣N×n的樣本矩陣A。
(23)
步驟3根據失效域指示函數IF的定義,計算樣本矩陣A對應的IF(x);根據失效概率的定義,計算PfY:
(24)
步驟4將Xi的樣本空間等樣本數的連續的分為s個無重疊的子區間,Ak=[ak-1,ak),1≤k≤s
步驟5根據Ak,找到與之對應的樣本輸出IF的子集,即:Bk=(IF|Xi∈Ak)
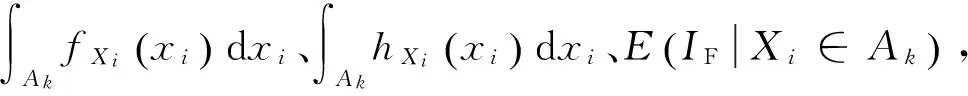
(25)
(26)
(27)
(28)
步驟7將式(28)代入式(21)中,可得Si的估計值。本文所提的基于交叉熵和空間分割計算全局靈敏度的方法,規避了常規重要抽樣法中確定重要抽樣函數的困難,并且僅需一組樣本,便可計算出所有變量的靈敏度指標,計算量與問題維數無關,提高了計算效率。能夠較好地解決多設計點問題和小失效概率問題。
2.4 空間分割策略
在空間分割方法中,采用何種劃分方式將關系到計算結果的好壞[18-20]。文獻[18]提出幾種不同的分割方法,Plischke等[20]指出等樣本數目劃分是一種簡單有效的方法,Li和Mahadevan在文獻[19]也使用了這種分割方法,因此本文采用等樣本數目劃分的方式計算。
3 算例分析
本節通過1個數值算例和2個工程算例說明所提方法的合理性和高效性,并與蒙特卡羅法以及文獻[14]所提方法的計算結果進行對比分析。為公平地比較每種方法的效率和精度,文中給出100次重復計算結果的方差和均值。
算例1考慮一個結構系統,其極限狀態函數為
(29)
式中:Xi(i=1,2,3)~N(0,1)。將蒙特卡羅法計算所得結果,作為參照解。本文使用交叉熵方法確定抽樣中心,單層樣本量N0=1 000,初始參數ρ=0.07,在該算例中多層交叉熵的迭代次數僅為1次,使用1 000個樣本點,用于確定重要抽樣密度。根據交叉熵方法所得重要抽樣密度函數,抽樣1 000個隨機樣本,計算失效概率,基于評估失效概率所使用的這組樣本,利用空間分割方法,計算變量的靈敏度指標。計算結果如表1和圖1所示,表中Ncall為每次計算需要調用極限狀態函數的次數。
從圖1可以看出,文獻[14]所提方法與本文所提方法計算結果均與參照解吻合較好,從而說明了文中所提方法的正確性;由表1中100次重復計算結果的方差容易看出,在方差相當的情況下,本文所提方法調用極限狀態函數的次數明顯小于文獻[14],說明所提方法的樣本利用率以及計算效率更高。這是因為本文方法只需重復利用產生的一組樣本,即可得到所有變量的靈敏度指標,而文獻[14]所提方法計算量與問題維數相關,為Ncall=N(n+2)+Nce。
由計算結果可知輸入隨機變量的重要度排序為X3>X2>X1,顯然,若能設法減少輸入隨機變量X3的不確定性,可以有效地降低結構系統的失效概率。
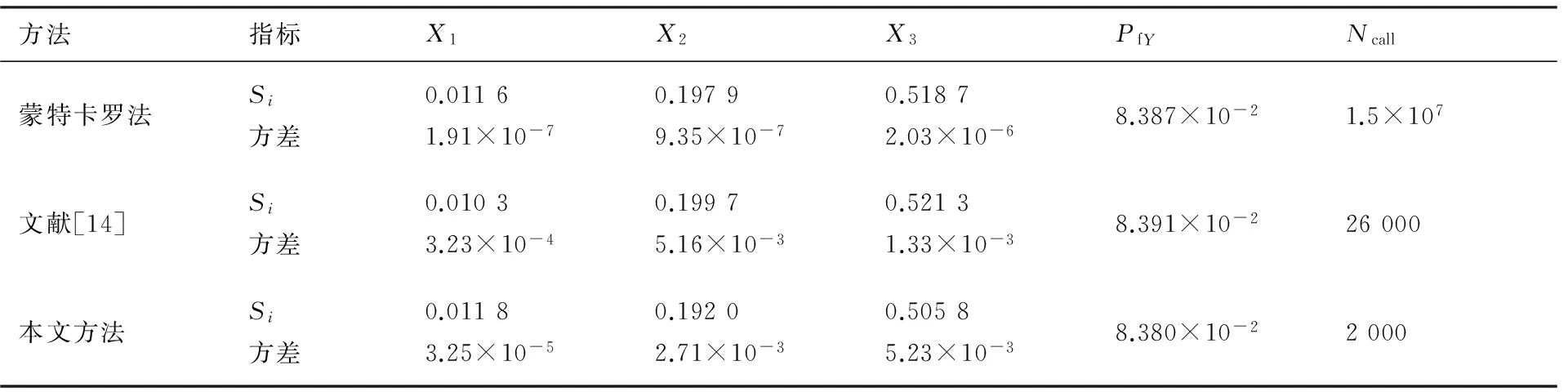
表1 算例1基于全局可靠性靈敏度計算結果Table 1 Results of global sensitivity analysis for Example 1
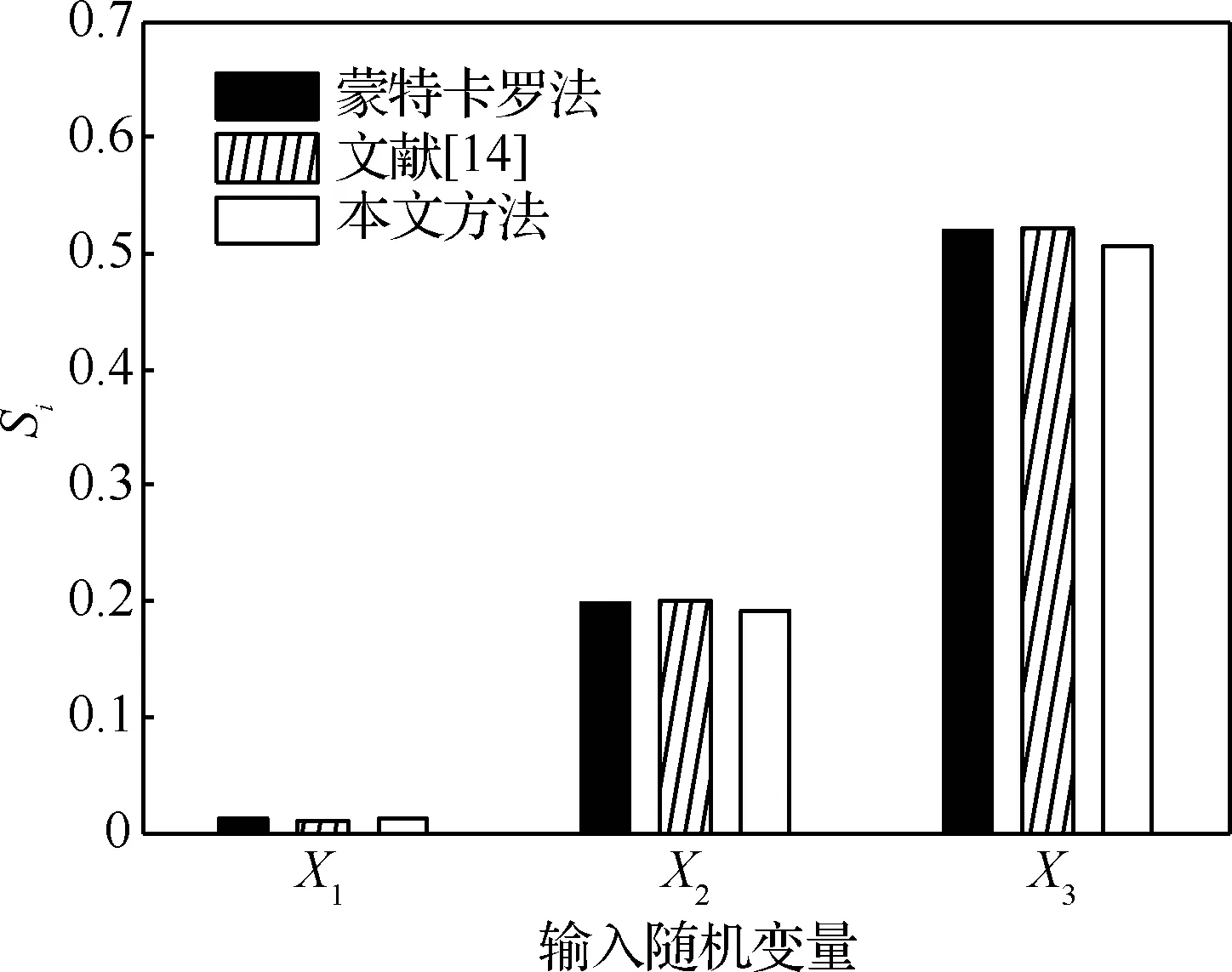
圖1 算例1重要性測度結果Fig.1 Results of importance measure of Example 1
算例2考慮屋架問題
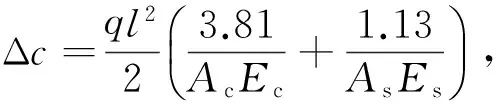
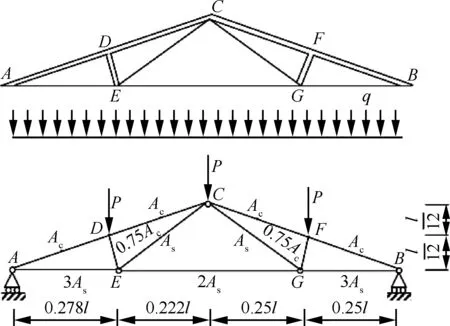
圖2 屋架結構的簡單示意圖Fig.2 Schematic diagram of roof truss
本算例中,使用蒙特卡羅法的計算結果作為參照解,為方便對比,將表3的計算結果繪制成柱狀圖(圖3)。由圖3可以看出:本文方法與參照解吻合較好,從而說明其準確性。根據表3易得,與文獻[14]方法相比,在穩健性相當的情況下,本文方法使用的樣本數與問題維數無關,其計算效率更高。
由圖3進一步可知:本文所提方法得到的輸入變量的重要性排序與蒙特卡羅方法所得排序一致,均為:Ac>q>Es>As>l>Ec。可以看出,混凝土的截面積Ac的重要度較之其他變量大許多,因此降低Ac的不確定性可以最大程度地改善結構的可靠性。
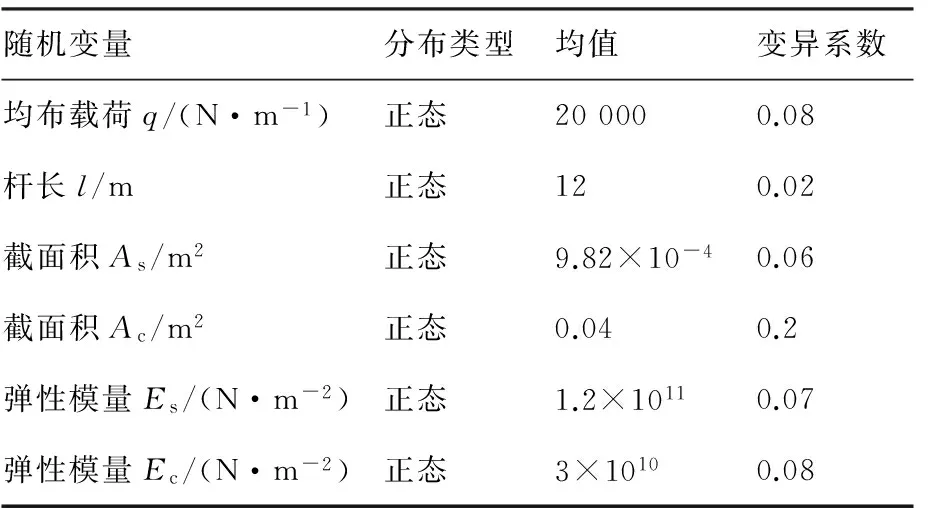
表2 屋架結構的隨機變量的分布參數
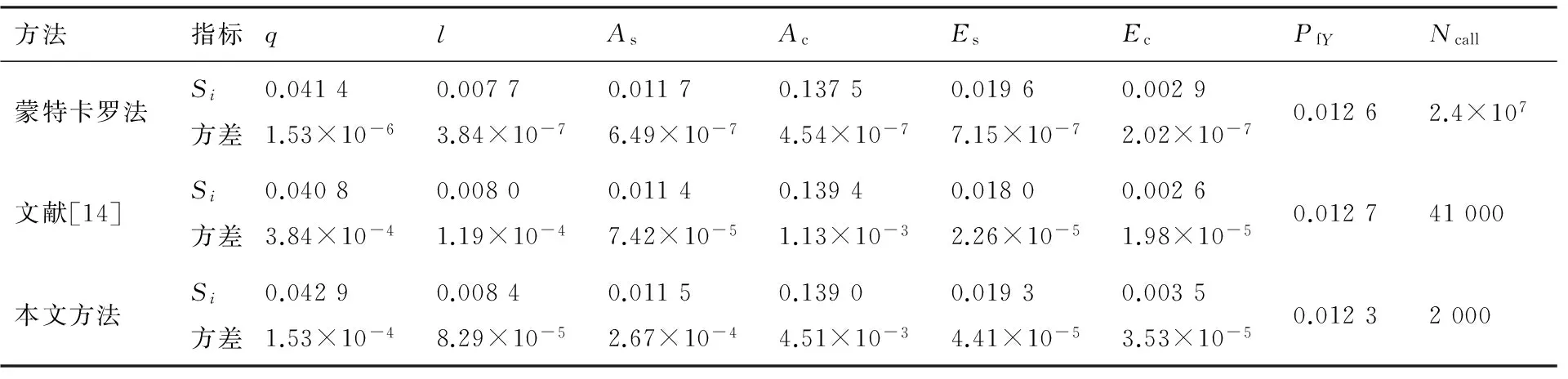
表3 屋架結構的全局可靠性靈敏度計算結果Table 3 Results of global sensitivity analysis for roof truss
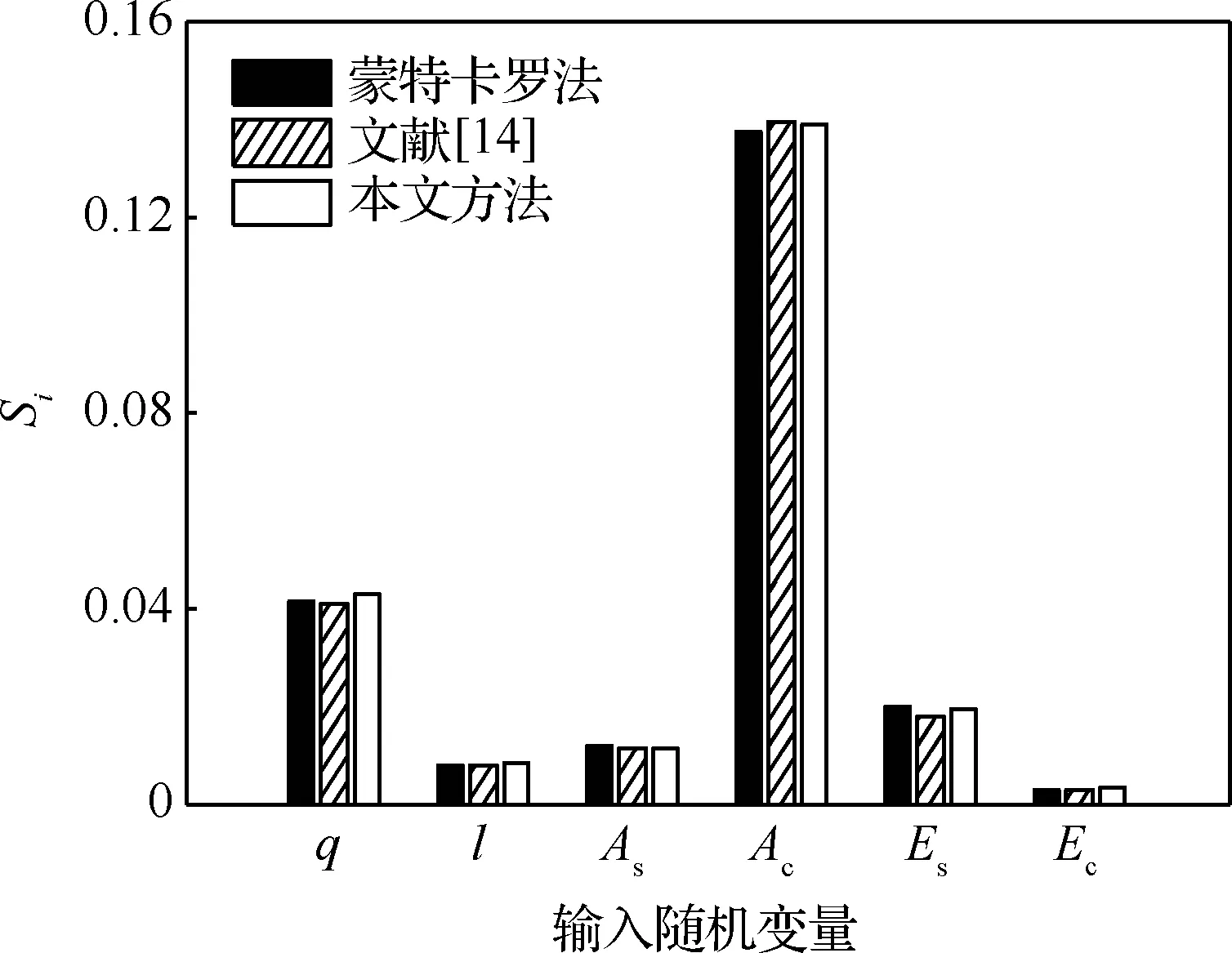
圖3 屋架結構重要性測度結果Fig.3 Results of importance measure of roof truss
算例3三盒段機翼結構
該算例修改自文獻[22]。翼盒是飛機結構的重要組成部件,支撐著機翼的主要框架。如圖 4所示的三盒段機翼結構,由16個板和28個桿組成。結構中28個桿由不同方向區分成3類,即x、y和z方向。在每一個方向上的桿的長度和橫截面積均相同。L1、L2、L3分別表示x、y、z這3個方向上桿的長度;所有桿的橫截面積均為A;桿和板的彈性模量為E;泊松比為0.3;P為施加在節點上的外載荷;T為板的厚度。
假設各個輸入隨機變量之間相互獨立,且均服從正態分布,具體的分布參數見表4。
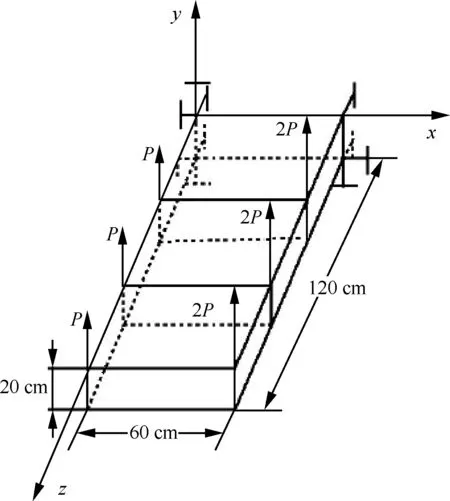
圖4 翼盒結構示意圖Fig.4 Diagram of wing box structure
表4 翼盒結構隨機變量的數字特征
Table 4 Parameters of random variables of wing box
structure
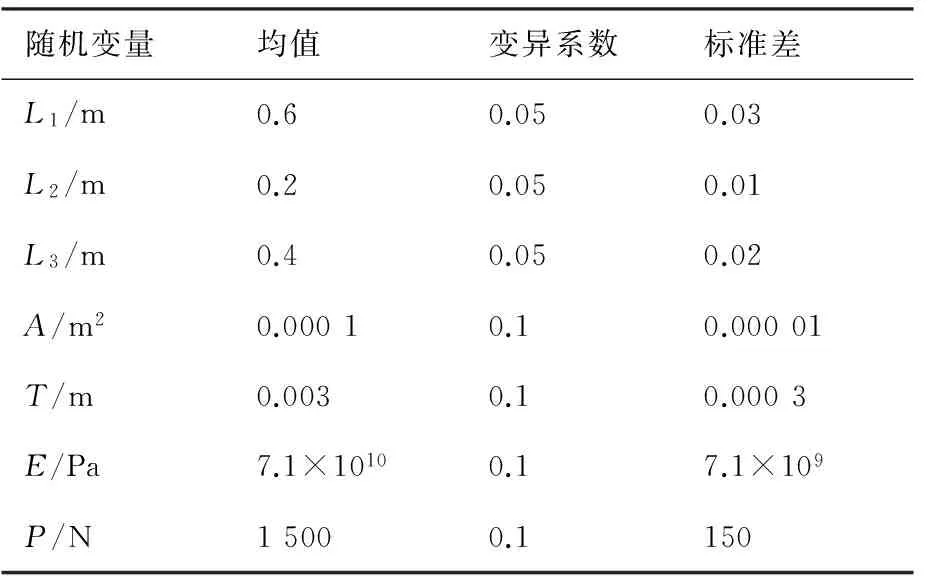
隨機變量均值變異系數標準差L1/m0.60.050.03L2/m0.20.050.01L3/m0.40.050.02A/m20.00010.10.00001T/m0.0030.10.0003E/Pa7.1×10100.17.1×109P/N15000.1150
盒段的設計目標之一是在外載荷的作用下,位移不能超過某一個值。根據這一準則,極限狀態函數可以構建為
g(x)=Dt-d(L1,L2,L3,A,T,E,P)
(30)
式中:Dt=0.006 m為最大允許位移,d(L1,L2,L3,A,T,E,P)為三盒段機翼結構的最大位移,可以通過有限元分析計算得到。在ANSYS中建立三盒段機翼的有限元模型,如圖5所示。
采用交叉熵方法,設定初始參數ρ=0.07,單層樣本量N0=1 000。該算例計算過程中,多層交叉熵的迭代次數僅為2次,使用2 000個樣本點。確定抽樣中心后,重要抽樣1 000個樣本點,應用空間分割法,計算輸入變量的可靠性靈敏度指標。使用蒙特卡羅法,文獻[14]所提方法和本文所提方法可靠性靈敏度指標的計算結果見表5。
以蒙特卡羅法的計算結果作為參照解,從圖6中可以看出,3種方法的結果吻合很好。無論是重要度排序還是數值結果,本文所提方法與蒙特卡羅法均一致。由表5中100次重復計算結果的方差可知:與文獻[14]相比,在方差相當的前提下,本文方法使用的樣本數目更少,其計算效率更高。從計算結果可以看出,輸入變量的重要度排序為:E>L2>P>T>A>L1>L3,其中變量E和L2對模型輸出不確定性有比較大的影響。因此,在設計過程中,工程設計人員可以通過控制上述重要變量的不確定性來高效的提高機翼翼盒的可靠性。
圖5 翼盒結構有限元模型Fig.5 Finite element model of wing box structure
表5 翼盒結構全局可靠性靈敏度計算結果Table 5 Results of global sensitivity analysis for wing box structure
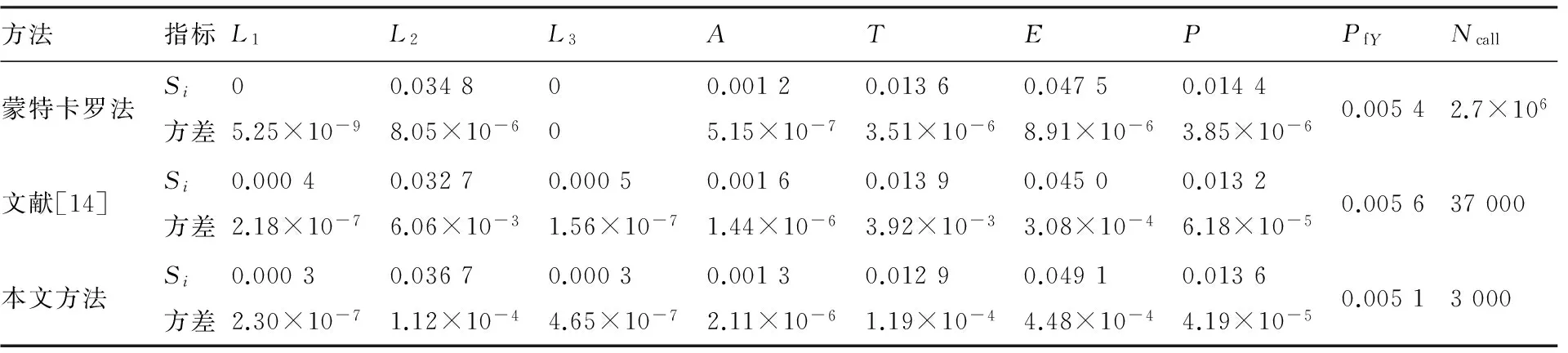
方法指標L1L2L3ATEPPfYNcall蒙特卡羅法Si方差05.25×10-90.03488.05×10-6000.00125.15×10-70.01363.51×10-60.04758.91×10-60.01443.85×10-60.00542.7×106文獻[14]Si方差0.00042.18×10-70.03276.06×10-30.00051.56×10-70.00161.44×10-60.01393.92×10-30.04503.08×10-40.01326.18×10-50.005637000本文方法Si方差0.00032.30×10-70.03671.12×10-40.00034.65×10-70.00132.11×10-60.01291.19×10-40.04914.48×10-40.01364.19×10-50.00513000
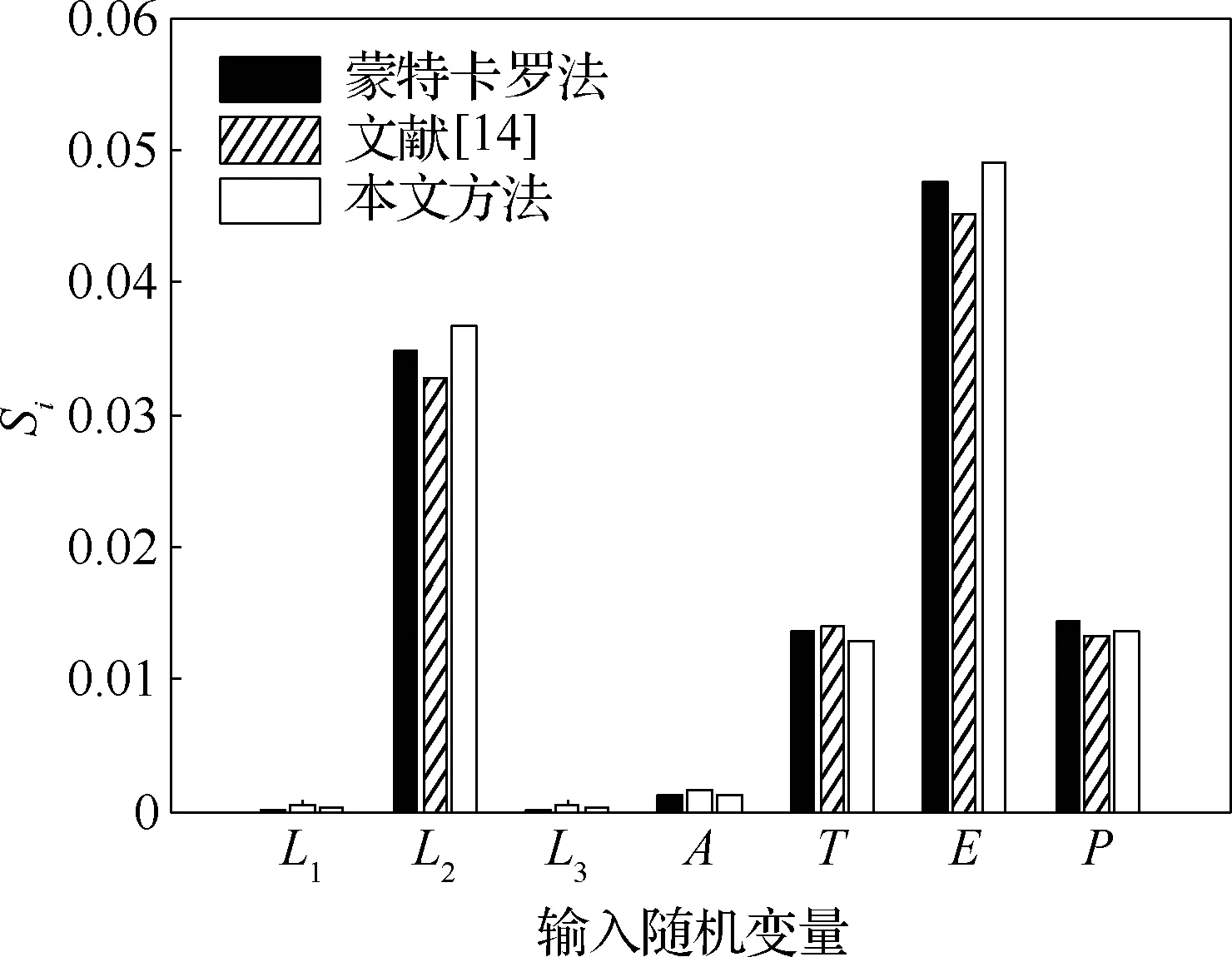
圖6 翼盒結構重要性測度結果Fig.6 Results of histogram of importance measure of wing box structure
4 結 論
基于失效概率的全局靈敏度分析,本文提出了基于交叉熵和空間分割的的高效算法。交叉熵算法自適應移動抽樣中心,逐步確定重要抽樣密度函數,適用于非線性極限狀態函數和多設計點的復雜情況。使用這種方法可以使得更多的樣本點落入失效域,提高抽樣效率。在此基礎上,使用空間分割方法,重復利用一組樣本,通過對這組樣本的不同劃分即可得到所有變量的靈敏度指標,極大地提高了樣本的利用效率,降低了計算量。本文通過3個算例,驗證了所提方法的計算效率和精度,為工程全局可靠性靈敏度分析提供了新工具。
[1] SALTELLI A. Sensitivity analysis for importance assessment[M]. New Dersey: Wiley, 2002: 579-590.
[2] 呂震宙, 宋述芳, 李洪雙, 等. 結構機構可靠性及可靠性靈敏度分析[M]. 北京: 科學出版社, 2009: 6-8.
LU Z Z, SONG S F, LI H S, et al. Reliability and sensitivity analysis of structure and mechanism[M]. Beijing: Science Press, 2009: 6-8 (in Chinese).
[3] SALTELLI A. Global sensitivity analysis: The primer[M]. New Dersey: Wiley, 2004: 1-42.
[4] HELTON J C, DAVIS F J. Latin hypercube sampling and the propagation of uncertainty in analyses of complex systems[J]. Reliability Engineering & System Safety, 2003, 81(1): 23-69.
[5] SALTELLI A, MARIVOET J. Non-parametric statistics in sensitivity analysis for model output: A comparison of selected techniques[J]. Reliability Engineering & System Safety, 1990, 28(2): 229-253.
[6] IMAN R L, HORA S C. A robust measure of uncertainty importance for use in fault tree system analysis[J]. Risk Analysis, 1990, 10(3): 401-406.
[7] SOBOL I M. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates[J]. Mathematics & Computers in Simulation, 2001, 55(1-3): 271-280.
[8] BORGONOVO E. A new uncertainty importance measure[J]. Reliability Engineering & System Safety, 2007, 92(6): 771-784.
[9] 呂震宙, 李璐祎, 宋述芳, 等. 不確定性結構系統的重要性分析理論與求解方法[M]. 北京: 科學出版社, 2015: 1-8.
LU Z Z, LI L Y, SONG S F, et al. The important analysis theory and the solution method of the uncertainty structure system[M]. Beijing: Science Press,2015:1-8 (in Chinese).
[10] CUI L J, LU Z Z, ZHAO X P. Moment-independent importance measure of basic random variable and its probability density evolution solution[J]. Science China Technological Sciences, 2010, 53(4): 1138-1145.
[11] LI L, LU Z Z, FENG J, et al. Moment-independent importance measure of basic variable and its state dependent parameter solution[J]. Structural Safety, 2012, 38(38): 40-47.
[12] BORGONOVO E, CASTAINGS W, TARANTOLA S. Model emulation and moment-independent sensitivity analysis: An application to environmental modelling[J]. Environmental Modelling & Software, 2012, 34(8): 105-115.
[13] WEI P F, LU Z Z, HAO W R, et al. Efficient sampling methods for global reliability sensitivity analysis[J]. Computer Physics Communications, 2012, 183(8): 1728-1743.
[14] 任超, 李洪雙. 基于失效概率的全局重要性測度分析的交叉熵方法[J]. 西北工業大學學報, 2017, 35(3): 536-544.
REN C, LI H S. Cross-entropy method for failure probability based global importance measure analysis[J]. Northwestern Polytechnical University, 2017, 35(3): 536-544 (in Chinese).
[15] RUBINSTEIN R Y. Optimization of computer simulation models with rare events[J]. European Journal of Operational Research, 1997, 99(1): 89-112.
[16] RUBINSTEIN R Y. The cross-entropy method for combinatorial and continuous optimization[J]. Methodology & Computing in Applied Probability, 1999, 1(2): 127-190.
[17] ZHAI Q, YANG J, ZHAO Y. Space-partition method for the variance-based sensitivity analysis: Optimal partition scheme and comparative study[J]. Reliability Engineering & System Safety, 2014, 131(6): 66-82.
[18] PLISCHKE E. An adaptive correlation ratio method using the cumulative sum of the reordered output[J]. Reliability Engineering & System Safety, 2012, 107: 149-156.
[19] LI C, MAHADEVAN S. An efficient modularized sample-based method to estimate the first-order Sobol’ index[J]. Reliability Engineering & System Safety, 2016, 153: 110-121.
[20] PLISCHKE E, BORGONOVO E, SMITH C L. Global sensitivity measures from given data[J]. European Journal of Operational Research, 2013, 226(3): 536-550.
[21] 李洪雙, 馬遠卓. 結構可靠性分析與隨機優化設計的統一方法[M]. 北京: 國防工業出版社, 2015: 129-139.
LI H S, MA Y Z. Unified methods for structure reliability analysis and stochastic optimization design [M]. Beijing: National Defense Industry Press, 2015: 129-139 (in Chinese).
[22] ZHOU C, LU Z, YUAN X. Use of relevance vector machine in structural reliability analysis[J]. Journal of Aircraft, 2013, 50(6): 1726-1733.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
