
基于自然紋理識別的分類器算法設計研究
2018-03-20 09:10:03廣東工業(yè)大學自動化學院孟可然
電子世界 2018年4期
關(guān)鍵詞:分類
廣東工業(yè)大學自動化學院 孟可然
廣州中智融通金融科技有限公司 吳衛(wèi)增 張 偉
廣東工業(yè)大學自動化學院 周延周
0 引言
自然紋理識別是機器學習的一種,讓計算機具有像人類一樣的學習和理解能力,可以對新的對象樣本做出它自己的判斷,并要求有一定的準確率。它是一個多種學科綜合的一種科學學科,包括了機器視覺、數(shù)字圖像處理、機器學習、模式識別、統(tǒng)計學、凸理論分析等多個領(lǐng)域的知識。機器學習其實就是一種對未知的模型的逼近,由于真實模型是未知的,所以要讓計算機學會如何去選擇一個最優(yōu)的模型。而分類器正是一個選擇最優(yōu)解的手段,并且一個好的分類器對其泛化能力和推廣能力有較高的要求。
自然紋理識別的系統(tǒng)包含兩個部分:圖像特征信息提取和圖像識別。通過將圖像提取主成分并降維成低維表示,然后讓計算機使用分類器對它們進行分類并學習,當下次遇到新的樣本時通過先前分類后的情況對新的樣本進行判斷,這是圖像識別的常用流程,而且一般來說,分類器的推廣能力和準確度是隨著訓練樣本的增加而增強的。
1 機器學習中的常用分類器
上一章已經(jīng)對圖像特征信息提取方面進行了介紹,本章將對機器學習中的常用分類器做簡單的介紹,包括貝葉斯分類器,最近鄰分類器,人工神經(jīng)網(wǎng)絡分類器,并對本文使用到的支持向量機做原理剖析和步驟解釋。
1.1 貝葉斯分類器
貝葉斯分類器是統(tǒng)計學的一種表現(xiàn),它的主要思想是:根據(jù)經(jīng)驗和歷史數(shù)據(jù)分析計算出某對象的概率,然后通過貝葉斯分類器和先驗概率得到其后驗概率,再選擇后驗概率最大的類別作為對象的類別。其中,先驗概率的計算是根據(jù)目前僅有的資源而非全部相關(guān)資源進行計算的,后驗概率的計算則包含了更多的資源作為參考,包括計歷史和經(jīng)驗的資源,還有后來添加的資源。
貝葉斯分類器的計算使用的是貝葉斯公式:
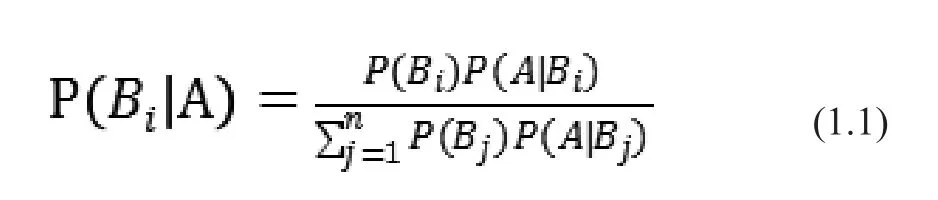
描述為在A時間發(fā)生的條件下Bi事件發(fā)生的概率。
貝葉斯分類的使用一般包含兩個步驟,第一個步驟是進行分類器的構(gòu)造,依據(jù)的是輸入的訓練樣本,并還將對分類器的結(jié)構(gòu)進行學習,類比于機器學習中的第一步。第二個步驟是分類器的運用(即使用其進行分類),依據(jù)是通過計算得來類結(jié)點的條件概率來決定被分入哪個類別。在現(xiàn)實中應用中,這兩個步驟通常都具有非常高的復雜度,因為它們與特征值的關(guān)系非常密切,所以在使用時一般給予簡化。
1.2 最近鄰分類器
最鄰近算法是機器學習中最為簡單且成熟的算法。它的基本思想是用最鄰近的一個或者多個樣本來分類一個新的樣本,而新的樣本一般具有臨近樣本的特征。最鄰近算法分類主要是根據(jù)相關(guān)的鄰近樣本,而非類別域,故它在重復性比較高的類域情況下也有著較好的分類質(zhì)量。
度量距離的公式為:
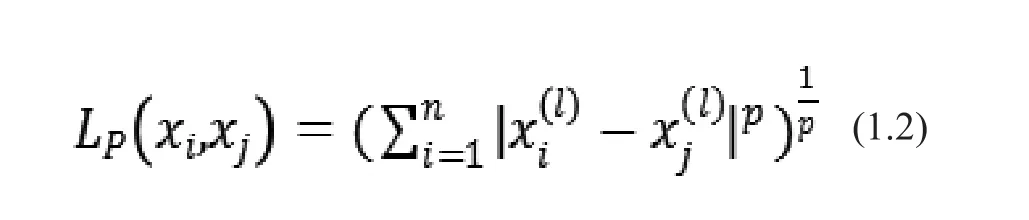
1.3 人工神經(jīng)網(wǎng)絡
人工神經(jīng)網(wǎng)絡從上世紀80年代開始就一直成為人工智能領(lǐng)域發(fā)展和研究的熱點。它使用將大量的簡單的處理單元聯(lián)系起來構(gòu)成復雜的數(shù)據(jù)處理網(wǎng)絡,由此計算計算量巨大的問題。人工神經(jīng)網(wǎng)絡的最終輸出值取決于該網(wǎng)絡的連接方式,連接方式不同則將會影響處理單元的順序,最終導致計算值的不同。
人工神經(jīng)網(wǎng)絡一般可以分為兩大類,分別是前向網(wǎng)絡和反饋網(wǎng)絡。前向網(wǎng)絡即是一種不包含反饋的網(wǎng)絡,每個結(jié)點都接收前一個單元的輸入并經(jīng)過本單元運算輸出給下一級,前向網(wǎng)絡的特點是比較簡單,容易實現(xiàn)。反饋網(wǎng)絡即是神經(jīng)網(wǎng)絡中包含反饋且具有聯(lián)想儲存的功能,特點是實現(xiàn)較為復雜人工神經(jīng)網(wǎng)絡在具有多種模型,其中的BP神經(jīng)網(wǎng)絡模型應用最為廣泛且效果較好。
2 支持向量機簡介
支持向量機(Support Vector Machine)在1995年首次被Cortes和Vapnik[1]所提出,它的優(yōu)勢體現(xiàn)在很多方面、包括具有高維特性、小樣本特性和非線性問題上,它還可以被推廣到其他很多的機器學習應用中。支持向量機的理論基礎是建立在統(tǒng)計學的知識體系上的,其中作為主要原理的是VC維理論和結(jié)構(gòu)風險最小理論。其主要思想是:通過對樣本的分析和學習,尋找一個最優(yōu)的超平面,將兩類樣本的分類間隔最大化。
支持向量機有三大優(yōu)勢,第一是在其處理問題只關(guān)注VC維且與樣本的維數(shù)無關(guān),它只尋找它所需的少數(shù)支持向量,所以它在高維數(shù)的分類中依舊可以有較好的表現(xiàn)。第二,由于支持向量機引進了核函數(shù)和松弛變量[2],使得它在樣本非線性情況下具有優(yōu)越性。第三,支持向量機的算法需要的樣本數(shù)相比于其他算法所需要的樣本數(shù)是相對比較小的。由于支持向量機三個顯著的優(yōu)勢,其被廣泛的應用于各種識別應用中。下面將對支持向量機的原理進行剖析,其中將介紹線性SVM分類器、非線性SVM分類中的核函數(shù)和松弛變量以及應用于SVM在多類分類中的方法。
3 支持向量機原理
3.1 線性SVM分類器
支持向量機與線性分類器的關(guān)系密不可分,支持向量機在處理低維非線性以致高維非線性的問題時,都是將其從非線性轉(zhuǎn)化為類線性的進行處理的。線性分類器是最簡單有效的分類器[3],它的思想是尋找一個線性函數(shù)(即分類函數(shù))將樣本分成兩類。如果樣本能夠被此線性函數(shù)完全分開,那么樣本就是線性可分的,反之則線性不可分。如圖1所示:
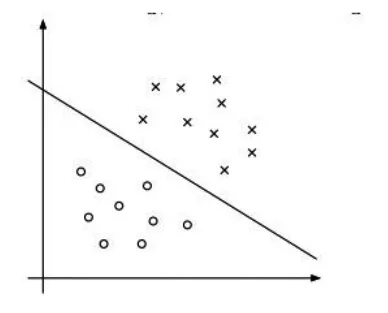
圖1 線性分類
圖中圈代表一類樣本,叉代表一類樣本,中間的直線便是分類函數(shù),此樣本集便是線性可分的。
由此可以定義線性函數(shù)為:

w為權(quán)向量,x為輸入,b為閾值。在二維情況下,線性函數(shù)如上圖是一條直線,但在三維情況下,線性函數(shù)就變成了一個平面,在更高維的情況下時,線性函數(shù)就是一個超平面。當取判斷閾值為0來判別樣本屬于哪個類時,就只需要將樣本帶入g(x)中去計算,若g(x)大于0則表明其屬于一個類,當g(x)小于0則屬于另一個類。可以看到線性函數(shù)并不是唯一的,若直線旋轉(zhuǎn)一點角度,依舊可以將兩個樣本分開,找到一個最優(yōu)的線性函數(shù)能夠最大程度的將兩類樣本分開成為了最重要的問題。因此SVM分類器的思想就在此體現(xiàn):找到一個線性函數(shù)能使樣本之間的分類間隔最大化,分類間隔越大,說明該線性函數(shù)的分類效果越好,反之,則越差。
當我們將樣本輸入給計算機進行訓練時,每個樣本的表示形式是這樣的:

其中y是標簽值(設為1或者-1),即用來表示該樣本屬于哪個類別的標記,x是表示樣本的向量。則一個樣本點到某超平面的距離可以表示為:
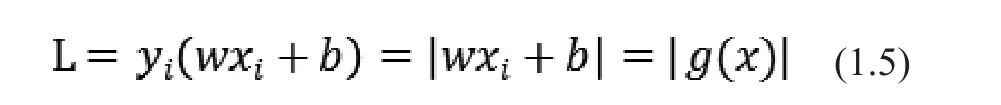
再使用歸一化對其進行變換(使用w的范數(shù)||w||),則距離可以表示成:
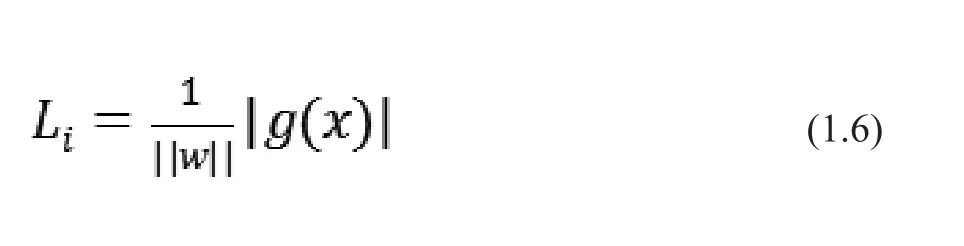
用歸一化的方式來表示的距離被稱為幾何間隔,是點到超平面的歐式距離。則上述兩個公式又可以表示為:
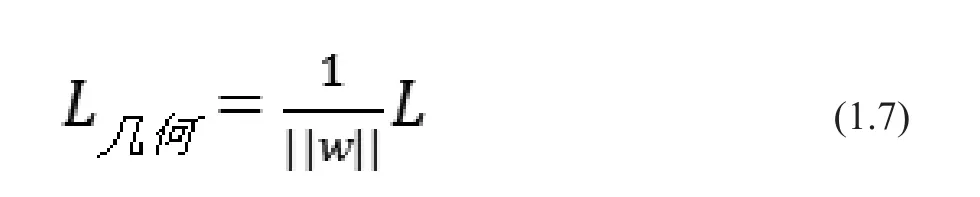
由于SVM的目標是找到一個分類平面使得分類間隔最大,等同于數(shù)學上的一個求最優(yōu)解的問題。如圖2所示,設H是分類超平面,其中H1和H2與H平行,且H1和H2是過離分類超平面最近的樣本做的平面。H1和H2到H的距離就是幾何距離。
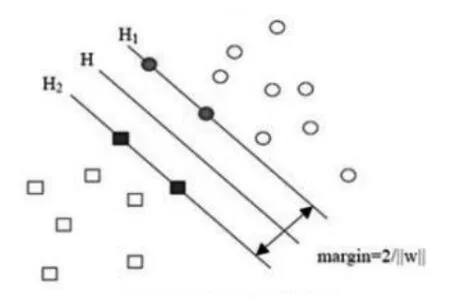
圖2 幾何間隔示意圖
在數(shù)學的求解上,通常將L設為1,使得幾何間隔和||w||成反比,求幾何間隔最大,即求||w||的最小值。根據(jù)上述條件,又因為每個樣本都要滿足在最大分隔距離之外(即),所以目標函數(shù)變?yōu)橐粋€帶約束的最優(yōu)解問題:
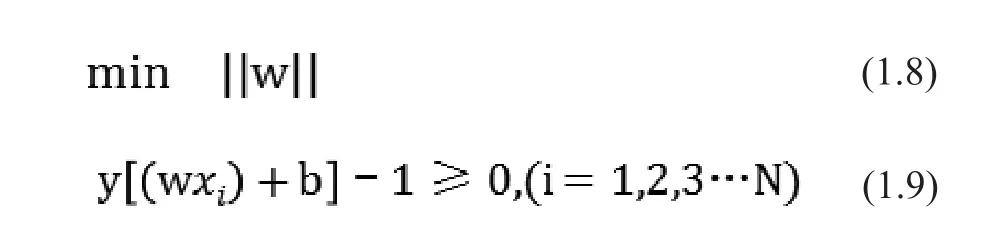
在求解這類帶多個約束的最優(yōu)問題時,一般將約束的不等情況取極端情況,也就是等于的情況。即向問題中添加拉格朗日乘子并構(gòu)造出拉格朗日函數(shù)得以將問題轉(zhuǎn)化為一個求無約束的求最優(yōu)解問題:
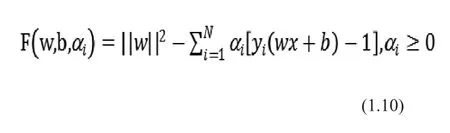
最后求得的分類平面函數(shù)為:
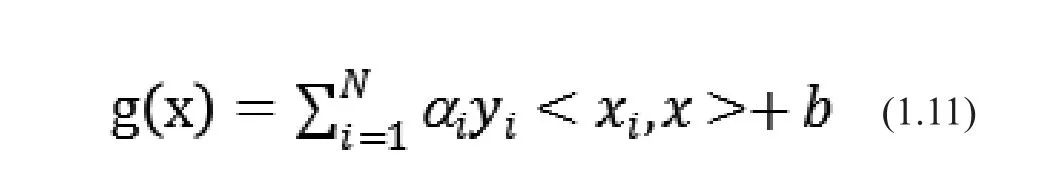
以上就是線性SVM分類器的原理。
3.2 非線性SVM分類器
在現(xiàn)實中,絕大部分分類問題都是非線性的,樣本正好呈現(xiàn)線性分類的情況少之又少。在紋理識別中也是如此,樣本被降維后仍然是一堆非線性的集合,但如果不進行分類,計算機將無法進行學習,識別也就無從而談。而為了解決非線性的分類問題SVM引入了核函數(shù),和松弛變量進行處理。當?shù)途S的形式下的樣本不呈線性時,將其轉(zhuǎn)化為高維則可以線性表達。
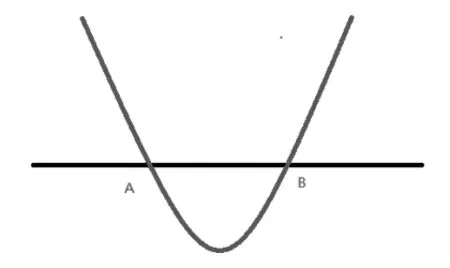
圖3 非線性分類示意圖
如圖3所示,當樣本分布為一條直線時,A和B點之間是一個類別,其余是另一個類別。此時要找一條直線將其分成兩個類別是不可行。設可以找到一條曲線,將兩個類別分開。其中曲線以上是一個類別,曲線以下是另一個類別。則該曲線的函數(shù)為:
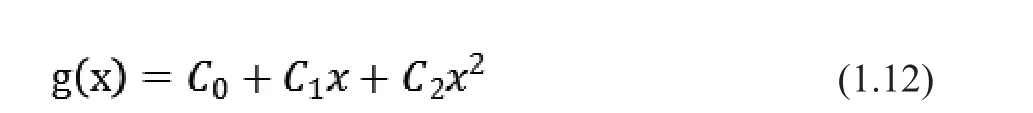
可以看到此分類函數(shù)并不是一個線性函數(shù),但可以新建向量y和a來表示g(x),即:
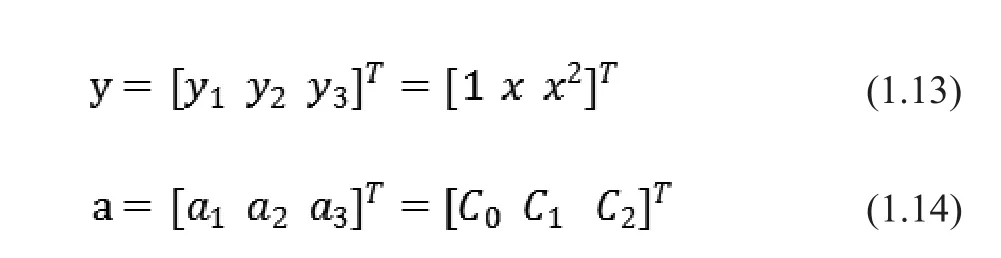
4 SVM在多類分類的方法
對訓練樣本訓練完后,就要進行分類的動作。在自然紋理識別中,通常會有多個樣本,那么分類就是對多類而言的。SVM在多類分類的情況下有一對多和一對一兩種策略。
4.1 一對多的分類
一對多分類的思想就是:對樣本依次進行屬于單個類與其他類的判斷并投票,將分類器對單個類做出相應并間隔為最大的類別作為分類類別。現(xiàn)有五個類型A,B,C,D,E,一個新輸入的樣本O。依次對樣本進行A與BCDE類,B與ACDE類,C與ABDE類,D與ABCE類,E與ABCD類的判斷,若分類器做出的判斷為屬于A類,又屬于C類,但在A類情況時樣本距離分類線的間隔比C類的大,那么給類別則被判定為A類。該方法的優(yōu)點是當條件理想時,只需要進行N(N為類別數(shù)目)次的分類器判斷就可以得到結(jié)果。但上述方法有個缺點就是,若每次分類器都判定給其他類時,將得不到結(jié)果。
4.2 一對一的分類
一對一分類的就是依次對任意兩個類別進行判斷,每次都讓分類器做出判斷并給其中一個類別投票,最終投票最多的那個類別就確定為分類類別。這種分類方法共需要N(N-1)/2個分類器,判斷的次數(shù)比一對多的分類方法要多。這種分類方法的缺點,其一的泛化誤差不存在上界。其二,由于分類器數(shù)量隨著N的數(shù)量增加而增加,當數(shù)量很大時,判斷速度會很慢。其三,這種判斷方法會使測試樣本受到非所屬類別的影響,因為即便在不屬于判別類型的分類器中也需要給出投票。
[1]VAPNIK V.Statistical learning theory[M].New York:Wiley,1998.
[2]趙文嵩.SVM在多類問題中的應用及推廣[D].聊城大學,2014.
[3]李艷芳.線性判別式的比較與優(yōu)化方法研究[D].華東理工大學,2015.
[4]張婧婧.復雜網(wǎng)絡中心化的研究[D].西安理工大學,2007.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
