網絡傳播信息內容的可信度研究進展
2018-04-16 07:53:30吳連偉樊笑冰
中文信息學報 2018年2期
吳連偉,饒 元,樊笑冰,楊 浩
(西安交通大學 軟件學院 社會智能與復雜數據處理實驗室,陜西 西安 710049)
0 概述
基于用戶生成內容的Web 2.0社交網絡平臺極大地促進了信息內容的生成、傳播與快速增長,在享受信息的快速獲取與傳播共享便利的同時,網絡中散布著大量的謠言、偏激和虛假信息。在線博客中存在著許多偏激和虛假的內容,微博也被大量的垃圾和謠言信息嚴重污染,甚至在線新聞媒體也被大量不可靠且沒有被證實的新聞所充斥[1],這種現象直接影響到了主流媒體。Howell[2]將海量數字化虛假內容信息列為影響現代社會發展的重大威脅之一。
Gupta[3]的研究結果表明:在Twitter中有將近52%的內容是確定可信的、35%的內容是大致可信的、13%的內容是確定不可信的。不可信信息將極大地渲染消極和負面的社會情緒,不僅影響社會和諧,而且也會影響國家安全與政治生態。例如,澎湃新聞曾在2016年1月4日發布“江西九江市潯陽區發生6.9級地震”的假新聞所引起的社會恐慌,2016年英國脫歐和美國總統大選事件中所引爆的媒體信任危機,許多類似的新聞使人們開始深刻地意識到“陰謀論、假新聞、極端的感情抒發”的信息在網絡傳播中給社會所傳遞的負面影響。如何在復雜網絡環境下快速識別出信息的真偽,以確保網絡中傳播信息的真實性與可信性,并對傳播信息內容的可信度進行度量,已成為目前學術界、工業界和政府機構共同關注且亟需解決的重要問題。
為了解決上述問題,本文在文獻調研分析與總結的基礎上,從信息可信性與不可信的特征出發,針對不同類型的信息內容特征進行識別、抽取與比較,在此基礎上,系統地梳理和分析當前主要的信息可信度建模與評測方法,為信息內容的可信度分析與研究奠定基礎。
1 網絡信息可信性分類與可信度定義
1.1 網絡信息可信性分類
從可信的角度看,信息可以分為可信與不可信兩大類,除了能夠證明信息本身的真實性、科學性、客觀性以及完整性以外的信息,其余信息均可稱為不可信信息。而在網絡中傳播的這些不可信信息本身也存在著一些明顯的差異,根據這些差異將不可信信息進一步歸納為:極端突發事件下的模糊信息、網絡偏激信息、網絡普通虛假信息、網絡謠言、誤報信息與垃圾信息等六種類型。
其中,極端突發事件是指具備嚴重危害性的不可預知的突發性事件,特別是指由于自然災害、事故災難、公共衛生事故以及社會安全事件等方面突發且不會重現的事件[4],由于極端突發事件除了具有爆炸性、不可重復性和嚴重危害性等特征外,還具有極強的模糊性,從而為虛假信息的快速傳播提供了空間;網絡偏激信息是指夸大或貶低事實、斷章取義或者是以偏概全的信息,這類信息中往往融入了個人的極端情感;網絡普通虛假信息包括惡意造假或蓄意欺騙的信息;網絡謠言指在網絡中傳播的一個存在爭議或者事實有待檢驗的信息陳述[5];誤報信息則是由于工作失誤而錯報的信息,產生的原因包括錄入失誤、疏忽或者專業能力差等[6];垃圾信息指與用戶無關且無價值、不被關注的信息,也包括失去時效的過時信息等。根據上述定義,表1從特點、發布者、目的性、危害性和可信度等特征的差異對信息進行了比較。
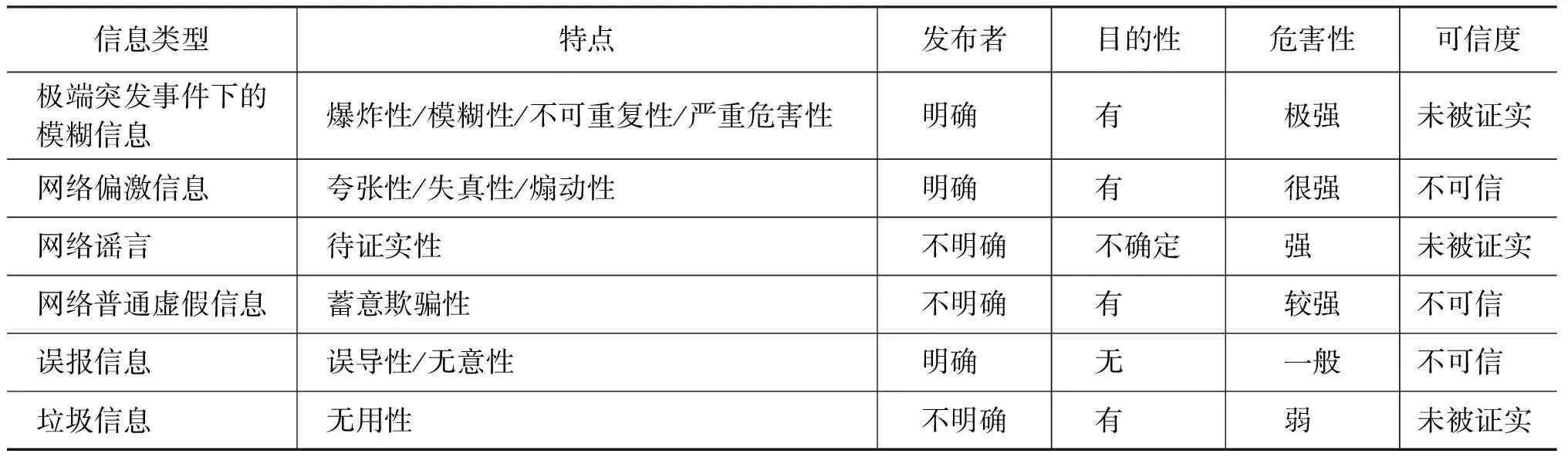
表1 六類不可信信息的特征對比表
由于信息傳播過程中的用戶社交網絡與興趣網絡交織融合,信息內容的組織形式具有多樣性且具有跨媒體特征,使得不可信信息識別的復雜性程度大幅提高,這直接影響到了網絡信息傳播過程中預測與引導策略的有效性。因此,本文提出了信息可信度概念來對所有信息的可信程度進行統一度量。
1.2 信息可信度的定義
信息可信度是評價信息內容質量的一種關鍵性指標,它與信息在網絡中傳播的核心要素相關,即與信息內容、話題、信息傳播者和傳播媒介及信息接受者等特征相關,因此,可用如下五元組來形式化地定義為:
IC=
(1)
其中,IC表示信息的可信度,C、T、P、M和R分別表示了信息內容、話題、信息傳播者、傳播媒介及信息接受者的特征集合,該模型所描述的信息在網絡中的傳播過程如圖1所示。盡管該模型在傳播要素與內容可信度度量之間建立了一種聯系,但并沒有解決如何選擇不同的特征維度并進行有效的評估測量這一關鍵問題。

圖1 信息可信度IC模型中網絡信息的傳播過程示意圖
West[7]認為可信度是信息接受者對信源或傳播媒介品質的一種主觀感受,這種品質不管內容如何,受眾都能毫無保留地對其信賴。而Fogg[8]進一步強調受眾對信息傳播者的信任主要來自于個人特質和信息來源可信程度特征的主觀測量。周東浩[9]將微博看作一個融合了社交圖譜和興趣圖譜的關系網絡,其中節點之間的結構相似度以及用戶對信息的傳播興趣對信息傳播概率的影響最大。在此基礎上,Metzger[10]認為信息可信度不僅包括了對信息源的專業性、吸引力以及可信賴性的主觀信任度,同時也包括了信息內容質量、精確度的客觀評判。而方濱興等[11]進一步將信息內容、人員以及行為動機的識別作為信息內容安全判斷與控制的核心要素,且通過行為動機的分析來客觀地反映人員的主觀行為。為了更好地分析信息內容的質量,Miyamori[12]開發了一個WISDOM系統,并從信息的內容、傳播者、表面特征和社會價值等四個方面來度量信息的可信度。Castillo[13]提出了一個基于多級社交網絡的信息內容可信度評價指標體系,其中一級特征指標包括信息內容、接收者、話題和傳播等四項,二級指標74項,為信息內容可信度測量奠定了重要的分析基礎。
綜上,考慮到信息在傳播過程中主觀與客觀因素對信息可信度測量的影響,為了更有效地建立信息的可信度評價模型,需要進一步深入地對可信信息以及上述六種不可信信息的特征進行分析和量度,因此,本文從IC模型的五個維度出發,對信息在傳播過程中的可信度特征進行研究與分析。
2 信息可信度特征與指標體系的建立
2.1 信息可信度特征指標
由于網絡結構與人們的行為傾向對信息傳播會產生非常大的不確定性影響,且傳播內容的可信度與網絡的結構特征、個體行為以及信息傳播的初始狀態之間存在著密切關系。同時,在線文本的有用性與價值性以及社交文本(如Tweets)內容中的URL、關注數、轉發數和內容長度均可以作為信息可信度評估的最佳指標[14]。Metzger[15]認為信息可視化模式比信息內容以及來源對可信度評估結果的影響更大。而Lipshultz[16]卻認為在構建公眾信任時的參與度、完整性以及目的性才是關鍵,他利用TweetLevel工具對Twitter中的信任進行了度量,結果表明網絡中的個體愿意信任那些和自己建立聯系的用戶所發表的、且具有一定轉發數量與引用數的信息內容。Castillo[17]則認為Tweet中信息的可信度與信息源、主題、作者的聲譽、寫作風格、信息傳播以及與時間相關特征緊密相關;徐靜[18]針對Web信息可信度的時效性、權威性、影響力和關注度四個特征進行驗證,并提出了一個多維度加權結合的可信度計算方法。Hardalov[1]則進一步提出了一個基于語言學(主要指n-gram)、可信性(大小寫、發音、拼寫與情感)以及語義(Embedding and DBPedia Data)三者融合的富特征(20條特征)條件下,語言無關的自動化的英文信息可信度識別方法,實驗結果表明在特定的測試集下,內容可信度的識別率竟高達99.36%。
目前,信息內容的可信度研究主要集中在對信息特征的分析與定義以及基于特征的可信度檢測上,本文將IC模型中的五個維度作為信息內容可信度特征分析的一級指標,在此基礎上,將該指標下所涉及的子特征細化為二級指標,并將具體可度量的細化特征作為三級指標,從而構建了一個信息內容可信度特征分析的指標體系,如表2所示。
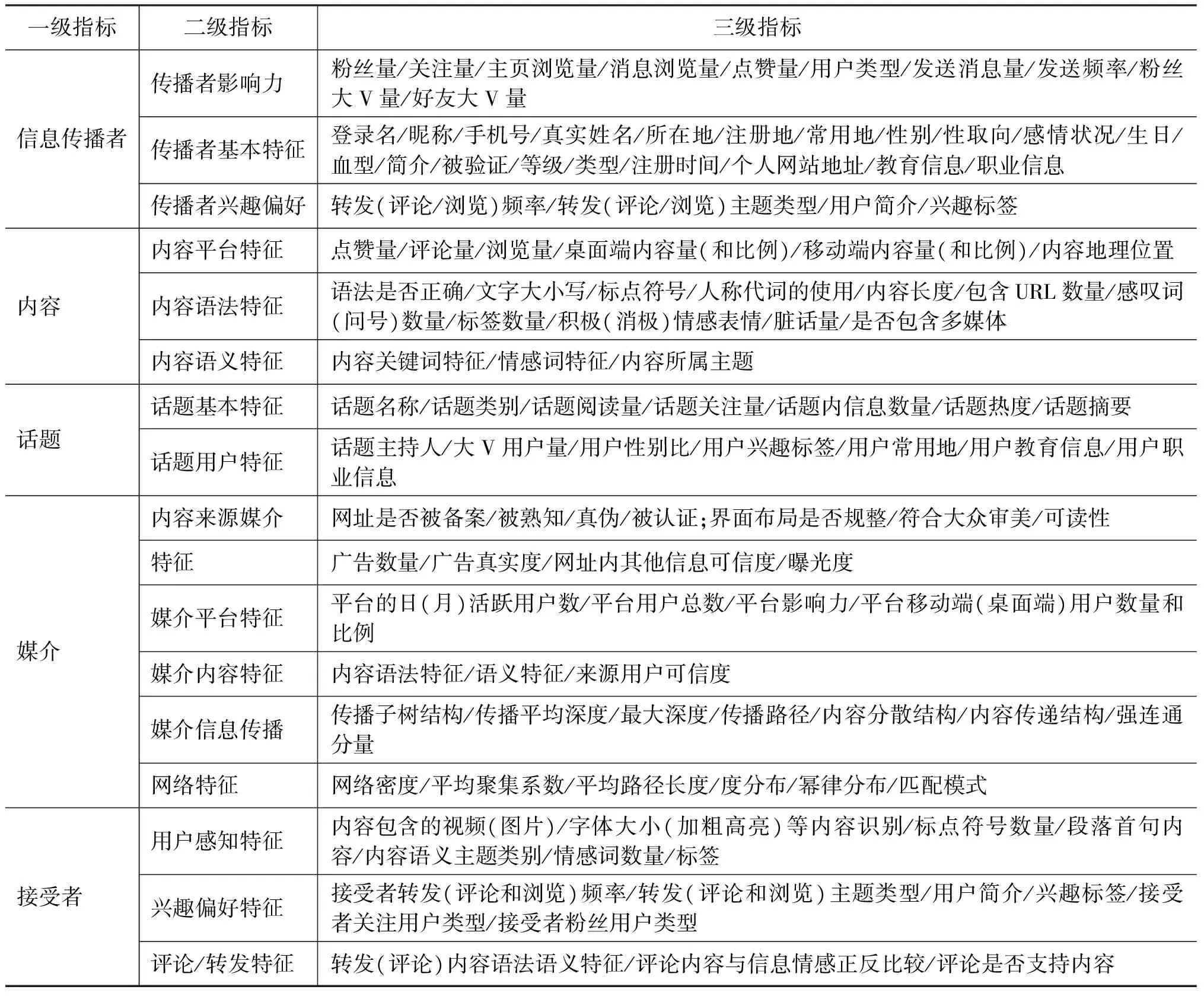
表2 信息內容可信度特征指標體系表
2.2 不可信信息特征描述與定義
在上述特征分析的基礎上,為了對不同類型的不可信信息的可信程度進行分析,下面對這些類型的信息可信特征以及度量方法進行分析。
2.2.1極端突發事件下模糊信息特征描述
突發事件是指突然發生的超常規的自然災害、事故災難、公共衛生事件和社會安全事件的總稱。它具有突發性、無重復性、無章可循但又能產生重大次生影響的特征。特別是突發事件產生后,相關信息的模糊性,使得心理處于恐慌狀態的人群對信息的渴求強烈,從而成為了各類不可信信息滋生與傳播的土壤[19]。例如,在日本福島核泄露事件發生后,Thomson[20]研究發現與這場危機現場距離越近的傳播者(即傳播者可信度中的地理位置)越能增加共享信息的可信度。Mendoza[21]定義了基于詞共現的主題(話題)抽取方法,通過抽取包括信息、內容(內容在平臺上的特征、語法特征、語義特征)、信息媒介(媒介平臺特征)和接受者(評論轉發特征)等一系列特征研究極端突發事件信息可信度,尤其是在新聞可信度識別領域獲得了較高的準確度。薛傳業[22]從信息內容、傳播來源(內容來源媒介特征)、傳播渠道(媒介平臺特征)、傳播者影響力、傳播者可信度、網絡依賴性等方面對突發事件中信息可信度進行研究,發現網絡的使用和信息的完整性對突發事件信息的可信度影響不顯著,但其他因素對突發事件中信息的可信度則存在明顯影響。
2.2.2網絡偏激信息特征描述
網絡偏激信息本質上是人們對現實社會認知和情緒的反映,它包括了夸大事實信息、斷章取義和以偏概全等言論,并影響公眾對社會生活審視的立場和價值判斷。網絡偏激信息往往會帶來嚴重的煽動效應,并對個人及社會造成嚴重的不良影響。Lewandowsky[23]指出:人們對事件的信任源自于其大腦中所形成的未被大眾質疑的信仰和觀念。特別是當信息中包含與用戶興趣偏好一致的信仰與觀念時,即使信息內容中存在著夸大或帶有某些偏激的言論,人們可能也會不加驗證地選擇接受。另外,由于偏激信息整體言論是可信的,只有部分言論是不可信的,導致了僅從文本內容語法特征以及淺顯的語義特征兩個方面將無法完成對偏激信息的判斷與識別,所以目前的研究采用了深度學習技術從信息內容本身的深層語義理解方向進行分析與研究,進而識別與判定偏激信息。
2.2.3網絡謠言特征描述
謠言是一種在人群之間私下流傳,對公眾感興趣的事物、事件或問題未經證實的闡述或詮釋[24]。因此,謠言往往是一個有爭議的與事實有待檢驗的陳述[5]。Turner[25]指出,通過是否有可靠的消息來源、是否是人們所預期與希望知道的信息以及聽起來似乎是真的這三個方面的特征可以有效驗證謠言的真實性。Bessi[26]在研究Facebook中的謠言信息時,發現用戶更傾向于和自己觀點相同的好友(話題的用戶特征)進行交流與傳播。Hamidian[27]利用了包括時間、標簽、URL和轉發等特征和內容的一元、二元模型的語法特征以及100維的Twitter潛在語義向量(TLV)特征進行謠言檢測。Yang[28]收集了大量被新浪官方正式辟謠的新浪微博謠言數據集,進行了基于時間與地理位置以及客戶端程序發送微博情況在內的19種信息內容特征的謠言檢測與識別。Liu[29]將信息來源媒介的可信度、媒介身份和媒介平臺等特征相結合,并采用實時性算法來實現謠言信息的實時檢測。周東浩[9]利用傳播者與接受者的興趣偏好相似度特征來研究信息的傳播,并指出傳播者與接受者的興趣偏好相似度越高,接受者越傾向于接受傳播者所傳播的信息,且信息是否契合用戶的興趣偏好也是決定用戶是否接受并傳播的重要因素。
2.2.4網絡普通虛假信息特征描述
虛假信息是指“故意制造的不真實信息”,它具有傳播速度快、傳播范圍廣和傳播結構呈散布型網狀結構的特點。Fallis[30]將虛假信息的主要特點概括為:它是一款精心策劃的產品,從技術上看是一個復雜的欺騙過程,但虛假信息的來源并不一定是虛假的,也就是說通過虛假信息的來源特征并不能準確評判虛假信息。因此,僅利用信息的來源則無法區分虛假信息與其他信息,同時,虛假信息的傳播對象往往針對特定的人群或組織。Karlova[6]從真實性、準確性、完整性、時效性和欺騙性五個維度測量與區分誤報信息、虛假信息和政治宣傳信息,并指出這三種信息在本質上只有虛假信息帶有蓄意欺騙性質。Kumar[31]從認知心理學角度,采用信息傳播所涉及的信息的一致性、相關的消息、信息接受者的總體可接受性和消息來源的可靠性等四種相關的欺騙線索來分析和評估社交媒體上誤報信息、虛假信息和政治宣傳信息的差異,并提出了阻止虛假信息傳播的不同解決方案。
2.2.5誤報信息特征描述
誤報信息是指錯誤的或誤導性的信息,它常常具有被官方或影響力高的人員來發布、擴散傳播迅速、存活時間短和較易被證實的特點。Ratkiewicz[5]研究了2010年美國總統競選活動中在Twitter上的選舉造勢的內容數據,發現具有很強傳播感染性的誤報信息用錯誤觀念影響了民眾的支持傾向,并對投票選舉結果產生了嚴重影響。Karlova[32]認為誤報信息很難檢測,但是采用基于群體智慧的眾包方式則可以有效地對其進行識別和控制。Neys[33]和Lewandowsky[23]認為誤報信息的存在是極其危險的,需要對網絡中的誤報信息進行檢測、識別,并盡可能使其在早期得到及時的預防與控制。表3將信息、誤報信息與虛假信息從真實性、完整性、時效性和欺騙性這四個維度進行比較分析,其中誤報信息和虛假信息均不真實,但只有虛假信息具有欺騙性。
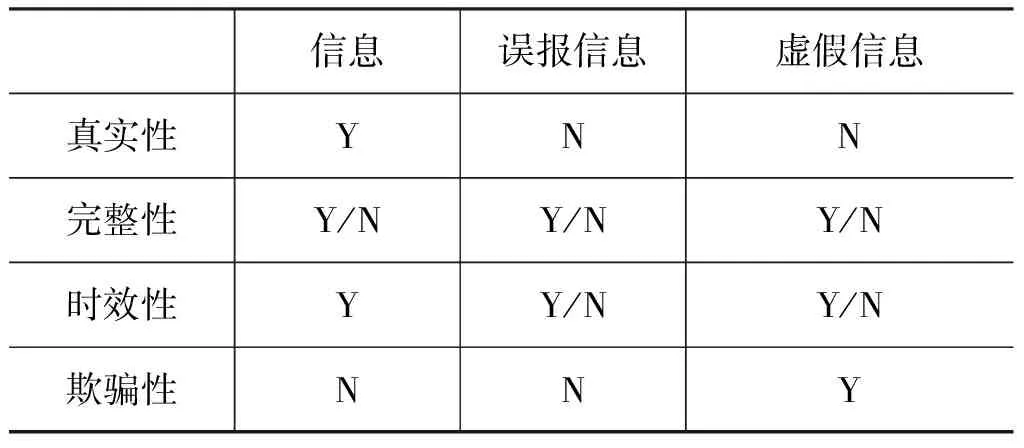
表3 信息、誤報信息與虛假信息比較表
注:Y=Yes,N=No;Y/N=可能是Yes也可能是No,取決于信息的本身和時間
2.2.6垃圾信息特征描述
網絡中垃圾信息通常是指由網絡水軍創造的隨意且無用的信息,以及各種無效廣告等與用戶無關的信息。由于網絡垃圾信息無用且干擾了正常的信息獲取,因此,用戶往往不會主動傳播這類信息,同時也希望識別并過濾掉這些信息對人們產生的負面影響。Ratkiewicz[5]利用meme的節點數量、邊的數量、平均度、平均強度、最大連接組件的平均邊權重、最大最小出入度以及六類情緒統計維度等共18種特征對網絡中的垃圾信息進行了分類。Wang[34]利用基于用戶粉絲和關注的有向圖特征以及Tweets內容本身特征如重復Tweets、評論與@用戶(接受者評論/轉發特征)、URL和話題等四種特征對Twitter進行了垃圾信息檢測。Tan[35]抽取了網站評論信息中的垃圾內容與URL之間的連接關系,并通過社交圖譜定義了垃圾信息散布者的節點特征、分享信息的URL和用戶鏈接圖譜的節點度、邊特征等在內的九個相關特征,從而為垃圾信息的識別與過濾奠定了實現基礎。
綜上,通過對上述六類信息的可信度特征描述與分析,本文進一步將這六種不可信信息的特征指標進行對比,形成的整個特征指標體系如表4所示。
表中的對勾號(√)代表“存在”,比如第一個(√),表示在“極端突發事件信息”中存在著“傳播者影響力”特征。
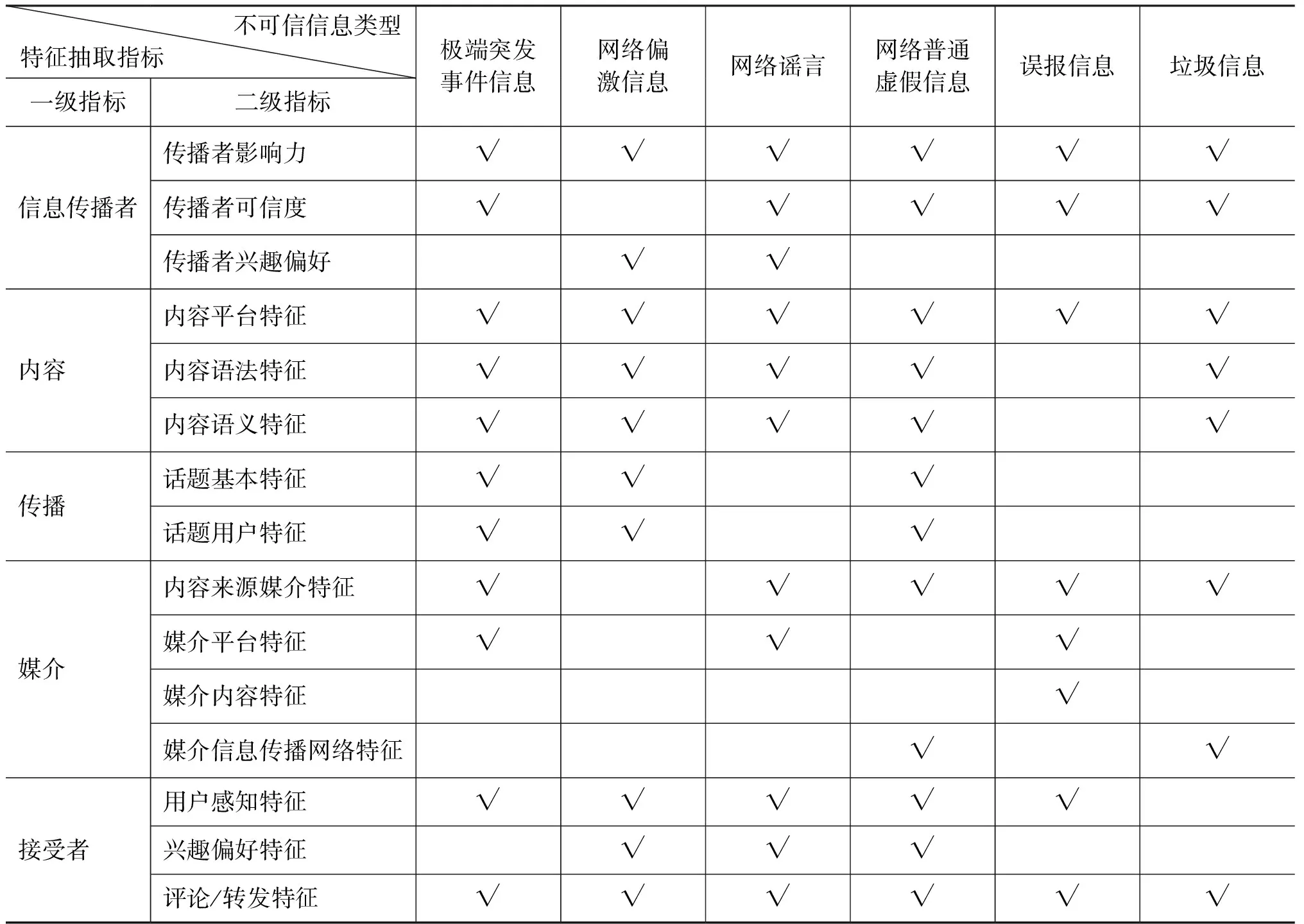
表4 六類不可信信息的特征比較表
3 內容可信度分析建模
根據IC信息可信度模型以及信息可信特征指標體系,如何建立基于特征的信息內容可信度分析與評估模型則成為了關鍵。圖2顯示了網絡信息可信度分析的基本過程,即主要包括信息獲取、話題識別與跟蹤、特征抽取、可信度模型的建立與分析以及計算結果的評估。在此基礎上,本文從傳統的信息可信度基本模型、基于淺語義特征的可信度模型、基于媒體融合的深層語義理解研究以及其他相關模型[38]等方面來分別進行介紹。
3.1 信息可信度基本模型
Fogg[36]提出一個評判互聯網信息可信度過程的“關注—釋義”模型,該模型認為人們對信息往往是先關注后釋義,即:當評判在線信息的可信度時,人們首先會觀察到一些需要關注的信息要素,然后再對這些元素進行解釋和釋義。其中,有五個關鍵因素直接影響到了“關注”的程度:用戶的參與程度(即審查網頁內容的動機或能力)、網站的話題(新聞或娛樂)、用戶的任務動機(尋找信息)、用戶的經驗(新手或專家)以及個體差異(認知的需求、學習方式)。而在“釋義”階段,主要的影響因素包括用戶的期望假設(文化、過去經歷等)、用戶能力與知識以及外部環境等因素。 Sunder[37]提出了由信息傳播的媒介、代理、交互性和可操縱性等四個要素組成的MAIN模型。其中,信息媒介的差異會采用不同的方式將信息傳播給不同的受眾;代理則表示媒介的具體代表;交互性反映了人們的信息交流方式,不同的互動方式所采用的啟發式評測規則也會存在差異;可操縱性反映了獲取信息的操作方式,例如,網站的層次結構、大綱和超鏈接的設計會直接影響到人們獲取信息的難易程度。通過分析上述四個要素來獲取對信息質量評估的啟發式判斷規則。
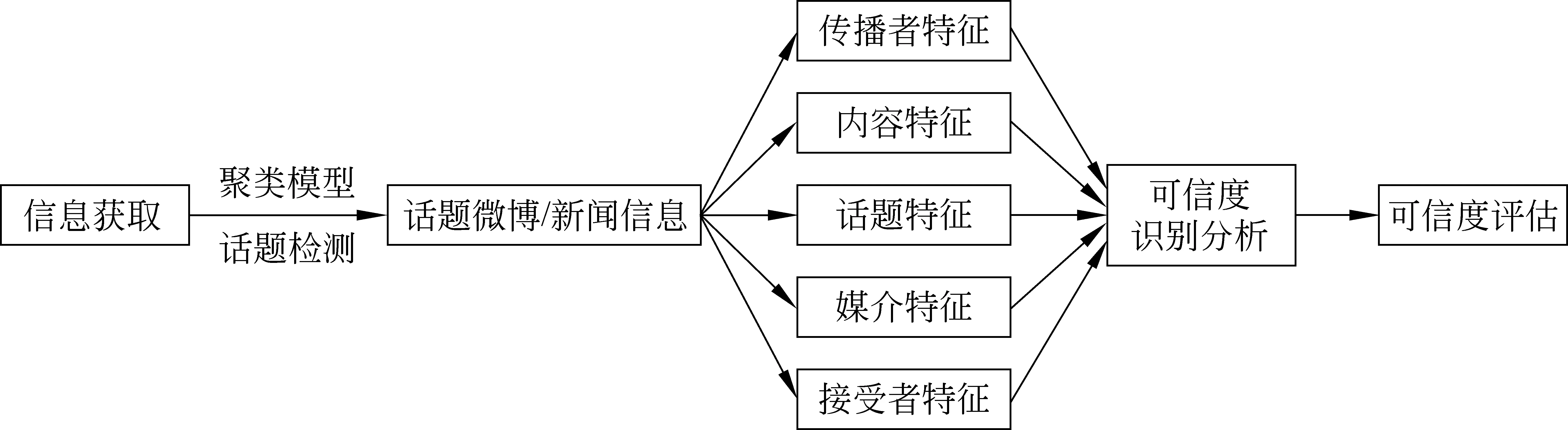
圖2 信息內容可信度分析過程示意圖
高雅[38]在新聞信息可信度評測要素研究的基礎之上,結合微博的傳播學特征和社會網絡結構特征,在多級信息分層傳播條件下,建立了一個微博新聞事件信息可信度模型,即一級傳播提供了對事件信息可信度分析的基準,而多級多次傳播則為信息可信度分析和度量提供了一個基于網絡節點特征以及傳播動力學特征的新視角,并利用因子分析法和層次分析法,采用主客觀相結合的方式來確定指標體系的權重,實現了微博事件信息的可信度評判。郭國慶[39]在研究消費者在線評論可信度的影響時,在霍夫蘭德信息傳播模型的基礎上,從信源、信息內容、接受者以及社會影響這四個角度對在線評論內容的可信度進行研究,特別是將在線評論作為一個重要社會影響因素,提出了一個在線評論的可信度影響模型。Lucassell[40]利用信息語義(semantics)、表面特征(surface)和信息源(source)三者組成的3S模型來判斷信息的可信度,并展示了信任判斷的形成過程,通過實驗驗證了該模型具有較好的信息可信度識別率。
Wu[41]利用新浪微博官方公布的謠言庫建立了網絡信息可信度評估平臺(NICE),并用來評估社交媒體上未被檢驗可信性的信息可信度。該平臺首先從用戶特征、內容特征、時間特征和評論特征四個方面對事件信息進行可信度表示(the credibility representation),事件可信度表示如式(2)所示。
(2)
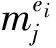
隨后,利用常規的邏輯回歸分類算法將信息劃分為謠言信息和非謠言信息,如圖3所示。基于該思路,NICE模型在評估信息可信度和檢測謠言方面具有了較好的性能。
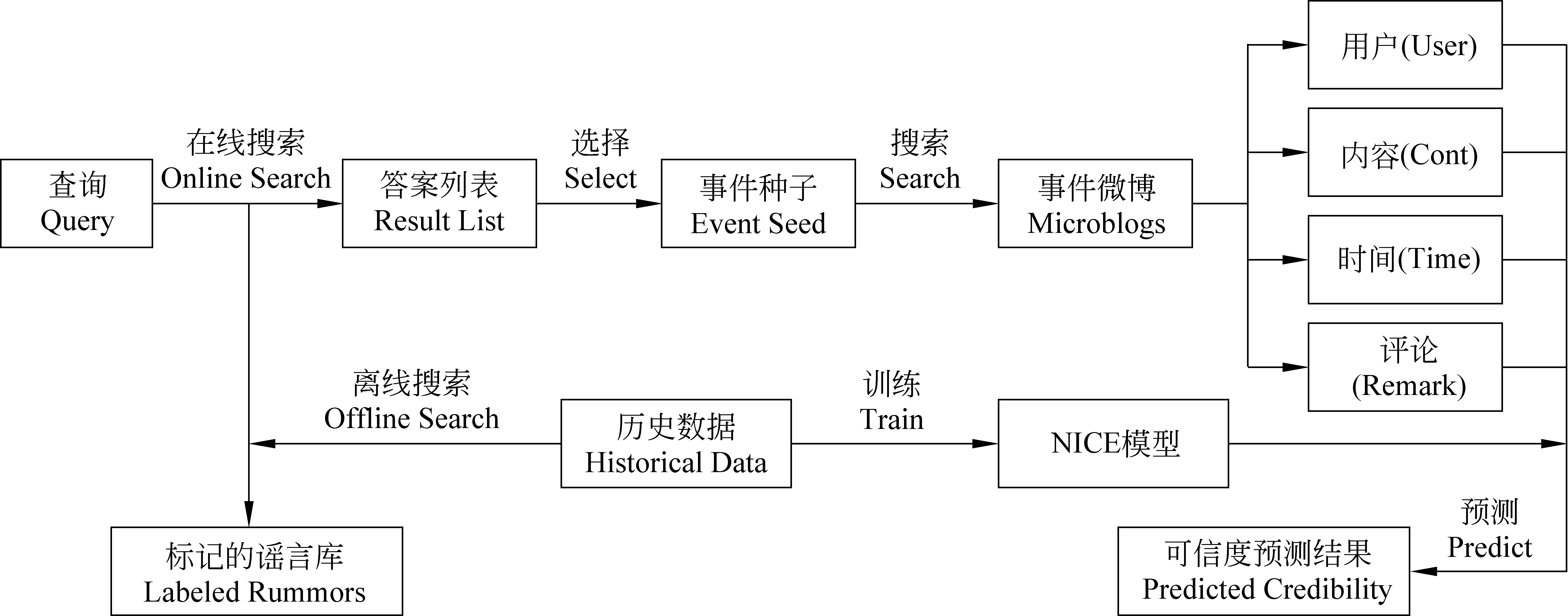
圖3 NICE平臺整體結構示意圖
3.2 基于淺語義特征的可信度模型
Gupta[42]在對信息可信度特征進行抽取的基礎上,采用有監督機器學習的RankSVM方法對微博信息進行可信度評分排序;同時,利用基于PageRank和事件圖相結合的算法來計算Twitter內容的可信度,并獲得較高的準確率[43]。Chang[44]則利用謠言特征所建立的五種結構和時間特征規則來對Twitter中的政治謠言以及極端用戶進行識別和檢測。為了進一步檢測具有多信息來源的網絡信息內容可信度,Pasternack[45]提出了一個LCA概率模型,該模型利用來自真實世界的兩個無監督數據集和兩個半監督的數據集,通過對內容的語義擴展來獲取更有價值的可信度特征因素,并提高了可信度判別的準確率。而Unankard[46]利用基于文本相似度和位置相關性聚類模型對Tweets的內容進行聚類,從而獲取更多信用語義特征,用來對Twitter中所發生的事件的信用特征進行評估。而Kyoto大學研發的基于聚類模型的WISDOM[47]信息可信度綜合評估系統,則通過對搜索引擎搜索結果中的一個或多個特征屬性進行內容聚類,如按照信息發送者、主要觀點和對立觀點等方面進行聚類,為用戶提供了多個角度的信息可信度評價。
3.3 基于媒體融合的深層語義理解研究可信度
深度學習技術快速發展,使得人們從信息內容表層淺顯語義研究過渡到了深層語義理解問題的研究上。例如,由于網絡偏激信息中存在一部分夸大的言論或者是貶低的事實,而另一部分信息往往是可信的,從簡單的淺層語義特征無法對該類信息做出準確的判斷與識別,這就需要進一步采用深層語義理解以提高對偏激信息可信度的識別準確率。而Takahashi抽取了謠言內容的日期、地點、人物和組織等信息特征,并對這些特征信息進行過濾,實現謠言檢測,利用淺層特征對謠言的識別率僅維持在34%左右。而Hamidian[27]加入了深層語義特征后,利用謠言內容的時間、標簽、URL、轉發等Twitter信息以及特定網絡特征和內容的一元模型、二元模型等語法特征信息,首次利用了100維的Twitter潛在向量(TLV)的語義特征進行謠言檢測,使得謠言的識別精確率提高到了97.2%。
另一方面,網絡中的信息越來越呈現出多媒體融合的新特征,大量的圖片、視頻和音頻等多媒體信息與本文信息相互結合且相互影響,通過不同媒體信息的可信特征的抽取與識別,以及語義特征的補充,例如,網絡中常說到的“有圖有真相”,就是將圖片中的可信特征與文本的可信特征進行了結合,提高了內容可信度的識別準確率,但同時也增加了計算處理的復雜程度。其中,如何對信息中存在的多媒體內容的真實性與可信性進行度量,以及多媒體信息內容與文本內容之間的可信度特征的融合策略等方面仍然存在著關鍵性的挑戰。
4 信息內容可信度測量評價方法
通過對信息可信度特征的抽取與信息可信度建模,可以對信息內容可信度進行計算和測量,但是如何評價測量結果的質量好壞與有效性,則是一個關鍵。一般地,可信度測量評價分為可信度的客觀評測和用戶感知評測兩方面,其中,客觀評測是指通過常規量化的客觀指標評測信息內容的可信度,這些指標包括真正率(TP-Rate)、真負率(TN-Rate)、假正率(FP-Rate)、假負率(FN-Rate)、準確率(Accuracy Rate)、精確率(Precision Rate)、召回率(Recall Rate)和F1度量(F1-measure)等。而用戶感知測評主要是從用戶自身感受的角度所形成的Checklist標準,其中包括時效性、權威性、客觀性、準確性以及信息覆蓋范圍等。這兩個方面從不同的側面和角度對信息內容的可信度進行了評測。此外,本文還對在線信息內容可信度的實時性測評以及基于實證的測評方法進行了介紹。
4.1 內容可信度客觀評測
內容可信度的客觀評測主要通過常規量化的客觀指標進行評測。Castillo[13]對文本特征子集、用戶特征子集、傳播特征子集和最常見特征子集等四個特征子集從真正率、假正率、精確率、召回率和F1度量等客觀指標進行內容可信度評估。Hardalov[1]利用信息內容的語法、內容和語義等特征,在三種不同的數據集上驗證虛假信息檢測的準確率,并在此基礎上對信息可信度進行評測,結果表明語法特征比內容特征的評價準確率更高,而基于語義特征的評價準確率最高。Zhang[48]使用精確率作為唯一客觀評估指標,利用GPPooled Brown、GPPooled Bow和Majority三種方法對Tweets的內容進行了謠言檢測,發現GPPooled Bow法的精確度明顯高于其他兩種算法。Liu[29]利用準確率從Tweets數量和時間上對文中提到的四種方法進行了評估,發現特定的算法組合將會在數量和時間上獲得最佳的準確度。
4.2 內容可信度的用戶感知評測
客觀指標是從內容的基本物理特征出發,來研究信息內容的可信度,缺少用戶主體自身對信息可信度的感受。因此,美國圖書館協會(ALA)主導的可信度評測系統則從信息的權威性、時效性、客觀性、公開性、準確性以及信息覆蓋范圍等標準,并采用Checklist方法來對網站信息的質量進行自動評估。Gupta[2]在基于半監督排序模型的基礎上,開發了一個實時可信度評分的瀏覽器插件TweetCred,它可以利用用戶打分和用戶問卷調查兩種反饋方式獲取用戶對信息的主觀評價,并實現對信息內容可信度質量的度量。Rieh[49]認為信息內容的可信度不是一個離散的評估事件,而是一個持續不斷的迭代過程,因此,通過主觀判斷來實現信息的真實性、可靠性、準確性和完整性的分類,以及信息可信度與信息質量的評價,這也是一個動態的過程。綜上,本文根據相關文獻[50]總結出與用戶感知評測相關的指標,如表5所示。

表5 信息可信度用戶感知指標
4.3 信息可信度實時自動檢測
在線網絡信息往往具有極強的時效性特征,特別是為了消除由于大量不準確或者虛假信息的廣泛傳播,對社交網絡以及社會和諧所造成的危害與負面的影響,如何對信息內容可信度進行實時的分析與檢測也成為了目前的研究關鍵與挑戰之一。傳統的謠言檢測方法一般是對每條Tweet內容進行可信度分析,但大多數情況下我們僅記得某個事件的關鍵字,很難完整地描述一條Tweet所敘述的事件。Gupta[2]利用開發的TweetCred插件,對540萬條Tweets信息的可信度進行計算,實驗結果顯示,82%的用戶檢測到系統中存在的不良信息,所需要的響應時間為6秒,99%的用戶檢測到不良信息的響應時間控制在10秒以內,從而保證了實時的可信度評分。Zhao[51]利用BOSTON數據集進行謠言檢測,利用改進算法來進行謠言檢測,其中檢測出46個謠言所使用的時間為4.3小時,而利用主題趨勢算法檢測出71個謠言的平均時間為3.6小時,利用標簽追蹤算法檢測35個謠言所需要的時間為2.8小時。由于信息傳播過程的復雜性與信息特征的差異性,面對海量的在線信息,在實時檢測的基礎上,提高信息可信度識別的準確率,仍然是未來研究的熱點之一。
4.4 信息可信度的實證研究
實證研究能夠為網絡傳播中的信息在可信度檢測方面提供有效的佐證,并通過問卷調查來獲得信息可靠性與可信性的評判依據。目前,信息可信度的實證研究主要是針對特定的熱點事件,而網絡中不同類型的信息可信度的實證研究并沒有形成通用方法或架構,如湯志偉[19]選取了汶川大地震作為網絡公共危機案例,采用實證方法研究信息的可信度問題。結果顯示,網民對政府與傳統媒體所發布的信息的可信度評價顯著高于普通網民發布的信息,而對網絡新聞的可信度要高于論壇信息和即時通信工具所傳播的信息。此外,網民在公共危機時對網絡信息的可信度評價與其所具有的網絡經驗、信任傾向顯著相關,但與性別、年齡等因素不存在明顯相關性。
5 研究展望
本文針對目前網絡傳播信息內容的可信度研究進行了分析與綜述。首先,通過對信息特征的梳理,將信息分為可信信息與不可信信息,且不可信信息根據可信的程度又進一步分為:極端突發事件信息、網絡偏激信息、網絡謠言、虛假信息、誤報信息和垃圾信息等六種類型,并結合信息在網絡中的傳播特點與要素從內容、話題、媒介、傳播者和接受者等維度對不同類型的信息進行了特征描述與定義。其次,從信息內容與信息傳播等淺層語義特征、基于多媒體的信息融合以及深層語義理解等角度,對信息的可信度建模工作進行了梳理與歸納總結。在此基礎上,本文對信息內容可信度的評價方法進行了分析,并通過從客觀評測、用戶感知評測、信息實時性和實證評價等多個方面對信息可信度的評測標準與方法進行了分析與介紹。
此外,本文針對網絡傳播信息可信度分析過程中存在的關鍵技術與挑戰也進行了介紹和分析,特別是在目前社交網絡正在呈現出海量實時交互條件下的跨語言、跨媒介以及跨媒體的新特征,也為網絡傳播的信息的可信度識別帶來了前所未有的新挑戰。例如,當考慮到來自新聞、微博、微信、論壇等不同類型的跨媒介信息交叉擴散傳播的過程中,由于信息產生的來源、環境、傳播者、接受者、媒介等要素都發生了不同程度的變化,從而導致了原有的單網絡媒介信息傳播過程中的信息可信度研究方法無法應用于跨媒介情況,因此,需要創建一些全新的跨域條件下的網絡傳播信息可信度的分析與建模方法與策略。同樣,當考慮到多語言信息之間的關聯、自動翻譯與聚類跟蹤,以及多媒體條件下的語義映射,都為信息可信度的分析提出了更高的要求與挑戰。解決這些問題,不僅需要通過知識圖譜與知識推理,同時也需要對信息的傳播動力學機制進行深入研究,在此基礎上,結合目前的深度學習以及強化學習的策略,逐步尋找到一個更好的信息可信度的識別與分析方法,而這些工作與挑戰也不斷激勵著人們向更高的研究目標前進。
[1]Hardalov M,Koychev I,Nakov P.In search of credible news[C]//Proceedings of the AIMSA 2016,Springer,LNAI9883,2016:172-180.
[2]Howell L.Digital wildfires in a hyperconnected world [R/OL].http://reports.wetorum.org/global-risks-2013/risk-case-11digital-wildfires-in-a-hyper connected-world1,2013.
[3]Gupta A,Kumaraguru P,Castillo C,et al.TweetCred:Real time credibility assessment of content on Twitter[C]//Proceedings of the SocInfo 2014,2014:228-243.
[4]中國災害防御協會.中華人民共和國突發事件應對法[2007][G].中國突發公共事件防范與快速處置2008優秀成果選編.2008.
[5]Ratkiewicz J,Conover M,Meiss M,et al.Detecting and tracking the spread of astroturf memes in microblog streams[J].Computer Science,2010:249-252.
[6]Karlova N A,Lee J H.Notes from the underground city of disinformation:A conceptual investigation[C]//Proceedings of the ASIST 2011,2011,48(1):1-9.
[7]West M D.Validating a Scale for the measurement of credibility:A covariance structure modeling approach[J].Joumalism Quarterly,1994,71(1):159-168.
[8]Tseng S,Fogg B J.Credibility and computing technology[J].Communications of the ACM,1999,42(5):39-44.
[9]周東浩,韓文報,王勇軍.基于節點和信息特征的社會網絡信息傳播模型[J].計算機研究與發展,2015,52(1):156-166.
[10]Metzger M J.Making sense of credibility on the web:Models for evaluating online information and recommendations for future research[J].Journal of the American Society for Information Science and Technology,2007,58(13):2078-2091.
[11]方濱興,賈焰,韓毅.社交網絡分析核心科學問題、研究現狀及未來展望[J].中國科學院院刊,2015,30(2):187-199.
[12]Miyamori H,Akamine S,Kato Y,et al.Evaluation data and prototype system WISDOM for information credibility analysis[J].Internet Research,2008,18(2):155-164.
[13]Castillo C,Mendoza M,Poblete B.Information credibility on Twitter[C]//Proceedings of the 20th international conference on World wide web.ACM,2011:675-684.
[14]J O’Donovan,B Kang,G.Hllerer,et al.Credibility in context:An analysis of feature distribution in Twitter[J]Prjuacn,Searity,Risk & Trust,2013,545(3):293-301.
[15]Metzger M J,Andrew J F.Credibility and trust of information in online environments:The use of cognitive heuristics[J].Journal of Pragmatics,2013,59(112):210-220.
[16]J H Lipschultz,Social Media Trust,Credibility and Reputation Management [EB/OL],https://www.huffingtonpost.com/jeremy-harris-lipschultz/soliul-media-trust-credib_b_3858017.html,2013.
[17]Castillo C,Mendoza M,Poblete B.Predicting information credibility in time-sensitive social media(+supplementary material).Internet Research[J].2013,23(5):560-588.
[18]徐靜,楊小平,柳增.基于內容信任的Web信息可信度驗證方法研究[J].北京理工大學學報,2014,34(7):710-715.
[19]湯志偉,彭志華,張會平.網絡公共危機信息可信度的實證研究——以汶川地震為例[J].情報雜志,2010,29(2):45-49.
[20]Thomson R,Ito N,Suda H,et al.Trusting tweets:The Fukushima disaster and information source credibility on Twitter[C]//Proceedings of the 9th International ISCRAM Conference,2012:1-10.
[21]Mendoza M,Poblete B,Castillo C.Twitter under crisis:Can we trust what we RT?[C]//Proceedings of the 1st Workshop on Social Media Analytics.ACM Press,2010:71-79.
[22]薛傳業,夏志杰,張志花,等.突發事件中社交媒體信息可信度研究[J].現代情報,2015,35(4):12-16.
[23]Lewandowsky S,Ecker U K,Seifert C M,et al.Misinformation and its correction continued influence and successful debiasing[J].Psychol Sci Public Interest,2012,13(3):106-131.
[24]Peterson W A,Gist N P.Rumor and public opinion[J].American Journal of Sociology,1951,57(2):159-167.
[25]Turner R H, Kapferer J N, Fink B.Rumors:Uses,Interpretations and Images[J].Contemporary Sociology,,1990,20(5):794.
[26]Bessi A,Coletto M,Davidescu G A,et al.Science Vs.conspiracy:Collective narratives in the age of Misinformation [J].Plos One,2015,10(2):1-17.
[27]Hamidian S,Diab M T.Rumor identification and belief investigation on Twitter[C]//Proceedings of the 7th WASSA,2016:3-8.
[28]Yang F,Liu Y,Yu X,et al.Automatic detection of rumor on Sina Weibo[C]//Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics.ACM,2012:13.
[29]Liu X,Nourbakhsh A,Li Q,et al.Real-time rumor debunking on Twitter[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management.ACM,2015:1867-1870.
[30]Fallis D.A conceptual analysis of disinformation[C]//Proceedings of the 4th Amual iConference,2009.
[31]Kumar K P K,Geethakumari G.Detecting misinformation in online social networks using cognitive psychology[J].Human-centric Computing and Information Sciences,2014,4(1):1.
[32]Karlova N A,Fisher K E.Plz RT:A social diffusion model of misinformation and disinformation for understanding human information behaviour[J].Inform Research,2013,18(1):1-17.
[33]DeNeys W,Cromheeke S,Osman M(2011)Biased but in doubt:Conflict and decision condence[J].Plos One 6(1):e15954.
[34]Wang A H.Don’t follow me:Spam detection in Twitter[C]//Proceedings of the 2010 International Conference on Security and Cryptography.IEEE,2010:1-10.
[35]Tan E,Guo L,Chen S,et al.Unik:Unsupervised social network spam detection[C]//Proceedings of the 22 nd ACM internulind conference on information & knowle dge management 2013:479-488.
[36]Fogg B J.Prominence-interpretation theory:Explaining how people assess credibility online[C]//Proceedings of the ACM Chi Lauderdle Florida Usa ACM,2003 722-723.
[37]Sundar S S.Technology and credibility:Cognitive heuristics cued by modality,agency,interactivity and navigability[J].Digital Media,Youth,and Credibility.MacArthur Foundation Series on Digital Media and Learning,2007:73-100.
[38]高雅.微博新聞事件信息可信度評價[D].吉林:吉林大學碩士學位論文,2013.
[39]郭國慶,陳訊,何飛.消費者在線評論可信度的影響因素研巧[J],當代經濟管理,2010(10):17-23.
[40]Lucassen T,Schraagen J M.Factual accuracy and trust in information:The role of expertise[J].Journal of the Association for Information Science and Technology,2011,62(7):1232-1242.
[41]Wu S,Liu Q,Liu Y,et al.Information credibility evaluation on social media[C]//Proceedings of the 13th AAAI Conference on Artificial Intelligence,2016.
[42]Gupta A,Kumaraguru P.Credibility ranking of Tweets during high impact events[C]//Proceedings of the 1st workshop on Privacy and security in Onlire Social Media.2012:2-8.
[43]Gupta M,Zhao P,Han J.Evaluating Event Credibility on Twitter[C]//Proceedings of the 2012 SIAG/DM,2012:153-164.
[44]Chang C,Zhang Y,Szabo C,et al.Extreme user and political rumor detection on Twitter[C]//Proceedings of the Advanced Data Mining and Applications.Springer International Publishing,2016:751-763.
[45]Pasternack J,Dan R.Latent credibility analysis[C]//Proceedings of the International Conference on World Wide Web.2013:1009-1020.
[46]Unankard S.,Li X,Sharaf M A.Emerging event detection in social networks with location sensitivity[J].World Wide Web-internet & Web Information Systems,2015,18(5):1393-1417.
[47]Akamine S,Kawahara D,Kato Y,et al.WISDOM:A web information credibility analysis system[C]//Proceedings of the ACL-IJCNLP 2009 Software Demonstrations.Association for Computational Linguistics,2009:1-4.
[48]Zhang Y,Szabo C,Sheng Q Z,et al.Classifying perspectives on twitter:immediate observation,affection,and speculation[C]//Proceedings of the 16th International Conference on Web Information Systems Engineering,Part I,493-507.
[49]Rieh S Y.Credibility and cognitive authority of information[N].Bates M Maack M N.Encyclopedia of library and information sciences:3rd ed.New York:Taylor and Francis Group,LLC,2010:1137-1344.
[50]馮曉碩.[C].全國計算機信息管理學術研討會,2013.
[51]Zhao Z,Resnick P,Mei Q.Enquiring minds:Early detection of rumors in social media from enquiry posts[C]//Proceedings of the 24th International Conference on World Wide Web.ACM,2015:1395-1405.

吳連偉(1992—),博士研究生,主要研究領域為自然語言處理、信息可信度識別與分析。E-mail:wlianwei@qq.com

饒元(1973—),博士生導師,主要研究領域為社會智能與復雜數據處理。E-mail:yuanrao@163.com

樊笑冰(1993—),碩士研究生,主要研究領域為自然語言處理、可信信息傳播動力學機制研究。E-mail:fanxiaobing212@outlook.com
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
