基于Hadoop-Mahout的分布式課程推薦算法
2018-04-18 11:39:48徐文健劉青昆鄭曉薇李永波
計算機應用與軟件 2018年3期
徐文健 劉青昆 鄭曉薇 李永波
1(遼寧師范大學計算機與信息技術學院 遼寧 大連 116081) 2(瓦房店市第八高級中學 遼寧 大連 116300)
0 引 言
2012年是大規模開放在線課程MOOC元年,隨著MOOC的全球化,MOOC的學習者和課程規模都在不斷擴大,并且逐漸在各個高校的教育方式中發揮著重要的作用。
MOOC的全新學習模式的優點十分突出,然而在這種自由選課和自主學習的學習模式下,不可避免地會出現傳統學習模式下未曾遇到的一些問題:比如在線課程種類繁多、魚龍混雜,學習者很多時候并不能找到真正適合自己的課程。當學習者發現課程并不適合自己時,學習時間已經過半,在不停的切換課程后可能會對課程學習失去耐心。而隨著學習過程的進行,學習者對課程表現出的忠誠度也會發生變化,最終能堅持將課程學習完成的只是一小部分[1]。以上問題的出現導致了在線學習者的學習效率降低、學習質量難以保證。在有些MOOC平臺上為學習者提供了相應的課程推薦功能,通過對學習者的學習記錄等信息來分析用戶或課程之間相似程度以及課程的熱門程度。但隨著MOOC學習者的人數逐漸增加,大量學習者的數據加大了服務器的負載和工作壓力;同時目前的推薦算法不能針對性地給學習者個性化推薦,推薦結果往往并不盡如人意。
利用Apache-Mahout機器學習框架中的協同過濾推薦算法可對在線課程進行評價,得到相應的推薦值矩陣。但這種算法對課程的評價僅考慮了學習這門課程的人數的多少以及部分讀者的評論,沒有將課程本身的質量因素和適用性加入到對學習者進行推薦的過程中。本文從對在線課程作綜合評價的角度提出IRS課程評價方法,以交互度I、評價率R、用戶評分S等參數作為評價指標。在進行個性化推薦時,將用戶的偏好與IRS結合形成新的推薦算法。本文在Hadoop分布式云計算環境下,以慕課網學習者的學習數據為實驗樣本,Hadoop集群中各個節點對數據進行并行處理,處理速度快、延遲低且易于操作。實驗結果表明本文的IRS推薦算法所推薦的課程更適合學習者的個性化學習。實驗數據體現了在Hadoop集群下IRS并行推薦算法對大數據量處理的高效性,同時驗證了該推薦算法的可行性。
1 IRS課程評價方法
1.1 學習參與度與交互度
參與度的概念在傳統課堂教學的研究中已經有很多成果,早期研究中將學習參與度定義為學生關注,并完成一定學習任務的學習參與行為表現。之后學者不斷對學習參與度的概念提出新的內容和新的定義,現在的學習參與度的概念在原有概念的基礎上加入了學習者情感方面的內容,不僅指學生完成學習任務,同時在學習的過程中的積極認知、行為、情感等表現[2]。
在線學習參與度與傳統課堂教學的參與度最大的不同在于學習環境的不同,而兩種環境下學習者學習參與的實質是相同的。同樣是在完成學習任務時,表現于努力理解學習內容,花費精力解決學習中出現的問題,反復觀看課程視頻、反復研讀課程資料課件、積極與老師同學進行交流探討、認真完成作業、分享學習成果、幫助學習者解決難題等[3]。由此可見,學習者對于一門課程的參與度很大程度上影響了學習者對該課程感興趣的程度,因而可以將其作為評價該門課程的一項指標。為了更合理地描述學習者對課程的認可程度,基于學習參與度的定義,本文提出交互度I的概念,指學習者對于所學習的某門課程,單位時間內與該課程的平均交互的次數。其量化公式為:
(1)
式中:Q代表交互數,指學習者在學習一門課程中,做筆記、問答、評論、作業、觀看視頻等動作的總次數;RC代表完成率,表示某人學習此門課程的進度,即當前已完成課程量與課程總量的比值;T代表課程時長;n為學習者樣本的數量。
1.2 IRS評價指標
慕課網是垂直的互聯網IT技能免費培訓的網站,網站中有涵蓋IT領域各方面超多700個課程,數以百萬計的學習者。在用戶對于課程的學習中,學習者可對內容是否充實、邏輯是否清晰,是否簡單易懂進行打分。經統計,截至2017年3月30日之前,在慕課網已有的課程評分中,學習者對內容充實、邏輯清晰、簡單易懂的平均評分分別為9.79、9.57、9.50(10滿分),學習者的綜合平均評分為9.60分(10滿分)。從各個課程來看,絕大多數課程的評分均高于9.0分,由此可看出,參與評價的學習者對課程表示認可的程度很高。但由于參與評價的學習者在總學習人數中不足百分之一,僅憑少數學習者的評分并不能全面評價一門課程。
為了更客觀、合理地評價一門在線課程,本文提出一個評價對象基于課程的IRS指標評價方法,用于評價一門課程是否具有傳統意義上較高的參與度,對學習者有較大的吸引力,使其更好地參與到課程學習當中。IRS指標中:I為交互度;評價率R為參與該課程評價的總人數與參加該課程學習的總人數的比值,該數值越高,體現出越多學習者愿意為該課程進行評價,為保證數據可用性,采用千分數記錄數據,見式(2)。評分S為參與評價的所有用戶根據各個方面對該課程的主觀打分的平均值。

(2)
IRS指標評價量化公式為:
IRS=α1I·+α2R·+α3S·
(3)
式中:α1、α2、α3為I、R、S各個指標的權重,通過熵值法確定。I·、R·、S·為各個課程所對應指標的真實值。表1列舉出了IRS評價指標中各個指標的含義。
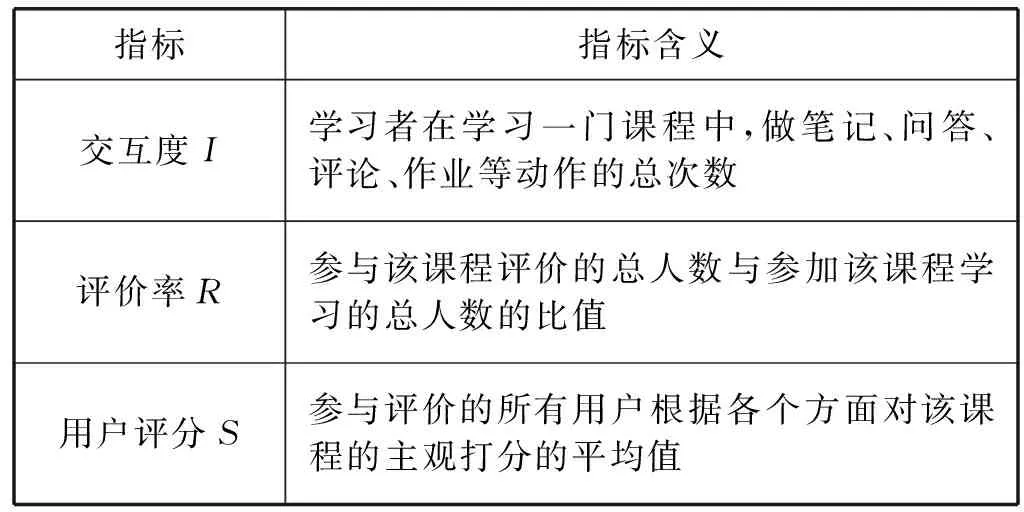
表1 IRS各個指標的含義
IRS評價指標權衡影響學習者學習質量的三個因素,綜合并客觀地對一門課程進行量化,從而進行課程評價。
本文爬取并計算Java入門、Ajax全接觸、C語言入門等15門課程的各個指標的數據,得到各指標的權重:α1=0.662、α2=0.205、α3=0.133,由此可見交互度在IRS指標系列中所占比重較大,學習者在學習的過程中是否能夠更多地參與到課程中去,對于評價一門課程有著重要的參考意義。
2 分布式云計算推薦服務與算法
推薦系統的作用在于通過數據挖掘等技術,找到用戶與物品等信息上的聯系,通過對信息的分析與計算,發現適合用戶或用戶更感興趣的信息,結合這些信息對用戶做出相應的推薦[4]。在實際應用中,系統在對用戶進行推薦時,需要實時處理大量數據,為了保證推薦系統能夠高效地處理海量數據,分布式云計算能出色地完成任務。
2.1 Hadoop與Mahout簡介
作為目前應用廣泛的云計算平臺,Hadoop具有計算效率高、穩定性好、開源等特點。Hadoop的核心:HDFS(分布式文件系統),實現對分布式存儲的底層支持[5];MapReduce是云計算并行框架,Map(拆分映射)和Reduce(化簡規約),其思想是:Map函數將數據切割為獨立的數據塊,分配給Hadoop集群做并行計算,再通過Reduce函數將結果匯總,輸出需要的結果[6]。其函數式編程思想的概念表達可表示為:
Map
Mahout是ASF(Apache Software Foundation)旗下的一個開源項目,提供了可擴展的機器學習領域經典算法的實現。其主要部分為協同過濾(CF)、推薦引擎(recommender)、聚類(clusting)和分類(classification)[7]。通過Apache Hadoop庫,可以將Mahout擴展至分布式云計算平臺,并進行相應的計算功能。
2.2 Mahout推薦算法
2.2.1共現矩陣
在Mahout協同過濾推薦算法中,用到共現矩陣M。共現矩陣中的元素為在某些用戶偏好值列表中每個項目對共同出現的次數,即用戶對兩種項目同時偏好的次數,矩陣中對角線上的元素無效。
2.2.2計算用戶向量
在進行個性化推薦時,將每一個用戶的偏好視為一個向量,這些用戶偏好被視為n維空間中的點,每個維度代表一個項目,用戶對項目的偏好值為此向量中的值,用戶沒有表達偏好的項目映射維向量中的0值。由于用戶通常情況下只對一小部分項目表達過偏好,所以用戶向量中的值大多為零,是一個系數矩陣。
2.2.3產生推薦結果
將共現矩陣M和用戶向量U相乘得到推薦結果R,如下式所示:
(4)
式中:對于課程x,uix代表用戶i對應的偏好值,Rix為推薦值,在得到的推薦值矩陣R中,矩陣R對應的值為相應課程的推薦值,將這些值從大到小進行排序即為所求推薦結果[8]。
2.3 IRS在線課程推薦算法
2.3.1IRS推薦算法
基于原始的Mahout推薦方法,引入IRS指標評價,將學習者對已學習過的課程的評分作為用戶偏好值構成向量,得到改進后的推薦方法。如下式所示:
(5)

2.3.2算法實現
在Mahout工具中,org.apache.mahout.cf.taste.hadoop.item.RecommenderJob
將推薦過程中各種Mapper和Reducer組件粘連在一起,將原封裝代碼中偏好值的計算方式按照式(5)進行更改,在HDFS中得到改進后的偏好值和偏好向量。
2.4 IRS分布式推薦算法流程
本文通過網絡爬蟲從慕課網得到學習者的數據,包括學習者學習過的課程和對應的評分,在Mahout的RecommenderJob作業下,進行分布式計算,其推薦算法的基本流程為:
(1) 生成用戶向量:map函數解析每一個用戶ID和若干個課程ID,實現一一對應的關系;Reduce函數利用全部課程ID,與用戶的偏好值對應,構造用戶向量。
(2) 計算共現關系:將流程(1)的輸出結果作為輸入,通過第二個MapReduce函數,循環遍歷非零元素進行累計,統計課程共現的次數,得到共現矩陣。
(3) 計算用戶偏好向量:將預計算的k值與學習者對應的偏好值做乘積,構成用戶偏好向量;對流程(2)得到的共現矩陣的每一列的列向量與用戶向量的對應元素相乘,將結果保存至推薦向量R中。
(4) 計算矩陣乘:通過兩個MapReduce函數將共現矩陣與用戶向量歸并為一條輸出記錄并存儲下來。
(5) 形成推薦:算法為每個用戶合并推薦向量,將推薦值按從大到小的順序進行排序,除去學習者已經學習過的課程,找到N個最大值(為方便計算和統計,本文實驗中N取值為3),輸出得到推薦結果。
3 實驗及結果分析
3.1 實驗環境
本文中實驗使用的硬件平臺由三臺CPU Inter(R) E5-2609 四核2.40 GHz、8 GB的惠普PC構建,其中一臺Hadoop3作為主機來分配任務,其余兩臺Hadoop2、Hadoop1作為從機來實現計算任務。搭載Ubuntu 14.04操作系統,安裝JDK1.7.0_25、Hadoop-2.7.3、mahout-0.12.0和Eclipse java EE IDE集成開發環境。設定分布式環境Hadoop和mahout環境存放目錄為/usr/hadoop。
3.2 實驗內容
本次實驗分別選取了1.5 MB(18 600條記錄)、3.0 MB(37 306條記錄)、6.0 MB(74 512條記錄)、12.0 MB(149 024條記錄)四種數據量大小不同的學習者信息,數據文件表(部分)內容為不同的學習者所學習過的課程及課程編號,如圖1所示。在Hadoop-Mahout環境下通過單個節點、雙節點和三節點分別對這些數據表進行實驗。
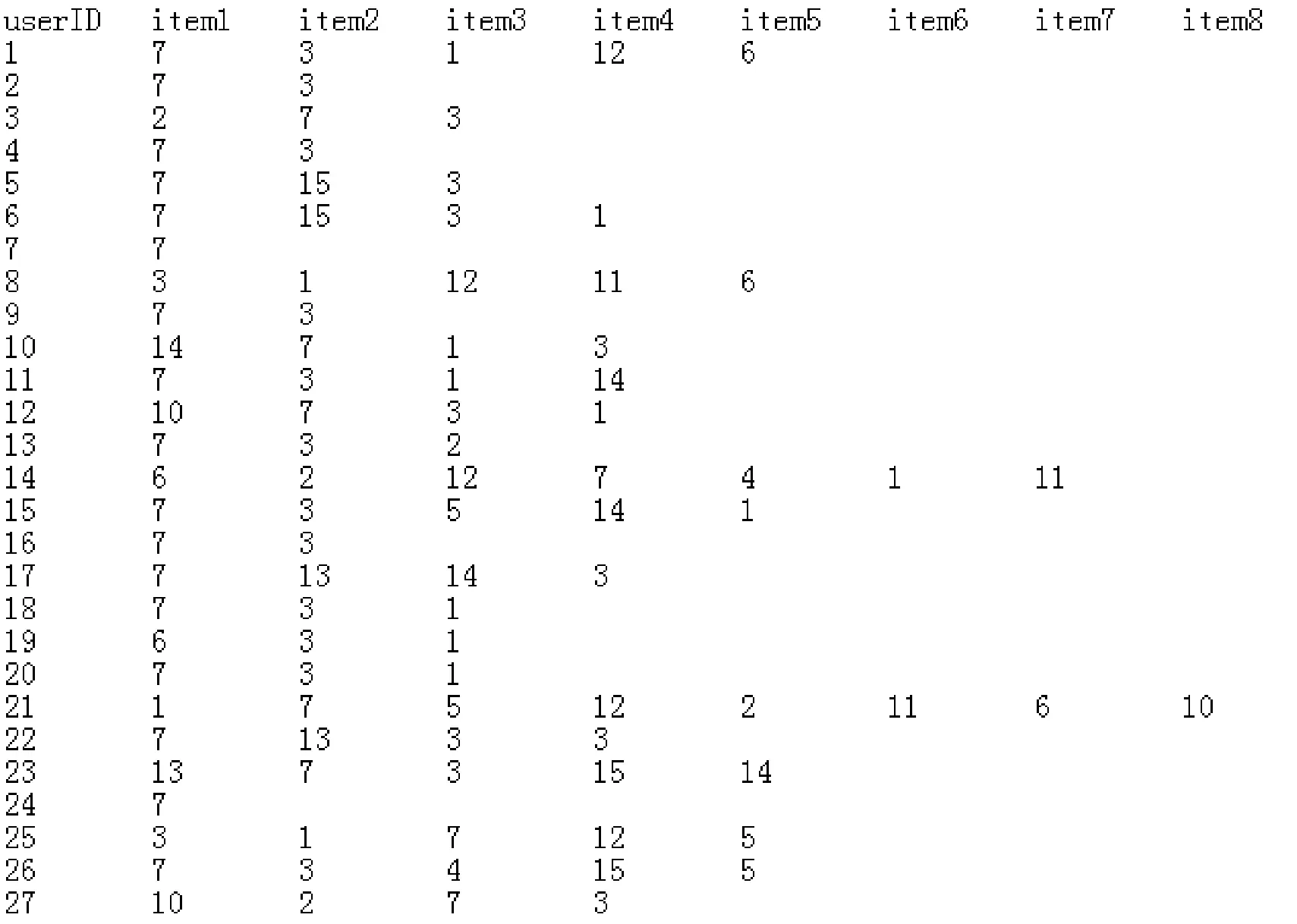
圖1 userID-itemID數據文件
以1.5 MB大小的數據文件表的分布式計算為例,輸出的推薦結果如圖2所示,輸出格式為:userID [itemID:R1,itemID2:R2,itemID3:R3]。

圖2 1.5 MB文件推薦結果
從輸出結果看出,對用戶1的推薦課程為2號、11號、12號課程,推薦指數分別為1 824 365,1 043 211,775 426。圖中其他行是對其他用戶的推薦結果。
并行加速比用來衡量并行機工作的速度,即順序執行時間與并行執行時間的比值;并行效率為加速比與節點個數的比值。本實驗的評價數值計算如表2所示。

表2 并行執行效果對比
表2顯示出在不同的數據規模中,隨著數據量的增大,集群所承擔的額外開銷所占的比例變小,加速比和并行效率也相應增加。從而證明本文設計的推薦算法適用于分布式環境,并驗證了分布式環境下并行計算的高效性。
通過實驗可得出結論:在節點數目一定時,執行時間的縮短趨勢隨著數據規模的增加而加大;在數據規模一定時,執行時間隨節點數的增加而相應大幅減少[9]。
3.3 推薦效果
本實驗隨機選取100名學習者的學習數據,抽取相關的在線課程作為測試數據集,對改進前后的推薦算法分別進行實驗,計算分析兩者的差別。

(6)
(7)
計算結果表明,雖然IRS推薦算法的推薦結果命中174門課程(共300門推薦課程)、命中率58%,相比較Mahout推薦算法的命中213門課程、命中率71%較低,但評分差為0.448。評分差為正值表明IRS推薦算法較Mahout推薦算法推薦了更多被學習者忽略或還沒有被學到的高質量課程,且IRS推薦算法的推薦課程對于學習者來說評分更高,滿意程度更好。所以本文的推薦算法更適合學習者的個性化學習。
4 結 語
本文提出的IRS在線課程分布式推薦算法,在機器學習框架Mahout協同過濾推薦算法的基礎上,將評價對象基于課程的IRS指標評價方法與用戶的偏好結合,形成更適合學習者個性化學習的推薦算法。本實驗以Hadoop云計算平臺的MapReduce為基礎,將大量在線學習者的學習行為數據分配于集群的節點機,極大地加快了推薦算法的運行速度。新的推薦算法在Hadoop分布式云平臺的運行,不僅解決了在線課程推薦系統的實時性需求,為學習者更加客觀、科學地推薦課程;同時在大量數據的網絡環境中,提高運行速度,減輕服務器的工作負載。在遠程教育和在線教育領域的建設中,對提高網絡課程的學習質量和工作效率具有較重要的參考意義。
[1] 魏玲,李陽. 基于RFL的MOOC學習者細分忠誠度研究——以“怪誕行為學”課程為例[J].現代教育技術.2016,26(11):67-73.
[2] Skinner E A, Belmont M J. Motivation in the classroom: Reciprocal effects of teacher behavior and student engagement across the school year.[J]. Journal of Educational Psychology, 1993, 85(4):571-581.
[3] 朱文輝,靳玉樂.網絡化合作活動學習對教育碩士在線學習參與度影響的行動研究[J].中國電化教育,2013,319(8):48-54.
[4] 孟祥武,劉樹棟,張玉潔,等.社會化推薦系統研究[J].軟件學報,2016,26(6):1356-1372.
[5] 趙彥榮,王偉平,孟丹,等.基于Hadoop的高效連接查詢處理算法CHMJ[J].軟件學報,2012,23(8):2032-2041.
[6] 江務學,張璟,王志明.MapReduce并行編程架構模型研究[J].微電子學與計算機,2011,28(6):168-170.
[7] 劉剛. Hadoop應用開發技術詳解[M].北京:機械工業出版社,2014.
[8] 李龍飛.基于Hadoop+Mahout的智能終端云應用推薦引擎的研究與實現[D].西安:電子科技大學,2013.
[9] 鄭曉薇,馬琳. 基于Hadoop集群的多表并行關聯算法及應用[J].微型機與應用,2013,32(4):91-93.
猜你喜歡
小學教學研究(2022年18期)2022-06-29 02:18:18
石油瀝青(2021年4期)2021-10-14 08:50:44
甘肅教育(2020年24期)2020-04-13 08:24:40
勞動保護(2019年3期)2019-05-16 02:38:06
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
創業家(2015年5期)2015-02-27 07:53:25
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
