基于鄰接矩陣的業(yè)務(wù)流程間距離計(jì)算方法
2018-04-19 08:04:19吳亞鋒
計(jì)算機(jī)工程 2018年4期
吳亞鋒,,2
(1.南京航空航天大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,南京 211106;2.上海第二工業(yè)大學(xué) 計(jì)算機(jī)與信息工程學(xué)院,上海 201209)
0 概述
隨著業(yè)務(wù)流程管理技術(shù)的不斷發(fā)展,企業(yè)應(yīng)用的各類(lèi)信息管理系統(tǒng)越來(lái)越多,如人力資源管理系統(tǒng)、供應(yīng)鏈管理系統(tǒng)、企業(yè)資源計(jì)劃系統(tǒng)等。記錄企業(yè)運(yùn)行的數(shù)據(jù)信息以事件日志的形式保存在這些信息管理系統(tǒng)中[1],這些保存下來(lái)的數(shù)據(jù)信息蘊(yùn)藏著企業(yè)運(yùn)行的具體執(zhí)行過(guò)程,具有重大的商業(yè)價(jià)值。如何利用好保存下來(lái)的數(shù)據(jù)信息,是企業(yè)面臨的重要問(wèn)題。
關(guān)于業(yè)務(wù)流程間距離的計(jì)算問(wèn)題,即業(yè)務(wù)流程相似度的計(jì)算,一直是企業(yè)界和學(xué)術(shù)界共同關(guān)心的熱點(diǎn)問(wèn)題。但現(xiàn)有流程相似度計(jì)算方法多數(shù)僅考慮流程模型本身所蘊(yùn)含的信息,忽視了保存在信息系統(tǒng)中事件日志的重要作用。針對(duì)該問(wèn)題,本文基于信息管理系統(tǒng)保存的事件日志提取活動(dòng)軌跡,利用文獻(xiàn)[2]提出的變遷緊鄰關(guān)系,通過(guò)遍歷事件日志中的活動(dòng)軌跡尋找兩兩活動(dòng)之間存在的緊鄰活動(dòng)關(guān)系,利用此關(guān)系的組合構(gòu)造鄰接矩陣,并將其結(jié)合事件日志中案例軌跡發(fā)生的總次數(shù)得到概率鄰接矩陣,最后以矩陣間的距離表示業(yè)務(wù)流程間的距離。
1 相關(guān)工作
現(xiàn)有的業(yè)務(wù)流程相似度計(jì)算方法都是從業(yè)務(wù)流程模型本身出發(fā),主要可以分為3類(lèi):1)文本內(nèi)容相似度計(jì)算;2)流程模型結(jié)構(gòu)相似度計(jì)算;3)流程行為相似度計(jì)算。
文本內(nèi)容相似度計(jì)算主要從節(jié)點(diǎn)的語(yǔ)法、語(yǔ)義、屬性、類(lèi)型和節(jié)點(diǎn)上下文進(jìn)行計(jì)算[3-5],這類(lèi)方法計(jì)算簡(jiǎn)單、快捷,只需計(jì)算節(jié)點(diǎn)對(duì)應(yīng)標(biāo)簽文本的相似度。然而,當(dāng)流程模型的結(jié)構(gòu)發(fā)生改變影響流程間相似度時(shí),該類(lèi)方法卻無(wú)法捕獲,因此,其準(zhǔn)確性不高。
現(xiàn)有流程結(jié)構(gòu)相似度計(jì)算方法大多通過(guò)計(jì)算流程拓?fù)浣Y(jié)構(gòu)的相似度,基于圖編輯距離[6]或樹(shù)編輯距離[7]計(jì)算流程結(jié)構(gòu)相似度。首先通過(guò)某種編輯距離來(lái)計(jì)算流程拓?fù)浣Y(jié)構(gòu)的相似度;然后使用流程拓?fù)浣Y(jié)構(gòu)的相似度表示流程結(jié)構(gòu)相似度。流程模型的拓?fù)浣Y(jié)構(gòu)反映了不同業(yè)務(wù)邏輯單元之間的邏輯關(guān)系,如順序、選擇、并行和循環(huán)等。
關(guān)于流程行為相似度的計(jì)算,早期的方法主要集中于流程等價(jià)方面,如軌跡等價(jià)[8]、互模擬等價(jià)[9]。然而這些方法只能得到等價(jià)與非等價(jià)結(jié)果,無(wú)法求出流程行為相似度的具體數(shù)值,因此,在大多數(shù)實(shí)際應(yīng)用中是無(wú)效的。現(xiàn)有計(jì)算結(jié)果較好的流程行為相似度計(jì)算方法有變遷緊鄰關(guān)系法、行為輪廓法、主變遷序列法和因果足跡法。
文獻(xiàn)[2]提出了一種稱(chēng)為變遷緊鄰關(guān)系(Transition Adjacent Relation,TAR)算法的流程相似性度量方法。該方法以Petri網(wǎng)為建模基礎(chǔ),通過(guò)計(jì)算流程變遷之間的兩兩緊鄰關(guān)系來(lái)構(gòu)造TAR集合,最后以2個(gè)TAR集合之間的Jaccard系數(shù)表示2個(gè)流程的相似度。文獻(xiàn)[10]在TAR算法的基礎(chǔ)上提出TAR++算法,其在具有緊鄰關(guān)系的任務(wù)之間增加一個(gè)重要性系數(shù),再使用帶重要性系數(shù)的任務(wù)緊鄰關(guān)系集合的相似度表示流程行為的相似度。
文獻(xiàn)[11-12]提出了一種稱(chēng)為行為輪廓(Behavioral Profile,BP)算法的流程行為相似性計(jì)算方法,其對(duì)TAR中的緊鄰關(guān)系進(jìn)行擴(kuò)充,允許將流程變遷之間的非緊鄰關(guān)系定義為一種弱關(guān)系,從而將變遷關(guān)系細(xì)化,具體包含嚴(yán)格順序關(guān)系、交錯(cuò)順序關(guān)系和互斥關(guān)系等。但是該方法無(wú)法有效處理不可見(jiàn)任務(wù),也不能區(qū)分循環(huán)結(jié)構(gòu)和并發(fā)結(jié)構(gòu)。
文獻(xiàn)[13]提出一種稱(chēng)為主變遷序列(Principal Transition Sequence,PTS)算法的流程行為相似性度量方法,該方法給出了主變遷序列的概念,通過(guò)3種不同的主變遷序列表示3種不同的邏輯結(jié)構(gòu)。使用這3種主變遷序列來(lái)表示流程模型的行為,2個(gè)序列的相似度為這2個(gè)序列的最長(zhǎng)公共子序列長(zhǎng)度和這2個(gè)序列中最長(zhǎng)序列長(zhǎng)度的比值,最后將不同類(lèi)型的序列相似度加權(quán)求和所得值作為流程的相似度。但是該方法不能有效處理循環(huán)結(jié)構(gòu),同時(shí)也破壞了流程模型的語(yǔ)義完整性。文獻(xiàn)[14]在PTS算法的基礎(chǔ)上提出了PTS++算法,通過(guò)定義完整觸發(fā)序列表示流程行為,基于A*算法結(jié)合剪枝策略實(shí)現(xiàn)觸發(fā)序列集合間的映射,進(jìn)而完成流程行為相似度的計(jì)算。
文獻(xiàn)[15]提出一種稱(chēng)為因果足跡(Causal Footprint,CF)算法的流程行為相似度計(jì)算方法。該方法使用模型中的活動(dòng)、路由、前向連接鏈、后向連接鏈等將流程模型表示為一個(gè)向量,并利用2個(gè)向量間的夾角余弦值表示2個(gè)流程間的相似度。但該方法無(wú)法有效區(qū)分AND、XOR等路由結(jié)構(gòu),且計(jì)算效率較低。
本文首先介紹有關(guān)事件日志的基本概念,給出從事件日志的執(zhí)行案例軌跡中構(gòu)造鄰接矩陣的方法;然后借鑒矩陣論中矩陣范數(shù)的概念定義流程間距離,證明所定義的流程間距離滿(mǎn)足距離度量的2個(gè)特性;最后將文獻(xiàn)[2]中使用的業(yè)務(wù)流程實(shí)例模型利用事件日志產(chǎn)生工具(Process Log Generator,PLG)[16]生成人工事件日志,通過(guò)對(duì)比實(shí)驗(yàn)證明本文所提方法的有效區(qū)分性,同時(shí)利用真實(shí)事件日志數(shù)據(jù)集對(duì)其時(shí)間性能進(jìn)行分析。
2 事件日志
目前事件日志的數(shù)據(jù)源多種多樣,如數(shù)據(jù)庫(kù)、文本文件、消息日志、事務(wù)日志等。這些保存下來(lái)的事件日志信息為科學(xué)研究和企業(yè)生產(chǎn)實(shí)踐提供了大量的數(shù)據(jù)來(lái)源。從信息系統(tǒng)的角度來(lái)看,事件日志反映了業(yè)務(wù)流程在實(shí)際運(yùn)行中的真實(shí)執(zhí)行情況。事件日志具有時(shí)間戳、成本、資源和活動(dòng)等相關(guān)信息。
表1是一個(gè)關(guān)于網(wǎng)上購(gòu)物的索賠申請(qǐng)?zhí)幚磉^(guò)程,每個(gè)索賠申請(qǐng)對(duì)應(yīng)于一個(gè)案例。事件可能與某些活動(dòng)有關(guān),其中活動(dòng)指register request、check ticket、reject等。由表1可以看出:1)案例是由事件組成的,且每個(gè)事件僅屬于一個(gè)案例;2)案例中的事件是有序的;3)事件具有屬性,典型的屬性包括活動(dòng)、時(shí)間戳、成本和資源等。
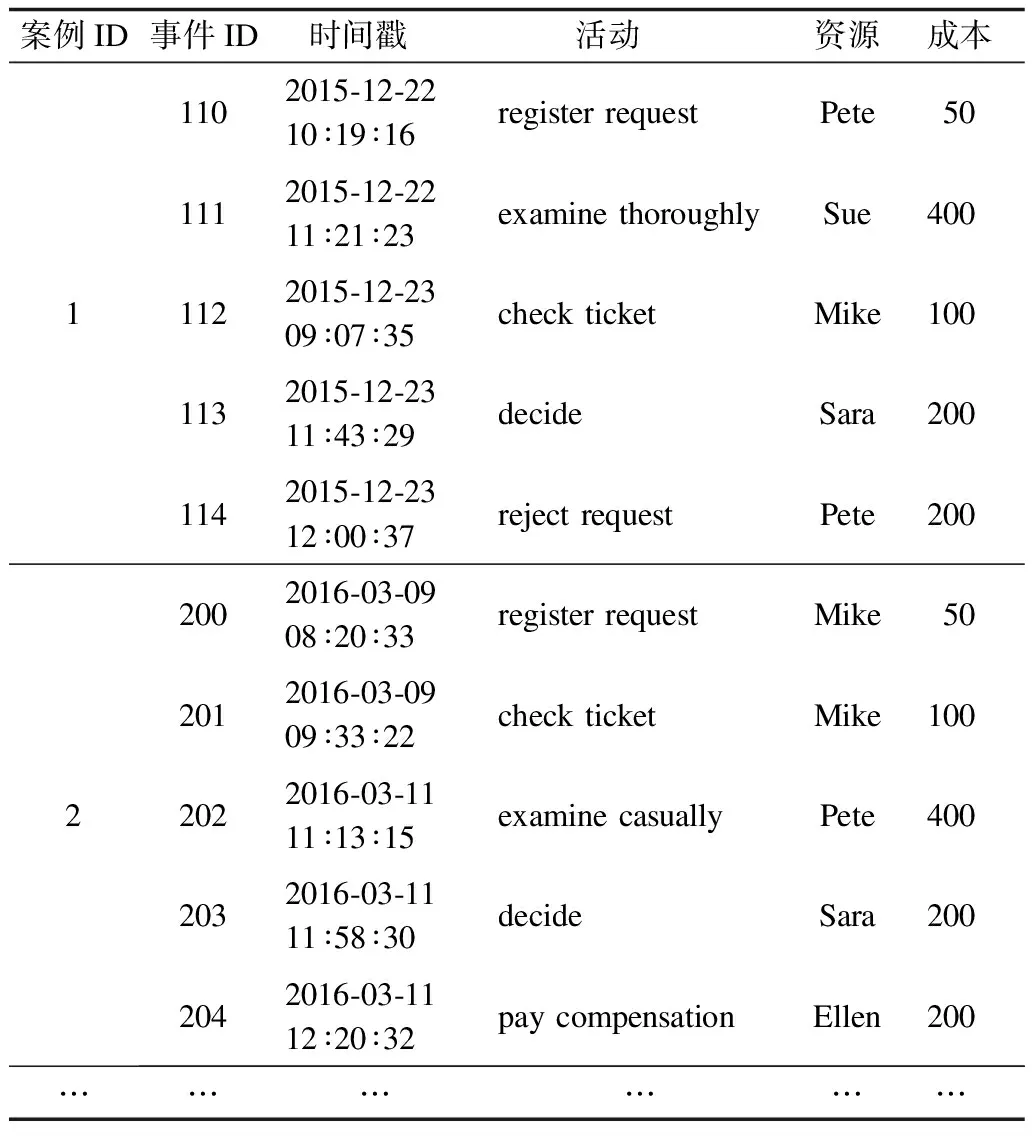
表1 網(wǎng)上購(gòu)物索賠申請(qǐng)?zhí)幚磉^(guò)程
定義1(事件、屬性) 設(shè)E為事件空間,即所有可能的事件標(biāo)識(shí)的集合。事件可以由不同的屬性來(lái)表示。設(shè)AN為屬性名的集合。對(duì)于任意的事件e∈E和屬性名n∈AN,#n(e)是事件e的屬性n的值。
例:表1中一個(gè)事件(事件ID為110)有一個(gè)與活動(dòng)#activity(e)=(register request)相對(duì)應(yīng)的時(shí)間戳#time(e)=(2015-12-22 10∶19∶16),被一個(gè)特定的人#person(e)=(Pete)所執(zhí)行,有相關(guān)的成本#cost(e)=(50)等。
定義2(分類(lèi)器) 對(duì)任意的事件e∈E,e是事件的名稱(chēng),將e稱(chēng)為事件的分類(lèi)器。
定義3(軌跡) 軌跡t是事件e的一個(gè)有限序列。
定義4(案例) 設(shè)C為案例空間,即所有可能的案例標(biāo)識(shí)符的集合。每一個(gè)案例都有一個(gè)強(qiáng)制性的屬性——軌跡。
例:表1中案例1的軌跡為{110,111,112,113,114},案例2的軌跡為{200,201,202,203,204}。
如果使用事件的活動(dòng)名稱(chēng)來(lái)表示事件,那么e=#activity(e)。
定義5(事件日志) 事件日志是案例的集合。
例:表1表示的事件日志為{案例1,案例2,…}。
定義6(簡(jiǎn)單軌跡) 簡(jiǎn)單軌跡t被定義為活動(dòng)的有限序列。
例:表1中案例1對(duì)應(yīng)的簡(jiǎn)單軌跡t1為{register request,examine thoroughly,check ticket,decide,reject request}。
定義7(簡(jiǎn)單事件日志) 令A(yù)為活動(dòng)名稱(chēng)的集合。簡(jiǎn)單軌跡t被定義為一個(gè)活動(dòng)的序列,即t∈A*。簡(jiǎn)單事件日志L被定義為A上軌跡的一個(gè)多集。
例:表1對(duì)應(yīng)的簡(jiǎn)單事件日志為L(zhǎng)={register request,examine thoroughly,check ticket,decide,reject request},{register request,check ticket,examine casually,decide,pay compensation},…},其中一個(gè)簡(jiǎn)單軌跡t={register request,examine thoroughly,check ticket,decide,reject request}。
定義8(從事件日志提取簡(jiǎn)單事件日志) 設(shè)L是定義5中定義的事件日志,假設(shè)存在一個(gè)分類(lèi)器,e是事件的名稱(chēng),則使用這個(gè)分類(lèi)器可以將L中的案例序列轉(zhuǎn)換成活動(dòng)名稱(chēng)序列。
事件日志的來(lái)源和格式多種多樣,有關(guān)事件日志的更多知識(shí)可以參考文獻(xiàn)[17]。
3 鄰接矩陣構(gòu)造
事件日志中保存著業(yè)務(wù)流程運(yùn)行過(guò)程產(chǎn)生的豐富信息,反映流程的特征。然而,在業(yè)務(wù)流程的實(shí)際運(yùn)行過(guò)程中可能會(huì)出現(xiàn)流程執(zhí)行異常或日志記錄錯(cuò)誤的情況,日志數(shù)據(jù)中往往存在一些噪聲,因此,如何對(duì)保存在事件日志中的信息進(jìn)行有效的提取與分析是本文需要解決的關(guān)鍵問(wèn)題之一。現(xiàn)有研究已經(jīng)證實(shí)噪聲的特點(diǎn)是發(fā)生概率低。因此,本文利用噪聲的這一特點(diǎn)首先對(duì)事件日志進(jìn)行預(yù)處理,刪除發(fā)生率小于給定閾值的案例軌跡,然后再進(jìn)行鄰接矩陣的構(gòu)造。以文獻(xiàn)[1]中使用的2個(gè)簡(jiǎn)單事件日志為例,詳細(xì)介紹緊鄰活動(dòng)關(guān)系和活動(dòng)鄰接矩陣的構(gòu)造。
表2所示的簡(jiǎn)單事件日志中共有5個(gè)不同的活動(dòng)、6個(gè)案例軌跡,例如有2個(gè)案例的簡(jiǎn)單軌跡為

表2 簡(jiǎn)單事件日志數(shù)據(jù)表L1

表3 簡(jiǎn)單事件日志數(shù)據(jù)表L2
3.1 預(yù)處理
由于事件日志中可能存在噪聲,因此在構(gòu)造鄰接矩陣之前需要對(duì)簡(jiǎn)單事件日志進(jìn)行預(yù)處理,即刪除案例軌跡的發(fā)生率小于給定閾值的軌跡,從而降低噪聲對(duì)計(jì)算結(jié)果的影響。事件日志的預(yù)處理包括以下2個(gè)部分:1)求出2個(gè)事件日志中相同活動(dòng)的比例;2)求出事件日志中每條軌跡所占的比率。
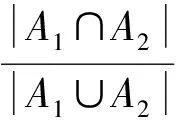
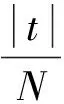
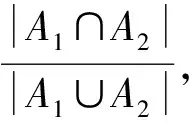
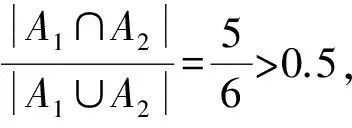

表4 預(yù)處理后的簡(jiǎn)單事件日志數(shù)據(jù)表L2
3.2 鄰接矩陣構(gòu)造過(guò)程
鄰接矩陣構(gòu)造是根據(jù)事件日志中的活動(dòng)緊鄰關(guān)系進(jìn)行的。因此,在介紹鄰接矩陣構(gòu)造之前,首先給出緊鄰活動(dòng)與鄰接矩陣的定義。
定義11(緊鄰活動(dòng)) 設(shè)L為簡(jiǎn)單事件日志,A為活動(dòng)集合,活動(dòng)a,b∈A,a、b是緊鄰活動(dòng)當(dāng)且僅當(dāng)簡(jiǎn)單事件日志L中存在有簡(jiǎn)單軌跡t=t1,t2,…,tn,使得ti=a,ti+1=b,其中i∈{1,2,…,n-1}。
例:表2所示的案例1中緊鄰活動(dòng)關(guān)系有a1a2、a2a3、a3a4。
定義12(鄰接矩陣) 以緊鄰活動(dòng)在事件日志的所有簡(jiǎn)單軌跡中出現(xiàn)次數(shù)的總和作為元素的矩陣稱(chēng)為鄰接矩陣(Adjacent Matrix,AM)。
對(duì)于任意給定的事件日志,可以按照如下方法為其構(gòu)造鄰接矩陣:對(duì)于一個(gè)包含有N個(gè)不同活動(dòng)的事件日志,首先初始化一個(gè)N×N的方陣,其中,N表示事件日志中不同類(lèi)型活動(dòng)的數(shù)量,例如表2所示的事件日志中共包含有5個(gè)不同的活動(dòng)a1、a2、a3、a4、a5,因此,表2所示的事件日志對(duì)應(yīng)于一個(gè)5×5的鄰接矩陣。對(duì)于事件日志中的任意2個(gè)活動(dòng)ai和aj,依次遍歷事件日志中的每條軌跡,求出活動(dòng)ai和aj在簡(jiǎn)單事件日志中所有簡(jiǎn)單軌跡中緊鄰出現(xiàn)的總次數(shù),假設(shè)為n,,那么在鄰接矩陣中AM(i,j)所對(duì)應(yīng)的位置填入n,即AM(i,j)=n,如果活動(dòng)ai和aj沒(méi)有作為緊鄰活動(dòng)在簡(jiǎn)單事件日志中出現(xiàn)過(guò),則鄰接矩陣的相應(yīng)位置填入0。為了表示簡(jiǎn)單,本文對(duì)于鄰接矩陣中0元素的所在位置留有空白表示。
將表2和表4中的事件日志進(jìn)行鄰接矩陣的構(gòu)造,所求出的鄰接矩陣如圖1和圖2所示。
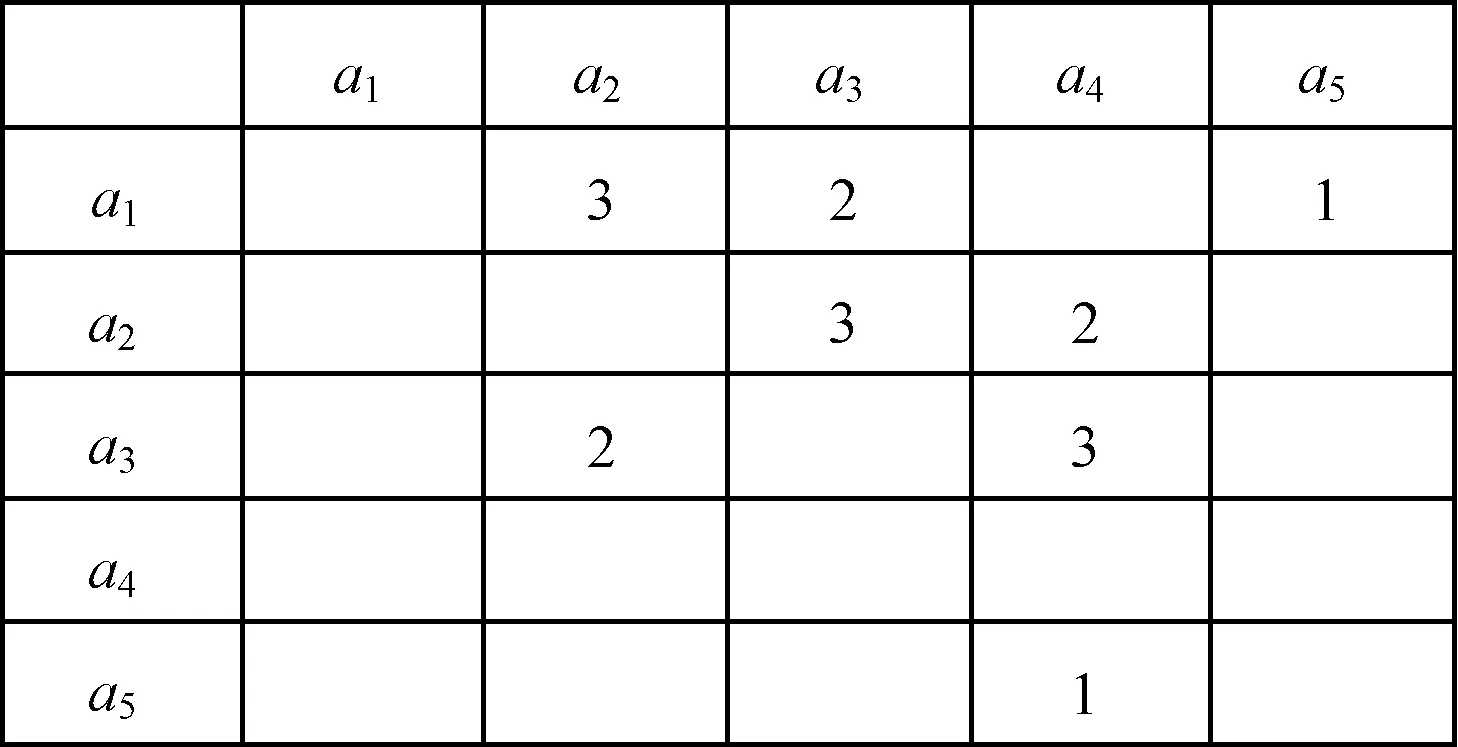
圖1 L1預(yù)處理后所對(duì)應(yīng)的鄰接矩陣
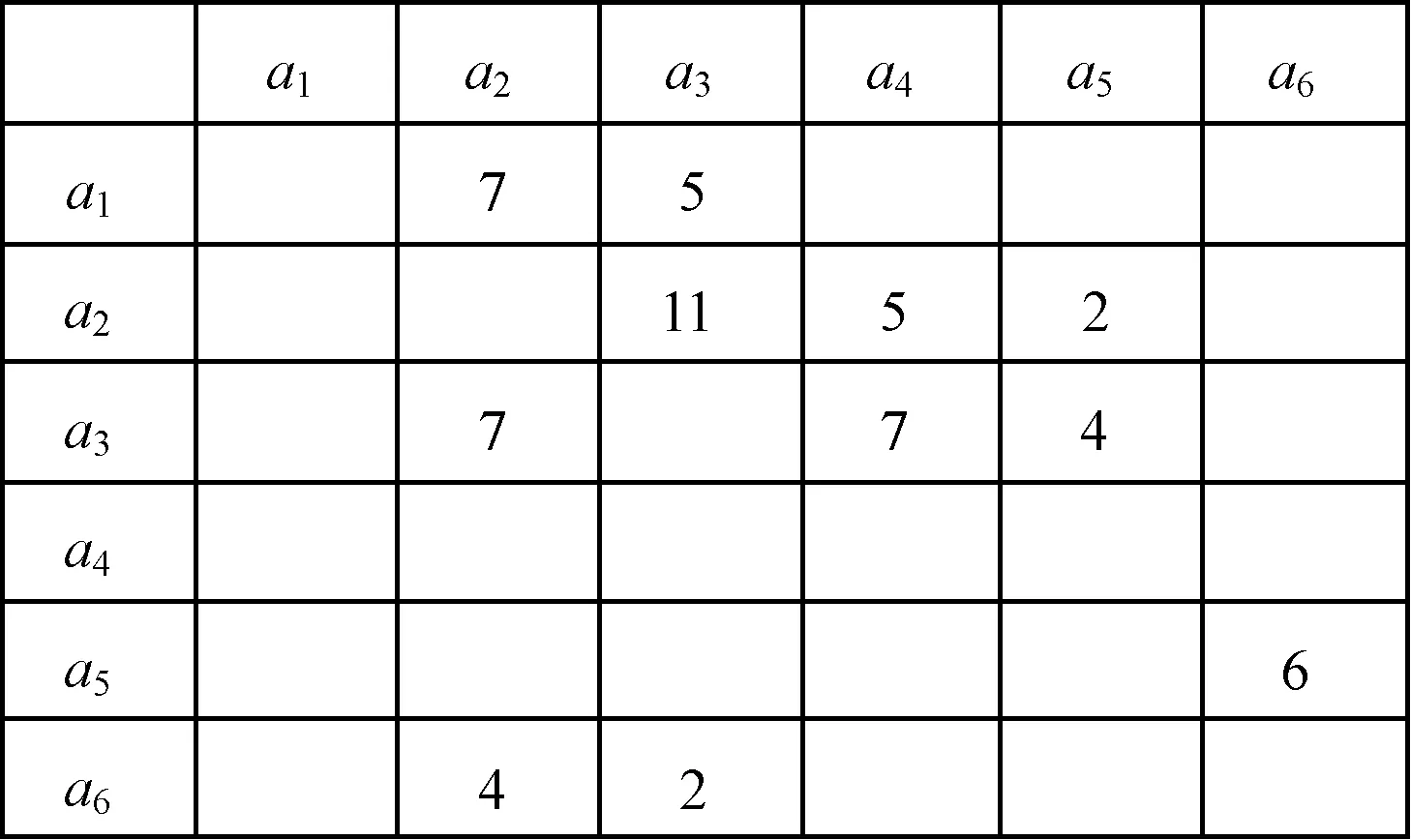
圖2 L2預(yù)處理后所對(duì)應(yīng)的鄰接矩陣
定義13(概率鄰接矩陣) 由鄰接矩陣中的每個(gè)元素除以事件日志中案例軌跡的總數(shù)所得到的矩陣,稱(chēng)為概率鄰接矩陣。
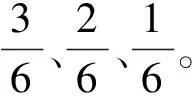
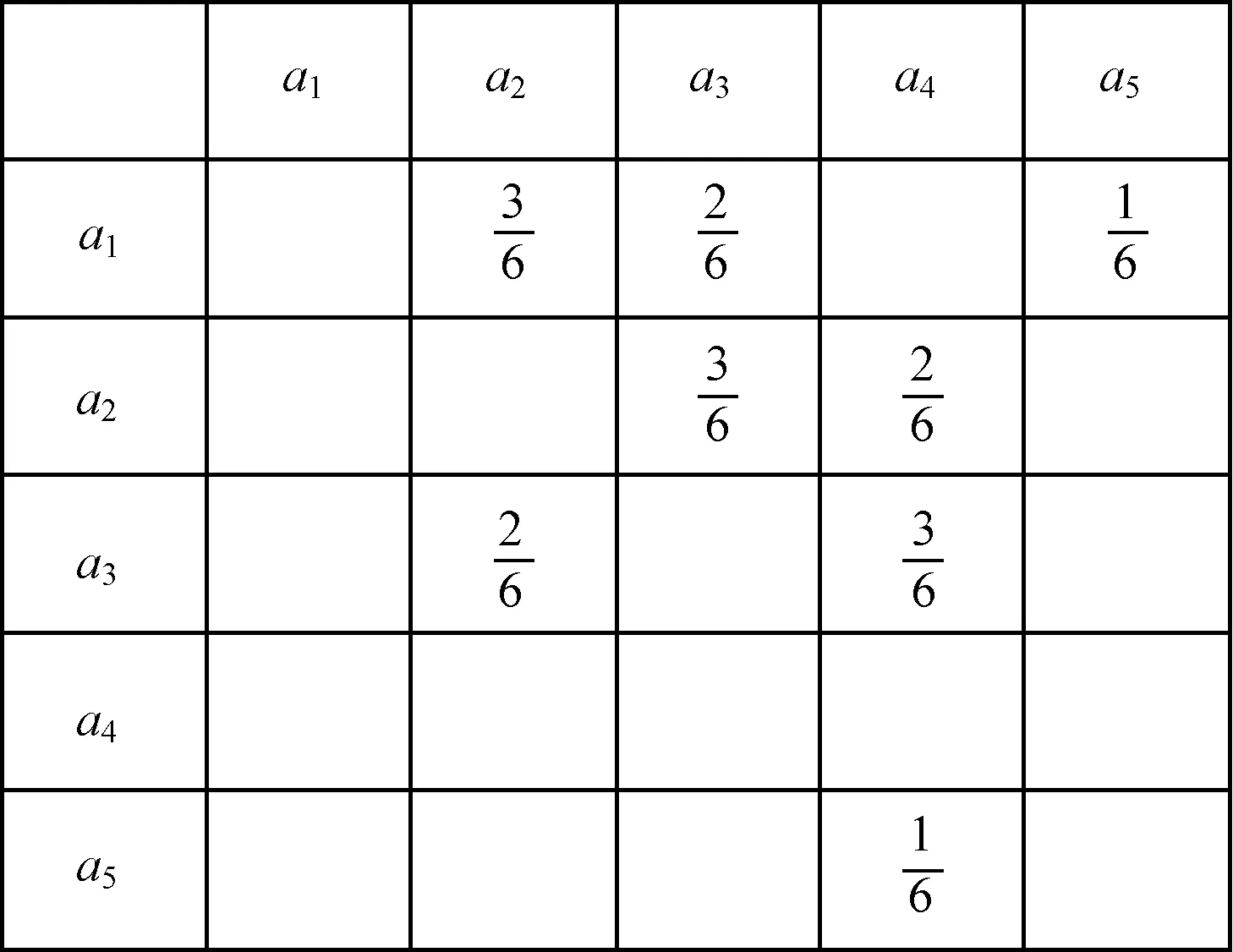
圖3 L1預(yù)處理后所對(duì)應(yīng)的概率鄰接矩陣
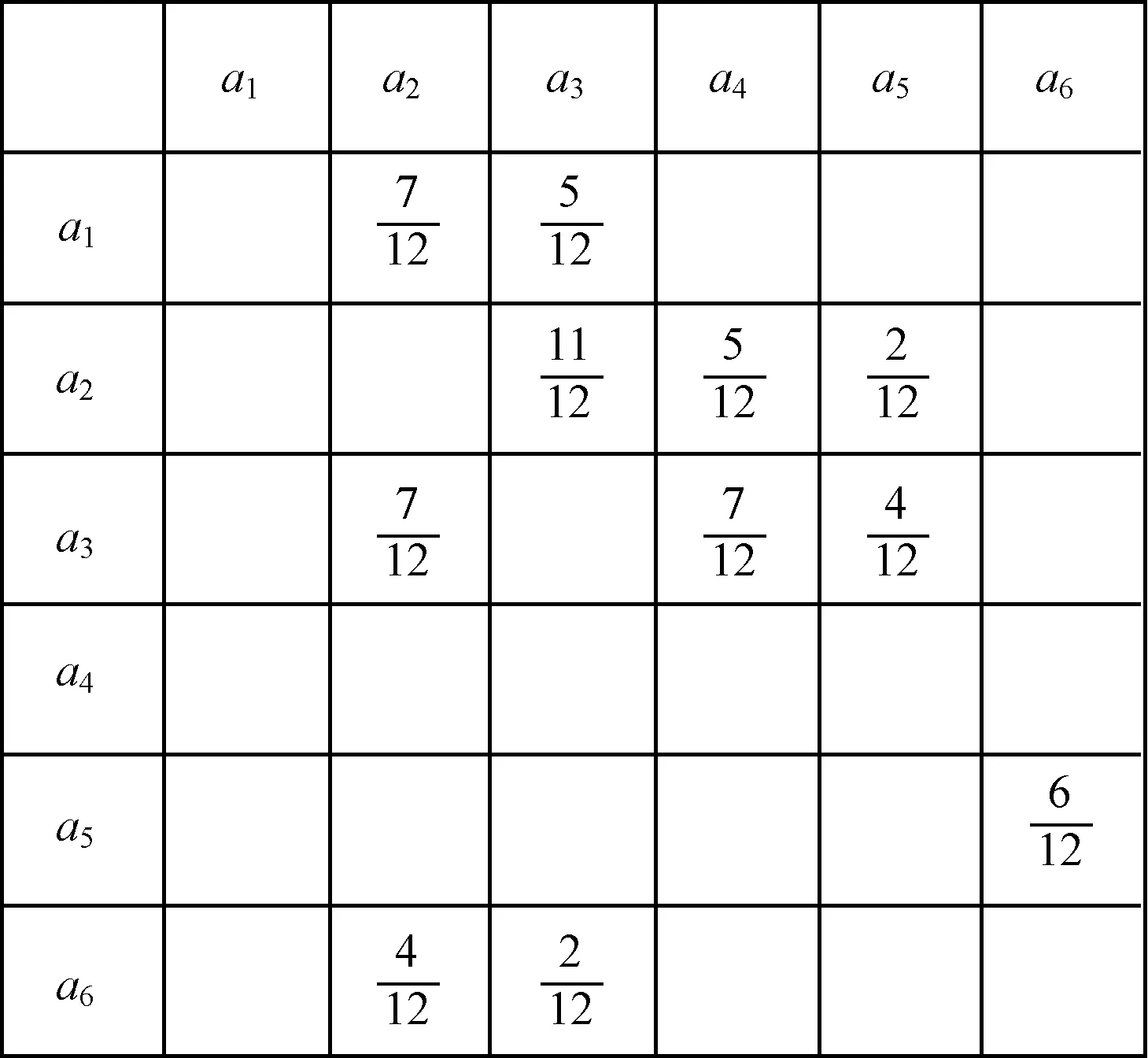
圖4 L2預(yù)處理后所對(duì)應(yīng)的概率鄰接矩陣
4 流程間距離計(jì)算
流程間距離的計(jì)算分為定性分析和定量計(jì)算,所謂定性分析就是對(duì)2個(gè)事件日志中的活動(dòng)集合求取相同活動(dòng)率,若所求的相同活動(dòng)率較小,則說(shuō)明所對(duì)應(yīng)的流程間距離較大;若所求的相同活動(dòng)率較大,則說(shuō)明所對(duì)應(yīng)的流程間距離較小。所謂流程間距離的定量計(jì)算就是指利用一種數(shù)值化的方法來(lái)度量流程間距離的具體大小。
定義14(同維概率鄰接矩陣) 設(shè)L1和L2為2個(gè)事件日志,A1和A2為對(duì)應(yīng)事件日志L1和L2的活動(dòng)集合,AM1和AM2為事件日志L1和L2所對(duì)應(yīng)的概率鄰接矩陣,NAM1和NAM2表示同維概率鄰接矩陣,其維數(shù)m=|A1∪A2|,假設(shè)A1∪A2={a1,a2,…,am},則NAM1(i,j)和NAM2(i,j)可以進(jìn)行如下的定義:
根據(jù)定義14所給的同維概率鄰接矩陣的定義,可以給出表2和表4所示的事件日志L1和L2所對(duì)應(yīng)的同維概率鄰接矩陣,分別如圖5和圖4所示(簡(jiǎn)單事件日志L2的同維概率鄰接矩陣同圖4)。
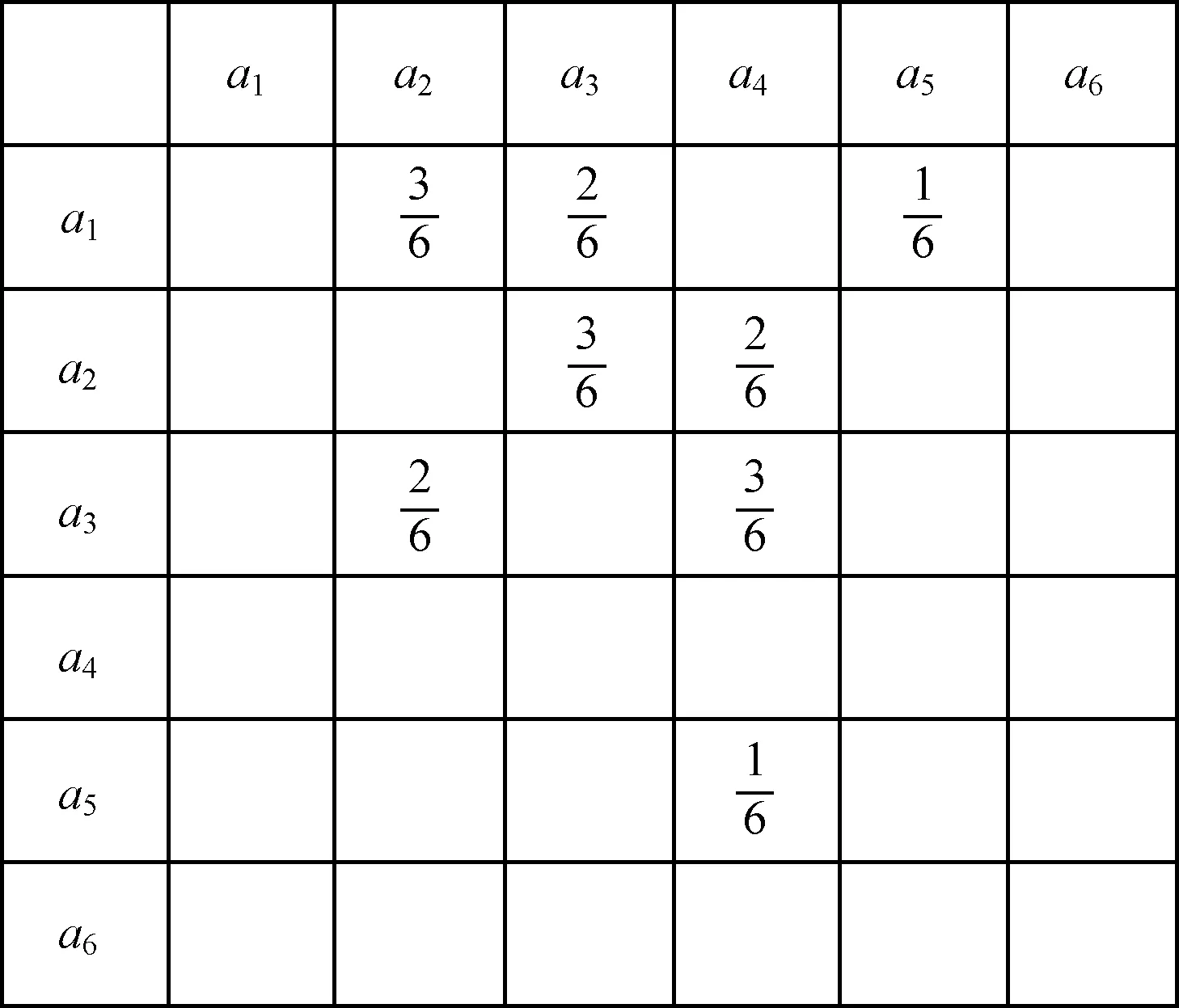
圖5 簡(jiǎn)單事件日志L1的同維概率鄰接矩陣
在矩陣論中,矩陣間距離的度量可以使用矩陣范數(shù)進(jìn)行表示,因此,本文給出流程間距離的定義。
定義15(流程間距離) 設(shè)Li、Lj為任意2個(gè)事件日志,NAMi、NAMj為其對(duì)應(yīng)的同維概率鄰接矩陣,事件日志Li、Lj所對(duì)應(yīng)的流程間距離D(Li,Lj)定義如下:
D(Li,Lj)=tr[(NAMi-NAMj)×(NAMi-NAMj)T]
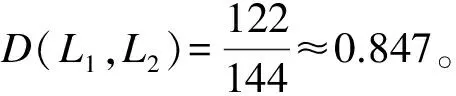
定理1任意給定3個(gè)簡(jiǎn)單事件日志L1、L2和L3,流程間距離D滿(mǎn)足以下性質(zhì):
1)非負(fù)性:D(L1,L2)≥0,當(dāng)且僅當(dāng)L1=L2成立時(shí),有D(L1,L2)=0。
2)對(duì)稱(chēng)性:D(L1,L2)=D(L2,L1)。
3)三角不等式:D(L1,L2)≤D(L1,L3)+D(L3,L2)。
證明:
1)由流程間距離的定義可知D(L1,L2)≥0,若D(L1,L2)=0,則說(shuō)明NAM1-NAM2是零矩陣,從而得NAM1=NAM2,即L1=L2,反之亦然。
2)由事件日志L1和L2的流程間距離的定義可得:
D(L1,L2)=
tr[(NAM1-NAM2)×(NAM1-NAM2)T]=
tr[(NAM2-NAM1)×(NAM2-NAM1)T]=
D(L2,L1)
3)由事件日志L1和L2的流程間距離的定義可得:
D(L1,L2)=
tr[(NAM1-NAM2)×(NAM1-NAM2)T]=
NAM3(i,j)-NAM2(i,j)}2≤
tr[(NAM1-NAM3)×(NAM1-NAM3)T]+
tr[(NAM3-NAM2)×(NAM3-NAM2)T]=
D(L1,L3)+D(L3,L2)
證畢。
5 驗(yàn)證實(shí)驗(yàn)
本節(jié)首先使用人工生成的事件日志進(jìn)行對(duì)比實(shí)驗(yàn),對(duì)本文方法進(jìn)行可行性驗(yàn)證,然后,利用真實(shí)事件日志數(shù)據(jù)集對(duì)本文方法的執(zhí)行效率進(jìn)行實(shí)驗(yàn)分析。本文實(shí)驗(yàn)環(huán)境為:Inter(R) Core(TM)i5-6420P CPU @2.80 GHz 8 GB內(nèi)存。實(shí)驗(yàn)程序使用Java語(yǔ)言編寫(xiě),JDK版本為1.7.0,運(yùn)行在64位Windows7系統(tǒng)上。
5.1 實(shí)例驗(yàn)證
首先使用事件日志產(chǎn)生工具(PLG)進(jìn)行人工事件日志的生成。本文使用文獻(xiàn)[2]所給的4個(gè)流程模型進(jìn)行人工事件日志的生成,所用流程模型如圖6所示。
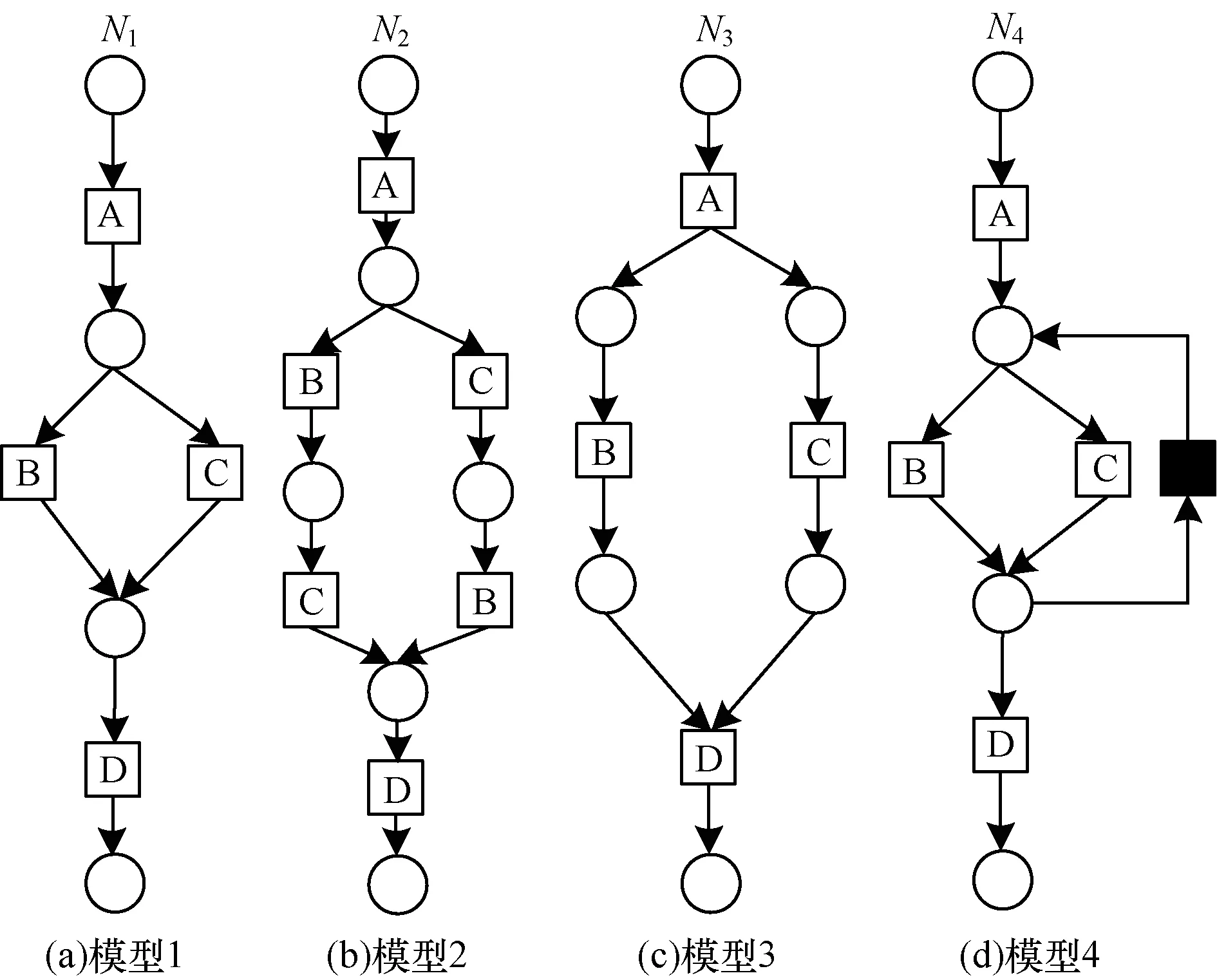
圖6 流程模型實(shí)例
使用PLG分別執(zhí)行圖1所示的4個(gè)業(yè)務(wù)流程模型,每個(gè)業(yè)務(wù)流程模型執(zhí)行50次,即使得生成的4個(gè)人工事件日志為分別包含50條案例軌跡的簡(jiǎn)單事件日志,所生成的4個(gè)事件日志分別為:{
本文所構(gòu)造的鄰接矩陣和文獻(xiàn)[2]使用的TAR集合都是通過(guò)活動(dòng)鄰接關(guān)系構(gòu)造的,但是TAR算法僅考慮了變遷之間的緊鄰關(guān)系,屬于流程模型的局部行為特征,因而不能有效地識(shí)別出非自主選擇結(jié)構(gòu),同時(shí)也無(wú)法區(qū)分流程模型中存在的循環(huán)結(jié)構(gòu)和順序結(jié)構(gòu)。且TAR算法僅考慮了流程模型本身所蘊(yùn)含的信息,而忽視了保存在信息系統(tǒng)中事件日志的有效應(yīng)用。因此,將本文方法與TAR方法進(jìn)行比較,從而證明本文方法能夠更好地區(qū)分選擇結(jié)構(gòu)和并行結(jié)構(gòu),同時(shí)可以發(fā)現(xiàn)不可見(jiàn)任務(wù)。
由圖7可知,流程模型N2和N3的距離為0,則說(shuō)明流程模型N2和N3應(yīng)該相同,但筆者發(fā)現(xiàn)模型N2為選擇分支結(jié)構(gòu),流程模型N3為并行分支結(jié)構(gòu),這兩個(gè)流程模型并不相同,但是它們的執(zhí)行軌跡相同,形成的TAR集合也相同。因此,說(shuō)明TAR不能有效地區(qū)分選擇分支結(jié)構(gòu)和并行分支結(jié)構(gòu)。
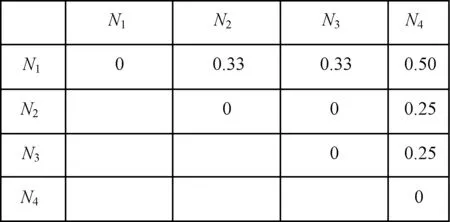
圖7 基于TAR算法的流程間距離
由圖8可知,流程模型N2和N3的距離為0.06,則說(shuō)明流程模型N2和N3是不相同的,這說(shuō)明即使2個(gè)流程模型的執(zhí)行軌跡相同,但其對(duì)應(yīng)的流程模型仍有可能是不同的。因此,基于鄰接矩陣的流程間距離計(jì)算方法可以有效地區(qū)分選擇分支結(jié)構(gòu)和并行分支結(jié)構(gòu)。同時(shí),筆者發(fā)現(xiàn)流程N(yùn)1和N4的距離只有0.04,相較TAR算法求出的0.5小很多,這是因?yàn)椴豢梢?jiàn)任務(wù)在真實(shí)的執(zhí)行過(guò)程中出現(xiàn)的次數(shù)較少,因此,可以在預(yù)處理階段設(shè)置一個(gè)較大的閾值將其過(guò)濾掉。如果軌跡發(fā)生率的閾值設(shè)置的大一點(diǎn),則N1和N4的距離為0,會(huì)把不可見(jiàn)任務(wù)當(dāng)成噪聲去掉。
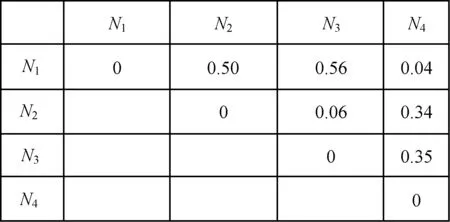
圖8 基于鄰接矩陣的流程間距離
5.2 效率分析
影響本文方法執(zhí)行效率的2個(gè)關(guān)鍵因素分別是事件日志中每條案例軌跡的長(zhǎng)度以及事件日志中案例軌跡的個(gè)數(shù)。因此,本節(jié)分別從這2個(gè)因素對(duì)流程間距離計(jì)算所花時(shí)間進(jìn)行驗(yàn)證。本節(jié)實(shí)驗(yàn)所使用的數(shù)據(jù)來(lái)自https://data.4tu.nl保存的真實(shí)數(shù)據(jù)集,從中選擇了4類(lèi)事件日志數(shù)據(jù),分別是:Hospital Log,Sepsis Cases,Road Traffic和BPIC 2012。所挑選的事件日志具體細(xì)節(jié)如表5所示。
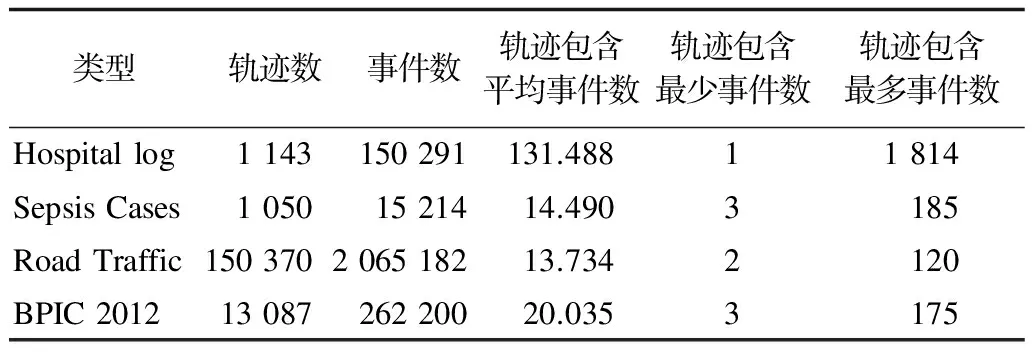
表5 事件日志數(shù)據(jù)集
從所選的4個(gè)事件日志中,分別將每個(gè)事件日志形成新的4類(lèi)事件日志,形成的事件日志中的案例軌跡數(shù)分別為5、10、15和20。每類(lèi)中的軌跡長(zhǎng)度從5增加到20。筆者觀察在軌跡數(shù)一定的情況下,隨著軌跡長(zhǎng)度的增加,計(jì)算所花時(shí)間的變化情況。
圖9中的每條曲線表示,在軌跡數(shù)一定的情況下,隨著軌跡長(zhǎng)度的增加,計(jì)算所花的時(shí)間也隨之增加。增加的幅度和事件日志的案例軌跡數(shù)有關(guān),事件日志的案例軌跡數(shù)越大,增加的幅度也越大。例如當(dāng)軌跡數(shù)為20時(shí),隨著軌跡長(zhǎng)度從5增加到20,計(jì)算所花時(shí)間由92.1 ms增加到了780.4 ms,增加的幅度分別為200.4%、201.4%和209.8%。在圖9所示的不同曲線之間,筆者發(fā)現(xiàn)在軌跡長(zhǎng)度一定的情況下,事件日志中的案例軌跡數(shù)越大,計(jì)算所需的時(shí)間也就越多。
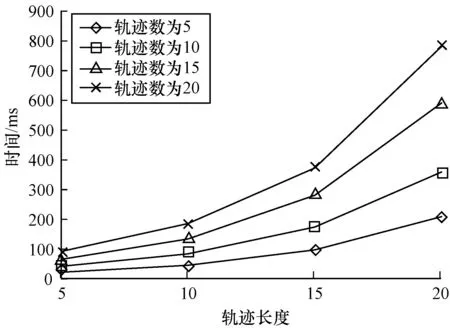
圖9 實(shí)驗(yàn)結(jié)果
6 結(jié)束語(yǔ)
現(xiàn)有的流程間距離計(jì)算方法大多從流程模型本身入手,而忽略了流程模型實(shí)際執(zhí)行產(chǎn)生的事件日志。本文依據(jù)流程模型實(shí)際執(zhí)行產(chǎn)生的事件日志來(lái)計(jì)算流程間距離,通過(guò)挖掘流程執(zhí)行產(chǎn)生的案例軌跡中包含的活動(dòng)緊鄰關(guān)系構(gòu)造活動(dòng)鄰接矩陣,同時(shí)使用矩陣論中矩陣范數(shù)的定義表示矩陣間的距離,利用所求得的矩陣間距離來(lái)定義流程間距離,并證明所定義的流程間距離滿(mǎn)足距離度量的性質(zhì)。實(shí)驗(yàn)結(jié)果表明,本文算法具有有效區(qū)分性,并且計(jì)算效率較高。下一步將提升鄰接矩陣構(gòu)造算法的效率,并設(shè)計(jì)更合理的預(yù)處理參數(shù)閾值。
[1] AALST W M P V D,SCHONENBERG M H,SONG M.Time prediction based on process mining[J].Information Systems,2011,36(2):450-475.
[2] ZHA H,WANG J,WEN L,et al.A workflow net similarity measure based on transition adjacency relations[J].Computers in Industry,2010,61(5):463-471.
[3] AKKIRAJU R,IVAN A.Discovering business process similarities:an empirical study with SAP best practice business processes[C]//Proceedings of ICSOC’10.San Francisco,USA:[s.n.],2010:515-526.
[4] YAN Z,DIJKMAN R,GREFEN P.Fast business process similarity search with feature-based similarity estima-tion[C]//Proceedings of OTM’10.Berlin,Germany:Springer,2010:60-77.
[5] 宋有美,李建波,和天玥,等.基于節(jié)點(diǎn)相似性的容遲網(wǎng)絡(luò)概率路由算法[J].計(jì)算機(jī)工程,2016,42(9):63-70.
[6] DIJKMAN R,DUMAS M.Graph matching algorithms for business process model similarity search[C]//Proceedings of BPM’09.Berlin,Germany:Springer,2009:835-842.
[7] KUNZE M,WESKE M.M.Metric trees for efficient similarity search in large process model repositories[C]//Proceedings of BPM’10.Berlin,Germany:Springer,2010:535-546.
[8] POMELLO L,ROZENBERG G,SIMONE C.A survey of equivalence notions for net based systems[M]//ROZENBERG G.Advances in Petri Nets.Berlin,Germany:Springer,1992:410-472.
[9] GLABBEEK R J V,WEIJLAND W P.Branching time and abstraction in bisimulation semantics(extended abstract)[J].Journal of the ACM,1991,43(3):555-600.
[10] 殷 明,聞立杰,王建民,等.基于變遷緊鄰關(guān)系重要性的流程相似性算法[J].計(jì)算機(jī)集成制造系統(tǒng),2015,21(2):344-358.
[11] WEIDLICH M,MENDLING J,WESKE M.Efficient consistency measurement based on behavioural profiles of process models[J].IEEE Transactions on Software Engineering,2011,37(3):410-429.
[12] WEIDLICH M,POLYVYANYY A,MENDLING J,et al.Efficient computation of causal behavioural profiles using structural decomposition[M]//LILIUS J,PENCZEK W.Applications and Theory of Petri Nets.Berlin,Germany:Springer,2010:77-685.
[13] WANG J,HE T,WEN L,et al.A behavioral similarity measure between labeled petri nets based on principal transition sequences[C]//Proceedings of OTM’10.Berlin,Germany:Springer,2010:394-401.
[14] 董子禾,聞立杰,黃浩未,等.基于觸發(fā)序列集合的過(guò)程模型行為相似性算法[J].軟件學(xué)報(bào),2015,26(3):449-459.
[15] DIJKMAN R,DUMAS M,DONGEN B V,et al.Similarity of business process models:metrics and evaluation[J].Information Systems,2011,36(2):498-516.
[16] BURATTIN A,SPERDUTI A.PLG:a framework for the generation of business process models and their execution logs[C]//Proceedings of BPM’10.Berlin,Germany:Springer,2011:214-219.
[17] WIL V D A.Process mining:data science in action[M].Berlin,Germany:Springer,2016.
猜你喜歡
少先隊(duì)活動(dòng)(2022年5期)2022-06-06 03:45:04
家庭科學(xué)·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
少先隊(duì)活動(dòng)(2021年2期)2021-03-29 05:40:48
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2019年6期)2019-06-24 03:37:50
海峽姐妹(2018年3期)2018-05-09 08:20:40
中國(guó)公路(2017年7期)2017-07-24 13:56:38
山東青年(2016年1期)2016-02-28 14:25:25
中國(guó)衛(wèi)生(2015年4期)2015-11-08 11:16:06
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
