基于改進貝葉斯算法的文件監(jiān)控系統研究?
2018-04-27 03:33:53周亮
艦船電子工程 2018年4期
周 亮
(中移鐵通湖南分公司云數據支撐中心 長沙 412006)
1 引言
隨著國際互聯網絡的發(fā)展,計算機聯網數量在飛速增加,黑客、病毒和木馬已經呈現出爆發(fā)式增長模式[1],安全攻擊呈現出新特點,網絡的安全性越來越受到重視[2~4]。由于計算機系統和信息網絡系統本身固有的脆弱性[5],越來越多的網絡安全問題開始困擾著我們,黑客入侵和病毒蔓延的趨勢有增無減,社會、企業(yè)和個人也因此蒙受了越來越大的損失。傳統的安全保護類技術已經無法滿足當前的需求。網絡安全主動防御系統[6]是一種更深層次上進行的主動網絡安全防御措施,它不僅可以通過監(jiān)測網絡實現對內部攻擊、外部入侵和誤操作的實時保護,有效彌補防火墻的不足,而且能夠結合其他網絡安全產品,對網絡安全進行主動、實時的全方位保護。主動防御[7]是一種前攝性防御,由于一些防御措施的實施,使攻擊者無法完成對目標的攻擊,或者使系統能夠在無需人為被動響應的情況下預防安全事件。主動防御將使網絡安全防護進入一個全新的階段,也被認為是未來網絡安全防護技術的發(fā)展方向。而主動防御的核心模塊就是文件監(jiān)控[8],通過文件監(jiān)控實時的監(jiān)控系統可疑文件的操作,能夠做到對病毒的防御。
針對上述問題,本文將介紹一種基于改進貝葉斯算法的文件監(jiān)控系統。該系統實時監(jiān)控所有的文件操作,并將可疑的文件行為進行分析評判。通過對傳統的貝葉斯算法進行改進,提出一種基于加權的貝葉斯算法,在一定程度上彌補了傳統貝葉斯算法在假設各特征向量無關聯的偏差,提高了評判的準確性。
2 文件監(jiān)控整體邏輯
本文提出的文件監(jiān)控系統通過在驅動級捕捉文件的IO操作,并根據這個IO操作來判斷這些文件的危險性。文件監(jiān)控整體邏輯如圖1所示,文件監(jiān)控主要由驅動檢測模塊、行為分析模塊以及查殺模塊組成。驅動檢測模塊工作在驅動層,實時監(jiān)控整個驅動層,并且捕捉文件的IO操作,經過過濾后把進入系統的可疑文件的行為信息以特征向量的形式上傳到行為分析模塊。行為分析模塊工作在應用層,行為分析模塊接收到驅動傳遞上來的行為特征向量之后,首先會與行為特征庫進行比對,比對成功,把病毒信息返回給驅動;比對不成功則調用行為分析算法進行進一步分析,若判定為病毒,則把結果返回給驅動模塊。驅動模塊拿到分析的結果后,調用查殺模塊對病毒文件進行隔離處理,本文側重于介紹文件監(jiān)控,對查殺模塊不做介紹。
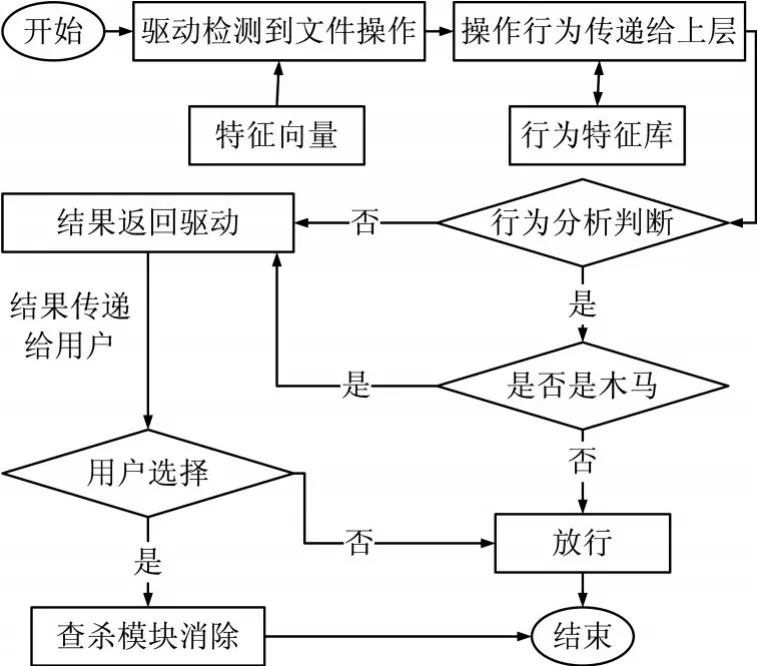
圖1 文件監(jiān)控整體流程
3 驅動檢測模塊
3.1 驅動檢測模塊闡述
病毒作為一種程序,想要在操作系統中獲取用戶信息,都必須調用操作系統提供的各種功能函數才能達到傳播自身和破壞系統的目的[9]。而系統API對系統文件進行的讀寫操作,都會有IO操作傳遞到驅動模塊[10]。因此驅動檢測模塊就利用病毒調用系統API的一系列行為提取出特征。同時,驅動會把正常的文件操作過濾掉,把可疑的或者無法確定的文件行為以特征向量的形式上傳給行為分析模塊,由該模塊作進一步確定。
3.2 驅動過濾原理
Windows所有驅動程序都是IRP包驅動的[11]。IRP的全名是I/O Request Package,即輸入輸出請求包,它是Windows內核中的一種非常重要的數據結構。上層應用程序與底層驅動程序通信時,應用程序會發(fā)出I/O請求,操作系統將相應的I/O請求轉換成相應的IRP,不同的IRP會根據類型被分派到不同的派遣例程中進行處理。病毒進行攻擊時,調用系統API進行的文件操作都會是對系統文件的讀寫,而這些讀寫都會存放在IRP中,并下發(fā)到底層驅動。驅動檢測模塊可以對下發(fā)IRP包進行監(jiān)聽和攔截,然后對這些信息按照定好的規(guī)則進行分析,把不符合規(guī)則的文件信息上傳到分析模塊。
4 基于加權的改進貝葉斯算法
行為分析模塊的主要作用是接受驅動模塊傳遞上來的行為特征向量,并對這些行為特征向量進行分析,以便進一步確定文件是否是病毒文件。而分析的核心算法就是改進的基于加權的貝葉斯算法。
4.1 樸素貝葉斯算法
樸素貝葉斯算法[12]是一種分類算法(結構模型如圖2所示),分類效果好、性能穩(wěn)定、結構簡單易于實現、計算效率高,而且算法的時間復雜度和空間復雜度都比較小,因此適合于檢測未知的惡意程序,包括病毒。樸素貝葉斯分類用于木馬行為分析時,分類集包括:木馬程序、正常程序、不確定程序。待檢測程序的一組異常行為特征組成的特征向量,且每個分量都是行為特征庫中的行為特征。
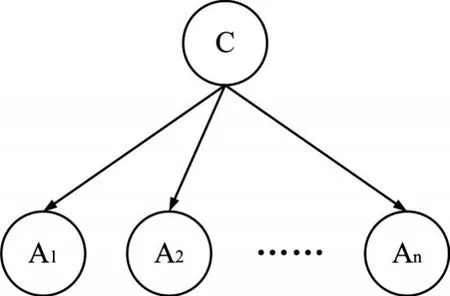
圖2 樸素貝葉斯分類模型結構
樸素貝葉斯算法的基礎,貝葉斯定理:
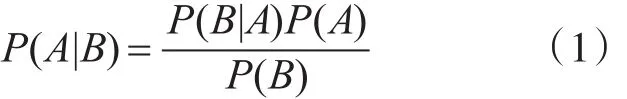
由貝葉斯定理可以看出,樸素貝葉斯[13]的思想是對給出的待分類項,求解在此項出現的條件下各個類別出現的概率,其中最大的概率所屬類別即認為是待求分類項的類別。
樸素貝葉斯分類器的工作原理如下:
1)設X={a1,a2,...,am}為一個待分類項,而每個a為X的一個特征屬性。
2)有類別集合C={y1,y2,...,yn}。
3)統計得到在各類別下各個特征屬性的條件概率估計。即:
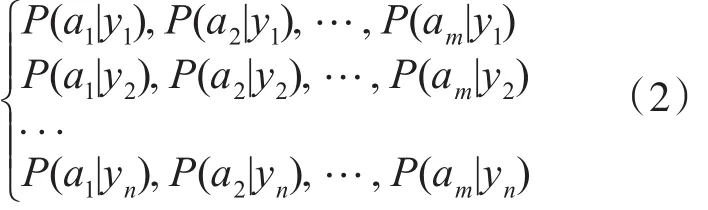
假設各個特征屬性是條件獨立的,則根據貝葉斯定理有如下推導:
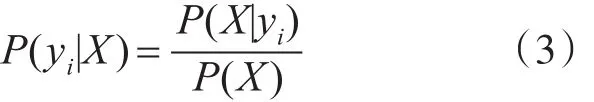
由于P(X)對所有類別都是相同的,可看作常數,因此只需計算分子即可:
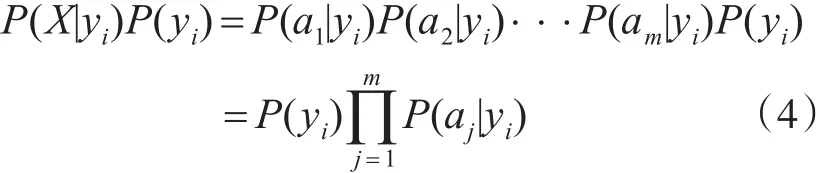
因此,P(yk|X)最大值中的yk即我們所求的分類。根據上述分析,樸素貝葉斯分類的流程可以由圖3表示。
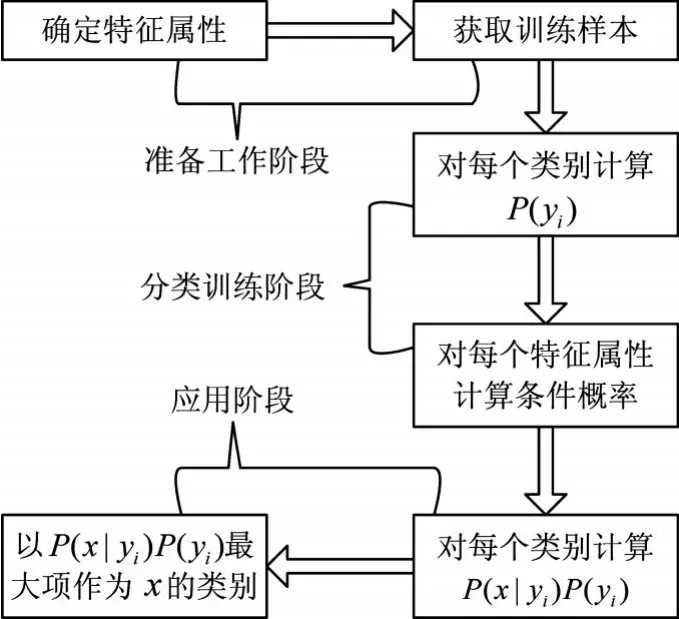
圖3 樸素貝葉斯分類流程
由以上流程可知,整個樸素貝葉斯分類分為三個階段:
第一階段:準備工作階段,這個階段的任務是為樸素貝葉斯分類做必要的準備,主要工作是根據具體情況確定特征屬性,并對每個特征屬性進行適當劃分,然后由人工對一部分待分類項進行分類,形成訓練樣本集合。這一階段的輸入是所有待分類數據,輸出是特征屬性和訓練樣本。這一階段是整個樸素貝葉斯分類中唯一需要人工完成的階段,其質量對整個過程將有重要影響,分類器的質量很大程度上由特征屬性、特征屬性劃分及訓練樣本質量決定。
第二階段:分類器訓練階段,這個階段的任務就是生成分類器,主要工作是計算每個類別在訓練樣本中的出現頻率及每個特征屬性劃分對每個類別的條件概率估計,并記錄結果。其輸入是特征屬性和訓練樣本,輸出是分類器。這一階段是機械性階段,根據前面討論的公式可以由程序自動計算完成。
第三階段:應用階段。這個階段的任務是使用分類器對待分類項進行分類,其輸入是分類器和待分類項,輸出是待分類項與類別的映射關系。這一階段也是機械性階段,由程序完成。
4.2 改進的貝葉斯算法
樸素貝葉斯模型發(fā)源于古典數學理論,因此有著堅實的數學基礎,以及穩(wěn)定的分類效率,其算法簡單,對于小規(guī)模的數據表現很好,能夠處理多分類任務,適合增量式訓練。樸素貝葉斯算法是通過計算一些先驗概率和特征的條件概率得出待驗證的特征概率,這些先驗概率是需要已有的樣本集計算的,而有一個可靠的樣本集至關重要。同時樸素貝葉斯算法在計算過程中是假設各特征屬性之間是沒有關聯的,但是一個病毒的各種行為往往是相互影響的,因此該算法在某種程度上是有誤差的,因此本文提出對該算法的一種改進。
綜上所述,目前樸素貝葉斯算法存在兩個問題:先驗概率和特征的條件概率的計算以及特征屬性之間的關聯。先驗概率和特征的條件概率的計算主要依賴于提供的樣本集,而目前還沒有公認的比較權威的木馬樣本集,因此主要依賴于研究者自己提供,為確保結果的可靠性,選擇樣本時盡量做到平均,把樣本分為三類(木馬程序、正常程序和不確定程序)。借鑒特征加權這一思想,提出基于特征加權的貝葉斯行為分析算法。
該算法的意思就是為程序的每個特征定義一個權值系數,該權值系數的含義是某一個特征行為對一個文件是否是病毒的影響程度。例如:正常程序和病毒修改注冊表這一行為的目的顯然是不一樣的,病毒的行為更具危害,因此它的這一特征權值系數就比正常程序大。在實際應用中,不論是正常程序還是病毒程序,它們運行時的一系列行為是相互關聯的,而樸素貝葉斯的思想是假設這些行為特征沒有關聯,為修正這個假設帶來的偏差,提出加權的思想。根據權值系數[14]的概念,為每一個程序的每一個類別增加一個加權系數,分別為:{w1,w2,…,wn},用以調整后驗概率的計算偏差。這些權值的大小由該特征對某一類別是不是病毒的影響程序來決定。在本文中,這些權值的具體數值由綜合實驗得出,并在之后的樣本實驗中根據錯誤分類進行調整。
根據以上分析,在樸素貝葉斯基礎之上,為每個類別增加一個權值系數,最后計算公式為
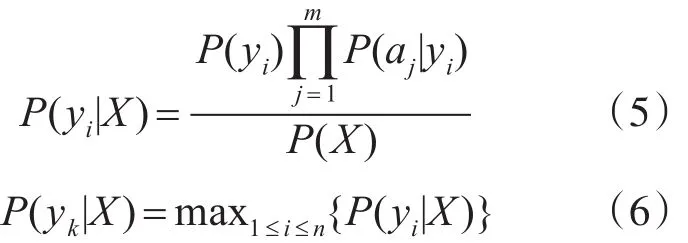
因此,yk即我們所求的分類。其結構模型如圖4所示。
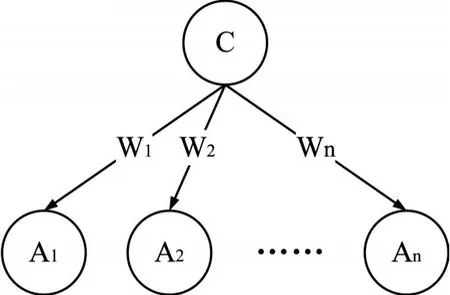
圖4 基于特征加權的貝葉斯分類模型結構
4.3 詳細算法流程
搜集大量的程序構成樣本空間,根據上述將樣本空間分成三類,即C={病毒程序,正常程序,不確定程序}。假設訓練樣本中收集的程序中有a個木馬程序,b個正常程序和c個不確定程序。則三個類別的先驗概率分別為

然后從三種分類的程序中提取出行為特征X={a1,a2,...,am},例如:修改注冊表SHSetValueA、創(chuàng)建文件CreateFileA、程序執(zhí)行CreateProcess等調用系統API的行為。而對于某個行為特征,如ak,經過統計a個木馬中表現此特征的個數是d,b個正常程序表現此特征的個數是e,c個正常程序表現此特征的個數是f,則該特征在三個類別下的條件概率分別為
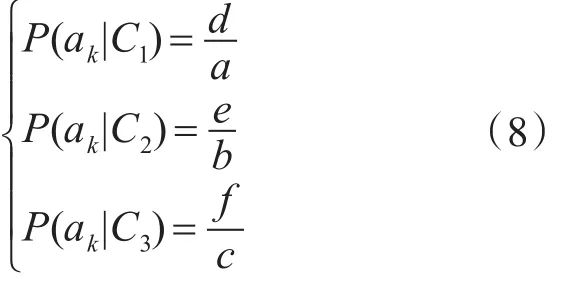
根據以上計算可以得到樣本行為庫。而對于一個待驗證程S,它的行為特征表示為X={a1,a2,...,am} ,對應三個類別的加權系數為W={w1,w2,w3}。則對應的每個類別的概率為
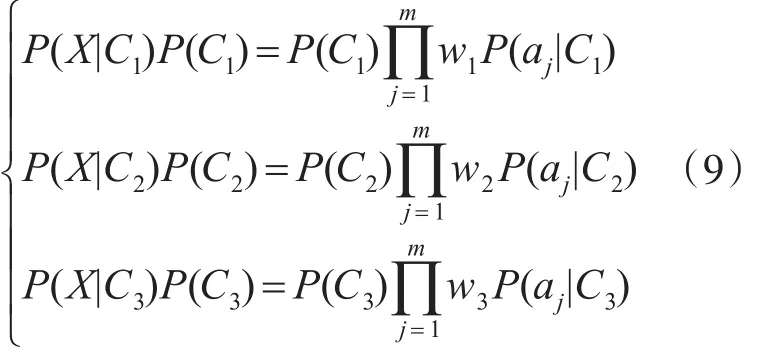
則該待驗證程序的類別為上述三個最大值中的Ci。
5 實驗結果
通過搜集大量的程序構成樣本空間。分為木馬程序、正常程序以及不確定程序。樣本數據如表1所示。每個類別選取200個構成最初的行為庫,然后每個類別選擇50個測試樣本,計算錯誤率。
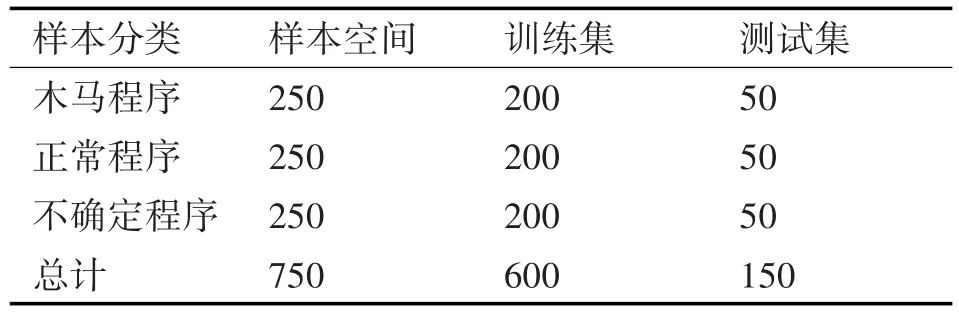
表1 實驗的樣本數據
計算錯誤率中主要計算兩類:1)將木馬程序判斷為正常程序,稱為FN;2)將正常程序判斷為木馬程序,稱為FP。從150條測試集中隨機選擇一些數據測試,測試結果如圖5所示。
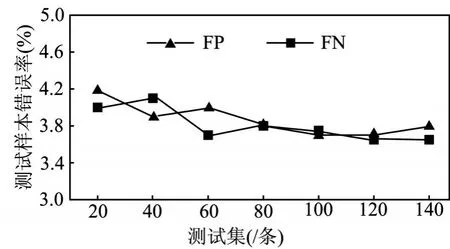
圖5 測試樣本錯誤率
從實驗結果來看,排除一些人為造成的誤差,在樣本數量較少的情況下樣本的錯誤率偏低,表明本文提出的文件監(jiān)控在樣本較少的情況下監(jiān)控效果良好。在如今大數據時代,還需要更多的樣本對該文件監(jiān)控系統進行測試以確保其實際應用價值。
6 結語
本文為了實現文件監(jiān)控的整體性,從驅動層攔截文件操作到上層的行為進行分析,到最終確定文件類別。本文重點介紹了行為改進的貝葉斯算法,在樸素貝葉斯算法模型的基礎之上,提出基于特征加權的貝葉斯行為分析算法,該算法在一定程度上解決了樸素貝葉斯算法的一些缺點,如忽略特征屬性之間的關聯等。但該算法還是依賴于樣本的訓練,因此,如何確定樣本的數量和質量也是研究的重點。經過實驗分析,本文提出的文件監(jiān)控效率良好,能夠在信息安全等方面有良好的應用。
[1]姜學東,王昊欣.互聯網網站網絡安全威脅及策略分析[J].電子測試,2017(09):79-80.
[2]龔儉,臧小東,蘇琪,等.網絡安全態(tài)勢感知綜述[J].軟件學報,2017,28(04):1010-1026.
[3]黃同慶,莊毅.一種實時網絡安全態(tài)勢預測方法[J].小型微型計算機系統,2014,35(02):303-306.
[4]趙穎,樊曉平,周芳芳,等.網絡安全數據可視化綜述[J].計算機輔助設計與圖形學學報,2014,26(05):687-697.
[5]熊芳芳.淺談計算機網絡安全問題及其對策[J].電子世界,2012(22):139-140.
[6]董希泉,林利,張小軍,等.主動防御技術在通信網絡安全保障工程中的應用研究[J].信息安全與技術,2016,7(01):80-84.
[7]張大偉,沈昌祥,劉吉強,等.基于主動防御的網絡安全基礎設施可信技術保障體系[J].中國工程科學,2016,18(06):58-61.
[8]郝增帥,郭榮華,文偉平,等.基于特征分析和行為監(jiān)控的未知木馬檢測系統研究與實現[J].信息網絡安全,2015(02):57-65.
[9]曹玉林,馬建萍.基于微分方程的MANETs病毒傳播模型研究[J].計算機工程.2017(02):1-6.
[10]呂晨,姜偉,虎嵩林.一種基于新型圖模型的API推薦系統[J].計算機學報,2015,38(11):2172-2187.
[11]楊立敏,李耀華,王平,等.IRP理論和IEEE Std 1459-2010在變流器驅動電機能效測試中的應用比較[J].電工電能新技術,2016,35(01):1-6,12.
[12]皮靖,邵雄凱,肖雅夫.基于樸素貝葉斯算法的主題爬蟲的研究[J].計算機與數字工程,2012,40(06):76-78,123.
[13]王輝,陳泓予,劉淑芬.基于改進樸素貝葉斯算法的入侵檢測系統[J].計算機科學,2014,41(04):111-115,119.
[14]毛明,楊譜,李旭飛.遞歸擴散層的權值系數計算方法[J].計算機工程,2014,40(11):126-129,134.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2019年12期)2019-05-21 02:55:44
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學生必讀(中年級版)(2018年4期)2018-07-05 06:00:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
環(huán)球時報(2017-03-30)2017-03-30 06:44:45
