一種基于Spark的大數據匿名化系統實現
2018-05-04 02:38:58卞超軼朱少敏周濤
電信科學 2018年4期
關鍵詞:系統
卞超軼,朱少敏,周濤
(1.北京啟明星辰信息安全技術有限公司,北京 100193;2.北京郵電大學,北京 100876)
1 引言
電力行業大數據分析與應用促進了電力系統運行方式、管理體制、發展理念和技術路線等方面的重大變革,成為智能電網和全球能源互聯網創新發展的重要技術支撐。電力大數據分析涉及電力企業核心數據以及用戶隱私數據,具有實時性更高、數據敏感度更強等特點,其數據安全與隱私保護的需求更加迫切,安全技術要求更高。例如,為了分析用戶用電行為,需要將用電數據提供給內外部分析人員,但是原始數據中包含涉及用戶隱私部分,一旦大規模泄露并被不法分子利用,存在巨大安全隱患;在電力企業運行管理方面,目前廣泛利用大數據技術實現電源電網規劃、發輸變電設備狀態評估、配電網供電可靠性等研究與應用,這些海量異構大數據是電力企業內部關鍵的運行管理數據,關系到電力企業的安全穩定運行,大規模研究與利用對數據處理、使用和存儲等方面的信息安全帶來了新挑戰;防范大數據環境下電力系統核心數據和用戶敏感數據的采集、上傳及傳播過程中的敏感數據泄露風險,迫切需要研究適應電力業務大數據分析架構的大數據去隱私化處理理論、模型和算法,形成大數據多層次全方位敏感數據保護基礎環節。
數據匿名化是指以隱私防護為目的而對數據敏感部分進行特殊處理的過程,典型處理手段包括加密、單向散列、消去、掩蓋和模糊泛化等,以避免數據在公開或共享時發生隱私泄露。分組匿名化(group-based anonymization)是一類經典數據匿名化技術框架,它通過構造匿名數據分組使得組內的各條數據無法互相區分,從而隱藏數據對應的用戶身份。本文設計并實現了一種基于Spark實現的大數據匿名化系統,利用分布式內存計算來提高計算處理效率,支持Hadoop平臺多種常用數據格式,如HDFS文件、Hive表等,并對系統實現的效果進行了測試驗證及性能評估。
2 相關工作
2.1 Hadoop平臺
Hadoop[1]是由Apache負責開發及維護的開源軟件框架,主要目標是提供對大數據分布式存儲及計算處理的支持。Hadoop的核心是分布式文件系統HDFS與分布式計算引擎MapReduce。
Spark[2]是一種分布式內存計算引擎,相比于MapReduce,啟用了內存分布數據集,將計算任務中間結果保存在內存中,避免了 MapReduce計算處理中利用HDFS中轉而帶來的大量磁盤I/O,大幅提高并行計算效率。在存儲方面,Spark沿用HDFS,實現對 Hadoop平臺上的多種數據管理訪問直接支持。
2.2 分組匿名化
傳統數據匿名化方法僅僅通過去除數據中的身份信息(例如身份證號、姓名等)達到信息隱匿效果,但是仍可利用一些其他信息來定位識別個體。例如,表1中雖然沒有包含身份信息,但是仍可以根據其中的非敏感信息(年齡、國籍及郵編)推斷識別出具體的個人,從而造成用戶用電量這類隱私敏感信息的泄露。這些可以被用于識別個體身份的非敏感信息被稱為準標識符(quasi-identifier)。數據匿名化技術正是通過對數據中的這些準標識符進行處理以達到隱私保護的效果。
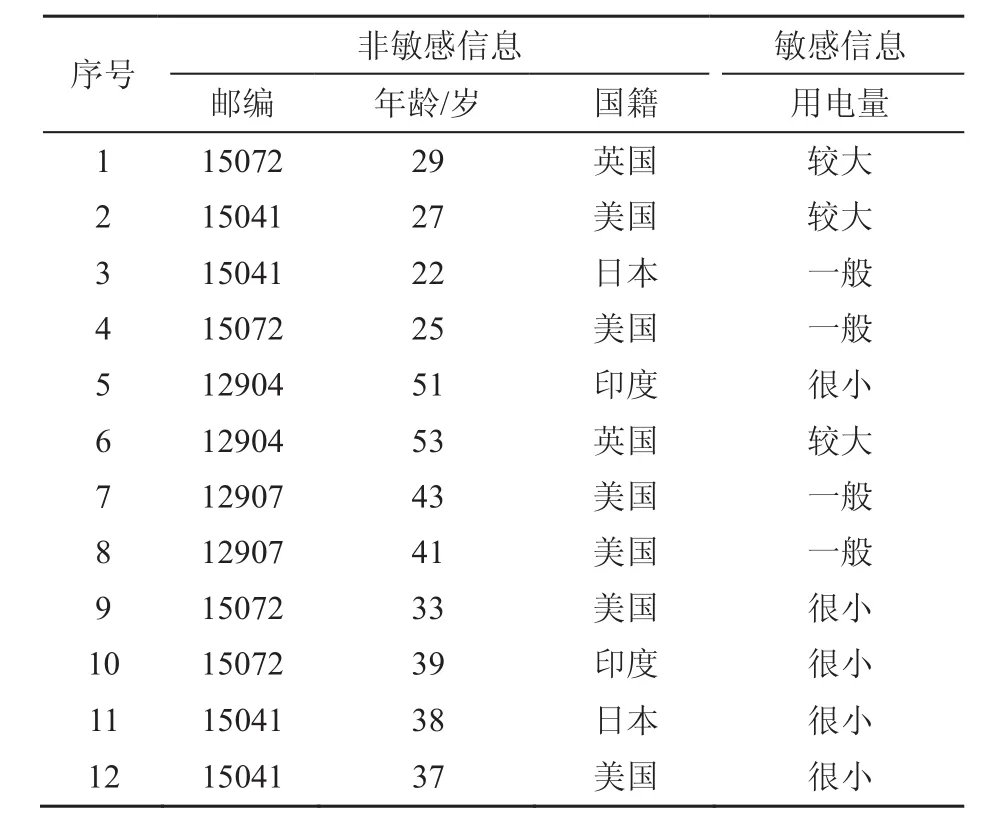
表1 包含敏感信息的數據
分組匿名化是一類經典數據匿名化技術,其核心思想是通過構造匿名記錄組,使得同一組內的多條數據難以相互區分。k-匿名化(k-anonymity)[3]要求處理后的數據中存在的任意準標識符取值的組合都與至少 k條記錄匹配。匿名化處理的手段有泛化和隱藏:泛化是指將屬性的取值進行模糊替換處理,比如將“28”替換成“<30”,將“中國”替換成“亞洲”等;隱藏是指將屬性值隱去,例如使用“*”替換。表2給出了對表1數據經過4-匿名化處理后的一種結果。總共12條數據形成了3組,每組內的4條數據擁有完全相同的準標識符,無法互相區分。
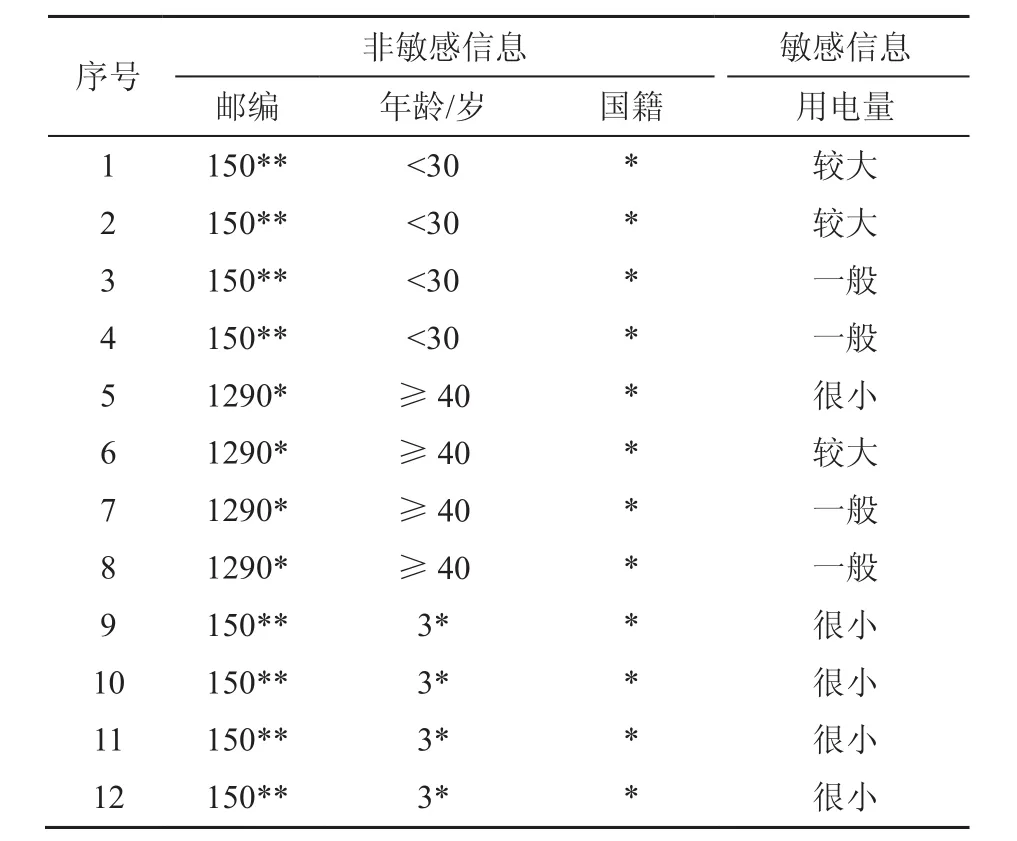
表2 4-匿名化示例
k-匿名化有缺陷,如表2中最后一組敏感屬性取值相同,這樣仍然暴露了隱私信息,因此l-多元化(l-diversity)[4]要求每種準標識符組合對應數據至少有l種不同敏感屬性值。表3展示了對表1數據進行 3-多元化處理后的結果,它保證了每組敏感屬性至少有3種不同的取值。
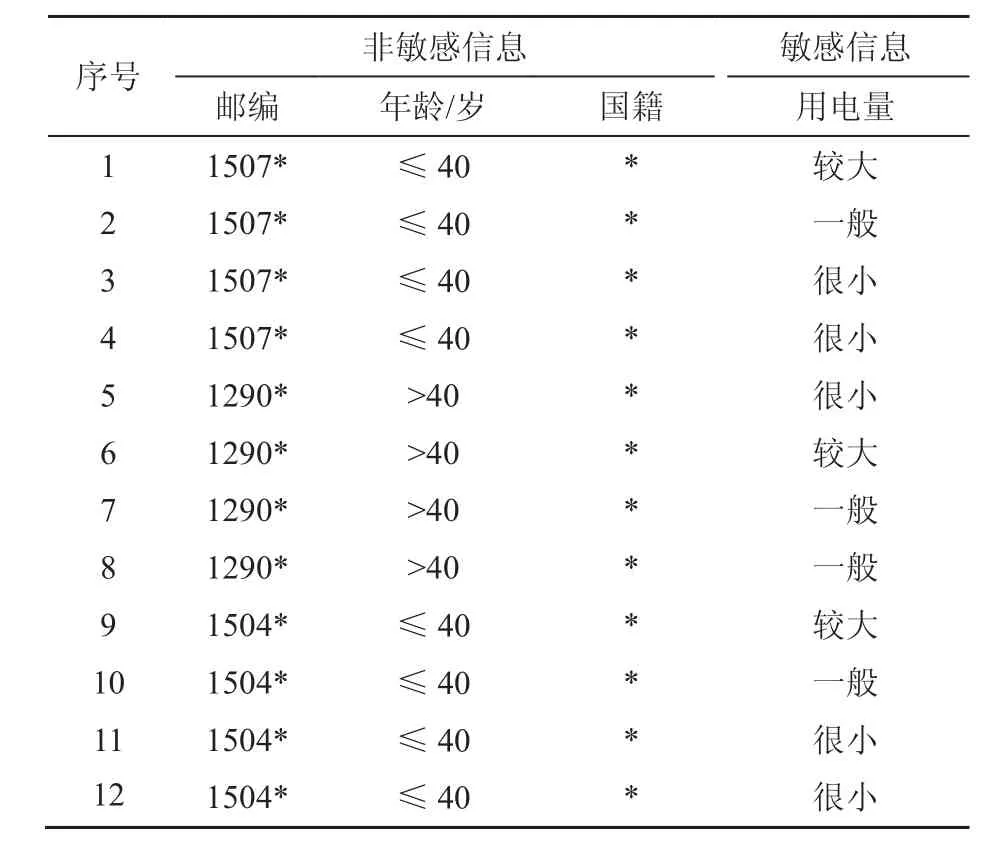
表3 3-多元化示例
k-匿名化和l-多元化是廣泛應用的分組匿名化框架,已經有相應算法被提出以滿足隱私要求[5],也有適用于小規模數據的開源工具發布[6],但是針對大數據場景僅有一些利用MapReduce來并行匿名化處理過程的工作[7]。為了滿足電力大數據分析實際安全需求,本文設計了基于分布式內存計算引擎Spark開發,支持對以HDFS文件、Hive表等格式存儲于 Hadoop平臺的數據進行高效匿名化處理的系統,滿足分組匿名化的隱私要求,實現數據公開及共享時的有效隱私防護。
3 系統實現
3.1 匿名化算法
本系統采用Mondrian算法[8]來實現數據匿名化。核心思想是先將所有準標識符對應的屬性完全模糊化,這種情況下所有數據條目都是相同的,然后逐輪選取一個屬于準標識符的屬性增加公開信息,對數據進行不斷劃分,并確保劃分出的任意子集包含的數據條目數均不小于k,也就是保證k-匿名化要求被滿足。算法每輪迭代中都會選取構成準標識符的一個屬性對數據進行劃分,循環迭代直至不能再劃分,即無論如何繼續劃分都會造成某個子集不再滿足 k-匿名化要求。數據屬性有兩種類型:數值屬性和類別屬性。前者的劃分是通過選取中間值(或中位數)對數據進行二分,而后者則是根據可取的具體類別數對數據進行劃分(二分或多分,由類別屬性的取值數決定)。
圖1給出了一個對包含年齡、郵編這兩個數值屬性的數據集使用 Mondrian算法達到 2-匿名化要求的處理過程示例。圖1(a)為數據分布情況,以“★”符號表示數據條目。初始數據中的年齡及郵編屬性被完全模糊化,例如均以“*”表示。假設首先選擇郵編這一屬性進行數據劃分,則結果如圖1(b)所示。這時位于圖1(b)左側的數據子集的郵編屬性可由初始的“*”表示變化為“≤27K”,而右側的數據子集的郵編屬性變化為“>27K”。然后對位于圖1(b)左側的數據子集選擇年齡這一屬性再次進行劃分,結果如圖1(c)所示。相應地,圖1(c)左下方數據的年齡屬性由初始的“*”變化為“≤60”,而左上方數據的年齡屬性變化為“>60”。同樣對位于圖1(c)右側的數據子集也選擇年齡這一屬性進行再劃分,結果如圖1(d)所示。這樣圖1(d)右下方數據的年齡屬性變化為“≤62”,圖 1(d)右上方數據的年齡屬性變化為“>62”。此時不能再進行任何劃分,否則會破壞2-匿名化要求。最后數據被劃分為4個分組,每個分組內的數據無法互相區分。例如圖1(d)中左上方的兩條數據的年齡屬性均為“>60”,郵編屬性均為“≤27K”。
上述的Mondrian算法在簡單修改后即可支持l-多元化。具體來說,在每次數據劃分時不檢查劃分出的子集所包含的數據條目數,而改為檢查劃分出的數據子集是否滿足 l-多元化要求。如果滿足就繼續遞歸劃分,否則就回滾該次劃分。
3.2 算法復雜度
Mondrian匿名化算法應用于僅包含數值屬性的數據集時的工作過程與kd樹的構造過程相同,所以具有相同的計算復雜度,即O(nlogn),其中n為總數據集大小。而按類別屬性進行劃分時,只需要遍歷一遍相應數據即可,與數值屬性時按中位數二分的計算復雜度是相同的(均為 O(k),這里k為要劃分的數據集大小);劃分后形成的子集數雖然有差別,但是對于總體計算復雜度的影響只體現在常數系數上。因此,Mondrian算法應用于一般數據集的計算復雜度仍為 O(nlogn),具有良好的可擴展性,適用于大數據場景。
3.3 實現細節
(1)數值類型的劃分實現方式
Mondrian算法對數值屬性劃分時采取的方法是按中位數進行二分。由于在大數據規模下使用快速排序再定位中位數計算,時間復雜度較高,且線性時間復雜度的求中位數算法在 Spark上實現較為復雜,所以系統實現時通過統計每種取值出現的次數再快速定位出中位數,從而發揮Spark的數據并行處理優勢。
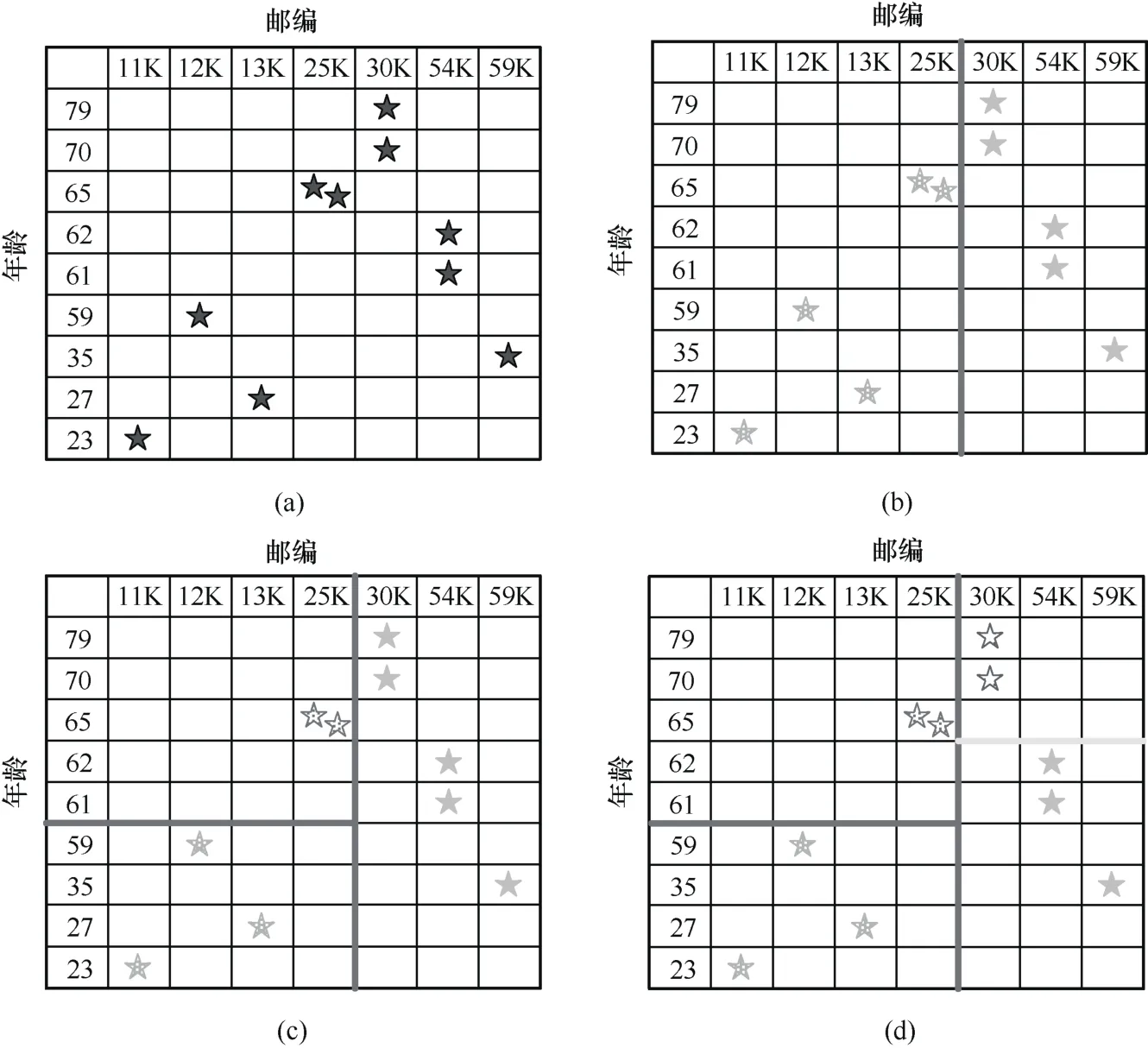
圖1 Mondrian算法劃分數值屬性數據示例
(2)遞歸算法的實現方法
Mondrian匿名化算法是一個具有遞歸思想的算法,自頂而下地對數據進行劃分,不斷對劃分出的子數據集使用相同過程進行再次劃分,直至滿足停止條件。然而遞歸實現在 Spark分布式計算平臺上無法使用。本文改進為采用非遞歸實現,使用一個隊列記錄之后要繼續進行劃分的子數據集,然后按順序從隊列中取出依次進行。
(3)輸入配置文件
數據匿名化處理需要類別屬性的泛化樹作為輸入。所謂泛化樹,就是類別屬性進行泛化處理時的層次關系結構,如“中國”→“東亞”→“亞洲”→“*”。本系統中采用文本格式配置文件提供這一輸入,文件中的每一行描述一個從葉節點(具體屬性取值)到根節點(通常為“*”)的泛化關系,例如上述的泛化關系可表達為:“中國;東亞;亞洲;*”。
4 系統驗證
本文系統測試采用機器學習及數據分析挖掘中常用的數據集Adult進行。Adult數據集是從美國1994年人口普查數據庫抽取而來,其中包含一個敏感屬性——收入狀況,其他屬性包括年齡、婚姻狀態、職業、性別等。在測試中選取了其中8個非敏感屬性(構成準標識符),其中兩個是數值屬性,其余6個均為類別屬性。測試時將數據集以文本文件形式存放在HDFS中,同時將匿名化算法所需要的泛化樹等配置信息也置于HDFS中供系統初始化時讀取。
4.1 效果測試
圖2顯示了測試數據集中準標識符屬性的取值樣例,其中第一列與第三列是數值屬性,其余均為類別屬性。而圖3則給出了準標識符屬性經過本系統進行k-匿名化(k取值為10)處理后的樣例。注意這兩個圖中的數據條目并非一一對應,只是隨機選取的展示樣例。可以看出,數值屬性被泛化成一個區間,如第一列的“[38,45]”和第三列的“[11,14]”;而類別屬性則被泛化成“*”或其他更高層次的泛化表達。經檢查確認,本系統的匿名化處理結果與Mondrian算法的開源單機實現版本[9]相同,證明了本系統的匿名化算法實現的正確性。類似地,對于 l-多元化也進行了相應測試,同樣能夠得到預期正確結果,本文不再單獨列出。

圖2 原始數據集準標識符屬性樣例
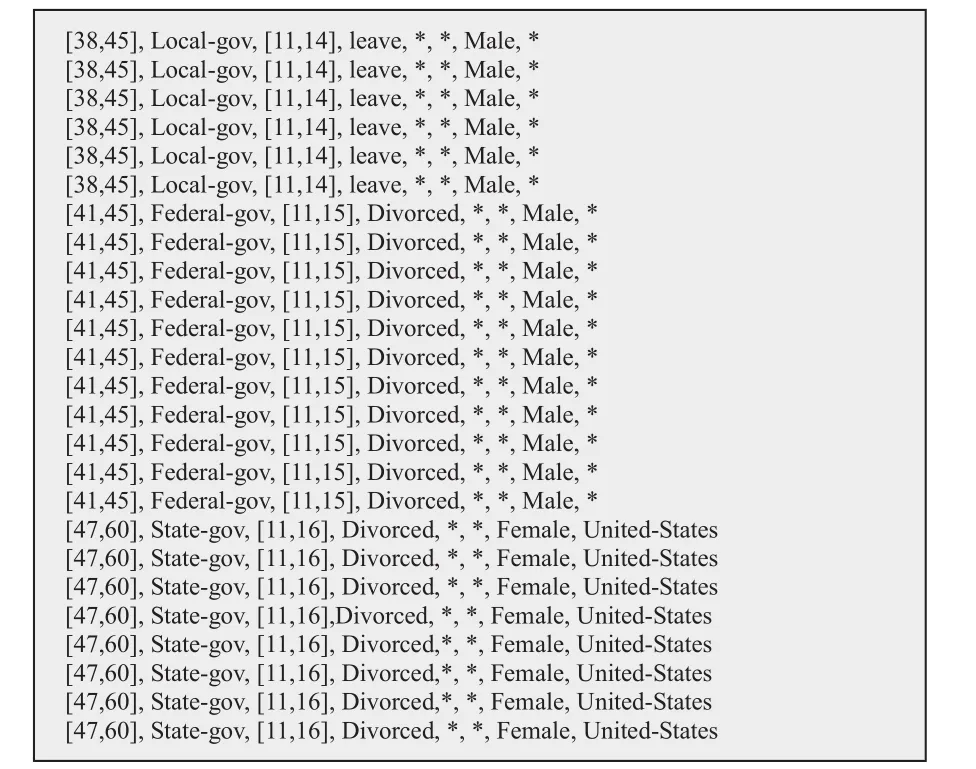
圖3 經數據匿名化處理后的準標識符屬性樣例
4.2 性能評估
為了驗證基于 Spark實現的系統在對數據進行匿名化處理時能否有效提高效率,對 Adult數據集進行擴充之后開展了一些簡單實驗。原始Adult數據集包含約 30 000條數據,無法體現Spark在大數據處理方面的優勢,因此將其復制100倍、1 000倍,并對復制數據條目的數值屬性進行隨機修改,從而獲得供性能評估測試用的數據。具體來說,復制100倍、1 000倍后的數據條數分別達到約3 ×106和30×106,相應的數據文件大小分別約為380 MB及3.8 GB。使用單機版的匿名化程序和基于 Spark實現的本系統分別進行相同的處理并記錄各自消耗的時間,對于兩種大小的數據集均重復進行了10次實驗。其中實驗用的Spark集群由3臺Dell R720服務器(CPU:Intel?Xeon? E5-2603 v2@ 1.80 GHz,8核;內存:64 GB DDR3@ 1 600 MHz)組成,而單機版則在其中一臺服務器上運行。圖 4給出了實驗結果,直方塊表示10次實驗的平均值,誤差條表示標準差。結果顯示基于Spark實現的匿名化系統比單機版程序對380 MB和3.8 GB數據集進行匿名化處理所用的時間分別少約 21%和 47%,表明基于 Spark實現的系統能夠有效提高數據匿名化處理的效率,而且在數據規模增大時優勢更為明顯。
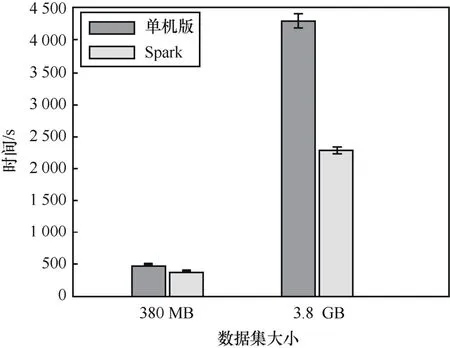
圖4 數據匿名化處理時間對比
5 結束語
本文設計了一個基于分布式內存計算引擎Spark開發實現的大數據匿名化系統,支持對Hadoop平臺的多種存儲格式的數據進行高效匿名化處理,使用Mondrian算法達到k-匿名化、l-多元化等分組匿名化框架,能夠在數據公開時對其中包含的隱私信息進行防護隱藏使其不會被惡意攻擊者獲取。系統性能相比于單機處理有明顯提升。在未來的研究工作中,將參考Spark MLlib中決策樹算法的實現來進一步提高系統的處理效率,并對數據經本系統匿名化處理后的價值損失進行理論分析與評估。
參考文獻:
[1] Apache Software Foundation.Apache Hadoop[EB].2011.
[2] Apache Software Foundation.Apache Spark[EB].2014.
[3] SWEENEY L.K-anonymity: a model for protecting privacy[J].International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 557-570.
[4] MACHANAVAJJHALA A, KIFER D, GEHRKE J, et al.L-diversity: privacy beyond k-anonymity[J].ACM Transactions on Knowledge Discovery from Data (TKDD), 2007, 1(1): 3.
[5] FUNG B, WANG K, CHEN R, et al.Privacy-preserving data publishing: a survey of recent developments[J].ACM Computing Surveys (Csur), 2010, 42(4): 14.
[6] PRASSER F, KOHLMAYER F.Putting statistical disclosure control into practice: the ARX data anonymization tool[M].Berlin: Springer International Publishing, 2015.
[7] JADHAV R H, INGLE R B.A survey on data anonymization approaches using MapReduce framework on cloud[J].Digital Image Processing, 2015, 7(2): 48-49.
[8] LEFEVRE K, DEWITT D J, RAMAKRISHNAN R.Mondrian multidimensional k-anonymity[C]//International Conference on Data Engineering, April 3-7, 2006, Atlanta, GA, USA.Piscataway: IEEE Press, 2006: 25.
[9] QIYUAN G.GitHub-qiyuangong/basic_mondrian[EB].2015.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
