基于不平衡文本數據挖掘的鐵路信號設備故障智能分類
2018-05-07 00:34:14楊連報馬小寧吳艷華
鐵道學報 2018年2期
楊連報,李 平,薛 蕊,馬小寧,吳艷華,鄒 丹
(1.中國鐵道科學研究院,北京 100081;2.中國鐵道科學研究院 電子計算技術研究所,北京 100081)
鐵路信號設備是鐵路信號、車站聯鎖設備、區間閉塞設備等的總稱,是保證列車運行與調車作業安全的重要保障[1]。隨著鐵路信號設備的升級改造和快速發展,鐵路局積累了海量的鐵路信號設備事故故障數據。鐵路信號設備故障多以非結構化文本形式記錄,需依靠人工理解和專家經驗進行故障分類,易造成故障分類的不準確和隨意性。在鐵路大數據時代,應用文本挖掘等機器學習算法實現鐵路信號設備故障的智能分類是當前急需解決的問題。
鐵路信號設備類型眾多且各設備故障機理不同[2],存在故障類別數據不平衡的問題,即絕大多數文本屬于同一類故障,而其他故障只有少量的文本。鐵路信號設備故障智能分類通過文本挖掘技術實現對鐵路信號設備故障不平衡文本數據的結構化轉換,通過故障類別數據均衡以及集成學習EL(Ensemble Learning)[3]實現故障的智能分類。
鐵路信號設備故障不平衡文本數據結構化轉換,主要是指提取故障文本的特征并轉換為向量。目前,文本數據主要基于詞袋法BOW(Bag of Words)以向量空間模型VSM[4](Vector Space Model)來表征文檔,即將文檔看成一系列詞的集合,通過抽取能夠表征文檔特征的關鍵詞并轉換為向量。最常用的文本特征提取算法有詞頻-逆文檔頻率TF-IDF[5](Term Frequency-Inverse Document Frequency)、信息增益IG[6](Information Gain)、互信息MI[7](Mutual Information)、主題模型TM[8](Topic Model)、Word2Vec[9-10]、卡方檢驗等。其中,以TF-IDF使用最為廣泛和簡單。由于鐵路行業缺乏語料庫,關于鐵路信號設備文本結構化轉換的研究較少。文獻[11]通過主題模型實現對高鐵信號系統車載設備文本的特征提取,并通過貝葉斯網絡實現故障診斷。文獻[12]通過TF-IDF實現文本特征向量提取,并通過詞云的形式實現對地鐵施工安全風險的分析。
鐵路信號設備的故障文本數據均衡與集成學習,主要是從數據和算法兩方面來解決數據不平衡問題。數據層面主要是通過更改數據集的樣本分布來實現數據的平衡,主要分為過采樣和欠采樣兩種[13]。過采樣是自動生成小類別數據,欠采樣是選取大類別數據中的部分樣本。文獻[14]提出的SMOTE(Synthetic Minority Oversampling Technique)算法是過采樣中比較常用的一種,主要有Borderline-SMOTE[15]、SVM-SMOTE等幾種改進版本。其基本思想是合成新的少數類別樣本,實現樣本類別的平衡。算法層面主要通過訓練多個分類器,充分利用分類器的差異性,通過Voting方式實現不同分類器的集成學習。傳統的文本分類主要是基于單個分類器模型,如邏輯回歸LR(Logistic Regression)、決策樹DT(Decision Tree)、SVM(Support Vector Machine)和離散型樸素貝葉斯Multinomial NB(Multinomial Naive Bayesian)等[16],但這些分類器模型主要適用于平衡的訓練數據樣本。集成分類器主要包含Bagging和Boosting兩種,Bagging的代表算法主要是隨機森林RF[17](Random Forest),Boosting的代表算法是梯度提升樹GBDT[18](Gradient Boost Decision Tree)等。
本文借鑒專家學者在文本結構化處理和不平衡數據分類中的經驗,結合鐵路信號設備文本數據特點,提出基于TF-IDF+SVM-SMOTE+Voting的多分類器集成學習分類模型。該模型通過TF-IDF算法實現故障文本的特征抽取和向量轉化,并利用SVM-SMOTE算法實現鐵路信號設備故障小類別數據的自動生成,通過Voting的方式集成LR、Multinomial NB、SVM等基分類器以及RF、GBDT等集成分類器算法,實現鐵路信號設備的智能分類。為驗證模型的正確性和有效性,本文選取某鐵路局2012—2016年鐵路信號設備故障不平衡文本數據共計10類641條進行試驗分析。
1 鐵路信號設備故障智能分類整體架構
基于不平衡文本數據挖掘的鐵路信號設備故障智能分類的整體架構如圖1所示,整個架構分為數據處理層、模型優化層和智能分類層3個層次。
框架的最底層是數據處理層。數據處理層主要實現鐵路信號設備故障文本數據結構化處理,抽取文本的特征,并轉換為計算機可識別和計算的文本向量。針對轉化后的文本向量,利用SVM-SMOTE模型對小類別數據進行自動生成,從數據層面解決樣本數據不均衡的問題。
框架的中間層為模型優化層。針對數據處理層所得到的樣本數據,模型優化層利用邏輯回歸、樸素貝葉斯、支持向量機等基分類器,以及隨機森林、GBDT等集成分類器進行分類,并根據參數特點進行調優。調優的參數主要有迭代次數、學習步長、采樣率等。最后,通過Voting的方式對調優后的集成分類器以及基分類器進行集成學習,得到最終的智能分類模型。
框架的最上層為智能分類層。智能分類層主要是根據模型優化層得到的智能分類模型,對待分類的文本進行自動分類。
2 不平衡故障文本數據處理
鐵路信號設備主要包含調度集中CTC(Centralized Traffic Control)設備、列車調度指揮系統TDCS(Train Operation Dispatching Command System)設備、列車運行監控裝置LKJ、車載設備、聯鎖設備、閉塞設備、道岔、軌道電路、信號機、電源屏設備。鐵路信號設備故障分類方式有多種,本文按照設備的功能及現象來劃分,主要分為10類故障,即CTC設備故障、LKJ設備故障、TDCS設備故障、閉塞設備故障、車載設備故障、道岔故障、電源屏故障、軌道電路故障、微機聯鎖故障、信號機故障等。圖2為某鐵路局電務段2012—2016年信號設備故障分布情況。
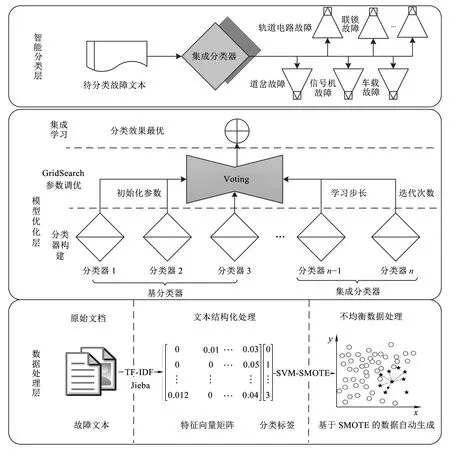
圖1 基于不平衡文本數據挖掘的鐵路信號設備故障智能分類整體架構
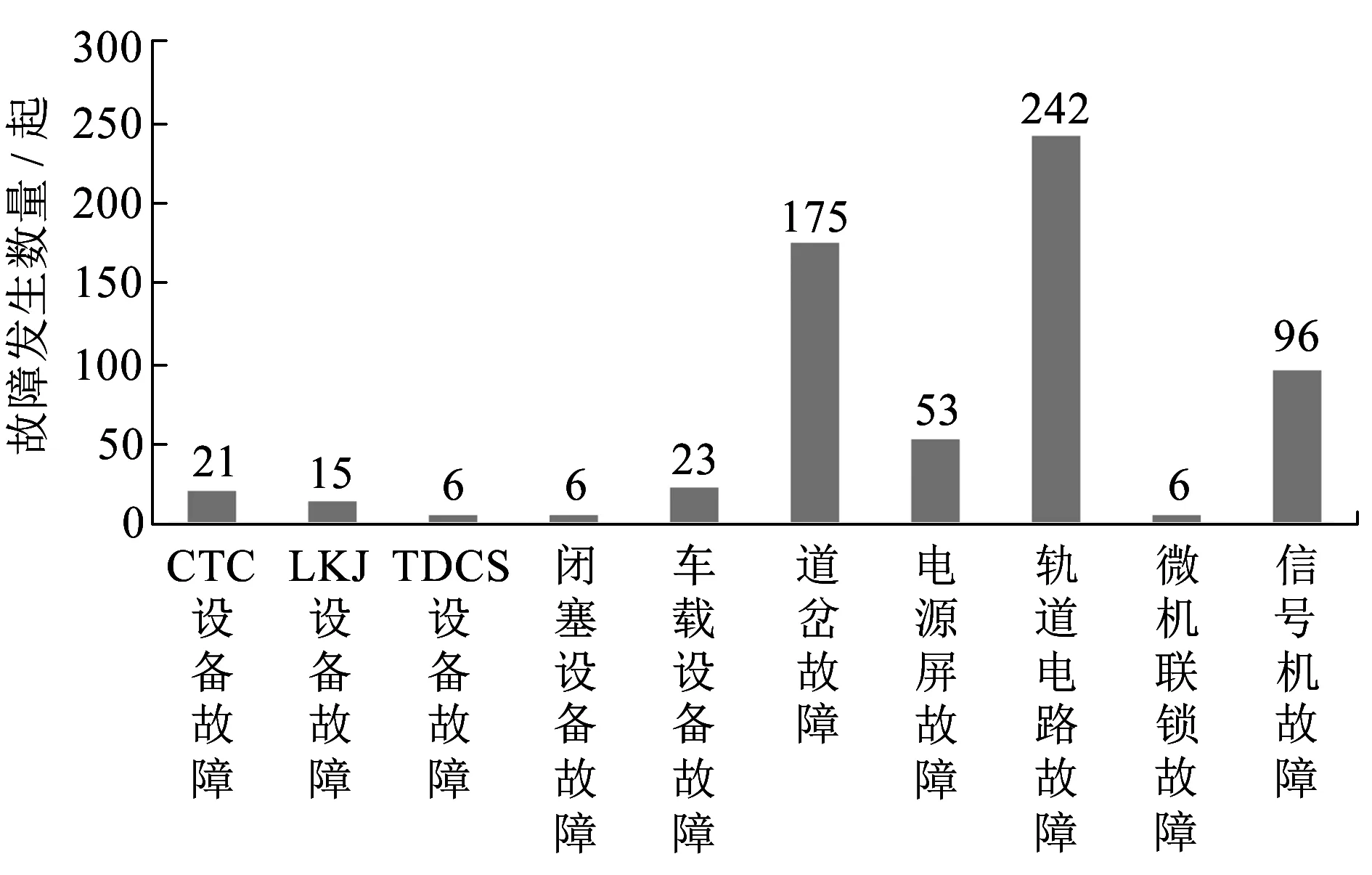
圖2 某鐵路局電務段2012—2016年鐵路信號設備故障分布情況
由圖2可知,故障主要以道岔、軌道電路、信號機等為主,對于微機聯鎖、TDCS、閉塞等設備的故障較少,不均衡比例達到1∶40,為典型的數據分類不均衡問題,直接通過模型訓練容易造成分類的不準確。
2.1 鐵路信號設備故障文本數據與中文分詞
鐵路信號設備故障文本數據主要由現場人員通過自然語言記錄所形成。部分實例見表1,表1中記錄的主要信息為故障發生經過、原因描述以及故障分類。

表1 鐵路信號設備故障文本數據(部分)
鐵路信號設備故障文本數據結構化處理首先要實現故障文本的分詞。主流的分詞技術主要有基于詞典匹配的中文分詞、基于字統計模型的中文分詞、基于字標注的中文分詞以及基于深度學習的中文分詞等。本文采用Jieba分詞工具,利用通用詞典和自定義領域詞典實現鐵路信號設備故障文本的分詞,如圖3所示。自定義領域詞典主要是鐵路信號設備故障的常用詞匯。

圖3 領域詞典與通用詞典相結合的鐵路信號設備中文分詞
2.2 基于TF-IDF的故障文本特征提取與向量化
TF-IDF(Term Frequency-Inverse Document Frequency)是一種基于統計的常用加權方法,廣泛應用于檢索與文本分析中。TF-IDF假設:如果一個詞在一個文檔中頻繁出現,而在其他文檔中出現較少或不出現,則認為該詞作為該文檔的關鍵詞,將該文檔與其他文檔區分開來。
TF表示詞頻,即該詞在一個文檔中出現的次數,理論上出現的次數越多則與文檔的主題越相關,但需要排除一些停用詞,如“的”“地”“了”“但”等。詞頻TFi,j為
( 1 )
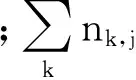
逆向文檔頻率IDFi為
( 2 )
式中:ki為詞wi在文檔集合D中相關的文檔個數;N為D的大小;同理,分母加1是為了避免分母為0的情況。
將詞頻與逆向文檔頻率結合起來,即用IDFi來矯正TFi,就得到了文檔dj中詞wi的權重,即
Wi,j=TFi×IDFi
( 3 )
則某個文檔dj可用單詞權重構成向量
dj=[W1,jW2,jW3,j…Wn,j]
( 4 )
2.3 基于SVM-SMOTE的故障少數類別樣本自動生成
SMOTE是一種常用的合成少數類樣本數據以達到訓練集數據的類別平衡的過采樣技術,使得分類器的學習能力得到顯著提高。其基本原理為:通過選擇少數類樣本xi的k個鄰近同類樣本,并從k個鄰近同類樣本中隨機選取一個xj,通過隨機線性插值,構造出新的少數類樣本xnew為
xnew=xi+u(xi-xj) 0≤u≤1
( 5 )
由于傳統SMOTE沒有考慮其鄰近樣本的分布特點,可能在類別間發生重復。近年來有一些基于SMOTE的改進算法相繼被提出,具有代表性的算法包括Borderline-SMOTE算法、SVM-SMOTE算法等。Borderline-SMOTE僅對邊界上的少數類樣本進行線性插值,從而起到加強邊界樣本的作用。SVM-SMOTE根據不同類別樣本鄰近比例,通過SVM構造分類邊界,能夠根據實際的樣本數據分布進行插值,使得類別之間區分更為明顯。需要說明的是,SVM-SMOTE主要利用SVM對不平衡數據分類不太敏感的特性,用于平衡數據,使分類效果更佳。因此,本文選擇SVM-SMOTE算法實現少數類別數據的生成。不同SMOTE算法生成少數類樣本的效果如圖4所示。
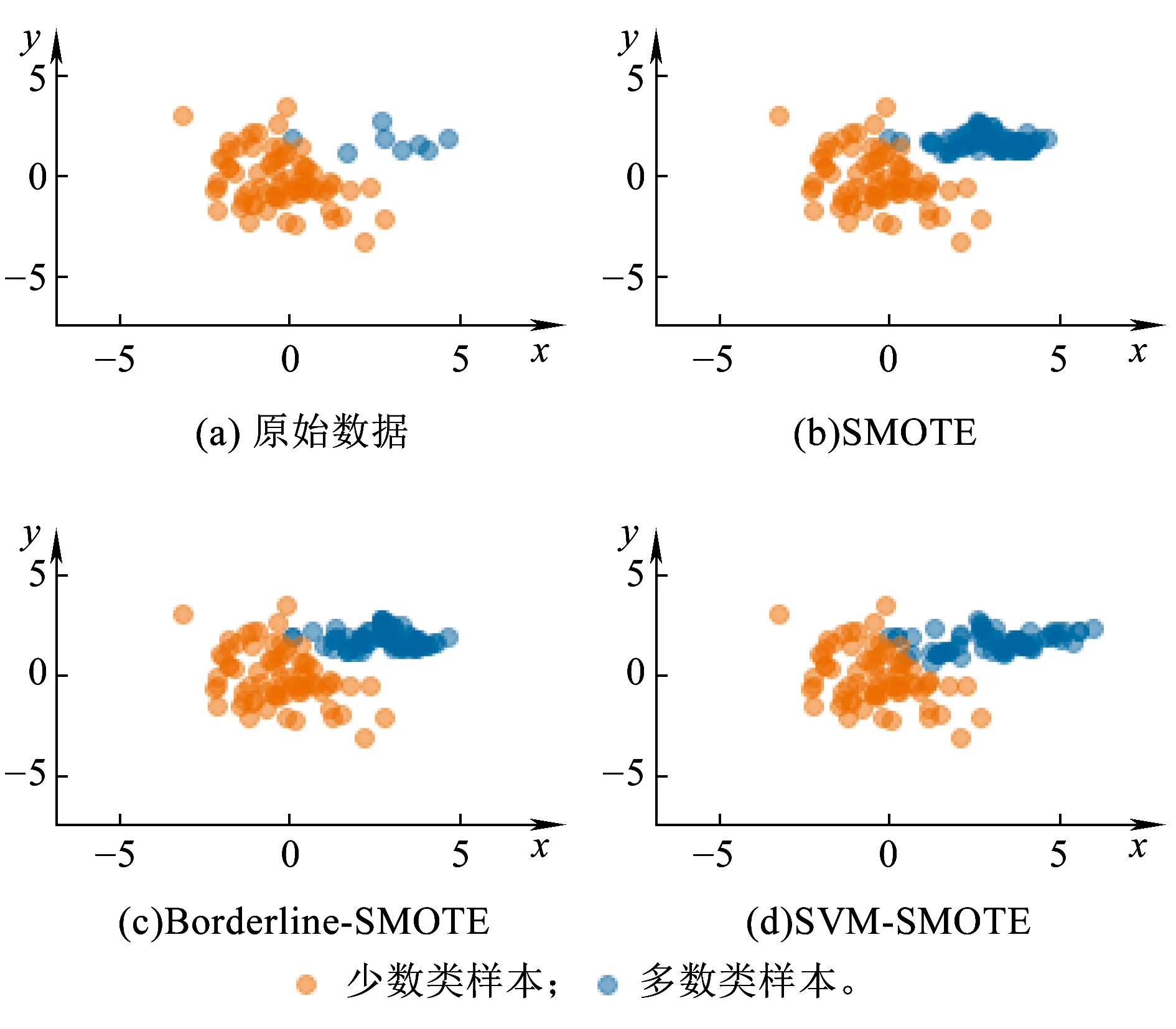
圖4 不同SMOTE算法合成少數類樣本示意圖
3 基于Voting的多分類器集成學習故障智能分類模型
3.1 基分類器
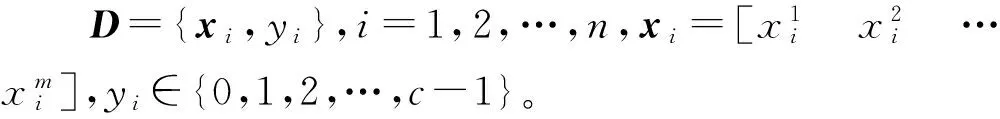
(1)LR是一種基于統計分析的分類方法,可以得到概率型的分類結果為
( 6 )
由此可以得出相應的Logistic回歸模型為
gk(x)=βk0+βk1x1+βk2x2+…+βkmxm
( 7 )
參數β的計算通常通過最大似然方法進行估計。
(2)DT是一種特殊的樹形結構,主要用來進行分類和決策。決策樹包含3種類型的節點,分別為:決策節點,通常用矩形框來表示;機會節點,通常用圓圈來表示;終結點,通常用三角形來表示。常用的決策樹生成算法有ID3、C4.5和C5.0等。
(3)SVM是通過構造一個超平面f(x),使得該函數能夠表示類別y與樣本向量x的關系。定義線性x不敏感損失函數為
( 8 )
如果存在一個超平面,即
f(x)=ωTx+b=0
( 9 )
式中:ω∈Rn,b∈R,使得
|y-f(x)|≤ε
(10)
則稱樣本集D是ε-線性近似的,f(x)為線性回歸估計函數。樣本點{xi,yi}到超平面的距離為
(11)
為得到最優的超平面分類,轉換為一個優化問題,即使‖ω‖2最小。
針對非線性問題,SVM通過非線性映射φ(xi)將樣本映射為高維特征空間,并通過核函數的方式計算內積。此時優化問題的目標函數可表示為
(4)MultinomialNB是適用于離散特征的樸素貝葉斯模型。該模型將文檔看作是帶詞頻的詞語集合,在計算先驗概率和條件概率時,會做一些平滑處理,從而解決如果某一維的特征值沒在訓練樣本中出現,使得后驗概率為0的問題。
先驗概率p(y=k)為
條件概率p(xi|y=k)為
式中:Ny=k是類別為k的樣本個數;Ny=k,xi是類別為k的樣本中,特征向量為值是xi的樣本個數;α為平滑值。當α=1時,稱作Laplace平滑;當0<α<1時,稱作Lidstone平滑;當α=0時,不做平滑。
3.2 集成分類器
集成分類器是將多個基分類器按照一定策略進行組合而共同決策的分類器。主要包括基分類器間相互依賴的Boosting算法和基分類器間相互獨立的Bagging算法。Boosting通過對樣本集的操作獲得樣本子集,利用樣本子集訓練基分類器,最后通過對基分類器的加權融合獲得集成分類器。Bagging算法是隨機有放回的選擇訓練數據構造基分類器,進行組合得到集成分類器。本文選取基于Bagging的并行集成分類器RF和基于Boosting的串行集成分類器GBDT進行文本分類。
RF使用CART決策樹作為基分類器,同時對決策樹的建立做了改進。傳統決策樹在節點上所有的n個樣本特征中選擇一個最優的特征來做決策樹的左右子樹劃分,RF通過隨機選擇節點上的nsub(nsub≤n)個樣本特征,在這些隨機選擇的子樣本特征中,選擇一個最優的特征來做決策樹的左右子樹劃分。RF進一步增強了模型的泛化能力,避免了過擬合現象的出現。RF主要的調優參數為Bagging框架參數和CART決策樹參數,其中Bagging框架參數包括最大迭代次數等,CART決策樹參數有最大樹深度等。
GBDT又叫MART(Multiple Additive Regression Tree),是一種迭代的決策樹算法,該算法由多棵CART回歸決策樹組成,通過梯度提升算法實現損失函數的優化,最終得到最優的回歸樹。GBDT需要調優的參數較多,主要分為Boosting框架參數和CART樹參數,其中Boosting框架參數包括最大迭代次數、學習步長等,CART決策樹參數有最大樹深度。
3.3 基于Voting的多分類器集成學習
集成學習的基本原理是構造若干個分類精度不高的弱分類器,把各個弱分類器的結果按照一定策略組成一個強分類器,從而解決分類問題。多分類器集成學習的優勢在于,克服了弱分類器現實分類中存在的計算和統計方面的問題,減少分類中存在的位置風險,具有更好的泛化能力。
假設分類器的錯誤率相互獨立,隨著集成中基分類器數目的增大,集成的錯誤率將以指數級下降,最終趨向于零。但在實際任務中,基分類器很難互相獨立。為了選取盡量準確和多樣的集成分類器,本文根據基分類器和集成分類器在樣本數據集上的表現性能,優先選取分類效果最好的分類器進行集成學習,通過最優分類器與其他分類器的加權投票組合,選出表現性能最優的組合集成分類器。該方法的基本流程如圖5所示。
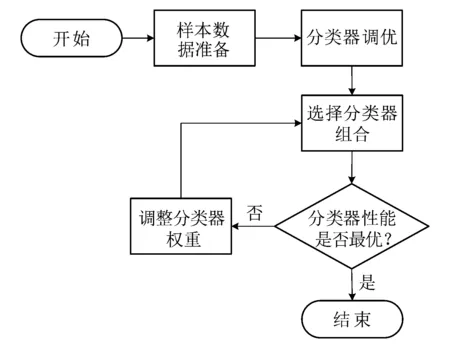
圖5 基于Voting的多分類器集成學習流程
4 試驗分析
本文通過選擇某鐵路局電務段的電務設備不平衡故障文本數據來驗證所提方法的有效性和準確性。試驗數據包含10種故障類別643條數據。本文采取準確率Precision,召回率Recall和F-score作為模型評價和對比的指標。
準確率計算公式為
(15)
召回率計算公式為
F-score計算公式為
式中:TPi為被正確分到此類的實例個數;TNi為被正確識別不在此類的實例個數;FPi為被誤分到此類的實例個數;FNi為屬于此類但被誤分到其他類的實例個數;C表示所有類別的總數。
試驗主要分為兩部分,即不平衡故障文本數據處理試驗分析;基于SMOTE處理后基于Voting的多分類器集成學習故障智能分類試驗分析。
4.1 不平衡故障文本數據處理試驗分析
試驗使用Jieba分詞工具實現電務設備故障文本的分詞,并通過TF-IDF計算權重并進行歸一化,得到試驗文本故障數據的向量表示。為驗證SMOTE處理不平衡數據的故障文本數據效果,通過SVM-SMOTE方法生成了少數類別數據。其中,TDCS設備故障數據由原來的6條自動生成為172條,閉塞設備故障由原來的6條生成為84條,微機聯鎖故障由原來的6條生成為133條,總數據量變為1 014條,見表2。
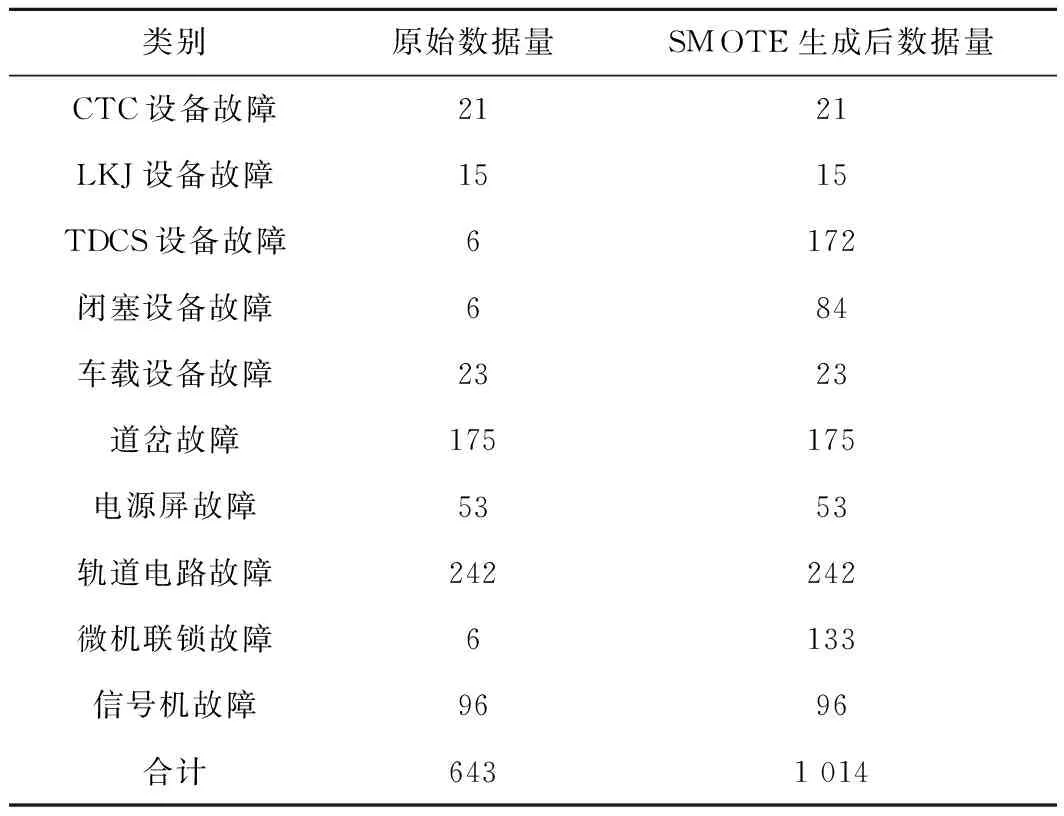
表2 原始數據和SMOTE生成少數類別數據
4.2 故障智能分類試驗分析
試驗選取了常用的傳統基分類器(LR,Multinomial NB和SVM)和集成分類器(RF和GBDT),分別在原始數據集和采用SMOTE處理前后的兩個數據集進行訓練和測試,并通過準確率、召回率、F-score等分類性能指標進行對比分析,從而驗證SMOTE處理不平衡數據的故障文本數據對分類性能的影響。為防止產生過擬合的問題,兩個數據集均隨機選取80%用來訓練分類器,20%作為測試集。
4.2.1 原始文本數據集分類試驗
集成分類器需要根據樣本數據調優才能達到較好的分類效果。試驗通過GridSearchCV進行調優,經過調優后,RF的最佳迭代次數為180次,GBDT的最優迭代次數為180,學習步長為0.3,最優采樣率為0.8。調優后的集成分類器和傳統基分類器的分類結果見表3。
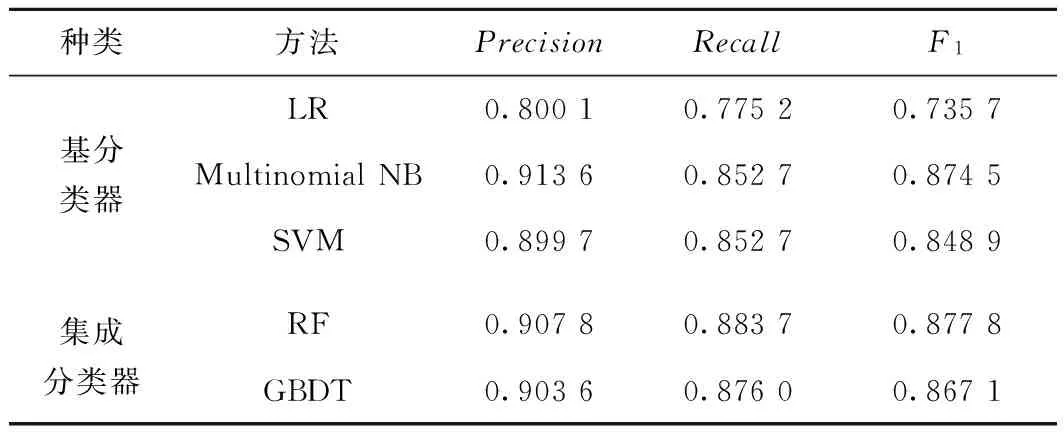
表3 原始數據分類效果
由表3可知,針對極端不平衡的文本數據集,集成分類器的效果略優于基分類器,而基分類器中邏輯回歸的分類效果最差,集成分類器中隨機森林的分類效果最佳。
4.2.2 SMOTE處理后文本數據集分類試驗
在用SMOTE方法對少數類數據進行補足之后,對分類器進行重新訓練和測試。此時集成分類器的RF最優迭代次數為160,GBDT的最優迭代次數為180,學習步長為0.3,最優采樣率為0.6。分類結果見表4。
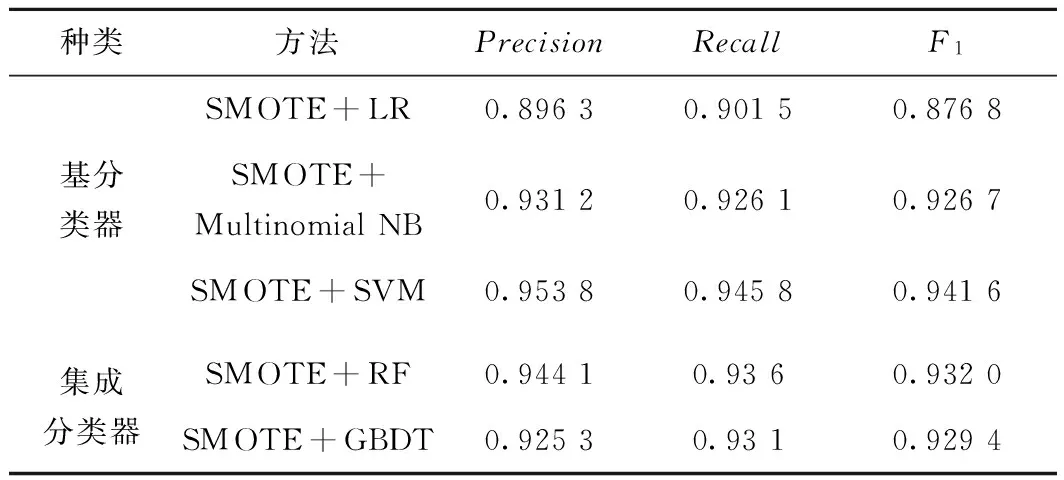
表4 SMOTE生成數后的分類效果
由表4可以看出,經過SMOTE對不均衡故障文本數據處理之后,基分類器和集成分類器的各分類指標均有明顯提高。尤其基分類器中SVM的分類效果有了大幅提升。
4.2.3 SMOTE+Voting集成分類試驗
在上述試驗的基礎上,選取基分類器和集成分類器進行Voting集成學習,其中選擇表現性能最好的SVM分類器與其他4種分類器的組合,通過Voting的方式實現集成學習,得到的分類效果見表5。
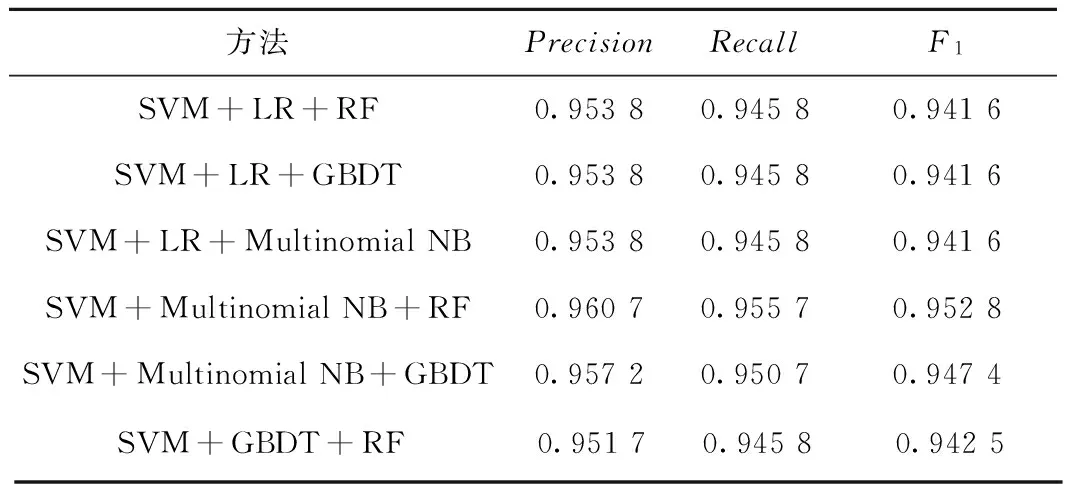
表5 SMOTE+Voting集成分類效果
由表5可以看出,SVM+LR+RF、SVM+LR+GBDT、SVM+LR+Multinomial NB等的組合并沒有提高整體的分類效果,而是和基分類器SVM分類效果一樣。而SVM+Multinomial NB+RF、SVM+Multinomial NB+GBDT、SVM+GBDT+RF的集成學習均比SVM單個分類器的效果要好,尤其SVM+Multinomial NB+RF的性能最佳,準確率、召回率和F-score均有1%的提高。
4.3 試驗總結
根據以上試驗分析,以SVM分類為例,對比其在原始數據集、SMOTE處理后數據集和SMOTE+Voting方法之后的分類性能,如圖6所示。
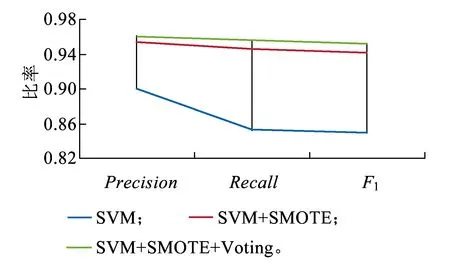
圖6 SVM不同處理方法分類性能比較
由圖6可以看出,針對不平衡故障文本數據,本文提出的SMOTE+Voting的多分類器集成算法在各方面的性能指標最優。說明本文提出的鐵路信號設備智能分類模型算法在處理不平衡樣本的文本數據上具有優勢,可為鐵路電務設置不平衡故障文本數據分類提供參考。
5 結束語
本文通過對鐵路信號設備故障文本數據進行分詞和基于TF-IDF轉換為權重特征向量,實現故障文本數據的向量表示。同時,利用SVM-SMOTE實現鐵路信號設備小類數據的自動生成,從而均衡故障文本數據,提高分類效果。通過邏輯回歸、Multinomial NB、SVM等基分類器以及隨機森林、GBDT等集成分類器,對SMOTE處理后的數據進行訓練和學習,得到最優的分類模型。為提高分類模型的泛化能力,提出基于Voting的多分類器集成學習分類方法。通過對某鐵路局電務段的鐵路信號設備不平衡故障文本數據的試驗,驗證了所提模型的準確性和有效性,為鐵路信號設備智能分類提供了新的思路和解決方案。
參考文獻:
[1]佟立本.鐵道概論[M].7版.北京:中國鐵道出版社,2016.
[2]李佳奇,黨建武.基于MAS電務故障診斷模型的研究[J].鐵道學報,2013,35(2):72-80.
LI Jiaqi,DANG Jianwu.Study on Electric Fault Diagnosis Model Based on MAS[J].Journal of the China Railway Society,2013,35(2):72-80.
[3]DIETTERICH T G.Ensemble Methods in Machine Learning[C]//Mutliple Classifier Systems.Berlin:Springer Berlin Heidelberg,2000:1-15.
[4]TURNEY,PETER D,PANTEL,et al.From Frequency to Meaning:Vector Space Models of Semantics[J].Journal of Artificial Intelligence Research,2010,37(1):141-188.
[5]El-KHAIR I A.TF*IDF[J].Encyclopedia of Database Systems,2009,13(12):3085-3086.
[6]STACHNISS C,GRISETTI G,BURGARD W.Information Gain-based Exploration Using Rao-Blackwellized Particle Filters[C]//Robotics:Science and Systems Conference,2005:65-72.
[7]WANG G,LOCHOVSKY F H.Feature Selection with Conditional Mutual Information Maximin in Text Categorization[C]//Thirteenth ACM International Conference on Information and Knowledge Management.ACM,2004:342-349.
[8]ZHU Y,LI L,LUO L.Learning to Classify Short Text with Topic Model and External Knowledge[C]//International Conference on Knowledge Science,Engineering and Management.Berlin:Springer Berlin Heidelberg,2013:493-503.
[9]MIKOLOV T,CHEN K,CORRADO G,et al.Efficient Estimation of Word Representations in Vector Space[J].Computer Science,2013.
[10]MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed Representations of Words and Phrases and Their Compositionality[C]//International Conference on Neural Information Processing Systems.Nevada:Curran Associates Inc.,2013:3111-3119.
[11]趙陽,徐田華.基于文本挖掘的高鐵信號系統車載設備故障診斷[J].鐵道學報,2015,37(8):53-59.
ZHAO Yang,XU Tianhua.Text Mining Based Fault Diagnosis for Vehicle On-board Equipment of High Speed Railway Signal System[J].Journal of the China Railway Society,2015,37(8):53-59.
[12]李解,王建平,許娜,等.基于文本挖掘的地鐵施工安全風險事故致險因素分析[J].隧道建設,2017,37(2):160-166.
LI Jie,WANG Jianping,XU Na,et al.Analysis of Safety Risk Factors for Metro Construction Based on Text Mining Method[J].Tunnel Construction,2017,37(2):160-166.
[13]HE H,BAI Y,GARCIA E A,et al.ADASYN:Adaptive Synthetic Sampling Approach for Imbalanced Learning[C]//IEEE International Joint Conference on Neural Networks.New York:IEEE,2008:1322-1328.
[14]CHAWLA N V,BOWYER K W,HALL L O,et al.SMOTE:Synthetic Minority Over-sampling Technique[J].Journal of Artificial Intelligence Research,2002,16(1):321-357.
[15]HAN H,WANG W Y,MAO B H.Borderline-SMOTE:a New Over-Sampling Method in Imbalanced Data Sets Learning[J].Lecture Notes in Computer Science,2005,3644(5):878-887.
[16]AGGARWAL C C,ZHAI C.A Survey of Text Classification Algorithms[J].Springer US,2012,45(3):163-222.
[17]BREIMAN L.Random Forests[J].Machine learning,2001,45(1):5-32.
[18]FRIEDMAN J H.Greedy Function Approximation:a Gradient Boosting Machine[J].Annals of Statistics,2001,29(5):1189-1232.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
汽車維修與保養(2019年7期)2020-01-06 03:30:42
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
汽車維護與修理(2016年10期)2016-07-10 08:17:41
小學教學參考(2015年20期)2016-01-15 08:44:38
汽車維修與保養(2015年6期)2015-04-17 03:31:50
