基于深度神經(jīng)網(wǎng)絡(luò)的關(guān)鍵詞識別系統(tǒng)①
2018-05-17 06:46:28孫彥楠夏秀渝
計算機系統(tǒng)應(yīng)用 2018年5期
孫彥楠,夏秀渝
(四川大學(xué) 電子信息學(xué)院,成都 610065)
1 引言
關(guān)鍵詞識別 (Keyword Recognition,KWR)是從自然聲音流中檢測并確認出一個或幾個特定關(guān)鍵詞的技術(shù).其廣泛應(yīng)用于語音檢索、人機交互、語音監(jiān)聽等社會經(jīng)濟生活領(lǐng)域.關(guān)鍵詞識別與一般語音識別最大的不同是關(guān)鍵詞識別時會遭遇大量的集外詞(Out-Of-Vocabulary,OOV),但不需對這些集外詞的內(nèi)在信息作具體的識別.
現(xiàn)階段關(guān)鍵詞識別的方法主要有3種[1]: 1) 利用動態(tài)時間規(guī)整算法基于滑動匹配思想的關(guān)鍵詞檢出方法.它利用滑動窗口在連續(xù)語音流中進行搜索、匹配計算,進而檢出關(guān)鍵詞.這類方法關(guān)鍵詞識全率和識準率均不是很高.2) 利用隱馬爾可夫算法基于垃圾模型的方法.這種方法不僅需要對每個關(guān)鍵詞建模,還需要對多種集外詞(其他音節(jié)、自然聲音等)建立不同模型,即垃圾模型.然后用垃圾模型與關(guān)鍵詞模型共同搭建網(wǎng)絡(luò),最后采用維特比解碼得出結(jié)果.該方法需要一個較為全面的語料庫建模,識準率受關(guān)鍵詞的規(guī)模影響較大,模型訓(xùn)練和識別匹配的運算量巨大,且當(dāng)關(guān)鍵詞發(fā)生變化時需要重新訓(xùn)練模型.3) 基于文本的關(guān)鍵詞檢出方法,該方法通過一個大詞匯量連續(xù)語音識別系統(tǒng)識別待檢音頻,再對結(jié)果進行搜索,最終確定這段被測語音是否包含關(guān)鍵詞.這種方法需要大量的標注數(shù)據(jù)資源.
近幾年以來,少資源或零資源場景下的關(guān)鍵詞識別由于其廣泛的適用性得到廣泛的關(guān)注.少資源或無資源是指缺乏足夠標注的目標樣本語音數(shù)據(jù),并不具備訓(xùn)練一個魯棒的大詞匯量語音識別系統(tǒng)的條件[2].深度神經(jīng)網(wǎng)絡(luò) (Deep Neural Network,DNN) 憑借其無監(jiān)督學(xué)習(xí)的能力在連續(xù)語音識別技術(shù)領(lǐng)域得以廣泛應(yīng)用并取得了相比于以前更好的識別性能.因此,本文針對少資源或零資源情況提出了一種基于自動音頻分割技術(shù)和深度神經(jīng)網(wǎng)絡(luò)的連續(xù)語音流關(guān)鍵詞識別方案.
2 系統(tǒng)原理及方案設(shè)計
2.1 系統(tǒng)總體框架
關(guān)鍵詞識別系統(tǒng)的總體框架如圖1所示.
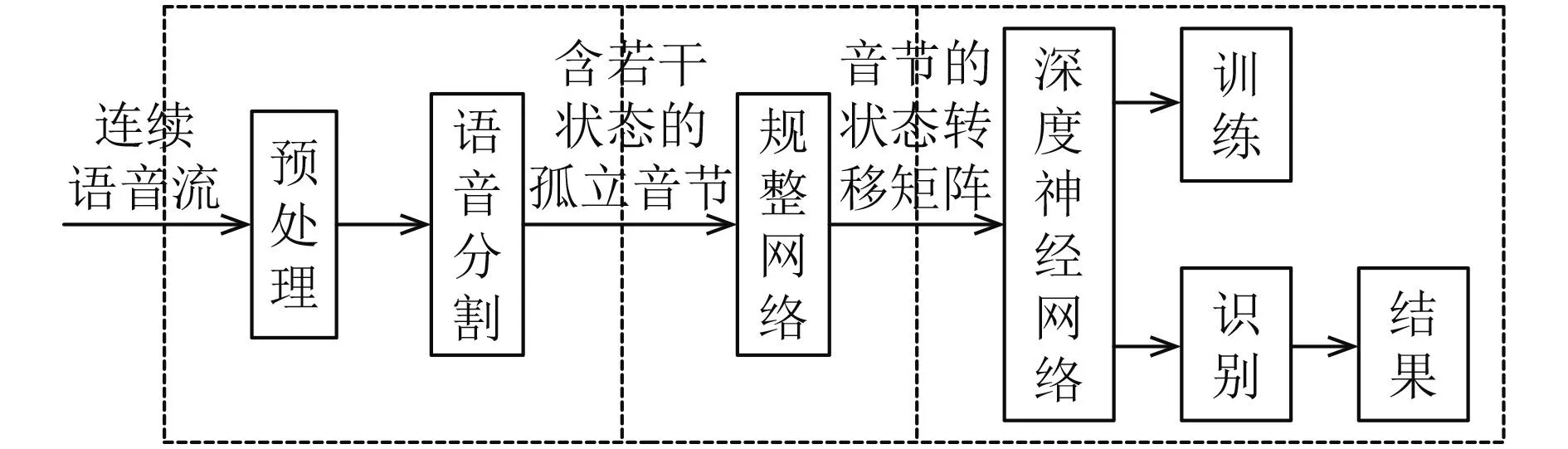
圖1 系統(tǒng)框架
整個系統(tǒng)分為3部分: 1) 語音預(yù)處理及分割模塊,該模塊將連續(xù)語音流自動分割為不同大小的音頻段,涉及有聲無聲段的分割,音節(jié)和音素狀態(tài)的分割等.2) 音節(jié)狀態(tài)轉(zhuǎn)移矩陣生成模塊,該模塊在語音分割模塊輸出結(jié)果的控制下完成音節(jié)參數(shù)特征的提取和時間規(guī)整.3) 基于深度神經(jīng)網(wǎng)絡(luò)的關(guān)鍵詞識別模塊,該模塊分為訓(xùn)練和測試兩個模塊,訓(xùn)練模塊完成網(wǎng)絡(luò)權(quán)值的學(xué)習(xí),測試模塊完成關(guān)鍵詞的識別.
2.2 預(yù)處理及語音分割
針對自然連續(xù)語音流,語音預(yù)處理及分割模塊完成有聲無聲段,音節(jié)和音素的自動分割.具體框圖如圖2所示.

圖2 預(yù)處理及語音分割流程
預(yù)處理包括提升語音高頻部分的預(yù)加重和分幀處理.端點檢測是將語音流中的無聲段去除,只保留有聲部分.目的是減少后續(xù)計算量,同時還可以提高語音識別的正確率.本文使用頻譜方差作為端點檢測的特征參數(shù),該特征參數(shù)在去除靜音和噪聲的同時,可以避免將語音段中的輕音部分認定為是無聲段.采用雙門限判定法[3]來檢測語音,用高門限判斷是不是有聲段,用低門限確定有聲段的起止點位置.
音節(jié)是人類聽覺可以區(qū)分清楚的語音基本單位,在漢語中一個漢字的讀音就代表一個音節(jié).音節(jié)分割模塊將連續(xù)有聲段語音分割成一個個孤立的音節(jié),用于后續(xù)以音節(jié)為聲學(xué)單元的關(guān)鍵詞識別.
觀察語音的語譜圖,我們可以很容易的區(qū)分每一個音節(jié).這是因為音節(jié)作為一個短時音頻段落,其聽覺譜段間差異較大,段內(nèi)差異較小,因此可以采用基于度量距離的算法實現(xiàn)分割.
我們提出一種綜合數(shù)據(jù)段段間均值和方差的度量方法,用來表征音頻段落之間的差異,簡稱為DIS[4,5]:

式(1)中分子表示左右兩段音頻特征各自均值的差異,分母反映兩段音頻特征方差的平均值.當(dāng)兩段音頻之間特征均值差異較大,段內(nèi)特征方差小時,DIS越大,表明兩段音頻段間距離越大.
假設(shè)特征向量參數(shù)各維度獨立,特征維度為D,協(xié)方差矩陣簡化為對角陣,則:

本文特征參數(shù)選用短時能量參數(shù)和12維Mel頻率倒譜系數(shù)共13維.為簡化計算,我們將式(1)就簡化為:

音節(jié)分割分3步完成,分別是計算DIS、取極大值點和分割點確認.具體做法為分窗計算DIS距離值,逐幀滑動得到一系列DIS值,提取距離值曲線上的極大值點,為了消除音頻失真帶來的誤差,兩個極大值點距離很近時只取一個,然后利用閾值判斷其是否為分割點,當(dāng)極大值點的DIS值超過預(yù)設(shè)門限T-DIS時,判斷為分割點,否則舍去.分割點確認后,相鄰分割點間的音頻段落即為音節(jié),為減小信息丟失,采取了重疊分段的思想,左右兩個分割點分別向左向右擴充3幀構(gòu)成最終的分割段.
單個音節(jié)內(nèi)部的聽覺譜相對其他音節(jié)來說差異較小,但仍然可以繼續(xù)細分成更小的段落(比如音素).因此,我們可以繼續(xù)利用公式(3)設(shè)置更小的滑動窗將音節(jié)劃分成差異更加細微的音頻段落,這些段落可能是某個音素,可能是某個音素到靜音之間或者某兩個音素之間的過渡部分.在本文中,我們將其稱之為音素級段基元.音素級段基元雖然長度各不相同,但其內(nèi)部各幀之間狀態(tài)變化很小.本文取其內(nèi)部核心幀的特征參數(shù)均值作為該段音頻的狀態(tài).這樣不僅壓縮了數(shù)據(jù)量簡化了后期的運算量,同時也避免了同一種音節(jié)由于持續(xù)時間不同導(dǎo)致的特征參數(shù)差異較大的問題.
通過以上處理,我們就將連續(xù)語音流分割成一個個含有若干狀態(tài)的獨立音節(jié),同時將連續(xù)語音識別問題轉(zhuǎn)化為包含有未知信息的孤立詞識別問題.
2.3 音節(jié)的狀態(tài)轉(zhuǎn)移矩陣
本文采用音節(jié)作為聲學(xué)識別單元,狀態(tài)轉(zhuǎn)移矩陣作為音節(jié)整體特征被送入后級神經(jīng)網(wǎng)絡(luò)進行識別.生成狀態(tài)轉(zhuǎn)移矩陣的框圖如圖3所示.
經(jīng)過音頻分割,每個音節(jié)可以用少量幾個狀態(tài)的特征參數(shù)表示,為進一步壓縮數(shù)據(jù),可以采用矢量量化對特征參數(shù)進行數(shù)據(jù)壓縮.應(yīng)用聚類算法如K-means算法進行矢量量化時,采用歐式距離作為相似性的評價指標.傳統(tǒng)的矢量量化以數(shù)據(jù)x和碼字Yj(j=1,2,…,N)的最小距離作為唯一評價指標,以此確定區(qū)域邊界,尋找最佳劃分(胞腔).這種方法對所有數(shù)據(jù)進行等精度的量化,但對于關(guān)鍵詞識別來說,只需要識別少量的集內(nèi)詞,對大量的集外詞不需要作具體的識別.如果由所有數(shù)據(jù)(集內(nèi)詞和集外詞)來確定碼字個數(shù),較多的碼字相對于少量的集內(nèi)詞來說過于浪費,而當(dāng)碼字的數(shù)量較少時量化精度得不到保證,集內(nèi)詞之間就會缺乏區(qū)分性.對于關(guān)鍵詞識別,我們希望集內(nèi)詞之間有較高的量化精度,同時總的碼字數(shù)量較少,所以本文提出了一種改進型的矢量量化方法.

圖3 狀態(tài)轉(zhuǎn)移矩陣形成簡圖
改進型矢量量化的碼書生成只采用關(guān)鍵詞數(shù)據(jù)(集內(nèi)詞)進行訓(xùn)練,獲取有意義的精度較高的碼書.確定各胞腔的最佳區(qū)域邊界采用了兩個評價指標,分別是: 數(shù)據(jù)x和碼字Yj(j=1,2,…,N)間最小的距離值Dmin,碼字Yj(j=1,2,…,N)空間大小T.最佳區(qū)域邊界的確定必須滿足以下兩個公式:

語音信號的特征參數(shù)每一維可以近似看作高斯分布[6],我們依據(jù)3σ準則來確定距離范圍,取胞腔內(nèi)所有數(shù)據(jù)的碼字距離標準差的三倍T3σ作為距離范圍指標.本文實驗發(fā)現(xiàn),只要訓(xùn)練使用的關(guān)鍵詞音節(jié)樣本數(shù)量足夠,最后得到的每個碼字的邊界大小T3σ大致相同.
圖4 為傳統(tǒng)矢量量化與改進型矢量量化胞腔邊界的比較圖.
矢量量化的具體過程如下: 對于測試用關(guān)鍵詞數(shù)據(jù)或集外詞數(shù)據(jù),先計算其特征參數(shù)和各碼字的歐式距離并確定最小距離,然后再判斷該最小距離值是否在T3σ范圍內(nèi),若滿足條件則將其歸屬為某一個高精度有意義的量化中心.如果超出該范圍,則認定其不屬于該碼書所在的胞腔,將此種情況下的特征參數(shù)全部另歸為其他一類,也就是由集外詞等垃圾信息確定的一個低精度碼字.

圖4 傳統(tǒng)矢量量化與改進型矢量量化的比較
這種改進型的矢量量化只對關(guān)鍵詞相關(guān)特征參數(shù)敏感,對無關(guān)音節(jié)的特征參數(shù)不敏感,保證了關(guān)鍵詞的量化精度,滿足識別要求的同時大大減小了矢量量化的工作量.
語音具有時變性,不同字發(fā)音不同,不同人或同一人在不同環(huán)境下讀同一個字的發(fā)音都不同,包括聲音大小,重音位置,持續(xù)時間都有所不同.音頻信號的豐富變化使得一個音節(jié)的音頻特征參數(shù)序列的長度是可變的,而大多數(shù)神經(jīng)網(wǎng)絡(luò)要求輸入數(shù)據(jù)的結(jié)構(gòu)固定[7].為了反映語音時變特征同時適應(yīng)神經(jīng)網(wǎng)絡(luò)輸入的要求,本文將特征參數(shù)序列通過時間規(guī)整網(wǎng)絡(luò)轉(zhuǎn)換為狀態(tài)轉(zhuǎn)移矩陣,狀態(tài)轉(zhuǎn)移矩陣能反映語音信號時變特征且維數(shù)固定.
通過前面矢量量化,將關(guān)鍵詞音素級段基元的特征參數(shù)歸屬于某個確定碼字(音素狀態(tài)),這樣每一個音節(jié)都對應(yīng)為一個狀態(tài)序列O={O1,O2,…,ON}.N是一個音節(jié)音素狀態(tài)的總數(shù)量,Oi是第i(i=1,2,…,N)個狀態(tài)的標號,Oi的最大值為碼本個數(shù)K.時間規(guī)整網(wǎng)絡(luò)的輸出是一個K×K的矩陣,在文本,我們用TRM(m,n)代表輸出矩陣第m行第n列的元素(m=1,2,…,K;n=1,2,…,K).定義:

則:

公式(5)反映了音節(jié)內(nèi)任意兩個相鄰狀態(tài)的狀態(tài)轉(zhuǎn)移情況,通過公式(6)映射到輸出矩陣TRM對應(yīng)的坐標(節(jié)點)上,統(tǒng)計音節(jié)所有狀態(tài)轉(zhuǎn)移的情況得到最終的輸出矩陣.通過這種方式,就可以將長度不同的音節(jié)規(guī)整為格式統(tǒng)一的狀態(tài)轉(zhuǎn)移矩陣.
狀態(tài)轉(zhuǎn)移矩陣作為音節(jié)的整體特征矢量可以直接饋入下一級神經(jīng)網(wǎng)絡(luò)完成語音識別,但這樣一個多達2500維的輸入依然顯得過于龐大.因為每個音節(jié)只有2~7個狀態(tài),所以每個音節(jié)的狀態(tài)轉(zhuǎn)移矩陣是一個稀疏矩陣,其大多數(shù)節(jié)點的值為0.觀察圖5所有訓(xùn)練用關(guān)鍵詞音節(jié)的狀態(tài)轉(zhuǎn)移矩陣累加圖,我們發(fā)現(xiàn)大多節(jié)點的響應(yīng)很小甚至為0,這也就意味著,對關(guān)鍵詞識別來說,這些節(jié)點是多余的,其輸出不需要送入下級網(wǎng)絡(luò).因此,我們通過設(shè)定閾值篩選出有用的節(jié)點,以減少后續(xù)神經(jīng)網(wǎng)絡(luò)的規(guī)模.本文通過這種方式篩選出157個節(jié)點,后續(xù)神經(jīng)網(wǎng)絡(luò)的規(guī)模大大減小了.

圖5 所有訓(xùn)練用關(guān)鍵詞音節(jié)的狀態(tài)轉(zhuǎn)移矩陣累加圖
本節(jié)以音節(jié)為識別單位,生成壓縮的狀態(tài)轉(zhuǎn)移矩陣作為音節(jié)的整體特征,該特征反映了語音的部分時序特性,同時完成了音節(jié)的時間規(guī)整.音節(jié)的狀態(tài)轉(zhuǎn)移矩陣將作為后續(xù)識別神經(jīng)網(wǎng)絡(luò)的輸入.
2.4 基于深度神經(jīng)網(wǎng)絡(luò)的語音識別
深度神經(jīng)網(wǎng)絡(luò)是一個有輸入層,超過兩個的隱層和輸出層的非線性轉(zhuǎn)換單元的多層感知器[8],如圖6所示.與“淺層”神經(jīng)網(wǎng)絡(luò)相比,深度神經(jīng)網(wǎng)絡(luò)擁有更強大的建模和表征能力,能夠?qū)崿F(xiàn)復(fù)雜函數(shù)的逼近.本文選用深度神經(jīng)網(wǎng)絡(luò)作為語音識別模塊,可以有效提高系統(tǒng)分類識別性能.
深度學(xué)習(xí)是針對模型具有“深層”結(jié)構(gòu)的網(wǎng)絡(luò)權(quán)值學(xué)習(xí)算法,能夠有效解決僅采用反向傳播算法所造成的訓(xùn)練容易陷于局部最優(yōu)解的問題,解決深層網(wǎng)絡(luò)無法調(diào)整到神經(jīng)網(wǎng)絡(luò)低層參數(shù)而出現(xiàn)的性能急劇下降的問題,可以有效的抑制訓(xùn)練過程中的過擬合現(xiàn)象等.深度學(xué)習(xí)核心的內(nèi)容就是利用無監(jiān)督性的學(xué)習(xí),消除信號中的冗余信息,提煉具有高效分類能力的特征,提高算法的識別率.常用的深度神經(jīng)網(wǎng)絡(luò)模型有深度信念網(wǎng)絡(luò) (Deep Belief Network,DBN)、卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)、稀疏自編碼器(Sparse Auto-Encoder,SAE)[9]等模型,這些模型試用于不同的數(shù)據(jù).深度信念網(wǎng)絡(luò)是一個概率生成模型,其目的在于建立觀察數(shù)據(jù)和標簽之間的聯(lián)合分布,對于本文這種比較稀疏的數(shù)據(jù),學(xué)習(xí)容易收斂于局部最優(yōu)解.卷積神經(jīng)網(wǎng)絡(luò)是人工神經(jīng)網(wǎng)絡(luò)的一種,它的權(quán)值共享網(wǎng)絡(luò)結(jié)構(gòu)降低了網(wǎng)絡(luò)模型的復(fù)雜度,減少了權(quán)值的數(shù)量.但其在語音識別中,通常使用若干幀梅爾倒譜系數(shù)作為數(shù)據(jù),有利于解決語音的時變性問題、降低學(xué)習(xí)復(fù)雜復(fù).稀疏自編碼器試圖找出每組輸入數(shù)據(jù)的類似于線性代數(shù)中基的概念的一組基的線性組合,所以其對較為稀疏的數(shù)據(jù)有著學(xué)習(xí)過程快,學(xué)習(xí)性能優(yōu)異且穩(wěn)定的特點.因此本文選用稀疏自編碼器作為進行語音識別的模型.

圖6 深度神經(jīng)網(wǎng)絡(luò)簡圖
稀疏編碼算法是一種無監(jiān)督學(xué)習(xí)方法,其本質(zhì)是本文上節(jié)提到的K-means算法的變體,它尋找一組“超完備”基向量來更高效地表示樣本數(shù)據(jù).超完備基的好處是它們能更有效地找出隱含在輸入數(shù)據(jù)內(nèi)部的結(jié)構(gòu)與模式[10].稀疏自編碼器的結(jié)構(gòu)如圖7所示,稀疏自編碼器在自編碼器的基礎(chǔ)上對網(wǎng)絡(luò)編碼層輸出進行約束,僅有少部分節(jié)點處于激活狀態(tài),其余節(jié)點均處于未激活狀態(tài).用最少個數(shù)的編碼層神經(jīng)元輸出來表示輸入數(shù)據(jù),對數(shù)據(jù)進行降維.它利用低階特征進行線性稀疏組合成高階特征來表征原有信號,篩選出信號中的顯著性原子,這對提高語音識別的識別率具有重要意義.

圖7 稀疏自編碼器
本文利用深度稀疏自動編碼機神經(jīng)網(wǎng)絡(luò)進行語音識別,步驟如下:
a) 提取訓(xùn)練語音的音節(jié)狀態(tài)轉(zhuǎn)移矩陣,將其作為網(wǎng)絡(luò)輸入訓(xùn)練第一個編碼層的網(wǎng)絡(luò)參數(shù).并將訓(xùn)練好的編碼數(shù)據(jù)作為第一編碼層的輸出.
b) 把步驟a)的輸出作為輸入,用同a)一樣的方法訓(xùn)練第二編碼層的網(wǎng)絡(luò)參數(shù).類似的方式可以逐層訓(xùn)練出更多的隱層參數(shù).
c) 把步驟b)的最后一級隱層輸出作為Softmax回歸模型的輸入,然后利用原始數(shù)據(jù)的標簽(硬分類為某個關(guān)鍵詞或者為集外詞)監(jiān)督性訓(xùn)練得到Softmax分類器.
d) 級聯(lián)稀疏自動編碼機和Softmax分類器,生成全局網(wǎng)絡(luò).計算整個網(wǎng)絡(luò)的誤差函數(shù)及其對各個參數(shù)的編導(dǎo)值,更新權(quán)值.
e) 采用LBFGS算法進行整個網(wǎng)絡(luò)的權(quán)值優(yōu)化計算,通過誤差反向傳播算法微調(diào)網(wǎng)絡(luò)參數(shù),提高分類器的精準性.
f) 將測試數(shù)據(jù)的狀態(tài)轉(zhuǎn)移矩陣送入到訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)中進行識別測試.
本節(jié)以音節(jié)的壓縮狀態(tài)轉(zhuǎn)移矩陣作為神經(jīng)網(wǎng)絡(luò)的輸入,使用稀疏自編碼器組合低階特征組完成信號高階特征表示,然后使用Softmax分類器分類識別多個關(guān)鍵詞和集外詞.該算法操作簡單,不同關(guān)鍵詞特征區(qū)分明顯.
3 系統(tǒng)實現(xiàn)及實驗分析
3.1 實驗設(shè)計
本文的音頻數(shù)據(jù)由3部分構(gòu)成,第1組數(shù)據(jù)由微機上的聲卡在實驗室采集,7男3女共10人分別用慢語速,正常語速和快語速連續(xù)錄入普通話朗讀0~9共10個音節(jié),每人每種語速重復(fù)兩遍共60組數(shù)據(jù),30組用于訓(xùn)練,另外30組用于識別測試; 第2組數(shù)據(jù)是用于建立垃圾模型只包含集外詞的語音流、非語言語音流(雷鳴聲、鳥叫、貓叫等自然界聲音和人發(fā)出的咳嗽、喘氣等)共 10 段,每段平均長度為 3 min; 第 3 組數(shù)據(jù)是采集于廣播傳媒,包括含有普通話數(shù)字0~9和集外詞的語音流共30段(每段時長平均為10 min).3組數(shù)據(jù)采樣頻率均為8000 Hz.

在進行矢量量化之前需要對樣本特征作歸一化處理,本文利用公式(7)進行倒譜均值歸一化(CMN)[9],以減弱潛在的聲學(xué)信道扭曲帶來的影響.
公式(7)將每一個維度i的特征O歸一化為均值為0的實數(shù)特征,其中分別表示某幀第i維歸一化后的特征參數(shù)、原始參數(shù)、均值.
首先利用我們提出的音頻分割方法將音頻數(shù)據(jù)分割成孤立音節(jié); 接著利用微機采集的關(guān)鍵詞數(shù)據(jù)(第1組中的訓(xùn)練數(shù)據(jù))訓(xùn)練得到碼書,得到50個量化中心,利用訓(xùn)練好的碼書就可以對第1組中的測試數(shù)據(jù)、第2組數(shù)據(jù)和第3組數(shù)據(jù)的每個音節(jié)狀態(tài)進行矢量量化了; 最后,利用歸整網(wǎng)絡(luò)得到每個音節(jié)的狀態(tài)轉(zhuǎn)移矩陣,壓縮后共抽取157維構(gòu)成神經(jīng)網(wǎng)絡(luò)的輸入.
神經(jīng)網(wǎng)絡(luò)輸入層結(jié)點為157個,2個隱含層神經(jīng)元節(jié)點數(shù)量依次為80,40,輸出層神經(jīng)元節(jié)點數(shù)量為11(10個節(jié)點表示10種關(guān)鍵詞,另外1個節(jié)點表示集外詞),學(xué)習(xí)率為 0.8e–4.
3.2 語音分割實驗
1) 連續(xù)語音流的音節(jié)分割
首先利用雙門限判定法檢測語音起止點,結(jié)果如圖8所示.

圖8 普通話“9月27日星期二”的端點檢測
圖8中實線表示有聲段起始時刻,虛線表示有聲段終止時刻.然后對有聲段進行音節(jié)分割,結(jié)果如圖9所示.
圖9中在語音波形圖和語譜圖中虛線代表人工分割的位點,實線代表DIS算法分割的位點.使用觀測窗長分別為4、7、9幀的DIS值按照0.2、0.5、0.3的加權(quán)系數(shù)加權(quán)求合,確定用于音節(jié)分割的綜合DIS值,根據(jù)綜合DIS值的平均值確定預(yù)設(shè)門限T-DIS,根據(jù)T-DIS在極大值中尋找分割點.由圖9可見,DIS算法的音節(jié)分割點和人工分割點基本吻合.

圖9 普通話“9月27日星期二”的音節(jié)標注
我們以人工標注點為基準,分析了音節(jié)自動分割的效果.采用兩個評價指標: 音節(jié)分割率和音節(jié)分割精準度.
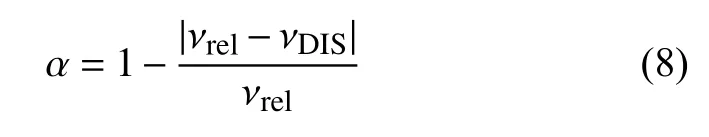
音節(jié)分割率α定義為:νrel表示人工標注分割的音節(jié)數(shù)目,νDIS表示DIS算法分割的音節(jié)數(shù)目.
音節(jié)劃分的精準度β定義為:

Tsk,Tek,Eck分別表示人工標注的第k個音節(jié)的開始時間、結(jié)束時間和持續(xù)時長.分別表示DIS分割算法的第k個音節(jié)的開始時間、結(jié)束時間,M表示實際音節(jié)的個數(shù).
統(tǒng)計的結(jié)果如表1所示.第1組數(shù)據(jù)是在安靜的實驗室環(huán)境下錄制的普通話數(shù)字0~9,可以代表傳統(tǒng)意義的孤立詞.第2組數(shù)據(jù)為廣播傳媒包含有普通話數(shù)字0~9和集外詞的語音流.
實驗表明,DIS分割算法能夠比較有效的將語音流中的音節(jié)單獨分割開來.
2) 音節(jié)內(nèi)部的狀態(tài)分割
利用DIS算法,采用大小為4幀的分析窗,還可進一步將音節(jié)分割為不同的音素狀態(tài).圖10為數(shù)字7的音素狀態(tài)分割情況.

表1 DIS 算法音節(jié)分割效果

圖10 數(shù)字 7 的 DIS 分割圖
從圖10可見,每個音節(jié)內(nèi)部聽覺譜隨時間還是有所變化,通過DIS算法將音節(jié)進一步細分為音素級段基元,段基元內(nèi)部各幀狀態(tài)變化很小.
3.3 孤立詞(集內(nèi)詞)識別實驗
利用語音分割算法將連續(xù)語音流分割成孤立的音節(jié),就可以用類似孤立詞識別的方法進行關(guān)鍵詞(集內(nèi)詞)識別了,本文基于神經(jīng)網(wǎng)絡(luò)進行語音識別.語音特征參數(shù)送入神經(jīng)網(wǎng)絡(luò)時,需要進行時間規(guī)整處理[11,12],采用語音信號處理中常見的非線性時間規(guī)整方法,以各幀參數(shù)間歐式距離作為參考量,將音節(jié)特征參數(shù)序列規(guī)整為固定的幀數(shù),作為神經(jīng)網(wǎng)絡(luò)的輸入.本組實驗進行集內(nèi)詞(1~9)識別實驗.首先通過人工分割或DIS自動分割出第1組和第3組數(shù)據(jù)中所有的集內(nèi)詞,然后使用第1組中的訓(xùn)練數(shù)據(jù)進行訓(xùn)練,使用第1組中的識別測試數(shù)據(jù)和第3組中的集內(nèi)詞數(shù)據(jù)進行識別測試.
表2比較了基于人工分割和DIS自動分割的音節(jié)識別結(jié)果,對比了最小距離時間規(guī)整法和本文時間規(guī)整算法的語音識別結(jié)果,其中語音識別均采用深度神經(jīng)網(wǎng)絡(luò)完成.

表2 集內(nèi)詞識別結(jié)果 (單位: %)
實驗結(jié)果表明,在人工分割的情況下,本文方法和經(jīng)典的最小距離法都可以克服不同說話人的干擾,具有較高的識別率,二者均能夠良好的發(fā)揮深度神經(jīng)網(wǎng)絡(luò)的優(yōu)勢.而在DIS自動分割的情況下,由于分割是存在誤差的,導(dǎo)致經(jīng)典的最小距離法識別率迅速下降,而本文方法由于時間規(guī)整網(wǎng)絡(luò)采用了狀態(tài)轉(zhuǎn)移矩陣,比較好的保持了關(guān)鍵狀態(tài)轉(zhuǎn)移信息,識別率下降不多,對音節(jié)分割不精確表現(xiàn)出良好的魯棒性.
3.4 關(guān)鍵詞識別實驗
關(guān)鍵詞識別是從自然聲音流中檢測并確認出特定的關(guān)鍵詞.本組實驗基于第3組數(shù)據(jù)完成,關(guān)鍵詞為0~9.與2.3節(jié)不同的是,關(guān)鍵詞識別時會遭遇大量的集外詞,這些詞不需具體識別,但需和關(guān)鍵詞相區(qū)別,所以相比實驗二神經(jīng)網(wǎng)絡(luò)的輸出端新增了一個輸出端代表集外詞.
在關(guān)鍵詞識別技術(shù)領(lǐng)域,常使用以下指標對系統(tǒng)性能進行評價:

基于第3組數(shù)據(jù),關(guān)鍵詞識別結(jié)果如表3.

表3 關(guān)鍵詞識別結(jié)果
實驗結(jié)果表明,相比于大詞匯量的語音識別系統(tǒng),本文關(guān)鍵詞識別方法得益于改進的矢量量化運用,系統(tǒng)開銷大大降低,而識別性能尚可.音頻自動分割技術(shù)和狀態(tài)轉(zhuǎn)移規(guī)整網(wǎng)絡(luò)解決了音頻動態(tài)特征的表達問題,再結(jié)合深度神經(jīng)網(wǎng)絡(luò)強大的分類能力,系統(tǒng)花費的時間更短,費效比更低.本文關(guān)鍵詞識別方法受說話人的影響較小,在沒有使用第3組中說話人數(shù)據(jù)訓(xùn)練的情況下而對其識別(少資源場景),對第3組數(shù)據(jù)中的關(guān)鍵詞具有較高的識別率.
4 結(jié)論
本文提出了一種易于對接神經(jīng)網(wǎng)絡(luò)的關(guān)鍵詞識別方法.首先利用DIS算法將語音流分割成獨立的音節(jié),然后通過規(guī)整網(wǎng)絡(luò)找到能反映音頻信號動態(tài)信息的特征參數(shù),較為準確的描述了關(guān)鍵詞的語義信息.深度神經(jīng)網(wǎng)絡(luò)算法簡便易用,識別結(jié)果較為準確,時間花費度比較低,可適于多種規(guī)模的關(guān)鍵詞和集外詞情況.實驗結(jié)果表明,本文所展示的系統(tǒng)可以在少資源或者零資源(low or zero-resource)場景下較為準確在自然語音流的識別出多個特定關(guān)鍵詞,降低了說話人口音的影響,且當(dāng)集外詞的規(guī)模增大時,識全率和識準率只有很小的下降,具有較好的魯棒性.
參考文獻
1Xu H,Yang P,Xiao X,et al.Language independent queryby-example spoken term detection using N-best phone sequences and partial matching.Proceedings of 2015 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).South Brisbane,Queensland,Australia.2015.5191–5195.
2Chan W,Jaitly N,Le Q,et al.Listen,attend and spell: A neural network for large vocabulary conversational speech recognition.Proceedings of 2016 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).Shanghai,China.2016.4960–4964.
3宋知用.MATLAB在語音信號分析與合成中的應(yīng)用.北京: 北京航空航天大學(xué)出版社,2013.
4孫衛(wèi)國,夏秀渝,喬立能,等.面向音頻檢索的音頻分割和標注研究.微型機與應(yīng)用,2017,36(5): 38–41.
5Kamper H,Jansen A,Goldwater S.A segmental framework for fully-unsupervised large-vocabulary speech recognition.Computer Speech & Language,2017,(46): 154–174.
6Bahdanau D,Chorowski J,Serdyuk D,et al.End-to-end attention-based large vocabulary speech recognition.Proceedings of 2016 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Shanghai,China.2016.4945–4949.
7Sharma P,Abrol V,Sao AK.Deep-sparse-representationbased features for speech recognition.IEEE/ACM Transactions on Audio,Speech,and Language Processing,2017,25(11): 2162–2175.
8Hinton G,Deng L,Yu D,et al.Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups.IEEE Signal Processing Magazine,2012,29(6): 82–97.
9Goodfellow I,Bengio Y,Courville A.Deep learning.Cambridge,MA: The MIT Press,2016.
10Yu D,Deng L.Automatic speech recognition: A deep learning approach.New York,NY,USA: Springer Publishing Company,2015.
11張欣,夏秀渝,王雪君.一種聽覺顯著圖提取模型.四川大學(xué)學(xué)報 (自然科學(xué)版),2014,51(2): 292–298.
12侯靖勇,謝磊,楊鵬,等.基于 DTW 的語音關(guān)鍵詞檢出.清華大學(xué)學(xué)報 (自然科學(xué)版),2017,57(1): 18–23.
