基于Hadoop的協同過濾并行化算法①
2018-05-17 06:47:36謝穎華
計算機系統應用 2018年5期
關鍵詞:用戶
曹 霞,謝穎華
(東華大學 信息科學與技術學院,上海 201620)
1 引言
隨著互聯網的快速發展,推薦系統越來越受到大家的關注,很多人都開始研究如何優化推薦系統.更有很多電子商務平臺也在開始使用推薦系統,比如說Amazon、淘寶、京東,以及各種我們現在使用的手機軟件APP,隨處可見的推薦系統.
協同過濾算法主要分為兩種類型,一種是基于項目(item)的協同過濾,一種是基于用戶(user)的協同過濾[1].如今這兩種已經不能滿足各類網站的推薦效率,有很多人陸續提出了對協同過濾算法的改進方法.如有人提出基于聚類模型的協同過濾算法[2],原理就是用聚類對user或item分組,然后用協同過濾算法是對一件item評分,將評分最高的item推薦給user.還有人提出了基于用戶的Hadoop協同過濾算法[3],也就是本文將進行詳細描述的思想.更有人提出的基于ALS(Alternating Least Squares)的協同過濾[4],ALS算法是基于矩陣分解的協同過濾算法中的一種,在Soven的oryx框架中,推薦算法便是采用的這種算法.
隨著海量信息的暴增,數據沒有辦法能夠很好地儲存和計算,這個時候就需要我們對推薦算法做一些改進.不光對算法本身做出優化,也要在運行平臺上做出很大的變化,這時我們就加入了Hadoop平臺.正如我們所知道的,其實一直以來我們的協同過濾算法都是以單機的形式來運行的,這在某種程度上就會影響運行速率,隨著數據的增多,也越來越不能滿足如此大量數據的運算.因此本文提出基于Hadoop這樣的云平臺來實現基于用戶的協同過濾的并行化.因此多機形式下運行推薦算法成為推薦算法研究中一個新的研究方向.
本文將傳統的協同過濾在Hadoop平臺下實現并行化,也就是基于MapReduce的推薦過程,各個部分功能分模塊開發,互不影響,從而方便地進行推薦算法的擴展.
2 相關概念
2.1 關于協同過濾
協同過濾算法的推薦主要有5步,第一步為根據原理建立評分模型,第二步為選出可作為模型中的中間標準項目,第三步是根據公式計算中間項目的最近鄰居項目集,第四步是從最近項目集選出最優解,第五步是推薦完成.本文采用普遍應用的統計學的準確性度量——平均絕對誤差(MAE)以及單機運行時間和Hadoop集群運行時間的加速比.
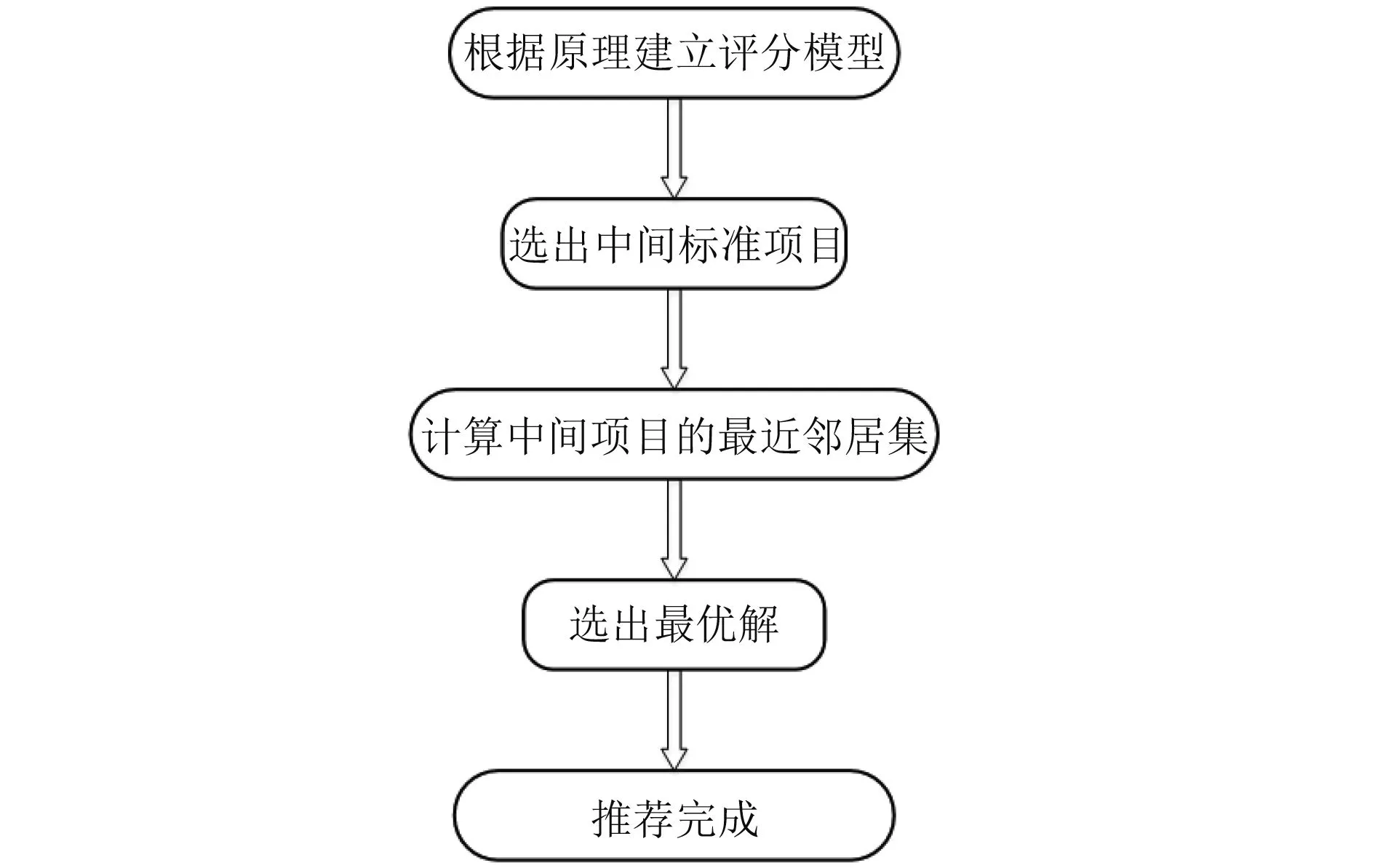
圖1 協同過濾推薦算法流程圖
上面已經提到過,協同過濾算法的推薦過程分以上5個過程這五步當中最重要的就是第三步,也就是最近鄰居集的計算.一般常見的相似性度量方法有三種: 皮爾遜(Pearson)相關相似性、余弦相似性、修正的余弦相似性等,下面依次介紹這3種度量方法.
(1) 皮爾遜相關相似性
皮爾遜相關相似性是度量兩個變量的線性相關性的方法,計算公式[5]如下:

其中表示用戶m和用戶n共同評分的項目集合,分別表示用戶n和用戶m對項目p的評分;則分別代表用戶n和用戶m對系統中所有項目的評分均值.
(2) 余弦相似性
在協同過濾中,用戶的評分向量是用戶的興趣描述,通過計算兩用戶的評分向量之間的夾角余弦來度量用戶的相似度.計算公式[5]如下:

(3) 修正的余弦相似性
在實際的推薦系統中,對同一項目,用戶的評分尺度可能不同.修正的余弦相似度將該問題考慮在內,通過用戶的評分均值來消除評分尺度的不同.計算公式[5]如下:

2.2 關于MapReduce編程模型
Hadoop是Apache軟件基金會旗下的一個開源分布式計算平臺,以HDFS和MapReduce為兩大核心.MapReduce是一種編程模型,用于大規模數據集(大于1 TB)的并行運算.當前的軟件實現是指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定并發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共享相同的鍵組.
一個Map/Reduce作業(job)通常會把輸入的數據集切分為若干獨立的數據塊,由Map任務(task)以完全并行的方式處理它們.框架會對Map的輸出先進行排序,然后把結果輸入給Reduce任務.通常作業的輸入和輸出都會被存儲在文件系統中.整個框架負責任務的調度和監控,以及重新執行已經失敗的任務.
通常,MapReduce框架和分布式文件系統是運行在一組相同的節點上的,也就是說,計算節點和存儲節點通常在一起.MapReduce框架由一個單獨的master JobTracker和每個集群節點一個slave TaskTracker共同組成.master負責調度構成一個作業的所有任務,這些任務分布在不同的slave上,master監控它們的執行,重新執行已經失敗的任務.而slave僅負責執行由master指派的任務.應用程序至少應該指明輸入/輸出的位置(路徑),并通過實現合適的接口或抽象類提供map和reduce函數.再加上其他作業的參數,就構成了作業配置 (job configuration).然后,Hadoop 的 job client提交作業(jar包/可執行程序等)和配置信息給JobTracker,后者負責分發這些軟件和配置信息給slave、調度任務并監控它們的執行,同時提供狀態和診斷信息給job client.
3 基于 Hadoop 的協同過濾算法
3.1 算法原理
Hadoop是一個開源的分布式計算開源框架,它提供了分布式文件系統 (Hadoop Distributed File System,HDFS)和支持MapReduce分布式計算的軟件架構.MapReduce框架的計算過程分為Map和Reduce兩個階段.在MapReduce作業中,輸入的數據集被切分為若干獨立的數據塊,先由Map任務并行處理,對Map的輸出數據排序后,再作為輸入數據交由Reduce任務處理,最終輸出計算結果.每個階段的輸入輸出數據格式是
基于MapReduce的協同過濾,這時就需要我們輸入用戶—項目評分測試集M,項目聚類集合C以及聚類中心c0,最后得出推薦結果.用戶-項目評分矩陣如下圖,假設有n個項目和m個用戶,rij就是用戶j對第i個項目的評分,以此類推[6].
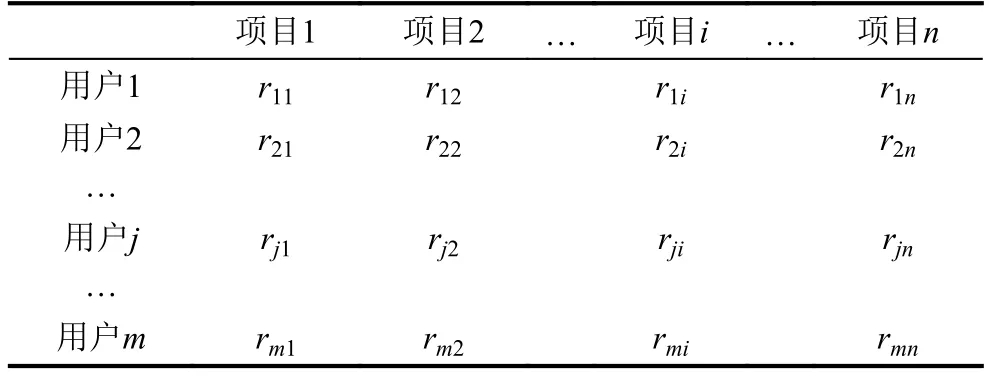
表1 用戶-項目評分矩陣
步驟如下:
(1) 根據上面所提到的公式,我們將矩陣中要計算的項目與我們所選好的目標項目c0進行計算得到s結果.
(2) 將計算出來的s與我們設定好的相似性閾值比較,把相似度大于等于相似性閾值的項目放到一個集合W中.
(3) 在W中進行我們的最后一步,基于Hadoop平臺上的MapReduce分塊計算.系統自動將一個作業待處理的大數據劃分為很多個數據塊,每個數據塊對應于一個計算任務,并自動調度計算節點來處理相應的數據塊.作業和任務調度功能主要負責分配和調度計算節點(Map節點或Reduce節點),同時負責監控這些節點的執行狀態,并負責Map節點執行的同步控制,這樣就可以實現協同過濾的并行化.

圖2 推薦過程流程圖
3.2 基于MapReduce的協同過濾算法
本文研究的用戶-類矩陣中的數據反映了用戶對項目的喜愛程度,但是其中的數據可能會有一定的差異,所以基于MapReduce就在一定程度上可以解決這個問題.并且可以計算用戶相似度,可以查找領居,進行興趣推薦,那么就需要多輪MapReduce任務.
(1) 第1輪Map任務: 原始的用戶數據處理后會統一存放在HBase數據庫的信息表中,這里面會有一系列的用戶對項目的評分.Map任務是將用戶的評分信息讀取出來 (String),以
(2) 第1輪Reduce任務: 此任務的輸入就是上面Map 的輸出,形式為
(3) 第2輪Map任務: 此任務的輸入也是上一任務的輸出,分別以
(4) 第 2輪Reduce任務: 此任務的輸入是
(5) 第3個MapReduce任務: 這個任務是對上一個MapReduce的結果做出整理,計算用戶相似度以及鄰居,并且進行排序,然后得到我們想要的矩陣集合.
(6) 第4個 MapReduce任務: 該任務是結合信息表中的信息和上一任務計算的用戶相似度和鄰居,輸出<(UserID + ClassID),(Rating + Similarity)>,然后完成預測評分.
(7) 第5個MapReduce: 對最終的數據進行排序,通過找到預測評分最高的k個類得出推薦結果.
3.3 預測評分原理
在協同過濾最后一步就是產生推薦,推薦的過程中要對用戶未評分的項目進行預測,預測的方法如下,我們可以用公式表示[7]:

其中u表示用戶,i表示未被用戶評分過的項目,n為與項目i相似的項目,N是與項目i相似的項目集合.
上面公式中我們將進行一個矩陣的乘法,在基于MapReduce框架中,我們要先對矩陣分塊處理,使得不同模塊在不同節點進行處理,因此在利用預測評分公式前需要對輸入的向量進行預處理,會調用到Mahout API中的partialMultiply接口,這個將會啟動了兩個Map任務和一個Reduce任務.
第一個Map負責讀取訓練集的用戶向量.主要是讀取關鍵字為用戶編號,向量值為用戶對各個項目的評分向量.
第二個Map任務是負責讀取項目相似度向量,關鍵字為項目索引,值為相似度向量.
Reduce任務的輸入是上面兩個Map任務的輸出結果,將關鍵字一致的向量聚集到一起,組成一個新的矩陣,然后計算最緊鄰居集.
4 實驗結果及分析
4.1 實驗方案
本文實驗數據采用開源的美國Minnesota大學GronpLens項目組提供的Movielens(ml-lm)數據集,該數據集已經被廣泛應用在推薦系統的測評中.其包含了6040名用戶對3952部電影的超過1000 000的評價,分值為1到5的整數,分數越高表示用戶對電影的評價越高.該數據集有3張數據表組成: Users(用戶特征信息)、Movies(電影特征信息)、Ratings(評價信息).每一條記錄中包含用戶標識、電影標識、評價數值和時間,從中可以獲取本文所需的用戶基本信息、評價和時間等數據進行進一步的分析與處理.
本系統研究協同過濾算法的MapReduce并行化.通過Python操作HDFs上的文件,首先在HDFs上創建保存數據的文件夾; 然后MapReduce程序的每個輸出文件作為下一個MapReduce的輸入文件.
本實驗中,主要考察傳統的基于用戶的利用余弦相似度計算的協同過濾和在此基礎上的協同過濾并行化的推薦質量.實驗分別為一臺PC構建的單機模式以及三個節點構成的Hadoop集群.本文主要通過兩種方法來證實并行化的基于Hadoop的協同過濾算法的推薦系統及其推薦結果比傳統的協同過濾算法的推薦系統其推薦結果更能符合用戶的預期,與此同時比較單節點和3個節點的運行時間以及加速比.
一種方法就是用運行時間作為衡量算法擴展性的指標,同時也采用了加速比來衡量算法的擴展性,加速比定義為單機運行時間和Hadoop集群的運行時間的比值,計算公式如下:

另外一種就是根據平均絕對誤差協MAE值,MAE的值越小,表明算法的推薦精度越高.這種方法就是衡量推薦與真實的用戶賦給值的偏差.對于每一對評分預測數據

一般來說,平均絕對誤差越小,推薦結果越準確,系統性能就越好.
4.2 預測評分原理
(1) 一方面,選取平均絕對誤差協(MAE)作為算法推薦質量的評價指標,MAE的值越小,表明算法的推薦精度越高.從1 MB數據集中分別選取數據集為1000、10 000、15 000、20 000、40 000 和 60 000 作為6組實驗數據,分別用余弦相似度和修正余弦相似度以及本文方法(利用兩個節點并行)進行MAE值比較,如圖3 所示.

圖3 MAE 值
從圖3可以看出,實驗數據集越稀疏,MAE值越大,這就說明數據越多,可參考的就越多,平均絕對誤差也就越小; 當然,我們將單機模式與并行模式作比較,也不難發現在Hadoop環境下MAE的值也會相應的減少,可以得知修正的余弦相似度是比傳統的余弦相似度這種算法更加提升了推薦質量,并且基于Hadoop平臺,推薦性能也會隨著節點數增加而得到改善.
(2) 接下來分析余弦相似性的協同過濾與并行化的協同過濾的運行時間,因此我們將給出單節點、兩個節點和三個節點的運行時間以及加速比的對比情況.
從圖4可以看出,隨著數據集的增多,運行時間也會隨之增加,相比單節點、兩個節點以及三節點的Hadoop的運行情況,總體來說,在數據集很大的情況下并行能明顯縮短時間,這也足以說明基于MapReduce的協同過濾并行化推薦更適合于大數據的推薦系統.但是我們發現在數據集很小的情況下,并行化并沒有顯示出更加大的優勢,這是因為,在數據集小的情況下,Hadoop并行還需要進行資源配置,Map和Ruduce之間進行數據傳輸也需要消耗時間,因此在數據集很小的情況下就沒必要進行并行.
(3) 通過上述實驗,我們計算加速比進行比較如圖5所示.
從圖5我們可以看出,并行化以后的協同過濾很大程度上的增大了運行時間的加速比,并且當數據集越大的時候,加速比就越大,也就是說并行化對越大的數據集越有優化作用.我們還看出,理想的狀況下,要想充分地利用Hadoop集群的運算能力,Map的個數最好是Hadoop的節點倍數,這樣還可以防止機器被閑置.
經過以上實驗的分析,我們可以得出基于Hadoop的協同過濾對較大的數據集能有成效的優化運算能力,從而提升推薦速度.隨著現在互聯網規模的不斷擴大,這一發現對于推薦系統具有極大的應用,我們可以通過適當的增加Hadoop集群節點來提高推薦效率.

圖5 不同數據集的加速比
5 結論
本文介紹了傳統基于項目和用戶的協同過濾算法以及Hadoop平臺的MapReduce編程模型,分析了基于Hadoop平臺的協同過濾算法.實驗驗證在大規模數據的情況下,采用基于Hadoop的MapReduce編程模型進行并行化的協同過濾算法可提高推薦效率和推薦精度.
參考文獻
1李濤,王建東,葉飛躍,等.一種基于用戶聚類的協同過濾推薦算法.系統工程與電子技術,2007,29(7): 1178–1182.
2Xue GR,Lin CX,Yang Q,et a1.Scalable collaborative filtering using cluster-based smoothing.Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Salvador,Brazil.2005.114-121.
3Zhao ZD,Shang MS.User-based collaborative-filtering recommendation algorithms on hadoop.Proceedings of the Third International Conference on Knowledge Discovery and Data Mining.Phuket,Thailand.2010.478–481.
4Pan R,Zhou YH,Cao B,et al.One-class collaborative filtering.Proceedings of the Eighth IEEE International Conference on Data Mining.Pisa,Italy.2008.502–511.
5李燦.基于Hadoop的并行化協同過濾推薦算法研究.[碩士學位論文].楊凌: 西北農林科技大學,2016.
6肖強,朱慶華,鄭華,等.Hadoop 環境下的分布式協同過濾算法設計與實現.現代圖書情報技術,2013,(1): 83–89.[doi:10.11925/infotech.1003-3513.2013.01.13]
7李狀.基于Hadoop的協同過濾推薦算法的設計與實現[碩士學位論文].南京: 南京郵電大學,2016.
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
