基于新聞時效性的協同過濾推薦算法①
2018-05-17 06:47:59馮文杰
計算機系統應用 2018年5期
馮文杰,熊 翱
(北京郵電大學 網絡技術研究院,北京 100876)
隨著移動網絡技術的高速發展,網絡新聞生產、傳播速度都呈爆炸性的增長,人們逐漸從新聞信息匱乏的時代進入了新聞信息過載的時代.無論是新聞消費者還是新聞生產者都遇到了很大的挑戰: 從消費者角度來看,如何從大量新聞中發現自己感興趣的新聞是一件非常困難的事情; 從生產者角度來看,如何提高新聞瀏覽量和受眾規模,也是一件很困難的事情.與此同時,隨著社會節奏的加快,新聞消費者傾向于在更加碎片化的時間內瀏覽新聞,因此新聞消費者主動搜索新聞以解決信息過載問題的意愿也就更低,換言之,用戶希望在花費更少時間的前提下得到更適合自己的新聞.
個性化推薦系統[1]就是解決這一問題的重要工具.在新聞推薦領域,個性化新聞推薦系統通過聯系用戶和新聞,一方面幫助用戶發現對自己有價值的新聞,另一方面讓新聞能夠展現在對它感興趣的用戶面前,從而實現新聞消費者和新聞生產者的雙贏.其中協同過濾算法[2]是推薦系統中應用較為廣泛的推薦算法,該算法基于鄰域; 根據領域選取的區別,可以分為基于用戶的協同過濾算法[3]以及基于物品的協同過濾算法[4].而在新聞推薦算法領域,一般更適合使用基于用戶的協同過濾推薦算法,因為在一個新聞系統中,用戶量是相對固定且變化不明顯的,維護基于用戶的協同過濾算法在性能上有更好的表現.
但基于用戶的協同過濾算法容易忽視新聞信息的特性,導致推薦新聞的時效性不足,降低了新聞推薦的實際接受率; 并且需要不斷調整相似用戶的新聞信息表,在數據量大時,算法時間開銷會非常大.
本文針對上述問題,提出了基于新聞時效性的協同過濾推薦算法,該方法充分考慮到了新聞信息老化[5]的特點,通過建立新聞的時效性模型,改進了基于用戶的協同過濾系統中對最近鄰用戶的選擇; 在維護用戶相似度的矩陣時,將新聞集進行提前過濾,保留時效性較高的新聞信息.在新聞信息量較大的情況下也能維持算法的高性能,本文利用該改進的算法,對某網絡新聞系統的新聞、用戶行為數據集進行了仿真實驗,證明了本文所提方法的有效性.
1 新聞時效性模型和基于用戶的協同過濾推薦算法
1.1 新聞時效性模型
對于推薦系統而言,不同類型的物品具有不同的生命周期,即它們的時效性會有很大的差別.例如新聞信息就要比電影的生命周期短很多; 用戶可能會滿意對很久之前電影的推薦,因為電影的信息熵并不會因為時間的推移而減少; 而對用戶推薦老舊新聞,很多時候都是無效的,因為新聞的時效性非常重要; 即使是比較重要的歷史性新聞信息,實質上也算是過期信息,對用戶瀏覽新聞并無幫助.
從新聞信息的產生,推薦,成為熱點,衰退到最后的消失,新聞信息在時間軸上總是呈現一定的規律; 這一點和應用信息計量學中的文獻老化理論是相似的,例如文獻[6,7]就通過文獻老化模型來描述網絡信息的效用變化.因此我們可以根據信息老化的特點,建立新聞推薦系統的時效性模型,定義如下:
定義1.新聞發布時刻新聞發布時刻是指當新聞被生產完畢并正式發布的時間節點,但還沒被個性化推薦系統加入相似新聞集.一般而言,這個時刻與推薦系統更新時刻越近則說明新聞越新,在經過初級過濾系統時,它被過濾的可能性越低.
定義2.推薦算法更新時刻由于新聞會不斷發布,因此推薦算法更新新聞信息庫的時間也要根據系統的計算能力與實際新聞發布數量來設定,一般而言,兩次更新間隔越短,推薦效果越好,但會消耗很大的系統性能,需要根據實際系統來設定這個參數.
定義3.新聞生命周期生命周期是指在新聞發布后,自某個時刻起不再有新聞消費者對其做出消費行為,從這個時刻起,零星的閱讀行為可以認為是系統噪聲不予考慮.
根據文獻信息老化規律模型,即貝爾納在1958年提出的信息老化的負指數模型:

公式(1)中,t為文獻的出版年齡,表示t年時文獻被引用頻率.是一個與文獻分類有關的常數,為文獻的老化率.
將此模型應用于新聞信息,可以用公式(2)定義,將在后面驗證負指數模型對新聞老化規律模型的適用性.

其中,t表示當前時刻,為新聞發布時刻表示新聞在t時刻時的用戶反饋統計數量,需要根據新聞系統設定合適的時間粒度,來統計該時刻分段的用戶反饋數量.是該新聞的老化系數,表示該新聞隨著時間推移其效果的衰減系數,越小,說明這條新聞的時效性越強;則為某一個常數,和新聞在發布后的初始統計時間粒度內的用戶反饋統計數量有關,以第一個統計時間段為例,在第一個時間粒度內,用戶反饋統計數量參數受新聞初始閱讀量影響較大,但不會表現新聞時效性的變化趨勢; 即較大的新聞會擁有比較大的初始閱讀量,但不能保證衰減速度慢; 在本文研究的時效性改進算法中,更關心新聞本身的時效性變化趨勢,所以進行線性回歸分析,計算出、后,主要采取作為推薦算法的輸入,實際上對公式(2)變形后,可以在公式(3)中更清楚的認識到老化參數與時間推移之間的關系:
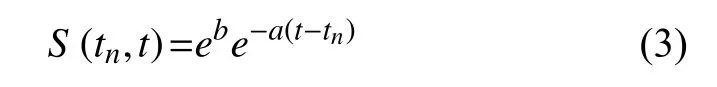
變形后,對老化曲線擬合更貼近于常見的負指數模型,在數學表達上也更加直觀.只要求出老化系數即可.
對于一條特定的新聞而言,老化系數代表了其在發布后傳播效果的衰減速度,發布后衰減不明顯的新聞是時效性較強的新聞,新聞消費者認為其有很高的時效價值; 而當一條新聞到達自己的生命周期后,那么此新聞就沒有時效價值了.
1.2 基于用戶的協同過濾算法原理
基于用戶的協同過濾算法(以下簡稱UserCF算法)是推薦系統中最常見的算法之一,應用十分廣泛;主要包括兩個步驟,首先尋找與目標用戶興趣度相似的用戶集合.然后找出在這個用戶集合中的用戶喜歡而目標用戶尚未關注的物品信息,將其推薦給目標用戶.
在計算兩個用戶的興趣相似度時,主要利用行為的相似度來計算興趣的相似度.給定用戶和用戶,集合表示用戶曾經有過正反饋的物品集合,集合為用戶曾經有過正反饋的物品集合,就可以計算和的興趣相似度常見的相似度計算公式有兩種,第一種是杰卡德相似度計算公式[8]:

第二種是余弦相似度計算公式:

根據用戶之間的興趣相似度,可以給用戶推薦和他興趣最相似的個用戶喜歡的新聞,公式(6)度量了UserCF算法中用戶對新聞的感興趣程度.
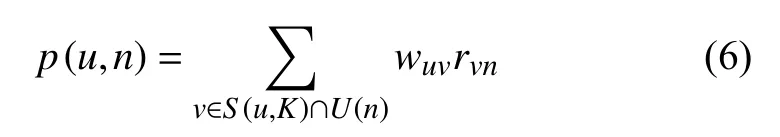
在此式中包含了與用戶興趣最為接近的個用戶是對新聞n有過行為的用戶集合是用戶和用戶的興趣相似度代表用戶對新聞的交互評分,由其閱讀時長、新聞長度、點贊、評論等正反饋行為歸一化得出,以衡量用戶對新聞的興趣度.計算出后,比較通用的做法是根據某個用戶對新聞的預測評分做Top-N推薦,即推薦出前個高評分結果.
2 基于新聞時效性的協同過濾算法
2.1 算法設計
傳統的UserCF算法中沒有考慮信息時效性的問題,這種做法可能適合電影、電商類系統,但卻忽略了新聞信息的時效性.為了解決這個問題,本文結合上文中的新聞時效性模型,根據新聞衰老系數與生命周期,對推薦新聞預測評分進行加權,同時過濾過時新聞,降低了算法輸入數據的規模,從而提高了推薦的效果.
2.2 數據模型
(1)新聞信息集合,表示新聞系統中的新聞集合,會根據生產者的輸出而更新,加入新的新聞.用集合來表示i條新聞的集合,這個集合用來計算用戶相似度.
(2)推薦系統輸入新聞集合,表示新上架的新聞,作為推薦系統在選取推薦新聞時的輸入集;同時也用來計算新聞時效性.用集合來表示.集合包含了那些在推薦算法更新輸入時刻仍然較為活躍,并未消耗完生命周期的新聞,這些新聞仍然有不少用戶在閱讀;由于UserCF算法要進行比較復雜的用戶偏好度計算,同時要進行時效性模型的檢驗,所以將輸入集限定在仍然在生命周期內的新聞,可以大幅降低算法復雜度.
(3)用戶信息集合,表示新聞系統中的用戶集合,會根據系統用戶的增加而更新,但變化很緩慢.用集合來表示個用戶的集合.
(4)用戶,新聞興趣矩陣用戶會對新聞做出不同的行為,如閱讀、點贊、分享及評論等;通過用戶行為偏好向量空間模型來計算用戶對新聞興趣值(5)新聞訪問表,用于記錄新聞被閱讀、收藏、贊操作及其具體時間,用于計算新聞被訪問隨時間變化的趨勢,即其時效性.
2.3 通過時效性參數改進推薦算法
算法詳細步驟如下:
1)在推薦算法更新時刻確定集合,并對集合中的元素進行統計,根據系統設定的時間粒度,從新聞訪問行為表中計算在每個時段內新聞被訪問的數據.通過時效性模型曲線擬合計算新聞老化率,并計算集合中新聞老化率的最大值,記為
2)用戶相似興趣度計算,可以選擇余弦相似度計算,也可以選擇杰卡德相似度計算.在選定相似度公式后,計算用戶相似興趣度的輸入集包含整個新聞集合與用戶集合,而非新聞子集合,這是為了獲取用戶完整的歷史興趣愛好,以構建正確的用戶相似興趣度矩陣.在這里我們選取杰卡德相似度公式:
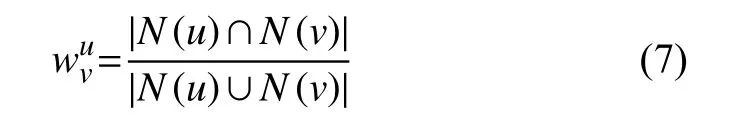
3)基于時效性參數改良預測評分結果:
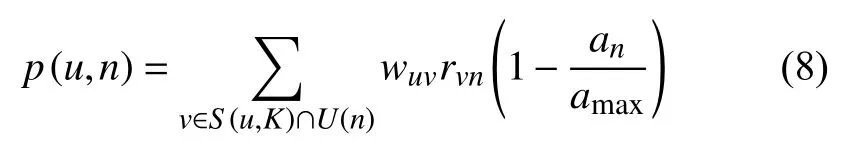
對集合中的新聞應用公式(8),計算出用戶對集合中新聞的興趣度,通過加入時效性參數作為加權,即可得出最終預測興趣評分.
4)選取Top-N作為最后的推薦方法,選擇集合中最高興趣評分的個元素作為用戶推薦的結果.
3 實驗分析
本文對某新聞報業集團的網絡新聞數據與用戶數據進行實驗.共計 5436 條新聞,43 187 個用戶.部分新聞數據如表1所示,該表表示某個新聞的閱讀情況.
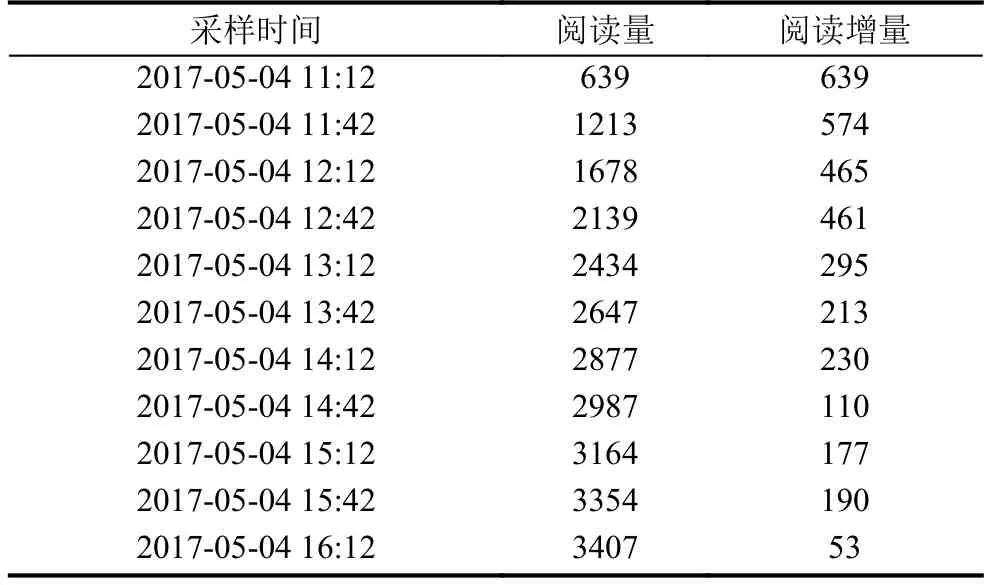
表1 實驗部分新聞訪問數據
3.1 時效性模型實驗
首先對新聞集進行時效性模型檢驗,根據其閱讀量變化,使用負指數模型進行擬合校驗,以單條新聞為例,圖1即單條新聞閱讀變化量擬合結果.
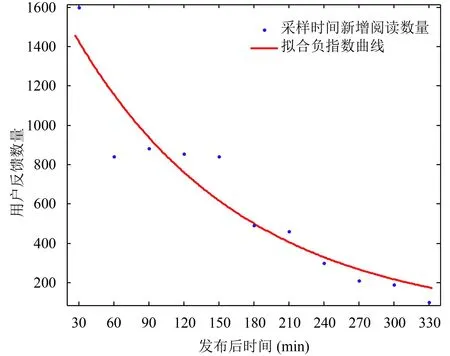
圖1 單條新聞擬合結果
表2為其時效性模型檢驗結果.對于本文的時效性模型而言,SSE與RMSE與模型輸入數量級有關,對結果沒有太大的解釋意義; R-square與Adjusted R-square則表達了擬合結果與目標模型的效果,越接近1說明模型越好.表2中對應新聞瀏覽量變化趨勢比較符合時效性模型曲線,即閱讀量與時間之間有較強的相關關系,可以根據其擬合得到的老化系數作為推薦模型的輸入.

表2 某新聞擬合結果
表3所示為對測試集合中的新聞進行時效性模型檢驗,從中可以看出,擬合結果R-square大于0.80的比例為70.7%,即其與負指數時效性模型擬合度較好,有較高的說服度,這些新聞的主要特點是平均總閱讀量比較高,因此噪音表現不明顯; 而剩余的新聞平均總閱讀量比較低,受關注度低,即使在發布的第一時間,也很少有用戶關注; 對在發布后的某個特定時間段的抗噪音能力較差,用戶反饋統計數量容易受波動,難以體現時效性變化的總體趨勢.

表3 新聞集合擬合結果統計
針對時效性模型的擬合誤差,需要根據具體情況設定誤差實驗分析; 總體而言,對于閱讀量較大的新聞,時效性模型是比較適用的,擁有比較好的正確率與精度,也可以從中看出新聞閱讀量與時間的相關性; 對于抗噪聲能力較差的非熱門新聞,可以將其剔除出新聞輸入集合,只對訂閱用戶推送,因此就不會受到非精確時效衰減率影響.
3.2 基于時效性模型改進UserCF算法的實驗
根據實驗(1)的結果,得出了時效性模型的新聞老化系數,改進 UserCF 算法; 本實驗采用 Mahout[9]作為UserCF框架,在計算用戶興趣度時,考慮時效性模型中老化系數的影響.
將實驗(1)中的新聞數據集中R-square超過0.80的新聞集單獨抽出,形成一個新的新聞集A,與原新聞集N分別作為新聞總集,進行兩次實驗,實驗步驟相同,輸入不同,其他參數一致.最后與傳統的 UserCF算法作為對照比較.
本實驗中,將用戶行為數據集隨機且均勻分成8 份,6 份作為訓練集,2 份作為測試集,通過準確率與召回率來評價推薦算法的效果:
式(9)為準確率的公式:

式(10)為召回率的公式:
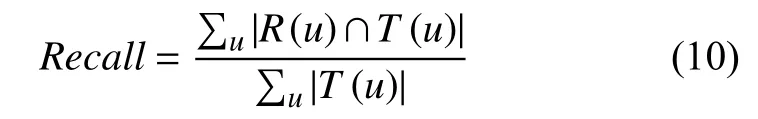
其中為推薦新聞集合為用戶實際喜歡的新聞信息.準確率用于描述最終推薦列表中實際發生的用戶-新聞興趣評分,召回率用于描述有多少比例的用戶-新聞興趣評分出現在最后的最終的推薦列表中.

表4 推薦算法實驗結果
表4為推薦算法實驗結果,首先對于不同的輸入新聞集合N與A,A代表那些和時效性模型擬合程度較好的新聞數據集,它們的平均閱讀數量也較高,抗噪聲能力強; 實際上在一個推薦系統中,熱門新聞受推薦的概率會更大,因此其準確率與召回率都會更高.在傳統的UserCF算法中,A集合有著更高的推薦準確率與召回率,但與N集合差別并不大,UserCF算法沒有考慮到時間推移的影響,只響應了高閱讀量新聞的特性,略微提高了推薦準確率與召回率.
在相同的輸入集合下,改進后的UserCF算法有著更好的表現,這是因為基于時效性模型改進的UserCF算法考慮到了新聞時效性衰減的因素,較好地利用了老化系數,降低了衰減較快新聞的權重; 對于和時效性模型擬合較好的新聞集合,改進后的UserCF性能還會有提高,這是因為這類新聞不僅衰減速度慢,時效性強,同時自身閱讀量高,故而推薦效果還會有所增強.
3.3 時效性模型誤差分析
在時效性模型實驗實驗中,針對擬合誤差較大的新聞集合,即R-square值低于0.80以下的新聞集合B,進行誤差分析與算法性能分析.

表5 誤差實驗結果
表5為誤差新聞集實驗結果.對于R-square值較低的新聞集合,由于其和時效性模型偏差較大,擬合所得的老化率不能完全反應新聞實際失效的速度,在引入UserCF算法時并不會大幅提高UserCF性能; 但從實際結果來看,時效性模型改進的UserCF算法仍然有15%的提高.這是因為高誤差新聞集合中的新聞閱讀量較少,這些新聞很容易在算法的第一步時因為生命周期消耗殆盡,從而被提前過濾.沒有進入輸入集合中; 但相對于總新聞集合中的推薦實驗結果,這些誤差使得時效性模型改進的UserCF算法的提高較為有限.
4 結論與展望
隨著網絡新聞量的爆發式增長,如何在信息過載的情境下為新聞消費者提供合理的新聞推薦集成為了重點問題.本文結合文獻信息老化模型,應用于新聞信息上,利用時效性模型中的老化參數改進了基于用戶的協同過濾算法,對新聞-用戶數據集進行了分析和研究.從實驗結果上看,這種改進型算法適用于抗噪能力強的熱門新聞,能提高新聞推薦算法的準確率和召回率.
但是本文提出的方法只考慮了協同過濾算法中興趣評分處理與新聞時效性的問題,并沒有解決協同過濾算法中冷啟動[10]問題,同時也沒有考慮到系統初始狀態下的用戶稀疏性[11]問題.所以該算法在未來還有很大的改進空間.
參考文獻
1Liu JX,Tang MD,Zheng ZB,et al.Location-aware and personalized collaborative filtering for web service recommendation.IEEE Transactions on Services Computing,2016,9(5): 686–699.[doi: 10.1109/TSC.2015.2433251]
2馬宏偉,張光衛,李鵬.協同過濾推薦算法綜述.小型微型計算機系統,2009,30(7): 1282–1288.
3項亮.推薦系統實踐.北京: 人民郵電出版社,2012: 33–37.
4鄧愛林,朱揚勇,施伯樂.基于項目評分預測的協同過濾推薦算法.軟件學報,2003,14(9): 1621–1628.
5陸研,毛健駿,屠方楠.網絡信息老化規律研究——新浪新聞與新浪微博實證研究.高等函授學報(哲學社會科學版),2011,24(12): 52 –55.[doi: 10.3969/j.issn.1007-2187.2011.12.021]
6馬費成,望俊成.信息生命周期研究述評(Ⅰ)——價值視角.情報學報,2010,29(5): 939–947.
7鞠菲.網絡信息老化實證研究——以新浪新聞為例.情報雜 志 ,2010,29(10): 41 –45,40.[doi: 10.3969/j.issn.1002-1965.2010.10.010]
8李斌,張博,劉學軍,等.基于 Jaccard 相似度和位置行為的協同過濾推薦算法.計算機科學,2016,43(12): 200–205.[doi: 10.11896/j.issn.1002-137X.2016.12.036]
9Owen S.MAHOUT 實戰 (圖靈程序設計叢書).王斌,韓冀中,萬吉譯.北京: 人民郵電出版社,2014: 28–73.
10孫小華.協同過濾系統的稀疏性與冷啟動問題研究[博士學位論文].杭州: 浙江大學,2005.
11林建輝,嚴宣輝,黃波.融合信任用戶的協同過濾推薦算法.計算機系統應用,2017,26(6): 124–130.[doi: 10.15888/j.cnki.csa.005805]
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
