Storm環境下基于權重的任務調度算法
2018-05-21 00:50:07英昌甜師康利蒲勇霖
計算機應用 2018年3期
魯 亮,于 炯,卞 琛,英昌甜,3,師康利,蒲勇霖
(1.新疆大學 信息科學與工程學院,烏魯木齊 830046; 2.新疆大學 軟件學院,烏魯木齊 830008;3.新疆大學 電氣工程學科博士后科研流動站,烏魯木齊 830047)
0 引言
隨著互聯網和各類智能終端的普及,數據呈現出井噴式發展的趨勢,MapReduce等各類大數據處理框架應運而生[1-2]。然而,這類傳統的大數據批量處理框架無法滿足部分企業的實時性業務需求。Apache Storm[3-4]作為一個開源、實時、分布式部署、容錯且擴展性良好的大數據流式計算系統[5-6],已成功解決這一問題并引起了學術界和企業界的高度關注。在Storm系統中,只要數據源處于活動狀態,元組便會源源不斷地發送至各工作節點,計算和傳輸將持續發生,無需進行中間結果的持久化存儲,在實時個性化推薦、實時交通大數據分析、實時臨床數據分析等領域具有廣闊的應用前景[7-9]。
Storm在進行任務分配時采用輪詢(Round-Robin,RR)調度算法,即將用戶提交的拓撲中包含的每一個任務均勻分配到各工作進程中,再將各工作進程均勻分配到各工作節點上,未考慮到各任務計算開銷的差異以及任務與任務之間不同類型的通信開銷,這將對Storm處理的實時性產生較大影響。針對這一問題,已有少量國內外學者展開相關研究。文獻[10]提出資源感知的在線調度算法R-Storm,將Storm資源分為硬約束(針對內存)和軟約束(針對CPU和網絡)兩類,利用任務需求的各類靜態資源和工作節點所能提供的靜態資源之間的關系實現調度,最終達到最大化資源利用率和提高集群吞吐量的效果,但該算法中各任務的資源需求完全依靠程序員人為設定而并非通過監測獲得,不適合數據流快速變化場景下的在線調度。文獻[11]對此進行改進,添加了資源負載監測模塊并將監測結果存入數據庫,并使用調度生成器根據數據庫中的數據進行實時調度,但并未評估調度自身對系統運行帶來的影響以及重調度后是否能夠帶來更低的系統延遲。文獻[12]提出Storm框架下流量感知的在線調度算法T-Storm,通過監測任務負載、工作節點負載以及任務與任務之間的數據傳輸負載,將通信開銷大的任務動態分配至空閑資源較多的節點上。然而,該算法并無法保證通信開銷大的一對任務一定分配到同一個節點中,且一個拓撲需求的節點數量依賴于用戶設定。此外,文獻[13]提出一種帶權圖的k劃分算法,文獻[14-16]提出流式計算框架下實時高效的資源調度算法和優化框架。以上研究解決了流式計算環境下的任務優化調度問題,但無法直接移植于Storm平臺。文獻[17]提出并實現了一種服務質量感知的Storm分布式調度器,其在網絡時延和可靠性等方面均優于Storm默認調度算法的執行結果,但這與本文集中式數據中心的研究背景不符。文獻[18]將拓撲熱邊的概念引入Storm平臺,其主要思想是將熱邊關聯的源任務和目標任務調度到同一工作節點執行,以達到減少網絡通信開銷的效果。然而該算法未充分考慮拓撲內部通信的全局性,并未將非熱邊的調度優化考慮在內。文獻[19]為了分別降低進程間通信開銷和節點間通信開銷,在充分考慮Storm拓撲中各任務通信情況的基礎上提出一種兩階段調度算法,但該算法并未考慮到各任務自身計算開銷的差異性。文獻[20]提出Storm環境下離線和在線的兩種自適應調度算法,其中離線調度算法用于拓撲運行前的拓撲結構分析,而在線調度算法用于拓撲運行中各節點的實時負載監測和任務分配的動態調整,其中在線調度算法效果更優。這種自適應調度算法解決了部分Storm環境中的通信開銷問題,但執行時僅逐對考慮相互通信的任務,未將當前任務與其直接通信的所有任務全部考慮進來,這對于較為復雜的拓撲而言尚缺乏全局性,容易陷入局部最優,且當所有任務間的數據傳輸速率一致時,該算法無法工作。
為了改進Storm默認調度算法、克服已有相關研究的不足,本文提出一種Storm環境下基于權重的任務調度算法(Task Scheduling Algorithm based on Weight in Storm,TSAW-Storm)。該算法根據實時監測到的負載數據,為拓撲中包含的任務和數據流分別賦予不同的點權和邊權,并根據本文提出的負載均衡模型和最優通信模型的要求,將任務調度到合適的工作節點內。實驗結果表明,相對于Storm默認調度算法和文獻[20]的在線調度算法,TSAW-Storm在Storm集群系統延遲、通信開銷和負載均衡方面均有所改進。
1 Storm作業模型
在Storm中,一個流式作業稱為一個拓撲,表示為一個有向無環圖,由組件和數據流共同構成。組件分為Spout和Bolt兩種:其中Spout為數據源編程單元,用于為拓撲運行提供數據;Bolt為數據處理編程單元,用于實現拓撲中的處理邏輯。數據流是由無限的元組組成的序列,是Storm中對傳遞的數據進行的抽象,可通過不同的流組模式實現組件之間的數據流傳輸。如圖1所示,ca和cb為數據源編程單元Spout,其余組件為數據處理編程單元Bolt,所有箭線為數據流;特別地,組件cf和cg為數據終點,通常用于將最終數據展示至終端或持久化至數據庫。

圖1 拓撲邏輯模型 Fig. 1 Logical model of a topology
為提高拓撲執行的并行度,每個組件均可同時運行多個實例,稱之為任務。任務是各組件最終執行的代碼單元。設tij表示組件ci運行的第j個實例,sij,kl表示任務tij向任務tkl發送的數據流。數據流通過描述拓撲中數據的流向,將上游任務和下游任務關聯起來,由此提出如下關聯任務的概念。
定義1 關聯任務。對于任意任務tgh、tij與tkl,若存在任務tgh向任務tij發送的數據流sgh,ij與任務tij向任務tkl發送的數據流sij,kl,則任務tgh與tkl統稱為任務tij的關聯任務。
圖2即為圖1的一種實例模型。特別地,當組件ci的實例數量為1時,定義ti1=ti。可以看到cd的實例數量為3,cf的實例數量為2,其余組件的實例數量為1。以任務td1為例,其上游任務ta與tb以及下游任務tf1與tf2均稱為任務td1的關聯任務。

圖2 拓撲實例模型 Fig. 2 Instance model of a topology
在Storm集群中,資源池由一系列工作節點構成,定義該集合為N={n1,n2,…,n|N|}。每個工作節點內配置有若干個槽,每個槽只能容納一個工作進程。文獻[12]通過Storm吞吐量測試[21]表明,對于單個拓撲而言,若在一個工作節點內分配多個工作進程(即占用多個槽),將會增加進程間通信開銷進而導致運行效率的下降。因此,本文僅在一個工作節點內分配一個工作進程,此時Storm默認的輪詢調度算法可簡化為一個拓撲中包含的所有任務在各工作節點上的均勻分配,任務與工作節點間的對應關系可定義如下。
定義2 任務分配法則。若任務tij分配到了工作節點nk上,則記f(tij)=nk或f-1(nk)=tij;若任務集合Tnk={t11,t12,…,tij,…}分配到了工作節點nk上,則記f(Tnk)=nk或f-1(nk)=Tnk,其中f即為任務或任務集合在工作節點上的分配法則。如圖3為圖2的拓撲運行于包含有3個工作節點的Storm集群中的任務分配模型,若以工作節點n1及運行在該工作節點上的任務集合為例,可表示為:f({td1,tc,tf1})=n1,f-1(n1)={td1,tc,tf1}。

圖3 任務分配模型 Fig. 3 Model for task assignment
由圖3可知,Storm系統中的任務之間存在兩種通信模式,分別是類似于任務td1與tf2之間的節點間通信以及類似于任務td1與tf1之間的節點內通信。其中節點間通信受制于當前環境下的網絡帶寬和帶寬利用率大小,開銷往往很大;而節點內通信與網絡無關,由于一個任務運行于一個工作線程內,因此其通信類型僅為進程內的線程級通信,開銷很小并可忽略不計[14]。然而Storm默認輪詢的任務調度算法并未兼顧到這兩種通信模式的差異性,從而導致較大的節點間通信開銷。此外,由于各組件自身業務邏輯的不同,CPU占用率必然存在差異;即使是同一個組件中各個業務邏輯相同的任務,也將由于部分流組模式(如Field Grouping)的限制,并不會將其接收到的所有數據流均分到各實例中,故各任務的計算開銷依然存在差異,輪詢的任務分配方式無法保證集群中各工作節點的負載均衡。為了更好地評估任務的計算開銷和任務間傳輸的數據流大小,提出如下帶權拓撲的概念。
定義3 帶權拓撲(Weighted Topology, WT)。設任務tij占用的CPU資源大小為wtij,任務tij與tkl之間傳輸的數據流大小為wsij,kl,則圖2的拓撲實例模型中各任務和任務間的數據流可分別使用wtij和wsij,kl構成拓撲的點權和邊權,其值可通過后文提出的負載監視模塊進行實時獲取。這樣的拓撲實例模型稱作帶權拓撲。
2 問題建模與分析
本節在帶權拓撲的基礎之上建立負載均衡模型與最優通信模型。其中負載均衡模型建立了各工作節點理想負載與實際負載間差異大小的度量指標,可為調度算法運行時的終止條件和運行后的負載均衡效果評估提供理論依據;最優通信模型則證明了節點間數據流傳輸代價與節點內數據流傳輸代價此消彼長的轉化關系,為最小化通信開銷的任務遷移過程提供了決策原則。
2.1 負載均衡模型
設某一帶權拓撲中包含的任務集合為T,nx為工作節點集合N中任意一個工作節點,工作節點nk上分配的任務集合為f-1(nk),工作節點nl(k≠l)上分配的任務集合為f-1(nl),則必然有:
(1)
且:
f-1(nk)∩f-1(nl)=?;k≠l
(2)
記Wnx為工作節點nx的CPU負載,其值為分配給工作節點nx上的所有任務需要占用的CPU資源總量,即:
(3)
記W為Storm集群的CPU負載總和,即集群中各工作節點的CPU負載總量。在同構環境下,各工作節點的CPU負載隨任務分配模型的變化而此消彼長,但W始終不變,其計算方法為:
(4)
若將集群中的CPU負載總和均勻分布到各工作節點上,則每個工作節點需容納的CPU負載為:
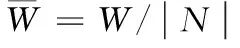
(5)
式(5)表示在理想狀態下達到負載均衡后各工作節點的CPU負載情況。事實上,集群中各工作節點不可能達到完全的負載均衡狀態,故使用式(6)標準差來衡量各工作節點的實際負載與理想負載的偏離程度。標準差越小則表示各工作節點間的負載差異越小,負載越為均衡。
(6)
2.2 最優通信模型
如第1章所述,Storm系統中任務之間的通信模式可分為節點間通信和節點內通信,其中節點間的通信開銷遠大于節點內的通信開銷。因此,若尋求Storm系統中通信模式的優化途徑,需令節點間通信開銷達到最小,即盡可能減少工作節點間傳輸的數據流總和,可表示為:
(7)
定理1 最優通信開銷原則。最小化節點間傳輸的數據流大小等價于最大化節點內傳輸的數據流大小,即式(7)等價于:
(8)
證明 由第1章Storm作業模型可知,拓撲一旦提交到集群,拓撲實例模型即固定下來,其包含的任務總數和數據流總數不可改變。因此在不發生擁塞的情況下,總數據流大小為一定值C,即:
(9)
證畢。
由定理1可知,在進行Storm系統任務調度時,為了達到最優通信模型的要求,應盡可能地把通信頻繁的任務調度到同一個工作節點上,以最大限度地降低節點間通信開銷。
3 基于權重的任務調度算法
為了達到上述負載均衡模型和最優通信模型的要求,本章提出Storm環境下基于權重的任務調度算法(TSAW-Storm),并進行算法評估與部署。
3.1 邊權增益
TSAW-Storm旨在盡可能均衡分配各工作節點負載的前提下,盡量減少節點間傳輸的數據流總和。而由最優通信模型可知,當任務分配法則發生變化時,節點間數據流與節點內數據流將相互轉化。為了量化這一過程,提出如下邊權增益的概念。
定義4 邊權增益。對于任務tij,若存在任務分配法則f(tij)=np,設Ttij,np為與任務tij關聯且位于工作節點np上的任務集合,Ttij,nq為與任務tij關聯且位于工作節點nq上的任務集合,且p≠q,若將任務tij由工作節點np遷移至工作節點nq,則邊權增益可表示為:


(10)
以圖3為例,對于任務td3而言,位于該任務所在工作節點n3上的關聯任務集合為Ttd3,n3={ta},位于工作節點n2上的關聯任務集合為Ttd3,n2={tb,tf2},若將任務td3由工作節點n3遷移至工作節點n2,則數據流sb,d3和sd3,f2將由節點間數據流轉化為節點內數據流,而數據流sa,d3將由節點內數據流轉化為節點間數據流,其邊權增益的計算方法為:
Gtd3=wsb,d3+wsd3,f2-wsa,d3
(11)
可見,邊權增益反映了任務遷移前后節點間數據流的差值。邊權增益越大,則意味著將更多的節點間數據流轉化為了節點內數據流,這符合2.2節中最優通信模型的要求,是后續算法的設計目標之一。
3.2 算法描述
計算邊權增益的前提是獲取帶權拓撲的關聯任務及其對應邊權;而為了在獲取最大化邊權增益的同時不違背負載均衡模型的約束,帶權拓撲的點權及各工作節點的CPU負載值同樣不可或缺。因此在TSAW-Storm的設計過程中,需在用戶提交拓撲后首先執行Storm默認調度算法,并當拓撲運行穩定后完成上述數據的采集和存儲。當工作節點的CPU負載持續不均,即集群中所有工作節點的最大CPU負載與最小CPU負載之差在時間間隔τ內持續大于閾值ε時,則觸發算法1進行任務的重新調度。具體步驟如下:
算法1 TSAW-Storm。

2)對于?nx∈N′,如果nx中存在拓撲運行所需要的數據源且n|N|中分配的任務包含有Spout實例,或nx中不存在數據源但n|N|中分配的任務不包含有Bolt實例,則隨機將工作節點n|N|中的一個Spout實例遷移至工作節點nx;否則隨機將工作節點n|N|中的一個Bolt實例遷移至工作節點nx。設從工作節點n|N|中遷出的任務為tij,則有Tnx←{tij},Tn|N|←Tn|N|-{tij},同時根據式(3)更新工作節點CPU負載Wn|N|和Wnx。
3)獲取與Tnx中各任務關聯且位于工作節點n|N|上的任務集合,記為Tnx,n|N|。
4)將Tnx,n|N|中邊權增益最大的任務tkl遷移至工作節點nx,此時Tnx←Tnx∪{tkl},Tn|N|←Tn|N|-{tkl},同時根據式(3)更新工作節點CPU負載Wn|N|和Wnx。

6)重復第2)~5)步,逐步構建N′中各工作節點上分配的任務集合。
7)執行任務分配,即對于x∈1,2,…,|N|,實施f-1(nx)←Tnx。
3.3 算法解釋與算法評估
在算法1的執行過程中,第1)步獲取算法后續計算所需數據,并進行各項初始化操作。第2)步完成當前工作節點上的第一個任務分配,這是進行邊權增益計算的前提。在第一個任務的選擇過程中,如果待遷入任務的工作節點上存儲有數據源,則將拓撲中的數據源編程單元Spout分配到該工作節點上,目的是盡量避免Spout將遠程數據源讀入拓撲時帶來的節點間通信開銷,提高任務本地化執行的概率,進而提高Storm系統的運行效率。然而,將Spout中包含的所有任務均分配到數據源所在工作節點上的做法是不可取的,原因有以下兩點:其一,拓撲中Spout的各個任務彼此之間并無關聯,若將其分配到同一個工作節點上,勢必導致更小的節點內數據流,與最優通信模型的要求不符;其二,Spout中的每一個任務均需讀取其下游Bolt運行所需的所有數據,輸出的數據流總量必然很大,若各任務的分布過于集中,勢必給其所在工作節點與其下游Bolt所在工作節點之間帶來過多的節點間數據流,進而導致網絡擁塞,效果適得其反。為了避免上述情況的發生,第2)步僅為存在數據源的每個工作節點初始化分配一個Spout實例。第3)~6)步嚴格遵循負載均衡模型和最優通信模型的要求,根據最大化邊權增益原則,逐步選擇當前情況下最合適的任務從工作節點n|N|上遷出,并及時更新任務遷移后相關工作節點CPU負載的預測值,最終確定所有工作節點上的任務分配法則。這一過程存在遍歷關聯任務、計算最大邊權增益等需要較大時間開銷的重復性工作,時間復雜度為O(|S|·|N|)(S為帶權拓撲包含的數據流集合);然而以上步驟實質上并未改變任務分配模型,拓撲依然正常運行,用戶的實時性作業需求并未受到影響。直到步驟7)時才執行具體的任務分配,此時需重新分配拓撲中各任務在各工作節點中的映射關系,時間開銷為O(|T|);在這一時刻,拓撲執行會不可避免地存在短暫的中斷,延遲將有所增加,具體情況將在第4章實驗中進行評估。
3.4 算法實現與部署
為實現并部署算法1,需使用Storm為開發人員提供的可插拔自定義任務調度器,即實現接口org.apache.storm.scheduler.IScheduler中的方法public void schedule(Topologies topologies, Cluster cluster)。改進后的Storm架構如圖4所示。需要說明的是,一個完整的Storm分布式系統由運行進程Nimbus的主控節點、運行進程Supervisor的工作節點、運行進程UI的控制臺節點以及運行進程ZooKeeper的協調節點共同構成,而圖4并未修改控制臺節點和協調節點的工作機制,故將其省略,僅保留新增模塊以及與新增模塊相關聯的部分,其中新增加的四個模塊如下:
1)負載監視模塊。負責在一定的時間窗口內,收集各任務占用的CPU負載信息及各任務之間的數據流大小分別作為帶權拓撲的點權和邊權。由于Storm中的一個任務運行于一個工作線程中,因此為了獲取任務執行過程中占用的CPU資源大小以及各對任務在單位時間傳輸的元組數量,需實時追蹤各任務對應的線程ID及其相關聯的所有線程。其中各線程的CPU資源占用大小可通過ThreadMXBean類的getThreadCpuTime(long id)方法獲取到其占用的CPU時間,并與其所處工作節點的CPU主頻相乘求得;各對線程間傳輸的數據流大小需使用計數器變量統計各線程接收到的上游線程發送的元組數量,并與時間窗口容量相除獲得數據流傳輸速率。具體實現需添加在組件中各Spout的open()和nextTuple()方法以及各Bolt的prepare()和execute()方法中。
2)MySQL數據庫。負責存儲歷次任務分配信息以及負載監視模塊傳來的負載信息和數據流大小,并實時更新。
3)任務調度模塊。負責讀取數據庫中的信息,并在負載持續不均時觸發算法1以及時作出任務調度決策。
4)自定義調度器。覆蓋主控節點中Storm默認輪詢的調度算法,負責讀取任務調度模塊生成的調度決策并執行任務調度。

圖4 改進的Storm系統架構 Fig. 4 Improved architecture of Storm
4 實驗與分析
4.1 實驗環境與分析
實驗環境采用相同硬件配置的PC搭建一個包含有12個節點的Storm集群,其中共同運行進程Nimbus、進程UI和數據庫服務MySQL的節點1個,運行進程ZooKeeper的協調節點3個,其余8個為運行進程Supervisor的工作節點。表1列出了各節點具體的軟硬件配置。
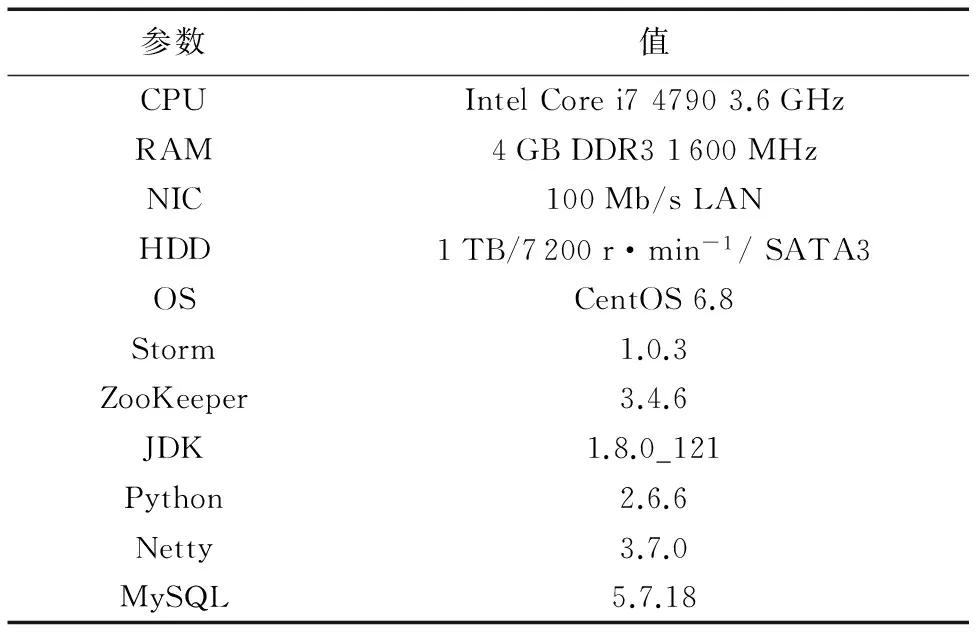
表1 Storm集群軟硬件配置Tab. 1 Hardware and software configuration of Storm cluster
實驗基于Intel公司Zhang[22]發布在GitHub上的基準測試storm-benchmark-master,本文選取其中CPU敏感型(CPU-Sensitive)的WordCount構建拓撲,數據源為其自身提供的原版英國歷史小說《雙城記》,格式為txt。原著中各單詞出現的頻率不盡相同,因此在實際生產環境中具有一定的代表性,若此時使用Storm默認輪詢的調度算法,極易在計數過程中發生各工作節點CPU負載不均的情況,進而觸發TSAW-Storm,便于評估算法的執行效果。表2列出了WordCount運行時的各項參數配置及其相關說明。需要進一步解釋的是,表2中工作進程個數設置為8,意味著8個工作節點中各分配1個工作進程,這樣便消除了同一節點內工作進程間的通信開銷,與文中任務分配模型的描述相符;Acker用來跟蹤元組的處理結果,其值默認設置與工作進程個數相同;Spout緩存隊列長度可對Spout的元組發射速率進行控制,并進而決定Storm系統的吞吐量,通過多次實驗后設置該集群配置下的合適值為50;時間間隔tau和閾值epsilon即為3.2節中敘述的τ與ε,表示若集群中所有工作節點的最大CPU負載與最小CPU負載之差在每80 s時間間隔內持續超過20%時,觸發TSAW-Storm,該值可根據Storm默認調度算法的運行結果進行人為調整。

表2 WordCount參數配置Tab. 2 Parameter configuration of WordCount
為驗證TSAW-Storm的有效性,文中除了與Storm默認調度算法進行對比之外,還部署了文獻[20]的Storm自適應在線調度算法(online scheduler)。該算法在運行后取得了較好的調度效果,其核心思想是實時監測各工作節點和各任務的CPU負載情況以及各對任務之間的數據流大小,當存在CPU負載持續超出閾值的工作節點時觸發任務重分配機制,即首先按照遞減的順序排列拓撲中各對任務之間的數據流大小,然后將任務逐對調度至那些令其重分配后產生最低CPU負載的工作進程和工作節點中。表3列出了采用在線調度算法進行對比實驗時的各項參數配置。需要說明的是,為了與TSAW-Storm在同等CPU負載條件下觸發任務調度,各項參數均通過多次實驗進行微調并最終確定了理想值,其中參數reschedule.timeout為在線調度算法的觸發周期,參數capacity為在線調度算法中CPU的使用率上限,這兩項參數分別與本文算法中的τ與ε存在對應關系。

表3 在線調度算法參數設置Tab. 3 Parameter configuration of online scheduler
4.2 實驗結果與分析
本節通過實驗評估TSAW-Storm在系統延遲、通信開銷和負載均衡三個方面的表現。為便于數據統計,以下各項測試均在基準測試的配置文件中設置metrics.poll為5 000,metrics.time為300 000,其單位為ms,即每組實驗每5 s進行一次采樣,總時長為5 min。
4.2.1 系統延遲測試
延遲表明一個元組從Spout發射到最終被成功處理的時間消耗,反映了拓撲執行一次的響應時間,刻畫了系統的運行效率。圖5統計了WordCount在Storm默認調度算法(圖例中Default)、在線調度算法(圖例中Online)與基于權重的任務調度算法(圖例中TSAW-Storm)下的系統延遲。

圖5 三種任務調度算法下的系統延遲對比 Fig. 5 Comparison of latency among three task scheduling algorithms
如圖5所示,從實驗開始到第一個峰值結束時間段表示拓撲提交時的初次任務分配,此時的任務分配均遵循Storm默認調度算法。其中0~25 s的零延遲階段表示任務分配的計算與同步過程,由于此時存在未被成功調度的任務,拓撲實例模型并不完整,故無法形成一條完整的數據流;同時,Spout中的任務往往首先完成分配并開始發射數據,在其下游Bolt中的任務未被成功調度的情況下,Spout緩存隊列中的元組因無法及時得到處理而導致系統延遲隨著運行時間的推進而不斷增加,進而出現30~35 s的極高峰值。第一個峰值過后,系統延遲逐漸趨于收斂,在集群中各工作節點不發生意外的情況下,默認調度算法將不再實施任務調度,系統延遲的保持在11.2 ms左右;而此時在線調度算法與TSAW-Storm開始收集集群中各工作節點以及工作節點上各任務占用的CPU負載信息和各任務之間的數據流大小,為各任務未來的優化配置提供決策依據。
隨著運行時間的推移,第90 s時在線調度算法觸發,此時所有任務在各工作節點上重新分配,系統暫停一切數據流傳輸,故系統延遲在90~100 s時間間隔內無法觀測;第105~110 s時系統延遲達到極高峰,隨后迅速下降,整個任務重調度過程相當于拓撲提交時的初始化任務分配,執行開銷較大。在線調度算法觸發的原因是此時集群中已經存在CPU負載在80 s內超過70%的工作節點,而之所以圖5中第90 s才出現系統延遲的極端變化,其原因有以下幾點:1)主控節點的重調度指令分發到各工作節點需要消耗一定的時間;2)調度發生時,Spout雖然不再發射數據,但整個拓撲中仍存在少量未被完全處理的數據流,Acker機制仍在進行系統延遲的統計工作;3)采樣周期為一定值,統計誤差不可避免。由圖5可知,在線調度算法運行時對系統的影響范圍在第90~115 s,最大延遲為91.9 ms;系統運行穩定后,延遲平均值約為8.50 ms,相對于Storm默認調度算法降低約24.1%。
TSAW-Storm的觸發和執行過程與在線調度算法類似。第90 s時TSAW-Storm觸發,原因是在80 s的觀測周期內存在最大CPU負載與最小CPU負載之差持續大于20%的工作節點。與在線調度算法不同的是,TSAW-Storm觸發后的系統延遲在90~95 s時間間隔內無法觀測,僅為在線調度算法的一半左右,且隨后發生的延遲最高峰值為27.5 ms,僅為在線調度算法最大延遲的29.9%,可見TSAW-Storm對Storm系統的正常運行并未造成較大的影響。TSAW-Storm運行結束后,系統運行迅速趨于穩定,延遲平均值穩定在約7.84 ms,相對于在線調度算法降低約7.76%,相對于Storm默認調度算法降低約30.0%。TSAW-Storm觸發時之所以對系統整體影響較小,是因為該算法首先由主控節點計算更優的任務分配方案,這一過程并未改變任務分配模型,拓撲依然正常運行;而后再根據計算結果一次性執行任務分配,故影響系統正常運行的時間很短, Spout緩存隊列中的元組等待處理的時間也較短,不會導致類似在線調度算法產生的突發延遲。而TSAW-Storm之所以在收斂后能夠形成較低的系統延遲,是因為該算法不同于在線調度算法中逐對任務調度的方法,它針對帶權拓撲中的每一個任務,均充分考慮了與其相關聯的所有數據流,其調度更具全局性。此外,TSAW-Storm提高了任務本地化執行的概率,消除了一部分Spout中的任務讀取遠程數據源時的網絡開銷,這是導致系統延遲降低的又一個重要原因。
4.2.2 通信開銷測試
本節討論基準測試WordCount在Storm默認調度算法、在線調度算法與TSAW-Storm下的工作節點間通信開銷。圖6為采用三種不同調度算法時工作節點間單位時間的元組傳輸總量。
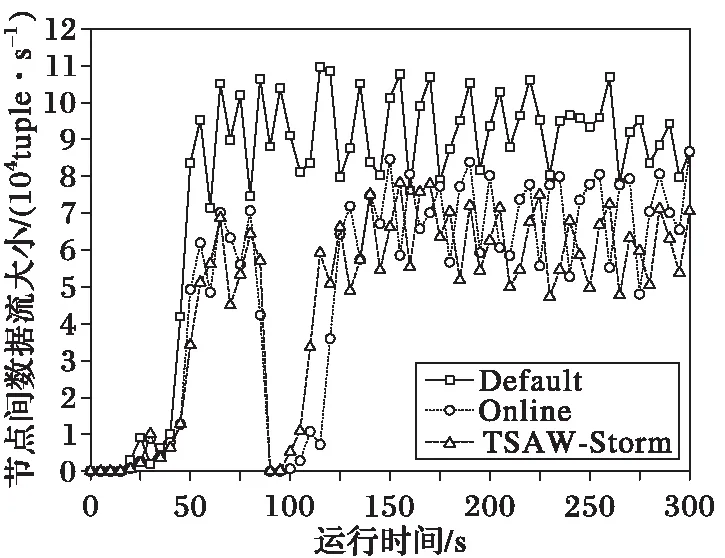
圖6 三種任務調度算法下的節點間數據流大小對比 Fig. 6 Comparison of inter-node tuple rate among three task scheduling algorithms
與圖5中的系統延遲類似,圖6中節點間數據流大小的統計結果亦可清晰反映在線調度算法與TSAW-Storm的觸發情況。可以看出,無論是采用Storm默認調度算法的初始化任務分配,還是在線調度算法與TSAW-Storm觸發后的優化調度,節點間數據流大小均將經歷一個從0迅速上升到正常狀態的過程,并不存在類似圖5中的峰值情況。這是因為表2中對WordCount的Spout緩存隊列長度作了合理限制,當未被成功處理的元組達到緩存隊列的上限時,Spout將暫停發射數據流,因此并不會發生因元組大量累積而突發傳輸的情況。由圖6可知,Storm默認調度算法執行且系統運行趨于穩定后(50~300 s),節點間數據流大小的平均值約為92 446 tuple/s;而當在線調度算法和TSAW-Storm觸發且系統穩定運行后(分別為125~300 s和115~300 s),節點間數據流大小的平均值約分別為70 335 tuple/s和62 026 tuple/s,相比Storm默認調度算法分別降低了23.9%和32.9%,其中TSAW-Storm相比在線調度算法執行后的節點間數據流大小下降了11.8%。可見,TSAW-Storm在降低節點間通信開銷方面具有更為明顯的效果,其原因是TSAW-Storm中最大化邊權增益和Spout任務本地化的思想能夠最大范圍地考慮到整個帶權拓撲的任務間通信情況,從而將更多的節點間數據流轉化為節點內數據流。而之所以TSAW-Storm在4.2.1節中降低的系統延遲不如降低的節點間數據流大小效果明顯,是因為在各類Storm基準測試中,WordCount屬于CPU敏感型拓撲[22],節點間數據流的減小僅可作為該類拓撲性能優化的方向之一,未來將針對拓撲的自身特性探索更多可能的優化方向。
4.2.3 負載均衡測試
本節討論基準測試WordCount在Storm默認調度算法、在線調度算法與TSAW-Storm下分別運行時集群的負載均衡情況。由于Storm默認調度算法采用輪詢的方式分配任務,因此各工作節點上初始化分配的任務數量相同。然而WordCount數據源中各單詞出現的頻率存在很大差異,當SplitBolt采用Field Grouping方式進行數據流分發時,各CountBolt中的任務需要處理的數據流大小差異很大,單純采用輪詢方式進行任務分配極易導致各工作節點的負載不均。在線調度算法與TSAW-Storm在任務重調度過程中充分考慮到不同任務負載的差異性,從而克服了默認調度算法在負載均衡方面的不足。表4為采用這三類任務調度算法執行任務分配后各工作節點的CPU負載均值。
由于在線調度算法和TSAW-Storm觸發前均使用Storm默認調度算法執行任務分配,因此可將表4中的Storm默認調度算法(Default)執行后的CPU負載看成是在線調度算法(Online)和TSAW-Storm觸發前各工作節點的資源占用情況。由表4可知,Storm默認調度算法執行后,各工作節點的負載不均現象較為嚴重,標準差高達12.66%,其中6號工作節點的CPU負載最高,7號工作節點的CPU負載最低,二者差值為33.4%。因最大CPU負載超出表3中設置的CPU使用率上限(capacity=70%),且最大CPU負載與最小CPU負載之差也超出了表2中設置的閾值(epsilon=20%),故在線調度算法和TSAW-Storm同時觸發,這與圖5中系統延遲以及圖6中節點間數據流大小的統計結果也是相吻合的。在線調度算法和TSAW-Storm執行后,集群中各工作節點的CPU負載均低于70%且負載基本均衡,不必再次觸發任務調度;標準差分別為3.47%和3.26%,僅為Storm默認調度算法的27.4%和25.8%。可見兩種任務調度算法均能達到負載均衡的效果,且TSAW-Storm效果略優,其執行后的CPU負載標準差相比在線調度算法降低了5.93%。這是因為在向除最后一個工作節點之外的其他工作節點逐步遷入任務的過程中,每個工作節點實際容納的負載大小均不能超過其理想情況下的CPU負載,這比在線調度算法中每次尋找具有最低CPU負載的工作節點的做法在負載均衡方面更便于控制。然而通過表4可以發現,使用TSAW-Storm執行任務調度后,8號工作節點的CPU負載將略低于其他7個工作節點,這是由于該調度算法的工作機制導致的:在算法1的初始化過程中,帶權拓撲中的所有任務都被擬分配至8號工作節點,而后再結合Spout任務本地化和最大化邊權增益的思想,將8號工作節點中的任務逐一分析并遷移至其他7個節點,直到各工作節點中分配的負載大小均在剛好大于其理想情況下的CPU負載為止。這種做法雖然不易導致節點過載,且能夠較好地保證1~7號節點的負載均衡,但可能導致位于8號工作節點上的任務被過多地遷出,進而發生該工作節點的CPU負載略低于其他工作節點的情況。若需解決這一問題,可在TSAW-Storm執行結束后,在滿足最優通信模型的前提下進行少量任務交換,這將在未來繼續開展研究。

表4 三種任務調度算法下的CPU負載對比Tab. 4 Comparison of CPU load among three task scheduling algorithms
5 結語
Storm默認輪詢的任務調度算法并未考慮到各任務計算開銷的差異以及任務之間不同類型的通信模式,在負載均衡和節點間通信開銷方面仍存在較大的優化空間。針對這一問題,本文將各任務占用的CPU資源大小作為拓撲的點權,任務間的數據流大小作為拓撲的邊權,提出帶權拓撲的概念;并在此基礎上建立負載均衡模型和最優通信模型,進而提出Storm環境下基于權重的任務調度算法(TSAW-Storm)。該算法利用最大化邊權增益的思想逐步構建起各工作節點中承載的任務集合,在保證集群負載均衡的同時,盡可能將節點間數據流轉化為節點內數據流,從而減小網絡開銷,提高Storm系統的運行效率。實驗通過基準測試WordCount從系統延遲、通信開銷以及負載均衡三個方面論證了本文調度算法的有效性。
下一步研究工作主要集中在以下幾個方面:1)本文實驗開展的背景為同構集群環境,下一步研究中將探索拓撲權值與CPU性能和網絡帶寬的關系,將TSAW-Storm移植至異構Storm集群環境下;2)根據TSAW-Storm調度后的任務分配結果進一步嘗試優化,如采用任務交換等方法,解決某一工作節點負載較低的問題;3)從拓撲自身的結構特征出發,將TSAW-Storm進一步推廣至更為復雜的Storm商業應用領域,使其適用于更為豐富的業務場景。
參考文獻(References)
[1] 孟小峰,慈祥.大數據管理:概念、技術與挑戰[J].計算機研究與發展,2013,50(1):146-169. (MENG X F, CI X. Big data management: concepts, techniques and challenges [J]. Journal of Computer Research and Development, 2013, 50(1): 146-169.)
[2] CHEN C L P, ZHANG C Y. Data-intensive applications, challenges, techniques and technologies: a survey on big data [J]. Information Sciences, 2014, 275(11): 314-347.
[3] TOSHNIWAL A, TANEJA S, SHUKLA A, et al. Storm @Twitter [C]// Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2014: 147-156.
[4] Apache. Apache Storm [EB/OL]. (2017-08-01) [2017-08-10]. http://storm.apache.org.
[5] 孫大為,張廣艷,鄭緯民.大數據流式計算:關鍵技術及系統實例[J].軟件學報,2014,25(4):839-862. (SUN D W, ZHANG G Y, ZHENG W M. Big data stream computing: technologies and instances [J]. Journal of Software, 2014, 25(4): 839-862.)
[6] RANJAN R. Streaming big data processing in datacenter clouds [J]. IEEE Cloud Computing, 2014, 1(1): 78-83.
[7] 王銘坤,袁少光,朱永利,等.基于Storm的海量數據實時聚類[J].計算機應用,2014,34(11):3078-3081. (WANG M K, YUAN S G, ZHU Y L, et al. Real-time clustering for massive data using Storm [J]. Journal of Computer Applications,2014,34(11):3078-3081.)
[8] 喬通,趙卓峰,丁維龍.面向套牌甄別的流式計算系統[J].計算機應用,2017,37(1):153-158. (QIAO T, ZHAO Z F, DING W L. Stream computing system for monitoring copy plate vehicles [J]. Journal of Computer Applications, 2017, 37(1): 153-158.)
[9] TA V D, LIU C M, NKABINDE G W. Big data stream computing in healthcare real-time analytics [C]// Proceedings of 2016 IEEE International Conference on Cloud Computing and Big Data Analysis. Piscataway, NJ: IEEE, 2016:37-42.
[10] PENG B Y, HOSSEINI M, HONG Z H, et al. R-Storm: resource-aware scheduling in Storm [C]// Proceedings of the 16th Annual Middleware Conference. New York: ACM, 2015: 149-161.
[11] 劉月超,于炯,魯亮.Storm環境下一種改進的任務調度策略[J].新疆大學學報(自然科學版),2017,34(1):90-95. (LIU Y C, YU J, LU L. An improved task schedule strategy in Storm environment [J]. Journal of Xinjiang University (Natural Science Edition), 2017, 34(1): 90-95.)
[12] XU J L, CHEN Z H, TANG J, et al. T-Storm: traffic-aware online scheduling in Storm [C]// Proceedings of the 34th IEEE International Conference on Distributed Computing Systems. Piscataway, NJ: IEEE, 2014: 535-544.
[13] 鄭麗麗,武繼剛,陳勇,等.帶權圖的均衡k劃分[J].計算機研究與發展,2015,52(3):769-776. (ZHENG L L, WU J G, CHEN Y, et al. Balancedk-way partitioning for weighted graphs [J]. Journal of Computer Research and Development, 2015, 52(3): 769-776.)
[14] SUN D W, ZHANG G Y, YANG S L, et al. Re-Stream: real-time and energy-efficient resource scheduling in big data stream computing environments [J]. Information Sciences, 2015, 319: 92-112.
[15] GHADERI J, SHAKKOTTAI S, SRIKANT R. Scheduling storms and streams in the cloud [J]. ACM SIGMETRICS Performance Evaluation Review, 2015, 43(1): 439-440.
[16] LIU Y, SHI X, JIN H. Runtime-aware adaptive scheduling in stream processing [J]. Concurrency and Computation: Practice and Experience, 2016, 28(14): 3830-3843.
[17] CARDELLINI V, GRASSI V, LO PRESTI F, et al. Distributed QoS-aware scheduling in Storm [C]// Proceedings of the 9th ACM International Conference on Distributed Event-Based Systems. New York: ACM, 2015: 344-347.
[18] 熊安萍,王賢穩,鄒洋.基于Storm拓撲結構熱邊的調度算法[J].計算機工程,2017,43(1):37-42.(XIONG A P, WANG X W, ZOU Y. Scheduling algorithm based on Storm topology hot-edge [J]. Computer Engineering, 2017, 43(1):37-42.)
[19] ESKANDARI L, HUANG Z, EYERS D. P-Scheduler: adaptive hierarchical scheduling in Apache Storm [C]// Proceedings of the Australasian Computer Science Week Multiconference. New York: ACM, 2016: Article No. 26.
[20] ANIELLO L, BALDONI R, QUERZONI L. Adaptive online scheduling in Storm [C]// Proceedings of the 7th ACM International Conference on Distributed Event-Based Systems. New York: ACM, 2013: 207-218.
[21] MARZ N. Public stormprocessor/storm-benchmark [EB/OL]. (2012- 08- 20) [2017- 08- 10]. https://github.com/stormprocessor/storm-Benchmark.
[22] ZHANG M. Intel-hadoop/storm-benchmark forked from manuzhang/storm-benchmark [EB/OL]. (2015- 11- 02) [2017- 08- 10]. https://github.com/intel-hadoop/storm-benchmark.
This work is partially supported by the National Natural Science Foundation of China (61462079, 61562086), the Natural Science Foundation of Xinjiang Uygur Autonomous Region of China (2017D01A20), the Educational Research Program of Xinjiang Uygur Autonomous Region of China (XJEDU2016S106), the Graduate Research and Innovation Project of Xinjiang Uygur Autonomous Region of China (XJGRI2016028).
LULiang, born in 1990, Ph. D. candidate. His research interests include distributed computing, in-memory computing.
YUJiong, born in 1964, Ph. D., professor. His research interests include grid computing, distributed computing.
BIANChen, born in 1981, Ph. D., associate professor. His research interests include distributed computing, in-memory computing.
YINGChangtian, born in 1989, Ph. D.. Her research interests include in-memory computing, green storage.
SHIKangli, born in 1990, M. S. candidate. Her research interests include distributed computing, in-memory computing.
PUYonglin, born in 1991, M. S. candidate. His research interests include in-memory computing, green computing.
