基于3D卷積的視頻錯幀篩選方法
2018-05-25 08:50:55繆宇杰吳智鈞
計算機技術與發展 2018年5期
繆宇杰,吳智鈞,宮 婧
(1.南京郵電大學 物聯網學院,江蘇 南京 210003; 2.南京郵電大學 理學院,江蘇 南京 210003)
0 引 言
近年來,隨著深度學習的興起,諸如CNN等深度學習框架的提出,很多機器學習的問題得到了解決,比如在真實場景下的目標識別、人體行為分析等等。但是,其識別結果的精準度還是不能令人滿意,精準度的提高依然是深度學習領域一項具有挑戰性的任務。
好的視頻特征應該具備豐富的與識別內容相關的信息。視頻可以看作是一組連續幀,即靜態圖片。每張靜態圖片所提取的特征是獨立的、互不相關的,并且只存在于空間維度上。為了更好地提取視頻信息,有必要找到幀與幀之間的聯系。文中采用3D卷積的方法,能夠同時在時間和空間維度上提取視頻特征[1]。
要正確提取視頻的特征視頻,首要條件是必須保證幀序列有序。假設幀序列是無序的,那么根據該序列所提取的特征很有可能是不準確的,利用這樣的特征來訓練或者測試深度學習的模型,很可能會導致最終結果的誤判。所以,驗證幀序列是否有序是一項很重要的任務。
文中提出一種方法來驗證視頻幀序列的順序。首先,提出錯幀篩選模型,描述了其整體結構;其次,對該模型的主要技術關鍵點進行詳細介紹;最后,通過實驗對該方法進行驗證。
1 相關研究
機器學習[2]分為有監督和無監督兩個類,基本上可以從它們會不會得到一個特定的標簽輸出來區分。監督學習(supervised learning)是通過已有的訓練樣本(即已知數據及其對應的輸出)來訓練,從而得到一個最優模型,再利用這個模型將所有新的數據樣本映射為相應的輸出結果,對輸出結果進行簡單的判斷從而實現分類的目的。那么這個最優模型也就具有了對未知數據進行分類的能力。而無監督學習(unsupervised learning)[3]事先沒有任何訓練數據樣本,需要直接對數據進行建模。無監督學習在學習時并不知道其分類結果是否正確,亦即沒有受到監督式增強(告訴它何種學習是正確的)。其特點是僅對此種網絡提供輸入范例,且自動從這些范例中找出其潛在類別規則。當學習完畢并經測試后,也可以將之應用到新的案例上。
現有的大多數深度學習模式識別方法通常由兩個關鍵步驟組成:第一步是手工標注數據集的特征,第二步是在已標注的特征基礎上學習分類器[4-7]。但是,手工標注作為有監督學習的特點之一正變得越來越不受歡迎,原因是耗費了大量的時間和精力,尤其在數據集更加復雜的情況下,手工標注的代價成倍增長。因此,文中采用無監督學習的方法來學習沒有經過手工標注的視頻特征。
2 錯幀篩選模型
文中的目標是通過錯幀篩選模型,從若干組幀序列中,將錯誤的一組幀序列篩選出來。從同一個視頻中采樣出若干組視頻幀序列(詳見3.1小節),假設有N+1組幀序列,那么此模型的輸入可表示為f={f1,f2,…,fN+1,其中,fi為第i組幀序列。在這組輸入中,有N組幀序列是有序的,只有一組幀序列是錯序的,且這組錯幀的位置隨機。
將f的每一組幀分別輸入錯幀篩選模型的一個分支,如圖1所示。首先對其進行編碼(詳見2.2小節),編碼后每個分支會通過5個卷積層和1個全連接層,這一部分與AlexNet[13]相同。每個分支網絡的權值以及參數均相同。

圖1 錯幀篩選模型

將上述計算結果輸入最后兩個全連接層和一個線性分類器,這個分類器能夠對N+1個輸入進行分析對比,進而預測出錯幀的一組視頻序列。
3 關鍵技術
3.1 視頻幀采樣
視頻幀的采樣也是一項非常重要的工作,具有良好特性的幀序列有助于預測結果精準度的提升。如果采樣的幀序列之間的變化很小,那么很難判斷出這組幀序列是順序還是亂序。圖2所示為一組有序的視頻幀,幀a和b、幀e和f之間的動作變化很小,而幀b、c、d、e之間差別很明顯。由圖2易知,很難判斷{a,b,c}、{b,a,c}哪組是亂序,但{c,d,e}、{e,c,d}很容易判斷,因此需要選取幀間差異較大的幀作為輸入。使用粗幀級光流[14]來測量幀與幀之間的變化程度,把每個幀的平均流量大小作為該幀的權重,并用它來偏置采樣較大變化幀的窗口。此方法保證了采樣的幀序列不會出現難以分辨是否為錯幀的情況。

圖2 幀間差異示例
設采樣結果為I=I1,I2, …,In這樣一組包含n幀的視頻序列,且有序,即I1I2…In。在上述的采樣結果I中,還需要再進行一次采樣作為錯幀篩選模型的輸入。在這個步驟中,采用了隨機采樣的方法。在I中隨機采樣出X幀圖像N次,則產生了N組有序的幀序列,每組有X幀。亂序的幀序列的采樣也是隨機采樣X幀,并保證亂序。
3.2 視頻幀編碼
在完成視頻幀采樣之后,需要對每一組幀序列進行編碼,編碼的目的是提取幀序列的結構信息。完成編碼后,可以將多幀圖片合并為一幀。這樣做的好處是在訓練錯幀篩選模型時,不需要限定每組輸入的幀數,因為不論每組輸入的幀數是多少,通過編碼都可以提取為一幀的信息。
文中采用3D卷積[15]的方法進行編碼。在2D CNN中,2D卷積在卷積層具有提取局部鄰域上層特征映射的功能。坐標為(x,y)的單元在第i層的第j個特征映射的值為:
成本有效是指成本可以被收益補償。再生水項目的投資較大,而再生水水價一般需要維持在低于甚至遠低于飲用水水價的水平,因此再生水項目實現成本有效性面臨很大困難。除了選擇有利的技術方案以降低成本外,爭取到撥款和優惠利率的長期貸款對于降低成本也很重要,而用戶收費(包括使用費和入戶管網費等)也必須有保障。成本有效是再生水項目作為公用事業實現商業化運作的前提。
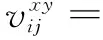
(1)
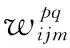
2D CNN中的特征映射也是2D的,只反映了圖像空間上的信息,沒有考慮時間上的信息。文中采用3D CNN中的3D卷積方法,在卷積層的特征映射連接了上一層多幀連續圖像,這樣既包含了空間信息,也包含了時間信息,從而可以獲取一組幀序列的信息。則式1可以改寫為:

(2)
其中,Ri是3D卷積核在時間維度上的大小。
在視頻幀編碼中只進行了一次卷積運算,然后對一組幀序列的特征映射求均值,結果即為編碼的結果。
4 實驗結果與分析
使用UCF101數據集進行實驗。UCF101數據集是由真實用戶拍攝上傳的具有復雜背景的視頻,共有101個動作類別,13 000個視頻片段,時長共27小時。
實驗中,從同一個視頻片段中采樣7組幀序列,其中6組是有序的,1組是無序的。每組幀序列有7幀圖像,大小為80*60,卷積核大小為7*7*3(7*7表示空間維度,3表示時間維度)。將幀序列輸入網絡,首先對幀序列進行編碼,編碼結果如圖3所示。

圖3 幀序列編碼結果
為了驗證該方法的有效性,將實驗獲得的驗證錯幀結果的準確性與文獻[12]比較,結果如表1所示。從表1可見,文中方法提高了對錯幀檢驗的準確性。
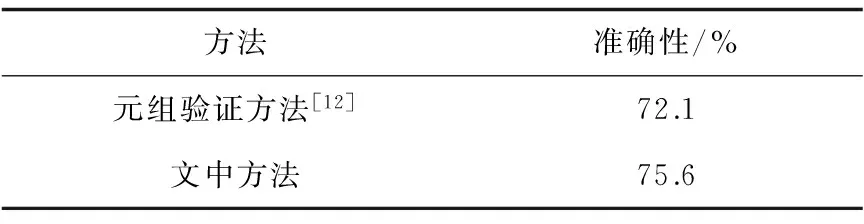
表1 不同幀順序驗證方法準確性對比
5 結束語
文中提出了一種基于3D卷積的視頻幀順序驗證方法,能夠對視頻幀序列順序與否進行驗證。通過無監督學習視頻特征的方法,避免了有監督學習中所需的手工標注標簽的過程,很大程度上減少了時間與精力的耗費。3D卷積對視頻序列特征的提取,不僅獲取了該序列空間上的信息,同時獲取到了時間上的信息,提升了驗證的準確性。
參考文獻:
[1] 林海波,李 揚,張 毅,等.基于時序分析的人體運動模式的識別及應用[J].計算機應用與軟件,2014,31(12):225-228.
[2] 郭麗麗,丁世飛. 深度學習研究進展[J].計算機科學,2015,42(5):28-33.
[3] 殷瑞剛,魏 帥,李 晗,等.深度學習中的無監督學習方法綜述[J].計算機系統應用,2016,25(8):1-7.
[4] 王滿一,宋亞玲,李 玉,等.結合區域光流特征的時序模板行為識別[J].系統仿真學報,2015,27(5):1146-1151.
[5] JHUANG H,SERRE T,WOLF L,et al. A biologically inspired system for action recognition[C]//International conference on computer vision.Rio de Janeiro,Brazil:IEEE,2007:1-8.
[6] 楊祎玥,伏 潛,萬定生.基于深度循環神經網絡的時間序列預測模型[J].計算機技術與發展,2017,27(3):35-38.
[7] 徐慶伶,汪西莉.一種基于支持向量機的半監督分類方法[J].計算機技術與發展,2010,20(10):115-117.
[8] DOERSCH C,GUPTA A,EFROS A A.Unsupervised visual representation learning by context prediction[C]//International conference on computer vision.[s.l.]:IEEE,2015.
[9] 朱 陶,任海軍,洪衛軍.一種基于前向無監督卷積神經網絡的人臉表示學習方法[J].計算機科學,2016,43(6):303-307.
[10] PICKUP L C,PAN Z,WEI D,et al.Seeing the arrow of time[C]//IEEE conference on computer vision and pattern recognition.Columbus,OH,USA:IEEE,2014:2043-2050.
[11] JAYARAMAN D,GRAUMAN K.Learning image representations tied to ego-motion[C]//International conference on computer vision.Santiago,Chile:IEEE,2015:1413-1421.
[12] MISRA I,ZITNICK C L,HEBERT M.Shuffle and learn:unsupervised learning using temporal order verification[C]//European conference on computer vision.Berlin:Springer,2016:527-544.
[13] JEFF D,JIA Yangqing,VINYALS O,et al.DeCAF:a deep convolutional activation feature for generic visual recognition[C]//International conference on machine learning.Beijing,China:ACM,2014.
[15] JI Shuiwang,XU Wei,YANG Ming,et al.3D convolutional neural networks for human action recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2013,35(1):221-231.
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
人大建設(2020年4期)2020-09-21 03:39:12
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
