基于數據挖掘的圖書館讀者借閱系統設計
2018-06-12 06:41:20閻星宇
現代電子技術 2018年12期
關鍵詞:數據挖掘
閻星宇
摘 要: 分析圖書館讀者借閱對提高圖書借閱率、統計圖書量具有重要意義。傳統圖書館讀者借閱系統主要通過以往讀者借閱信息對圖書借閱率、圖書量所需增減情況進行分析,忽略了圖書庫存量對讀者借閱率的影響。為此,提出并設計基于數據挖掘的圖書館讀者借閱系統。在分析其整體結構的基礎上,給出詳細的硬件設計過程,引入數據挖掘方法,實現對軟件部分的設計。實驗結果表明,采用改進圖書館讀者借閱系統可實現圖書的高速借閱,提高借閱率及借閱準確度,具有一定的實用性。
關鍵詞: 數據挖掘; 圖書借閱率; 讀者借閱信息; 借閱系統; 圖書庫存量; 系統設計
中圖分類號: TN919.25?34 文獻標識碼: A 文章編號: 1004?373X(2018)12?0180?03
Abstract: Library reader borrowing analysis is of great significance in improving the borrowing rate of books and obtaining the quantity of books. The traditional library reader borrowing system mainly analyzes the increase and decrease demand of book quantity and book borrowing rate according to the past borrowing information of readers, which ignores the impact of book inventory on the reader borrowing rate. Therefore, a library reader borrowing system based on data mining is proposed and designed. On the basis of analyzing its overall structure, the detailed hardware design process is given, and the data mining method is introduced to realize the design of the software part. The experimental results show that the improved library reader borrowing system can achieve the high?speed borrowing of books, and improve the borrowing rate and borrowing accuracy, which has a certain practicability.
Keywords: data mining; book borrowing rate; reader borrowing information; borrowing system; book inventory; system
design
0 引 言
圖書館作為搜集、整理、收藏圖書資料供人閱覽、參考的機構,是知識文化傳播的重要陣地,也是圖書信息聚集和分散的主要場所。其資料繁多,內含大量的信息數據。當前,圖書館內圖書數量的逐年遞增,在如此龐大的圖書規模中找到讀者感興趣的書籍非常困難。傳統圖書館讀者借閱系統存在借還流程長、盤點和查找工作繁瑣、借閱和安全脫節、圖書管理員與讀者的滿意度低、條形碼技術缺陷等問題,已經不能滿足現有圖書管理的需求,且搜索功能的不強大,搜索結果眾多,讀者發現在自己感興趣的書籍十分困難[1]。在這種情況下,研究并設計一種能夠整合讀者行為數據,讀者興趣愛好的新圖書館讀者借閱系統,成為該領域亟待解決的問題。對此,本文結合數據挖掘,根據讀者已有的歷史信息智能分析讀者的興趣愛好,運用數據挖掘技術全面、準確地給讀者推薦滿意的書籍,幫助讀者完成快速借閱圖書。
1 借閱系統整體結構分析
本文設計的圖書館讀者借閱系統主要由圖書借還模塊、圖書管理模塊、讀者管理模塊、圖書盤點模塊和賬戶管理模塊組成,最終結果在顯示器顯示借閱結果。為了提高借閱系統的借閱率及圖書推薦準確度[2],在其控制層添加數據挖掘的功能,通過實現對圖書數據進行挖掘,縮短查找圖書所用時間,提高借閱率。其圖書館讀者借閱系統整體結構如圖1所示。
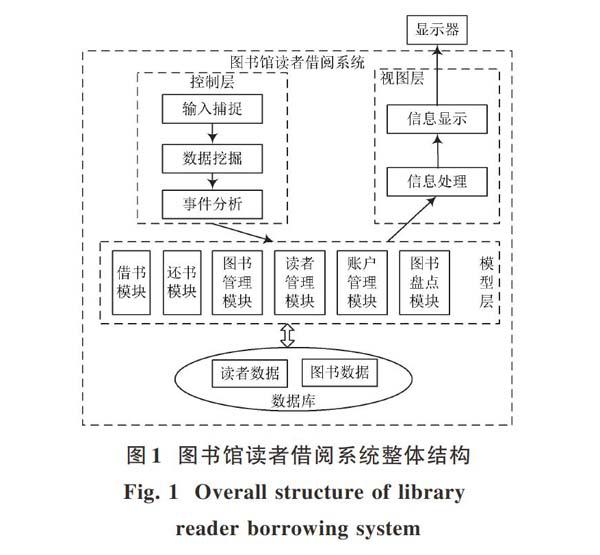
由圖1可知,系統通過讀者輸入要求對其內容在控制層進行判斷,合理調度處理功能模塊。在模塊中進行借書、還書、圖書管理、讀者管理、圖書盤點模塊及賬戶管理等功能[3]。而視圖層為讀者提供出錯處理及借閱信息的顯示,出錯處理負責處理出錯信息,并將出錯信息返回給讀者。整體圖書借閱系統啟動并初始化以后進入到主界面等待讀者的輸入,當用戶輸入圖書信息時,首先要確定讀者的身份[4],確認完畢方可進行下一步圖書借閱。每個子系統的界面都會為各種功能模塊提供使用方法,控制層在對讀者輸入的信息進行判斷,調用相應的模型處理輸入信息。
2 硬件部分設計
在硬件設計過程中,主要對借書模塊、讀者管理模塊、數據庫及控制層進行設計分析,具體步驟如下:
1) 借書模塊主要通過讀者及管理員兩部分進行使用。圖書管理員借閱是對讀者借閱圖書的記錄進行管理,主要包括查詢超期的讀者、催促讀者還書等。通過不同列表的不同數據,在超期記錄中向用戶發送催還信息,在預約記錄中向讀者發送預約信息,為了避免記錄過多,可在當天或前兩天進行記錄[5]。圖書管理員可以使用該模塊實現對書庫中圖書情況進行查詢,也可通過圖書借閱實現讀者對圖書的借閱及續借[6]。

2) 讀者管理主要目的是為管理人員提供讀者類別、讀者信息、借書卡等日常維護管理。其中讀者類別主要是對讀者信息進行查詢、增加、修改及刪除等。讀者信息管理主要對讀者進行查詢、增加、修改及注銷。借書卡管理主要是辦理借書卡或者對借書卡進行掛失、注銷[7]。整體的讀者管理部分由讀者管理員進行負責,對讀者進行管理時,管理員身份需要驗證,并在系統初始化部分對讀者信息進行分類及對讀者類型進行添加[8]。讀者類型的添加也是挖掘讀者信息的前提條件,讀者管理員可以根據實際需求調整是否對新的讀者類型進行添加或對已有讀者類型進行修改、刪除。
3) 數據庫設計。為了更好地與借書模塊結合,系統的用戶采用r_user表,及外擴的sys_role,讀者角色關聯表sys_user_role,菜單表sys_menu[9],角色菜單關聯表sys_role_menu等輔助表。
4) 控制層設計。在控制層添加數據挖掘的功能形成數據倉庫,將挖掘的圖書相關數據存儲在數據倉庫中。而數據倉庫主要是為管理決策模式的設置提供對應支持信息,用于讀者數據處理的決策支持,主要處理方式以挖掘分析為主。其與數據庫的區別為數據庫直接與日常操作處理數據相關,數據倉庫主要是應用于高層決策分析,主要來源于對數據庫的日常業務操作[10],主要為圖書借閱系統提供讀者決策支持的當前及歷史數據。數據倉庫可有效地把操作數據集成在統一的環境中,為讀者提供決策型數據,并對其余模塊進行訪問。圖書數據挖掘的引入可讓讀者更快、更方便地查詢所需圖書信息,縮短查詢圖書所用時間,提高借閱率。
3 軟件部分設計
在軟件設計部分,主要針對借書流程進行分析,其實現流程如圖2所示。其中,查詢借書量是從讀者借閱數據庫里查找讀者借書量的信息,加入借書量為該圖書館賬戶借書量的最大值時,則進行報錯提示,重新進行其他書籍的借閱;反之,假如借書量未達到最大值,則從圖書數據庫中搜查該書是否有足夠的庫存,有則借閱成功,同時進行圖書數據庫更新。由圖2可知,流程開始后,首先通過用戶數據挖掘確定用戶信息,通過挖掘圖書數據確定圖書信息;其次檢驗讀者身份;然后調用借書模塊功能完成對圖書庫出借信息的填寫(此步驟顯示借書量是否已經達到、圖書庫存是否為空,若均存在顯示報錯,退出借書流程,重新進行借書);最后將借書結果顯示在顯示器上,即圖書借閱成功(此步驟與借閱成功后對圖書庫信息的更新同步進行)。
4 系統驗證
為了驗證改進系統在圖書館讀者借閱圖書時的有效性,設置其開發環境為eclipse 5.8, apache?tomcat 6, MySQL?9,后臺開發框架為Spring Framework 6.0, Spring MVC 4.0, MyBatis 3.2+; 前臺開放框架為Jquery 1.9, Twitter Bootstrap 2.3.1。采用傳統借閱系統與改進借閱系統為對比,以圖書借閱耗時及圖書借閱準確率為指標進行實驗分析,結果如表1所示。
從表1可知,在圖數量一定的情況,采用傳統借閱系統時,其借閱耗時隨著借閱圖數量的增加逐漸增大,最高時達到了350 s,最低時耗時為120 s;其圖書借閱準確度也隨著圖書量的增加而增加,但其準確度出現了忽高忽低的現象,不穩定,最高時為90%,最低時為50%;相比傳統方法,采用改進方法時,其借閱耗時及準確度均隨著圖書數量的增加而延長,但未出現忽高忽低的現象,穩定性較好。耗時最高為61 s,最低為8 s,節約時間最高289 s,最低112 s,準確度最高為99%,最低為89%,最多提高了39%,最少提高了9%,具有一定的實用性。
5 結 論
本文研究圍繞傳統借閱系統存在因借閱耗時長導致的借閱率低、準確性差的問題,提出并設計了基于數據挖掘的圖書館讀者借閱系統,得到結果如下:通過控制層構造出讀者對圖書的借閱信息,并利用數據挖掘算法對讀者信息進行挖掘,減少搜索空間,降低借閱耗時;通過驗證發現,相比傳統借閱系統,改進系統的圖書借閱率及圖書借閱準確率均有提高。
參考文獻
[1] 韓吉義.基于數據挖掘技術的高校圖書館檔案信息管理平臺的構筑[J].山西檔案,2015(6):61?63.
HAN Jiyi. Data?mining technology based construction of archival information management platform for university libraries [J]. Shanxi archives, 2015(6): 61?63.
[2] 茹文,忻展紅.圖書館借閱數據分類信息的關聯性研究[J].北京郵電大學學報(社會科學版),2016,18(1):14?19.
RU Wen, XIN Zhanhong. Associations between different classifications of library circulation data [J]. Journal of Beijing University of Posts and Telecommunications (Social sciences edition), 2016, 18(1): 14?19.
[3] 賴劍菲,江舟.基于WLAN的圖書館讀者行為采集分析平臺框架研究[J].圖書情報工作,2015(10):67?71.
LAI Jianfei, JIANG Zhou. Study on collection and analysis platform framework of library readers′ behaviors based on WLAN [J]. Library and information service, 2015(10): 67?71.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
