基于作者主題模型和輻射模型的用戶位置預測模型
2018-06-20 06:16:54劉嘉勇
計算機應用 2018年4期
李 琰,劉嘉勇
0 引言
隨著移動設備的廣泛應用以及定位技術的發展,基于位置的服務(Location Based Service, LBS)越來越受到社會各界的關注[1]。目前,LBS獲得的位置信息僅限于移動用戶的當前位置,這使得為用戶提供的服務缺乏可預見性。為了提高LBS的服務質量,對用戶未來位置的預測已成為近年來的研究熱點。事實上,良好準確的位置預測算法不僅可以讓LBS中的商家根據預測結果挖掘潛在的客戶進行商品推送,而且能幫助用戶利用商家的精準推送從海量商品中進行高效選擇,從而獲得更好的用戶體驗[2]。
文獻[3]研究了一種基于變階的Markov位置預測模型,該模型預測能力高于標準Markov模型;但此類算法通常存在數據稀疏問題,因此憑借單個用戶的歷史軌跡數據構建狀態轉移矩陣的Markov位置預測模型準確率不高。文獻[4]用已有的先驗知識,為用戶建立個性化的位置推理模型,一定程度上解決了數據稀疏的問題;但該方法實現過程復雜,適用范圍狹窄。文獻[5]中提出了在空間維度上基于輻射模型的位置預測方法,提高了預測的準確率;但該方法對地點的吸引力定義不準確,并且在時間維度上只考慮了單個用戶的行為規律,限制了模型的預測能力。
針對上述問題,本文提出在時間維度上利用作者主題模型(Author Topic Model, ATM)[6]自動地發現與目標用戶移動行為相似的用戶群,根據用戶群的行為規律來優化個人的行為規律模型,以解決數據稀疏的問題,并擴大預測模型的適用范圍;在空間維度上對基于輻射模型的空間預測方法[5]進行了改進和優化,最后通過大量實驗和實際數據集測試,驗證了該預測模型的有效性。
1 本文模型
本文提出的位置預測模型基于人類移動具有強規律性,文獻[7-8]指出可以將人類有強周期性的移動看作往返于“家庭”和“工作”位置狀態之間。如圖1所示:圖1(a)展示用戶在一天時間內處于家庭/工作位置狀態的概率分布;圖1(b)描述在家庭/工作位置狀態下用戶簽到數據在地理空間上的分布情況。其中,圈和叉分別表示在家庭位置狀態和工作位置狀態下用戶的簽到數據,圖1(b)中圈圍成區域是工作位置狀態區域,而叉圍成的則是家庭位置狀態區域。

圖1 用戶周期性移動規律展示圖
本文模型操作流程如圖2所示:
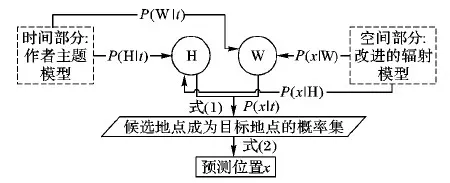
圖2 模型預測流程
1)在時間維度上,先依據作者主題模型自動地發現用戶在移動行為規律上相似的群體,然后計算在時刻t相似用戶群在位置狀態(家庭H/工作W)的概率,即用戶的概率p(H|t)和p(W|t)。
2)在空間維度上,對文獻[5]中提出的基于輻射模型的空間預測進行改進,對用戶的家庭和工作位置狀態區域進行單獨的輻射模型訓練,并計算在t時刻,用戶的候選簽到地點集Venues分別在H和W位置狀態區域成為簽到地點x的概率p(x|H)和p(x|W),其中Venues指在所有用戶位置數據中出現過的地點。
3)綜合以上結果,根據式(1)計算得到Venues成為簽到地點x的概率p(x|t),比較候選地點的概率大小,取概率值最大的地點作為預測的簽到地點x,如式(2)所示:
p(x|t)=p(x|H)·p(H|t)+p(x|W)·p(W|t)
(1)
x=arg max{p(x|t),x∈Venues}
(2)
2 基于作者主題模型的時間-位置狀態預測
作者主題模型是一個級聯生成模型[9],它是隱含狄利克雷分布(Latent Dirichlet Allocation, LDA)[10]結合元數據作者的衍生模型,可以解決計算作者間的相似度問題。
基于作者主題模型(ATM)的時間-位置狀態預測模型憑借用戶歷史簽到數據訓練ATM后自動發現用戶在移動行為規律上相似的群體,然后用ATM訓練結果中權重排名前N的表示用戶位置狀態轉移的詞去描述該群體的移動行為規律,最后依據群體的行為規律以及本文提出的時間-用戶位置狀態概率算法得到在時間t用戶處于位置狀態(H/W)的概率。模型實現流程如圖3所示。
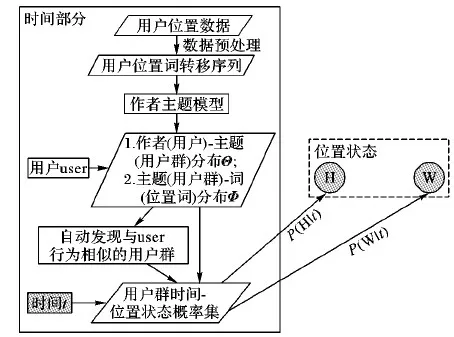
圖3 時間-位置狀態預測模型實現流程
2.1 位置數據預處理
位置數據預處理主要是將用戶每天的原始簽到數據表示為由48個位置詞按照時間先后順序構成的位置詞轉移序列[11]。位置詞用來表示用戶在某時段的位置狀態轉移過程,包含3個連續位置標簽和1個時間段標簽,位置標簽標記簽到位置所處的位置狀態區域,時間段標簽用簽到時間對應的時段標記,例如:位置詞HHH1,其位置標簽是HHH,時間段標簽是1,它表示用戶在時間段1的位置轉移是HHH,即在時段1該用戶一直在家庭位置狀態區域活動。本節的位置數據表示可分為以下三個步驟:
1)確定簽到位置數據集中每個位置的標簽,即根據用戶在訪問位置的時間空間分布規律,確定該位置所處的位置狀態區域(H:家,W:工作,O:其他,N:缺失數據)。
2)確定用戶每天的位置標簽轉移序列。位置標簽轉移序列的定義與位置詞轉移序列的類似,它是由48個位置標簽按照時間先后順序構成的轉移序列。本文以30 min作為劃分時間單位,將一天劃分為48個時間塊,對于每個時間塊,選擇用戶停留時間最長的位置作為用戶在該時間塊的停留位置,從而確定該時間塊的位置標簽,以此便形成用戶每天的位置標簽轉移序列。
3)確定用戶每天的位置詞轉移序列,即先從用戶每天的位置標簽轉移序列中從頭依次取3個連續位置標簽,然后由步驟2)可知,3個位置標簽跨越1.5 h,通過時間累加的計算可得到它們對應的時段,取包含位置標簽多的時段為位置詞的時段標簽,進而結合3個連續位置標簽和對應的時段標簽得到一個完整的位置詞。以此類推,可獲得48個位置詞,并按照時間先后順序構成位置詞轉移序列。本文將人的一天分為8個時間段:1)00:00—07:00;2)07:00—09:00;3)09:00—11:00;4)11:00—14:00;5)14:00—17:00;6)17:00—19:00;7)19:00—21:00;8)21:00—24:00。
2.2 用戶-用戶群模型的生成
用戶-用戶群模型是作者主題模型在本文的應用,本文憑借該模型來自動發現與目標用戶在移動行為規律上相似的用戶群體。
在用戶-用戶群模型中,每個位置詞w和兩個潛在變量(用戶u和用戶群g)相聯系。如圖4所示,該模型的生成過程包括兩個步驟:1)挑選一個用戶u和一個用戶群g;2)根據用戶-用戶群概率分布Θ和用戶群-位置詞概率分布Φ生成位置詞w。其中α和β是模型的先驗參數[9]。
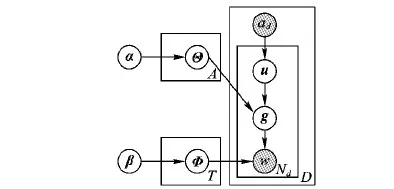
圖4 用戶-用戶群模型的概率圖模型
憑借所有用戶的位置詞轉移序列數據訓練用戶-用戶群模型,得到參數Θ和Φ。從圖4中用戶-用戶群的概率圖模型易知,有以下條件概率:
P(w|A,α,β)=?P(w|A,Θ,Φ)P(Θ,Φ|α,β)dΘdΦ
(3)
其中:Θ表示用戶-用戶群概率分布;Φ表示用戶群-位置詞概率分布;A表示位置數據集中的用戶。當Θ和Φ被看作隨機變量時,位置數據集的邊緣概率可以通過對它們進行積分得到。一些估計推斷方法可用來估計級聯貝葉斯模型的后驗分布,本節采用吉布斯采樣[10]來進行推斷,從而獲得參數Θ和Φ的值。其推導過程如下:
在用戶群G數量固定時,θ和φ的條件下w的概率可以表示為:
(4)
同時,可以得到每個位置詞轉移序列中的位置詞wd的概率:
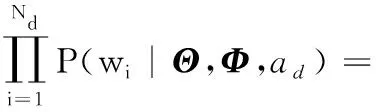
(5)
根據式(4)和(5),式(3)可表示為:
P(w|A,α,β)=
考慮到這里采用離散隨機變量和多項式分布,位置詞集的分布可以進一步轉換為向量u、g的所有可能組合的和形式,因此,式(4)可以轉換為如下形式:
P(w|A,α,β,G)=
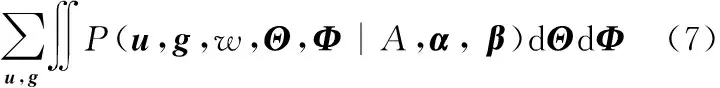
其中:
P(u,g,w,Θ,Φ|A,α,β)=
(9)

對式(8)中的Θ和Φ進行積分可得:
P(u,g,w|A,α,β)=
(10)
根據吉布斯采樣,需要估計P(u,g|Dtrain,α,β)。其中,Dtrain為訓練數據中的用戶和位置詞集合。根據貝葉斯準則,吉布斯采樣可以使用如下條件分布:
P(ui=a,gi=t|wi=w,u-i,g-i,w-i,A,α,β)=
(11)
可以得到:
P(ui=a,gi=t|wi=w,u-i,g-i,w-i,A,α,β)∝
(12)
在第s次采樣中,在用戶群gN+1=G條件下位置詞wN+1=W的概率為:
(13)
同樣,在用戶uN+1=a條件下用戶群gN+1=t的位置詞概率為:
(14)
通過上述的吉布斯采樣過程可以對參數Θ和Φ的值進行估計。
2.3 相似用戶群體的發現
本文用100名用戶的位置數據訓練用戶-用戶群模型,并將用戶群數設定為50,然后根據模型估計的參數Θ和Φ,選擇用戶群5、20和28按指定概率排序,得到的結果如表1~2所示。本文使用2.2節生成的模型自動地發現相似用戶群以及他們的特征路徑。在表1中,如用戶群5所示,排名靠前的位置詞大多都包含工作標簽W,這說明與用戶群5移動行為相似的用戶(如:用戶10)工作時間較長,且工作時間集中在4~6時間段。如表2所示,用戶16和19與用戶群20相似,從表1中可知,他們2、7、8時間段在家,并在4和5時間段處于工作狀態。以此類推,可以發現用戶11和8在1和8時間段處于家庭位置狀態,4~6時間段在工作并且在時間段8回家。再者,用戶群20的工作時間比用戶群5和28的工作時間短,可推測對于與用戶群5相似度高的用戶(如:用戶10和5),他們的工作量比與用戶群20相似度高的用戶(如:用戶16和19)大。

表1 不同用戶群中按 P(w|g)排序排名前9的位置詞

表2 不同用戶群中按 P(g|u)排序排名前4的用戶
如圖5所示,用戶10的移動行為規律主要與用戶群30相似,而用戶13與多個用戶群相似。由此可知,用戶10在行為移動方面的生活方式是幾乎不變,而用戶13可能具有高度變化的生活方式。此外,還可以發現,圖6中所有用戶排名前三相似用戶群的概率之和都大于0.5,并且大約有1/3用戶的概率接近1,這說明用戶的行為移動模式可以憑借其排名前三的相似用戶群行為規律共同去描述。
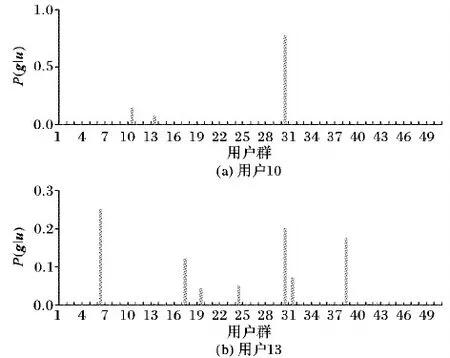
圖5 不同用戶的相似用戶群概率分布

圖6 所有用戶排名Top3用戶群的概率和分布
2.4 時間-用戶位置狀態概率算法
時間-用戶位置狀態概率算法是用來計算在指定時間t用戶處于位置狀態(H/W)概率的算法,該算法的實現步驟如下:
1)根據2.2節訓練模型得到的參數Θ定位到與用戶相似排名前N的用戶群以及相應的概率user_sim_ug。
2)通過參數Φ和user_sim_ug可獲得目標用戶相似用戶群分別在8個時段中概率最大的位置詞以及計算相應概率p_i。
3)最后計算出目標用戶在時間t所處的位置狀態的概率p(S|i)。
概率p_i和p(S|i)的計算公式如下:
p_i=p_g·p_l;i∈[1,8]
(15)

S∈{H,W},i∈[1,8] (16)
其中:p_i為i時段概率最大位置詞的概率;p_g是目標用戶屬于用戶群g的概率;p_l是i時段概率最大位置詞在Φ中的概率;p(S|i)是目標用戶在i時段時位置狀態為S的概率;count_S是i時段用戶位置詞中包含S的數值;l_word是位置詞的長度。另外,根據圖6的結果,說明用戶的行為移動模式可以用其排名前三的相似用戶群行為模式共同去描述,所以,本文將排名前N位設定為前3位。
3 基于輻射模型的位置狀態-候選地點預測
3.1 基于輻射模型的空間預測模型
輻射模型最初用于對移動性和遷移模式的建模[12],該模型用于計算彼此距離r處的位置i和j之間的流動強度Tij(位置i、j分別具有群體m和n),如式(17)[13]所示:
(17)
其中:Ti是離開位置i的用戶總數;sij是以i為中心、半徑為rij的圓中的用戶總數(該數不包括在位置i和j上停留的用戶數)。
文獻[5]中提出在空間預測建模上對家庭H和工作W位置狀態區域進行單獨的輻射模型訓練,他們假設在每個位置狀態區域中有一個中心地點,即用戶經常簽到的地點并且用戶通常從該地點移動到同一區域內的不同候選地點,其中候選地點指在所有用戶位置數據中出現過的地點。例如,用戶工作地點即可視為W區域的中心地。在他們的研究中,假設移動僅在中心地點與其他地點之間發生,對于給定的區域,在j簽到的概率等于用戶從中心地i移動到地點j的概率,如式(18)所示:
(18)
其中:n代表地點j的吸引力。文獻[5]將它定義為在所有用戶位置數據集中在該地點進行簽到的總次數。m與n的定義相同,但m僅用于代表家庭或工作中心地點i的吸引力。然而,地點的吸引力越大,其成為用戶簽到地點的概率也就越大。
3.2 基于輻射模型的位置狀態-候選地點預測模型
位置狀態-候選地點預測模型是在文獻[5]中提出的空間預測模型上進行改進得到,具體模型實現流程如圖7所示。
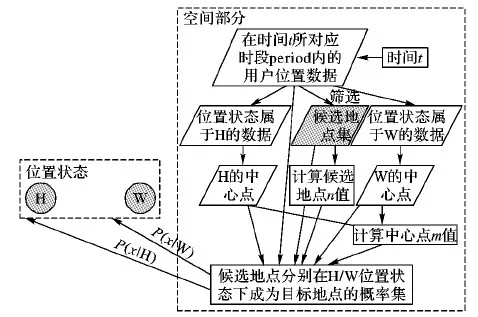
圖7 位置狀態-候選地點預測模型流程
文獻[5]將地點的吸引力n定義為所有用戶在該地點進行簽到的總次數,本文作者認為該定義存在不合理性。假設研究對象是在學校區域內活動的用戶群體并在此基礎上計算學校食堂的吸引力n值,眾所周知,目標群體在學校食堂簽到的總次數較多,按文獻[5]對n的定義來計算食堂的吸引力n,必然得到的結論是:無論何時,食堂的n值大。實際上,在非就餐時間食堂處于關閉狀態,它的吸引力n大大降低,這與根據n的原定義得出的結論矛盾。因此,本文加入時間因素更準確地定義n為:在指定時間所屬時段所有用戶在該地點進行簽到的總次數。最后通過實驗驗證了這種改進方法的有效性。具體確定地點n值的改進算法偽代碼如算法1。
算法1get_N():獲得地點的n值。
輸入 指定時間t,check_in_dataset(用戶位置數據集)。
輸出n。
確定時刻t所處的時段i(i∈[1,8]);
從check_in_dataset中篩選出屬于i時段的簽到數據,并存入check_in_period中;
fordataincheck_in_perioddo
從data中找到不同的簽到地點venues;
forvenueinvenusdo
對venue進行計數,再將相應的值存入n[venue]中;
endfor
endfor
returnn;
4 實驗與分析
4.1 數據及評價標準
本文采用美國著名LBS網站Gowalla的簽到數據集來進行用戶位置預測。其中,本文選取的實驗數據集包含2009年8月3日—11月10日90天共1萬多用戶的60多萬條位置數據。從數據集中抽取較活躍的100名用戶進行實驗。每條簽到數據包括用戶移動設備串號、簽到id、簽到時間、簽到點經度以及簽到點緯度。
對于每個用戶的位置數據,將其80%數據設定為訓練集,剩余20%設定為測試集,并采用準確率來評判位置預測算法的有效性。
驗證步驟如圖8所示。
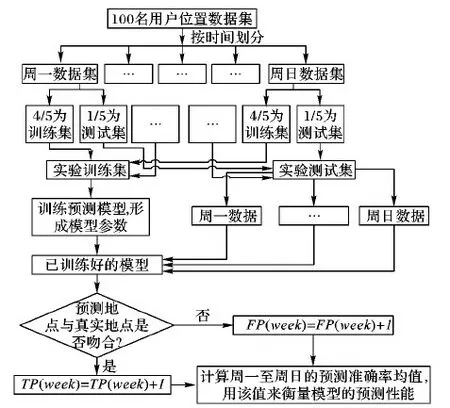
圖8 算法驗證步驟流程
本文采用準確率作為評價標準。
準確率是指預測正例與預測樣本的比例,是廣泛用于信息檢索和統計學領域的度量值,用來評價結果的質量。其計算公式如下:

(19)
表3是兩分類器混淆矩陣(confusion matrix)。

表3 兩分類混淆矩陣
其中:TP表示實際為正類,實驗結果也為正類的樣本數量;FN表示實際為正類,實驗結果為反類的樣本數量;FP表示實際為反類,結果為正類的樣本數量;TN表示實際為反類,結果也為反類的樣本數量。
4.2 結果與分析
與本文模型對比的是文獻[3,5]模型。對比模型介紹如下:
模型A:文獻[3]中提出的基于變階的Markov模型,利用訓練好的變階Markov模型,根據文獻[3]已定義的公式結合該用戶當前所處的位置,來計算其出現在每一可能位置的概率,然后將概率最大的那個位置選作預測結果。
模型B:文獻[5]中提出的輻射模型(Radiation Model, RM),在空間維度上采用輻射模型,在時間維度上采用一維混合高斯模型,并綜合以上兩個維度來預測用戶位置。
模型C:本文提出的預測模型,在模型B的基礎上進行改進,在時間維度上改用基于ATM的時間-位置狀態預測模型。
模型D:本文提出的預測模型,在模型C的基礎上進行改進,在空間維度上采用本文改進的基于輻射模型的位置狀態-候選地點預測模型。
各個模型所有實驗用戶周一至周日預測準確率均值的對比結果如表4所示。
從表4可看出:1)本文模型C和D的平均預測準確率均優于對比模型;模型D的預測準確率高于C,這說明在空間維度上對模型C改進是有效的。本文提出的模型D的平均預測準確率比基于Markov的預測模型A[3]提高了近28個百分點,比同類型預測模型B[5]提高了近31個百分點。2)與模型A[3]相比,由于模型B、C、D的預測準確率受用戶移動規律性的影響且一般用戶在工作日的移動規律性強于周末,因而本文提出的模型更適用于預測在工作日中用戶的位置。
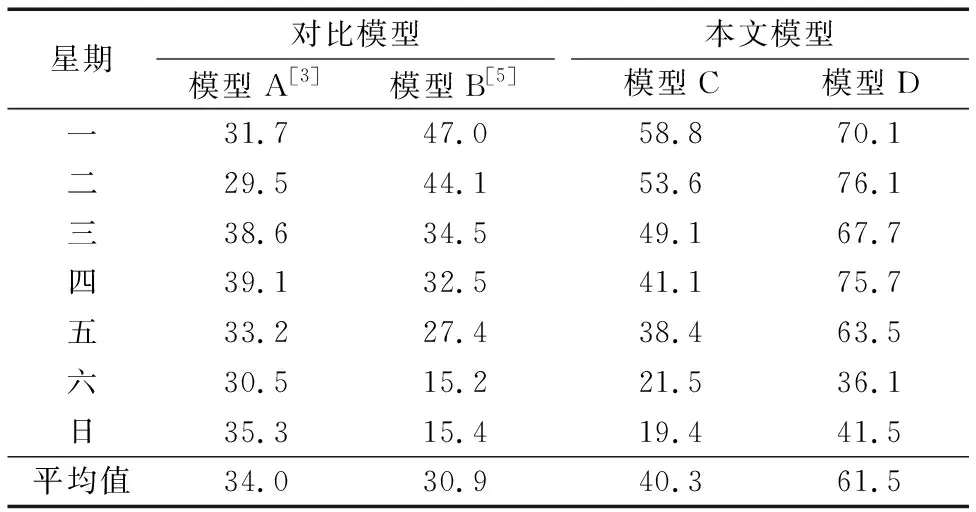
表4 各種模型的平均預測準確率 %
5 結語
本文從用戶歷史位置數據中研究了預測用戶位置的算法,提出一種基于作者主題模型和輻射模型的用戶位置預測模型。該模型在時間維度上,采用了作者主題模型訓練出用戶的兩個概率分布矩陣,依據矩陣可得到用戶在某時刻下的狀態(“家”或“工作”);在空間維度上,依據輻射模型得到在用戶所處狀態下最可能出現的地點,將此地點作為預測地點。通過大量實驗結果驗證了本文模型在預測用戶位置上的有效性。然而,預測用戶下一時刻的位置,不僅與用戶自身的行為習慣有關,還受朋友關系等其他因素影響,下一步將致力于進行基于社交關系和用戶行為習慣的位置預測。
參考文獻(References)
[1] BAO J, ZHENG Y, MOKBEL M F. Location-based and preference-aware recommendation using sparse geo-social networking data[C]// Proceedings of the 20th International Conference on Advances in Geographic Information Systems. New York: ACM, 2012: 199-208.
[2] NOULAS A, SCELLATO S, LATHIA N, et al. Mining user mobility features for next place prediction in location-based services[C]// ICDM 2012: Proceedings of the 2012 IEEE 12th International Conference on Data Mining. Washington, DC: IEEE Computer Society, 2012: 1038-1043.
[3] Yang j, J X, M Xu, et al. Predicting next location using a variable order Markov model[C]// IWGS 2014: Proceedings of the 5th ACM SIGSPATIAL International Workshop on GeoStreaming. New York: ACM, 2014: 37-42.
[4] 薛迪, 吳禮發, 李華波, 等.TraDR: 一種基于軌跡分解重構的移動社交網絡位置預測方法[J]. 計算機科學, 2016, 43(3): 93-98.(XUE D, WU L F, LI H B, et al. TraDR: a destination prediction method based on trajectory decomposition and reconstruction in geo-social networks[J]. Computer Science, 2016, 43(3): 93-98.)
[5] TARASOV A, KLING F, POZDNOUKHOV A. Prediction of user location using the radiation model and social check-ins[C]// UrbComp 2013: Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing. New York: ACM, 2013: Article No. 8.
[6] ROSEN-ZVI M, GRIFFITHS T, STEYVERS M, et al. The author-topic model for authors and documents[C]// UAI 2004: Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence. Arlington, Virginia, USA: AUAI Press, 2004: 487-494.
[7] EAGLE N, PENTLAND A. Eigenbehaviors: identifying structure in routine[J]. Behavioral Ecology and Sociobiology, 2009, 63(7): 1057-1066.
[8] LI Z, DING B, HAN J, et al. Mining periodic behaviors for moving objects [C]// KDD 2010: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2010: 1099-1108.
[9] 李杰, 王小偉.基于作者主題模型的遙感圖像自動類別標注方法[J]. 計算機應用與軟件, 2013, 30(10): 263-265.(LI J, WANG X W. Automatic category tagging of remote sensing images using author topic model[J]. Computer Applications and Software, 2013, 30(10): 263-265.)
[10] 徐戈, 王厚峰.自然語言處理中主題模型的發展[J]. 計算機學報, 2011, 34(8): 1423-1436.(XU G, WANG H F. The development of topic models in natural language processing[J]. Chinese Journal of Computers, 2011, 34(8): 1423-1436.)
[11] FARRAHI K, GATICA-PEREZ D. What did you do today? Discovering daily routines from large-scale mobile data[C]// MM 2008: Proceedings of the 16th ACM International Conference on Multimedia. New York: ACM, 2008: 849-852.
[12] SIMINI F, GONZLEZ M C, MARITAN A, et al. A universal model for mobility and migration patterns[J]. Nature, 2012, 484(7392): 96-100.
[13] McARDLE G, LAWLOR A, LLXREY E, et al. City-scale traffic simulation from digital footprints[C]// UrbComp 2012: Proceedings of the 2012 ACM SIGKDD International Workshop on Urban Computing. New York: ACM, 2012: 47-54.
[14] ZHENG J, NI L M. An unsupervised framework for sensing individual and cluster behavior patterns from human mobile data[C]// UbiComp 2012: Proceedings of the 2012 ACM Conference on Ubiquitous Computing. New York: ACM, 2012: 153-162.
[15] 張瑩, 李智, 張省.基于位置的社交網絡用戶軌跡相似性算法[J]. 四川大學學報(工程科學版), 2013, 45(增刊2): 140-144.(ZHANG Y, LI Z, ZHANG S. Users trajectory similarity algorithmic research on location-based social network[J]. Journal of Sichuan University (Engineering Science Edition), 2013, 45(S2): 140-144.)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
