改進卷積神經網絡在遙感圖像分類中的應用
2018-06-20 06:16:56劉雨桐李志清楊曉玲
計算機應用 2018年4期
劉雨桐,李志清,楊曉玲
0 引言
在遙感技術研究中,不論是專業信息的提取、動態變化預測,還是專題地圖制作以及遙感數據庫的建立都離不開遙感圖像的分類。如何高效、準確地對遙感圖像進行分類成為該領域的重要研究內容。場景分類是學習將圖像映射到語義內容標簽的過程。遙感圖像分類根據不同的統計方法,可劃分為隨機統計法和模糊數學方法;根據不同層次的特征提取一般可分為低層特征處理和中層特征處理兩大主要方法;根據事先是否需要訓練樣本,又可分為監督學習、半監督學習[1]和無監督學習[2]三大類。低層的特征通常采用場景圖像的顏色[3]、方向梯度[4]、密度特征[5]、特征點[6]、變換域的紋理[7]等來描述。由于低層特征泛化性差,目前場景分類方法主要基于中層語義[8]建模。中層特征指基于統計分布的低層特征與語義的聯系,包括語義的屬性、對象和局部語義概念(如稀疏表示[9]和語義概率主題模型[10])等。目前采用中層語義來進行分類最為廣泛的是基于視覺詞袋(Bag of Visual Words, BOVW)模型的方法[11],它將圖像視為文檔,即若干個沒有順序的“視覺詞匯”集合,根據場景的低層特征來提取出互相獨立的視覺詞匯,然后利用K-Means[12]等聚類算法合并詞義相近的視覺詞,構成一個單詞表。中層語義場景分類能一定程度地緩解語義鴻溝問題,但基于語義對象組合變換的中層語義對于場景尺度的變化、傳感器的拍攝時空和角度的差異缺乏有效的處理措施。
近年來,卷積神經網絡(Convolutional Neural Network, CNN)模型[13-14]在圖像分類任務上的應用,大大提高了圖像分類精度。隨著ReLU(Rectified Linear Units)和dropout操作的出現,以及大數據和GPU(Graphics Processing Unit)帶來的機遇,Alex在ImageNet圖像分類挑戰上提出的AlexNet網絡結構模型[15]贏得了2012屆ImageNet大規模視覺識別挑戰賽冠軍。與傳統的統計學方法相比,神經網絡無需對概率模型作出假設,具有極強的學習能力和容錯能力,適用于空間模式識別的各種問題。CNN是針對圖像分類及識別任務而特別設計的多層神經網絡,是一種深度學習方法。CNN具有的局部感受野和權值共享特點,能夠有效減少訓練參數數目,子采樣(池化)特點能聚合對不同位置的特征,在降低特征維度的同時還能改善結果(不容易過擬合)。在識別位移、縮放以及其他形式扭曲不變性的二維圖像時,CNN在同一特征映射面上進行權值共享的特點使其能隱式地從訓練數據中進行并行學習,這也成為CNN相對于神經元全連接網絡的一大優勢。
本文提出一種改進卷積神經網絡的遙感圖像分類方法:1)嵌入Inception模塊,在較高層使用不同尺度的卷積核進行操作,通過擴展網絡的寬度來加強網絡的特征提取能力。2)采用Maxout網絡,并結合dropout操作來擬合不同的激活函數,使模型在提高圖像分類精度的同時,一定程度上降低過擬合的影響。在美國土地使用分類數據集(UCM_LandUse_21)上進行的實驗結果表明,與當今前沿遙感圖像分類方法相比,本文方法能取得更高的分類精度。
1 卷積神經網絡
CNN是一個多層的神經網絡,一般由輸入、特征提取層(多層)以及分類器組成,每層由多個二維相互獨立神經元組成。網絡通過逐層的特征提取學習輸入圖像的高層特征,然后將其輸入到分類器中對結果進行分類。圖1為一個對手寫體圖像進行識別的CNN結構LeNet-5的模型。
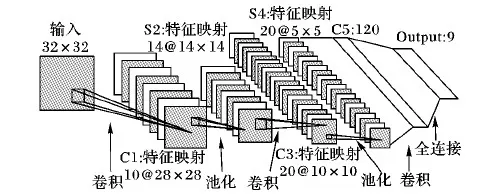
圖1 手寫體識別CNN結構LeNet-5
卷積層是CNN的特征映射層,具有局部連接和權值共享的特征。這兩種特征降低了模型的復雜度,并使參數數量大幅減少。
下采樣(池化)層是CNN的特征提取層,它將輸入中的連續范圍作為池化區域,并且只對重復的隱藏單元輸出特征進行池化,該操作使CNN具有平移不變性。實際上每個用來求局部平均和二次提取的卷積層后都緊跟一個下采樣層,這種兩次特征提取的結構使CNN在對輸入樣本進行識別時具有較高畸變容忍力。
全連接層將之前提取到的特征進行綜合,使圖像特征信息由二維降為一維。
輸出層(Softmax神經元層)解決線性多類的分類問題,使用Softmax方法進行分類能在一定程度上提升網絡學習速度。Softmax函數中引入了K組參數(w,b),相當于引入K個分隔超平面, maxP(Y=j|x(i),θ,b)為最終分類結果(其中:θ表示模型的可學習參數)。假設函數如下:
(1)
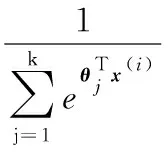
K項概率密度分布為:
(2)
2 改進CNN遙感圖像分類方法
2.1 改進CNN的結構
本文方法的結構分為三個模塊。首先是圖片預處理,利用圖片生成器在訓練時生成大量規定批次的數據來實時進行數據提升。然后,其CNN用對每幅圖像進行卷積操作,提取該圖像的特征。本文方法的卷積操作由三個卷積層(后接最大池化層)以及一個Inception模塊(后接最大池化層)組成,既有縱向的延伸,又有橫向的擴展;而傳統CNN只有縱向到底加深。最后由Maxout網絡對卷積操作提取到的特征進行全連接的處理后由分類器對遙感圖像進行分類。改進CNN整體模型如圖2所示。
2.2 Inception結構
傳統CNN改進方法只強調通過加深網絡層數來提高網絡特征處理能力,然而單一尺度卷積核無法實現對多尺度特征的利用。本文方法在傳統CNN中嵌入結合Network in Network[15]思想的Inception結構。該模塊先聚合輸入特征,然后利用其非線性變換能力對特征進行再加工和濾波處理,以此實現多尺度特征的利用。
Inception結構通過并聯不同尺度卷積核來增加網絡寬度,獲取遙感圖像中多種尺度特征,從而提高網絡特征提取能力。
本文方法嵌入的Inception結構如圖3所示。值得一提的是只有當Inception結構所在層數越高、通道數越多時,該方法才能取得更高的效率。因為當使用圖3中Inception模型結構時,其中的1×1卷積核將信息進行壓縮后再聚合會帶來一定程度的信息損失,而模型底層主要提取的是細節特征,細節信息的細微損失很可能給整個模型的圖像特征學習帶來極大的影響。在對特征進行3×3或5×5卷積前引入1×1卷積核則是為了與上一層的神經元進行全連接,使原本特征圖數量的連接數降低到1×1卷積的數量,從而提高模型的計算效率。
2.3 Maxout模型
Maxout模型實際上是一個使用激活函數的簡單前饋網絡結構,網絡結構上在傳統多層感知機(Multi-Layer Perceptron,MLP)網絡隱含層前添加了一個隱隱含層,網絡結構如圖4所示。與常用激活函數(Sigmoid[16]、tanh[17]等)不同的是,Maxout網絡不僅可以學到隱層節點間的關系,還能學到每個隱層節點的激活函數。
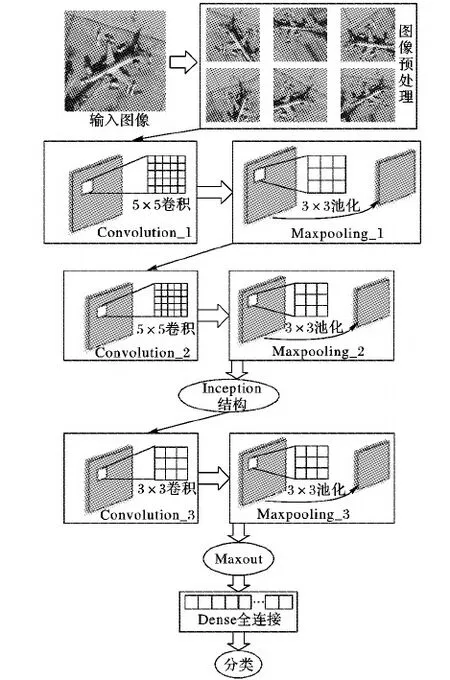
圖2 改進CNN結構整體模型
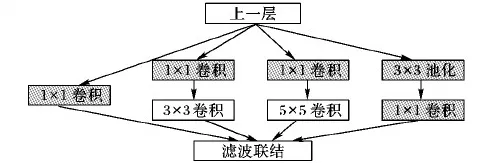
圖3 Inception結構
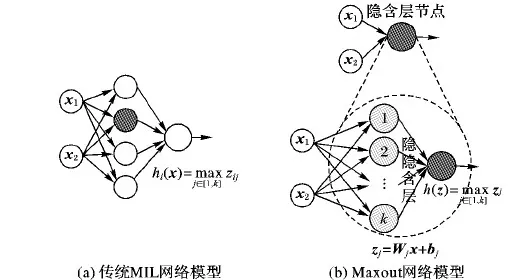
圖4 傳統MLP網絡模型和Maxout網絡模型
對于給定輸入x∈Rd(x表示上一層的狀態),Maxout函數在隱藏層實現功能為:
hi(x)=max(zij);j∈[1,k]
(3)
zij=xTW…ij+bij;W∈Rd×m×k,b∈Rm×k
(4)
其中:W和b是需要學習的參數矩陣;d表示輸入層節點的個數;m表示隱含層節點數量;k指每個隱含層節點對應的“隱隱含層”節點數。隱含層的Maxout節點輸入值為k個“隱隱含層”節點中的最大輸出值。
任意凸函數能被以任意精度的分段線性函數擬合,而“隱隱含層”的k個節點在不同取值范圍的最大輸出值有局部線性特征,可判定Maxout網絡能擬合任意凸函數。結合dropout操作可促進Maxout網絡優化,因為在Maxout網絡中每個“隱隱含層”節點都對輸出進行預測,但每個Maxout單元只學習該網絡預測的最大值,這使網絡每次都只能學到相同的預測。改變dropout操作的參數能決定輸入被映射在分段線性函數的哪一段,讓Maxout網絡在輸入處有更大的線性區域,從而保證Maxout單元學習到不同的輸出特征,同時減少Maxout單元最大化濾波器的變化。
3 實驗
3.1 實驗數據集
UCM_LandUse_21數據集[18]為美國土地使用分類數據集,它包含21種土地使用場景類型,每種類型中有256×256×3尺寸的100幅場景圖(見圖5)。高光譜遙感圖像維數高、訓練樣本有限以及場景混合度大等特點給該數據集的分類帶來了巨大的困難。遙感圖像的場景是以其使用功能定義來分類的,也就是說一幅圖像中存在多種土地覆蓋類型,所以分類難度比一般場景分類大。例如:圖5(t)中有圖5(f)、圖5(r),以及圖5(n)這三種土地覆蓋。

圖5 UCM_LandUse_21類遙感圖像場景示例
3.2 圖像預處理
在用CNN對圖像進行訓練前,先對圖像進行歸一化等預處理,將數據映射到輸出層的激活函數值域(0,1)區間內。由于遙感圖像獲取難,訓練數據有限,本文方法對歸一化后的數據進行一系列的隨機變換(旋轉、移動、縮放、翻轉等方式)來對模型訓練樣本進行擴展。每次訓練時數據生成器會無限生成數據,直到達到規定的次數epoch為止。每個epoch將生成一個批次的圖像數據。進行擴展后的圖像數據有利于抑制過擬合,提高模型的泛化能力。
實驗過程中隨機選取每類場景圖像數據的80%作為訓練數據,其余20%為測試數據。
3.3 CNN結構參數設置及卷積操作可視化
本文方法所改進的CNN網絡層結構參數如表1所示。
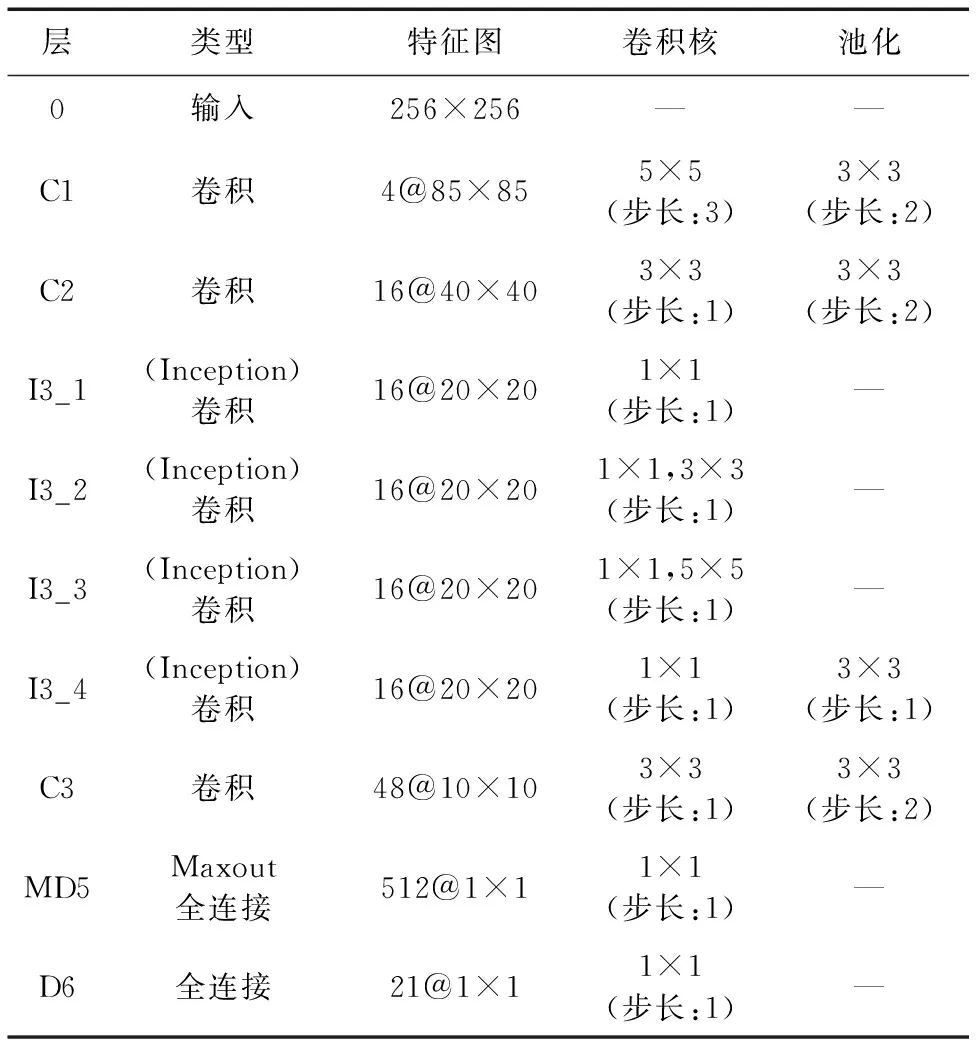
表1 改進CNN網絡參數
CNN在網絡中對從在底層提取到的線、角等特征進行傳遞,并在網絡的高層開始識別更復雜的特征,該特性使CNN更擅長識別圖像中的物體。圖6為一張機場遙感圖像在本文方法所提模型中經過各個卷積層特征處理后的部分結果,展示CNN在各個階段進行圖像處理的情況。由圖6可見,在卷積操作下,圖像的背景激活度逐漸變小,模型在C1和C2層中提取到的基本上是顏色、邊緣等底層特征,在I3層呈現更多的是飛機等地標性紋理特征,而在C4層卷積處理后所呈現的特征則已經無法通過肉眼辨認。
3.4 改進CNN分類能力分析
為分析本文方法的Inception模塊和Maxout模塊對分類效果的影響,本文對傳統CNN、加入Inception模塊的方法(In_CNN)、同時結合Inception模塊和Maxout網絡的方法(InM_CNN)以及在InM_CNN加入dropout操作后的本文方法在同樣的數據集UCM_LandUse_21進行分類實驗。圖7展現了這四種方法的正確率隨epoch的增加而變化,可見:傳統CNN的分類正確率最低;加入Inception模塊后的In_CNN正確率在一定程度上得到了提升;加入Maxout層后的InM_CNN,正確率雖然在epoch為400之前有明顯提高,但之后震蕩較大(過擬合),正確率下降了近6%;而本文方法一定程度上抑制了過擬合的影響,分類正確率在后期也能穩步增長,達到了最好的分類效果。
由此可見,本文對CNN進行的所有改進都是合理有效的。

圖6 卷積層操作可視化
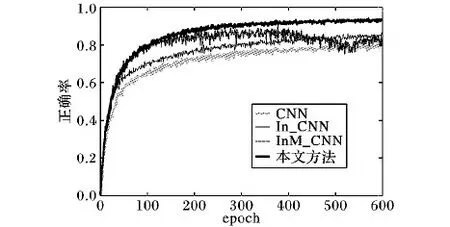
圖7 本文方法與另三種方法分類正確率對比
3.5 實驗與分析
圖8的分類結果混淆矩陣直觀展現了在本文方法下每類場景的分類正確率以及該場景錯判為其他場景的情況。圖8中的分類正確率為5次獨立重復實驗后所得的平均值,總體分類正確率達到了93.45%。
由圖8可見本文方法對UCM_LandUse_21數據集中耕地、機場、叢林、高爾夫球場、立交橋等紋理差異小的場景分類準確率較高,對建筑、港口、中等密集住宅區等分類準確率較低,說明本文方法對存在二義性,即對紋理差異較小的圖像分類效果還有待改善。
為驗證本文方法分類優勢,通過UCM_LandUse_21數據集,將本文方法與近幾年具有代表性的幾種方法作對比。其分類結果如表2所示。
由表2可見,中層視覺詞典學習方法所得分類正確率高于以低層特征進行學習的BOVW和支持向量機算法。基于神經網絡的算法(ConvNet、MNCC、基于多尺度深度卷積神經網絡(Multi-Scale Deep CNN, MS_DCNN)、本文方法)的分類正確率均較高,而中層特征混合了稀疏編碼后其分類正確率也得到了一定的提升,分類效果甚至超過了部分神經網絡算法,但本文方法分類正確率明顯高于其他文獻所提方法,因此本文對傳統CNN的改進使其圖像分類能力得到了顯著提升。
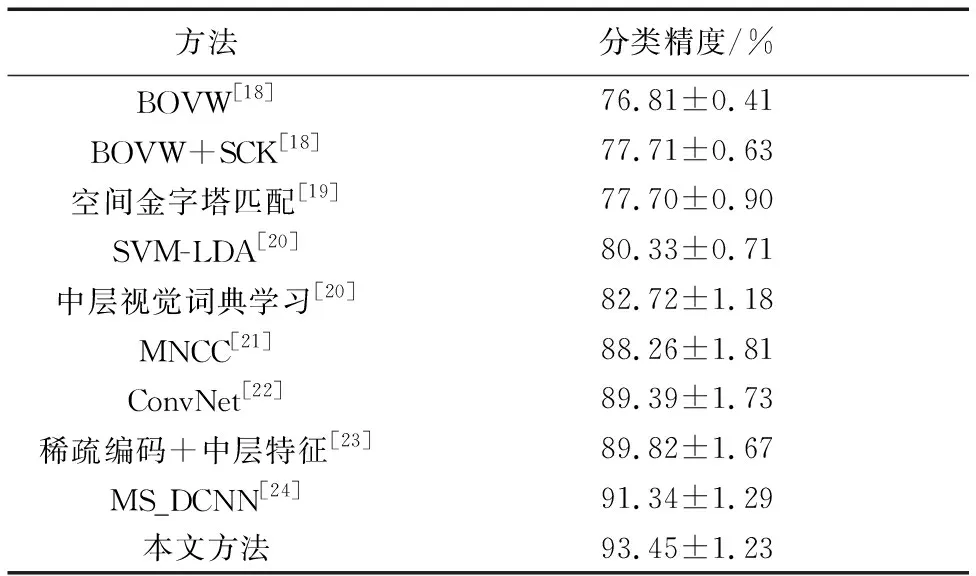
表2 不同方法對UCM_LandUse_21數據集的平均分類精度

圖8 UCM_LandUse_21場景分類混淆矩陣
表2中的MS_DCNN方法[24]同樣也以深度卷積神經網絡為框架并且都利用了多尺度特征,不過該方法是在圖像預處理階段利用controlet變換對圖像進行多尺度分解來獲得多尺度特征的,并未改變傳統卷積神經網絡的結構,而且MS_DCNN的分類精度最為接近本文方法,因此本文將該方法與本文方法訓練過程中分類精度曲線的變化進行對比。分類正確率的對比如圖9所示。
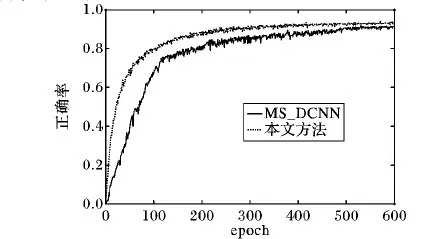
圖9 本文方法與MS_DCNN方法的分類正確率對比
可見,本文方法經過較少的迭代次數就能達到80%以上的正確率,而MS_DCNN相對較慢;因此,從正確率的提升速度和最后的正確率來說,本文方法都優于該方法。
4 結語
本文方法通過改進CNN模型直接對圖片進行特征提取,通過Inception模塊的不同尺度卷積核來增加CNN網絡的寬度,從而提高網絡特征提取的能力,實現對多尺度特征的利用。Maxout網絡結合dropout操作可消除激活函數選擇的不確定性,減少參數確定帶來的計算步驟和抑制過擬合的影響。實驗結果表明,本文對CNN的每項改進都合理有效,并且本文在UCM_LandUse_21數據集上取得了較好的分類效果。如何減少本文方法對存在二義性的圖像的誤分率是下一步的研究方向。
參考文獻(References)
[1] 蔡月紅,朱倩, 孫萍, 等. 基于屬性選擇的半監督短文本分類算法[J]. 計算機應用, 2010, 30(4): 1015-1018.(CAI Y H, ZHU Q, SUN P, et al. Semi supervised short text categorization based on attribute selection [J]. Journal of Computer Applications, 2010, 30(4): 1015-1018.)
[2] 修馳, 宋柔. 基于無監督學習的專業領域分詞歧義消解方法[J]. 計算機應用, 2013, 33(3): 780-783.(XIU C, SONG R. Disambiguation of domain word segmentation based on unsupervised learning[J]. Journal of Computer Applications, 2013, 33(3): 780-783.)
[3] 張永庫, 李云峰, 孫勁光. 綜合顏色和形狀特征聚類的圖像檢索[J]. 計算機應用, 2014, 34(12): 3549-3553.(ZHANG Y K, LI Y F, SUN J G. Image retrieval based on clustering according to color and shape features [J]. Journal of Computer Applications, 2014, 34(12): 3549-3553.)
[4] LI Z, HU D W, ZHOU Z T. Scene recognition combining structural and textural features[J]. Science China Information Sciences, 2013, 56(7): 1-14.
[5] ZHANG F, DU B, ZHANG L. Saliency-guided unsupervised feature learning for scene classification[J]. IEEE Transactions on Geoscience & Remote Sensing, 2014, 53(4): 2175-2184.
[6] ZHU X, MA C, LIU B, et al. Target classification using SIFT sequence scale invariants [J]. Journal of Systems Engineering and Electronics, 2012, 23(5): 633-639.
[7] AKOGLU L, TONG H, KOUTRA D. Graph based anomaly detection and description: a survey[J]. Data Mining and Knowledge Discovery, 2015, 29(3): 626-688.
[8] 吳航, 劉保真, 蘇衛華, 等. 視覺地形分類的詞袋框架綜述[J]. 中國圖象圖形報, 2016, 21(10): 1276-1288.(WU H, LIU B Z, SU W H, et al. Bag of words for visual terrain classification: a comprehensive study[J]. Journal of Image and Graphics, 2016, 21(10): 1276-1288.)
[9] LI E, DU P, SAMAT A, et al. Mid-level feature representation via sparse autoencoder for remotely sensed scene classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing, 2016, 10(3): 1068-1081.
[10] SINGH A, PARMANAND, SAURABH. Survey on pLSA based scene classification techniques[C]// Proceedings of the 2014 5th International Conference on Confluence the Next Generation Information Technology Summit. Piscataway, NJ: IEEE, 2014: 555-560.
[11] ZHAO L J, TANG P, HUO L Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model[J]. IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing, 2015, 7(12): 4620-4631.
[12] 傅德勝, 周辰. 基于密度的改進K均值算法及實現[J]. 計算機應用, 2011, 31(2): 432-434.(FU D S, ZHOU C. ImprovedK-means algorithm and its implementation based on density [J]. Journal of Computer Applications, 2011, 31(2): 432-434.)
[13] TURAGA S C, MURRAY J F, JAIN V, et al. Convolutional networks can learn to generate affinity graphs for image segmentation[J]. Neural Computation, 2010, 22(2): 511-538.
[14] PINTO N, DOUKHAN D, DICARLO J J, et al. A high-throughput screening approach to discovering good forms of biologically inspired visual representation[J]. PLoS Computational Biology, 2009, 5(11): e1000579.
[15] PANG Y, SUN M, JIANG X, et al. Convolution in convolution for network in network[J]. IEEE Transactions on Neural Networks & Learning Systems, 2016, PP(99): 1-11.
[16] 王朔琛, 汪西莉. 參數自適應的半監督復合核支持向量機圖像分類[J]. 計算機應用, 2015, 35(10): 2974-2979.(WANG S C, WANG X L. Semi-supervised composite kernel support vector machine image classification with adaptive parameters[J]. Journal of Computer Applications, 2015, 35(10): 2974-2979.)
[17] 柴瑞敏, 曹振基. 基于改進的稀疏深度信念網絡的人臉識別方法[J]. 計算機應用研究, 2015, 32(7): 2179-2183.(CAI R M, CAO Z J. Face recognition algorithm based on improved sparse deep belief networks[J]. Application Research of Computers, 2015, 32(7): 2179-2183.)
[18] YANG Y, NEWSAM S. Bag-of-visual-words and spatial extensions for land-use classification[C]// GIS 2010: Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. New York: ACM, 2010: 270-279.
[19] LU F X, HUANG J. Beyond bag of latent topics: spatial pyramid matching for scene category recognition[J]. Frontiers of Information Technology & Electronic Engineering, 2015, 16(10): 817-829.
[20] ZHANG F, DU B, ZHANG L. Saliency-guided unsupervised feature learning for scene classification[J]. IEEE Transactions on Geoscience & Remote Sensing, 2014, 53(4): 2175-2184.
[21] 劉揚, 付征葉, 鄭逢斌. 基于神經認知計算模型的高分辨率遙感圖像場景分類[J]. 系統工程與電子技術, 2015, 37(11): 2623-2633.(LIU Y, FU Z Y, ZHENG F B. Scene classification of high-resolution remote sensing image based on multimedia neural cognitive computing[J]. Systems Engineering and Electronics, 2015, 37(11): 2623-2633.)
[22] NOGUEIRA K, MIRANDA W O, SANTOS J A D. Improving spatial feature representation from aerial scenes by using convolutional networks[C]// Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images. Piscataway, NJ: IEEE, 2015: 289-296.
[23] LI E, DU P, SAMAT A, et al. Mid-level feature representation via sparse autoencoder for remotely sensed scene classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing, 2016, PP(99): 1-14.
[24] 許夙暉, 慕曉冬, 趙鵬, 等. 利用多尺度特征與深度網絡對遙感影像進行場景分類[J]. 測繪學報, 2016, 45(7): 834-840.(XU S H, MU X D, ZHAO P, et al. Scene classification of remote sensing image based on multi-scale feature and deep neural network[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(7): 834-840.)
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
