面向MapReduce計算模式的中間數據通信優化
2018-06-20 06:17:02曹云鵬王海峰
計算機應用 2018年4期
曹云鵬,王海峰
(1.臨沂大學 信息科學與工程學院,山東 臨沂 276002;2.山東省網絡環境智能計算技術重點實驗室 臨沂大學研究所,山東 臨沂 276002)(*通信作者電子郵箱gadfly7@126.com)
0 引言
隨著互聯網、物聯網、云計算等技術的迅猛發展,信息空間中各類應用層出不窮,這些應用在改變人類生活方式的同時產生了巨大數據資源。全球數據量以指數增長,并呈現出爆炸式的發展趨勢,根據國際數據公司(International Data Corporation, IDC)的報告,預計到2020年全球數據總量達到45 ZB。一個大規模生產、分享和應用數據的時代已經來臨,在電子政務、智能交通、智能制造、精準醫學、海洋監測、現代農業、電子商務和物流管理等應用領域中都需要對海量數據進行處理和深入分析,海量數據的分析與查詢成為一個重要研究應用領域。MapReduce是谷歌公司提出的一種分布式大數據處理的計算模型,基于MapReduce的應用程序能運行在大規模異構集群中,采用典型的主從模式分割大數據處理作業,映射到各個從屬節點中并行計算,最后匯聚和合并計算結果。因此普通用戶在MapReduce處理海量數據時根據具體算法邏輯編寫Map和Reduce函數,并行化、容錯、數據分發和負載均衡等復雜的管理工作由底層框架自動完成。現有的Hadoop、Spark都是基于MapReduce計算模式的開源框架,用戶提交的作業被劃分成若干數據塊,每個數據塊分配到集群節點的一個Mapper執行。當Map計算階段完成后會產生大量中間結果,再把中間數據作為Reducer的輸入來匯總計算結果,整個計算作業的性能由Reducer運行最慢的來決定。MapReduce計算模式是大數據并行處理應用最廣泛的模型,因此具有較大研究價值。
現有研究和工程實踐中發現MapReduce計算模型的中間數據處理階段(Shuffle過程)會產生海量通信數據。在Facebook的數據中心內Shuffle匯聚階段產生的網絡流量占到數據中心總流量的46%。MapReduce計算模型的性能主要影響因素是Map階段的計算性能和Shuffle過程中的網絡通信性能[1]。在Shuffle階段集群中大量計算節點利用網絡來交換并重新定位中間數據,為Reduce階段的匯總計算提供輸入數據。例如在Facebook數據中心的MapReduce計算集群中,所有MapReduce作業Shuffle網絡傳輸占總運行時間的33%,其中26%的作業Shuffle傳輸占到50%以上,有16%的作業網絡傳輸占據70%以上的運行時間[1],因此中間數據的通信成為性能優化的瓶頸。
本文針對多租戶的異構集群計算環境,研究Map密集型的大數據處理作業的中間數據通信局部性,利用機器學習的方法來挖掘MapReduce作業的通信局部性,嘗試探索中間數據通信活躍度與作業特征之間的相關性,通過作業分類來實施通信優化策略,降低集群中跨機架交換機數據通信量。實驗結果表明,本文提出的通信優化方案對Shuffle密集型作業的計算性能優化效果達到4%~5%,而且數據量越大的優化效果越明顯。此外,隨著異構集群規模的增加,通信優化效果比較穩定,表明該方法對集群擴展性具有很好的適應性。
1 相關工作
MapReduce是一個典型的大數據并行處理計算模型。從開源框架Hadoop推出以來,學術界開展了大量性能參數調優的研究。在MapReduce計算模型中Shuffle過程需要從各個節點匯聚大量Map任務的輸出數據,再傳送到Reduce任務作為輸出,這個過程會產生大量磁盤I/O讀寫和網絡讀寫,因此Shuffle階段是典型的I/O密集型任務。本文關注Shuffle階段中間數據的通信優化問題,現有研究主要從以下三個角度來優化Shuffle中間數據的讀寫性能:1)從軟件整體架構和流程優化角度來研究。Yu等[2]提出優化的Hadoop框架來實現Shuffle、Merge和Reduce階段的交替,減少數據復制和網絡傳輸,提高數據移動性能;Rahman等[3]針對Shuffle密集型的MapReduce計算作業設計了一個利用Lustre文件存儲系統來保存中間計算數據的體系優化方案,并利用RDMA(Remote Direct Memory Access)機制的權限目錄選擇來實時處理中間數據。2)從任務調度角度來優化中間數據通信。Shi等[4]提出智能Shuffle任務調度策略,用來解決中間數據重新定位產生的網絡擁塞和Reduce任務不均衡問題,該調度方法適合多種網絡拓撲結構;Arslan等[5]考慮數據局部性和網絡拓撲擁塞兩個因素,設計了一個Reduce任務的調度策略,把Reduce任務盡量調度到離Map產生的中間數據近的節點中,以此提高通信性能和能效;Zheng等[6]根據Map和Shuffle階段對計算資源的需求不同,對CPU密集和輸入/輸出(I/O)密集的任務采用聯合調度方式來提高資源復用率。3)從MapReduce計算模式中考慮細粒度的數據劃分、放置策略等。Ke等[7]針對Shuffle中間數據通信問題,設計了一種新的數據分區和聚合方式來減少中間數據通信;此后該研究團隊在Hadoop基礎上增加了一個中間數據聚合測試體系設計,以減少Shuffle階段的網絡通信量[8];對Shuffle再進行更細粒度的分析,分成排序、分組和數據傳輸等階段,通過優化Shuffle中操作序列的方式來提高中間數據通信性能[9];Yu等[10]引入虛擬Shuffle的思想,通過虛擬Shuffle來解決磁盤讀寫競爭和中間數據移動性能瓶頸的問題;從MapReduce框架中數據放置策略優化的角度來減少跨數據中心的數據傳輸和跨機架的數據通信[11];Lee等[12]挖掘MapReduce計算模式中數據塊的深度局部性,通過分析數據局部性來調整數據塊放置策略,解決Shuffle階段的數據重定位引起的通信瓶頸問題。
本文方案從MapReduce任務調度的角度來優化Shuffle階段的數據傳輸性能,采用統計分類的方法來挖掘作業中間數據網絡通信的局部性,比Arslan方案[5]有更好的準確性,最后通過重新部署Map任務的分配將通信活躍的作業都集中到同一個機架內,減少跨機架數據傳輸的通信量。本文方案去除考慮數據局部性和網絡擁塞的復雜性,具有較好的應用價值。
2 中間數據通信優化方法
2.1 優化方法
本節中的優化方法不考慮網絡擁塞和數據傳輸的細節,將MapReduce作業中通信活躍的作業調度到同一個集群機架中,這樣節點之間大量的Shuffle數據傳輸被控制在機架之內,通過減少跨機架數據傳輸來提高中間數據傳輸性能。
先提取MapReduce作業的特征,然后建立貝葉斯分類模型。利用分類模型把作業分成通信活躍和通信不活躍的兩大類,重新調度通信活躍作業,將其各任務部署到集群同一機架內,以此減少中間數據跨機架的傳輸延遲。另外為了實現負載均衡,將通信不活躍的作業依據比例向性能排序的計算節點上調度。
該方案需要解決以下四個問題:1)Map密集型作業特征提取。提取出大數據實時處理作業的運行前靜態特征,建立作業特征向量為下一步的分類做好準備。2)異構集群中通信活躍度的度量方式。為了研究作業特征與集群內跨機架通信局部性的非線性關系,建立通信活躍度模型以及設計可行的測量方法。3)采用機器學習方法構造一個作業分類預測模型,通過預測模型實現大數據作業的通信局部性的預判。4)在作業分類預測模型基礎上提出優化的大數據布局方案來解決中間數據的通信性能瓶頸問題。
2.2 大數據作業特征
在MapReduce模型中計算作業初始化后,根據集群中資源配置情況形成若干個Map任務和Reduce任務,這些計算任務要分布到集群中不同節點并發執行。對于Map密集型作業有大量的Map任務處理原始輸入數據,并且在各節點中形成中間計算結果;Reduce任務則以中間結果為輸入,計算得出最終處理結果。目前MapReduce系統中Map任務分發是靜態的,其分配結果是固定的分布。然而Reduce任務的分配是動態的,具有不確定性。現有研究中使用較多的作業特征是MapReduce作業的運行時性能參數,例如Map、Reduce階段的執行時間,Reduce階段的數據復制、排序的時間,運行時刻集群資源的利用率(CPU、內存、磁盤和網卡的利用率)。然而運行時刻特征很難應用到作業分類預測中,因此必須使用作業運行前的Map任務分配信息作為特征。提取靜態作業特征的思路如下:一個MapReduce作業被劃分成多個任務,然后被分配到集群的各個計算節點中;將集群計算節點視為一個矩陣,矩陣中各元素的值為分配到該節點的Map任務數;最后以Map任務矩陣作為作業的特征向量。
下面舉例說明作業特征提取的具體方案。
假設異構集群G是一個由計算節點組成的集合,其中包括機架G={R1,R2,…,Rp},每個機架中包括若干節點Ri={n1,n2,…,nq}。MapReduce作業J根據Map任務處理的數據塊來實現Map任務劃分和映射,比如Map任務Mij表示運行在集群G中第i個機架上第j個節點nij中的Map任務。任何實現MapReduce計算模型的系統,或許使用多種任務分發和調度算法,但是最終每個作業調度后都會形成一個Map任務矩陣J=[Mij]p×q,該矩陣表示作業在集群運行之前的分發狀態,矩陣中的元素Mij表示映射到該節點nij中的Map任務數量;若集群中的某節點失效或者不存在,則設置Mij為空(Null)。在此以一個5個機架每個機架有6節點的集群為例,假設一個作業Ji的Map任務矩陣如式(1)所示:
(1)
在任務矩陣中非零元素表示分配到到該節點的Map任務數量,比如M02=7為集群中R0機架中第三個節點n02中分配了7個Map計算任務;所有零元素表示該節點未分配到任務,比如M00=0;Null節點表示該節點不存在或者處于故障狀態。以該任務矩陣為基礎提取作業的運行前特征。由于Null節點是一種隨機狀態并且在樣本訓練時完全可以確定,因此將Null節點簡化為零元素節點,即為處于工作狀態的節點視為未分配到任務階段。然后再用一個較大的Map任務數來規范化矩陣(Max=100),把矩陣中的非零元素規范到區間[0,1]內,應用上述轉化規則后任務矩陣由式(1)變為式(2):
(2)
總之,Map任務矩陣是任務節點之間并行特征的表現形式,在此提取節點并行特征并轉化成特征向量,比如式(2)矩陣轉化為特征向量組如下:
Ti=(t0,t1,t2,t3,t4)
(3)
向量組的每個向量是式(2)矩陣中的一行,例如:
t0=(0,0.04,0.07,0,0,0)
另外,該特征向量提取方法不失一般性,可以適應各種MapReduce生態系統的調度算法。由于在相同的作業調度算法前提下研究作業的分類以及通信優化,MapReduce作業的靜態特征只受作業數據規模大小影響,因此該提取特征方法通用性較好。此外,MapReduce作業特征是一種由調度算法生成的預先調度方案,這種預調度方案用于作業的分類判斷中,根據分類判斷再重新生成能夠提高中間數據通信局部性的調度方案,最后實施的是優化后的調度方案。
2.3 集群通信活躍度
接下來需要對MapReduce作業分類。為了有效控制中間數據的通信局部性,本文將作業分成通信活躍和不活躍兩大類,因此要解決對中間數據通信活躍度的量化問題。在此引入集群通信活躍度,然后根據通信活躍度進行作業分類預測。設一個大數據作業Ji的計算節點集合Ri={n1,n2,…,np},然而這個計算節點集合Ri也是一個通信集合。若該通信集合中一對跨機架節點ni與nj的數據通信量為dj:
dj(〈ni,nj〉,ni∈Ri,nj∈Rj,i≠j)
(4)
則作業Ji的中間數據通信量為Di:
(5)
其中:k是作業Ji通信集合中跨機架通信的節點對數目。因此一個作業Ji的集群通信活躍度CAi定義如下:
(6)
其中:取一個作業跨機架通信量的平均值作為其集群通信活躍度的量化指標,并且使用單個跨機架通信的最大值dmax把CA歸一化到區間[0,1]。接著要確定通信活躍度的閾值參數。為了減少閾值確定的主觀性,使用樣本數據分布分析的方式。首先從Hadoop基準程序集合和修改現有的大數據分析作業選擇50個樣本作業,然后采用Hadoop的作業并行分布方法運算,再具體測量作業中間數據通信量。具體方法如下:Hadoop中通過事件來確定Map階段開始和結束,并且反饋到Web監控頁面中。在此監聽Map結束事件來統計Map結束到整個作業結束期間的數據通信(暫時忽略Shuffle階段結束到作業結束階段的傳輸數據,這個階段的網絡通信量非常小)。再監聽每個物理節點Shuffle handler進程的端口,統計該端口以超文本傳輸協議(HyperText Transfer Protocol, HTTP)傳輸的中間數據量。最后統計出機架內和跨機架的通信量。最后通過式(6)計算出每個作業的通信活躍度,統計結果如圖1所示。
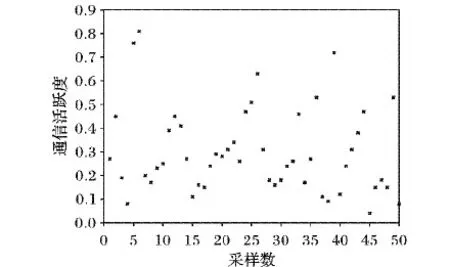
圖1 樣本作業通信活躍度分布
通過觀察樣本作業通信活躍度的分布可看出,在0.3~0.4存在一個明顯的分界線。利用樣本通信活躍度置信區間分析,接受30%的作業作為通信活躍作業時閾值可設定為0.38。
2.4 分類預測模型
本節建立MapReduce作業分類器,通過樣本作業的分類結果來訓練分類器,然后使用分類器預測未來出現MapReduce作業。該分類器的輸入是作業的預調度Map任務分配矩陣信息,輸出為通信活躍類型的判斷結果。分類是機器學習中一個有監督學習的方法。通過分析歷史數據的分類情況來構造一個分類函數或者分類模型,再利用該模型把待預測數據映射到某一特定類別中。構造分類器模型需要一個樣本數據作為訓練學習的輸入,每個樣本數據包含若干屬性,由屬性組成特征向量。另外訓練數據集的樣本數據除特征向量之外還有與之對應的類標簽。在此大數據作業Ti=((t0,t1,t2,t3,t4),C),其中:(t0,t1,t2,t3,t4)表示作業的特征向量;C為類標簽(C1為通信活躍作業,C0為通信惰性作業)。
樸素貝葉斯分類是當前公認的一種簡單而有效的概率分類方法,在一般貝葉斯算法的基礎上通過假定各種因素之間不存在關系,即各個因素完全獨立而得到的一種簡化貝葉斯分類法。本文工作選用樸素貝葉斯模型主要有兩個原因:1)從訓練學習角度而言,樸素貝葉斯分類模型非常適合小樣本訓練集合,而本文工作樣本數據采集難度較大,很難形成較大的訓練數據集。2)樸素貝葉斯算法簡單而且性能好,而計算的高效性和高精度能夠滿足本研究MapReduce作業分類的性能需求。
樸素貝葉斯分類的思想是利用貝葉斯定理來預測一個未知類別數據屬于各個類別的可能性,并且選擇可能性最大的一個類別作為該樣本的預測結果。假設有k個類的集合{C1,C2,…,Ck}和一個未知類別的樣本X={x1,x2,…,xk},則貝葉斯定理為:
(7)
由于P(X)對所有類別都是常數,因此通過式(8)可以計算出X屬于每一個類的概率,并取最大概率值的類為預測值。
(8)
為了簡化研究異構集群采用固定布局,比如4機架8節點,每個作業特征向量則為Ti=(t0,t1,t2,t3),類別C1表示通信活躍作業,C0表示通信惰性作業。貝葉斯分類器利用未知作業的預調度信息,即由特定調度算法生成的Map任務分配矩陣。再將該任務分配矩陣轉化成分類器的輸入向量,由分類器判斷作業的類別,為下一節的調度策略作準備。
2.5 作業優化調度策略
本節的調度算法利用作業分類預測結果,對MapReduce作業的子任務重新實施分配部署,減少集群中跨機架通信傳輸量。先由作業分類預測模型來判斷作業的通信類型,結果為通信活躍和通信不活躍兩類;再根據通信作業類型實行調度,對通信活躍的作業盡量部署到同一機架,以減少跨機架通信的性能損失;對于通信惰性大的作業則維持原來的分配方案。總之,作業優化調度的內涵與反饋控制模型相似,利用作業的預調度信息實現作業類型判斷,然后重新調整最終的調度方案,這是利用預調度信息反饋優化最終調度策略的思想。具體作業優化調度算法如算法1所示。
在算法1中算法輸出是每個作業最終的Map部署方案,該部署方案是一個作業在集群中各節點上部署的Map任務數量。首先取出作業隊列的一個作業J,根據常規方法進行預先調度(行3)),然后提取作業特征并送入分類預測函數處理(行4))。若作業預測類型是通信活躍型C1(行5)),則從集群中隨機選擇一個機架R,將作業的所有任務部署到該機架的節點中(行6)~10))。在部署的過程中,先對該中各節點根據性能排序(行7)),然后依據比例對機架Rj中的m個節點分配Map任務(比例公式如行9)所示),最后更新該任務的分配矩陣(行11))。另一個方面,對于通信惰性大的作業(作業類型為C0),則維持原有的調度方案(行13)~15))。算法1的創新之處在于充分利用Map密集型作業的通信局部性原理,根據作業類型預測來控制跨機架通信量。該算法復雜性為O(n),其中n為集群機架內節點數目。由于物理集群擴展性限制,機架內節點數在一個固定范圍內,而且數目較少,因此作業調度算法引起的性能損失非常小,與大數據作業的運行時間比較而言可忽略。
算法1 Map密集型作業優化部署算法。
輸入 大數據作業隊列Q(J1,J2,…,Jn)。
輸出 作業Ji的任務矩陣。
1) While(Queue(J) is not Null)
2)Ji=Deque(J)
3)Si=Scheduling(Ji)
4)Ji.type=Prediction(Si)
5) IFJi.type=C1Then
6)Rj=Random(R)
7) Sort(Rj)
8) For(i=0 tominRj) Do
9)
10) EndFor
11) update(Ji.S)
12) EndIF
13) IFJi.type=C0Then
14)Ji.S=S
15) EndWhile
3 實驗及分析
3.1 實驗環境
本文使用32個節點的集群,通過三層交換機建立仿真數據中心的仿真實驗環境,4個機架,每個機架交換機下8個節點。每個計算節點配置兩個Intel Xeon E5620 2.4 GHz的CPU,每個CPU擁有獨立的一兩級片內緩存,共享三級緩存;每個節點配有16 GB DDR RAM和至少500 GB的SATA硬盤空間。軟件操作系統使用Ubuntu15.0, JDK1.8, Hadoop1.2.1等。
在MapReduce作業中,Map密集型作業占比例非常高,因此本文關注Map密集型作業,實驗選擇的基準作業程序都是Map密集型的,分別是Hibench基準程序集中的Sort、WordCount、TeraSort、Bayesian Classification和K-means Cluster。實驗選擇4個機架,每個機架連接4個節點的集群規模。
表1中列出每個實驗作業的數據規模以及運行后的數據特點。為了方便表述,實驗中本文通信優化方案記為IO(Intermediate Optimization),基準方案為Hadoop中的默認計算方式簡記為MR(MapReduce)。
3.2 性能對比及分析
MapReduce作業計算性能主要由計算時間和中間數據傳輸時間來決定的,而本文關注優化中間數據傳輸時間,在保證計算時間不變的情況下作業的運行時間能夠體現數據傳輸時間的優化效果。首先對比兩種方法的作業運行時間。如圖2所示,基準作業st、ts、bc都出現大約有4%~5%性能提升,然而wc和kc兩個作業并未有明顯的性能改善。
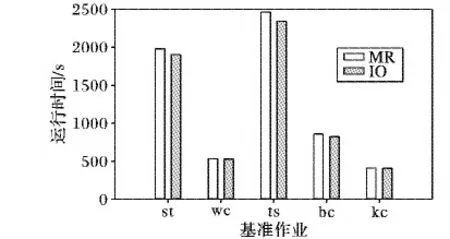
圖2 通信優化方案與基準方法運行時間比較

作業名簡稱數據量/GBMap輸入中間數據Reduce輸出Sortst120120.000120.0000WordCountwc20011.2304.1000TeraSortts1000140.0001000.0000Bayesian Classificationbc7849.00043.0000K-means Clusterkc660.3300.0046
從表1可知,在5個MapReduce基準作業中,st、ts、bc三個作業會產生大量中間數據,屬于Shuffle密集型作業,本文的通信優化方案針對中間數據通信進行優化,因此對這三個基準作業能帶來一定的性能提升;wc和kc兩個作業不是Shuffle密集型的作業,計算過程中產生的中間數據量非常小,因此性能提升效果并不明顯。由于本文是優化作業網絡傳輸延遲,因此為了提高實驗的針對性,對Shuffle密集型的作業TeraSort作進一步分析以展示性能優化效果。如圖3所示,數據集合的規模分別為32 GB、64 GB、128 GB、512 GB和1 TB,縱坐標表示Shuffle階段占整個作業計算時間的比例,比例相對減小則說明通信過程得到優化。隨著數據規模的增加,所提優化方案的Shuffle比例相對減小,說明隨著數據規模的增加通信優化對整個計算性能起了明顯的優化作用。數據量越大中間傳輸優化效果越明顯,體現了本文調度方案對大數據密集計算的性能提升具有較好的應用價值。

圖3 通信優化方案與基準方案TeraSort作業性能對比
3.3 集群擴展性分析
本節中驗證作業優化調度方案對集群擴展的適應性,分析集群擴展性對調度算法的影響。實驗中一直使用4個機架,每個機架的交換機分別連接2、4和8個節點,分別構造成8、16和32個節點的實驗床。在每種集群規模情況下執行Shuffle密集型的作業TeraSort來觀察Shuffle所占比例的變化,如圖3所示。隨著節點數量的增加,Shuffle所占比例有了下降趨勢,表明隨著節點增加通信優化的效果才能表現出來。當每個機架只有2個節點時,Shuffle所占比例最大;然而每個機架有8個節點時,作業處理的數據規模較小時(32 GB),Shuffle所占比例較大,通信優化的效果也不明顯,但是隨著數據規模增加通信優化效果開始明顯;當集群規模增加,但是計算作業數據量小時,集群管理的復雜性提高而中間數據通信量小,因此網絡背景流量掩蓋了網絡通信的優化效果。

圖4 集群擴展性對通信優化方案影響
3.4 多用戶環境性能分析
在計算集群或者數據中心中,多租戶提交MapReduce作業是一種常見的應用場景,為了驗證中間數據調度優化算法的應用效果,在本節實驗中模擬集群生產環境的多租戶多作業的應用場景,并且觀察性能表現。先選用表1中的基準作業5類Map密集的作業,然后每個作業選擇不同的10個數據集來模擬50個用戶作業。采用隨機算法來模擬多個用戶提交給32節點集群來計算。從作業響應時間和作業計算時間兩個角度來觀察性能優化效果,以進入作業隊列到開始執行的間隔作為響應時間,作業開始執行到執行完畢為作業計算時間。分別統計5類作業的平均響應時間和作業計算時間,如表2~3所示。

表2 作業平均響應時間對比
從表2可看出,在多作業環境中本文優化方案對降低平均響應時間有一定的效果,平均響應時間降低了2%~4%;對于中間數據通信量小的作業,平均響應時間優化效果不明顯。但是通過平均響應時間的方差數據可看出,通信優化方案的計算過程更加穩定。
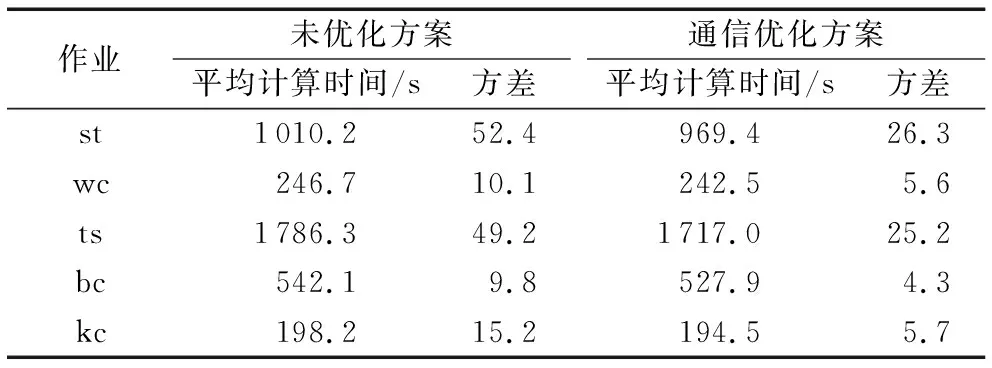
表3 作業執行時間對比
表3顯示本文方案對作業的平均計算時間也有一定程度的優化效果,而且計算過程更加穩定,對于Shuffle密集的作業計算性能優化效果明顯。由于本文重點考慮中間數據傳輸的性能優化,對中間數據量小的作業性能效果不顯著。
4 結語
MapReduce計算模式的大數據處理作業中以Map密集型作業為主,Map密集型作業又能分成Shuffle密集和Shuffle稀疏兩種類型。其中Shuffle密集類型作業中間計算數據量大,有本文提出的通信優化方法對該類型作業優化效果明顯。首先以MapReduce作業的預調度信息為依據,提取作業運行前的靜態特征;然后采用貝葉斯分類器建立集群機架通信局部性與作業特征之間的非線性關系;再根據未知作業特征信息來預測作業分類,根據作業類別重新優化調度方案并且執行優化后的調度方案。實驗結果表明,本文通信優化方案不僅減少了作業的整體計算時間,并且減小了Shuffle階段的比例,體現出對中間數據網絡傳輸延遲的優化效果;而且該優化方案隨著數據規模的增加優化效果更好,適合大數據密集型的應用場景。另外,該方案對集群擴展具有良好的適應性。在仿真的多租戶多作業場景中,通信優化方案減少了作業響應時間和執行時間,因此在工程實際中有較好的應用價值。目前通信優化方案對網絡拓撲結構依賴性較大,并且對各種網絡拓撲結構的適應性并未得到驗證,這也是下一步研究方向。
參考文獻(References)
[1] CHOWDHURY M, ZAHARIA M, MA J, et al. Managing data transfers in computer clusters with orchestra[J]. ACM SIGCOMM Computer Communication Review, 2011, 41(4): 98-109.
[2] YU W, WANG Y, QUE X, et al. Design evaluation of network-levitated merge for Hadoop acceleration[J]. IEEE Transactions on Parallel and Distributed Systems, 2014, 25(3): 602-611.
[3] RAHMAN M W, ISLAM N S, LU X, et al. A comprehensive study of MapReduce over lustre for intermediate data placement and shuffle strategies on HPC clusters[J]. IEEE Transactions on Parallel and Distributed Systems, 2017, 28(3): 633-646.
[4] SHI W, WANG Y, CORRIVEAU J, et al. Smart shuffling in MapReduce: a solution to balance network traffic and workloads[C]// Proceedings of the 2015 IEEE/ACM 8th International Conference on Utility and Cloud Computing. Piscataway, NJ: IEEE, 2015: 35-44.
[5] ARSLAN E, SHEKHAR M, KOSAR T. Locality and network-aware reduce task scheduling for data-intensive applications[C]// DataCloud 2014: Proceedings of the 5th International Workshop on Data-Intensive Computing in the Clouds. Piscataway, NJ: IEEE, 2014: 14-24.
[6] ZHENG H, WAN Z, WU J. Optimizing MapReduce framework through joint scheduling of overlapping phases[C]// Proceedings of the 2016 25th International Conference on Computer Communication and Networks. Piscataway, NJ: IEEE, 2016: 1-9.
[7] KE H, LI P, GUO S, et al. On traffic-aware partition and aggregation in MapReduce for big data applications[J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(3): 818-828.
[8] KE H, LI P, GUO S, et al. Aggregation on the fly: reducing traffic for big data in the cloud[J]. IEEE Network, 2015, 29(5): 17-23.
[9] WANG J H, QIU M K, GUO B, et al. Phase-reconfigurable shuffle optimization for Hadoop MapReduce[J]. IEEE Transaction on Cloud Computing, 2017,PP(99): 1.
[10] YU W, WANG Y, QUE X, et al. Virtual shuffling for efficient data movement in MapReduce[J]. IEEE Transactions on Computers, 2015, 64(2): 556-568.
[11] 荀亞玲, 張繼福, 秦嘯.MapReduce集群環境下的數據放置策略[J]. 軟件學報, 2015, 26(8): 2056-2073.(XUN Y L, ZHANG J F, QIN X. Data placement strategy for MapReduce cluster environment[J]. Journal of Software, 2015, 26(8): 2056-2073.)
[12] LEE S, JO J-Y, KIM Y. Performance improvement of MapReduce process by promoting deep data locality[C]// Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics. Piscataway, NJ: IEEE, 2016: 293-301.
This work is partially supported by the Natural Science Foundation of Shandong Province (ZR2017MF050, ZR2015FL014), the Higher Educational Science and Technology Program of Shandong Province (J17KA049), the Independent Innovation and Achievements Transformation Special Project of Shandong Province (2014ZZCX02702), the Primary Research and Development Project of Shandong Province (2016GGX109001).
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
學生天地(2020年17期)2020-08-25 09:28:54
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
故事大王(2016年7期)2016-09-22 17:30:08
現代企業(2015年2期)2015-02-28 18:45:09
